文章目录
- 案例信息介绍
- 后端异步处理请求和后端同步处理请求
- 同步方式
- 异步方式
- 环境文件目录
- 配置
- .env
- requirements.txt
- 完整代码
- ext.py
- app.py
- kafka_create_user.py
- 运行方式
- 本地安装 kafka
- 运行 app.py
- 使用 postman 测试
- 建立 http 长连接,等待后端处理结果
- 发送 RAW DATA
- 在看这个文章之前,建议先学习 kafka的工作原理 这个系列视频讲得很好,虽然基于
Java但是理解原理并不用区分语言。只需要看懂工作原理即可。
案例信息介绍
- 假设我的网站需要高并发地处理 user 注册这个简单的功能。
- 前端会发送
{"user_id": xxxx, "psw":xxx}的信息到后端完成创建- 前端用
postman来模拟 - 后端用
flask框架来简单演示
- 前端用
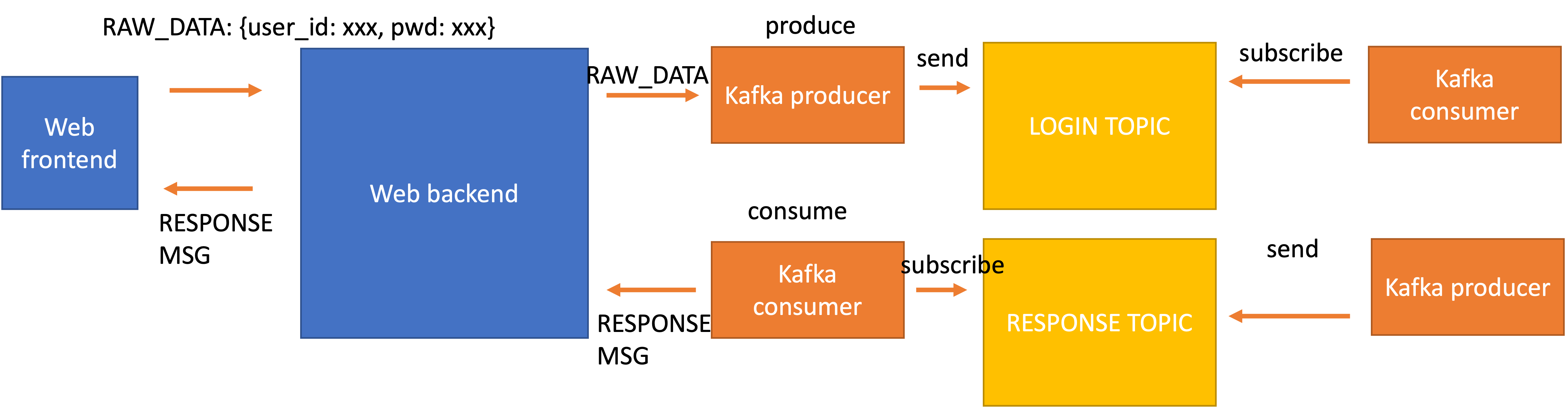
- 下面我用一张大致的图来表示代码的架构:
- 前端的原始数据进入后端之后,后端要用
kafka的架构在有序地处理 user 的请求,在这个任务中所有 user 的请求都是 register,因此我们就创建一个kafka的 topic 专门用来处理 user 的这类请求 - 同时由于 kafka 是通过队列的方式 异步地处理 user 的请求,所以当 kafka 处理完 user 的请求后,我们需要找到这个处理结果并返回给对应的 user
如果大家对于 异步处理 user 请求和同步处理没有概念,那么下面一章我先给大家讲一下同步处理请求和异步处理的区别
- 前端的原始数据进入后端之后,后端要用
后端异步处理请求和后端同步处理请求
同步方式
"""
@file: app.py.py
@Time : 2024/3/30
@Author : Peinuan qin
"""
import threading
import json
from flask import Flask, jsonify, request
from flask_cors import CORS
from ext import FLASK_HOST, FLASK_PORT
app = Flask(__name__)
CORS(app)
@app.route("/login", methods=['POST'])
def create_user_post():
data = request.json
"""
register user code ....
"""
return jsonify({"status": 200, "msg": "success"})
if __name__ == '__main__':
app.run(host=FLASK_HOST, port=FLASK_PORT, debug=True)
- 上述方式可以看到我的
create_user_post负责接受前端的数据并且即刻处理,处理之后将结果返回前端jsonify({"status": 200, "msg": "success"}),这个过程是一行接着一行发生的,如果中途出现了很耗时的操作,那么程序会一直等着。 - 在 Flask 应用中,如果
"register user code ...."处理需要20秒,这确实会阻塞处理该请求的线程,直到该过程完成。由于 Flask 开发服务器默认是单线程的,这意味着在这20秒内,服务器将无法处理来自其他用户的任何其他请求。 - 为了允许 Flask 同时处理多个请求,你可以启用多线程模式。这可以通过在
app.run()中设置threaded=True来实现app.run(host=FLASK_HOST, port=FLASK_PORT, debug=True, threaded=True)。这样,Flask 将能够为每个请求启动一个新的线程,从而允许同时处理多个请求。但这仍然并不是一种很好的方法,因为整个服务器来看,不具备扩展性。 假设我们服务器为每个 user 的请求开一个线程,那么服务器资源是有限的,当服务器宕机,也并不能很快的恢复这就导致扩展性很差。
异步方式
import threading
import json
from flask import Flask, jsonify, request
from flask_cors import CORS
from ext import FLASK_HOST, FLASK_PORT, users_streams, LOGIN_TOPIC, producer, logger, ResponseConsumer
from kafka_create_user import kafka_consumer_task
app = Flask(__name__)
CORS(app)
@app.route("/login", methods=['POST'])
def create_user_post():
data = request.json
# 发送数据到Kafka
producer.produce(LOGIN_TOPIC, key=str(data['user_id']).encode("utf-8"), value=json.dumps(data).encode("utf-8"))
producer.flush()
logger.info("send message to consumer")
return jsonify({"msg": "你好,请求正在处理"})
- 我们先忽略其他的代码,只看这一部分。
- 这里相当于我们接受 user 的请求之后,通过 kafka 把处理请求的需要转移到外部的服务器集群上去了。而 kafka 的特性在于非常高的可扩展性。增加 kafka 的节点就可以线性地将任务处理的数量提高。
- 如果你看我上面给的那张图,
kafka可以通过无限制增加consumer的数量来提高数据的处理能力。而后端的服务器需要做的就是把这些数据不断地派发出去,这个步骤相比于直接在后端将所有的请求处理来说可以忽略不计。
环境文件目录
.
├── app.py
├── ext.py
├── kafka_create_user.py
└── requirements.txt
配置
.env
- 首先构建一个配置文件
.env来存放基础的配置信息
FLASK_HOST=0.0.0.0
FLASK_PORT=9300
# LOGIN 这个 topic 是用来处理用户注册这个业务的
LOGIN_TOPIC=LOGIN
# RESPONSE_TOPIC 则是用来构建 response 来返回前端成功或者失败
RESPONSE_TOPIC=RESPONSE_TOPIC
requirements.txt
kafka-python==2.0.0
colorlog==6.7.0
configparser==5.3.0
flask==2.3.2
flask_basicauth==0.2.0
Flask-JWT-Extended==4.6.0
Flask-Limiter==3.5.1
Flask-PyMongo==2.3.0
requests==2.31.0
gunicorn==21.0.0
pymongo==4.6.0
pdfminer.six==20231228
flask_cors==4.0.0
python-dotenv
orjson==3.10.0
langchain
langchain-community
langchain_openai
chromadb
python=3.10
完整代码
ext.py
"""
@file: ext.py.py
@Time : 2024/3/30
@Author : Peinuan qin
"""
import json
import logging
import os
import queue
import threading
import colorlog
from confluent_kafka import Producer, Consumer, KafkaError
from dotenv import load_dotenv
from confluent_kafka.admin import AdminClient, NewTopic
# 加载 .env 中的变量
load_dotenv()
FLASK_HOST = os.environ['FLASK_HOST']
FLASK_PORT = os.environ['FLASK_PORT']
LOGIN_TOPIC = os.environ['LOGIN_TOPIC']
RESPONSE_TOPIC = os.environ['RESPONSE_TOPIC']
TOPICS = [LOGIN_TOPIC, RESPONSE_TOPIC]
def create_topic():
# Kafka服务器配置
admin_client = AdminClient({
"bootstrap.servers": "localhost:9092"
})
# 创建新主题的配置
topic_list = [NewTopic(topic, num_partitions=3, replication_factor=1) for topic in TOPICS]
# 注意: replication_factor 和 num_partitions 可能需要根据你的Kafka集群配置进行调整
# 创建主题
fs = admin_client.create_topics(topic_list)
# 处理结果
for topic, f in fs.items():
try:
f.result() # The result itself is None
logger.info(f"Topic {topic} created")
except Exception as e:
logger.error(f"Failed to create topic {topic}: {e}")
# Handler for logging
handler = colorlog.StreamHandler()
formatter = colorlog.ColoredFormatter(
"%(log_color)s%(asctime)s.%(msecs)03d - %(levelname)s - %(message)s",
datefmt='%Y-%m-%d %H:%M:%S',
log_colors={
'DEBUG': 'cyan',
'INFO': 'green',
'WARNING': 'yellow',
'ERROR': 'red',
'CRITICAL': 'red,bg_white',
}
)
handler.setFormatter(formatter)
# Logger
logger = colorlog.getLogger(__name__)
logger.addHandler(handler)
logger.setLevel(logging.INFO)
"""
尝试创建 topic
"""
create_topic()
# 初始化Kafka生产者
producer_config = {
'bootstrap.servers': 'localhost:9092'
}
producer = Producer(**producer_config)
"""
定义专门用来回复 response 的 consumer
"""
class ResponseConsumer:
"""
专门用来将各种处理好的结果返回给 user 作为 response; 也就是图中针对 RESPONSE TOPIC 的 consumer
"""
def __init__(self):
self.users_streams = {}
self.config = {
'bootstrap.servers': 'localhost:9092',
'group.id': 'user-response', # 设置 groupid,如果不知道为什么要设置 groupid 可以去先看 kafka 的讲解视频
'auto.offset.reset': 'earliest'} # 告诉 Kafka 消费者在找不到初始偏移量(offset)或者偏移量无效时(比如,指定的偏移量已经被删除),应该从哪里开始消费消息。它可以设置为 'earliest' 或 'latest'。设置为 'earliest' 意味着消费者将从主题的开始处开始读取数据,即尽可能不漏掉任何消息;设置为 'latest' 意味着消费者将从新产生的消息开始读取,即只消费自启动之后产生的消息。
self.consumer = Consumer(**self.config)
logger.info("Create Response Consumer")
self.consumer.subscribe([RESPONSE_TOPIC])
logger.info("Subscribe Response Topic")
# 因为可能有多个线程一起操作 consumer,所以通过 lock 来保证线程安全
self.lock = threading.Lock()
def get_or_make(self, user_id):
"""
获取某个 user_id 的 response queue, 如果当前 user_id 的 response queue 不存在就创建一个
每个 user_id 的 response queue 中都是返回给前端 user 的信息,也就是图中的 RESPONSE MSG
:param user_id:
:return:
"""
with self.lock:
# 如果当前 user_id 还没有 queue,就构建一个
q = self.users_streams.get(user_id, queue.Queue())
self.users_streams[user_id] = q
return q
def pop(self, user_id):
with self.lock:
self.users_streams.pop(user_id, None)
def put(self, user_id, msg_dict):
"""
当 user_id 的请求处理完,产生的 RESPONSE MSG 放到 user_id 的队列里面
:param user_id:
:param msg_dict:
:return:
"""
q = self.get_or_make(user_id)
if q:
with self.lock:
self.users_streams[user_id].put(msg_dict)
logger.info(f"put {msg_dict} into {user_id}'s queue")
return True
else:
return False
def listen_for_response(self):
"""
不断拉取 RESPONSE TOPIC 的 producer 生成的结果
:return:
"""
try:
while True:
msg = self.consumer.poll(timeout=1.0) # 1秒超时
if msg is None:
continue
if msg.error():
if msg.error().code() == KafkaError._PARTITION_EOF:
# End of partition event
continue
else:
print(msg.error())
break
"""
如果拉取到了就放到对应的 user_id 的 queue 里面
"""
if msg:
logger.info(f"received data: {msg}")
msg_data = json.loads(msg.value().decode("utf-8"))
user_id = msg.key().decode("utf-8")
logger.info(f"msg_data: {msg_data}")
logger.info(f"user_id: {user_id}")
put_flag = self.put(user_id, msg_data)
if not put_flag:
logger.error(f"Create RESPONSE MSG for {user_id} failed")
else:
logger.info(f"create RESPONSE MSG response for {user_id}")
except Exception as e:
self.consumer.close()
app.py
"""
@file: app.py.py
@Time : 2024/3/30
@Author : Peinuan qin
"""
import threading
import json
from flask import Flask, jsonify, request
from flask_cors import CORS
from ext import FLASK_HOST, FLASK_PORT, users_streams, LOGIN_TOPIC, producer, logger, ResponseConsumer
from kafka_create_user import kafka_consumer_task
app = Flask(__name__)
CORS(app)
response_consumer = ResponseConsumer()
@app.route("/login", methods=['POST'])
def create_user_post():
data = request.json
# 发送数据到Kafka
producer.produce(LOGIN_TOPIC, key=str(data['user_id']).encode("utf-8"), value=json.dumps(data).encode("utf-8"))
producer.flush()
logger.info("send message to login consumer")
return jsonify({"msg": "你好,请求正在处理"})
@app.route('/stream')
def stream():
user_id = request.args.get('user_id') # 假设用户ID通过查询参数传入
logger.info(f"uid: {user_id}")
logger.info(f"user_streams: {response_consumer.users_streams}")
def event_stream(user_id):
# 这里需要一种机制来持续发送数据给特定用户的流
q = response_consumer.get_or_make(user_id)
logger.info(f"{user_id} 's queue is: {q}")
while True:
if not q.empty():
message = q.get()
logger.info(f"message: {message}")
yield f"data: {json.dumps(message)}\n\n"
return app.response_class(event_stream(user_id), content_type='text/event-stream')
def run_multi_thread():
consumer_thread = threading.Thread(target=kafka_consumer_task)
response_thread = threading.Thread(target=response_consumer.listen_for_response, daemon=True)
logger.info("Start APP ...")
consumer_thread.start()
logger.info("Create User Consumer start ...")
response_thread.start()
logger.info("Response Consumer start ...")
app.run(host=FLASK_HOST, port=FLASK_PORT, debug=True, use_reloader=False)
if __name__ == '__main__':
run_multi_thread()
kafka_create_user.py
"""
@file: kafka_create_user.py
@Time : 2024/3/30
@Author : Peinuan qin
"""
import json
import os
from queue import Queue
import threading
# 初始化全局消息队列
from confluent_kafka import Consumer, KafkaError
from kafka import KafkaConsumer, KafkaProducer
from dotenv import load_dotenv
from ext import logger, LOGIN_TOPIC, RESPONSE_TOPIC, producer
def kafka_consumer_task():
"""
这里定义了 LOGIN TOPIC 的 consumer 的行为;也就是对 user_id 传过来的 RAW DATA 如何处理
:return:
"""
# Kafka配置
config = {
'bootstrap.servers': 'localhost:9092',
'group.id': 'user-login-group',
'auto.offset.reset': 'earliest'
}
consumer = Consumer(**config)
consumer.subscribe([LOGIN_TOPIC])
# 读取数据
try:
while True:
msg = consumer.poll(timeout=1.0) # 1秒超时
if msg is None:
continue
if msg.error():
if msg.error().code() == KafkaError._PARTITION_EOF:
# End of partition event
continue
else:
print(msg.error())
break
if msg:
data = json.loads(msg.value().decode("utf-8"))
key = msg.key().decode("utf-8")
print("key:", key)
"""
为了观察,我们将 user 传过来的数据保存到本地
"""
with open(f"{key}.json", 'w') as f:
json.dump(data, f, ensure_ascii=False, indent=4)
logger.info(f"successfully saved the {key}.json")
"""
完成任务后,通过 RESPONSE TOPIC 的 producer 生成 response,并发送给 RESPONSE TOPIC 等待对应的 consumer 来取,并且返回给前端
"""
producer.produce(RESPONSE_TOPIC, key=msg.key(), value=json.dumps({"msg": f"successfully create user {key}"}).encode("utf-8"))
producer.flush()
logger.info("send processed data to response consumer")
except KeyboardInterrupt:
pass
finally:
# 清理操作
consumer.close()
producer.flush()
producer.close()
强调一下:
- 如果你也是基于 Flask 框架,虽然这里的
debug=True可以保证每次更改代码后对代码进行重载,方便你进行调试。但是关于内存中的一些变量会消失,所以保证我上面的代码能够顺利运行,我设置了use_reloader=False否则response_consumer.users_streams总是为空,因为重载变量会造成混淆,引发未知的程序错误。app.py中的stream是以SSE的方式让服务器可以主动通知 user,本质是 user 向服务器建立长连接,然后 kafka 完成任务后通过这个端口将信息发送给 user
运行方式
本地安装 kafka
- 不知道如何安装请 参考
运行 app.py
- 直接用 pycharm 运行就可以
使用 postman 测试
建立 http 长连接,等待后端处理结果
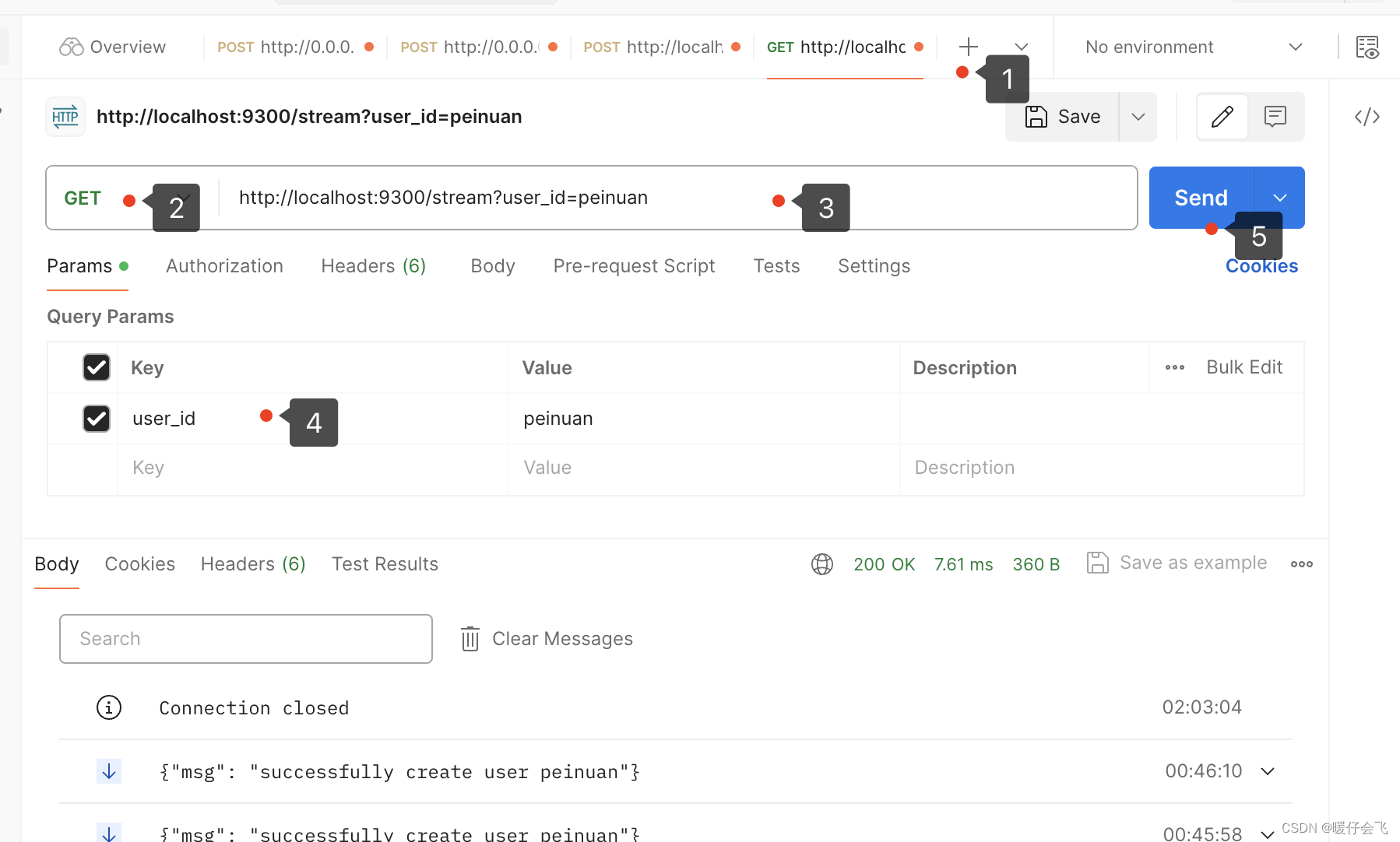
+新建窗口- 建立
http连接,针对stream端口,并且是GET方法(注意选中 http 协议哦,通过左上角的符号,不要选择其他协议) - 同时在
Params下面的key和value输入你 user_id 的信息(要和下面的/login的一致) - 然后点击
send - 长连接就会成功建立了
发送 RAW DATA
- 打开另一个新的窗口
- 输入你本地运行的地址和端口,并且选择
post方法 - 选择
body和raw选择json的格式并在文本框中键入json数据 - 发送
- 就会收到 阶段性的服务器回复 ,这代表后端已经通过 kafka 来异步处理数据
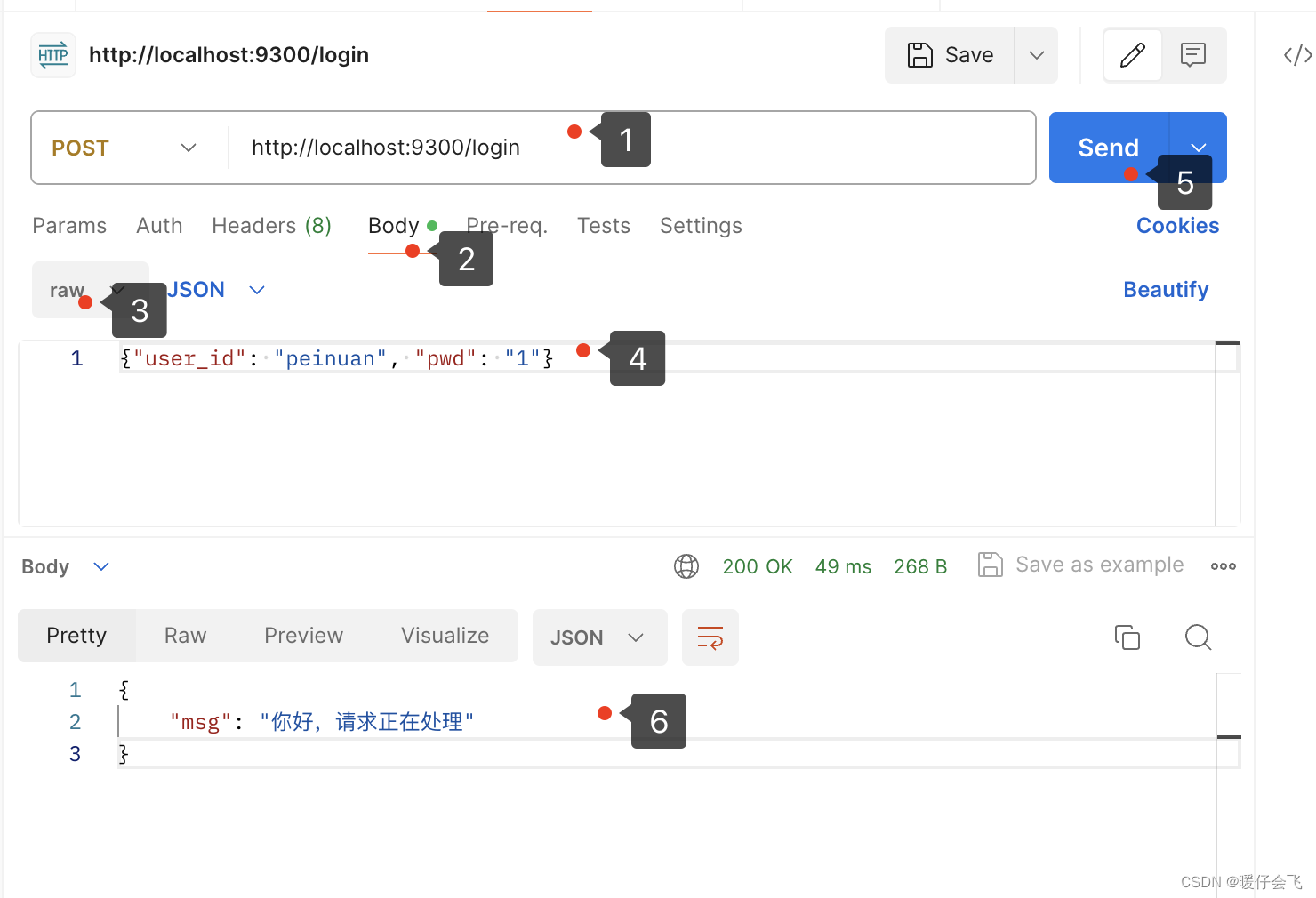
- 这个时候,很快你应该可以看到在长连接的那个 postman 窗口里面出现
{"msg": "successfully create user peinuan"};并且每次你在/loginsend 一次,这里就会成功获得一次结果(前端获得成功的信息)