MRM: Masked Relation Modeling for Medical Image Pre-Training with Genetics
Authors: Qiushi Yang, Wuyang Li, Baopu Li, Yixuan Yuan
Source: ICCV 2023

Abstract:
关于自动多模态医疗诊断的 ODERN 深度学习技术依赖于大量的专家注释,这既耗时又令人望而却步。最近基于掩码图像建模 (MIM) 的预训练方法在从未标记数据中学习有意义的表示并转移到下游任务方面取得了令人瞩目的进展。然而,这些方法只关注自然图像,而忽略了医疗数据的具体属性,导致下游医学诊断的泛化性能不尽如人意。在本文中,旨在利用遗传学来促进图像预训练,并提出一个掩蔽关系建模(MRM)框架。在以前的MIM方法中,没有显式屏蔽输入数据,导致疾病相关语义的丢失,而是设计了关系掩码来屏蔽自模态和跨模态级别的标记特征关系,从而在输入中保留了完整的语义,并允许模型学习丰富的疾病相关信息。此外,为了增强语义关系建模,提出了关系匹配来对齐完整特征和掩码特征之间的样本关系。关系匹配通过鼓励特征空间中的全局约束来利用样本间关系,为特征表示提供足够的语义关系。大量实验表明,所提出的框架简单而强大,在各种下游诊断任务中实现了最先进的转移性能。
在医学诊断中,大规模的多模态生物样本库数据,例如图像和遗传学,对于可靠的诊断是必要的,克服了单一模式的有限规模和疾病信息数据。然而,大规模数据集的专家注释令人望而却步,这使得训练传统的深度模型变得困难。特别是在这种多模态场景中,各个医学领域专家的要求阻碍了足够的注释访问,严重限制了自动诊断系统的接地。为了解决这个问题,最流行的趋势是自监督预训练,例如,掩码图像建模(MIM),旨在训练具有足够泛化能力的无标签模型。现有的MIM方法屏蔽了输入图像中的大部分补丁,并推断出缺失的内容,如图1(a)所示。利用上下文信息来浏览语义并重建整个图像,从而执行掩码和重构任务,以在没有注释的情况下预训练模型,并将有意义的表示转移到各种用于改进标签效率微调的下游任务。尽管取得了巨大的成功,但大多数作品都是为自然图像设计的,忽略了医学数据与自然图像之间的本质区别。因此,根据经验发现,现有的MIM不能在医学数据中很好地工作(见表1),甚至完全无法重建疾病(见图3)。原因源于对重大数据差异的批判性观察,可以将其概括为两个挑战。首先,与自然图像相比,医学数据中的语义区域有限。如图1(a)所示,语义丰富的前景始终是自然图像的主体,而其余非信息性背景区域仅代表一小部分。不同的是,在医学图像(图1(b))中,大多数区域是背景,而信息丰富的疾病区域通常规模很小。
在现有的MIM方法中屏蔽整个标记的策略下,如果疾病标记被屏蔽掉,则与疾病相关的语义将完全丢失,并导致灾难性的信息丢失,从而导致无法处理的重建。这个问题也存在于基因组学和自然图像之间。基因组学中的语义区域,即疾病相关模式,主要位于少数基因组片段中[28,5,7]。因此,这些观察结果并没有屏蔽整个输入标记,而是促使深入研究标记级关系的掩码,这保留了丰富的语义可判别性和充分的自我监督,如图 1 (c) 左图所示。第二个挑战是有限的语义关系。在自然图像中,背景和前景的关系,例如,天空中的鸟和房间里的人,往往是繁荣和丰富的,在语义水平学习中起着关键作用。相比之下,在每个医学数据样本中,疾病意识关系是有限的,不足以提供足够的鉴别证据。原因在于,医学数据集通常是从同一个人体器官(例如眼底)收集的,其中包含冗余和相似的解剖模式(例如毛细血管),这严重阻碍了疾病与复杂医学场景之间的关系建模。这一挑战阻碍了现有MIM方法中的可靠关系学习,并可能不可避免地导致后台中非信息关系的过度拟合。因此,考虑到每个数据样本中的有限语义关系,致力于超越独立和单个数据样本的自监督学习,并建议鼓励利用样本间关系的全局约束(见图1(c)右)。
为了应对上述挑战,如图1(c)所示,提出了MRM,这是一种从统一的关系视图中屏蔽的关系建模,包含关系掩蔽和关系匹配,以合理地预训练具有遗传学的多模态医学图像。为了在原始输入中保留完整的语义信息,设计了关系掩蔽策略,使模型能够学习与疾病相关的语义。关系掩码不是屏蔽输入数据,而是在自模态和跨模态级别上研究特征表示中的标记关系,并屏蔽所有多模态标记之间的关系。关系掩码使模型能够从原始数据中显式学习全局依赖性,而不会遗漏与疾病相关的语义信息。此外,为了改进语义关系建模,设计了关系匹配,通过对齐多个样本的特征关系来提供全局约束。具体而言,关系匹配利用自模态和跨模态水平上的样本关系来鼓励完整特征和掩蔽特征之间的关系一致性。这具有每个样本像素级重建损耗的互补优势,并提高了模型的传递能力。通过预训练模型,可以获得可以转移到监督下游诊断任务的特征表示,以提高标签效率的微调,从而缓解对专业注释的严格需求。
本文的贡献分为四个部分:
• 确定了当前 MIM 方法对医疗数据的挑战,并提出了 MRM,这是一种使用多模态医疗数据的掩蔽关系建模,以促进图像表示学习。
• 针对医疗数据中语义区域有限的问题,设计了关系掩码来掩蔽跨自我和跨模态的特征关系。与MIM显式掩蔽输入不同,关系掩蔽保留了输入中的疾病语义,赋予了强大的掩码和构造任务。
• 此外,为了丰富疾病之间的语义关系,提出关系匹配方法,通过在自身和跨模态水平上对齐完整特征和掩蔽特征之间的样本特征关系来捕捉丰富的疾病相关关系。
• 使用两个公共医疗预训练数据集对各种下游任务进行广泛的迁移评估表明,所提出的框架比最先进的方法具有更好的转移能力。

图 1.比较自然和医学数据的不同掩蔽策略。(a):现有的MIM方法屏蔽输入的自然图像,并推断缺失的内容,通过重构任务学习语义表征。(b):最近的疾病诊断预训练方法明确地在输入的医学数据(例如,医学图像和基因组)上采用MIM,而它们容易丢失微小的疾病区域并导致无法处理的重建。(c):该方法在多模态数据中屏蔽了标记特征关系,匹配了完整特征和掩码特征之间的样本关系,保留了完整的语义区域并丰富了关系信息。
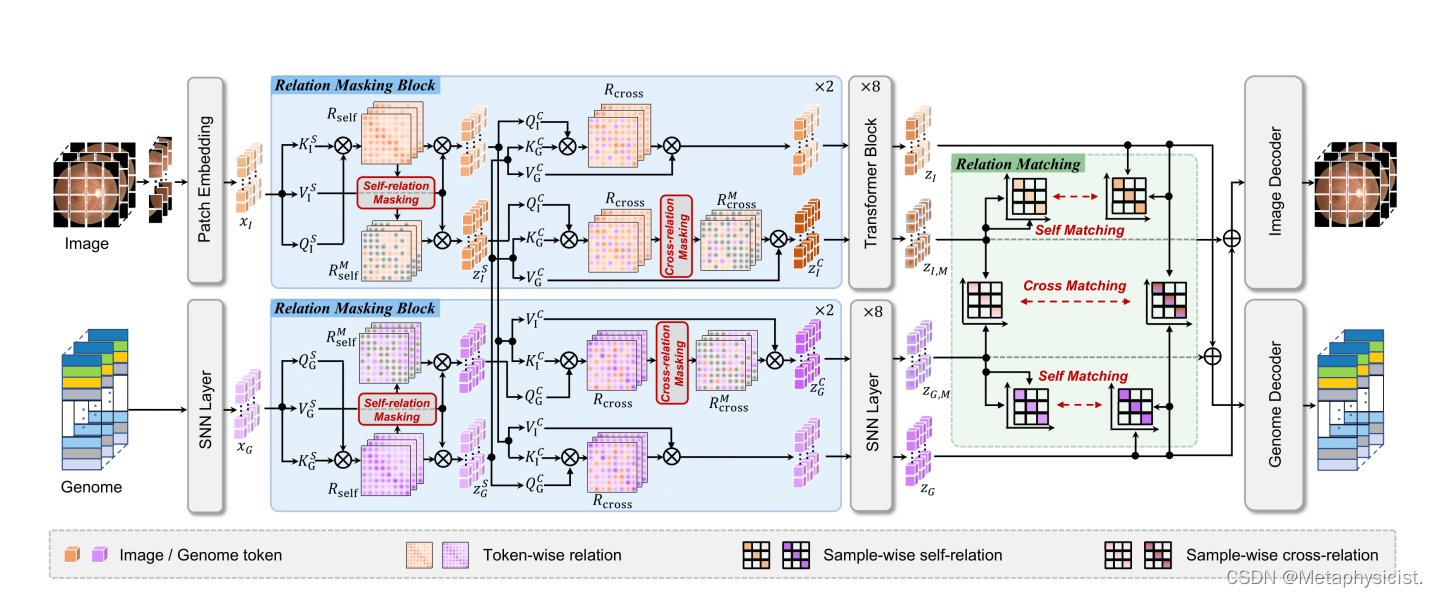
图2.掩码关系建模 (MRM) 概述。MRM 包含关系掩码,用于屏蔽标记、特征关系,同时保留与疾病相关的语义,以及关系匹配,以强制全局语义建模的样本关系一致性。
如图 2 所示,所提出的 MRM 包括关系掩蔽策略,以屏蔽特征关系并保留完整的疾病相关语义,以及关系匹配,为关系建模提供全局约束。使用输入图像习和基因组,ViT编码器fI和自归一化网络(SNN)通过关系掩蔽产生图像和基因组的掩码特征表示。同样,完整的表示由两个编码器获得,没有关系掩码。然后,将掩蔽特征,M与来自其他模态的完整特征聚合,分别得到融合特征。然后将这些融合特征放入图像解码器和基因组解码器中,以重建原始数据和。在完整和屏蔽的特征表示上采用关系匹配,并处理数据重建损失,以共同优化整体框架。
使用关系掩蔽进行重建。将输入数据输入到两个共享参数的网络中,其中第一个网络由一个 ViT 编码器组成,以产生完整的图像特征,以及一个具有自注意力块的 SNN 编码器,以产生基因组特征。同时,第二个网络在前两个注意力块中采用所提出的自模态和跨模态关系掩蔽,分别为图像和基因组生成掩蔽特征。之后,将掩蔽的特征与其他模态的完整特征合并,并产生图像和基因组的合并特征。然后将融合的特征放入解码器以重建图像和基因组。
关系掩码策略利用标记-特征关系进行掩码和重构任务。值得注意的是,尽管去除了强关系,但保留了数据中的内在信息。因此,以原始的完整图像和基因组为输入,的关系掩蔽可以保留完整的疾病相关语义。通过基于关系掩蔽的重建任务,鼓励模型恢复自我模态关系,以捕获每个模态内的疾病相关信息,并强制执行跨模态关系进行重构,学习丰富的多模态知识,以提高疾病相关表征,从而有效地转移下游诊断任务。
考虑到疾病之间的疾病感知关系在医学数据中是有限的,为了提供足够的语义关系,本文提出了关系匹配,这是一种全局约束,用于对齐自模态和跨模态样本的样本关系,以在特征空间中执行全局约束。
在预训练阶段,图像和基因组作为多模态输入被输入到模型中。采用所提出的关系掩码来生成掩码特征,并采用关系匹配作为全局约束,并结合数据重建损失来共同优化整体框架在基于下游图像的微调阶段,丢弃基因组分支,并利用图像编码器提取了特征表示,而无需进行关系掩码。在随机初始任务相关头之后,预训练的编码器在下游任务上进行微调以进行评估。
表 1.通过对四个基于下游视网膜图像的任务进行微调评估,与最先进的预训练算法进行比较。
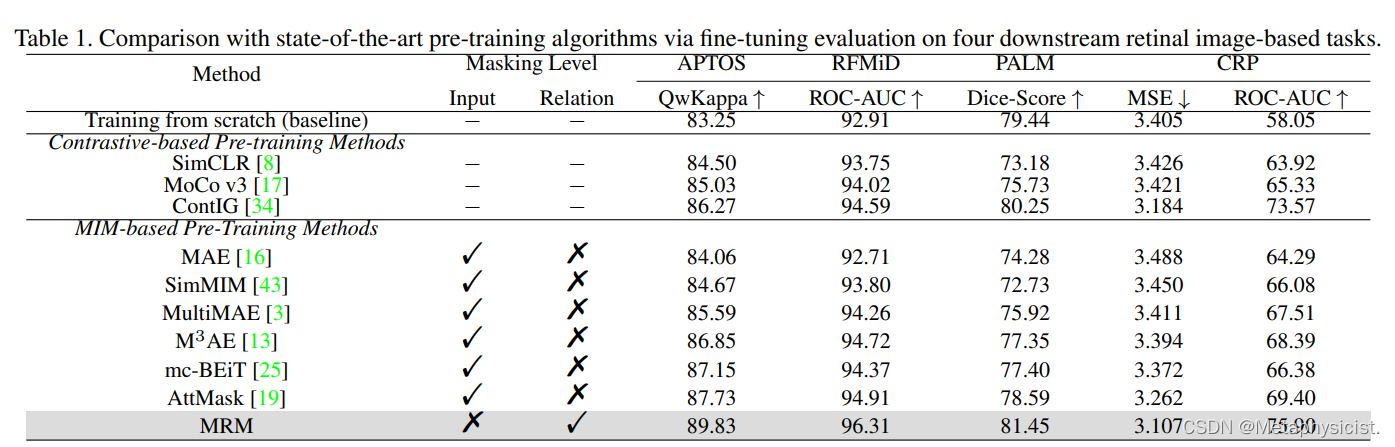
表 2.在下游病理图像任务上转换的结果。
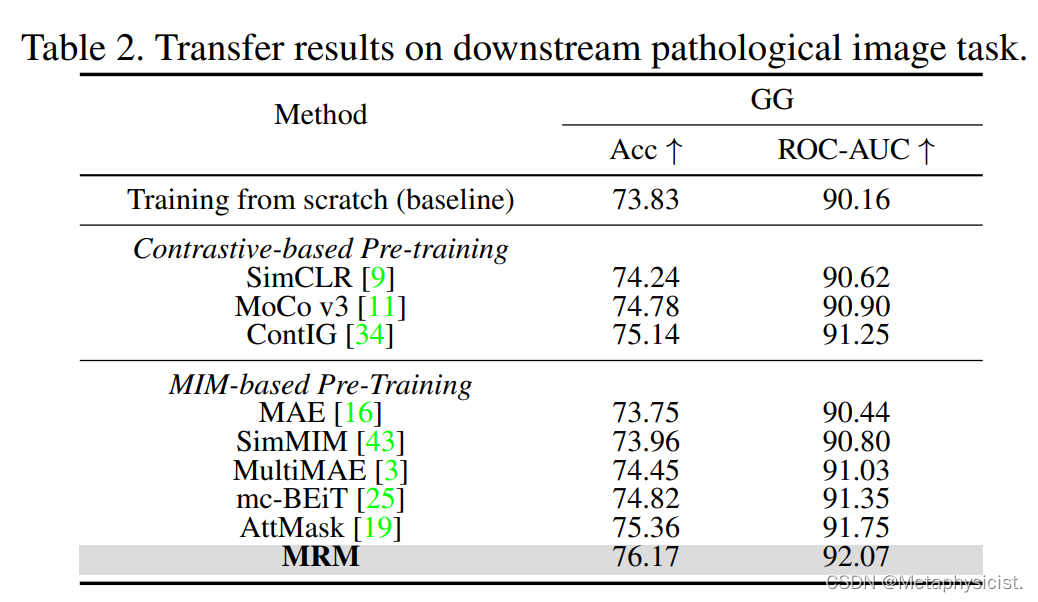
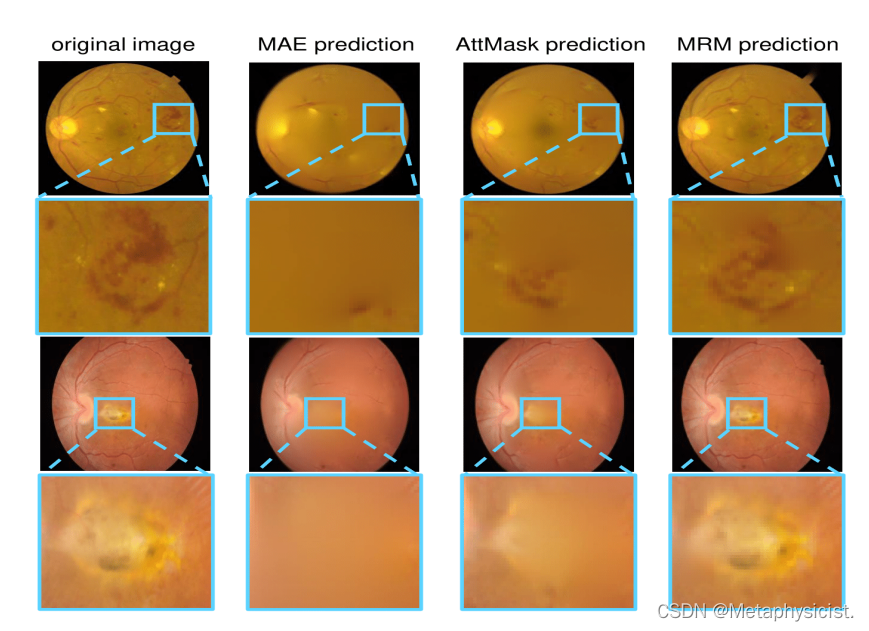
图3.不同方法重建结果的比较。从左到右分别是原始输入和MAE [16]、AttMask [19]和MRM的重建图像。可以观察到,MRM可以保留以蓝色为框架的疾病区域,而基于MIM的方法则丢失了它们。
表 3.在视网膜图像任务中,每个拟议成分在关系掩蔽和关系匹配方面的消融研究。
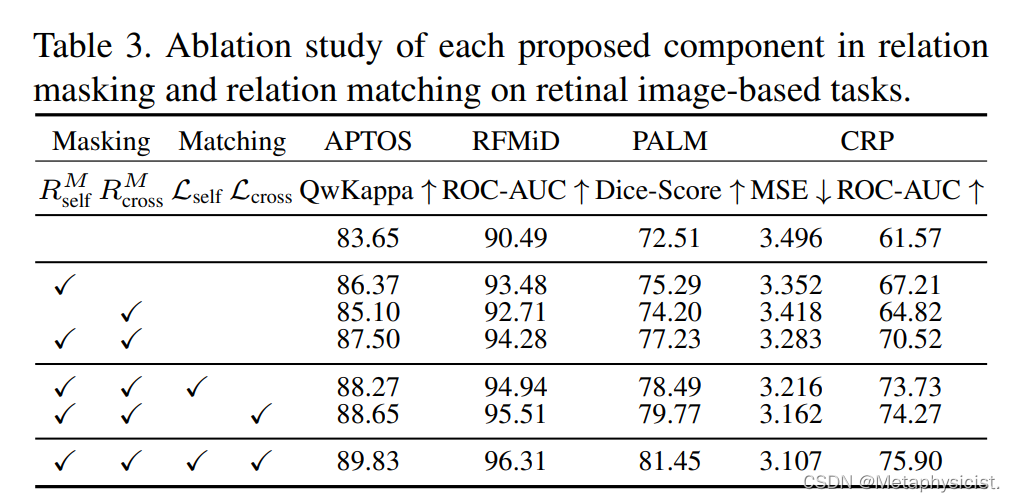

图4.消融研究。(a) 图像和基因组的掩蔽比τI和τG。(b) 两个损失函数的平衡系数λ。
表 4.基因-图像关联分析结果。
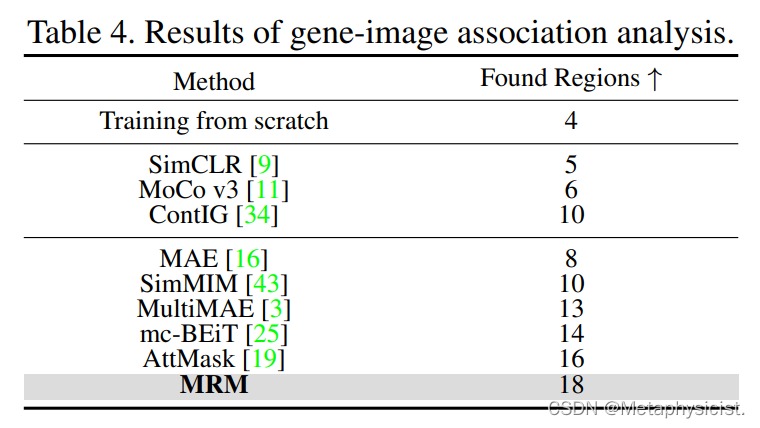
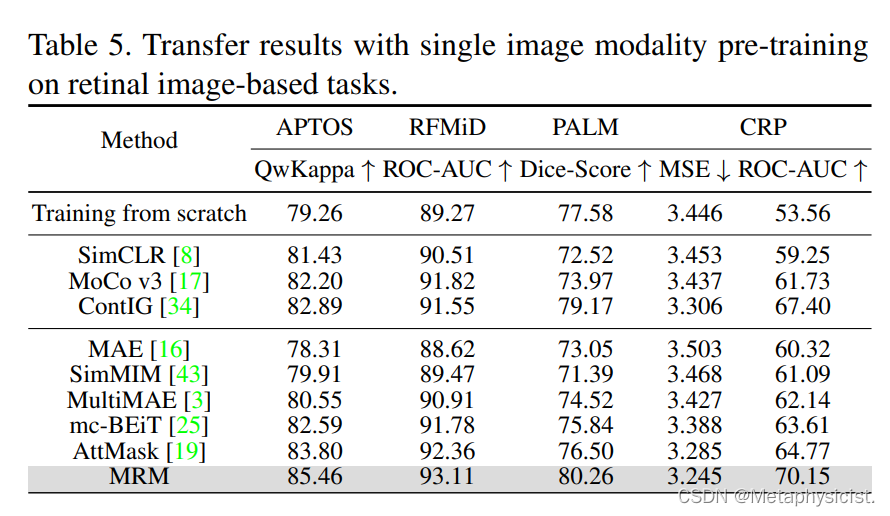
表 5.在基于视网膜图像的任务上使用单一图像模态预训练转换结果