注意:本文引用自专业人工智能社区Venus AI
更多AI知识请参考原站 ([www.aideeplearning.cn])
项目简介
《数据科学薪酬分析》是一个全面的分析项目,旨在探索和解释数据科学领域的薪酬趋势。通过分析607份不同工作年份、经验水平、就业类型、职位名称、薪酬水平、员工居住地、远程工作比例、公司所在地和公司规模的数据,本项目提供了对数据科学领域薪资结构和动态的深入洞见。
数据集覆盖了从2020年到2022年的薪酬数据,包括原始货币和美元计价的薪资,以及详细的职位分类,如数据科学家、机器学习科学家等。此外,数据集还包含了有关员工远程工作比例和公司大小的信息,这些都是影响当今工作环境的关键因素。
项目目标
- 薪酬趋势分析:研究数据科学领域的平均薪资水平,及其随工作年份的变化趋势。
- 经验水平与薪酬关系:探讨不同经验级别(如初级、中级、高级)的数据科学专业人士的薪资差异。
- 就业类型影响:分析全职、兼职等不同就业类型对薪资的影响。
- 职位分类薪酬比较:比较不同数据科学相关职位的薪资水平。
- 地理位置因素:研究员工居住地和公司所在地对薪资的影响。
- 远程工作比例与薪酬:评估远程工作比例与薪酬之间的关系。
- 公司规模与薪酬:探究不同规模公司对员工薪资的影响。
预期成果: 通过此项目,我们预期能够详细了解数据科学领域的薪酬现状和发展趋势。这将帮助求职者、HR专业人士和业界领导者更好地理解市场薪酬标准,为职业规划、招聘策略和薪酬结构的制定提供数据支持。
数据集
该数据集包含数据科学领域的薪资信息,包括工作年份、经验水平、就业类型、职位名称、薪资(原币和美元)、员工居住地、远程比例、公司地点和公司等各种属性。尺寸。以下是简要概述:
- 样本数据:
- 工作年份: 2020年至2022年。
- 经验级别: MI(中级)、SE(高级)等类别。
- 就业类型:全职(FT)、兼职(PT)等
- 职位名称:数据科学家、机器学习科学家等角色。
- 工资:既以原币计算,也以美元计算。
- 员工居住地和公司地点:国家/地区代码(例如,DE 代表德国,US 代表美国)。
- 远程比率:表示远程完成工作的百分比。
- 公司规模: L(大)、S(小)、M(中)等类别。
- 数量: 607 条。
- 年份范围:数据跨度为 2020 年至 2022 年。
该数据集可以深入了解薪资趋势、经验水平和公司规模对薪资的影响,以及远程工作趋势如何影响数据科学领域。进一步的分析可能包括探索变量之间的相关性、不同职称的薪资分布以及多年来的趋势。
分析方法
本项目将采用综合的数据分析和预测建模方法,利用Python的数据分析和机器学习工具进行深入分析。初始阶段包括统计分析、趋势分析和相关性分析,使用Pandas, NumPy, Matplotlib, Seaborn等工具进行数据处理和可视化,揭示数据科学领域薪酬的关键驱动因素和潜在模式。
进一步,我们将应用以下机器学习算法进行薪酬预测:
- 线性回归(Linear Regression):基础预测模型,用于评估薪酬与各种因素(如经验、公司规模等)之间的线性关系。
- 岭回归(Ridge Regression):线性回归的变体,通过引入正则化减少模型过拟合,适用于具有多重共线性的数据集。
- 随机森林回归(Random Forest Regressor):基于决策树集成的算法,能够处理非线性关系,并提供变量重要性评估,有助于识别影响薪酬的主要因素。
- 梯度提升回归(Gradient Boosting Regressor):另一种基于决策树的集成方法,通过逐步改正前一棵树的错误来增强预测能力,适合捕捉复杂的非线性模式。
- 支持向量回归(Support Vector Regression, SVR):利用核技巧处理非线性关系,特别适用于高维数据集。
项目依赖库:
- matplotlib==3.7.1
- pandas==2.0.2
- scikit_learn==1.2.2
- seaborn==0.13.0
代码实现
数据加载
import numpy as np
import pandas as pd%matplotlib inline
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.model_selection import train_test_split
import warnings
warnings.filterwarnings('ignore')df=pd.read_csv("ds_salaries.csv")df.head()| Unnamed: 0 | work_year | experience_level | employment_type | job_title | salary | salary_currency | salary_in_usd | employee_residence | remote_ratio | company_location | company_size | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 2020 | MI | FT | Data Scientist | 70000 | EUR | 79833 | DE | 0 | DE | L |
| 1 | 1 | 2020 | SE | FT | Machine Learning Scientist | 260000 | USD | 260000 | JP | 0 | JP | S |
| 2 | 2 | 2020 | SE | FT | Big Data Engineer | 85000 | GBP | 109024 | GB | 50 | GB | M |
| 3 | 3 | 2020 | MI | FT | Product Data Analyst | 20000 | USD | 20000 | HN | 0 | HN | S |
| 4 | 4 | 2020 | SE | FT | Machine Learning Engineer | 150000 | USD | 150000 | US | 50 | US | L |
df=df.drop('Unnamed: 0',axis=1)df.info()<class 'pandas.core.frame.DataFrame'> RangeIndex: 607 entries, 0 to 606 Data columns (total 11 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 work_year 607 non-null int64 1 experience_level 607 non-null object 2 employment_type 607 non-null object 3 job_title 607 non-null object 4 salary 607 non-null int64 5 salary_currency 607 non-null object 6 salary_in_usd 607 non-null int64 7 employee_residence 607 non-null object 8 remote_ratio 607 non-null int64 9 company_location 607 non-null object 10 company_size 607 non-null object dtypes: int64(4), object(7) memory usage: 52.3+ KB
数据分析
- 薪酬直方图
sns.histplot(data=df, x="salary_in_usd",kde=True);
直方图是右偏的。 这种分布在较低值单元格(左侧)中出现的次数较多,而在较高值单元格(右侧)中出现的次数很少。
- 薪酬饼图(基于年份)
df.groupby('work_year')['work_year'].count().plot.pie(autopct="%1.1f%%");
超过 50% 的数据是 2022 年的。
- 薪酬箱型图(基于年份)
fig = plt.figure()
ax = fig.add_subplot(1, 1, 1)
sns.boxplot(x='work_year', y='salary_in_usd', data=df, showfliers=False, ax=ax)
sns.stripplot(x='work_year', y='salary_in_usd', data=df, jitter=True, color='black', ax=ax)
plt.show()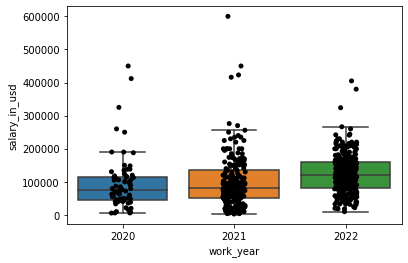
中位数逐年上升。
- 薪酬直方图(基于年份)
sns.histplot(data=df, x="salary_in_usd",kde=True,hue='work_year');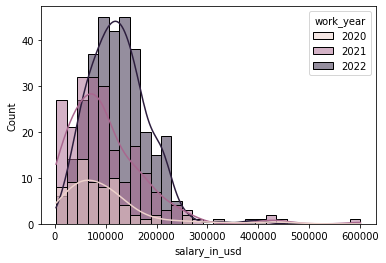
2020年右倾尤为突出,2022年则开始向左偏一点。
- Salary piechart by experience_level
df.groupby('experience_level')['experience_level'].count().plot.pie(autopct="%1.1f%%");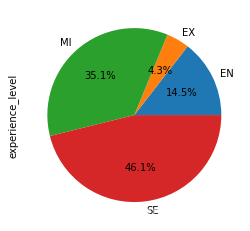
高级职称占46.1%。 其中中级职称占35.1%。
- 薪酬箱型图(基于职称)
fig = plt.figure()
ax = fig.add_subplot(1, 1, 1)
sns.boxplot(x='experience_level', y='salary_in_usd', data=df, showfliers=False, ax=ax)
sns.stripplot(x='experience_level', y='salary_in_usd', data=df, jitter=True, color='black', ax=ax)
plt.show()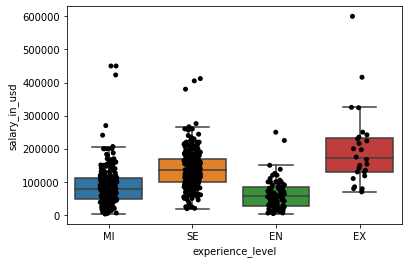
可以理解的是,薪资水平的中位数为 EN < MI < SE < EX。
- 薪酬直方图(基于职称)
sns.histplot(data=df, x="salary_in_usd",kde=True,hue='experience_level');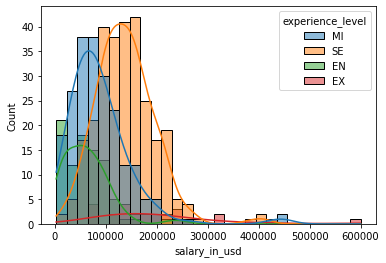
4 个职称等级的趋势都是呈右倾。
- 按工作类型分列的薪资饼图
df.groupby('employment_type')['employment_type'].count().plot.pie(autopct="%1.1f%%");
全职占据 96.0%.
- 按工作类型分列的薪资箱型图
fig = plt.figure()
ax = fig.add_subplot(1, 1, 1)
sns.boxplot(x='employment_type', y='salary_in_usd', data=df, showfliers=False, ax=ax)
sns.stripplot(x='employment_type', y='salary_in_usd', data=df, jitter=True, color='black', ax=ax)
plt.show()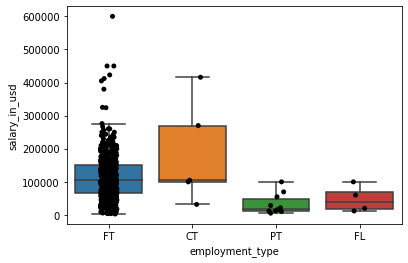
全职和承包商的中位数似乎相同。但承包商的工资范围很广,包括一些很高的工资。这可能取决于他们的技能。
- 按工作类型分列的薪资直方图
sns.histplot(data=df, x="salary_in_usd",kde=True,hue='employment_type');
全职的趋势是向右倾斜的。
- 按职位名称分列的薪资柱状图
df.groupby('job_title')['job_title'].count().sort_values(ascending=True).plot.barh(figsize=(8,10));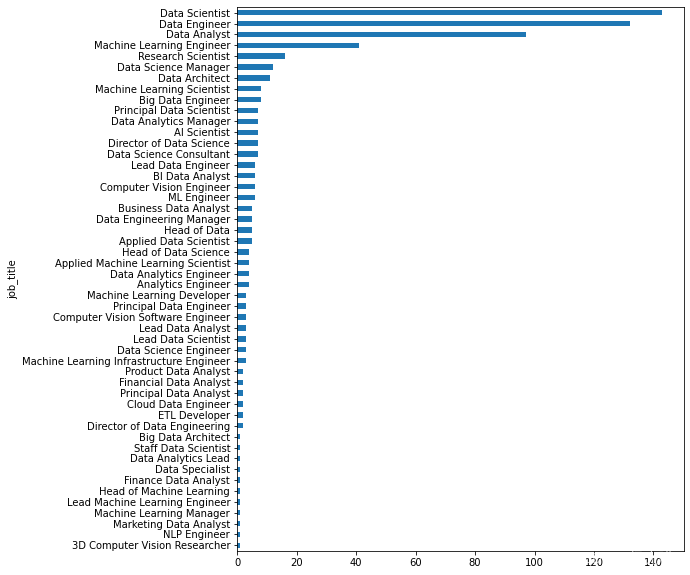
数据科学家、数据工程师和数据分析师是排名前三的职位。机器学习工程师和研究科学家紧随其后。
- 按职位名称分列的薪酬箱型图
fig = plt.figure(figsize=(8,10))
ax = fig.add_subplot(1, 1, 1)
sns.boxplot(y='job_title', x='salary_in_usd', data=df, showfliers=False, ax=ax)
sns.stripplot(y='job_title', x='salary_in_usd', data=df, jitter=True, color='black', ax=ax)
plt.show()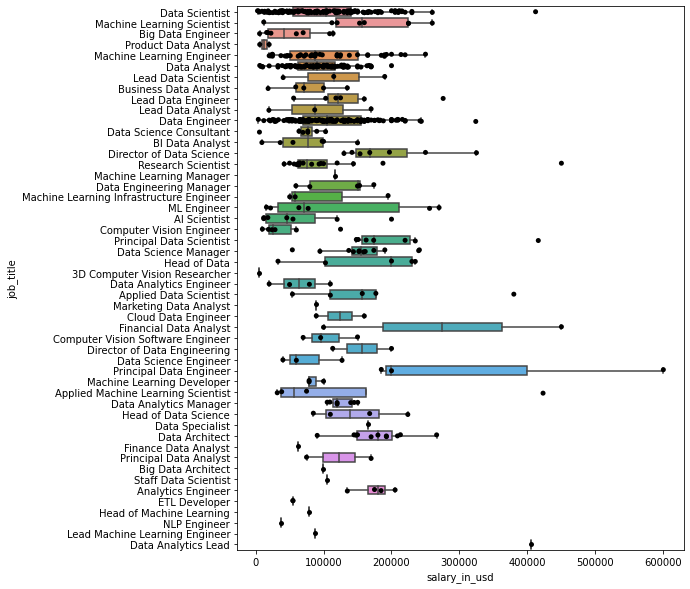
有很多职称和薪酬范围。这可能表明,职称与薪酬的相关性并不强。
- 按雇员居住地分列的薪酬柱状图
df.groupby('employee_residence')['employee_residence'].count().sort_values(ascending=True).plot.barh(figsize=(8,10));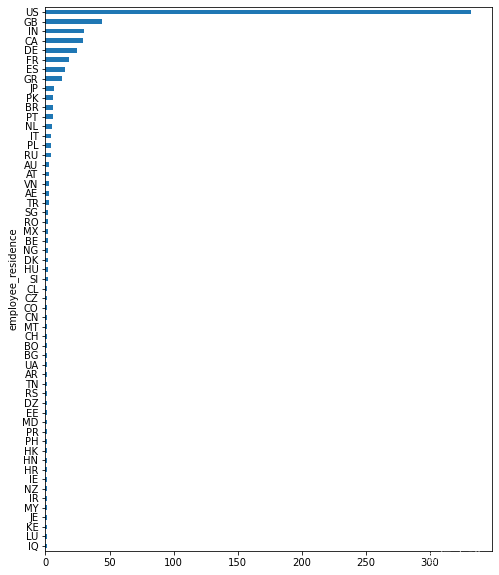
居住在美国的人数占绝大多数。其次是英国,印度和中国。
- 按雇员居住地分列的薪酬箱型图
fig = plt.figure(figsize=(8,15))
ax = fig.add_subplot(1, 1, 1)
sns.boxplot(y='employee_residence', x='salary_in_usd', data=df, showfliers=False, ax=ax)
sns.stripplot(y='employee_residence', x='salary_in_usd', data=df, jitter=True, color='black', ax=ax)
plt.show()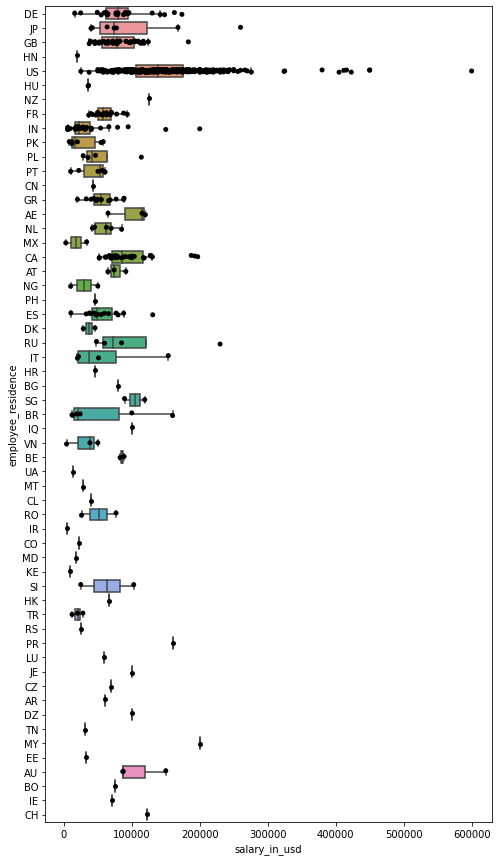
美国的中位数最高,差异最大。
- 按远程比例绘制的薪酬饼图
df.groupby('remote_ratio')['remote_ratio'].count().plot.pie(autopct="%1.1f%%");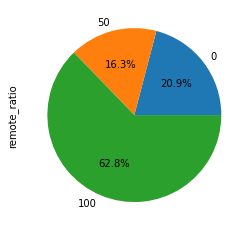
100% 的远程工作占 62.8%。另一方面,无远程工作占 20.9%。
- 按远程比例绘制的薪酬箱型图
fig = plt.figure()
ax = fig.add_subplot(1, 1, 1)
sns.boxplot(x='remote_ratio', y='salary_in_usd', data=df, showfliers=False, ax=ax)
sns.stripplot(x='remote_ratio', y='salary_in_usd', data=df, jitter=True, color='black', ax=ax)
plt.show()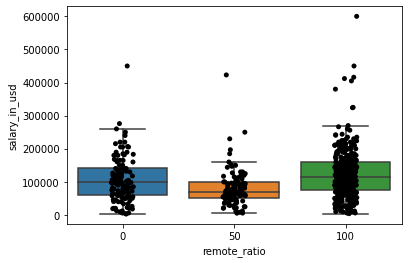
纯远程工作的薪酬中位数略高于非远程工作的薪酬中位数。
- 按远程比例绘制薪资直方图
sns.histplot(data=df, x="salary_in_usd",kde=True,hue='remote_ratio');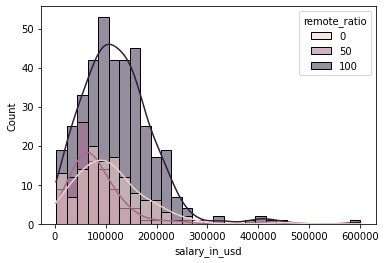
3 种类型的趋势呈右倾。
- 按公司所在地分列的薪金柱状图
df.groupby('company_location')['company_location'].count().sort_values(ascending=True).plot.barh(figsize=(8,8));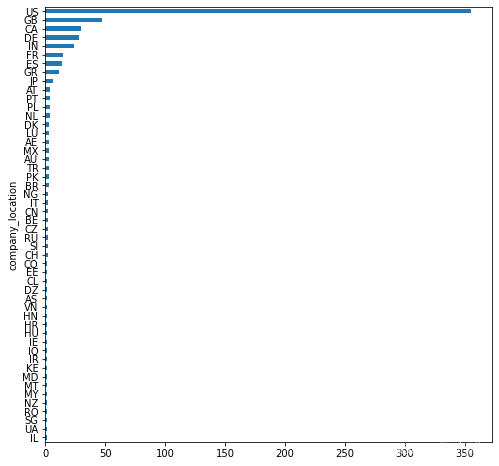
在美国的公司数量占绝大多数。其次是英国和中国。
- 按公司所在地分列的薪资箱型图
fig = plt.figure(figsize=(8,15))
ax = fig.add_subplot(1, 1, 1)
sns.boxplot(y='company_location', x='salary_in_usd', data=df, showfliers=False, ax=ax)
sns.stripplot(y='company_location', x='salary_in_usd', data=df, jitter=True, color='black', ax=ax)
plt.show()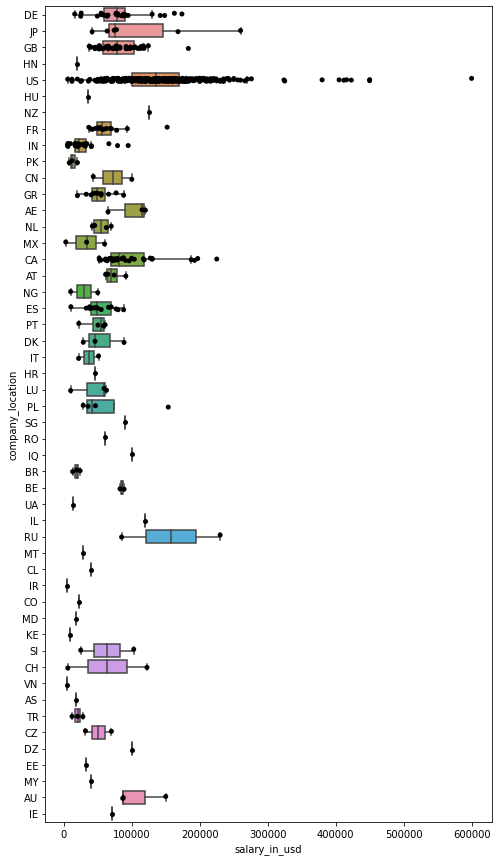
俄罗斯的中位数最高,美国的方差最大。
- 按公司规模分列的薪资饼图
df.groupby('company_size')['company_size'].count().plot.pie(autopct="%1.1f%%");
中型公司占据 53.7%.
- 按公司规模分列的薪金箱型图
fig = plt.figure()
ax = fig.add_subplot(1, 1, 1)
sns.boxplot(x='company_size', y='salary_in_usd', data=df, showfliers=False, ax=ax)
sns.stripplot(x='company_size', y='salary_in_usd', data=df, jitter=True, color='black', ax=ax)
plt.show()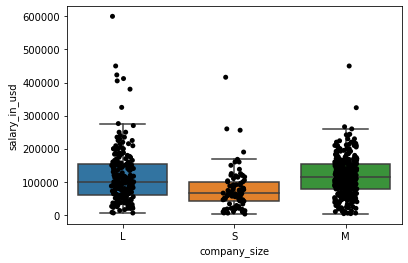
99% 的大中型公司薪酬范围相同
- 按公司规模分列的薪金柱状图
sns.histplot(data=df, x="salary_in_usd",kde=True,hue='company_size');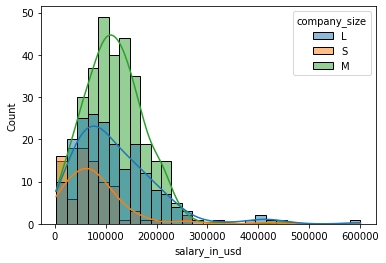
三个类型都是右倾的。
- 公司所在地和员工居住地
df.groupby(['company_location','employee_residence'])['company_location'].count().sort_values(ascending=True).tail(20).plot.barh();
大多数人在国内公司工作,大多数人在美国生活和工作。
特征工程和模型预测
- Features engineering
df2=df[df['job_title'].isin(['Data Analyst', 'Data Engineer', 'Data Scientist'])]df2.info()<class 'pandas.core.frame.DataFrame'> Int64Index: 372 entries, 0 to 605 Data columns (total 11 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 work_year 372 non-null int64 1 experience_level 372 non-null object 2 employment_type 372 non-null object 3 job_title 372 non-null object 4 salary 372 non-null int64 5 salary_currency 372 non-null object 6 salary_in_usd 372 non-null int64 7 employee_residence 372 non-null object 8 remote_ratio 372 non-null int64 9 company_location 372 non-null object 10 company_size 372 non-null object dtypes: int64(4), object(7) memory usage: 34.9+ KB
发现了异常值并丢弃了它们。
fig = plt.figure(figsize=(8,8))
ax = fig.add_subplot(1, 1, 1)
sns.boxplot(y='job_title', x='salary_in_usd', data=df2, showfliers=False, ax=ax)
sns.stripplot(y='job_title', x='salary_in_usd', data=df2, jitter=True, color='black', ax=ax)
plt.show()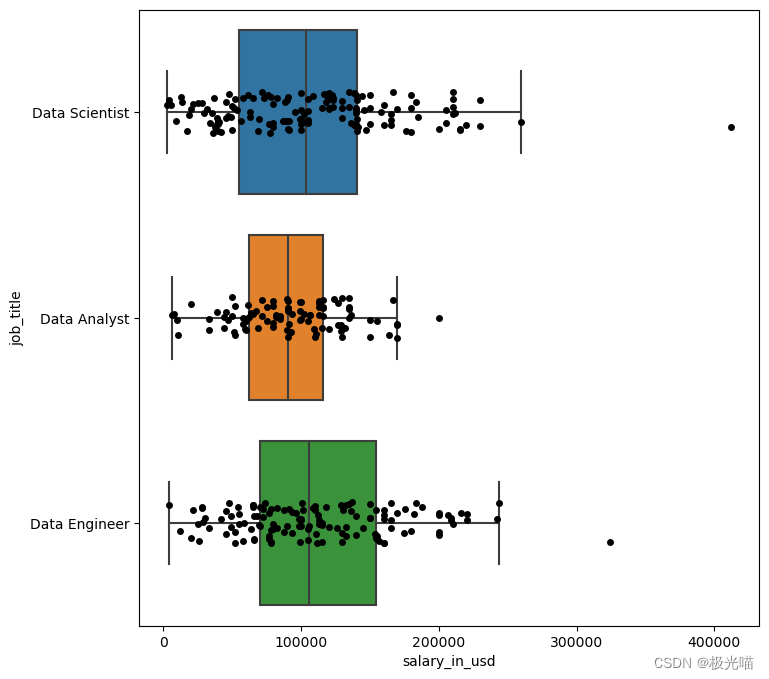
下面,我放弃了工资超过 30 万美元的数据,我专注于全职工作。
df2=df2[df2["salary_in_usd"] <= 300000]
df2=df2[df2['employment_type']== 'FT']删除了一些不太重要的功能。
df2=df2.drop(['work_year','salary_currency', 'employee_residence', 'company_location','salary','employment_type'],axis=1)df2.info()<class 'pandas.core.frame.DataFrame'> Int64Index: 363 entries, 0 to 605 Data columns (total 5 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 experience_level 363 non-null object 1 job_title 363 non-null object 2 salary_in_usd 363 non-null int64 3 remote_ratio 363 non-null int64 4 company_size 363 non-null object dtypes: int64(2), object(3) memory usage: 17.0+ KB
- 按职位和经验水平划分的薪资散点图
plt.figure(figsize=(8, 4))
plt.legend(fontsize=10)
plt.tick_params(labelsize=10)
ax=sns.scatterplot(x=df2['salary_in_usd'],y=df2['job_title'],hue=df2['experience_level'],data=df2)
plt.xticks(rotation=90)
ax.legend(loc='upper left',bbox_to_anchor=(1,1));No artists with labels found to put in legend. Note that artists whose label start with an underscore are ignored when legend() is called with no argument.
0 MI
5 EN
7 MI
10 EN
11 MI
..
601 EN
602 SE
603 SE
604 SE
605 SE
Name: experience_level, Length: 363, dtype: object

- Salary scatterplot by job_title and remote_ratio
plt.figure(figsize=(8, 4))
plt.legend(fontsize=10)
plt.tick_params(labelsize=10)
ax=sns.scatterplot(x=df2['salary_in_usd'],y=df2['job_title'],hue=df2['remote_ratio'],data=df2)
plt.xticks(rotation=90)
ax.legend(loc='upper left',bbox_to_anchor=(1,1));No artists with labels found to put in legend. Note that artists whose label start with an underscore are ignored when legend() is called with no argument.

- Salary scatterplot by job_title and company_size
plt.figure(figsize=(8, 4))
plt.legend(fontsize=10)
plt.tick_params(labelsize=10)
ax=sns.scatterplot(x=df2['salary_in_usd'],y=df2['job_title'],hue=df2['company_size'],data=df2)
plt.xticks(rotation=90)
ax.legend(loc='upper left',bbox_to_anchor=(1,1));No artists with labels found to put in legend. Note that artists whose label start with an underscore are ignored when legend() is called with no argument.

虚拟变量也称为指示变量,是为以数字形式表示分类数据而创建的二元 (0/1) 变量。这是必要的,因为许多机器学习算法只能处理数字输入。
如何pd.get_dummies()运作
该pd.get_dummies()函数将分类变量转换为虚拟/指标变量。对于分类列中的每个唯一值,get_dummies创建一个新列(虚拟变量),其中:
- 列名是原始变量名,后跟类别值。
- 此列中的每个单元格要么为 1(如果原始行具有该类别),要么为 0(否则)。
df2=pd.get_dummies(df2)
df2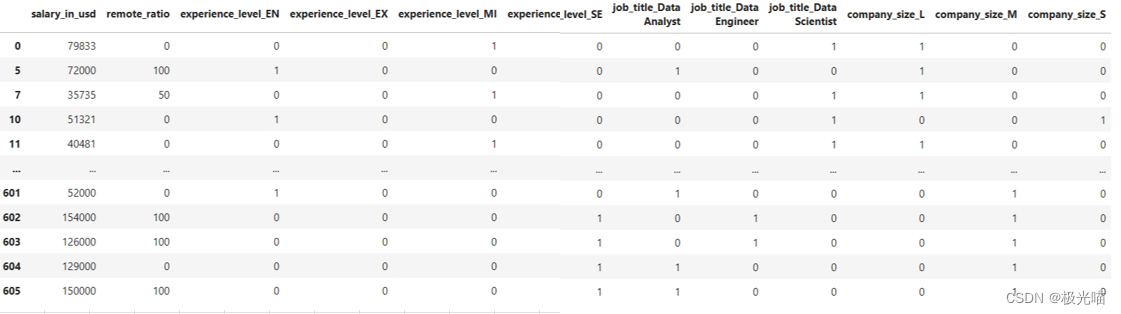
363 rows × 12 columns
df2['remote_ratio']=df2['remote_ratio']/100- 相关性热力图
plt.figure(figsize = (15,8))
sns.heatmap(df2.corr(),annot=True, fmt="1.1f");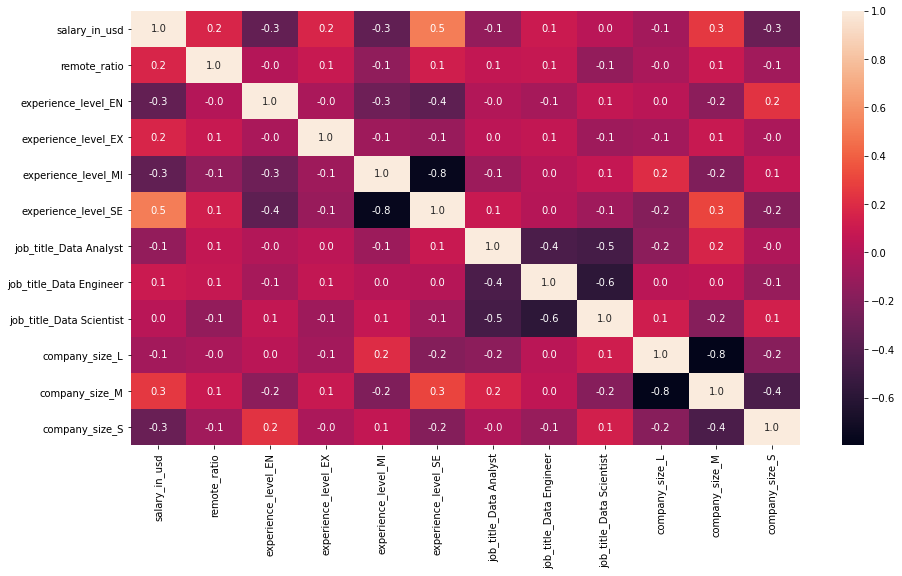
机器学习模型进行薪酬预测
x_train, x_test, y_train, y_test = train_test_split(df2.iloc[:, 1:14], df2.iloc[:, 0],
test_size=0.2, random_state=1)- Linear Regression
from sklearn.linear_model import LinearRegression
from sklearn.metrics import r2_score
from sklearn.metrics import mean_absolute_error
lr = LinearRegression()
lr.fit(x_train, y_train)
pred_lr = lr.predict(x_test)
r2_lr = r2_score(y_test, pred_lr)
mae_lr = mean_absolute_error(y_test, pred_lr)
print("R2 : %.3f" % r2_lr)
print("MAE : %.3f" % mae_lr)
print("Coef = ", lr.coef_)
print("Intercept =", lr.intercept_)R2 : 0.264 MAE : 33145.986 Coef = [ 1.34747637e+04 -9.03859743e+17 -9.03859743e+17 -9.03859743e+17 -9.03859743e+17 7.77763607e+17 7.77763607e+17 7.77763607e+17 -1.67886506e+17 -1.67886506e+17 -1.67886506e+17] Intercept = 2.939826430289901e+17
import matplotlib.pyplot as plt
%matplotlib inline
plt.ylabel("pred_lr")
plt.xlabel("y_test")
plt.scatter(pred_lr, y_test)
plt.show()
- Ridge
from sklearn.linear_model import Ridge
ridge = Ridge(alpha=10)
ridge.fit(x_train, y_train)
pred_ridge = ridge.predict(x_test)
r2_ridge = r2_score(y_test, pred_ridge)
mae_ridge = mean_absolute_error(y_test, pred_ridge)
print("R2 : %.3f" % r2_ridge)
print("MAE : %.3f" % mae_ridge)
print("Coef = ", ridge.coef_)R2 : 0.291 MAE : 32240.618 Coef = [ 12278.70035719 -32880.25157448 23252.10468529 -18269.26797332 27897.4148625 -14160.53719647 5551.82082446 8608.71637201 7246.10235738 13329.46968776 -20575.57204514]
plt.ylabel("pred_ridge")
plt.xlabel("y_test")
plt.scatter(pred_ridge, y_test)
plt.show()
- Random Forest Regressor
from sklearn.ensemble import RandomForestRegressor
RF = RandomForestRegressor()
RF.fit(x_train, y_train)
pred_RF = RF.predict(x_test)
r2_RF = r2_score(y_test, pred_RF)
mae_RF = mean_absolute_error(y_test, pred_RF)
print("R2 : %.3f" % r2_RF)
print("MAE : %.3f" % mae_RF)
print("feature_importances = ", RF.feature_importances_)R2 : 0.269 MAE : 31828.117 feature_importances = [0.14114534 0.03111304 0.09329405 0.02184626 0.42034331 0.07834587 0.02598718 0.0456546 0.03311938 0.03204233 0.07710864]
plt.ylabel("pred_RF")
plt.xlabel("y_test")
plt.scatter(pred_RF, y_test)
plt.show()
- Grandien Boosting Regressor
from sklearn.ensemble import GradientBoostingRegressor
GBDT = GradientBoostingRegressor()
GBDT.fit(x_train, y_train)
pred_GBDT = GBDT.predict(x_test)
r2_GBDT = r2_score(y_test, pred_GBDT)
mae_GBDT = mean_absolute_error(y_test, pred_GBDT)
print("R2 : %.3f" % r2_GBDT)
print("MAE : %.3f" % mae_GBDT)
print("feature_importances = ", GBDT.feature_importances_)R2 : 0.285 MAE : 32055.108 feature_importances = [0.11095028 0.04876561 0.1042554 0.0203419 0.45763526 0.08220522 0.00881789 0.05159151 0.02251798 0.00328136 0.0896376 ]
plt.ylabel("pred_GBDT")
plt.xlabel("y_test")
plt.scatter(pred_GBDT, y_test)
plt.show()
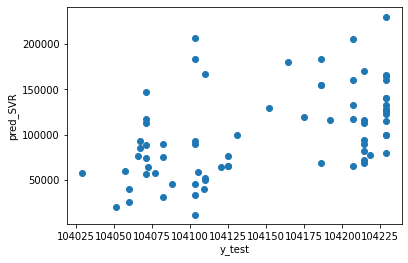
- Support Vector Regression
from sklearn.svm import SVR
SVR = SVR(kernel='linear', C=1, epsilon=0.1, gamma='auto')
SVR.fit(x_train, y_train)
pred_SVR = SVR.predict(x_test)
r2_SVR = r2_score(y_test, pred_SVR)
mae_SVR = mean_absolute_error(y_test, pred_SVR)
print("R2 : %.3f" % r2_SVR)
print("MAE : %.3f" % mae_SVR)
print("Coef = ", SVR.coef_)R2 : -0.002 MAE : 40603.041 Coef = [[ 22. -32. 4. -38. 66. -10. 5. 5. -9. 34. -25.]]
plt.ylabel("pred_SVR")
plt.xlabel("y_test")
plt.scatter(pred_SVR, y_test)
plt.show()