第 1 章 Doris 简介
1.1 Doris 概述
Apache Doris 由百度大数据部研发(之前叫百度 Palo,2018 年贡献到 Apache 社区后,更名为 Doris ),在百度内部,有超过 200 个产品线在使用,部署机器超过 1000 台,单一 业务最大可达到上百 TB。
Apache Doris 是一个现代化的 MPP(Massively Parallel Processing,即大规模并行处理) 分析型数据库产品。仅需亚秒级响应时间即可获得查询结果,有效地支持实时数据分析。
Apache Doris 的分布式架构非常简洁,易于运维,并且可以支持 10PB 以上的超大数据集。
Apache Doris 可以满足多种数据分析需求,例如固定历史报表,实时数据分析,交互式数据分析和探索式数据分析等。
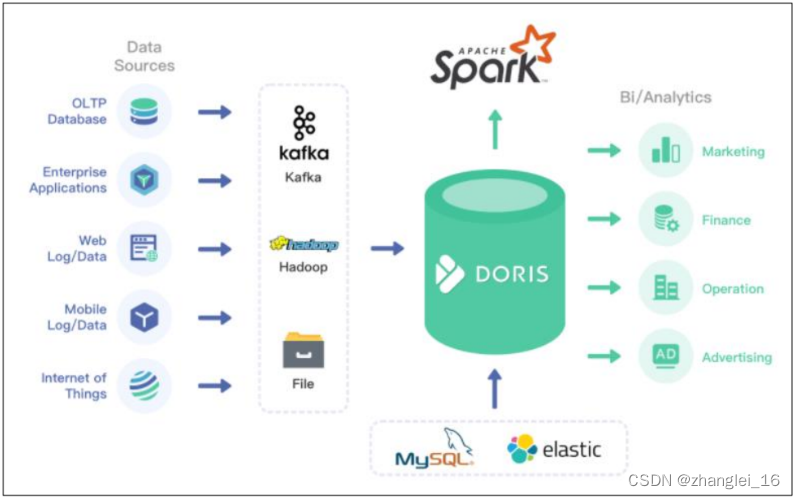

1.2 Doris 架构

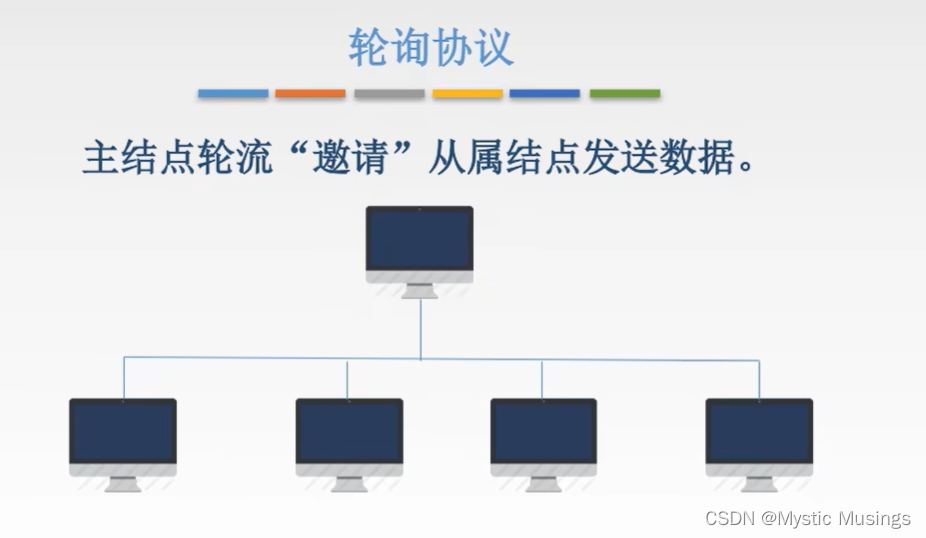
Doris 的架构很简洁,只设 FE(Frontend)、BE(Backend)两种角色、两个进程,不依赖于外部组件,方便部署和运维,FE、BE 都可线性扩展。
-
FE(Frontend):存储、维护集群元数据;负责接收、解析查询请求,规划查询计划,调度查询执行,返回查询结果。主要有三个角色:
(1)Leader 和 Follower:主要是用来达到元数据的高可用,保证单节点宕机的情况下,元数据能够实时地在线恢复,而不影响整个服务。
(2)Observer:用来扩展查询节点,同时起到元数据备份的作用。如果在发现集群压力非常大的情况下,需要去扩展整个查询的能力,那么可以加 observer 的节点。observer 不参与任何的写入,只参与读取。
-
BE(Backend):负责物理数据的存储和计算;依据 FE 生成的物理计划,分布式地执行查询。数据的可靠性由 BE 保证,BE 会对整个数据存储多副本或者是三副本。副本数可根据需求动态调整。
-
MySQL Client:Doris 借助 MySQL 协议,用户使用任意 MySQL 的 ODBC/JDBC 以及 MySQL 的客户端,都可以直接访问 Doris。
-
Broker:Broker 为一个独立的无状态进程。封装了文件系统接口,提供 Doris 读取远端存储系统中文件的能力,包括 HDFS,S3,BOS 等。
第 2 章 编译与安装
安装 Doris,需要先通过源码编译,主要有两种方式:使用 Docker 开发镜像编译(推荐)、直接编译。 直接编译的方式,可以参考官网:https://doris.apache.org/zh-CN/installing/compilation.html
2.1 安装 Docker 环境
1)Docker 要求 CentOS 系统的内核版本高于 3.10 ,首先查看系统内核版本是否满足
uname -r2)使用 root 权限登录系统,确保 yum 包更新到最新
sudo yum update -y 3)假如安装过旧版本,先卸载旧版本
sudo yum remove docker docker-common docker-selinux docker-engine4)安装 yum-util 工具包和 devicemapper 驱动依赖
sudo yum install -y yum-utils device-mapper-persistent-data lvm2 5)设置 yum 源(加速 yum 下载速度)
sudo yum-config-manager --add-repo https://download.docker.com/linux/centos/docker-ce.repo如果连接超时,可以使用 alibaba 的镜像源:
sudo yum-config-manager --add-repo http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo 6)查看所有仓库中所有 docker 版本,并选择特定版本安装,一般可直接安装最新版
yum list docker-ce --showduplicates | sort -r 7)安装 docker
(1)安装最新稳定版本的方式:
sudo yum install docker-ce -y
#安装的是最新稳定版本,因为 repo 中默认只开启 stable 仓库(2)安装指定版本的方式:
sudo yum install <FQPN> -y
# 例如:
sudo yum install docker-ce-20.10.14.ce -y 8)启动并加入开机启动
sudo systemctl start docker #启动 docker
sudo systemctl enable docker #加入开机自启动 9)查看 Version,验证是否安装成功
sudo docker version 若出现 Client 和 Server 两部分内容,则证明安装成功。
2.2 使用 Docker 开发镜像编译
1)下载源码并解压
通过 wget 下载(或者手动上传下载好的压缩包)。
wget https://dist.apache.org/repos/dist/dev/incubator/doris/0.15/0.15.0-rc04/apache-doris-0.15.0-incubating-src.tar.gz解压到/opt/soft
tar -zxvf apache-doris-0.15.0-incubating-src.tar.gz -C /opt/soft2)下载 Docker 镜像
sudo docker pull apache/incubator-doris:build-env-for-0.15.0可以通过以下命令查看镜像是否下载完成。
sudo docker images 3)挂载本地目录运行镜像
以挂载本地 Doris 源码目录的方式运行镜像,这样编译的产出二进制文件会存储在宿主机中,不会因为镜像退出而消失。同时将镜像中 maven 的 .m2 目录挂载到宿主机目录,以防止每次启动镜像编译时,重复下载 maven 的依赖库。
docker run -it \
-v /opt/software/.m2:/root/.m2 \
-v /opt/software/apache-doris-0.15.0-incubating-src/:/root/apache-doris-0.15.0-incubating-src/ \
apache/incubator-doris:build-env-for-0.15.04)在docker容器内,切换到 JDK 8
alternatives --set java java-1.8.0-openjdk.x86_64
alternatives --set javac java-1.8.0-openjdk.x86_64
export JAVA_HOME=/usr/lib/jvm/java-1.8.05)准备 Maven 依赖
编译过程会下载很多依赖,可以将我们准备好的 doris-repo.tar.gz 解压到 Docker 挂载的对应目录,来避免下载依赖的过程,加速编译。
[root@hadoop1 soft]# tar -zxvf doris-repo.tar.gz -C /opt/soft也可以通过指定阿里云镜像仓库来加速下载:
vi /opt/soft/apache-doris-0.15.0-incubating-src/fe/pom.xml
在<repositories>标签下添加:
<repository>
<id>aliyun</id>
<url>http://maven.aliyun.com/nexus/content/groups/public/</url>
</repository>
vi /opt/soft/apache-doris-0.15.0-incubating-src/be/pom.xml
在<repositories>标签下添加:
<repository>
<id>aliyun</id>
<url>http://maven.aliyun.com/nexus/content/groups/public/</url>
</repository>6)编译 Doris
[root@6fef83055389 apache-doris-0.15.0-incubating-src]# pwd
/root/apache-doris-0.15.0-incubating-src
[root@6fef83055389 apache-doris-0.15.0-incubating-src]# sh build.sh 如果是第一次使用 build-env-for-0.15.0 或之后的版本,第一次编译的时候要使用如下命令:
[root@6fef83055389 apache-doris-0.15.0-incubating-src]# pwd
/root/apache-doris-0.15.0-incubating-src
[root@6fef83055389 apache-doris-0.15.0-incubating-src]# sh build.sh --clean --be --fe --ui 因为 build-env-for-0.15.0 版本镜像升级了 thrift(0.9 -> 0.13),需要通过--clean 命令强制使用新版本的 thrift 生成代码文件,否则会出现不兼容的代码。
2.3 安装要求
2.3.1 软硬件需求

5)注意事项
(1)FE 的磁盘空间主要用于存储元数据,包括日志和 image。通常从几百 MB 到几个GB 不等。
(2)BE 的磁盘空间主要用于存放用户数据,总磁盘空间按用户总数据量* 3(3 副本)计算,然后再预留额外 40%的空间用作后台 compaction 以及一些中间数据的存放。
(3)一台机器上可以部署多个 BE 实例,但是只能部署一个 FE。如果需要 3 副本数据,那么至少需要 3 台机器各部署一个 BE 实例(而不是 1 台机器部署 3 个 BE 实例)。多个 FE 所在服务器的时钟必须保持一致(允许最多 5 秒的时钟偏差)
(4)测试环境也可以仅适用一个 BE 进行测试。实际生产环境,BE 实例数量直接决定了整体查询延迟。
(5)所有部署节点关闭 Swap。
(6)FE 节点数据至少为 1(1 个 Follower)。当部署 1 个 Follower 和 1 个 Observer 时,可以实现读高可用。当部署 3 个 Follower 时,可以实现读写高可用(HA)。
(7)Follower 的数量必须为奇数,Observer 数量随意。
(8)根据以往经验,当集群可用性要求很高时(比如提供在线业务),可以部署 3 个Follower 和 1-3 个 Observer。如果是离线业务,建议部署 1 个 Follower 和 1-3 个 Observer。
(9)Broker 是用于访问外部数据源(如 HDFS)的进程。通常,在每台机器上部署一个 broker 实例即可。
2.3.2 默认端口

当部署多个 FE 实例时,要保证 FE 的 http_port 配置相同。
部署前请确保各个端口在应有方向上的访问权限。
2.4 集群部署

生产环境建议 FE 和 BE 分开。
2.4.1 创建目录并拷贝编译后的文件
1)创建目录并拷贝编译后的文件
mkdir /opt/mod/apache-doris-0.15.0
cp -r /opt/soft/apache-doris-0.15.0-incubating-src/output /opt/mod/apache-doris-0.15.02)修改可打开文件数(每个节点)
sudo vi /etc/security/limits.conf
* soft nofile 65535
* hard nofile 65535
* soft nproc 65535
* hard nproc 65535 重启永久生效,也可以用 ulimit -n 65535 临时生效。
2.4.2 部署 FE 节点
1)创建 fe 元数据存储的目录
mkdir /opt/mod/apache-doris-0.15.0/doris-meta 2)修改 fe 的配置文件
vi /opt/mod/apache-doris-0.15.0/fe/conf/fe.conf
#配置文件中指定元数据路径:
meta_dir = /opt/mod/apache-doris-0.15.0/doris-meta
#修改绑定 ip(每台机器修改成自己的 ip)
priority_networks = 192.168.1.31/24 注意:
-
生产环境强烈建议单独指定目录不要放在 Doris 安装目录下,最好是单独的磁盘(如果有 SSD 最好)。
-
如果机器有多个 ip, 比如内网外网, 虚拟机 docker 等, 需要进行 ip 绑定,才能正确识别。
-
JAVA_OPTS 默认 java 最大堆内存为 4GB,建议生产环境调整至 8G 以上。
3)启动 hadoop1 的 FE
/opt/mod/apache-doris-0.15.0/fe/bin/start_fe.sh --daemon可以通过页面查看FE相关信息

2.4.3 配置 BE 节点
1)分发 BE
xsync /opt/mod/apache-doris-0.15.0/be 2)创建 BE 数据存放目录(每个节点)
mkdir /opt/mod/apache-doris-0.15.0/doris-storage1
mkdir /opt/mod/apache-doris-0.15.0/doris-storage23)修改 BE 的配置文件(每个节点)
vi /opt/mod/apache-doris-0.15.0/be/conf/be.conf
#配置文件中指定数据存放路径:
storage_root_path = /opt/mod/apache-doris-0.15.0/doris-storage1;/opt/mod/apache-doris-0.15.0/doris-storage2
#修改绑定 ip(每台机器修改成自己的 ip)
priority_networks = 192.168.1.31/24 注意:
-
storage_root_path 默认在 be/storage 下,需要手动创建该目录。多个路径之间使用英文状态的分号;分隔(最后一个目录后不要加)。
-
可以通过路径区别存储目录的介质,HDD 或 SSD。可以添加容量限制在每个路径的末尾,通过英文状态逗号,隔开,如:
storage_root_path=/home/disk1/doris.HDD,50;/home/disk2/doris.SSD,10;/home/disk2/doris 说明:
/home/disk1/doris.HDD,50,表示存储限制为 50GB,HDD;
/home/disk2/doris.SSD,10,存储限制为 10GB,SSD;
/home/disk2/doris,存储限制为磁盘最大容量,默认为 HDD
-
如果机器有多个 IP, 比如内网外网, 虚拟机 docker 等, 需要进行 IP 绑定,才能正确识别。
2.4.4 在 FE 中添加所有 BE 节点
BE 节点需要先在 FE 中添加,才可加入集群。可以使用 mysql-client 连接到 FE。
1)安装 MySQL Client
(1)创建目录
mkdir /opt/soft/mysql-client/ (2)上传相关以下三个 rpm 包到/opt/soft/mysql-client/
➢ mysql-community-client-5.7.28-1.el7.x86_64.rpm
➢ mysql-community-common-5.7.28-1.el7.x86_64.rpm
➢ mysql-community-libs-5.7.28-1.el7.x86_64.rpm
(3)检查当前系统是否安装过 MySQL
sudo rpm -qa|grep mariadb
#如果存在,先卸载
sudo rpm -e --nodeps mariadb mariadb-libs mariadb-server (4)安装
rpm -ivh /opt/soft/mysql-client/* 2)使用 MySQL Client 连接 FE
mysql -h hadoop1 -P 9030 -uroot 默认 root 无密码,通过以下命令修改 root 密码。
SET PASSWORD FOR 'root' = PASSWORD('oracle'); 3)添加 BE
ALTER SYSTEM ADD BACKEND "hadoop1:9050";
ALTER SYSTEM ADD BACKEND "hadoop2:9050";
ALTER SYSTEM ADD BACKEND "hadoop3:9050";4)查看 BE 状态
SHOW PROC '/backends';
2.4.5 启动 BE
1)启动 BE(每个节点),如果启动be有问题,可以查看/opt/mod/apache-doris-0.15.0/be/log目录下的日志
/opt/mod/apache-doris-0.15.0/be/bin/start_be.sh --daemon2)查看 BE 状态
mysql -h hadoop1 -P 9030 -uroot -p
SHOW PROC '/backends'; Alive 为 true 表示该 BE 节点存活。

2.4.6 部署 FS_Broker(可选)
Broker 以插件的形式,独立于 Doris 部署。如果需要从第三方存储系统导入数据,需要部署相应的 Broker,默认提供了读取 HDFS、百度云 BOS 及 Amazon S3 的 fs_broker。fs_broker 是无状态的,建议每一个 FE 和 BE 节点都部署一个 Broker。
1)编译 FS_BROKER 并拷贝文件
(1)进入源码目录下的 fs_brokers 目录,使用 sh build.sh 进行编译
#参考2.2,进入docker容器编译,注意要将jdk设置成1.8
[root@47dd1482f9ce apache_hdfs_broker]# pwd
/root/apache-doris-0.15.0-incubating-src/fs_brokers/apache_hdfs_broker
[root@47dd1482f9ce apache_hdfs_broker]# sh build.sh
#编译完成后,退出容器(2)拷贝源码 fs_broker 的 output 目录下的相应 Broker 目录到需要部署的所有节点上,改名为: apache_hdfs_broker。建议和 BE 或者 FE 目录保持同级。
方法同 2.2。
[hadoop@hadoop1 apache_hdfs_broker]$ pwd
/opt/soft/apache-doris-0.15.0-incubating-src/fs_brokers/apache_hdfs_broker/output/
[hadoop@hadoop1 output]$ sudo cp -r apache_hdfs_broker /opt/mod/apache-doris-0.15.0/
[hadoop@hadoop1 apache-doris-0.15.0]$ cd /opt/mod/apache-doris-0.15.0/
[hadoop@hadoop1 apache-doris-0.15.0]$ sudo chown -R hadoop:hadoop apache_hdfs_broker
#同步apache_hdfs_broker目录到其他节点
[hadoop@hadoop1 apache-doris-0.15.0]$ xsync apache_hdfs_broker2)启动 Broker
/opt/mod/apache-doris-0.15.0/apache_hdfs_broker/bin/start_broker.sh --daemon 3)添加 Broker
要让 Doris 的 FE 和 BE 知道 Broker 在哪些节点上,通过 sql 命令添加 Broker 节点列表。
1)使用 mysql-client 连接启动的 FE,执行以下命令:
mysql -h hadoop1 -P 9030 -uroot -p
ALTER SYSTEM ADD BROKER broker_name "hadoop1:8000","hadoop2:8000","hadoop3:8000";
#broker_name可以自定义其中 broker_host 为 Broker 所在节点 ip;broker_ipc_port 在 Broker 配置文件中的 conf/apache_hdfs_broker.conf。
4)查看 Broker 状态
使用 mysql-client 连接任一已启动的 FE,执行以下命令查看 Broker 状态:
SHOW PROC "/brokers"; 注:在生产环境中,所有实例都应使用守护进程启动,以保证进程退出后,会被自动拉起,如 Supervisor(opens new window)。如需使用守护进程启动,在 0.9.0 及之前版本中,需要修改各个 start_xx.sh 脚本,去掉最后的 & 符号。从 0.10.0 版本开始,直接调用 sh start_xx.sh 启动即可。
注:在生产环境中,所有实例都应使用守护进程启动,以保证进程退出后,会被自动拉起,如 Supervisor(opens new window)。如需使用守护进程启动,在 0.9.0 及之前版本中,需要修改各个 start_xx.sh 脚本,去掉最后的 & 符号。从 0.10.0 版本开始,直接调用 sh start_xx.sh 启动即可。
2.5 扩容和缩容
Doris 可以很方便的扩容和缩容 FE、BE、Broker 实例。
2.5.1 FE 扩容和缩容
可以通过将 FE 扩容至 3 个以上节点来实现 FE 的高可用。
1)使用 MySQL 登录客户端后,可以使用 sql 命令查看 FE 状态,目前就一台 FE
mysql -h hadoop1 -P 9030 -uroot -p
SHOW PROC '/frontends';
也可以通过页面访问进行监控,访问 8030,账户为 root,密码默认为空不用填写。
2)增加 FE 节点
FE 分为 Leader,Follower 和 Observer 三种角色。 默认一个集群,只能有一个 Leader,可以有多个 Follower 和 Observer。其中 Leader 和 Follower 组成一个 Paxos 选择组,如果Leader 宕机,则剩下的 Follower 会自动选出新的 Leader,保证写入高可用。Observer 同步Leader 的数据,但是不参加选举。
如果只部署一个 FE,则 FE 默认就是 Leader。在此基础上,可以添加若干 Follower 和Observer。
ALTER SYSTEM ADD FOLLOWER "hadoop2:9010";
ALTER SYSTEM ADD OBSERVER "hadoop3:9010";3)配置及启动 Follower 和 Observer
第一次启动时,启动命令需要添加参--helper leader 主机: edit_log_port:
(1)分发 FE,修改 FE 的配置(同 2.4.2)
scp -r /opt/mod/apache-doris-0.15.0/fe hadoop2:/opt/mod/apache-doris-0.15.0
scp -r /opt/mod/apache-doris-0.15.0/fe hadoop3:/opt/mod/apache-doris-0.15.0
#在节点2、节点3,修改fe的配置文件
[hadoop@hadoop2 conf]$ pwd
/opt/mod/apache-doris-0.15.0/fe/conf
[hadoop@hadoop2 conf]$ vi fe.conf
#将每个节点的配置文件,改成自己相应的IP
priority_networks = 192.168.1.32/24
#在节点2、节点3,创建fe的元数据目录
[hadoop@hadoop2 fe]$ mkdir -p /opt/mod/apache-doris-0.15.0/doris-meta(2)在 hadoop2 启动 Follower,第一次启动要加--helper,
/opt/mod/apache-doris-0.15.0/fe/bin/start_fe.sh --helper hadoop1:9010 --daemon(3)在 hadoop3 启动 Observer,第一次启动要加--helper
/opt/mod/apache-doris-0.15.0/fe/bin/start_fe.sh --helper hadoop1:9010 --daemon 4)查看运行状态
使用 mysql-client 连接到任一已启动的 FE。
SHOW PROC '/frontends'; 

5)删除 FE 节点命令,删除后,将相关节点的FE停止
ALTER SYSTEM DROP FOLLOWER[OBSERVER] "fe_host:edit_log_port"; 注意:删除 Follower FE 时,确保最终剩余的 Follower(包括 Leader)节点为奇数。
2.5.2 BE 扩容和缩容
1)增加 BE 节点
在 MySQL 客户端,通过 ALTER SYSTEM ADD BACKEND 命令增加 BE 节点。
2)DROP 方式删除 BE 节点(不推荐)
ALTER SYSTEM DROP BACKEND "be_host:be_heartbeat_service_port";注意:DROP BACKEND 会直接删除该 BE,并且其上的数据将不能再恢复!!!所以我们强烈不推荐使用 DROP BACKEND 这种方式删除 BE 节点。当你使用这个语句时,会有对应的防误操作提示。
3)DECOMMISSION 方式删除 BE 节点(推荐)
ALTER SYSTEM DECOMMISSION BACKEND "be_host:be_heartbeat_service_port";-
该命令用于安全删除 BE 节点。命令下发后,Doris 会尝试将该 BE 上的数据向其他 BE 节点迁移,当所有数据都迁移完成后,Doris 会自动删除该节点。
-
该命令是一个异步操作。执行后,可以通过 SHOW PROC '/backends'; 看到该 BE 节点的 isDecommission 状态为 true。表示该节点正在进行下线。
-
该命令不一定执行成功。比如剩余 BE 存储空间不足以容纳下线 BE 上的数据,或者剩余机器数量不满足最小副本数时,该命令都无法完成,并且 BE 会一直处于 isDecommission 为 true 的状态。
-
DECOMMISSION 的进度,可以通过 SHOW PROC '/backends'; 中的 TabletNum 查看,如果正在进行,TabletNum 将不断减少。
-
该操作可以通过如下命令取消:
CANCEL DECOMMISSION BACKEND "be_host:be_heartbeat_service_port";取消后,该 BE 上的数据将维持当前剩余的数据量。后续 Doris 重新进行负载均衡。
2.5.3 Broker 扩容缩容
Broker 实例的数量没有硬性要求。通常每台物理机部署一个即可。Broker 的添加和删除可以通过以下命令完成:
ALTER SYSTEM ADD BROKER broker_name "broker_host:broker_ipc_port";
ALTER SYSTEM DROP BROKER broker_name "broker_host:broker_ipc_port";
ALTER SYSTEM DROP ALL BROKER broker_name; Broker 是无状态的进程,可以随意启停。当然,停止后,正在其上运行的作业会失败,重试即可。
第 3 章 数据表的创建
3.1 创建用户和数据库
1)创建 test 用户
mysql -h hadoop1 -P 9030 -uroot -p
create user 'test' identified by 'test'; 2)创建数据库
create database test_db; 3)用户授权
grant all on test_db to test; 3.2 基本概念
在 Doris 中,数据都以关系表(Table)的形式进行逻辑上的描述。
3.2.1 Row & Column
一张表包括行(Row)和列(Column)。Row 即用户的一行数据。Column 用于描述一行数据中不同的字段。
-
在默认的数据模型中,Column 只分为排序列和非排序列。存储引擎会按照排序列对数据进行排序存储,并建立稀疏索引,以便在排序数据上进行快速查找。
-
而在聚合模型中,Column 可以分为两大类:Key 和 Value。从业务角度看,Key 和 Value 可以分别对应维度列和指标列。从聚合模型的角度来说,Key 列相同的行,会聚合成一行。其中 Value 列的聚合方式由用户在建表时指定。
3.2.2 Partition & Tablet
在 Doris 的存储引擎中,用户数据首先被划分成若干个分区(Partition),划分的规则通常是按照用户指定的分区列进行范围划分,比如按时间划分。而在每个分区内,数据被进一步的按照 Hash 的方式分桶,分桶的规则是要找用户指定的分桶列的值进行 Hash 后分桶。
每个分桶就是一个数据分片(Tablet),也是数据划分的最小逻辑单元。
-
Tablet 之间的数据是没有交集的,独立存储的。Tablet 也是数据移动、复制等操作的最小物理存储单元。
-
Partition 可以视为是逻辑上最小的管理单元。数据的导入与删除,都可以或仅能针对一个 Partition 进行。
3.3 建表示例
使用 CREATE TABLE 命令建立一个表(Table)。更多详细参数可以查看:
HELP CREATE TABLE; 建表语法:
CREATE [EXTERNAL] TABLE [IF NOT EXISTS][database.]table_name
(column_definition1[, column_definition2, ...]
[, index_definition1[, index_definition12,]])
[ENGINE = [olap|mysql|broker|hive]]
[key_desc]
[COMMENT "table comment"];
[partition_desc]
[distribution_desc]
[rollup_index]
[PROPERTIES ("key"="value", ...)]
[BROKER PROPERTIES ("key"="value", ...)];Doris 的建表是一个同步命令,命令返回成功,即表示建表成功。
Doris 支持支持单分区和复合分区两种建表方式。
1)复合分区:既有分区也有分桶
第一级称为 Partition,即分区。用户可以指定某一维度列作为分区列(当前只支持整型和时间类型的列),并指定每个分区的取值范围。
第二级称为 Distribution,即分桶。用户可以指定一个或多个维度列以及桶数对数据进行 HASH 分布。
2)单分区:只做 HASH 分布,即只分桶。
3.3.2 字段类型

 注:聚合模型在定义字段类型后,可以指定字段的 agg_type 聚合类型,如果不指定,则该列为 key 列。否则,该列为 value 列, 类型包括:SUM、MAX、MIN、REPLACE。
注:聚合模型在定义字段类型后,可以指定字段的 agg_type 聚合类型,如果不指定,则该列为 key 列。否则,该列为 value 列, 类型包括:SUM、MAX、MIN、REPLACE。
3.3.2 建表示例
我们以一个建表操作来说明 Doris 的数据划分。
3.3.2.1 Range Partition
CREATE TABLE IF NOT EXISTS example_db.expamle_range_tbl
(
`user_id` LARGEINT NOT NULL COMMENT "用户 id",
`date` DATE NOT NULL COMMENT "数据灌入日期时间",
`timestamp` DATETIME NOT NULL COMMENT "数据灌入的时间戳",
`city` VARCHAR(20) COMMENT "用户所在城市",
`age` SMALLINT COMMENT "用户年龄",
`sex` TINYINT COMMENT "用户性别",
`last_visit_date` DATETIME REPLACE DEFAULT "1970-01-01 00:00:00" COMMENT "用户最后一次访问时间",
`cost` BIGINT SUM DEFAULT "0" COMMENT "用户总消费",
`max_dwell_time` INT MAX DEFAULT "0" COMMENT "用户最大停留时间",
`min_dwell_time` INT MIN DEFAULT "99999" COMMENT "用户最小停留时间"
)
ENGINE=olap
AGGREGATE KEY(`user_id`, `date`, `timestamp`, `city`, `age`, `sex`)
PARTITION BY RANGE(`date`)
(
PARTITION `p201701` VALUES LESS THAN ("2017-02-01"),
PARTITION `p201702` VALUES LESS THAN ("2017-03-01"),
PARTITION `p201703` VALUES LESS THAN ("2017-04-01")
)
DISTRIBUTED BY HASH(`user_id`) BUCKETS 16
PROPERTIES
(
"replication_num" = "3",
"storage_medium" = "SSD",
"storage_cooldown_time" = "2018-01-01 12:00:00"
);3.3.2.2 List Partition
CREATE TABLE IF NOT EXISTS example_db.expamle_list_tbl
(
`user_id` LARGEINT NOT NULL COMMENT "用户 id",
`date` DATE NOT NULL COMMENT "数据灌入日期时间",
`timestamp` DATETIME NOT NULL COMMENT "数据灌入的时间戳",
`city` VARCHAR(20) COMMENT "用户所在城市",
`age` SMALLINT COMMENT "用户年龄",
`sex` TINYINT COMMENT "用户性别",
`last_visit_date` DATETIME REPLACE DEFAULT "1970-01-01 00:00:00" COMMENT "用户最后一次访问时间",
`cost` BIGINT SUM DEFAULT "0" COMMENT "用户总消费",
`max_dwell_time` INT MAX DEFAULT "0" COMMENT "用户最大停留时间",
`min_dwell_time` INT MIN DEFAULT "99999" COMMENT "用户最小停留时间"
)
ENGINE=olap
AGGREGATE KEY(`user_id`, `date`, `timestamp`, `city`, `age`, `sex`)
PARTITION BY LIST(`city`)
(
PARTITION `p_cn` VALUES IN ("Beijing", "Shanghai", "Hong Kong"),
PARTITION `p_usa` VALUES IN ("New York", "San Francisco"),
PARTITION `p_jp` VALUES IN ("Tokyo")
)
DISTRIBUTED BY HASH(`user_id`) BUCKETS 16
PROPERTIES
(
"replication_num" = "3",
"storage_medium" = "SSD",
"storage_cooldown_time" = "2018-01-01 12:00:00"
);3.4 数据划分
以 3.3.2 的建表示例来理解。
3.4.1 列定义
以 AGGREGATE KEY 数据模型为例进行说明。更多数据模型参阅 Doris 数据模型。
列的基本类型,可以通过在 mysql-client 中执行 HELP CREATE TABLE; 查看。
AGGREGATE KEY 数据模型中,所有没有指定聚合方式(SUM、REPLACE、MAX、MIN)的列视为 Key 列。而其余则为 Value 列。
定义列时,可参照如下建议:
-
Key 列必须在所有 Value 列之前。
-
尽量选择整型类型。因为整型类型的计算和查找比较效率远高于字符串。
-
对于不同长度的整型类型的选择原则,遵循够用即可。
-
对于 VARCHAR 和 STRING 类型的长度,遵循 够用即可。
-
所有列的总字节长度(包括 Key 和 Value)不能超过 100KB。
3.4.2 分区与分桶
Doris 支持两层的数据划分。第一层是 Partition,支持 Range 和 List 的划分方式。第二层是 Bucket(Tablet),仅支持 Hash 的划分方式。
也可以仅使用一层分区。使用一层分区时,只支持 Bucket 划分。
3.4.2.1 Partition
-
Partition 列可以指定一列或多列。分区类必须为 KEY 列。多列分区的使用方式在后面介绍。
-
不论分区列是什么类型,在写分区值时,都需要加双引号。
-
分区数量理论上没有上限。
-
当不使用 Partition 建表时,系统会自动生成一个和表名同名的,全值范围的Partition。该 Partition 对用户不可见,并且不可删改。
1) Range 分区
分区列通常为时间列,以方便的管理新旧数据。不可添加范围重叠的分区。
Partition 指定范围的方式
-
VALUES LESS THAN (...) 仅指定上界,系统会将前一个分区的上界作为该分区的下界,生成一个左闭右开的区间。分区的删除不会改变已存在分区的范围。删除分区可能出现空洞。
-
VALUES [...) 指定同时指定上下界,生成一个左闭右开的区间。
通过 VALUES [...) 同时指定上下界比较容易理解。这里举例说明,当使用 VALUES LESS THAN (...) 语句进行分区的增删操作时,分区范围的变化情况:
(1)如上 expamle_range_tbl 示例,当建表完成后,会自动生成如下 3 个分区:
p201701: [MIN_VALUE, 2017-02-01)
p201702: [2017-02-01, 2017-03-01)
p201703: [2017-03-01, 2017-04-01)(2)增加一个分区 p201705 VALUES LESS THAN ("2017-06-01"),分区结果如下:
p201701: [MIN_VALUE, 2017-02-01)
p201702: [2017-02-01, 2017-03-01)
p201703: [2017-03-01, 2017-04-01)
p201705: [2017-04-01, 2017-06-01)(3)此时删除分区 p201703,则分区结果如下:
p201701: [MIN_VALUE, 2017-02-01)
p201702: [2017-02-01, 2017-03-01)
p201705: [2017-04-01, 2017-06-01)注意到 p201702 和 p201705 的分区范围并没有发生变化,而这两个分区之间,出现了一个空洞:[2017-03-01, 2017-04-01)。即如果导入的数据范围在这个空洞范围内,是无法导入的。
(4)继续删除分区 p201702,分区结果如下:
p201701: [MIN_VALUE, 2017-02-01)
p201705: [2017-04-01, 2017-06-01)空洞范围变为:[2017-02-01, 2017-04-01)
(5)现在增加一个分区 p201702new VALUES LESS THAN ("2017-03-01"),分区结果如下:
p201701: [MIN_VALUE, 2017-02-01)
p201702new: [2017-02-01, 2017-03-01)
p201705: [2017-04-01, 2017-06-01)
可以看到空洞范围缩小为:[2017-03-01, 2017-04-01)
(6)现在删除分区 p201701,并添加分区 p201612 VALUES LESS THAN ("2017-01-01"),分区结果如下:
p201612: [MIN_VALUE, 2017-01-01)
p201702new: [2017-02-01, 2017-03-01)
p201705: [2017-04-01, 2017-06-01)即出现了一个新的空洞:[2017-01-01, 2017-02-01)
2)List 分区
分 区 列支 持 BOOLEAN, TINYINT, SMALLINT, INT, BIGINT, LARGEINT, DATE, DATETIME, CHAR, VARCHAR 数据类型,分区值为枚举值。只有当数据为目标分区枚举值其中之一时,才可以命中分区。不可添加范围重叠的分区。
Partition 支持通过 VALUES IN (...) 来指定每个分区包含的枚举值。下面通过示例说明,
进行分区的增删操作时,分区的变化。
(1)如上 example_list_tbl 示例,当建表完成后,会自动生成如下 3 个分区:
p_cn: ("Beijing", "Shanghai", "Hong Kong")
p_usa: ("New York", "San Francisco")
p_jp: ("Tokyo")(2)增加一个分区 p_uk VALUES IN ("London"),分区结果如下:
p_cn: ("Beijing", "Shanghai", "Hong Kong")
p_usa: ("New York", "San Francisco")
p_jp: ("Tokyo")
p_uk: ("London")(3)删除分区 p_jp,分区结果如下:
p_cn: ("Beijing", "Shanghai", "Hong Kong")
p_usa: ("New York", "San Francisco")
p_uk: ("London") 3.4.2.2 Bucket
(1)如果使用了 Partition,则 DISTRIBUTED ... 语句描述的是数据在各个分区内的划分规则。如果不使用 Partition,则描述的是对整个表的数据的划分规则。
(2)分桶列可以是多列,但必须为 Key 列。分桶列可以和 Partition 列相同或不同。
(3)分桶列的选择,是在 查询吞吐 和 查询并发 之间的一种权衡:
① 如果选择多个分桶列,则数据分布更均匀。
如果一个查询条件不包含所有分桶列的等值条件,那么该查询会触发所有分桶同时扫描,这样查询的吞吐会增加,单个查询的延迟随之降低。这个方式适合大吞吐低并发的查询场景。
② 如果仅选择一个或少数分桶列,则对应的点查询可以仅触发一个分桶扫描。此时,当多个点查询并发时,这些查询有较大的概率分别触发不同的分桶扫描,各个查询之间的 IO 影响较小(尤其当不同桶分布在不同磁盘上时),所以这种方式适合高并发的点查询场景。
(4)分桶的数量理论上没有上限。
3.4.2.3 使用复合分区的场景
以下场景推荐使用复合分区
(1)有时间维度或类似带有有序值的维度,可以以这类维度列作为分区列。分区粒度可以根据导入频次、分区数据量等进行评估。
(2)历史数据删除需求:如有删除历史数据的需求(比如仅保留最近 N 天的数据)。使用复合分区,可以通过删除历史分区来达到目的。也可以通过在指定分区内发送 DELETE 语句进行数据删除。
(3)解决数据倾斜问题:每个分区可以单独指定分桶数量。如按天分区,当每天的数据量差异很大时,可以通过指定分区的分桶数,合理划分不同分区的数据,分桶列建议选择区分度大的列。
3.4.2.4 多列分区
Doris 支持指定多列作为分区列,示例如下:
1)Range 分区
PARTITION BY RANGE(`date`, `id`)
(
PARTITION `p201701_1000` VALUES LESS THAN ("2017-02-01", "1000"),
PARTITION `p201702_2000` VALUES LESS THAN ("2017-03-01", "2000"),
PARTITION `p201703_all` VALUES LESS THAN ("2017-04-01")
) 指定 date(DATE 类型) 和 id(INT 类型) 作为分区列。以上示例最终得到的分区如下:
p201701_1000: [(MIN_VALUE, MIN_VALUE), ("2017-02-01", "1000") )
p201702_2000: [("2017-02-01", "1000"), ("2017-03-01", "2000") )
p201703_all: [("2017-03-01", "2000"), ("2017-04-01", MIN_VALUE)) 注意,最后一个分区用户缺省只指定了 date 列的分区值,所以 id 列的分区值会默认填充 MIN_VALUE。当用户插入数据时,分区列值会按照顺序依次比较,最终得到对应的分区。举例如下:
数据 --> 分区
数据 --> 分区
2017-01-01, 200 --> p201701_1000
2017-01-01, 2000 --> p201701_1000
2017-02-01, 100 --> p201701_1000
2017-02-01, 2000 --> p201702_2000
2017-02-15, 5000 --> p201702_2000
2017-03-01, 2000 --> p201703_all
2017-03-10, 1 --> p201703_all
2017-04-01, 1000 --> 无法导入
2017-05-01, 1000 --> 无法导入2)List 分区
PARTITION BY LIST(`id`, `city`)
(
PARTITION `p1_city` VALUES IN (("1", "Beijing"), ("1","Shanghai")),
PARTITION `p2_city` VALUES IN (("2", "Beijing"), ("2","Shanghai")),
PARTITION `p3_city` VALUES IN (("3", "Beijing"), ("3","Shanghai"))
)指定 id(INT 类型) 和 city(VARCHAR 类型) 作为分区列。最终得到的分区如下:
p1_city: [("1", "Beijing"), ("1", "Shanghai")]
p2_city: [("2", "Beijing"), ("2", "Shanghai")]
p3_city: [("3", "Beijing"), ("3", "Shanghai")]当用户插入数据时,分区列值会按照顺序依次比较,最终得到对应的分区。举例如下:
数据 ---> 分区
1, Beijing ---> p1_city
1, Shanghai ---> p1_city
2, Shanghai ---> p2_city
3, Beijing ---> p3_city
1, Tianjin ---> 无法导入
4, Beijing ---> 无法导入3.4.3 PROPERTIES
在建表语句的最后 PROPERTIES 中,可以指定以下两个参数:
3.4.3.1 replication_num
每个 Tablet 的副本数量。默认为 3,建议保持默认即可。在建表语句中,所有 Partition 中的 Tablet 副本数量统一指定。而在增加新分区时,可以单独指定新分区中 Tablet 的副本数量。
副本数量可以在运行时修改。强烈建议保持奇数。
最大副本数量取决于集群中独立 IP 的数量(注意不是 BE 数量)。Doris 中副本分布的原则是,不允许同一个 Tablet 的副本分布在同一台物理机上,而识别物理机即通过 IP。所以,即使在同一台物理机上部署了 3 个或更多 BE 实例,如果这些 BE 的 IP 相同,则依然只能设置副本数为 1。
对于一些小,并且更新不频繁的维度表,可以考虑设置更多的副本数。这样在 Join 查询时,可以有更大的概率进行本地数据 Join。
3.4.3.2 storage_medium & storage_cooldown_time
BE 的数据存储目录可以显式的指定为 SSD 或者 HDD(通过 .SSD 或者 .HDD 后缀区分)。建表时,可以统一指定所有 Partition 初始存储的介质。注意,后缀作用是显式指定磁盘介质,而不会检查是否与实际介质类型相符。
默认初始存储介质可通过 fe 的配置文件 fe.conf 中指定 default_storage_medium=xxx,
如果没有指定,则默认为 HDD。如果指定为 SSD,则数据初始存放在 SSD 上。
如果没有指定 storage_cooldown_time,则默认 30 天后,数据会从 SSD 自动迁移到 HDD 上。如果指定了 storage_cooldown_time,则在到达 storage_cooldown_time 时间后,数据才会迁移。
注意,当指定 storage_medium 时,如果 FE 参数 enable_strict_storage_medium_check 为 False 该参数只是一个“尽力而为”的设置。即使集群内没有设置 SSD 存储介质,也不会报错,而是自动存储在可用的数据目录中。 同样,如果 SSD 介质不可访问、空间不足,都可能导致数据初始直接存储在其他可用介质上。而数据到期迁移到 HDD 时,如果 HDD 介质不 可 访 问 、 空 间 不 足 , 也 可 能 迁 移 失 败 ( 但 是 会 不 断 尝 试 ) 。 如 果 FE 参 数 enable_strict_storage_medium_check 为 True 则当集群内没有设置 SSD 存储介质时,会报错 Failed to find enough host in all backends with storage medium is SSD。
3.4.4 ENGINE
本示例中,ENGINE 的类型是 olap,即默认的 ENGINE 类型。在 Doris 中,只有这个ENGINE 类型是由 Doris 负责数据管理和存储的。其他 ENGINE 类型,如 mysql、broker、es 等等,本质上只是对外部其他数据库或系统中的表的映射,以保证 Doris 可以读取这些数据。而 Doris 本身并不创建、管理和存储任何非 olap ENGINE 类型的表和数据。
3.4.5 其他
IF NOT EXISTS 表示如果没有创建过该表,则创建。注意这里只判断表名是否存在,而不会判断新建表结构是否与已存在的表结构相同
3.5 数据模型
Doris 的数据模型主要分为 3 类:Aggregate、Uniq、Duplicate
3.5.1 Aggregate 模型
表中的列按照是否设置了 AggregationType,分为 Key(维度列)和 Value(指标列)。 没有设置 AggregationType 的称为 Key,设置了 AggregationType 的称为 Value。
当我们导入数据时,对于 Key 列相同的行会聚合成一行,而 Value 列会按照设置的 AggregationType 进行聚合。AggregationType 目前有以下四种聚合方式:
-
SUM:求和,多行的 Value 进行累加。
-
REPLACE:替代,下一批数据中的 Value 会替换之前导入过的行中的 Value。REPLACE_IF_NOT_NULL :当遇到 null 值则不更新。
-
MAX:保留最大值。
-
MIN:保留最小值。
数据的聚合,在 Doris 中有如下三个阶段发生:
(1)每一批次数据导入的 ETL 阶段。该阶段会在每一批次导入的数据内部进行聚合。
(2)底层 BE 进行数据 Compaction 的阶段。该阶段,BE 会对已导入的不同批次的数据进行进一步的聚合。
(3)数据查询阶段。在数据查询时,对于查询涉及到的数据,会进行对应的聚合。
数据在不同时间,可能聚合的程度不一致。比如一批数据刚导入时,可能还未与之前已存在的数据进行聚合。但是对于用户而言,用户只能查询到聚合后的数据。即不同的聚合程度对于用户查询而言是透明的。用户需始终认为数据以最终的完成的聚合程度存在,而不应假设某些聚合还未发生。(可参阅聚合模型的局限性一节获得更多详情。)
3.5.1.1 示例一:导入数据聚合
1)建表
CREATE TABLE IF NOT EXISTS test_db.example_site_visit
(
`user_id` LARGEINT NOT NULL COMMENT "用户 id",
`date` DATE NOT NULL COMMENT "数据灌入日期时间",
`city` VARCHAR(20) COMMENT "用户所在城市",
`age` SMALLINT COMMENT "用户年龄",
`sex` TINYINT COMMENT "用户性别",
`last_visit_date` DATETIME REPLACE DEFAULT "1970-01-01 00:00:00" COMMENT "用户最后一次访问时间",
`last_visit_date_not_null` DATETIME REPLACE_IF_NOT_NULL DEFAULT
"1970-01-01 00:00:00" COMMENT "用户最后一次访问时间",
`cost` BIGINT SUM DEFAULT "0" COMMENT "用户总消费",
`max_dwell_time` INT MAX DEFAULT "0" COMMENT "用户最大停留时间",
`min_dwell_time` INT MIN DEFAULT "99999" COMMENT "用户最小停留时间"
)
AGGREGATE KEY(`user_id`, `date`, `city`, `age`, `sex`)
DISTRIBUTED BY HASH(`user_id`) BUCKETS 10;2)插入数据
insert into test_db.example_site_visit values\
(10000,'2017-10-01','北京',20,0,'2017-10-01 06:00:00','2017-10-01 06:00:00',20,10,10),\
(10000,'2017-10-01','北京',20,0,'2017-10-01 07:00:00','2017-10-01 07:00:00',15,2,2),\
(10001,'2017-10-01','北京',30,1,'2017-10-01 17:05:45','2017-10-01 07:00:00',2,22,22),\
(10002,'2017-10-02','上海',20,1,'2017-10-02 12:59:12',null,200,5,5),\
(10003,'2017-10-02','广州',32,0,'2017-10-02 11:20:00','2017-10-02 11:20:00',30,11,11),\
(10004,'2017-10-01','深圳',35,0,'2017-10-01 10:00:15','2017-10-01 10:00:15',100,3,3),\
(10004,'2017-10-03','深圳',35,0,'2017-10-03 10:20:22','2017-10-03 10:20:22',11,6,6);注意:Insert into 单条数据这种操作在 Doris 里只能演示不能在生产使用,会引发写阻塞。
3)查看表
select * from test_db.example_site_visit; 可以看到,用户 10000 只剩下了一行聚合后的数据。而其余用户的数据和原始数据保持一致。经过聚合,Doris 中最终只会存储聚合后的数据。换句话说,即明细数据会丢失,用户不能够再查询到聚合前的明细数据了。
3.5.1.2 示例二:保留明细数据
1)建表
CREATE TABLE IF NOT EXISTS test_db.example_site_visit2
(
`user_id` LARGEINT NOT NULL COMMENT "用户 id",
`date` DATE NOT NULL COMMENT "数据灌入日期时间",
`timestamp` DATETIME COMMENT "数据灌入时间,精确到秒",
`city` VARCHAR(20) COMMENT "用户所在城市",
`age` SMALLINT COMMENT "用户年龄",
`sex` TINYINT COMMENT "用户性别",
`last_visit_date` DATETIME REPLACE DEFAULT "1970-01-01 00:00:00" COMMENT "用户最后一次访问时间",
`cost` BIGINT SUM DEFAULT "0" COMMENT "用户总消费",
`max_dwell_time` INT MAX DEFAULT "0" COMMENT "用户最大停留时间",
`min_dwell_time` INT MIN DEFAULT "99999" COMMENT "用户最小停留时间"
)
AGGREGATE KEY(`user_id`, `date`, `timestamp`, `city`, `age`, `sex`)
DISTRIBUTED BY HASH(`user_id`) BUCKETS 10;2)插入数据
insert into test_db.example_site_visit2 values
(10000,'2017-10-01','2017-10-01 08:00:05','北京',20,0,'2017-10-01 06:00:00',20,10,10),
(10000,'2017-10-01','2017-10-01 09:00:05','北京',20,0,'2017-10-01 07:00:00',15,2,2),
(10001,'2017-10-01','2017-10-01 18:12:10','北京',30,1,'2017-10-01 17:05:45',2,22,22),
(10002,'2017-10-02','2017-10-02 13:10:00','上海',20,1,'2017-10-02 12:59:12',200,5,5),
(10003,'2017-10-02','2017-10-02 13:15:00','广州',32,0,'2017-10-02 11:20:00',30,11,11),
(10004,'2017-10-01','2017-10-01 12:12:48','深圳',35,0,'2017-10-01 10:00:15',100,3,3),
(10004,'2017-10-03','2017-10-03 12:38:20','深圳',35,0,'2017-10-03 10:20:22',11,6,6);3)查看表
select * from test_db.example_site_visit2;存储的数据,和导入数据完全一样,没有发生任何聚合。这是因为,这批数据中,因为加入了 timestamp 列,所有行的 Key 都不完全相同。也就是说,只要保证导入的数据中,每一行的 Key 都不完全相同,那么即使在聚合模型下,Doris 也可以保存完整的明细数据。
3.5.1.3 示例三:导入数据与已有数据聚合
1)往实例一中继续插入数据
insert into test_db.example_site_visit values
(10004,'2017-10-03','深圳',35,0,'2017-10-03 11:22:00',null,44,19,19),
(10005,'2017-10-03','长沙',29,1,'2017-10-03 18:11:02','2017-10-03 18:11:02',3,1,1);2)查看表
select * from test_db.example_site_visit;可以看到,用户 10004 的已有数据和新导入的数据发生了聚合。同时新增了 10005 用户的数据。
3.5.2 Uniq 模型
在某些多维分析场景下,用户更关注的是如何保证 Key 的唯一性,即如何获得 Primary Key 唯一性约束。因此,我们引入了 Uniq 的数据模型。该模型本质上是聚合模型的一个特例,也是一种简化的表结构表示方式。
1)建表
CREATE TABLE IF NOT EXISTS test_db.user
(
`user_id` LARGEINT NOT NULL COMMENT "用户 id",
`username` VARCHAR(50) NOT NULL COMMENT "用户昵称",
`city` VARCHAR(20) COMMENT "用户所在城市",
`age` SMALLINT COMMENT "用户年龄",
`sex` TINYINT COMMENT "用户性别",
`phone` LARGEINT COMMENT "用户电话",
`address` VARCHAR(500) COMMENT "用户地址",
`register_time` DATETIME COMMENT "用户注册时间"
)
UNIQUE KEY(`user_id`, `username`)
DISTRIBUTED BY HASH(`user_id`) BUCKETS 10;2)插入数据
insert into test_db.user values
(10000,'wuyanzu','北京',18,0,12345678910,'北京朝阳区','2017-10-01 07:00:00'),
(10000,'wuyanzu','北京',19,0,12345678910,'北京朝阳区','2017-10-01 07:00:00'),
(10000,'zhangsan','北京',20,0,12345678910,'北京海淀区','2017-11-15 06:10:20');3)查询表
select * from test_db.user; Uniq 模型完全可以用聚合模型中的 REPLACE 方式替代。其内部的实现方式和数据存储方式也完全一样。
3.5.3 Duplicate 模型
在某些多维分析场景下,数据既没有主键,也没有聚合需求。Duplicate 数据模型可以满足这类需求。数据完全按照导入文件中的数据进行存储,不会有任何聚合。即使两行数据完全相同,也都会保留。 而在建表语句中指定的 DUPLICATE KEY,只是用来指明底层数据按照那些列进行排序。
1)建表
CREATE TABLE IF NOT EXISTS test_db.example_log
(
`timestamp` DATETIME NOT NULL COMMENT "日志时间",
`type` INT NOT NULL COMMENT "日志类型",
`error_code` INT COMMENT "错误码",
`error_msg` VARCHAR(1024) COMMENT "错误详细信息",
`op_id` BIGINT COMMENT "负责人 id",
`op_time` DATETIME COMMENT "处理时间"
)
DUPLICATE KEY(`timestamp`, `type`)
DISTRIBUTED BY HASH(`timestamp`) BUCKETS 10;2)插入数据
insert into test_db.example_log values
('2017-10-01 08:00:05',1,404,'not found page', 101, '2017-10-01 08:00:05'),
('2017-10-01 08:00:05',1,404,'not found page', 101, '2017-10-01 08:00:05'),
('2017-10-01 08:00:05',2,404,'not found page', 101, '2017-10-01 08:00:06'),
('2017-10-01 08:00:06',2,404,'not found page', 101, '2017-10-01 08:00:07');3)查看表
select * from test_db.example_log; 3.5.4 数据模型的选择建议
因为数据模型在建表时就已经确定,且无法修改。所以,选择一个合适的数据模型非常重要。
(1)Aggregate 模型可以通过预聚合,极大地降低聚合查询时所需扫描的数据量和查询的计算量,非常适合有固定模式的报表类查询场景。但是该模型对 count(*) 查询很不友好。同时因为固定了 Value 列上的聚合方式,在进行其他类型的聚合查询时,需要考虑语意正确性。
(2)Uniq 模型针对需要唯一主键约束的场景,可以保证主键唯一性约束。但是无法利用 ROLLUP 等预聚合带来的查询优势(因为本质是 REPLACE,没有 SUM 这种聚合方式)。
(3)Duplicate 适合任意维度的 Ad-hoc 查询。虽然同样无法利用预聚合的特性,但是不受聚合模型的约束,可以发挥列存模型的优势(只读取相关列,而不需要读取所有 Key 列)
3.5.5 聚合模型的局限性
这里我们针对 Aggregate 模型(包括 Uniq 模型),来介绍下聚合模型的局限性。
在聚合模型中,模型对外展现的,是最终聚合后的数据。也就是说,任何还未聚合的数据(比如说两个不同导入批次的数据),必须通过某种方式,以保证对外展示的一致性。我们举例说明。
假设表结构如下:

假设存储引擎中有如下两个已经导入完成的批次的数据:
batch 1
| user_id | date | cost |
|---|---|---|
| 1001 | 2017-11-20 | 50 |
| 1002 | 2017-11-21 | 39 |
batch 2
| user_id | date | cost |
|---|---|---|
| 1001 | 2017-11-20 | 1 |
| 1001 | 2017-11-21 | 5 |
| 1003 | 2017-11-22 | 22 |
可以看到,用户 10001 分属在两个导入批次中的数据还没有聚合。但是为了保证用户只能查询到如下最终聚合后的数据:
| user_id | date | cost |
|---|---|---|
| 10001 | 2017-11-20 | 51 |
| 10001 | 2017-11-21 | 5 |
| 10002 | 2017-11-21 | 39 |
| 10003 | 2017-11-20 | 22 |
在查询引擎中加入了聚合算子,来保证数据对外的一致性。
另外,在聚合列(Value)上,执行与聚合类型不一致的聚合类查询时,要注意语意。比如我们在如上示例中执行如下查询:
SELECT COUNT(*) FROM table; 在其他数据库中,这类查询都会很快的返回结果。因为在实现上,我们可以通过如“导入时对行进行计数,保存 count 的统计信息”,或者在查询时“仅扫描某一列数据,获得 count 值”的方式,只需很小的开销,即可获得查询结果。但是在 Doris 的聚合模型中,这种查询的开销非常大。
上面的例子,select count(*) from table; 的正确结果应该为 4。但如果我们只扫描 user_id 这一列,如果加上查询时聚合,最终得到的结果是 3(10001, 10002, 10003)。而如果不加查询时聚合,则得到的结果是 5(两批次一共 5 行数据)。可见这两个结果都是不对的。
为了得到正确的结果,我们必须同时读取 user_id 和 date 这两列的数据,再加上查询时聚合,才能返回 4 这个正确的结果。也就是说,在 count() 查询中,Doris 必须扫描所有的 AGGREGATE KEY 列(这里就是 user_id 和 date),并且聚合后,才能得到语意正确的结果。当聚合列非常多时,count(*) 查询需要扫描大量的数据。
因此,当业务上有频繁的 count() 查询时,我们建议用户通过增加一个值恒为 1 的,聚合类型为 SUM 的列来模拟 count()。如刚才的例子中的表结构,我们修改如下:
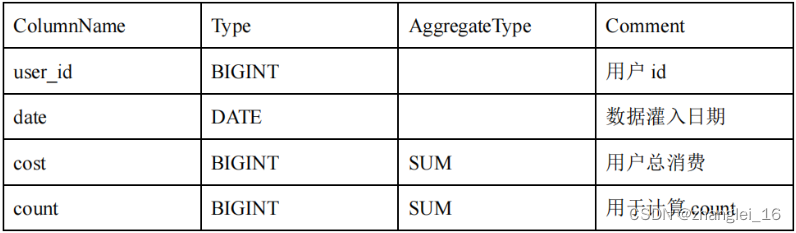
增加一个 count 列,并且导入数据中,该列值恒为 1。则 select count() from table; 的结果等价于 select sum(count) from table;。而后者的查询效率将远高于前者。不过这种方式也有使用限制,就是用户需要自行保证,不会重复导入 AGGREGATE KEY 列都相同的行。否则,select sum(count) from table; 只能表述原始导入的行数,而不是 select count() from table; 的语义。
另一种方式,就是 将如上的 count 列的聚合类型改为 REPLACE,且依然值恒为 1。那么 select sum(count) from table; 和 select count(*) from table; 的结果将是一致的。并且这种方式,没有导入重复行的限制。
3.6 动态分区
动态分区是在 Doris 0.12 版本中引入的新功能。旨在对表级别的分区实现生命周期管理(TTL),减少用户的使用负担。
目前实现了动态添加分区及动态删除分区的功能。动态分区只支持 Range 分区。
3.6.1 原理
在某些使用场景下,用户会将表按照天进行分区划分,每天定时执行例行任务,这时需要使用方手动管理分区,否则可能由于使用方没有创建分区导致数据导入失败,这给使用方带来了额外的维护成本。
通过动态分区功能,用户可以在建表时设定动态分区的规则。FE 会启动一个后台线程,根据用户指定的规则创建或删除分区。用户也可以在运行时对现有规则进行变更。
3.6.2 使用方式
动态分区的规则可以在建表时指定,或者在运行时进行修改。当前仅支持对单分区列的分区表设定动态分区规则。
建表时指定:
CREATE TABLE tbl1
(...)
PROPERTIES
(
"dynamic_partition.prop1" = "value1",
"dynamic_partition.prop2" = "value2",
...
)运行时修改
ALTER TABLE tbl1 SET
(
"dynamic_partition.prop1" = "value1",
"dynamic_partition.prop2" = "value2",
...
)3.6.3 动态分区规则参数
3.6.3.1 主要参数
动态分区的规则参数都以 dynamic_partition. 为前缀:

3.6.3.2 创建历史分区的参数
-
dynamic_partition.create_history_partition
默认为 false。当置为 true 时,Doris 会自动创建所有分区,当期望创建的分区个数大于 max_dynamic_partition_num 值时,操作将被禁止。当不指定 start 属性时,该参数不生效。
-
dynamic_partition.history_partition_num
当 create_history_partition 为 true 时,该参数用于指定创建历史分区数量。默认值为 -1, 即未设置。
-
dynamic_partition.hot_partition_num
指定最新的多少个分区为热分区。对于热分区,系统会自动设置其 storage_medium 参数为 SSD,并且设置 storage_cooldown_time。
hot_partition_num 是往前 n 天和未来所有分区
我们举例说明。假设今天是 2021-05-20,按天分区,动态分区的属性设置为:hot_partition_num=2, end=3, start=-3。则系统会自动创建以下分区,并且设置 storage_medium 和 storage_cooldown_time 参数:
p20210517 : ["2021-05-17", "2021-05-18") storage_medium=HDD storage_cooldown_time=9999-12-31 23:59:59
p20210518 : ["2021-05-18", "2021-05-19") storage_medium=HDD storage_cooldown_time=9999-12-31 23:59:59
p20210519 : ["2021-05-19", "2021-05-20") storage_medium=SSD storage_cooldown_time=2021-05-21 00:00:00
p20210520 : ["2021-05-20", "2021-05-21") storage_medium=SSD storage_cooldown_time=2021-05-22 00:00:00
p20210521 : ["2021-05-21", "2021-05-22") storage_medium=SSD storage_cooldown_time=2021-05-23 00:00:00
p20210522 : ["2021-05-22", "2021-05-23") storage_medium=SSD storage_cooldown_time=2021-05-24 00:00:00
p20210523 : ["2021-05-23", "2021-05-24") storage_medium=SSD storage_cooldown_time=2021-05-25 00:00:00-
dynamic_partition.reserved_history_periods
需要保留的历史分区的时间范围。当 dynamic_partition.time_unit 设置为 "DAY/WEEK/MONTH" 时,需要以 [yyyy-MM-dd,yyyy-MM-dd],[...,...] 格式进行设置。当 dynamic_partition.time_unit 设置为 "HOUR" 时,需要以 [yyyy-MM-dd HH:mm:ss,yyyy-MM-dd HH:mm:ss],[...,...] 的格式来进行设置。如果不设置,默认为 "NULL"。
我们举例说明。假设今天是 2021-09-06,按天分类,动态分区的属性设置为:
time_unit="DAY/WEEK/MONTH", \
end=3, \
start=-3, \
reserved_history_periods="[2020-06-01,2020-06-20],[2020-10-31,2020-11-15]"。则系统会自动保留:
["2020-06-01","2020-06-20"],
["2020-10-31","2020-11-15"]或者
time_unit="HOUR", \
end=3, \
start=-3, \
reserved_history_periods="[2020-06-01 00:00:00,2020-06-01 03:00:00]".则系统会自动保留:
["2020-06-01 00:00:00","2020-06-01 03:00:00"] 这两个时间段的分区。其中,reserved_history_periods 的每一个 [...,...] 是一对设置项,两者需要同时被设置,且第一个时间不能大于第二个时间``。
3.6.3.3 创建历史分区规则
假设需要创建的历史分区数量为 expect_create_partition_num,根据不同的设置具体数量如下:
(1)create_history_partition = true
① dynamic_partition.history_partition_num 未设置,即 -1.
则 expect_create_partition_num = end - start;
② dynamic_partition.history_partition_num 已设置
则 expect_create_partition_num = end - max(start, -histoty_partition_num);
(2)create_history_partition = false
不会创建历史分区,expect_create_partition_num = end - 0;
(3)当 expect_create_partition_num > max_dynamic_partition_num(默认 500)时,禁止创建过多分区。
3.6.3.4 创建历史分区举例
假设今天是 2021-05-20,按天分区,动态分区的属性设置为:create_history_partition=true, end=3, start=-3, history_partition_num=1,则系统会自动创建以下分区:
p20210519
p20210520
p20210521
p20210522
p20210523history_partition_num=5,其余属性与 1 中保持一直,则系统会自动创建以下分区:
p20210517
p20210518
p20210519
p20210520
p20210521
p20210522
p20210523history_partition_num=-1 即不设置历史分区数量,其余属性与 1 中保持一直,则系统会自动创建以下分区:
p20210517
p20210518
p20210519
p20210520
p20210521
p20210522
p202105233.6.3.5 注意事项
动 态 分 区 使 用 过 程 中 , 如 果 因 为 一 些 意 外 情 况 导 致 dynamic_partition.start 和 dynamic_partition.end 之间的某些分区丢失,那么当前时间与 dynamic_partition.end 之间的丢失分区会被重新创建,dynamic_partition.start 与当前时间之间的丢失分区不会重新创建。
3.6.4 示例
1)创建动态分区表
分区列 time 类型为 DATE,创建一个动态分区规则。按天分区,只保留最近 7 天的分区,并且预先创建未来 3 天的分区。
create table student_dynamic_partition1
(id int,
time date,
name varchar(50),
age int
)
duplicate key(id,time)
PARTITION BY RANGE(time)()
DISTRIBUTED BY HASH(id) buckets 10
PROPERTIES(
"dynamic_partition.enable" = "true",
"dynamic_partition.time_unit" = "DAY",
"dynamic_partition.start" = "-7",
"dynamic_partition.end" = "3",
"dynamic_partition.prefix" = "p",
"dynamic_partition.buckets" = "10",
"replication_num" = "1"
);2)查看动态分区表调度情况
SHOW DYNAMIC PARTITION TABLES; -
LastUpdateTime: 最后一次修改动态分区属性的时间
-
LastSchedulerTime: 最后一次执行动态分区调度的时间
-
State: 最后一次执行动态分区调度的状态
-
LastCreatePartitionMsg: 最后一次执行动态添加分区调度的错误信息
-
LastDropPartitionMsg: 最后一次执行动态删除分区调度的错误信息
3)查看表的分区
SHOW PARTITIONS FROM student_dynamic_partition1; 4)插入测试数据,可以全部成功(修改成对应时间)
insert into student_dynamic_partition1 values(1,'2022-03-31 11:00:00','name1',18);
insert into student_dynamic_partition1 values(1,'2022-04-01 11:00:00','name1',18);
insert into student_dynamic_partition1 values(1,'2022-04-02 11:00:00','name1',18);5)设置创建历史分区
ALTER TABLE student_dynamic_partition1 SET ("dynamic_partition.create_history_partition" = "true");
查看分区情况
SHOW PARTITIONS FROM student_dynamic_partition1;6)动态分区表与手动分区表相互转换
对于一个表来说,动态分区和手动分区可以自由转换,但二者不能同时存在,有且只有一种状态。
(1)手动分区转换为动态分区
如果一个表在创建时未指定动态分区,可以通过 ALTER TABLE 在运行时修改动态分区相关属性来转化为动态分区,具体示例可以通过 HELP ALTER TABLE 查看。
注意:如果已设定 dynamic_partition.start,分区范围在动态分区起始偏移之前的历史分区将会被删除。
(2)动态分区转换为手动分区
ALTER TABLE tbl_name SET ("dynamic_partition.enable" = "false"); 关闭动态分区功能后,Doris 将不再自动管理分区,需要用户手动通过 ALTER TABLE 的方式创建或删除分区。
3.7 Rollup
ROLLUP 在多维分析中是“上卷”的意思,即将数据按某种指定的粒度进行进一步聚合。
3.7.1 基本概念
在 Doris 中,我们将用户通过建表语句创建出来的表称为 Base 表(Base Table)。Base 表中保存着按用户建表语句指定的方式存储的基础数据。
在 Base 表之上,我们可以创建任意多个 ROLLUP 表。这些 ROLLUP 的数据是基于 Base 表产生的,并且在物理上是独立存储的。
ROLLUP 表的基本作用,在于在 Base 表的基础上,获得更粗粒度的聚合数据。
3.7.2 Aggregate 和 Uniq 模型中的 ROLLUP
因为 Uniq 只是 Aggregate 模型的一个特例,所以这里我们不加以区别。
1)以 3.5.1.2 中创建的 example_site_visit2 表为例。
(1)查看表的结构信息
desc example_site_visit2 all; (2)比如需要查看某个用户的总消费,那么可以建立一个只有 user_id 和 cost 的 rollup
alter table example_site_visit2 add rollup rollup_cost_userid(user_id,cost); (3)查看表的结构信息
desc example_site_visit2 all;(4)然后可以通过 explain 查看执行计划,是否使用到了 rollup
explain SELECT user_id, sum(cost) FROM example_site_visit2 GROUP BY user_id;Doris 会自动命中这个 ROLLUP 表,从而只需扫描极少的数据量,即可完成这次聚合查询。
(5)通过命令查看完成状态
SHOW ALTER TABLE ROLLUP;2)示例 2:获得不同城市,不同年龄段用户的总消费、最长和最短页面驻留时间
(1)创建 ROLLUP
alter table example_site_visit2 add rollup rollup_city_age_cost_maxd_mind(city,age,cost,max_dwell_time,min_dwell_time);(2)查看 rollup 使用
explain SELECT city, age, sum(cost), max(max_dwell_time),min(min_dwell_time) FROM example_site_visit2 GROUP BY city, age;
explain SELECT city, sum(cost), max(max_dwell_time),min(min_dwell_time) FROM example_site_visit2 GROUP BY city;
explain SELECT city, age, sum(cost), min(min_dwell_time) FROM example_site_visit2 GROUP BY city, age;(3)通过命令查看完成状态
SHOW ALTER TABLE ROLLUP;3.7.3 Duplicate 模型中的 ROLLUP
因为 Duplicate 模型没有聚合的语意。所以该模型中的 ROLLUP,已经失去了“上卷” 这一层含义。而仅仅是作为调整列顺序,以命中前缀索引的作用。下面详细介绍前缀索引,以及如何使用 ROLLUP 改变前缀索引,以获得更好的查询效率。
3.7.3.1 前缀索引
不同于传统的数据库设计,Doris 不支持在任意列上创建索引。Doris 这类 MPP 架构的 OLAP 数据库,通常都是通过提高并发,来处理大量数据的。
本质上,Doris 的数据存储在类似 SSTable(Sorted String Table)的数据结构中。该结构是一种有序的数据结构,可以按照指定的列进行排序存储。在这种数据结构上,以排序列作为条件进行查找,会非常的高效。
在 Aggregate、Uniq 和 Duplicate 三种数据模型中。底层的数据存储,是按照各自建表语句中,AGGREGATE KEY、UNIQ KEY 和 DUPLICATE KEY 中指定的列进行排序存储的。而前缀索引,即在排序的基础上,实现的一种根据给定前缀列,快速查询数据的索引方式。
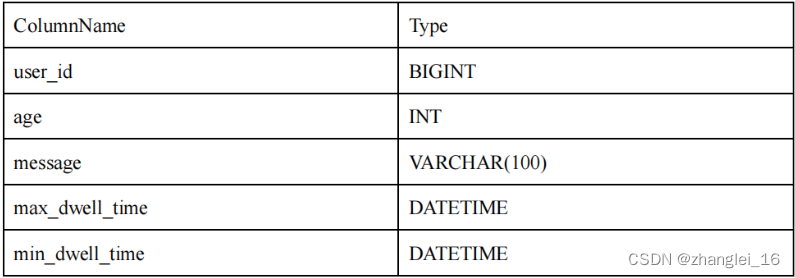
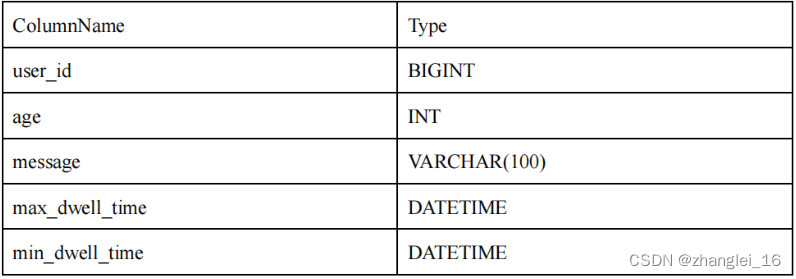
我们将一行数据的前 36 个字节 作为这行数据的前缀索引。当遇到 VARCHAR 类型时,前缀索引会直接截断。举例说明:
1)以下表结构的前缀索引为 user_id(8 Bytes) + age(4 Bytes) + message(prefix 20 Bytes)。
2)以下表结构的前缀索引为 user_name(20 Bytes)。即使没有达到 36 个字节,因为遇到 VARCHAR,所以直接截断,不再往后继续。

3)当我们的查询条件,是前缀索引的前缀时,可以极大的加快查询速度。比如在第一个例子中,我们执行如下查询:
SELECT * FROM table WHERE user_id=1829239 and age=20;该查询的效率会远高于如下查询:
SELECT * FROM table WHERE age=20;所以在建表时,正确的选择列顺序,能够极大地提高查询效率。
3.7.3.2 ROLLUP 调整前缀索引
因为建表时已经指定了列顺序,所以一个表只有一种前缀索引。这对于使用其他不能命中前缀索引的列作为条件进行的查询来说,效率上可能无法满足需求。因此,我们可以通过创建 ROLLUP 来人为的调整列顺序。举例说明。
Base 表结构如下:
我们可以在此基础上创建一个 ROLLUP 表:

可以看到,ROLLUP 和 Base 表的列完全一样,只是将 user_id 和 age 的顺序调换了。那么当我们进行如下查询时:
SELECT * FROM table where age=20 and message LIKE "%error%";会优先选择 ROLLUP 表,因为 ROLLUP 的前缀索引匹配度更高。
3.7.4 ROLLUP 的几点说明
-
ROLLUP 最根本的作用是提高某些查询的查询效率(无论是通过聚合来减少数据量,还是修改列顺序以匹配前缀索引)。因此 ROLLUP 的含义已经超出了“上卷” 的范围。这也是为什么在源代码中,将其命名为 Materialized Index(物化索引)的原因。
-
ROLLUP 是附属于 Base 表的,可以看做是 Base 表的一种辅助数据结构。用户可以在 Base 表的基础上,创建或删除 ROLLUP,但是不能在查询中显式的指定查询某ROLLUP。是否命中 ROLLUP 完全由 Doris 系统自动决定。
-
ROLLUP 的数据是独立物理存储的。因此,创建的 ROLLUP 越多,占用的磁盘空间也就越大。同时对导入速度也会有影响(导入的 ETL 阶段会自动产生所有ROLLUP 的数据),但是不会降低查询效率(只会更好)。
-
ROLLUP 的数据更新与 Base 表是完全同步的。用户无需关心这个问题。
-
ROLLUP 中列的聚合方式,与 Base 表完全相同。在创建 ROLLUP 无需指定,也不能修改。
-
查询能否命中 ROLLUP 的一个必要条件(非充分条件)是,查询所涉及的所有列(包括 select list 和 where 中的查询条件列等)都存在于该 ROLLUP 的列中。否则,查询只能命中 Base 表。
-
某些类型的查询(如 count(*))在任何条件下,都无法命中 ROLLUP。具体参见接下来的聚合模型的局限性一节。
-
可以通过 EXPLAIN your_sql; 命令获得查询执行计划,在执行计划中,查看是否命中 ROLLUP。
-
可以通过 DESC tbl_name ALL; 语句显示 Base 表和所有已创建完成的 ROLLUP。
3.8 物化视图
物化视图就是包含了查询结果的数据库对象,可能是对远程数据的本地 copy,也可能是一个表或多表 join 后结果的行或列的子集,也可能是聚合后的结果。说白了,就是预先存储查询结果的一种数据库对象。
在 Doris 中的物化视图,就是查询结果预先存储起来的特殊的表。
物化视图的出现主要是为了满足用户,既能对原始明细数据的任意维度分析,也能快速的对固定维度进行分析查询。
3.8.1 适用场景
-
分析需求覆盖明细数据查询以及固定维度查询两方面。
-
查询仅涉及表中的很小一部分列或行。
-
查询包含一些耗时处理操作,比如:时间很久的聚合操作等。
-
查询需要匹配不同前缀索引。
3.8.2 优势
-
对于那些经常重复的使用相同的子查询结果的查询性能大幅提升。
-
Doris 自动维护物化视图的数据,无论是新的导入,还是删除操作都能保证 base 表和物化视图表的数据一致性。无需任何额外的人工维护成本。
-
查询时,会自动匹配到最优物化视图,并直接从物化视图中读取数据。自动维护物化视图的数据会造成一些维护开销,会在后面的物化视图的局限性中展开说 明。
3.8.3 物化视图 VS Rollup
在没有物化视图功能之前,用户一般都是使用 Rollup 功能通过预聚合方式提升查询效率的。但是 Rollup 具有一定的局限性,他不能基于明细模型做预聚合。
物化视图则在覆盖了 Rollup 的功能的同时,还能支持更丰富的聚合函数。所以物化视图其实是 Rollup 的一个超集。
也就是说,之前 ALTER TABLE ADD ROLLUP 语法支持的功能现在均可以通过CREATE MATERIALIZED VIEW 实现。
3.8.4 物化视图原理
Doris 系统提供了一整套对物化视图的 DDL 语法,包括创建,查看,删除。DDL 的语法和 PostgreSQL, Oracle 都是一致的。但是 Doris 目前创建物化视图只能在单表操作,不支持 join。
3.8.4.1 创建物化视图
首先要根据查询语句的特点来决定创建一个什么样的物化视图。并不是说物化视图定义和某个查询语句一模一样就最好。这里有两个原则:
(1)从查询语句中抽象出,多个查询共有的分组和聚合方式作为物化视图的定义。
(2)不需要给所有维度组合都创建物化视图。
首先第一个点,一个物化视图如果抽象出来,并且多个查询都可以匹配到这张物化视图。这种物化视图效果最好。因为物化视图的维护本身也需要消耗资源。
如果物化视图只和某个特殊的查询很贴合,而其他查询均用不到这个物化视图。则会导致这张物化视图的性价比不高,既占用了集群的存储资源,还不能为更多的查询服务。
所以用户需要结合自己的查询语句,以及数据维度信息去抽象出一些物化视图的定义。
第二点就是,在实际的分析查询中,并不会覆盖到所有的维度分析。所以给常用的维度组合创建物化视图即可,从而到达一个空间和时间上的平衡。
通过下面命令就可以创建物化视图了。创建物化视图是一个异步的操作,也就是说用户成功提交创建任务后,Doris 会在后台对存量的数据进行计算,直到创建成功。
具体的语法可以通过下面命令查看:HELP CREATE MATERIALIZED VIEW
这里以一个销售记录表为例:

比如我们有一张销售记录明细表,存储了每个交易的时间,销售员,销售门店,和金额。
提交完创建物化视图的任务后,Doris 就会异步在后台生成物化视图的数据,构建物化视图。
在构建期间,用户依然可以正常的查询和导入新的数据。创建任务会自动处理当前的存量数据和所有新到达的增量数据,从而保持和 base 表的数据一致性。用户不需关心一致性问题。
3.8.4.2 查询
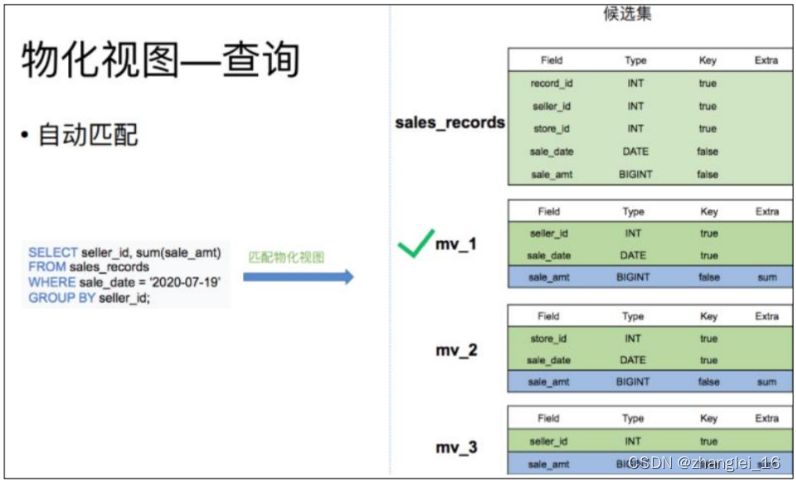
物化视图创建完成后,用户的查询会根据规则自动匹配到最优的物化视图。
比如我们有一张销售记录明细表,并且在这个明细表上创建了三张物化视图。一个存储了不同时间不同销售员的售卖量,一个存储了不同时间不同门店的销售量,以及每个销售员的总销售量。
当查询 7 月 19 日,各个销售员都买了多少钱的话。就可以匹配 mv_1 物化视图。直接对 mv_1 的数据进行查询。
3.8.4.3 查询自动匹配
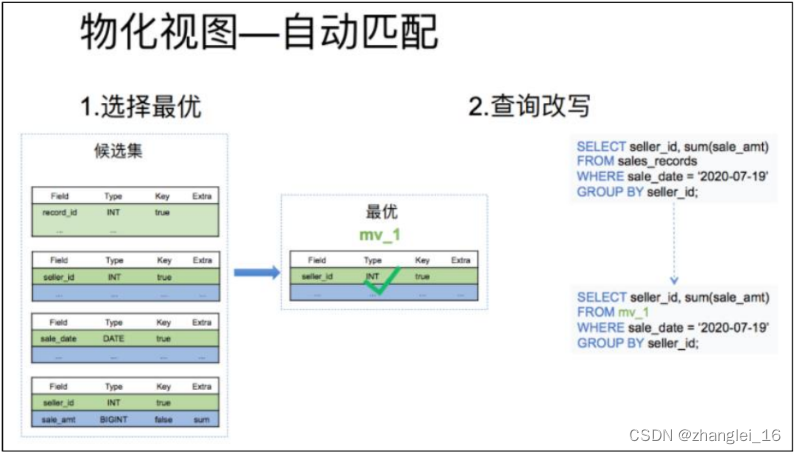
物化视图的自动匹配分为下面两个步骤:
(1)根据查询条件删选出一个最优的物化视图:这一步的输入是所有候选物化视图表的元数据,根据查询的条件从候选集中输出最优的一个物化视图
(2)根据选出的物化视图对查询进行改写:这一步是结合上一步选择出的最优物化视图,进行查询的改写,最终达到直接查询物化视图的目的。

其中 bitmap 和 hll 的聚合函数在查询匹配到物化视图后,查询的聚合算子会根据物化视图的表结构进行一个改写。详细见实例 2.
3.8.4.4 最优路径选择
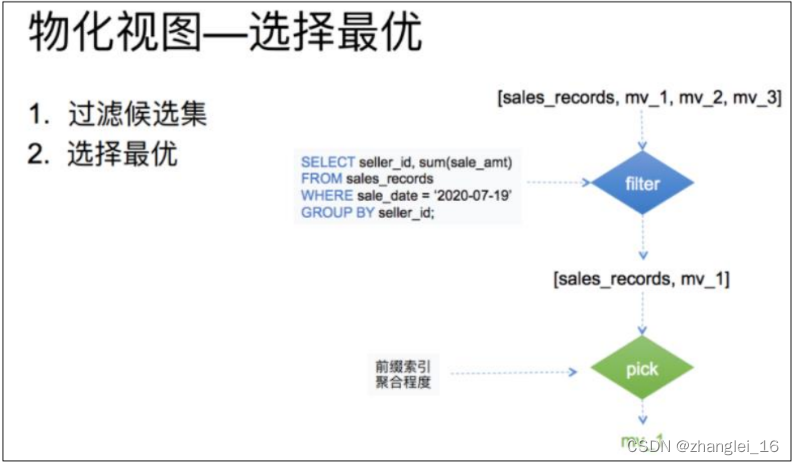
这里分为两个步骤:
(1)对候选集合进行一个过滤。只要是查询的结果能从物化视图数据计算(取部分行,部分列,或部分行列的聚合)出都可以留在候选集中,过滤完成后候选集合大小>=1。
(2)从候选集合中根据聚合程度,索引等条件选出一个最优的也就是查询花费最少物化视图。
这里再举一个相对复杂的例子,来体现这个过程:
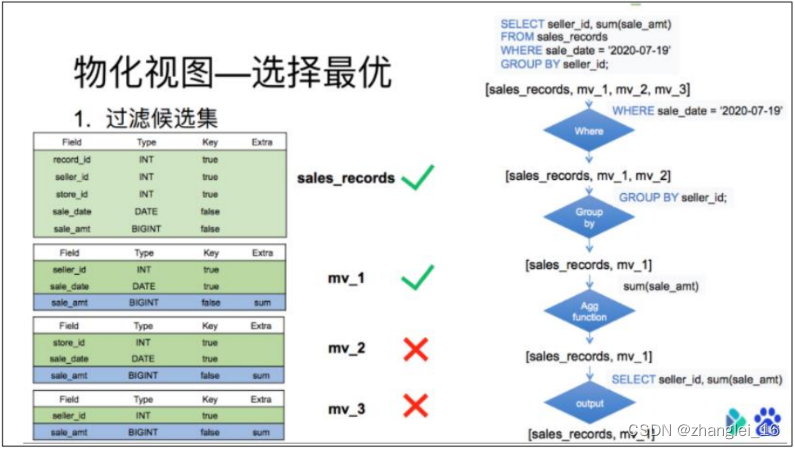
候选集过滤目前分为 4 层,每一层过滤后去除不满足条件的物化视图。
比如查询 7 月 19 日,各个销售员都买了多少钱,候选集中包括所有的物化视图以及 base表共 4 个:
第一层过滤先判断查询 where 中的谓词涉及到的数据是否能从物化视图中得到。也就是销售时间列是否在表中存在。由于第三个物化视图中根本不存在销售时间列。所以在这一层过滤中,mv_3 就被淘汰了。
第二层是过滤查询的分组列是否为候选集的分组列的子集。也就是销售员 id 是否为表中分组列的子集。由于第二个物化视图中的分组列并不涉及销售员 id。所以在这一层过滤中,mv_2 也被淘汰了。
第三层过滤是看查询的聚合列是否为候选集中聚合列的子集。也就是对销售额求和是否能从候选集的表中聚合得出。这里 base 表和物化视图表均满足标准。
最后一层是过滤看查询需要的列是否存在于候选集合的列中。由于候选集合中的表均满足标准,所以最终候选集合中的表为 销售明细表,以及 mv_1,这两张。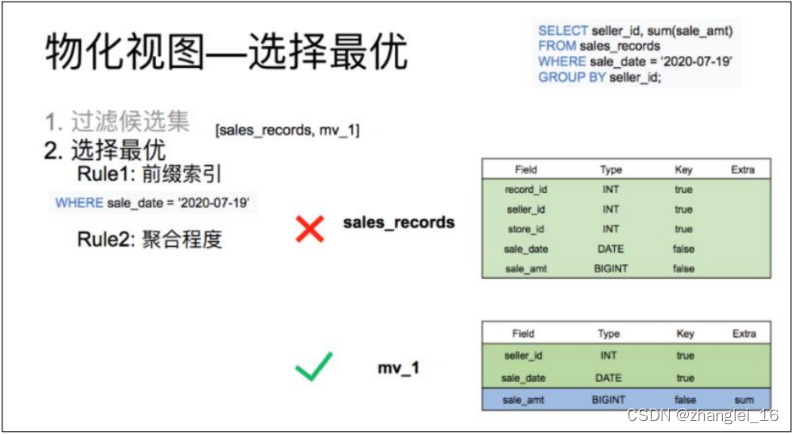
候选集过滤完后输出一个集合,这个集合中的所有表都能满足查询的需求。但每张表的查询效率都不同。这时候就需要再这个集合根据前缀索引是否能匹配到,以及聚合程度的高低来选出一个最优的物化视图。
从表结构中可以看出,base 表的销售日期列是一个非排序列,而物化视图表的日期是一个排序列,同时聚合程度上 mv_1 表明显比 base 表高。所以最后选择出 mv_1 作为该查询的 最优匹配。
最后再根据选择出的最优解,改写查询。
刚才的查询选中 mv_1 后,将查询改写为从 mv_1 中读取数据,过滤出日志为 7 月 19 日的 mv_1 中的数据然后返回即可。
3.8.4.5 查询改写
有些情况下的查询改写还会涉及到查询中的聚合函数的改写。
比如业务方经常会用到 count distinct 对 PV UV 进行计算。
例如;
广告点击明细记录表中存放哪个用户点击了什么广告,从什么渠道点击的,以及点击的时间。并且在这个 base 表基础上构建了一个物化视图表,存储了不同广告不同渠道的用户 bitmap 值。
由于 bitmap union 这种聚合方式本身会对相同的用户 user id 进行一个去重聚合。当用户查询广告在 web 端的 uv 的时候,就可以匹配到这个物化视图。匹配到这个物化视图表后就需要对查询进行改写,将之前的对用户 id 求 count(distinct) 改为对物化视图中 bitmap union 列求 count。
所以最后查询取物化视图的第一和第三行求 bitmap 聚合中有几个值。
3.8.4.6 使用及限制

(1)目前支持的聚合函数包括,常用的 sum,min,max count,以及计算 pv ,uv, 留存率,等常用的去重算法 hll_union,和用于精确去重计算 count(distinct)的算法 bitmap_union。
(2)物化视图的聚合函数的参数不支持表达式仅支持单列,比如: sum(a+b)不支持。
(3)使用物化视图功能后,由于物化视图实际上是损失了部分维度数据的。所以对表的 DML 类型操作会有一些限制:
如果表的物化视图 key 中不包含删除语句中的条件列,则删除语句不能执行。
比如想要删除渠道为 app 端的数据,由于存在一个物化视图并不包含渠道这个字段,则这个删除不能执行,因为删除在物化视图中无法被执行。这时候你只能把物化视图先删除,然后删除完数据后,重新构建一个新的物化视图。
(4)单表上过多的物化视图会影响导入的效率:导入数据时,物化视图和 base 表数据是同步更新的,如果一张表的物化视图表超过 10 张,则有可能导致导入速度很慢。这就像单次导入需要同时导入 10 张表数据是一样的。
(5)相同列,不同聚合函数,不能同时出现在一张物化视图中,比如:select sum(a), min(a) from table 不支持。
(6)物化视图针对 Unique Key 数据模型,只能改变列顺序,不能起到聚合的作用,所以在 Unique Key 模型上不能通过创建物化视图的方式对数据进行粗粒度聚合操作
3.8.5 案例演示
3.8.5.1 案例一
1)创建一个 Base 表
create table sales_records(
record_id int,
seller_id int,
store_id int,
sale_date date,
sale_amt bigint
)
distributed by hash(record_id)
properties("replication_num" = "1");
#插入数据
insert into sales_records values(1,2,3,'2020-02-02',10);
2)基于这个 Base 表的数据提交一个创建物化视图的任务,需要等表的数据完成均衡,或者可以关闭数据均衡。
create materialized view store_amt as
select store_id, sum(sale_amt)
from sales_records
group by store_id;3)检查物化视图是否构建完成
由于创建物化视图是一个异步的操作,用户在提交完创建物化视图任务后,需要异步的通过命令检查物化视图是否构建完成。
SHOW ALTER TABLE MATERIALIZED VIEW FROM test_db; (Version 0.13)
#查看 Base 表的所有物化视图
desc sales_records all;4)检验当前查询是否匹配到了合适的物化视图
EXPLAIN SELECT store_id, sum(sale_amt) FROM sales_records GROUP BY store_id;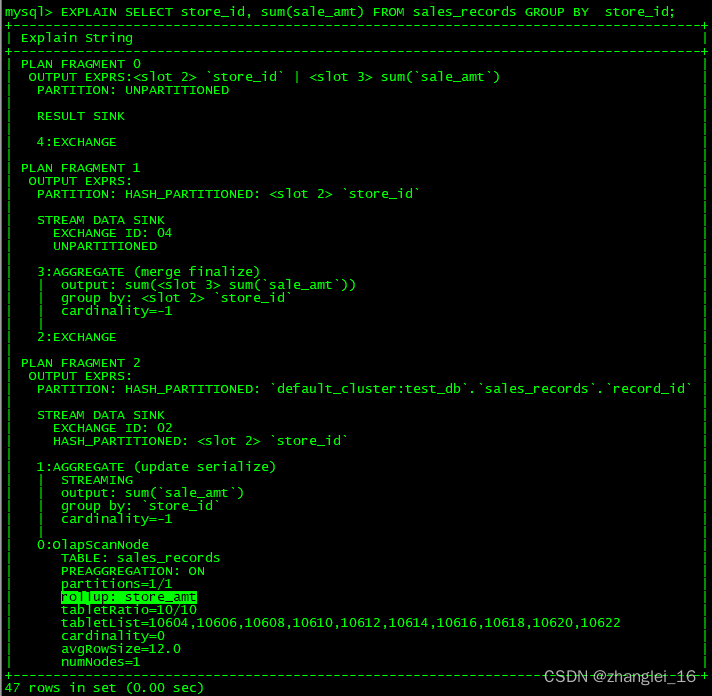
5)删除物化视图语法
DROP MATERIALIZED VIEW 物化视图名 on Base 表名; 3.8.5.2 案例二:计算广告的 pv、uv
假设用户的原始广告点击数据存储在 Doris,那么针对广告 PV, UV 查询就可以通过创建 bitmap_union 的物化视图来提升查询速度。
1)创建 base 表
create table advertiser_view_record(
time date,
advertiser varchar(10),
channel varchar(10),
user_id int
)
distributed by hash(time)
properties("replication_num" = "1");
#插入数据
insert into advertiser_view_record values('2020-02-02','a','app',123);2)创建物化视图
create materialized view advertiser_uv as
select advertiser, channel, bitmap_union(to_bitmap(user_id))
from advertiser_view_record
group by advertiser, channel;在 Doris 中,count(distinct) 聚合的结果和 bitmap_union_count 聚合的结果是完全一致的。而bitmap_union_count 等于 bitmap_union 的结果求 count,所以如果查询中涉及到 count(distinct) 则通过创建带 bitmap_union 聚合的物化视图方可加快查询。
因为本身 user_id 是一个 INT 类型,所以在 Doris 中需要先将字段通过函数 to_bitmap 转换为 bitmap 类型然后才可以进行 bitmap_union 聚合。
3)查询自动匹配
SELECT advertiser, channel, count(distinct user_id)
FROM advertiser_view_record
GROUP BY advertiser, channel;会自动转换成。
SELECT advertiser, channel, bitmap_union_count(to_bitmap(user_id))
FROM advertiser_uv
GROUP BY advertiser, channel;4)检验是否匹配到物化视图
explain SELECT advertiser, channel, count(distinct user_id) FROM advertiser_view_record GROUP BY advertiser, channel;在 EXPLAIN 的结果中,首先可以看到 OlapScanNode 的 rollup 属性值为 advertiser_uv。也就是说,查询会直接扫描物化视图的数据。说明匹配成功。
其次对于 user_id 字段求 count(distinct)被改写为求 bitmap_union_count(to_bitmap)。也就是通过 bitmap 的方式来达到精确去重的效果。
3.8.5.3 案例三
用户的原始表有(k1, k2, k3)三列。其中 k1, k2 为前缀索引列。这时候如果用户查询条件中包含 where k1=1 and k2=2 就能通过索引加速查询。
但是有些情况下,用户的过滤条件无法匹配到前缀索引,比如 where k3=3。则无法通过索引提升查询速度。
创建以 k3 作为第一列的物化视图就可以解决这个问题。
1)查询
explain select record_id,seller_id,store_id from sales_records where store_id=3;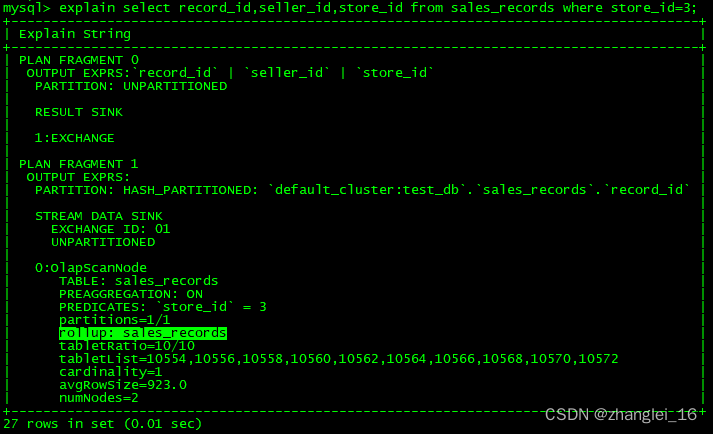
2)创建物化视图
create materialized view mv_1 as
select
store_id,
record_id,
seller_id,
sale_date,
sale_amt
from sales_records;通过上面语法创建完成后,物化视图中既保留了完整的明细数据,且物化视图的前缀索引为 store_id 列。
3)查看表结构
desc sales_records all;4)查询匹配
explain select record_id,seller_id,store_id from sales_records where store_id=3; 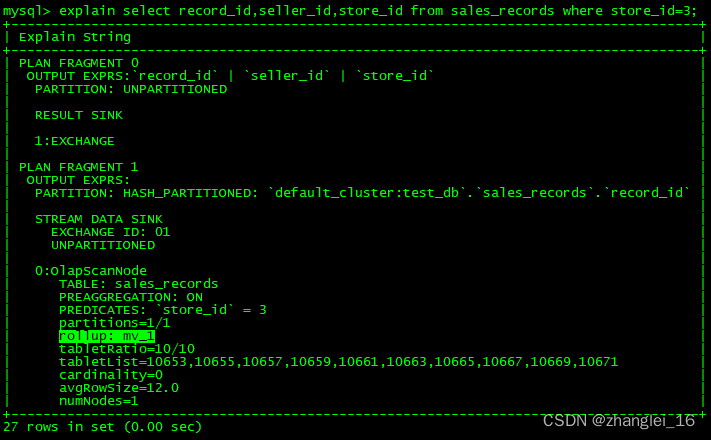
这时候查询就会直接从刚才创建的 mv_1 物化视图中读取数据。物化视图对 store_id 是存在前缀索引的,查询效率也会提升。
3.9 修改表
使用 ALTER TABLE 命令可以对表进行修改,包括 partition 、rollup、schema change、rename 和 index 五种。语法:
ALTER TABLE [database.]table
alter_clause1[, alter_clause2, ...];alter_clause 分为 partition 、rollup、schema change、rename 和 index 五种。
3.9.1 rename
1)将名为 table1 的表修改为 table2
ALTER TABLE table1 RENAME table2; 2)将表 example_table 中名为 rollup1 的 rollup index 修改为 rollup2
ALTER TABLE example_table RENAME ROLLUP rollup1 rollup2; 3)将表 example_table 中名为 p1 的 partition 修改为 p2
ALTER TABLE example_table RENAME PARTITION p1 p2;3.9.2 partition
1)增加分区, 使用默认分桶方式
现有分区 [MIN, 2013-01-01),增加分区 [2013-01-01, 2014-01-01),
ALTER TABLE example_db.my_table ADD PARTITION p1 VALUES LESS THAN ("2014-01-01"); 2)增加分区,使用新的分桶数
ALTER TABLE example_db.my_table ADD PARTITION p1 VALUES LESS THAN ("2015-01-01") DISTRIBUTED BY HASH(k1) BUCKETS 20;3)增加分区,使用新的副本数
ALTER TABLE example_db.my_table ADD PARTITION p1 VALUES LESS THAN ("2015-01-01") ("replication_num"="1");4)修改分区副本数
ALTER TABLE example_db.my_table MODIFY PARTITION p1 SET("replication_num"="1");5)批量修改指定分区
ALTER TABLE example_db.my_table MODIFY PARTITION (p1, p2, p4) SET("in_memory"="true");6)批量修改所有分区
ALTER TABLE example_db.my_table MODIFY PARTITION (*) SET("storage_medium"="HDD");7)删除分区
ALTER TABLE example_db.my_table DROP PARTITION p1;8)增加一个指定上下界的分区
ALTER TABLE example_db.my_table ADD PARTITION p1 VALUES [("2014-01-01"), ("2014-02-01"));3.9.3 rollup
1)创建 index: example_rollup_index,基于 base index(k1,k2,k3,v1,v2)。列式存储。
ALTER TABLE example_db.my_table ADD ROLLUP example_rollup_index(k1, k3, v1, v2); 2)创建 index: example_rollup_index2,基于 example_rollup_index(k1,k3,v1,v2)
ALTER TABLE example_db.my_table ADD ROLLUP example_rollup_index2 (k1, v1) FROM example_rollup_index; 3)创建 index: example_rollup_index3, 基于 base index (k1,k2,k3,v1), 自定义 rollup 超时时间一小时。
ALTER TABLE example_db.my_table ADD ROLLUP example_rollup_index(k1, k3, v1) PROPERTIES("timeout" = "3600"); 4)删除 index: example_rollup_index2
ALTER TABLE example_db.my_table DROP ROLLUP example_rollup_index2; 3.9.4 表结构变更
使用 ALTER TABLE 命令可以修改表的 Schema,包括如下修改:
-
增加列
-
删除列
-
修改列类型
-
改变列顺序
以增加列为例:
1)我们新增一列 uv,类型为 BIGINT,聚合类型为 SUM,默认值为 0:
ALTER TABLE table1 ADD COLUMN uv BIGINT SUM DEFAULT '0' after pv; 2)提交成功后,可以通过以下命令查看作业进度:
SHOW ALTER TABLE COLUMN; 当作业状态为 FINISHED,则表示作业完成。新的 Schema 已生效。
3)查看新的 Schema
DESC table1; 4)可以使用以下命令取消当前正在执行的作业:
CANCEL ALTER TABLE ROLLUP FROM table1; 5)更多可以参阅: HELP ALTER TABLE
https://doris.apache.org/zh-CN/sql-reference/sql-statements/Data%20Definition/ALTER%20TABLE.html
3.10 删除数据(Delete)
Doris 目前可以通过两种方式删除数据:DELETE FROM 语句和 ALTER TABLE DROP PARTITION 语句。
3.10.1 DELETE FROM Statement(条件删除)
delete from 语句类似标准 delete 语法,具体使用可以查看 help delete; 帮助。
语法:
DELETE FROM table_name [PARTITION partition_name]
WHERE
column_name1 op { value | value_list } [ AND column_name2 op { value
| value_list } ...];
如:
delete from student_kafka where id=1; 注意事项。
(1)该语句只能针对 Partition 级别进行删除。如果一个表有多个 partition 含有需要删除的数据,则需要执行多次针对不同 Partition 的 delete 语句。而如果是没有使用 Partition 的表,partition 的名称即表名。
(2)where 后面的条件谓词只能针对 Key 列,并且谓词之间,只能通过 AND 连接。 如果想实现 OR 的语义,需要执行多条 delete。
(3)delete 是一个同步命令,命令返回即表示执行成功。
(4)从代码实现角度,delete 是一种特殊的导入操作。该命令所导入的内容,也是一个新的数据版本,只是该版本中只包含命令中指定的删除条件。在实际执行查询时,会根据这些条件进行查询时过滤。所以,不建议大量频繁使用 delete 命令,因为这可能导致查询效率降低。
(5)数据的真正删除是在 BE 进行数据 Compaction 时进行的。所以执行完 delete 命令后,并不会立即释放磁盘空间。
(6)delete 命令一个较强的限制条件是,在执行该命令时,对应的表,不能有正在进行的导入任务(包括 PENDING、ETL、LOADING)。而如果有 QUORUM_FINISHED 状态的导入任务,则可能可以执行。
(7)delete 也有一个隐含的类似 QUORUM_FINISHED 的状态。即如果 delete 只在多数副本上完成了,也会返回用户成功。但是会在后台生成一个异步的 delete job(Async Delete Job),来继续完成对剩余副本的删除操作。如果此时通过 show delete 命令,可以看到这种任务在 state 一栏会显示 QUORUM_FINISHED。
3.10.2 DROP PARTITION Statement(删除分区)
该命令可以直接删除指定的分区。因为 Partition 是逻辑上最小的数据管理单元,所以使用 DROP PARTITION 命令可以很轻量的完成数据删除工作。并且该命令不受 load 以及任何其他操作的限制,同时不会影响查询效率。是比较推荐的一种数据删除方式。
该命令是同步命令,执行成功即生效。而后台数据真正删除的时间可能会延迟 10 分钟 左右。




![[C/C++] -- 二叉树](https://img-blog.csdnimg.cn/direct/40d3967febde4c3486c9e53cbfcc084d.jpeg)