💓博主CSDN主页:麻辣韭菜💓
⏩专栏分类:Linux知识分享⏪
🚚代码仓库:Linux代码练习🚚
🌹关注我🫵带你学习更多Linux知识
🔝
目录
前言
一.Linux下一切皆文件
二.缓冲区
1.缓冲区概念
2.缓冲区意义
3.缓冲区在哪里
三.文件系统
1.初识文件系统
2. 扇区中的块组是如何工作的?
3. 理解软硬链接
三.动静态库
生成静态库
生成动态库
编辑 1.导入环境变量方法
2.修改配置文件
3.软连接到系统库下面
前言
基础IO讲了什么是fd,以及fd的本质是什么,系统调用接口。本篇重点缓冲区,理解文件系统,全面认识Linux下一切皆文件。
一.Linux下一切皆文件
如何理解一切皆文件?我们都知道Linux是用C语言写的,那时候的编程思想都是面向过程。C语言是如何实现面向对象?甚至是运行时 像C++一样有多态的特性?
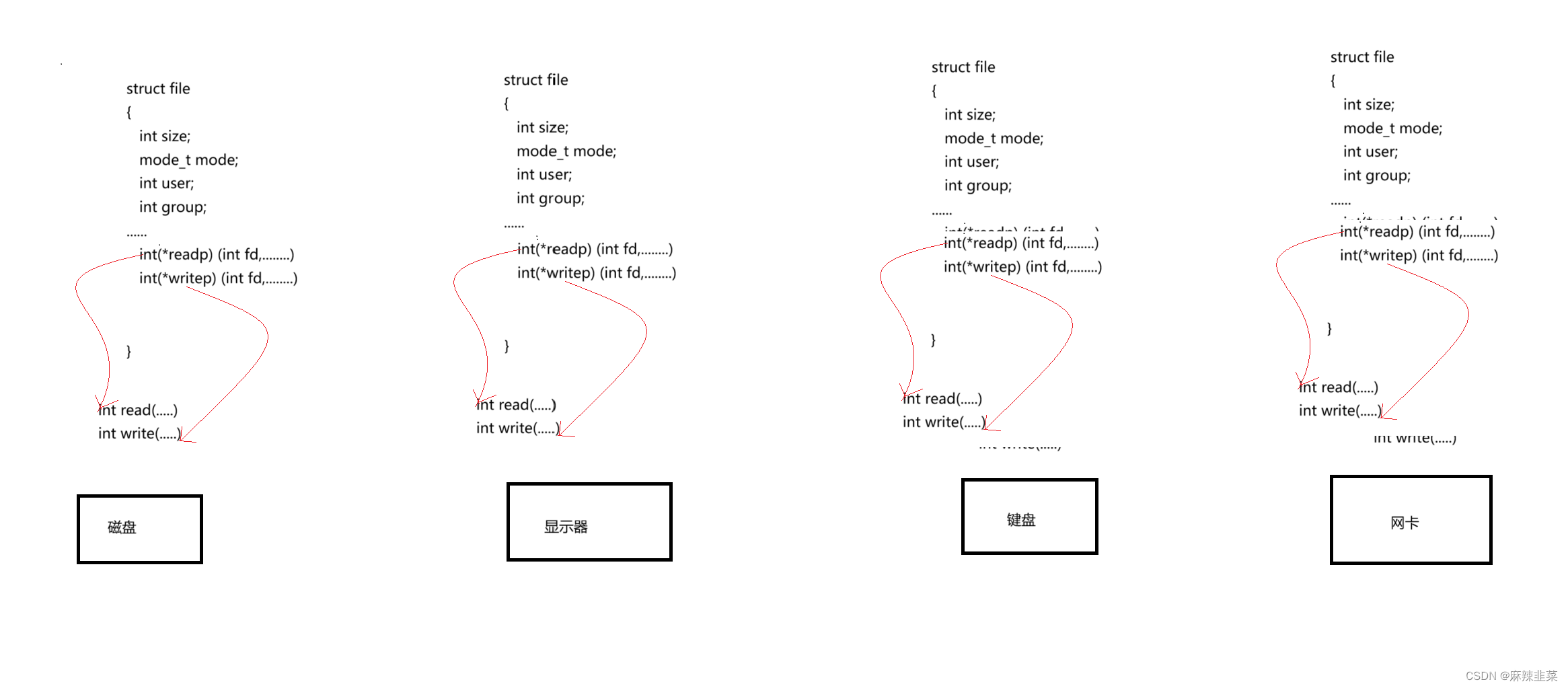
底层的不同的硬件,一定是对应不同的操作方法,但是这些设备都是外设,所以这些外设核心访问函数,都可以是read、write I/O,因此这些设备,都有的自己的read、write 但是它们实现方法肯定是不一样的。所以从OS角度来讲,这些设备被打开时,OS给它们创建struct file结构体,不同的外设(对象)调用自己的读写函数。这不就形成多态了吗?
二.缓冲区
1.缓冲区概念
什么是缓冲区?从生活角度来讲,最直观的就是快递公司,假如你在北京读大学,你高中的同学在新疆读大学,有一天你同学要给你寄新疆的特产。请问你同学给你寄东西是马上就发货的吗?如果是这样快递公司早就垮了。快递公司肯定是等到不同的人寄的东西,都是要发往北京 等到一车要装满之后,才发货。 这个车就是一段内存空间
2.缓冲区意义
为什么要有缓冲区? 从上面例子来说就是节约成本,对OS来说也是一样,大量频繁的IO访问对OS负担是很大的,这种模式我们叫做写透模式(WT),特点就是成本高,运行慢。
对用户而言建立缓冲区,写回模式(WB)快速,成本低。提高整机利用率。
3.缓冲区在哪里
缓冲区在哪? 我们先看一段代码看看结果
int main()
{
//c语言提供的
const char *s = "hello world1\n";
const char *s1 = "hello world2\n";
printf("hello linux\n");
fprintf(stdout, "%s", s);
fputs(s1, stdout);
//os提供的
const char *s2 = "hello world3\n";
write(1, s2, strlen(s2));
//创建子进程
fork();
return 0;
}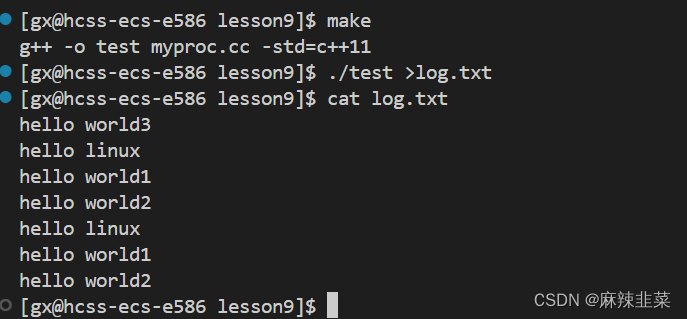
我们对子进程进行重定向 发现除了write只写一次,C提供的函数写入了两次这是为什么?
首先缓冲区的刷新策略先了解一哈:
1.立即刷新
2.行刷新
3.满刷新(全缓冲)
特殊情况:
•用户强制刷新(fflush)
•进程退出
•一般C库函数写入文件时是全缓冲的 而写入显示器是行缓冲。当重定向到普通文件时数据缓冲方式就由行缓冲变为了全缓冲。
•而我们放在缓冲区中的数据,就不会被立即刷新,甚至fork之后,但是进程进程退出了,会统一刷新,写入到文件中。但是创建子进程的
fork()调用会复制当前进程(父进程)的状态,包括程序计数器、寄存器内容、打开的文件描述符等。因此,在fork()之后,父进程和子进程都有自己的地址空间副本,但它们的程序执行路径是相同的。•所以当你父进程准备刷新的时候,子进程也就有了同样的 一份数据,随即产生两份数据。write 没有变化,说明没有所谓的缓冲。综上: printf fwrite fputs 库函数会自带缓冲区,而 write 系统调用没有带缓冲区。另外,我们这里所说的缓冲区, 都是用户级缓冲区。其实为了提升整机性能,OS也会提供相关内核级缓冲区,不过不再我们讨论范围之内。 那这个缓冲区谁提供呢? printf fwrite fputs是库函数, write 是系统调用,库函数在系统调用的“上层”, 是对系统 调用的“封装”,但是 write 没有缓冲区,而 printf fwrite 有,足以说明,该缓冲区是二次加上的,又因为是 C,所以由C 标准库提供。
三.文件系统
1.初识文件系统
电脑中有没有没有被打开的文件?当然有的,在哪里?磁盘。
问题一:单个文件角度,这个文件在哪里,这个文件多大?这个文件其他属性是什么?
问题二:OS层面角度,一共有多少个文件?各自属性在哪里?如何快速找到?磁盘还可以存储多少个文件?如何快速找到指定的文件?
要像彻底明白上面的两个问题 我们需要先了解磁盘的物理结构。

从上图可以看出磁盘并不是像光盘那样只有一面,它像是很多层的光盘叠放在一起,每一层都有一个读写磁头。 我们在看看盘面的俯视图。
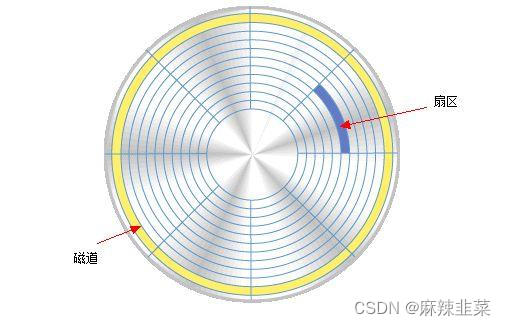
2. 扇区中的块组是如何工作的?
对于磁盘的每一个盘面来说,并不是所有的区域都可以用来存储数据,可以把扇区看作是C语言的中数组。每个一扇区的存储大小一般而言都是512字节。
所以OS就把整个磁盘拆分成无数的扇区,就变成了无数的数组。所以要找到一个文件
就只需要找到它的下标。
对磁盘的管理,变成了对数组的管理。那OS又是如何管理这些“数组”?
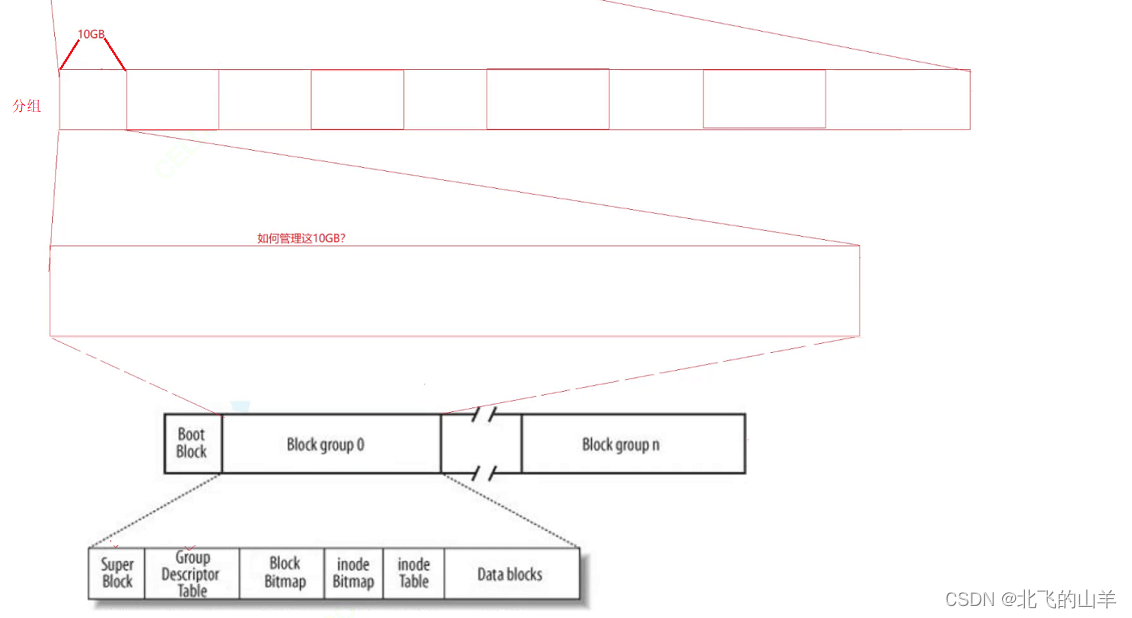
首先一个磁盘太大了,在我们电脑当中有C盘和D盘、E盘。这就是传说中分区。对磁盘的管理就变成了对一个小分区的管理。对分区在进行分,分成块组分治的思想管理 请看下图。
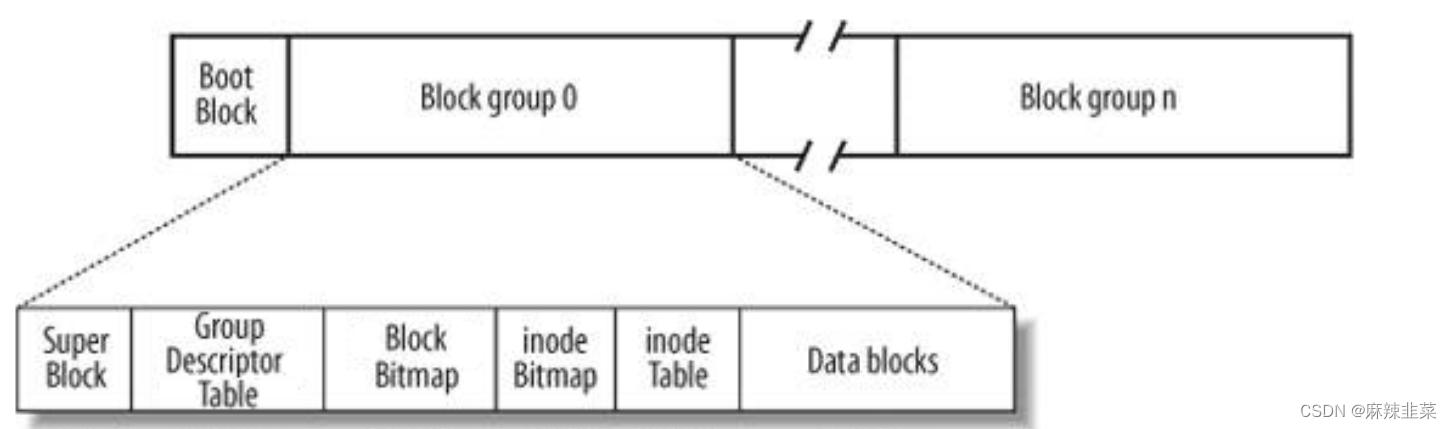
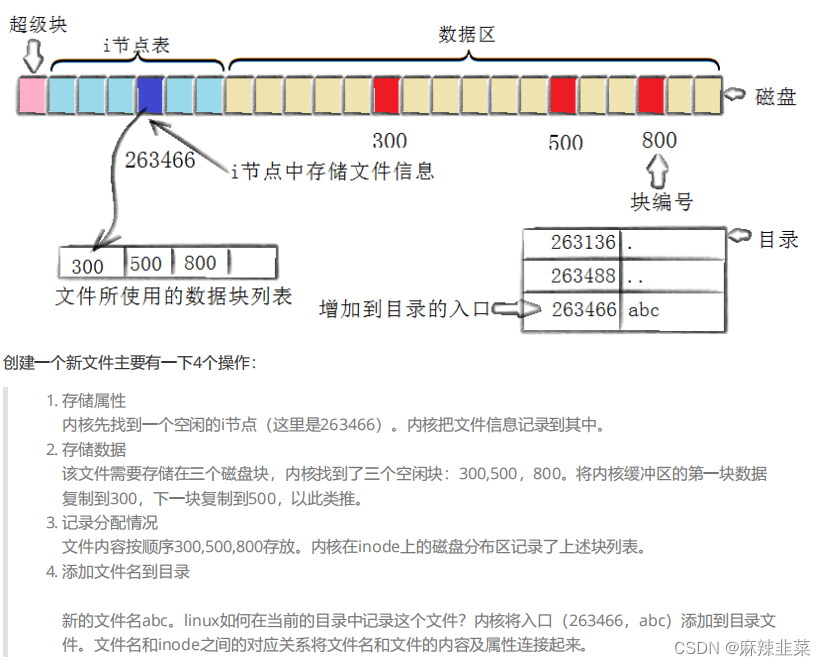
• Block Group : 文件系统会根据分区的大小划分为数个 Block Group 。而每个 Block Group 都有着相同的结构组成。• 超级块( Super Block ):存放文件系统本身的结构信息。记录的信息主要有: bolck 和 inode 的总量,未使用的block 和 inode 的数量,一个 block 和 inode 的大小,最近一次挂载的时间,最近一次写入数据的 时间,最近一次检验磁盘的时间等其他文件系统的相关信息。Super Block 的信息被破坏,可以说整个文件系统结构就被破坏了。• GDT , Group Descriptor Table :块组描述符,描述块组属性信息。• 块位图(Block Bitmap ): Block Bitmap 中记录着 Data Block 中哪个数据块已经被占用,哪个数据块没有被占用• inode 位图( inode Bitmap ):每个 bit 表示一个 inode 是否空闲可用。• 节点表 (inodeTable)点表 : 存放文件属性 如 文件大小,所有者,最近修改时间等• 数据区(Data blocks):多个4KB(扇区*8)大小集合。存放文件内容
块组被分成上面的相关内容,并且写入相关的管理数据,每一个块组都这么干,整个分区就被写入到了文件系统信息。这就是你电脑和手机每次重新安装系统所对应的传说之中的格式化。
一个文件“只”对应一个inode属性节点,inode编号。(当然不是一个文件名叫张三,万一它有小名了?)一个文件只能对应一个block吗??
当然不是,在struct inode这个结构体中定义一个int block[15] 这样的数组 这个数组下标对应就是你文件的存放block,这样就找到了文件的内容。
文件属性?inode编号不就是文件的属性吗?
这时有人要问了 一个 int block[15] 才多大,能放下一个大文件吗?
不是所有的data block,只能存放文件数据,也可以存放其他块组的块号!!大文件不就放下了吗?
3. 理解软硬链接
inode 和 文件名 请问找到文件的本质什么?inode编号 -> 分区特定的bg -> inode -> 属性 -> 内容 那怎么知道inode的编号?依托目录结构所以我们看到,真正找到磁盘上文件的并不是文件名,而是inode。 其实在linux中可以让多个文件名对应于同一个inode。看下图
使用指令:ln 创建硬链接

可以发现,在创建硬链接前,myproc.cc的引用计数是1,而创建硬链接后计数变成了2,其实硬链接的本质就是给相同的文件取别名,硬链接没有自己的inode,它和原文件的inode相同!请看下面的图片验证:
指令:ln -s 创建软连接
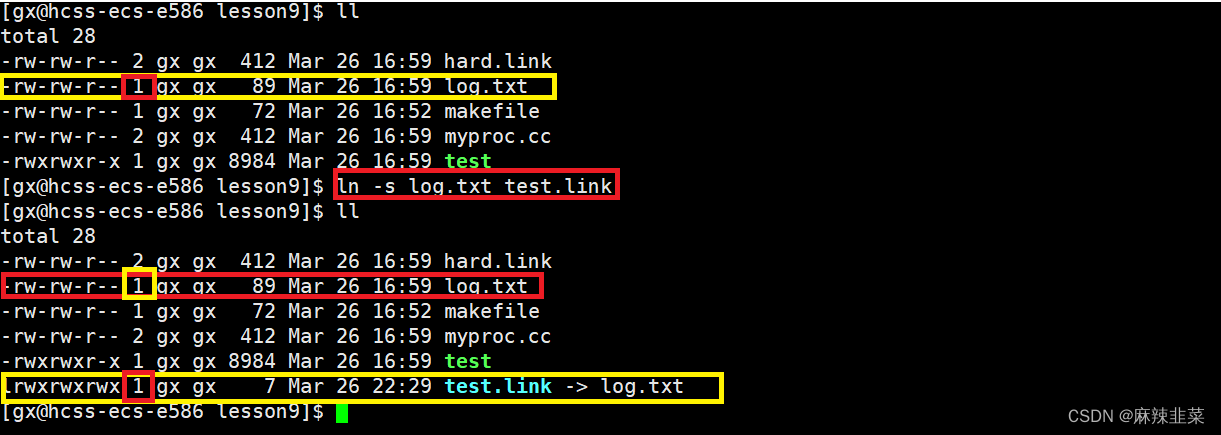

可以发现,创建的软连接是独立的一个文件,它有自己的inode,那软连接有什么用?看下图演示。
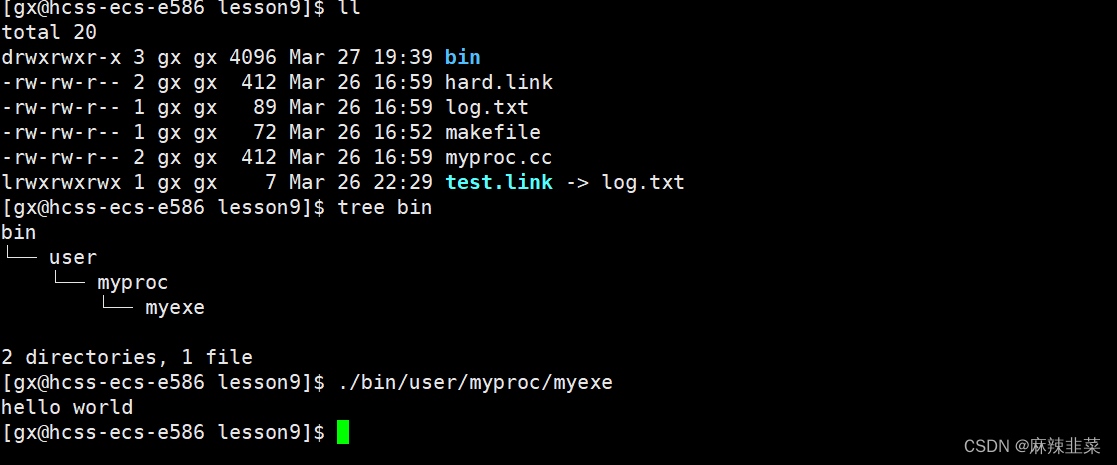
如果一个大型项目,你要运行别人的写的函数,可是这个可执行程序不在你的当前路径,你要运行每次都要加路径,万一这个可执行程序隐藏的很深,那不是光加路径就烦人了,这时软连接就起作用了。

软链接就如同window下的快捷方式!!!
三.动静态库
• 静态库(.a):程序在编译链接的时候把库的代码链接到可执行文件中。程序运行的时候将不再需要静态库• 动态库(.so):程序在运行的时候才去链接动态库的代码,多个程序共享使用库的代码。•一个与动态库链接的可执行文件仅仅包含它用到的函数入口地址的一个表,而不是外部函数所在目标文件的整个机器码 在可执行文件开始运行以前,外部函数的机器码由操作系统从磁盘上的该动态库中复制到内存中,这个过程称为动态链接(dynamic linking)•动态库可以在多个程序间共享,所以动态链接使得可执行文件更小,节省了磁盘空间。操作系统采用虚 拟内存机制允许物理内存中的一份动态库被要用到该库的所有进程共用,节省了内存和磁盘空间。
生成静态库

这是我写的两个简单函数,下面先生成.o文件
指令:g++ -c 文件名 -o 文件名.o
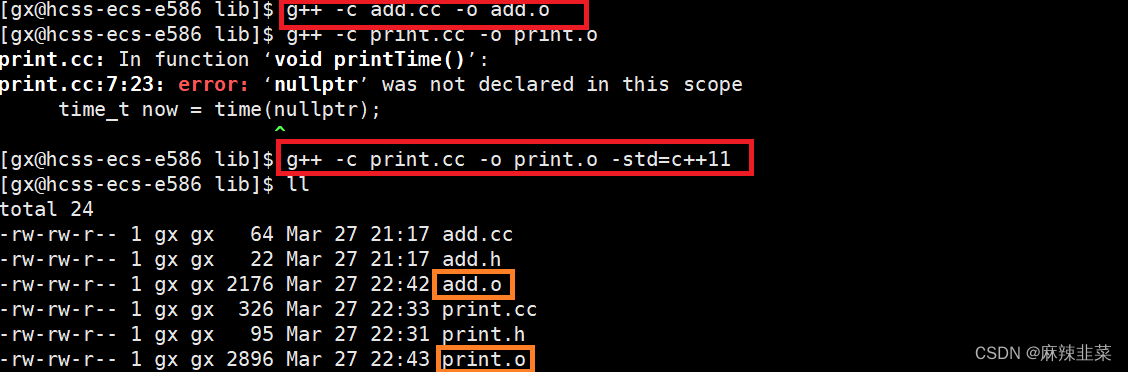
第二步打包.o文件 指令:ar -rc libother.a add.o print.o

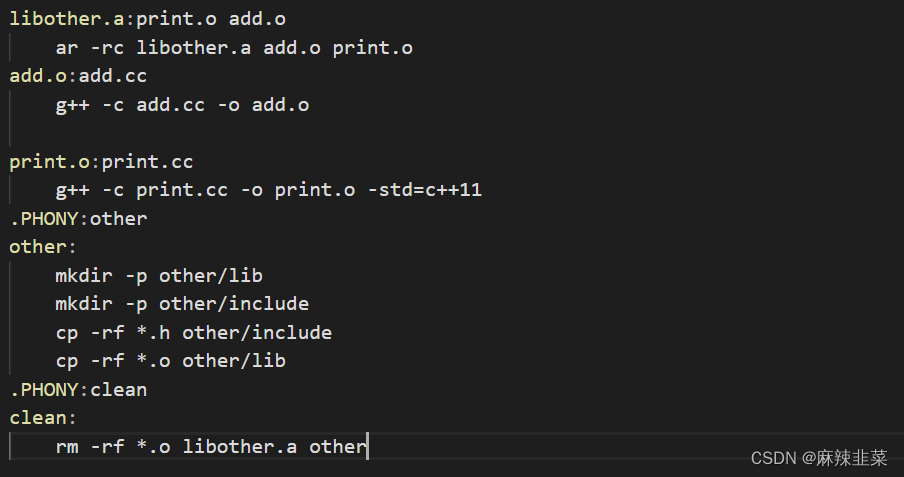
这里指令太多了,直接用makefile
第三步发布


![]()

指令:g++ main.cc -I ./other/include/ -L ./other/lib/ -l other


静态库还有一种拷贝到系统环境下的方法,这里就不演示了,不推荐。
生成动态库
同时生成动态库和静态库
指令:g++ -c -fPIC add.cc -o add_d.o
g++ -shared add_d.o print_d.o -o libother.so
-shared是g++编译器的一个选项,用于指示编译器生成共享对象文件(Shared Object File),这通常具有.so的扩展名。在Unix-like系统中,共享对象文件是一种可以被多个程序同时使用的库文件。这与静态库(通常由ar命令生成,具有.a扩展名)不同,静态库在链接时会被完整地复制到最终的可执行文件中。 当使用-shared选项时,g++会生成一个包含目标代码和重定位信息的共享对象文件。

.PHONY:all all:libother.so libother.a libother.so:add_d.o print_d.o g++ -shared add_d.o print_d.o -o libother.so add_d.o:add.cc g++ -c -fPIC add.cc -o add_d.o print_d.o:print.cc g++ -c -fPIC print.cc -o print_d.o -std=c++11 libother.a: add.o print.o ar -rc libother.a add.o print.o add.o:add.cc g++ -c add.cc -o add.o print.o:print.cc g++ -c print.cc -o print.o -std=c++11 .PHONY:other other: mkdir -p other/lib mkdir -p other/include cp -rf *.h other/include cp -rf *.a other/lib cp -rf *.so other/lib .PHONY:clean clean: rm -rf *.o *.a *.so other

 1.导入环境变量方法
1.导入环境变量方法
运行出错了,找不到动态库
导入环境变量:
export LD_LIBRARY_PATH=$LD_LIBART_PATH:/home/gx/linux-exercise/lesson9/uselib/other/lib


2.修改配置文件
/etc/ld.so.conf.d/ 在这个路径下创建一个文件 other.conf

sudo vim 打开这个文件
![]()

粘贴复制之后 再sudo ldconfig
![]()
这时我们再./a.out就找到这个库了。

3.软连接到系统库下面
指令:这里软连接要用绝对路径
sudo ln -s ~gx/linux-exercise/lesson9/uselib/other/lib/libother.so /lib64/libother.so


不推荐这个做法,因为我们写的这个库是没有经过官方认证的,这样会污染官方库。
下去自己试了之后就把它删除了。
![]()
还有没有其他方法,当然还有的,.bashrc 这里 把我们第一点方法放在这里就行。
建议不要做!!!
下节预告进程间通信 ,关注我带你学习更多Linux知识。