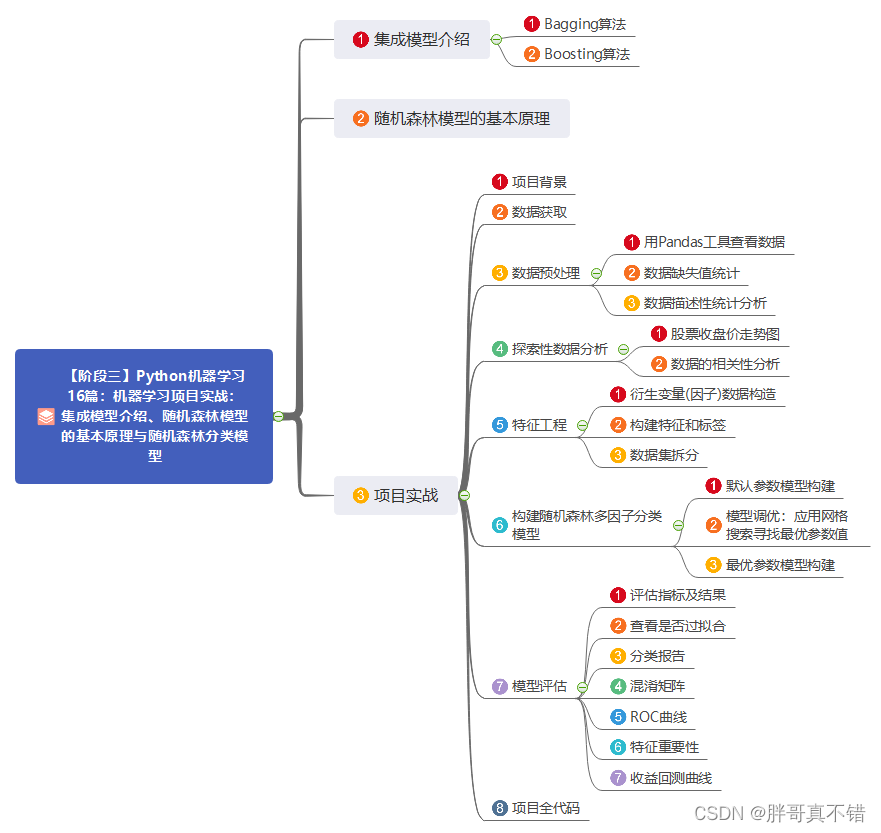
日升时奋斗,日落时自省
目录
1、文件基本认知
1.1、文件路径
1.2、相对路径
1.3、文件类型
2、Java的文件操作
2.1、文件操作类File
3、数据流读写
3.1字节流读文件
3.2、字节流写文件
3.3、字符流读操作
3.4、字符流写操作
4、文件操作案例
4.1、删除文件
4.2、普通文件复制(就是不能复制目录)
4.3、查找包含某字符的文件
1、文件基本认知
谈到文件无疑是从我们知道的开始说,狭义认知针对硬盘这种持久化存储的IO设备,当我们进行数据保存时,往往不是以以这个整体(一块内容)来保存的,而是单独保存的,这个独立的单位就在计算机中被抽象为文件的概念。
狭义:简单说就是硬盘上的文件 和 目录
文件除了有数据内容之外,还有一部分信息,例如文件名,文件类型,文件大小等并不作为文件数据类型而存在,这类信息就是文件的元信息。
广义:计算机中的软硬件资源
文件类似树结构一个文件下包含多个文件,当前文件有包含多个子文件,像树枝一样
文件的基本就是以上,没有什么特别的;
文件主要跟我们写代码有关系,之前我们写的代码,存储数据,主要是靠变量,变量是在内存中的。文件是在硬盘上的,本话题主要是如何实现代码与文件交接
1.1、文件路径
每个文件,在硬盘上都有一个具体的“路径”;

test.txt文件的路径 ,叫做E:/Test/test.txt表示一个文件的具体位置路径,就可以使用/来分割不同的目录级别.
这里注意细节的友友们,会看到图片上使用的是反斜杠(\)但是我上面打出来是 斜杠(/)
问题为什么不一样?这样写的意义是什么?
(1)其实两种写法都可以,都是对的,可以尝试一下斜杠
(2)其次就是在java中尽量写 斜杠表示法 。为什么???
因为代码去写反斜杠的不方便
例如 :java中代码:String path="E:\Test\test.txt"; 现在的\T就以个转义字符
斜杠与反斜杠肯定是有由来的 ,最早期的DOS系统使用过反斜杠 ,后来又改成了斜杠再后来Windows也继承了这样的设定。
刚刚事例中的文件路径开头都有一个大写字母C:、D:或者E:都叫做“盘符”,当然写小写也是可以的,都能起作用,盘符是通过“硬盘分区”来的,每个盘符可以单独的占一个硬盘,也可以若干个盘符占一个硬盘。
有个稀奇的问题,为啥没有a:,b:盘符?
有,但是出现的比较早,现在已经淘汰了,这样的盘符在之前叫做软盘,存储空间对于现在来说太小了只有几MB,所以喜欢了可以买个收藏
1.2、相对路径
因为绝对路径就是在“文件路径”标题下,以盘符开头的路径
相对路径:以当前所在的目录为基准,或者以..开头(也可以以.开头),找到指定路径
当前目录也称为工作目录,每个程序运行的时候,都有一个工作目录,这里来看一下相对路径是个啥,在控制台执行 打开控制台 win+r 然后输入cmd

这就是绝对路径因为它是默认的工作目录,那相对路径呢?

这俩就是相对路径了,执行程序运行的目录。(这是两个简单Windows操作系统命令,想了解更多,可以百度稍微科普一下,记几个常用就行了)
相对路径有带点的表示方式 这个可能友友们也会有困惑
先解释大体的概念 : 点+斜杠(./)就是当前所在目录,点+点+斜杠(../)就是上级目录
现在理解相对路径就不难了,以idea为例
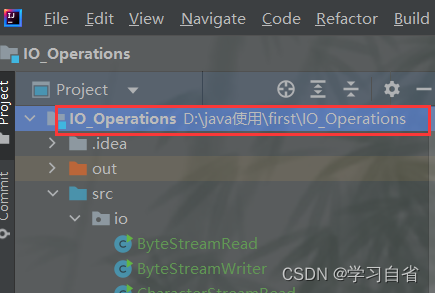
当你打开idea的时候,这个路径就是你当前所在目录(这里是我的哈,这里用作解释,你肯定跟我是不一样的) 当前文件路径:D:/java使用/first/IO_Operations
以IO_Operations文件定位
所在目录 :D:/java使用/first
现在使用点+斜杠的方式表示一下当前所在目录 :
相对路径: ./IO_Operations 工作目录 :D:/java使用/first/
相对路径: ./first/IO_Operations 工作目录:D:/java使用
相对路径: ./java使用/first/IO_Operations 工作目录: D:/
多个例子之后就不难找到 点+ 斜杠表示的规律 不管在那个目录下都表示是当前所在目录。
现在使用点+点+斜杠的方式表示一下 :../IO_Operations
IO_Operations文件的当前层目录是first所以只需要表示一个上层目录就行了,这里的java使用就是根目录 所以表示如上。
再举一个事例:D:/java使用/first/IO文件/IO_Operations (稍作修改)
同样以IO_Operations文件定位
现在使用点+点+斜杠的方式表示一下 :../../IO_Operations
这里只需要到到达根目录就行,当前层目录是IO文件 根目录是Java使用,相当于连跳两级,两个../就可以解决问题
1.3、文件类型
文件类型我们看见过很多种,word文件 ,exe程序,图片,视频等,虽然很多种但是文件还是分为两个大类;
(1)文本文件 (存的是文本,字符串)
字符串是由字符构成,字符是怎么写上去的,通过数字表示,能存储的一定都是合法的字符,因为会按照你指定的字符编码表进行查找对应的数字,然后进行存储
(2)二进制文件(存的是二进制数据,不一定是字符串了)
没有限制是不是字符都可以存,(光脚的不怕穿鞋的)
区分两种文件:能看的懂的就是文本文件(主要特征不乱),看不懂的就是二进制文件(乱)
2、Java的文件操作
2.1、文件操作类File
java标准库提供的一个File类,用于创建文件对象,这里叙述只三个构造方法(当然还有很多,有兴趣的友友,idea中查看或者API官方文档)
![]()
该构造方法带有两个参数 第一个参数是父目录 +孩子文件路径 两者都是用路径表示
![]()
该构造方法带有两个参数,第一个参数是父目录 +孩子文件路径,父目录就不需要路径了,直接放就行。
![]()
该构造方法就一个参数==>路径
说到路径这里解释一个问题,就是写路径的时候写斜杠还是反斜杠,由于的话就写separator针对Windows(是File里的一个静态变量)斜杠还是反斜杠就可以不用担心了,它会跟随系统
File file=new File("e:"+File.separator+"test.txt");如上写法就行,把斜杠或者反斜杠换成该静态方法
(1)再提一些File类中简单方法 以下方法相关 文件名 ,父目录,,文件路径,绝对路径,相对路径
public static void main(String[] args) throws IOException {
File file=new File("e:"+File.separator+"test.txt");
System.out.println(file.getName()); //获取文件名字
System.out.println(file.getParent()); //获取文件父目录
System.out.println(file.getPath()); //获取文件路径
System.out.println(file.getAbsoluteFile()); //获取绝对路径
System.out.println(file.getCanonicalFile()); //获取相对路径 此时 要抛出异常 快捷键 alt+enter(也就是回车)
}代码中只有相对路径比较特殊需要抛出异常 快捷键 alt+enter(enter也就是回车)。
提示:文件路径不用敲出来,直接复制粘贴就行,在同一个系统上的话不会错,如果不同系统也不放心的情况下使用 刚刚的静态方法就可以了(它会自己对应不同系统)
(2)以下代码解释方法 :文件存在,是否是文件 ,是否是目录 ,创建我呢间
public static void main(String[] args) throws IOException {
File file=new File("./test.txt");
System.out.println(file.exists()); //当前文件是否存在
System.out.println(file.isFile()); //是不是文件
System.out.println(file.isDirectory()); //是不是目录
file.createNewFile(); //创建文件
System.out.println(file.exists()); //当前文件是否存在
System.out.println(file.isFile()); //是不是文件
System.out.println(file.isDirectory()); //是不是目录
}File类创建对象的时候,本身是不会创建文件,这里有专门的方法创建文件,这里是以相对路径创建文件的所以会在idea的目录上显示(以下是过程及问题解决)
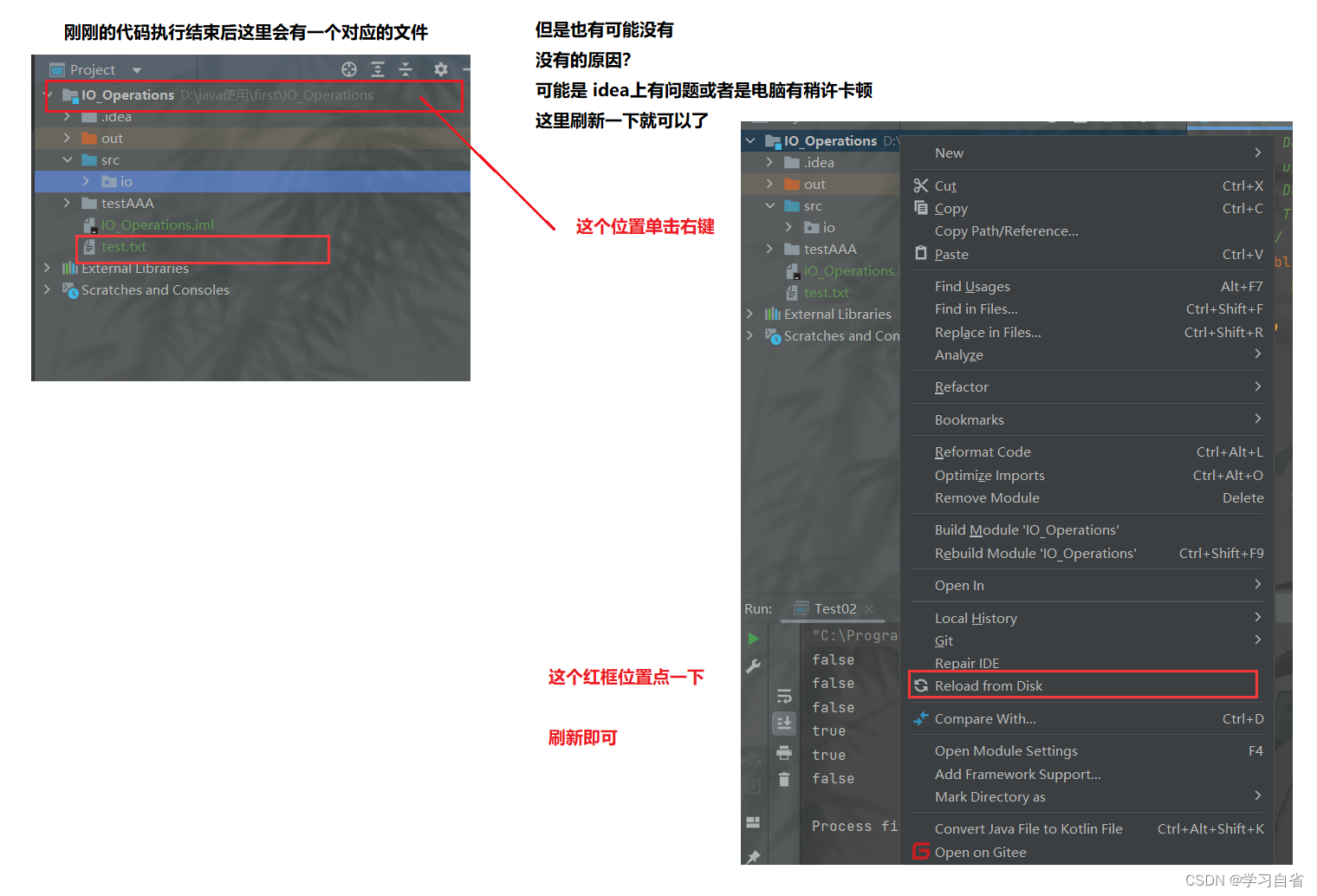
(3)以下是 删除文件,创建目录,还有替换文件名称
删除方法:delete 这个就没有过多的解释了
删除临时文件:deleteOnExit 方法 程序退出的时候,自动删除,临时文件程序有时候也会用到,啥是临时文件,咋没有见过???

public static void main(String[] args) {
//创建文件目录
File dir=new File("./test/aaa/bbb");
/*
* 创建多级目录的时候就需要 mkdirs
* */
dir.mkdirs(); //如果是创建一个目录的话 就使用 mkdir
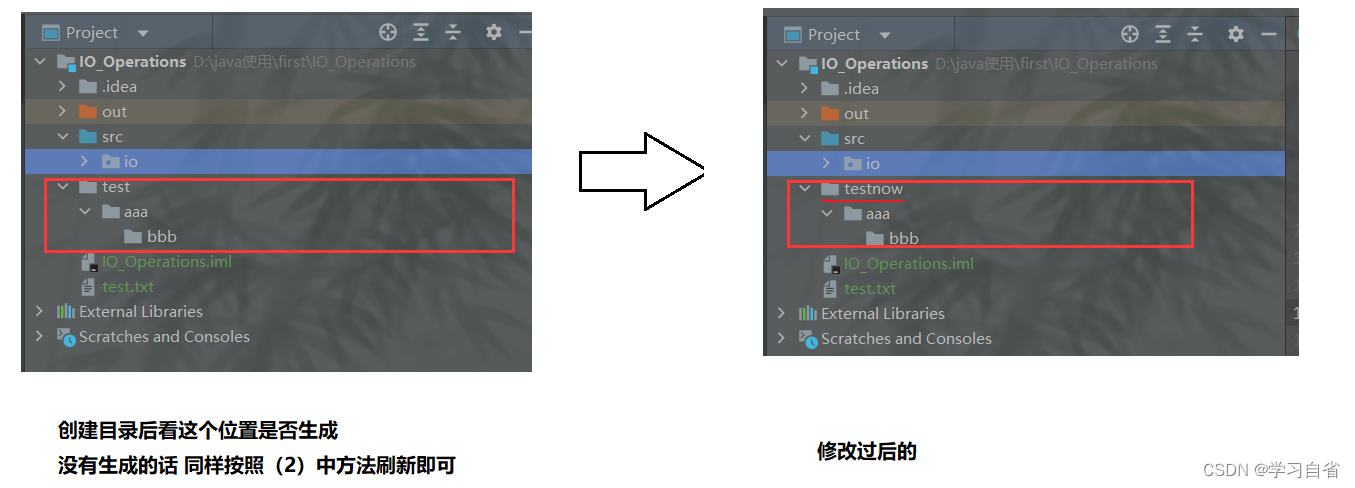
}public static void main(String[] args) {
//修改文件名称
File file=new File("./test");
File file1=new File("./testnow");
file.renameTo(file1); //修改昵称
}
3、数据流读写
使用“流对象”进行操作 如何理解流???
“流”字联想起来跟水有关系,水流 连绵不断,没有固定形状,那就可以划分多次,也可以不划分。以接水为例: 一家人需要水是固定量的,但是接水的次数是不定的
(1)可以一次接完
(2)也可以先接一半
(3)还可以将需要水分5次来接
这就是水流的提点,为什么会以流来解释到水,因为读字节 与 写字节也是如此
从文件中读取字节情况很多,可能一次读完,可能一次读不完,像水一样
(1)可以直接一次性读(写)完
(2)分两次读(写)完
(3)分多次读(写)完
流类型上分为两类 :字节流 、字符流
(1)字节流 相关类 FileInputStream ->(继承) InputStream 、FileOutputStream->OutputStream
![]()
(2)字符流 相关类 Reader ->(继承)FileReader 、 Writer->(继承)FileWriter
![]()
为什么会有继承这一说?
![]()
是因为这里InputStream/OutputStream/Reader/Writer都是抽象类是不能创建对象的。
3.1字节流读文件
读文件操作使用InputStream和FileInputStream两个类进行。
InputStream inputStream=new FileInputStream("e:/test.txt");创建对象,赋予文件路径即可
//进行读操作
while(true){
//获取字节对应的数字
int n=inputStream.read();
if(n==-1){ //文件读到末尾了也就是结束 此时read返回-1
break;
}
//因为获取的是数字,所以这里需要进行转换byte类型
System.out.println("字节流打印 "+(byte)n);
//如果是文字的话 就该以十六进制来打印了 可以去查字符表就能知道是什么了
System.out.printf("%x \n",(byte)n);
}以上两个写在一个main方法中就可以尝试了,这里说一下read方法在写的时候会抛出异常;有友友肯定疑惑这里的read读的返回值为啥是int,首先是方法这么定的,然后就是手动转化成byte类型就行;InputStream提供了三个重载方法read;

(1)read无参数版本一次读一个字节
(2)read有一个参数的版本 把内容一次填充提到byte数组中(这里相当于“输入型参数”)
(3)read 三个参数版本 其实就比(2)多了个范围从第几个开始多长
注:字节对于打印汉字可以使用16进制,对照编码表查找针对不同的(例如utf8,gbk,BIG5)根据自己需求对照即可(所以说字节流也是可读文本文件的)
这里再写一下read两个参数的代码(三个参数与两个参数大体相同就不在展示),前面创建对象是一样的,以下部分不同
//read带有一个参数时进行读取
while(true){
//首先需要准备一个数组 这里的字节数 可以随心所欲设置(有点夸张)意思明白即可。
byte[] buffer=new byte[1024];
//这里的传参操作就是把刚才的数组传进去, 计算的当前多少个字节
int len = inputStream.read(buffer);
System.out.println("len "+len);
if(len==-1){
break;
}
//读取就结果同样时转换成byte
for(int i=0;i<len;i++){
System.out.printf("%x \n",buffer[i]);
}
}上面给出的数组长度是1024,read就会尽可能的读取1024个字节,填到数组里,但是实际上,文件剩余长度是有限的,如果文件剩余长度超过了1024此时就只能接收到1024个字节,同时并进行打印,然后再次执行while循环,如果当前剩余的长度不足1024,此时有多少就返回多少。
注:读文件的时候,文件在磁盘上内容可能比较多,甚至超出内存容量,一次读完是不显示的,对此类文件操作都是一边读一边处理,处理好了一部分,再处理下一个部分
有一个问题,这里的数组名为什么刚好叫做buffer???
答案:buffer翻译为缓冲区,存在的意义就是提高IO操作的效率,单次IO操作,是要访问硬盘IO设备,单次操作是比较消耗时间的,如果频繁进行这样的IO操作,同样要耗费不少时间。这里很像mysql的插入操作,插入一组传给服务器也是消耗时间的,不如一次插入多组。
单次IO时间是一定的,缩短IO次数就会提高整个程序效率,第一个版本的代代码一个一个read次数多时间长;第二个版本是一次read1024个字节,循环降低了很多,也就是IO次数下降很多。
3.2、字节流写文件
OutputStream类来进行字节流写文件
public static void main(String[] args) throws IOException {
OutputStream outputStream = new FileOutputStream("e:/test.txt"); //字节流写 也是会报一个找不到文件的操作的
outputStream.write(97);
outputStream.write(98);
outputStream.write(99);
outputStream.write(100);
//记得关闭文件
outputStream.close();
}下面的操作用图解释

确实我们一般也都会续着写,当然不想清空,流对象还提供了一个“追加写”对象,通过这个就可以实现不清空文件把新内容写在后面。
解释一下:input(输入),output(输出)为什么在代码中input是写入程序,output是写文件??
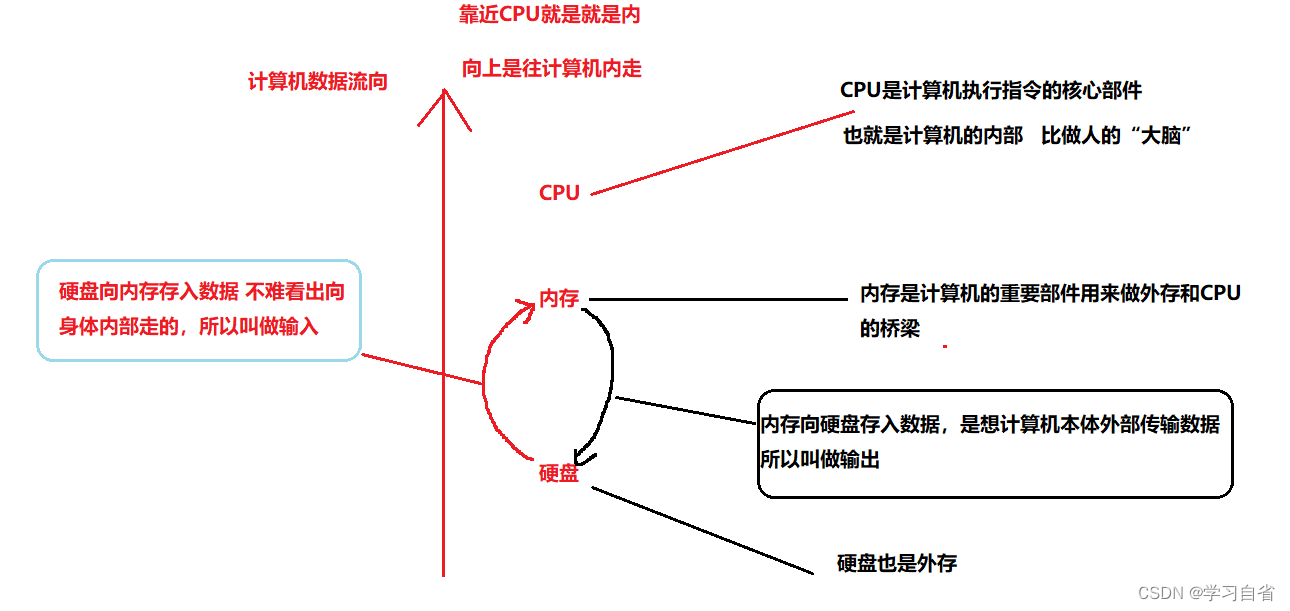
字节流写入涉及到了关闭文件的操作 close操作(尽量不要忘记)
为什么要写文件结束的时候要close?
进程->在内核里,使用PCB这样的数据结构来表示进程 (这里也有介绍PCB)
一个线程对应一个PCB
一个进程可以对应一个PCB也可以对应多个
PCB中有一个重要的属性叫做文件描述符表(相当于一个数组)记录了该进程打开那些文件,(即使一个进程里有多个线程也会有多个PCB)

如果真忘了写close操作会有什么问题?
针对java来说还好,但是其他语言不能保证,例如C语言自身就没有GC(Garbage collection)功能,在java中GC操作会回收这个OutputStream对象的时候去完成释放操作,但是GC不一定能准时回收,可能再我们下次一使用的时候GC还没有回收
所以,如果不入手动释放,意味着文件描述符表可以能会被占满(文件描述符表不能自动扩容言外之意就是会满,满了就会卡主,不能用了),文件描述符表不同系统长度不同,但是肯定不大,长度撑死就是几千,对于计算机对于几千几百还是太小了。
特殊情况:close一般情况是执行的,如果一个程序对这个文件一直都需要使用,那文件直到进程结束,PCB销毁,文件描述符表也就销毁了,文件资源会被自动回收(所以文件close之后,程序立即结束了,你忘了关闭,java会自动回收的)
注:虽然java有自动回收功能,但是尽可能手动回收
那出来手动结束,程序能不能自己来结束??答案: 能 所以有了更优雅的代码
try(OutputStream outputStream=new FileOutputStream("e:/test.txt")){
outputStream.write(97);
outputStream.write(98);
outputStream.write(99);
outputStream.write(100);
}使用try()这个写法虽然没有显示close,实际上是会执行的,try语句块执行结束就可以自动执行close操作,该语法被称为try with resources,但是不是说try中谁都可以放置,来看看为啥OutputStream可以?
![]()
实现了Closeable接口就可以该接口提供了close方法
3.3、字符流读操作
与字节流差不多使用,就是读的时候是一个字符一个字符读的,读文本的时候方便(因为读了能看懂)以下代码简单的读取文件内容
//字符流读操作
public static void main(String[] args) throws IOException {
try(Reader reader=new FileReader("e:/test.txt")){
while(true){
int ch=reader.read();
if(ch==-1){
break;
}
System.out.print(""+(char)ch);
}
}
}public static void main(String[] args) {
// Scanner scanner=new Scanner(System.in); 该种输入方式 返回的是字节流 只是读取的键盘信息
try(InputStream inputStream=new FileInputStream("e:/test.txt")){
Scanner scanner=new Scanner(inputStream);
//此时读取就是从文件中读取
scanner.next(); //此处不建议使用nextLine
} catch (IOException e) {
throw new RuntimeException(e);
}
}借读操作来介绍Scanner ,其实该类是搭配流对象进行使用的,这就是为什么我们每次写Scanner创建对象的时候都会在参数里写 System.in ,这是一个输入流与键盘相连能接受键盘传来的信息。
同样Scanner本身就是字节流所以可以放字节流对象。
3.4、字符流写操作
//字符流写操作
public static void main(String[] args) {
try(Writer writer=new FileWriter("e:/test.txt")){
writer.write("hello world");
writer.flush(); //每次写入都需要耍新缓冲区 , 为缓冲区不能总发着会进行覆盖
} catch (IOException e) {
throw new RuntimeException(e);
}
}writer写操作解释:写操作是先写在缓冲区里的,(缓冲区存在很多种形态,咱们自己的代码里也会有缓冲区;标准库里也可以有缓冲区,操作系统内核里也可以有缓冲区)
写操作执行完了,内容仍然可能在缓冲区里,还没有真的进入硬盘。
close操作,就会触发缓冲区的刷新,刷新后缓冲区将内容写到硬盘中,出来close之外还有别的方法,flush方法进行刷新,close方法一旦关闭文件后就不能在对文件操作了,flush方法进行刷新后仍然可以对文件操作。
4、文件操作案例
4.1、删除文件
扫描指定目录,并找到要删除的文件名称(不包含目录),并且后续访问到会问用户是否删除该文件(以下代码均有注释)
思路:
(1)第一次需要输入根目录 并且判断当前输入的是否是目录
(2)第二次需要输入你要删除的文件名称
(3)输入目录后不一定就是当前我们需要的目录,里面可能还包含了很多子目录,此时就需要递归了,文件是成树形结构的,所以次数采用深度优先进行遍历
(4)递归条件如果文件为空则返回,如果不为空 判断是否是目录如果是目录则继续递归,如果不是目录if判断当前文件中有是否包含删除文件名,包含再次判定是否需要删除即可
private static Scanner scanner=new Scanner(System.in);
public static void main(String[] args) {
//用户输入一个指定文件路径
System.out.println("请输入要搜索的文件路径");
String basepath=scanner.next(); // 提醒使用next就可以
//针对用户输入路径简单判断
File root=new File(basepath);
if(!root.isDirectory()){
//当前路径不存在或者不是一个文件 提醒一下
System.out.println("用户输入文件有误!!");
return;
}
//如果没有问题就进入下一步
//输入要删除的文件
System.out.println("请输入要删除的文件名称");
String deletename=scanner.next();
/*
* 前面是输入一个目录但是不一定当前目录下没有子目录
* 先从根本目录出发
* 先判定一下,当前目录里,看看是否包含要删除的文件, 如果是就删除 否则就跳过下一个
* 如果当前这里包含一些目录,针对目录进行递归
* */
scanDir(root,deletename);
} private static void scanDir(File root, String deletename) {
//列出root下的文件和目录
File[] files=root.listFiles(); //数组接收了当前文件目录
if(files==null){
//当前文件是空 ,就没有判定的需要了直接返回
//按递归的思想就是 这里不行这条路径就结束了
return ;
}
//开始进行遍历
for (File f:files) {
if(f.isDirectory()){
//如果是目录的话 就继续递归
scanDir(f,deletename);
}else{
//另一种 不是目录的话,只要包含就可以删了
if(f.getName().contains(deletename)){
System.out.println("已经找到要删除的文件是否要删除"+f.getAbsolutePath());
//找到之后 让用户确定是否要删除 如果删除 就输入 确认删除
String choic=scanner.next();
//用户输入后 进行判定
if(choic.equals("确认删除")){
f.delete();
System.out.println("删除成功");
}else{
System.out.println("删除取消");
}
}
}
}
} 运行结果和执行过程
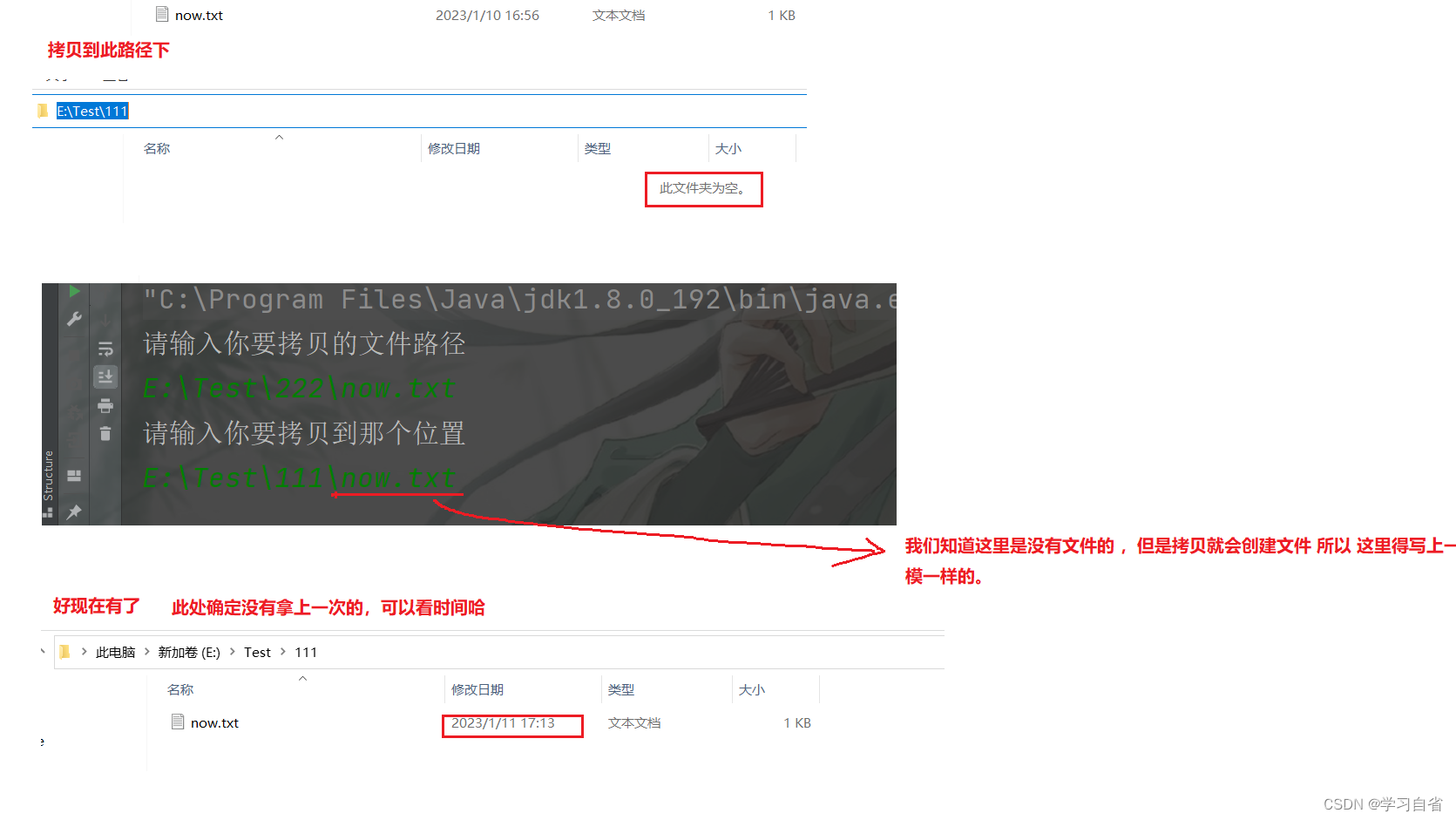
4.2、普通文件复制(就是不能复制目录)
思路:
(1)输入你要拷贝的文件路径包括当前你要拷贝的文件名(这先叫做被拷贝文件)
(2)输入你要拷贝在哪里这里还需要你写相同的文件名,因为是拷贝 (这里就叫做拷贝文件)
(3)两次输入完成之后 判定你要被拷贝的文件必须存在并且判定拷贝文件不能存在(要不这不就覆盖了)
(4)判定结束说明没有问题,字节流输入 输出创建 对象开始进行被拷贝文件输入拷贝文件输出(FileOutputStream会自动创建文件)
//拷贝文件
public static void main(String[] args) {
//输入两个路
// 源文件 和 目标文件
/*
* 解释 一个 思路就 拷贝出来的文件肯定是不存在的
* */
Scanner scanner=new Scanner(System.in);
System.out.println("请输入你要拷贝的文件路径");
String srcPath=scanner.next();
System.out.println("请输入你要拷贝到那个位置");
String destPath=scanner.next();
File srcfile=new File(srcPath);
//首先就是你要拷贝的地方要有东西 ,所以这个文件他一定是要存在的
if(!srcfile.isFile()){
//如果文件不存在 ,也就不存在打印这一说了 可以结束了
System.out.println("原文件路径有问题");
return ;
}
File desfile=new File(destPath);
//这个拷贝文件也需要判定,为什么呢,因为如果有重复就会产生覆盖
if(desfile.isFile()){
System.out.println("拷贝文件名重复");
return ;
}
//进行拷贝 try() 里面是可以放多个 字节流对象的 分号隔开
try(InputStream inputStream =new FileInputStream(srcfile);
OutputStream outputStream=new FileOutputStream(desfile)){
//进行文件读操作
while(true){
int b=inputStream.read();
if(b==-1){
break;
}
outputStream.write(b);
}
} catch (FileNotFoundException e) {
throw new RuntimeException(e); //这个异常其实可以删除了,删除了也不会影响
} catch (IOException e) {
throw new RuntimeException(e); //前面的异常继承该异常 所以都是同一个在起作用
}
}运行结果及执行过程
4.3、查找包含某字符的文件
扫描指定目录,并找到名称或者内容中包含指定字符的所有普通文件(不包含目录)
思路:
(1)第一步输入需扫描的文件路径 判定路径是否是目录
(2)创建一个List集合用来装包含这些字符的文件路径
(3)写一个深度优先遍历 因为给的当前路径也可能包含多个子目录,这里需要文件数组来接收当前文件列表该方法是 (listFiles),然后进行判定如果数组为空或者数组长度为0就递归返回,然后操作将文件分别进行判定是目录的就继续递归,如果不是就进行扫描是否有我们需要的字符出现(这里需要写一个方法来判定是否有这些字符)
(4)判定是否有这些字符的方法 采用思路:使用StringBuilder 来接收文件中的所有字符,然后判定如果该字符在StringBuilder对象中就返回true
注:以下三个代码是写在一个类中的,后面里两个是第一个代码中调用的自定义方法
public static void main(String[] args) throws IOException {
Scanner scanner=new Scanner(System.in);
System.out.println("请输入要扫描的的根目录");
String rootDirPath=scanner.next();
//输入路径直接使用文件创建对象
File rootdir=new File(rootDirPath);
//判定当前文件是否是目录
if(!rootdir.isDirectory()){
System.out.println("您输入的根目录不存在或者不是根目录");
return ;
}
System.out.println("请输入要找出的文件的字符");
//输入字符即可
String token=scanner.next();
//创建一个List集合是为了 接收包含字符的路径
List<File> result=new ArrayList<>();
//文件成树形结构 深度优先遍历
scanDirWithContent(rootdir,token,result);
//以下就是基础的打印方法,就不多介绍了
System.out.println("共找到了符合条件的文件" + result.size());
for(File f:result){
System.out.println(f.getCanonicalPath());
}
}private static void scanDirWithContent(File rootdir, String token, List<File> result) {
//这里是用了一个文件列表的方法 listFile 返回的是一个数组 用文件数组接收
File[] files=rootdir.listFiles();
//判定文件是 为空返回 文件长度为0返回也就是啥都没有写
if(files==null||files.length==0){
return ;
}
//如果有文件 将文件分开分别判断
for (File file: files){
//如果是目录的话就再递归
if(file.isDirectory()){
scanDirWithContent(file,token,result);
}else{
//如果是文件 就要进行字符查找了, 写一个方法进行字符查找
if(isContentContains(file,token)){
//如果查找到了就添加路径
result.add(file.getAbsoluteFile());
}
}
}
}private static boolean isContentContains(File file, String token) {
//这里采用StringBuilder是因为可变性
StringBuilder sb=new StringBuilder();
//字节流输入中放入文件路径 Scanner可以放入字节流 使用更多方法
try(InputStream inputStream=new FileInputStream(file);
Scanner scanner=new Scanner(inputStream,"UTF-8")){
//这下就完事了,正常将每个字符接收到 StringBuilder对象中
while(scanner.hasNextLine()){
sb.append(scanner.nextLine());
sb.append("\r\n");
}
} catch (FileNotFoundException e) {
throw new RuntimeException(e);
} catch (IOException e) {
throw new RuntimeException(e);
}
//返回这里不要感觉难 其实不难,查找找的字符串如果存在的话sb返回值就是一个正数数值 !=-1也就是true
return sb.indexOf(token)!=-1;
}运行结果及执行过程: