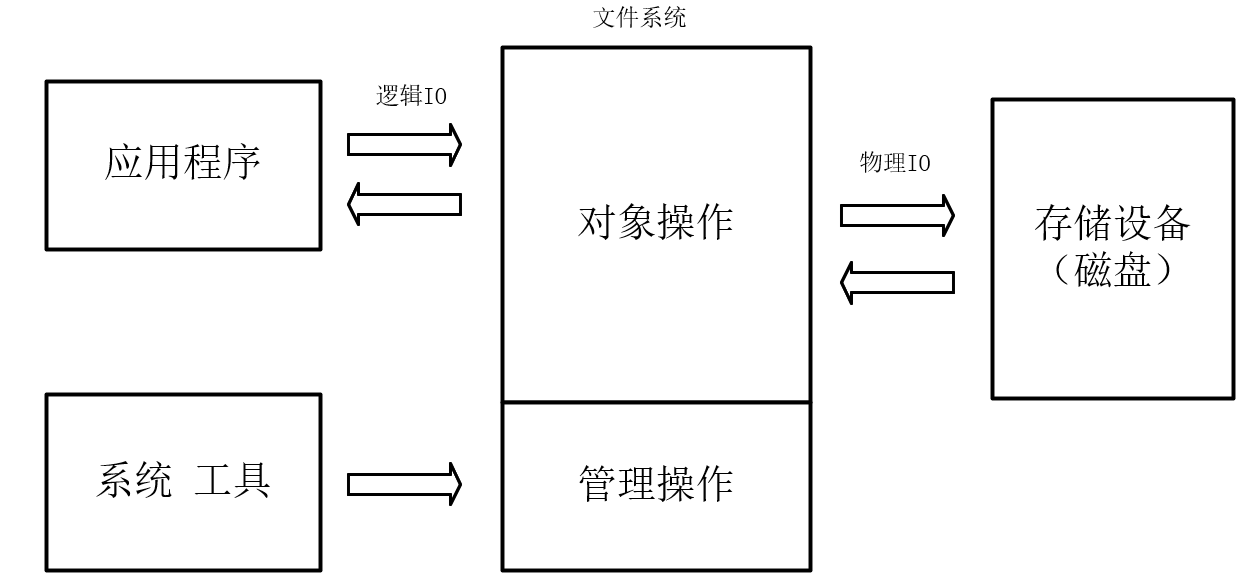
文件系统基本概念
文件系统接口
文件系统: 一种把数据组织成文件和目录的存储方式,提供了基于文件的存取接口,并通过文件权限控制访问。
存储的基本单位
扇区: 磁盘的最小存储存储单位(Sector)。一般每个扇区储存512字节(相当于0.5KB)
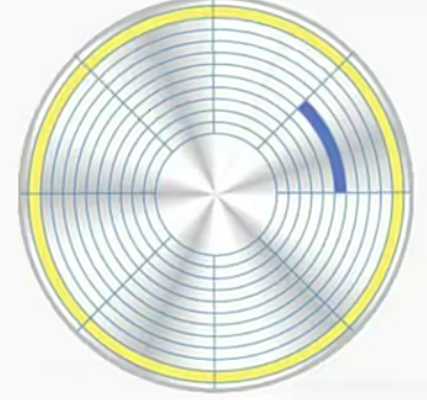
磁盘的每一面被分为很多条磁道,即表面上的一些同心圆,越接近中心,圆就越小。而每一个磁道又按512个字节为单位划分为等分,叫做扇区。
文件存储单位
块: 文件存取的最小单位。"块"的大小,最常见的是4KB,即连续八个sector组成一个block。

文件结构
Ext*格式化分区 :操作系统自动将硬盘分成三个区域。
目录项区 :存放目录下文件的列表信息
数据区 :存放文件数据
inode区( inode table) :存放inode所包含的信息

文件不包含目录项,只有后面两项
inode 是唯一标识
inode : “索引节点”,储存文件的元信息,比如文件的创建者、文件的创建日期、文件的大小等等。每个inode都有一个号码,操作系统用 inode 号码来识别不同的文件。ls -i 查看 inode 号
inode 节点大小一般是128字节或256字节。inode节点的总数,格式化时就给定,一般是每1KB或每2KB就设置一个inode。一块1GB的硬盘中,每1KB就设置一个inode,那么inode table的大小就会达到128MB,占整块硬盘的12.8%。
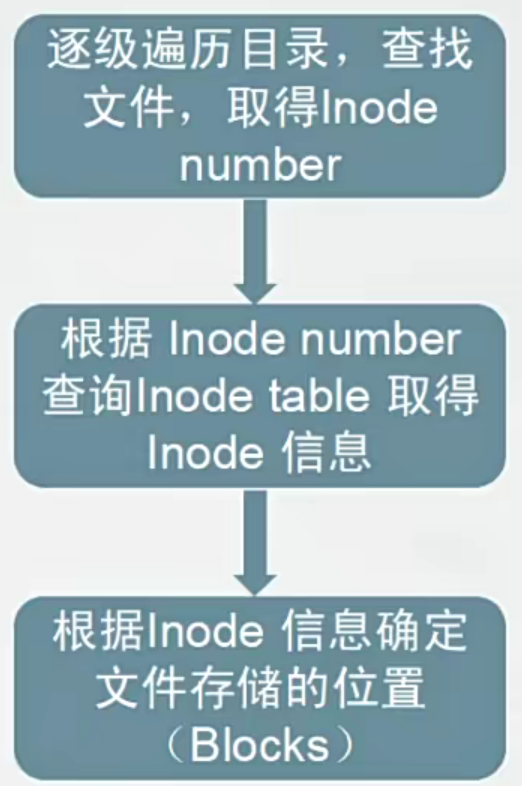
系统读取文件三步
Unix/Linux 系统内部不使用文件名,而使用 inode 号码来识别文件。对于系统来说,文件名只是 inode 号码便于识别的别称或者绰号。
表面上,用户通过文件名,打开文件。实际上,系统内部这个过程分成三步:首先,系统找到这个文件名对应的inode号码;其次,通过 inode 号码,获取 inode 信息;最后,根据 inode 信息,找到文件数据所在的 block,读出数据。
ls 命令只列出目录文件中的所有文件名
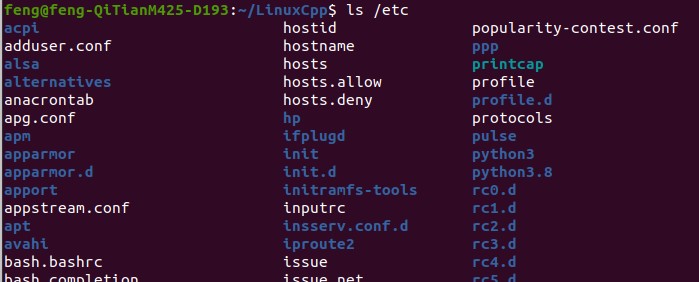
ls -i 命令列出整个目录文件,即文件名和inode号码。

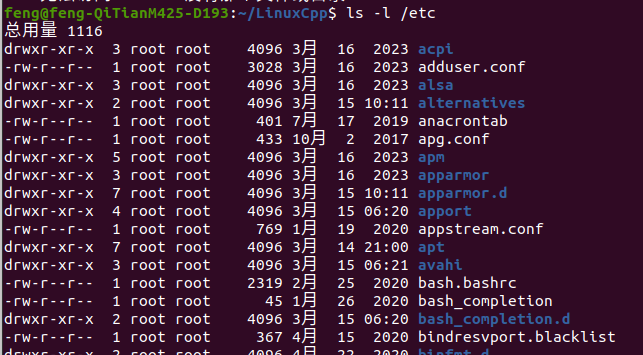
如果要查看文件的详细信息,就必须根据inode号码,访问inode节点,读取信息。ls -l 命令列出文件的详细信息。
Unix/Linux系统允许,多个文件名指向同一个inode号码。
分布式文件系统
分布式文件系统(Distributed File System,DFS) 是指文件系统管理的物理存储资源不一定直接连接在本地节点上,而是通过计算机网络与节点(可简单的理解为一台计算机)相连;或是若干不同的逻辑磁盘分区或卷标组合在一起而形成的完整的有层次的文件系统。
DFS为分布在网络上任意位置的资源提供一个逻辑上的树形文件系统结构,从而使用户访问分布在网络上的共享文件更加简便。
单独的 DFS共享文件夹的作用是相对于通过网络上的其他共享文件夹的访问点。
特点: 在一个分享的磁盘文件系统中,所有节点对数据存储区块都有相同的访问权,在这样的系统中,访问权限就必须由客户端程序来控制。分布式文件系统可能包含的功能有:透通的数据复制与容错。
分布式文件系统是被设计用在局域网。而分布式数据存储,则是泛指应用分布式运算技术的文件和数据库等提供数据存储服务的系统。
HDFS (The Hadoop Distributed File System)
结构: 主从式结构、有中心节点、中心化;
一个 HDFS 集群包括一个 NameNode 以及不等数量的 DataNode。NameNode 作为 master server 负责管理文件系统的命名空间和以及客户端对文件的访问。它执行文件系统里命名空间的一些操作,比如打开文件、关闭文件、重命名文件等,同时它也负责决定数据块 (block) 到 DataNode 的映射。DataNode 则负责管理连接到该节点上的存储,执行数据块(block)的生成、检测、复制等操作。
在文件系统内部,一个文件被分为一个或多个块,这些块被存储到一组DataNode上。
一种典型的部署方案,一台中心机器只运行NameNode软件,同时每台其他机器运行一个DataNode软件。
优势和特点:
1.有容错机制,能够探测错误并迅速修复错误;
2.系统设计倾向于批处理,不擅长交互性使用。强调数据访问的高吞吐量,而不是数据访问的低延迟;
3.适合大数据量。系统数据组织是以GB和TB为基础,支持高数据带宽和规模;
4.简单的一致性模型。一个文件一旦被创建、写入和关闭,就不会被改变;
5.数据计算在根据数据存放位置决定,尽量靠近数据位置,而不是取决于应用运行位置。
https://zhuanlan.zhihu.com/p/402369224
Fast Distributed file system, FastDFS
FastDFS:是一个开源的轻量级分布式文件系统。
功能包括:文件存储、文件同步、文件访问(文件上传、文件下载)等,解决了大容量存储和负载均衡的问题。特别适合中小文件(建议范围:4KB < file_size <500MB),对以文件为载体的在线服务,如相册网站、视频网站等。
FastDFS是为互联网应用量身定做的分布式文件系统,充分考虑了冗余备份、负载均衡、线性扩容等机制,并注重高可用、高性能等指标。和现有的类Google FS分布式文件系统相比,FastDFS的架构和设计理念有其独到之处,主要体现在轻量级、分组方式和对等结构三个方面。
FastDFS的存储策略
为了支持大容量,存储节点(服务器)采用了分卷(或分组)的组织方式。存储系统由一个或多个卷组成,卷与卷之间的文件是相互独立的,所有卷的文件容量累加就是整个存储系统中的文件容量。一个卷可以由一台或多台存储服务器组成,一个卷下的存储服务器中的文件都是相同的,卷中的多台存储服务器起到了冗余备份和负载均衡的作用。
在卷中增加服务器时,同步已有的文件由系统自动完成,同步完成后,系统自动将新增服务器切换到线上提供服务。当存储空间不足或即将耗尽时,可以动态添加卷。只需要增加一台或多台服务器,并将它们配置为一个新的卷,这样就扩大了存储系统的容量。
https://www.cnblogs.com/-yuanzheng/p/15185099.html
为什么海量存储选用大文件结构
1.大规模的小文件存取,磁头需要频繁的寻道和换道,因此在读取上容易带来较长的延时。
| 千兆网络发送 1MB 数据 | 10ms |
|---|---|
| 机房内网络 | 0.5ms |
| SATA 磁盘寻道 | 10ms |
| 从 SATA 磁盘顺序读取 1MB 数据 | 20ms |

2.频繁的新增删除操作导致磁盘碎片,降低磁盘利用率和IO读写效率。
3.Inode 占用大量磁盘空间,降低了缓存的效果。
TFS文件系统大文件结构
总体架构
一个TFS集群由两个NameServer节点(一主一备)和多个DataServer节点组成。这些服务程序都是作为一个用户级的程序运行在普通Linux机器上的。
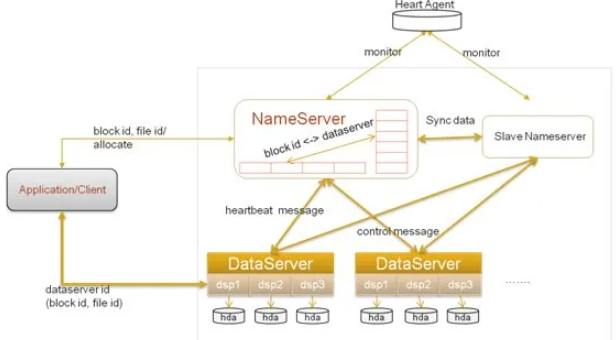
NameServer采用了HA结构,即两台机器互为热备,同时运行,一台为主,一台为备,主机绑定到对外vip,提供服务;当主机器宕机后,迅速将vip绑定至备份NameServer,将其切换为主机,对外提供服务。上图中的HeartAgent就完成了此功能。
HA(Highly Available),高可用性集群,是保证业务连续性的有效解决方案,一般有两个或两个以上的节点,且分为活动节点及备用节点。
通常把正在执行业务的称为活动节点,而作为活动节点的一个备份的则称为备用节点。当活动节点出现问题,导致正在运行的业务(任务)不能正常运行时,备用节点此时就会侦测到,并立即接续活动节点来执行业务。从而实现业务的不中断或短暂中断。
TFS的设计目标是海量小文件的存储,所以在TFS中,将大量的小文件(实际数据文件)合并成为一个大文件,这个大文件称为块(Block), 每个Block拥有在集群内唯一的编号(BlockId),Block Id在NameServer在创建Block的时候分配, NameServer维护block与DataServer的关系。Block中的实际数据都存储在 DataServer 上。而一台 DataServer 服务器一般会有多个独立 DataServer 进程存在,每个进程负责管理一个挂载点,这个挂载点一般是一个独立磁盘上的文件目录,以降低单个磁盘损坏带来的影响。
NameServer:管理维护 Block 和 DataServer 相关信息,包括 DataServer 加入,退出, 心跳信息, block 和 DataServer 的对应关系建立,解除。
正常情况下,一个块会在 DataServer 上存在, 主 NameServer 负责 Block 的创建,删除,复制,均衡,整理, NameServer不负责实际数据的读写,实际数据的读写由DataServer完成。
DataServer:负责实际数据的存储和读写。
TFS的块大小可以通过配置项来决定,通常使用的块大小为64M。TFS的设计目标是海量小文件的存储,所以每个块中会存储许多不同的小文件。DataServer进程会给Block中的每个文件分配一个ID(File ID,该ID在每个Block中唯一),并将每个文件在Block中的信息存放在和Block对应的Index文件中。这个Index文件一般都会全部存放在内存,除非出现DataServer服务器内存和集群中所存放文件平均大小不匹配的情况。
存储机制
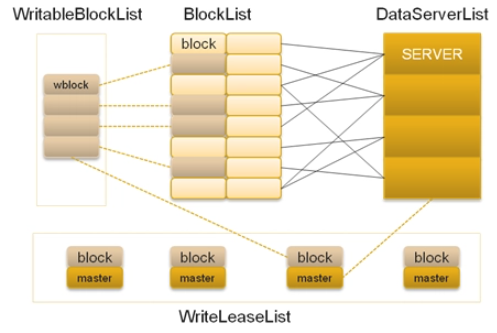
在TFS中,将大量的小文件(实际用户文件)合并成为一个大文件,这个大文件称为块(Block)。TFS以Block的方式组织文件的存储。每一个Block在整个集群内拥有唯一的编号,这个编号是由NameServer进行分配的,而DataServer上实际存储了该Block。在NameServer节点中存储了所有的Block的信息,一个Block存储于多个DataServer中以保证数据的冗余。对于数据读写请求,均先由NameServer选择合适的DataServer节点返回给客户端,再在对应的DataServer节点上进行数据操作。
NameServer需要维护Block信息列表,以及Block与DataServer之间的映射关系,其存储的元数据结构如下:
在DataServer节点上,在挂载目录上会有很多物理块,物理块以文件的形式存在磁盘上,并在DataServer部署前预先分配,以保证后续的访问速度和减少碎片产生。为了满足这个特性,DataServer现一般在EXT4文件系统上运行。
物理块分为主块和扩展块,一般主块的大小会远大于扩展块,使用扩展块是为了满足文件更新操作时文件大小的变化。
每个Block在文件系统上以“主块+扩展块”的方式存储。每一个Block可能对应于多个物理块,其中包括一个主块,多个扩展块。
在DataServer端,每个Block可能会有多个实际的物理文件组成:一个主Physical Block文件,N个扩展Physical Block文件和一个与该Block对应的索引文件。Block中的每个小文件会用一个block内唯一的fileid来标识。DataServer会在启动的时候把自身所拥有的Block和对应的索引文件加载进来。
容错机制
1.集群容错
TFS可以配置主辅集群,一般主辅集群会存放在两个不同的机房。主集群提供所有功能,辅集群只提供读。主集群会把所有操作重放到辅集群。这样既提供了负载均衡,又可以在主集群机房出现异常的情况不会中断服务或者丢失数据;
2.NameServer容错
Namserver 主要管理了 DataServer 和 Block 之间的关系。如每个 DataServer 拥有哪些 Block,每个 Block 存放在哪些DataServer 上等。同时,NameServer 采用了 HA 结构,一主一备,主 NameServer 上的操作会重放至备 NameServer。如果主 NameServer 出现问题,可以实时切换到备 NameServer;
另外 NameServer 和 DataServer 之间也会有定时的 heartbeat,DataServer 会把自己拥有的 Block 发送给 NameServer。NameServer 会根据这些信息重建 DataServe r和 Block 的关系;
3.DataServer容错
TFS 采用 Block 存储多份的方式来实现 DataServer 的容错。每一个 Block 会在 TFS 中存在多份,一般为 3 份,并且分布在不同网段的不同 DataServer上。对于每一个写入请求,必须在所有的 Block 写入成功才算成功。当出现磁盘损坏 DataServer 宕机的时候,TFS 启动复制流程,把备份数未达到最小备份数的 Block 尽快复制到其他 DataServer 上去。 TFS 对每一个文件会记录校验 crc,当客户端发现 crc 和文件内容不匹配时,会自动切换到一个好的 block 上读取。此后客户端将会实现自动修复单个文件损坏的情况。
并发机制
对于同一个文件来说,多个用户可以并发读;
现有TFS并不支持并发写一个文件。一个文件只会有一个用户在写。这在TFS的设计里面对应着是一个block同时只能有一个写或者更新操作。
平滑扩容
原有 TFS 集群运行一定时间后,集群容量不足,此时需要对 TFS 集群扩容。由于DataServer 与 NameServer 之间使用心跳机制通信,如果系统扩容,只需要将相应数量的新 DataServer 服务器部署好应用程序后启动即可。
这些 DataServer 服务器会向 NameServer 进行心跳汇报。NameServer 会根据 DataServer 容量的比率和 DataServer 的负载决定新数据写往哪台 DataServer 的服务器。根据写入策略,容量较小,负载较轻的服务器新数据写入的概率会比较高。同时,在集群负载比较轻的时候,NameServer会对 DataServer 上的 Block 进行均衡,使所有 DataServer 的容量尽早达到均衡。
在平滑扩容期间,对外的服务照常进行。对用户来说,并不会察觉到任何异常。
https://baike.baidu.com/item/TFS/5561187?fr=ge_ala
核心存储引擎设计
设计思路
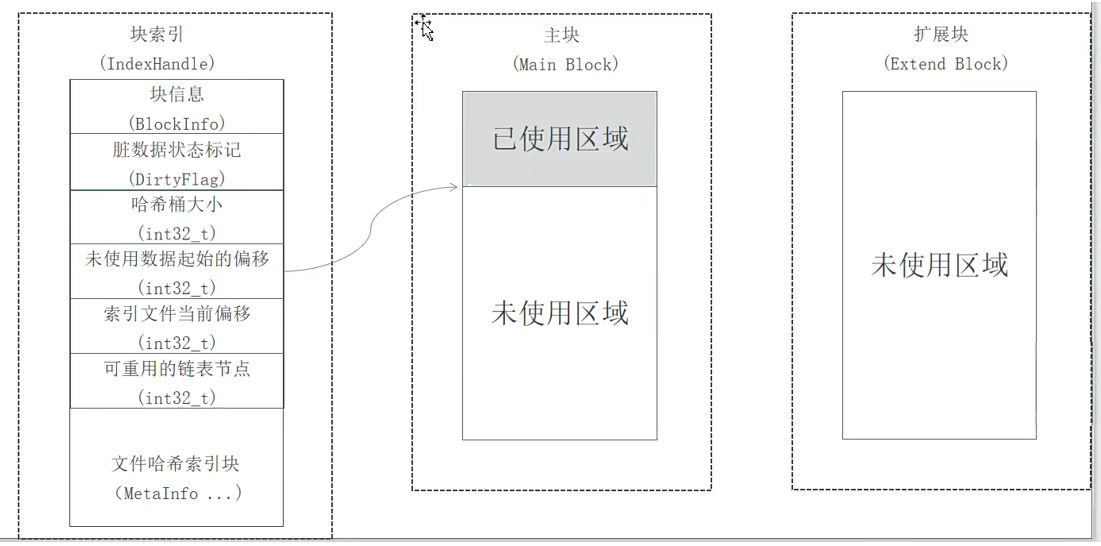
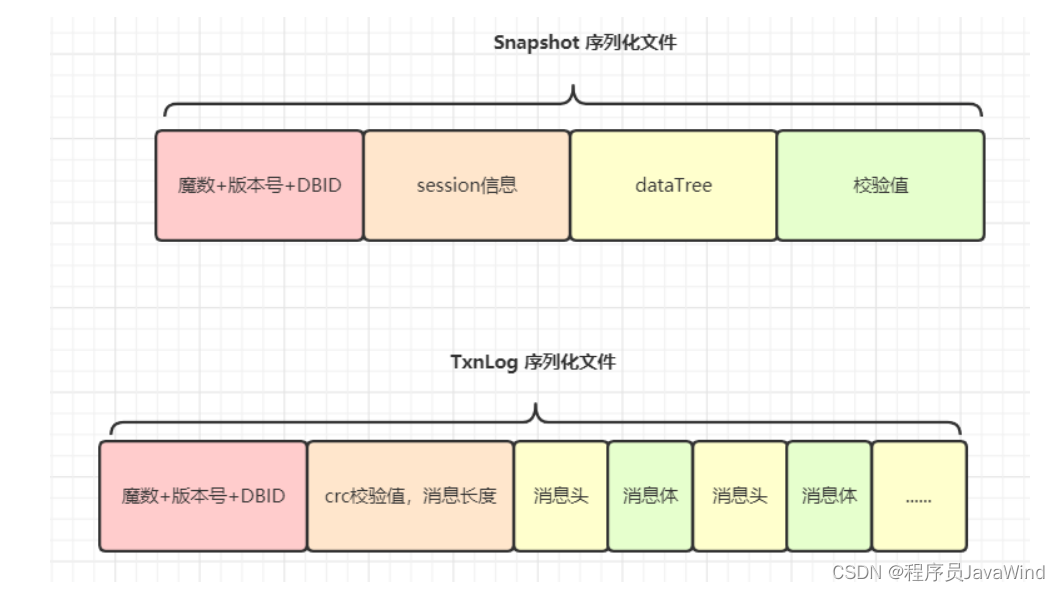
- 以block文件的形式存放数据文件(一般64M一个block),以下简称为“块”,每个块都有唯一的一个整数编号,块在使用之前所用到的存储空间都会预先分配和初始化;
- 每一个块由一个索引文件、一个主块文件和若干个扩展块组成,“小文件”主要存放在主块中,扩展块主要用来存放溢出的数据;
- 每个索引文件存放对应的块信息和“小文件”索引信息,索引文件会在服务启动时映射(mmap)到内存,以便极大的提高文件检索速度。“小文件”索引信息采用在索引文件中的数据结构哈希链表来实现;
- 每个文件有对应的文件编号,文件编号从1开始编号,依次递增,同时作为哈希査找算法的Key 来定位“小文件”在主块和扩展块中的偏移量。文件编号+块编号按某种算法可得到“小文件”对应的文件名。
大文件存储结构图
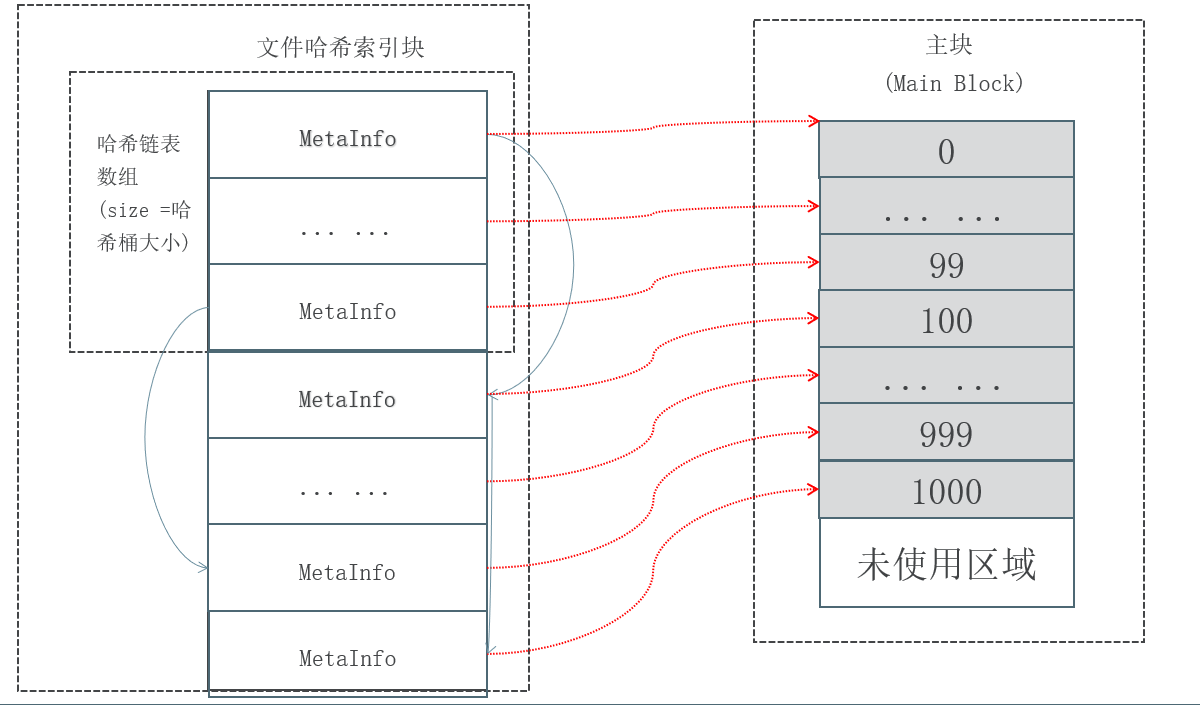
文件哈希链表实现图
哈希链表
正常的哈希链表头部是一个指针数组,数组中存放的是指针,指向该哈希桶的第一个元素。各节点中除了有存放 value 的变量,还有一个 next 指针,指向该桶的下一个元素。

每一个小文件就相当于哈希链表中的一个节点,每个小文件拥有一个 id 作为它的键唯一标识它,采用取余法作为哈希函数,即键 % 哈希桶数量 得到的就是哈希桶的数组索引,表示它储存在为该数组索引的哈希桶内。
程序序中的哈希链表都是通过指针链接的,指针中储存的是地址,而索引文件实现的哈希链表是通过储存在 int 变量里的文件偏移来链接的
文件映射
把硬盘数据搬到内存中去操作的方式被称为文件映射虚拟内存,由于内存访问的特殊性,数据到了内存后可提高访问和操作的速率。
场景:
1.进程间共享信息;
2.实现文件数据从磁盘到内存的映射,极大的提升应用程序访问文件的速度。
进程间通信-文件映射原理(mmap函数)
原理:将一个文件或者其他对象映射进内存。
1.使用普通文件提供的内存映射;
2.使用特殊文件提供的匿名内存映射。
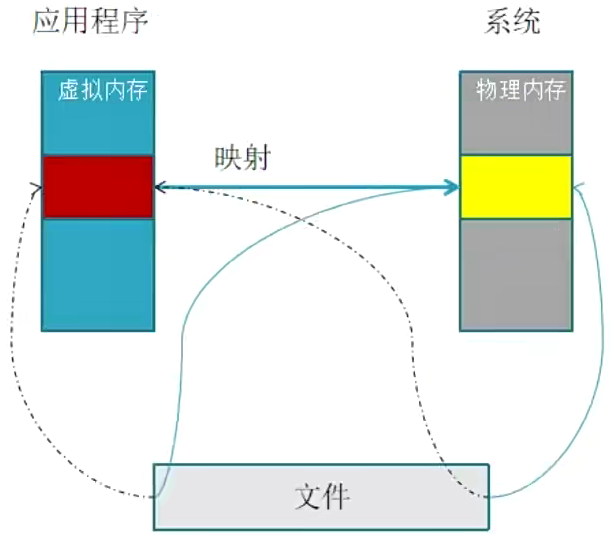
mmap()必须以PAGE_SIZE为单位进行映射,而内存也只能以页为单位进行映射,若要映射非PAGE_SIZE整数倍的地址范围,要先进行内存对齐,强行以PAGE_SIZE的倍数大小进行映射。
文件映射 mmap 接口
#include <sys/mman.h>
void* mmap(void* start,size_t length,int prot,int flags,int fd,off_t offset);
int munmap(void* start,size_t length);
参数 start:指向欲映射的内存起始地址,通常设为NULL,代表让系统自动选定地址,映射成功后返回该地址。
参数 length:代表将文件中多大的部分映射到内存。
参数prot:映射区域的保护方式。可以为以下几种方式的组合:
PROT EXEC 执行
PROT READ 读取
PROT WRITE 写入
PROT NONE 不能存取
参数flags:影响映射区域的各种特性。必须要指定MAP_SHARED或MAP_PRIVATE。
MAP_SHARED 映射区域数据与文件对应,允许其他进程共享;
MAP_PRIVATE 映射区域生成文件的copy,修改不同步文件;
MAP_ANONYMOUS 建立匿名映射。此时会忽略参数fd,不涉及文件,而且映射区域无法和其他进程共享;
MAP_DENYWRITE 允许对映射区域的写入操作,其他对文件直接写入的操作将会被拒绝;
MAP_LOCKED 将映射区域锁定住,这表示该区域不会被置swap。
参数fd:要映射到内存中的文件描述符。如果使用匿名内存映射时,即flags中设置了MAP_ANONYMOUS,fd设为-1。有些系统不支持匿名内存映射,则可以使用fopen打开/dev/zero文件,然后对该文件进行映射,可以同样达到匿名内存映射的效果。
参数offset:文件映射的偏移量,通常设置为0,代表从文件最前方开始对应,offset必须是分页大小的整数倍。
返回值
成功执行时,mmap()返回被映射区的指针,munmap()返回0。失败时,mmap()返回MAP_FAILED[其值为(void *)-1],munmap返回-1。
errno被设为以下的某个值:
EACCES:访问出错
EAGAIN:文件已被锁定,或者太多的内存已被锁定
EBADF:fd 不是有效的文件描述词
EINVAL:一个或者多个参数无效
ENFILE:已达到系统对打开文件的限制
ENODEV:指定文件所在的文件系统不支持内存映射
ENOMEM:内存不足,或者进程已超出最大内存映射数量
EPERM:权能不足,操作不允许
ETXTBSY:已写的方式打开文件,同时指定MAP_DENYWRITE标志
SIGSEGV:试着向只读区写入
SIGBUS:试着访问不属于进程的内存区
同步 msync
实现磁盘文件内容与共享内存区中的内容一致,即同步操作。
函数原型
int msync(void * addr,size_t len,int flags)
头文件
#include<sys/mman.h>
addr:文件映射到进程空间的地址;len:映射空间的大小;
flags:刷新的参数设置,可以取值MS_ASYNC/ MS_SYNC/ MS_INVALIDATE其中;
取值为MS_ASYNC(异步)时,调用会立即返回,不等到更新的完成;取值为MS_SYNC(同步)时,调用会等到更新完成之后返回;
返回值:成功则返回0;失败则返回-1;
系统函数
1.strerror()
函数声明: char * strerror ( int errnum );
头 文 件:#include <string.h>
返 回 值: 返回值为char * 类型 。指向描述错误错误的错误字符串的指针。
C语言的库函数在执行失败时,都会有一个错误码(0 1 2 3 4 5 6 7 8 9 …)
errno是C语言设置的一个全局错误码存放的变量,包含在头文件<errno.h>
https://blog.csdn.net/m0_65601072/article/details/125903755
2.fstat()
功能:由文件描述符取得文件的状态。
相关函数:stat、lstat、chmod、chown、readlink、utime。
头文件:#include <sys/stat.h> #include <unistd.h>
函数声明:int fstat (int filedes, struct stat *buf);
描述:fstat() 用来将参数filedes 所指向的文件状态复制到参数buf 所指向的结构中(struct stat), fstat() 与stat() 作用完全相同,不同之处在于传入的参数为已打开的文件描述符。
返回值:执行成功返回0,失败返回-1,错误代码保存在errno中。
https://blog.csdn.net/weixin_37926485/article/details/122804385
struct stat 这个结构体是用来描述linux系统中文件系统的文件属性的结构.
int stat(const char *path, struct stat *struct_stat);
int lstat(const char *path,struct stat *struct_stat);
两个函数的第一个参数都是文件的路径,第二个参数是struct stat的指针。返回值为0,表示成功执行。执行失败时,error被自动设置为相应的值。
3.fprintf()
函数声明:int fprintf (FILE* stream, const char*format, [argument])
参数:
stream– 这是指向 FILE 对象的指针,该 FILE 对象标识了流。
format– 这是 C 字符串,包含了要被写入到流 stream 中的文本。它可以包含嵌入的 format 标签,format 标签可被随后的附加参数中指定的值替换,并按需求进行格式化。format 标签属性是%[flags][width][.precision][length]specifier
[argument]:附加参数列表
功能:fprintf()函数根据指定的格式(format),向输出流(stream)写入数据(argument)。
函数说明:fprintf( )会根据参数format 字符串来转换并格式化数据,然后将结果输出到参数 stream 指定的文件中,直到出现字符串结束(‘\0’)为止。
4.explicit
explicit 关键字的作用就是防止单参类构造函数的隐式自动转换.
作用: 用来声明类构造函数是显示调用的,而非隐式调用,可以阻止调用构造函数时进行隐式转换。只可用于修饰单参构造函数,因为无参构造函数和多参构造函数本身就是显示调用的,再加上 explicit 关键字也没有什么意义。
5.ftruncate
int ftruncate(int fd,off_t length);
功能:将参数 fd 指定的文件大小改为参数 length 指定的大小。
参数 fd 为已打开的文件描述词,而且必须是以写入模式打开的文件。如果原来的文件大小比参数length大,则超过的部分会被删去。
返回值:执行成功则返回 0,失败返回 -1,错误原因存于errno。
6.strdup
c 语言中常用的一种字符串拷贝库函数,一般和 free( ) 函数成对出现
#include <string.h>
extern char *strdup(char *s);
功能:将字符串拷贝到新建的位置处;
strdup( )在内部调用了malloc( )为变量分配内存,不需要使用返回的字符串时,需要用free( )释放相应的内存空间,否则会造成内存泄漏。
返回值:返回一个指针,指向为复制字符串分配的空间;如果分配空间失败,则返回NULL值。
7.free
free()是C语言中释放内存空间的函数,通常与申请内存空间的函数malloc()结合使用,可以释放由 malloc()、calloc()、realloc() 等函数申请的内存空间。
void free(void *ptr)
ptr-- 指针指向一个要释放内存的内存块,该内存块之前是通过调用 malloc、calloc 或 realloc 进行分配内存的。如果传递的参数是一个空指针,则不会执行任何动作。
8.open
在对文件进行读写操作之前,先要打开文件。
open() 函数是 C/C++ 标准库中的一个 POSIX 标准函数,用于打开一个文件并返回一个文件描述符(File Descriptor)以供后续的读写操作,其函数声明如下:
#include <fcntl.h>
int open(const char* path, int flags, mode_t mode);
参数:第二个参数 flags 是一个掩码,用于指定打开文件时所使用的访问模式和选项。
O_RDONLY:以只读模式打开文件。相应的文件必须存在,否则打开操作会失败。
O_WRONLY:以只写模式打开文件。相应的文件必须存在,否则打开操作会失败。
O_RDWR:以读写模式打开文件。相应的文件必须存在,否则打开操作会失败。
O_CREAT:如果指定的文件不存在,则创建一个新的文件。如果文件已经存在,则不执行任何操作。需要指定文件的访问权限,通常使用权限掩码 S_IRUSR | S_IWUSR | S_IRGRP | S_IWGRP | S_IROTH,表示用户、用户组和其他用户都有读写权限。
O_TRUNC:如果文件已经存在,则将该文件的长度截短至零字节。如果文件不存在,则忽略该选项。
O_APPEND:打开文件时,将文件偏移量设置为文件末尾。在写入文件时,所有的数据都将被写入到文件的末尾,而不是覆盖文件中已有的数据。
flags 参数可以通过 | 运算符进行组合,以选择需要的访问模式和选项。
返回值:成功返回文件描述符可以用于后续的读写操作;如果打开文件失败,open() 函数将返回 -1,这时需要根据 errno 变量的值来确定错误的原因,并采取必要的补救措施。
9.close
调用 open() 方法打开文件,是文件流对象和文件之间建立关联的过程。
那么,调用 close() 方法关闭已打开的文件,就可以理解为是切断文件流对象和文件之间的关联。
注意,close() 方法的功能仅是切断文件流与文件之间的关联,该文件流并会被销毁,其后续还可用于关联其它的文件。
#include <unistd.h>
int close(int fd)
参数:fd文件描述符
函数返回值:0成功,-1出错
10.fsync
fsync 函数只对由文件描述符filedes指定的单一文件起作用,并且等待写磁盘操作结束,然后返回。可用于数据库这样的应用程序,这种应用程序需要确保将修改过的块立即写到磁盘上。
描述:将数据从操作系统的缓存写入磁盘;
fsync的主要作用是确保数据的持久性和可靠性。在某些情况下,数据仅存储在操作系统的缓存中,并没有写入磁盘。这可能导致以下几个问题:
数据丢失: 在发生系统崩溃或意外断电等情况下,缓存中的数据可能会丢失,而没有写入磁盘。这将导致数据的不可恢复性。
数据损坏: 在写入磁盘之前,缓存中的数据可能已经被修改或损坏。如果数据损坏,将无法正确恢复数据。
数据不一致: 如果缓存中的文件数据和元数据不同步,可能导致文件系统的一致性问题。这可能会在系统恢复后导致文件数据的丢失或破坏。
11.unlink
unlink() 函数功能即为删除文件。执行 unlink() 函数会删除所给参数指定的文件。
#include<unistd.h>
int unlink(const char *pathname);
执行unlink()函数并不一定会真正的删除文件,它先会检查文件系统中此文件的连接数是否为1,如果不是1说明此文件还有其他链接对象,因此只对此文件的连接数进行减1操作。若连接数为1,并且在此时没有任何进程打开该文件,此内容才会真正地被删除掉。在有进程打开此文件的情况下,则暂时不会删除,直到所有打开该文件的进程都结束时文件就会被删除。
返回值:成功返回0,失败返回 -1
12.pread
pread()不更新文件指针
read 调用会改变文件指针
Ssize_t pread(int fd,void *buf,size_t nbytes,off_t offset);
参数:
(1) fd:要读取数据的文件描述符
(2) buf:数据缓存区指针,存放读取出来的数据
(3) nbytes:要读取数据的字节大小
(4) offset:读取的起始地址的偏移量,读取地址=文件开始+offset。注意,执行后,文件偏移指针不变
调用 pread 相当于调用 lseet 后再调用 read 函数,其区别是调用 pread 时无法中断其定位和读操作
13.pwrite
ssize_t pwrite(int fd, const void *buf, size_t count, off_t offset);
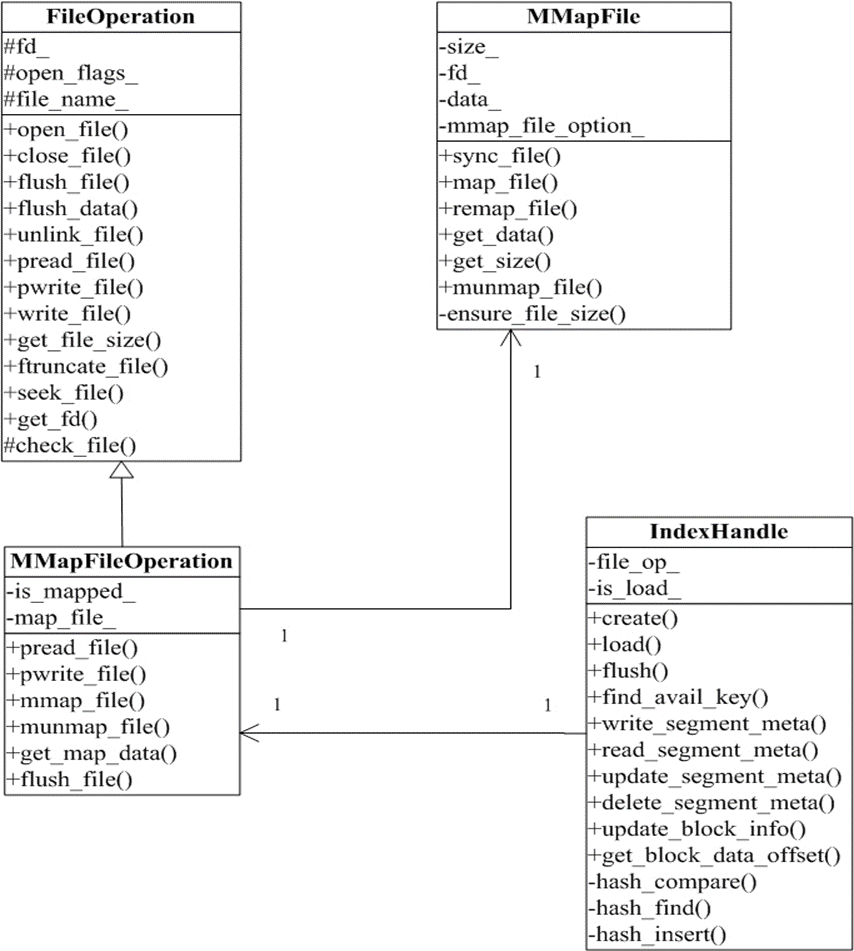
设计类图
源码实现
关键结构
块文件信息结构体
用来记录块文件信息,每一个主块文件对应一个块id,对应一个块文件信息结构体。
struct BlockInfo{
int block_id_ = 0; //块文件编号1......2^32-1 TFS = NameServer + DataServer
int version_; //块版本号
int file_count_; //当前已保存文件总数
int size_; //当前已保存文件数据总大小
int del_file_count_; //已删除的文件数量
int del_size_; //已删除的文件数据总大小
int seq_no_; //下一个可分配的文件编号 1......2^64 -1
};
索引信息结构体
struct IndexHeade{
BlockInfo block_info_; //块信息,储存主块的信息,每一个主块文件有且只有一个索引文件
int bucket_size_ = 0; //哈希桶大小,储存哈希桶个数
int data_file_offset_; //储存主块文件已使用空间的偏移
int index_file_size_; //储存索引文件可用来储存小块文件的起始位置
int free_head_offset_; //储存可重用的链表节点个数
};
小文件信息结构体
记录主块文件中的小文件在主块文件中的起始偏移的结构体,并且作为哈希链表中的链表节点使用。
struct MetaInfo{
int fileid_; //块id
struct{
int inner_offset_; //记录小文件在主块文件中的起始偏移
int size_; //小文件大小
} location_;
int next_mate_offset_; //记录在同一个哈希桶中的下一个小文件结构体的偏移量,类似于链表中的next指针
};
因为索引文件是要进行内存映射的,并且映射内存区与索引文件保存一致,所以各种数据的相对位置在索引文件中与在映射内存区是一样的。对索引文件的修改会同步到对应的内存中。对内存的修改也会同步到索引文件中。
每当在主块文件中储存一个小文件时,都应该创建一个MeatInfo结构体标识该小文件,并且初始化它的各项参数。同时应该将这个结构体插入哈希链表中,即储存在该主块文件对应的索引文件中。
索引文件头部储存的是索引信息结构体,接下来应该储存哈希桶索引。哈希桶索引之后是小文件信息结构体。
内存映射类 MMapFile
功能:实现内存映射的相关操作,封装内存映射相关函数。
class MMapFile
{
public:
// 无参构造函数
MMapFile();
// 防止隐式转换
explicit MMapFile(const int fd);
MMapFile(const MMapOption &mmap_options, const int fd);
~MMapFile();
// 同步文件
bool sync_file();
// 将文件映射到内存,同时设置访问权限:默认不可写
bool map_file(const bool write = false);
// 获取映射到内存数据的首地址
void *get_data() const;
// 获取映射数据的大小
int32_t get_size() const;
// 解除映射
bool munmap_file();
// 重新执行内存映射(常用来扩容)
bool remap_file();
private:
// 调整以后的大小,扩容,(扩容的新大小:new_size)
bool ensure_file_size(const int32_t new_size);
private: // 私有后面加_
int32_t size_;
int fd_;
void *data_;
struct MMapOption mmap_file_option_;
};
文件操作类 FileOperation
功能:实现文件的基本操作,作为文件映射操作类的基类。
class FileOperation
{
public:
// 构造函数 O_LARGEFILE:操作大文件
FileOperation(const std::string &file_name, const int open_flags = O_RDWR | O_LARGEFILE);
~FileOperation();
// 打开文件
int open_file();
// 关闭文件
void close_file();
// 把文件立即写入磁盘中
int flush_file();
// 把文件删除
int unlink_file();
// 内存映射实战值文件操作cpp实现(中)
// 读(有偏移量)
virtual int pread_file(char *buf, int32_t nbytes, const int64_t offset);
// 写(有偏移量)
virtual int pwrite_file(const char *buf, int32_t nbytes, const int64_t offset);
// 直接写(无偏移量)
int write_file(const char *buf, int32_t nbytes);
// 获取文件的大小
int64_t get_file_size();
// 截断文件,文件太大了,我要缩小一下
int ftruncate_file(const int64_t length);
// 从文件中进行移动 , offset偏移量
int seek_file(const int64_t offset);
// 获取文件描述符,文件句柄
int get_fd() const
{
return fd_;
}
protected:
// 文件描述符,文件句柄
int fd_;
// 怎么打开,可读?可写?
int open_flags_;
// 文件名
char *file_name_;
protected:
// 允许文件在没有正式开始之前打开
int check_file();
protected:
static const mode_t OPEN_MODE = 0644; // 权限
static const int MAX_DISK_TIMES = 5; // 操作系统超过五次失败就不读了
};
pread_file 函数
// 读(有偏移量)
int FileOperation::pread_file(char *buf, int32_t nbytes, const int64_t offset)
{
// ssize_t pread(int fd, void *buf, size_t count, off_t offset);
// ssize_t pread64(int fd, void *buf, size_t count, off64_t offset);//大文件读
// buf:是一个指向存储读取数据的缓冲区的指针;
// offset:表示从文件的哪个位置开始读取数据。
char *p_tmp = buf; // p_tmp指针是用于存储读取到的数据的缓冲区起始地址。
int32_t left = nbytes; // 剩余的字节数
int64_t read_offset = offset; // read_offset参数表示从文件的哪个位置开始读取数据。
int32_t read_len = 0; // 已读的长度
int i = 0;
while (left > 0)
{
i++; // 读的次数
if (i >= MAX_DISK_TIMES)
{
// 超过5次都没读成功,就不再读了
break;
}
if (check_file() < 0)
{
return -errno;
}
read_len = ::pread64(fd_, p_tmp, left, read_offset);
if (read_len < 0) // 没读到,读取错误
{
read_len = -errno;
// 在多线程下,errno在不断的更改,但是read_len不会变
if (-read_len == EINTR || EAGAIN == -read_len) // EINTR临时中断,EAGAIN系统让我们继续尝试
{
continue;
}
else if (EBADF == -read_len) // 文件描述符已经变坏了
{
fd_ = -1;
return read_len;
}
else
{
return read_len;
}
}
else if (0 == read_len) // 如果文件刚好读到尾部了
{
break; // 已经读完
}
// 在每次读取后,需要将缓冲区指针buf重新指向新的缓冲区,并将偏移量offset更新为当前位置
/*
虽然这两个参数都涉及到缓冲区和偏移量,但是它们的作用却有所不同。
buf参数主要用于指向待填充的缓冲区,而offset参数主要用于指定读取数据的起始位置。
在多次读取时,这两个参数都需要不断更新,以确保在正确的位置读取和存储数据。
*/
// pread()在每次读完后,需要更新buf和offset,但是read()只需要更新buf
// read_len = ::pread64(fd_, p_tmp, left, read_offset);
left -= read_len; // 剩余的字节数
p_tmp = p_tmp + read_len; // 文件的起始地址//这行可以注释,在读的时候不必改变文件起始位置
read_offset += read_len; // 文件偏移量
}
if (0 != left)
{
// 没有达到预期
return EXIT_DISK_OPER_INCOMPLETE;
}
return TFS_SUCCESS; // 成功
}
pwrite 函数
// 写(有偏移量)
int FileOperation::pwrite_file(const char *buf, int32_t nbytes, const int64_t offset)
{
// ssize_t pwrite(int fd, const void *buf, size_t count, off_t offset);
// ssize_t pwrite64(int fd, const void *buf, size_t count, off64_t offset);//大文件写
const char *p_tmp = buf; // p_tmp指针是用于存储写到的数据的缓冲区起始地址。
int32_t left = nbytes; // 剩余的字节数
int64_t write_offset = offset; // write_offset参数表示从文件的哪个位置开始写数据。
int32_t write_len = 0; // 已写的长度
int i = 0;
while (left > 0)
{
i++; // 读的次数
if (i >= MAX_DISK_TIMES)
{
// 超过5次都没读成功,就不再读了
break;
}
if (check_file() < 0)
{
return -errno;
}
write_len = ::pwrite64(fd_, p_tmp, left, write_offset);
if (write_len < 0) // 没写到,有错误
{
write_len = -errno;
// 在多线程下,errno在不断的更改,但是read_len不会变
if (-write_len == EINTR || EAGAIN == -write_len) // EINTR临时中断,EAGAIN系统让我们继续尝试
{
continue;
}
else if (EBADF == -write_len) // 文件描述符已经变坏了
{
fd_ = -1;
continue;
}
else
{
return write_len;
}
}
left -= write_len; // 剩余的字节数
p_tmp = p_tmp + write_len; // 文件的起始地址
write_offset += write_len; // 文件偏移量
} /*while循环*/
if (0 != left)
{
// 没有达到预期
return EXIT_DISK_OPER_INCOMPLETE;
}
return TFS_SUCCESS; // 成功
}
// 直接写(无偏移量)
int FileOperation::write_file(const char *buf, int32_t nbytes)
{
const char *p_tmp = buf; // p_tmp指针是用于存储写到的数据的缓冲区起始地址。
int32_t left = nbytes; // 剩余的字节数
int32_t write_len = 0; // 已写的长度
int i = 0;
while (left > 0)
{
++i;
if (i >= MAX_DISK_TIMES)
{
break;
}
if (check_file() < 0)
{
return -errno;
}
write_len = ::write(fd_, p_tmp, left);
if (write_len < 0) // 没写到,有错误
{
write_len = -errno;
// 在多线程下,errno在不断的更改,但是read_len不会变
if (-write_len == EINTR || EAGAIN == -write_len) // EINTR临时中断,EAGAIN系统让我们继续尝试
{
continue;
}
else if (EBADF == -write_len) // 文件描述符已经变坏了
{
fd_ = -1;
continue;
}
else
{
return write_len;
}
}
left -= write_len;
p_tmp += write_len;
}
if (0 != left)
{
// 没有达到预期
return EXIT_DISK_OPER_INCOMPLETE;
}
return TFS_SUCCESS; // 成功
}
文件内存映射操作类 MMapFileOperation
文件内存映射操作类继承自文件操作类,所以它拥有文件操作类的基本方法。并且持有一个内存映射类指针,用来进行内存映射。
它的主要功能是可以借助内存映射指针完成指定文件的内存映射。并且能使用继承自父类的方法读取文件内数据与往文件内写入数据。
class MMapFileOperation : public FileOperation // 文件映射操作类
{
public:
// MMapFileOperation构造函数,用父类构造函数去初始化file_name与open_flags
MMapFileOperation(const std::string &file_name,
const int open_flags = O_CREAT | O_RDWR | O_LARGEFILE) : FileOperation(file_name, open_flags),
map_file_(NULL), is_mapped_(false)
{
}
// 析构函数
~MMapFileOperation()
{
if (map_file_)
{
delete (map_file_);
map_file_ = NULL;
}
}
// 重新实现
int pread_file(char *buf, const int32_t size, const int64_t offset);
int pwrite_file(const char *buf, const int32_t size, const int64_t offset);
int mmap_file(const MMapOption &mmap_option);
int munmap_file();
void *get_map_data() const;
int flush_file();
private:
MMapFile *map_file_; // 映射文件
bool is_mapped_; // 是否已经映射
};
文件内存映射操作类的基本用法:首先实例化一个对象,它的构造函数需传入文件名与打开文件时的选项,如果带上O_CREAT选项则表示若此文件不存在则创建它。然后调用mmap_file()函数,该函数会对文件操作符fd_进行检测,如果它不是一个合法的值,则重新打开文件,给fd_赋值,确保fd_是一个合法值。然后该函数会检测实例化的对象持有的内存映射类指针是否是一个合法值,如果不是则实例化一个内存映射类对象并进行内存映射。如果是合法值则返回。
完成了文件的内存映射后,就可以读取文件数据或者往文件中写入数据。因为进行内存映射时设置的参数是保持文件与内存映射内存区的同步,所以对文件的修改会同步到对应的内存中。对内存的修改也会同步到文件中。
索引处理类 IndexHandle
持有文件内存映射操作类指针,用来进行文件的内存映射,文件读写等功能。
实际上我们生成索引文件所需要的所有操作都只需要一个索引处理类对象就能完成。
// index_hanle.h
#include "common.h"
#include "mmap_file_op.h"
namespace feng
{
namespace largefile
{
// 块索引头部
struct IndexHeader
{
public:
// 构造函数
IndexHeader()
{
memset(this, 0, sizeof(IndexHeader));
}
// 块信息
BlockInfo block_info;
// 脏数据状态标记暂时用不到
// 确定哈希桶的大小
int32_t bucket_size;
// 未使用数据起始的偏移量
int32_t data_file_offset; ///块数据的偏移,起始是0/
// 索引文件的当前偏移
int32_t index_file_size;
// 可重用的链表节点链表的链头,他们指向了文件哈希索引块
int32_t free_head_offset;
};
// 索引处理类
class IndexHandle
{
public:
IndexHandle(const std::string &base_path, const uint32_t main_block_id);
~IndexHandle();
// remove index:unmmap and unlink file
int remove(const uint32_t logic_block_id);
int flush();
//初始化 IndexHeader 结构体的各种属性,并把它加载到索引文件中
int create(const uint32_t logic_block_id,
const int32_t bucket_size,
const MMapOption map_option);
//检测各项属性是否正确,进行内存映射。
int load(const uint32_t logic_block_id,
const int32_t bucket_size,
const MMapOption map_option);
IndexHeader *index_header()
{
return reinterpret_cast<IndexHeader *>(file_op_->get_map_data());
}
// 更新块信息
int update_block_info(
const OperType oper_type, // 更新的类型
const uint32_t modify_size // 更新的长度
); // 更新块信息
// 从file_op_中获取映射信息
BlockInfo *block_info()
{
return reinterpret_cast<BlockInfo *>(file_op_->get_map_data());
}
// 返回这个桶这个数组的首节点
int32_t *bucket_slot()
{
// 因为已经映射到内存了
// 保存到文件的同时,还映射到了内存
// 在mmap内存映射中,映射到的内存是指系统内存,而不是磁盘内存。
// 系统内存(也称为随机访问存储器或RAM)和磁盘内存(也称为永久存储器或硬盘)是计算机中两种不同的存储介质
// 区别:
// 1.访问速度:系统内存的访问速度比磁盘内存快得多。
// 2.系统内存用于临时存储和处理数据
// 首先拿到映射的数据
return reinterpret_cast<int32_t *>(reinterpret_cast<char *>(file_op_->get_map_data()) + sizeof(IndexHeader));
}
// 得到桶大小
int32_t bucket_size() const
{
return reinterpret_cast<IndexHeader *>(file_op_->get_map_data())->bucket_size;
}
// 得到块数据的偏移量
int32_t get_block_data_offset()
{
return reinterpret_cast<IndexHeader *>(file_op_->get_map_data())->data_file_offset;
}
void commit_block_data_offset(const int file_size)
{
reinterpret_cast<IndexHeader *>(file_op_->get_map_data())->data_file_offset += file_size;
}
int32_t free_head_offset() const
{
return reinterpret_cast<IndexHeader *>(file_op_->get_map_data())->free_head_offset;
}
/*
reinterpret_cast是C++中的一种类型转换操作符,它允许您将一种类型的指针转换为任何其他类型 的指针,而不管这些类型是否相关。这种类型的转换被认为是所有类型转换操作中最强大和最危险的,因为它允许您将一种类型的对象转换为另一种类型的对象,而不管这两种类型是否兼容。
//这意味着如果使用不当,reinterpret_cast可能导致未定义的行为,因此应谨慎使用。
一般使用这种类型的强转,都是自信且强大的程序员,把轻松留给程序,把危险留给自己,为reinterpret_cast点赞!
*/
// 为响应block_write_test.cpp的号召,定义了一个api,专门写入metaInfo的
// 将节点写入索引文件
int write_segment_meta(const uint64_t key, MetaInfo &meta);
// 根据文件id读meta_info
// 从索引文件中找到节点
int read_segment_meta(const uint64_t key, MetaInfo &meta);
// 根据文件id删除meta_info
// 删除索引文件中节点。
int delete_segment_meta(const uint64_t key);
// 为响应index_handle.cpp的号召,我们定义一个api,从文件哈希表中查找key是否存在
// 最好能找到当前的偏移量current_offset和之前的偏移量previous_offset
// 哈希查找,在索引文件中找到键值为 key(key 作为形参在函数调用时传入) 的节点
int hash_find(const uint64_t key, int32_t ¤t_offset, int32_t &previous_offset);
//在索引文件中插入键值为 key 的节点
// 搞一个hash_insert(meta,slot,previous_offset)去插入(slot就是他要插入的哪个桶)
int32_t hash_insert(const uint64_t key, int32_t previous_offset, MetaInfo &meta);
private:
//比较 key 值是否与当前结构体 key 值一样(该函数第一个参数为 key 值,第二个参数为 MetaInfo 结构体)
bool hash_compare(const uint64_t left_key, const uint64_t right_key)
{
return (left_key == right_key);
}
MMapFileOperation *file_op_;
bool is_load_;
};
}
}
hash_find()
int hash_find(const int key, int& current_offset, int& previous_offset);
主要用于在哈希链表中查找节点,它接收三个参数,第一个是要查找节点的 key 值,第二个是储存要查找的节点在索引文件中的偏移,第三个是储存要查找节点的上一个节点在索引文件中的偏移(因为我们操作的是哈希链表,所以获得要操作的节点的上一个节点是很有必要的)。
int IndexHandle::hash_find(const uint64_t key, int32_t ¤t_offset, int32_t &previous_offset)
{
int ret = TFS_SUCCESS;
MetaInfo meta_info;
// 先清0
current_offset = previous_offset = 0;
// 根据键找到哪个桶
// 存在哪个桶是吧!这个桶也叫slot
// 1.确定key存放的桶(slot)的位置
int32_t slot = static_cast<uint32_t>(key) % bucket_size(); // 就这么简单即可知道是哪个桶
// 这要怎么读?我们定义一个函数int32_t* bucket_slot()返回这个桶这个数组的首节点
// 来,我们得到第一个节点的位置;
// 2.读取桶首节点存储的第一个节点的偏移量;如果偏移量为0,直接返回(EXIT_META_NOT_FOUND_ERROR)key不存在
// 3.再根据偏移量读取存储的metainfo
// 4.与key比较,是不是我们要的key,相等就设置current_offset与previous_offset并返回TFS_SUCCESS;
// 否则,继续执行5
// 5.从metainfo中取得下一个节点在文件中的偏移量;如果偏移量为0,直接返回(EXIT_META_NOT_FOUND_ERROR)key不存在,
// 否则跳转到3继续执行
int32_t pos = bucket_slot()[slot]; // bucket_slot 返回通这个数组的首届点,这种写法很高级
// 因为是数组,要遍历,这节点的key是不是你要的key
for (; pos != 0;)
{
// 读
ret = file_op_->pread_file(reinterpret_cast<char *>(&meta_info), sizeof(MetaInfo), pos);
if (TFS_SUCCESS != ret)
{
return ret;
}
// 哈希比较
if (hash_compare(key, meta_info.get_key()))
{
current_offset = pos; //用current_offset储存要查找节点的偏移
return TFS_SUCCESS; //查找成功,返回
}
previous_offset = pos; // pos变为上一个节点,保存当前节点的上一个节点的文件偏移
pos = meta_info.get_next_meta_offset(); // 读取下一个节点
}
return EXIT_META_NOT_FOUND_ERROR;
}
hash_insert()
int hash_insert(const int slot, const int previous_offset, const MetaInfo& meta);
如果要插入一个节点,首先会先查找该节点是否存在在哈希链表内,如果存在则不用再次插入,如果不存在则插入。所以在执行 hash_insert() 方法之前会先调用 hash_find() 方法进行查找,然后根据hash_find() 方法的返回值决定怎么继续执行。
hash_find() 方法与hash_insert() 方法结合起来使用可以实现将新的小文件信息结构体写入索引文件。
这个函数接收三个参数,第一个是哈希索引,第二个在是执行 hash_find() 方法后储存在 previous_offset 中的要查找节点的上一个节点的值。如果它为零则证明当前哈希桶没有元素。不为零则可以用来链接节点。第三个参数接收要插入的小文件信息结构体。
int32_t IndexHandle::hash_insert(const uint64_t key, int32_t previous_offset, MetaInfo &meta)
{
int ret = TFS_SUCCESS;
MetaInfo tmp_meta_info; // tmp表示临时变量
int32_t current_offset = 0;
// 1.确定key 存放的桶(slot)的位置
int32_t slot = static_cast<uint32_t>(key) % bucket_size();
// 2.确定meta 节点存储在文件中的偏移量
if (free_head_offset() != 0) // 有可重用的节点
{
// tmp_meta_info传入传出参数
ret = file_op_->pread_file(reinterpret_cast<char *>(&tmp_meta_info),
sizeof(MetaInfo),
free_head_offset());
if (TFS_SUCCESS != ret)
{
return ret;
}
current_offset = index_header()->free_head_offset;
if (debug)
{
std::cout << "///" << std::endl;
std::cout << "current_offset:" << current_offset << ",index_header()->free_head_offset:" << index_header()->free_head_offset << std::endl;
printf("Reuse metainfo, current_offset: %d\n", current_offset);
}
index_header()->free_head_offset = tmp_meta_info.get_next_meta_offset();
}
else // 没有可重用的节点
{
current_offset = index_header()->index_file_size;
index_header()->index_file_size += sizeof(MetaInfo); // 指向下一个可以希尔MetaInfo的位置
}
// 3.将meta 节点写入索引文件中
meta.set_next_meta_offset(0);
// 写入
ret = file_op_->pwrite_file(reinterpret_cast<const char *>(&meta),
sizeof(MetaInfo),
current_offset);
if (TFS_SUCCESS != ret)
{
// 写出错
// 回滚,index_file_size没有被利用
index_header()->index_file_size -= sizeof(MetaInfo);
return ret;
}
// 4. 将meta 节点插入到哈希链表中
// 前一个节点已经存在
if (0 != previous_offset)
{
ret = file_op_->pread_file(reinterpret_cast<char *>(&tmp_meta_info),
sizeof(MetaInfo),
previous_offset);
if (TFS_SUCCESS != ret)
{
// 读出错
// 回滚,index_file_size没有被利用
index_header()->index_file_size -= sizeof(MetaInfo);
return ret;
}
tmp_meta_info.set_next_meta_offset(current_offset);
ret = file_op_->pwrite_file(reinterpret_cast<const char *>(&tmp_meta_info), sizeof(MetaInfo), previous_offset);
if (TFS_SUCCESS != ret)
{
// 写出错
// 回滚,index_file_size没有被利用
index_header()->index_file_size -= sizeof(MetaInfo);
return ret;
}
}
else
{ // 不存在前一个节点的情况
// 直接就是首节点
bucket_slot()[slot] = current_offset;
}
return TFS_SUCCESS;
}
write_segment_meta()
int write_segment_meta(const int key, const MetaInfo& meta);
将小文件信息结构体写入索引文件,其实就是实现了 hash_find() 与hash_insert() 两个方法的整合。
// 为响应block_write_test.cpp的号召,我们定义了一个api,专门写入metaInfo的
int IndexHandle::write_segment_meta(const uint64_t key, MetaInfo &meta)
{
// 他当前偏移量时哪里,这两个变量对于hash_find来说,就是传入传出参数
int32_t current_offset = 0, previous_offset = 0; // 他前一个偏移是哪里
// 偏移量肯定是从0开始查
// 实现metaInfo的写入
// 1.第一步,我们要查这个key存在吗?
// 存在就不能写了,写就覆盖啦!不存在才可以写
// 核心的步骤:你要查找:从文件哈希表中查找key是否存在
// 定义一个哈希find(hash_find(key,current_offset,previous_offset))去查存不存在,啊!
// 2.第二步,如果不存在,就写入meta到哈希表中,
// hash_insert(slot, previous_offset, meta);去插入(slot就是他要插入的哪个桶)
int ret = hash_find(key, current_offset, previous_offset);
if (TFS_SUCCESS == ret) // 找到了,就不能写入了,写入了就把原来的给覆盖掉了
{
return EXIT_META_UNEXPECT_FOUND_ERROR;
}
else if (EXIT_META_NOT_FOUND_ERROR != ret)
{
return ret;
}
// 2.没找到、不存在就写入meta 到文件哈希表中
// hash_insert(key, previous_offset, meta);
ret = hash_insert(key, previous_offset, meta);
return ret;
}
read_segment_meta()
int IndexHandle::read_segment_meta(const int key, MetaInfo& meta);
该函数的功能是读出指定节点,通过 hash_find() 方法可以很容易实现。
// 根据文件id读meta_info
int IndexHandle::read_segment_meta(const uint64_t key, MetaInfo &meta)
{
int32_t current_offset = 0, previous_offset = 0;
// 1.确定key 存放的桶(slot)的位置
// int32_t slot = static_cast<uint32_t>(key) % bucket_size();
int32_t ret = hash_find(key, current_offset, previous_offset);
if (TFS_SUCCESS == ret) // exist
{
ret = file_op_->pread_file(reinterpret_cast<char *>(&meta),
sizeof(MetaInfo),
current_offset);
return ret;
}
else
{
return ret;
}
}
int dalete_segment_meta()
int dalete_segment_meta(const int key);
删除指定节点的函数.
// 根据文件id删除meta_info
int IndexHandle::delete_segment_meta(const uint64_t key)
{
int32_t current_offset = 0, previous_offset = 0;
int32_t ret = hash_find(key, current_offset, previous_offset);
if (ret != TFS_SUCCESS)
{
return ret;
}
// 它的上一个节点指向它的下一个节点,就把他删掉了
// 上一个节点已经知道了previous_offset,现在我们要找下一个节点
MetaInfo meta_info;
// 读取当前节点
ret = file_op_->pread_file(reinterpret_cast<char *>(&meta_info),
sizeof(MetaInfo),
current_offset);
if (TFS_SUCCESS != ret)
{
return ret;
}
else
{
if (debug)
{
std::cout << "读取成功!!!!!!!!!!!!!!!!!!!!!!!!!!!!!" << std::endl;
}
}
// 通过meta_info找到当前节点的下一个节点
int32_t next_pos = meta_info.get_next_meta_offset();
if (previous_offset == 0) // 前面没有节点了.它就是首节点,我们要删除首节点
{
int32_t slot = static_cast<uint32_t>(key) % bucket_size();
bucket_slot()[slot] = next_pos; // 找到槽,让槽指向它的下一个节点
}
else
{
MetaInfo pre_meta_info;
// 读取当前节点的上一个节点,pre_meta_info是传入传出参数
ret = file_op_->pread_file(reinterpret_cast<char *>(&pre_meta_info),
sizeof(MetaInfo),
previous_offset);
if (TFS_SUCCESS != ret)
{
return ret;
}
// 上一个节点链上下一个节点
pre_meta_info.set_next_meta_offset(next_pos);
// 在更新前一个节点的指针之前,它是存储在文件系统中的。
// 当需要删除当前节点时,需要先读取当前节点和前一个节点的数据块,
// 然后将前一个节点的指针更新,最后将更新后的前一个节点数据块重新写回文件系统中。
// 在这个"过程"中,前一个节点的数据块被"读取到内存"中,并在"内存中进行了修改",
// 但是"修改后的数据并没有被写回到文件系统中"。
// 也就是说,你读出来指的是将其从文件系统读到内存中,你的操作是在内存中的进行的,
// 你的文件系统没有改变,所以你还要"将你在内存中的操作后的结果"重新写入到文件系统中!
ret = file_op_->pwrite_file(reinterpret_cast<char *>(&pre_meta_info),
sizeof(MetaInfo),
previous_offset);
if (TFS_SUCCESS != ret) // 写失败,说明删除失败
{
return ret;
}
}
// 重用
// 删除并非真的删除,只是标记了该节点不可用了,然后再将该节点找个机会重用(当然,如果可重用节点过多,多到一定比例时,淘宝分布式文件系统会在人流量少时,将这些可重用节点进行删除[不过该功能,我并没实现])
// 把删除节点加入可重用节点链表(前插法)
// 1.第一步
meta_info.set_next_meta_offset(free_head_offset()); // index_header()->free_head_offset_;
ret = file_op_->pwrite_file(reinterpret_cast<char *>(&meta_info), sizeof(MetaInfo), current_offset);
if (TFS_SUCCESS != ret)
{
return ret;
}
// 2.第二步
index_header()->free_head_offset = current_offset;
if (debug)
{
std::cout << "=========================================================================" << std::endl;
printf("index_header()->free_head_offset:%d\n", index_header()->free_head_offset);
std::cout << "///" << std::endl;
std::cout << "current_offset:" << current_offset << ",index_header()->free_head_offset:" << index_header()->free_head_offset << std::endl;
printf("delete_segment_meta - Reuse metainfo, current_offset: %d\n", current_offset);
std::cout << "=========================================================================" << std::endl;
}
update_block_info(C_OPER_DELETE, meta_info.get_size());
return TFS_SUCCESS;
}
参考
1.淘宝分布式文件系统核心储存引擎学习总结



![[linux初阶][vim-gcc-gdb] OneCharter: vim编辑器](https://img-blog.csdnimg.cn/direct/22910ecd48b24173b760a42217b6425f.png)