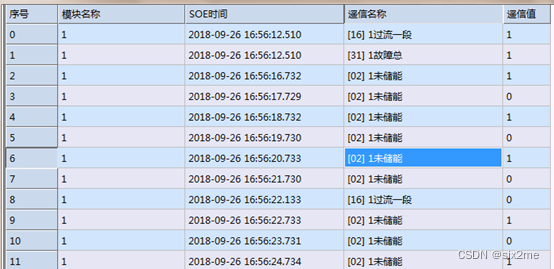
PyTorch深度学习实战(40)——零样本学习
- 0. 前言
- 1. 零样本学习
- 2. 实现零样本学习模型
- 2.1 模型分析
- 2.2 构建零样本学习模型
- 小结
- 系列链接
0. 前言
零样本学习 (Zero-Shot Learning) 是一种机器学习方法,旨在解决传统监督学习中,当训练数据中不存在某个类别的样本时,如何对该类别进行分类的问题。在传统监督学习中,分类模型需要通过训练数据学习到每个类别的特征和模式,并在测试阶段根据这些学习到的知识对新样本进行分类。然而,在现实世界中,我们无法获得所有可能类别的训练样本,因此零样本学习成为了一种重要的解决方案。在本节中,我们将学习零样本学习的基本概念,并使用 PyTorch 实现零样本学习模型。
1. 零样本学习
零样本学习 (Zero-Shot Learning) 是一种用于在没有相关样本数据的情况下分类或识别新的物体类别的机器学习技术。与传统监督学习不同,它并不需要训练数据集中包含所有可能的类别,而是通过学习如何从类别的语义描述(例如属性或关系)中推断出新类别的特征,并将这些特征用于分类或识别。在实际应用中,零样本学习可以帮助我们克服由于数据收集和标注成本高昂而产生的数据样本不足问题。
在零样本学习中,模型必须利用词向量自动生成属性(没有为训练提供属性),词向量包含单词之间的语义相似性。例如,所有动物都会有相似的词向量,而汽车则与动物之间的词向量表示有较大差距,本节中,我们将使用预训练的词向量。具有相似上下文的单词具有相似的词向量,词向量的 t-SNE 表示示例如下所示:

在上图中,可以看到相同类别的样本在二维空间中相互聚集,相似的类别也有相似的词向量。因此,单词就像图像一样,也有矢量嵌入,可以用于获取它们之间的相似性。
在下一小节中,实现零样本学习模型,利用以上原理识别模型在训练期间没有见到的类别。本质上,我们将直接学习如何将图像特征映射到单词特征。
2. 实现零样本学习模型
2.1 模型分析
在本节中,我们将使用 PyTorch 实现零样本学习模型,模型构建策略如下:
- 导入训练数据集
- 从预训练的词向量模型中获取每个类别对应的词向量
- 将图像输入预训练的图像分类模型,如
VGG16 - 网络预测输出图像中物体对应的词向量
- 训练模型后,在新的测试图像上预测词向量
- 最接近预测词向量的词向量类别作为测试图像的类别
2.2 构建零样本学习模型
接下来,使用 PyTorch 实现以上策略。
(1) 访问 GitHub 下载相关数据,并解压。
(2) 导入相关库:
import gzip
import _pickle as cPickle
import torch
import numpy as np
from torch import nn, optim
from torch.utils.data import DataLoader, Dataset
from matplotlib import pyplot as plt
from sklearn.preprocessing import LabelEncoder, normalize
device = 'cuda' if torch.cuda.is_available() else 'cpu'
(3) 定义特征数据的路径 (DATAPATH) 以及 word2vec 嵌入 (WORD2VECPATH):
WORD2VECPATH = "zero-shot-learning-master/data/class_vectors.npy"
DATAPATH = "zero-shot-learning-master/data/zeroshot_data.pkl"
(4) 提取可用类别列表:
with open('zero-shot-learning-master/src/train_classes.txt', 'r') as infile:
train_classes = [str.strip(line) for line in infile]
(5) 加载特征向量数据:
with gzip.GzipFile(DATAPATH, 'rb') as infile:
data = cPickle.load(infile)
(6) 定义训练数据和属于零样本类别的数据(训练期间不存在的类别)。在训练期间,只显示训练类别,并隐藏零样本模型类别:
training_data = [instance for instance in data if instance[0] in train_classes]
zero_shot_data = [instance for instance in data if instance[0] not in train_classes]
np.random.shuffle(training_data)
(7) 每个类别获取 300 张图像样本进行训练,其余图像用于进行验证:
train_size = 300 # per class
train_data, valid_data = [], []
for class_label in train_classes:
ctr = 0
for instance in training_data:
if instance[0] == class_label:
if ctr < train_size:
train_data.append(instance)
ctr+=1
else:
valid_data.append(instance)
(8) 打乱训练和验证数据,并将与类别对应的向量提取到字典 vectors 中:
np.random.shuffle(train_data)
np.random.shuffle(valid_data)
vectors = {i:j for i,j in np.load(WORD2VECPATH, allow_pickle=True)}
(9) 获取训练和验证数据的图像和词嵌入特征:
train_data = [(feat, vectors[clss]) for clss,feat in train_data]
valid_data = [(feat, vectors[clss]) for clss,feat in valid_data]
(10) 获取训练、验证和零样本类别:
train_clss = [clss for clss,feat in train_data]
valid_clss = [clss for clss,feat in valid_data]
zero_shot_clss = [clss for clss,feat in zero_shot_data]
(11) 定义训练数据、验证数据和零样本数据的输入和输出数组:
x_train, y_train = zip(*train_data)
x_train, y_train = np.squeeze(np.asarray(x_train)), np.squeeze(np.asarray(y_train))
x_train = normalize(x_train, norm='l2')
x_valid, y_valid = zip(*valid_data)
x_valid, y_valid = np.squeeze(np.asarray(x_valid)), np.squeeze(np.asarray(y_valid))
x_valid = normalize(x_valid, norm='l2')
y_zsl, x_zsl = zip(*zero_shot_data)
x_zsl, y_zsl = np.squeeze(np.asarray(x_zsl)), np.squeeze(np.asarray(y_zsl))
x_zsl = normalize(x_zsl, norm='l2')
(12) 定义训练、验证数据集和数据加载器:
from torch.utils.data import TensorDataset
trn_ds = TensorDataset(*[torch.Tensor(t).to(device) for t in [x_train, y_train]])
val_ds = TensorDataset(*[torch.Tensor(t).to(device) for t in [x_valid, y_valid]])
trn_dl = DataLoader(trn_ds, batch_size=32, shuffle=True)
val_dl = DataLoader(val_ds, batch_size=32, shuffle=False)
(13) 构建模型,以 4096 维特征作为为输入,预测 300 维向量为输出:
def build_model():
return nn.Sequential(
nn.Linear(4096, 1024), nn.ReLU(inplace=True),
nn.BatchNorm1d(1024), nn.Dropout(0.8),
nn.Linear(1024, 512), nn.ReLU(inplace=True),
nn.BatchNorm1d(512), nn.Dropout(0.8),
nn.Linear(512, 256), nn.ReLU(inplace=True),
nn.BatchNorm1d(256), nn.Dropout(0.8),
nn.Linear(256, 300)
)
(14) 定义函数在批数据上训练和验证模型:
def train_batch(model, data, optimizer, criterion):
ims, labels = data
_preds = model(ims)
optimizer.zero_grad()
loss = criterion(_preds, labels)
loss.backward()
optimizer.step()
return loss.item()
@torch.no_grad()
def validate_batch(model, data, criterion):
ims, labels = data
_preds = model(ims)
loss = criterion(_preds, labels)
return loss.item()
(15) 训练模型:
model = build_model().to(device)
criterion = nn.MSELoss()
optimizer = optim.Adam(model.parameters(), lr=1e-3)
n_epochs = 60
trn_loss_epochs = []
val_loss_epochs = []
for ex in range(n_epochs):
N = len(trn_dl)
trn_loss = []
val_loss = []
for bx, data in enumerate(trn_dl):
loss = train_batch(model, data, optimizer, criterion)
pos = (ex + (bx+1)/N)
trn_loss.append(loss)
trn_loss_epochs.append(np.average(trn_loss))
N = len(val_dl)
for bx, data in enumerate(val_dl):
loss = validate_batch(model, data, criterion)
pos = (ex + (bx+1)/N)
val_loss.append(loss)
val_loss_epochs.append(np.average(val_loss))
if ex == 10:
optimizer = optim.Adam(model.parameters(), lr=1e-4)
if ex == 40:
optimizer = optim.Adam(model.parameters(), lr=1e-5)
epochs = np.arange(n_epochs)+1
plt.plot(epochs, trn_loss_epochs, 'bo', label='Training loss A')
plt.plot(epochs, val_loss_epochs, 'r-', label='Test loss B')
plt.title('Training and Test loss over increasing epochs')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.grid('off')
plt.show()

(16) 预测属于零样本类别(模型未见过的类别)的图像 (x_zsl),并获取与所有可用类别相对应的实际特征 vectors 和类别名 classnames:
pred_zsl = model(torch.Tensor(x_zsl).to(device)).cpu().detach().numpy()
class_vectors = sorted(np.load(WORD2VECPATH, allow_pickle=True), key=lambda x: x[0])
classnames, vectors = zip(*class_vectors)
classnames = list(classnames)
vectors = np.array(vectors)
(17) 计算每个预测向量与可用类别对应的向量之间的距离,并测量前五个预测中出现的零样本类别的数量:
dists = (pred_zsl[None] - vectors[:,None])
dists = (dists**2).sum(-1).T
best_classes = []
for item in dists:
best_classes.append([classnames[j] for j in np.argsort(item)[:5]])
print(np.mean([i in J for i,J in zip(zero_shot_clss, best_classes)]))
# 0.7328664332166083
从以上结果可以看出,在模型的前 5 个预测中,可以正确预测约 73% 的图像,其中包含训练期间不存在类别的对象。其中,前 1、2 和 3 个预测的正确分类图像的百分比分别为 6%、14% 和 40%。
小结
在零样本学习中,每个类别通常都与一些语义属性或描述相关联,这些属性可以包括文本描述、语义嵌入或语义关系等。模型将这些语义信息与特征空间进行联系,从而能够根据语义相似度将新的未见类别样本归类到正确的类别中。具体来说,零样本学习的过程可以分为两个主要步骤:建模和推理。在建模阶段,模型需要学习到每个类别的语义表示,通常是将语义属性映射到一个低维的嵌入空间中。在推理阶段,当遇到一个未见类别的样本时,模型会将其与已知类别的语义表示进行比较,并基于相似度进行分类。在本节中,我们学习了零样本分类模型,用以在训练中不存在某个类别的图像时进行预测。
系列链接
PyTorch深度学习实战(1)——神经网络与模型训练过程详解
PyTorch深度学习实战(2)——PyTorch基础
PyTorch深度学习实战(3)——使用PyTorch构建神经网络
PyTorch深度学习实战(4)——常用激活函数和损失函数详解
PyTorch深度学习实战(5)——计算机视觉基础
PyTorch深度学习实战(6)——神经网络性能优化技术
PyTorch深度学习实战(7)——批大小对神经网络训练的影响
PyTorch深度学习实战(8)——批归一化
PyTorch深度学习实战(9)——学习率优化
PyTorch深度学习实战(10)——过拟合及其解决方法
PyTorch深度学习实战(11)——卷积神经网络
PyTorch深度学习实战(12)——数据增强
PyTorch深度学习实战(13)——可视化神经网络中间层输出
PyTorch深度学习实战(14)——类激活图
PyTorch深度学习实战(15)——迁移学习
PyTorch深度学习实战(16)——面部关键点检测
PyTorch深度学习实战(17)——多任务学习
PyTorch深度学习实战(18)——目标检测基础
PyTorch深度学习实战(19)——从零开始实现R-CNN目标检测
PyTorch深度学习实战(20)——从零开始实现Fast R-CNN目标检测
PyTorch深度学习实战(21)——从零开始实现Faster R-CNN目标检测
PyTorch深度学习实战(22)——从零开始实现YOLO目标检测
PyTorch深度学习实战(23)——从零开始实现SSD目标检测
PyTorch深度学习实战(24)——使用U-Net架构进行图像分割
PyTorch深度学习实战(25)——从零开始实现Mask R-CNN实例分割
PyTorch深度学习实战(26)——多对象实例分割
PyTorch深度学习实战(27)——自编码器(Autoencoder)
PyTorch深度学习实战(28)——卷积自编码器(Convolutional Autoencoder)
PyTorch深度学习实战(29)——变分自编码器(Variational Autoencoder, VAE)
PyTorch深度学习实战(30)——对抗攻击(Adversarial Attack)
PyTorch深度学习实战(31)——神经风格迁移
PyTorch深度学习实战(32)——Deepfakes
PyTorch深度学习实战(33)——生成对抗网络(Generative Adversarial Network, GAN)
PyTorch深度学习实战(34)——DCGAN详解与实现
PyTorch深度学习实战(35)——条件生成对抗网络(Conditional Generative Adversarial Network, CGAN)
PyTorch深度学习实战(36)——Pix2Pix详解与实现
PyTorch深度学习实战(37)——CycleGAN详解与实现
PyTorch深度学习实战(38)——StyleGAN详解与实现
PyTorch深度学习实战(39)——小样本学习(Few-shot Learning)







![[C/C++] -- 二叉树](https://img-blog.csdnimg.cn/direct/40d3967febde4c3486c9e53cbfcc084d.jpeg)