Transformer论文阅读
- 摘要
- 结论
- 1 Introduction (导言)
- 2 Background
- 3 Model Architecture
- 3.1 Encoder and Decoder Stacks
- Encoder
- Layer Norm
- Decoder
- 3.2 Attention
- 3.2.1 Scaled Dot-Product Attention
- 3.2.2 Scaled Dot-Product Attention
- 3.2.3 Applications of Attention in our Model
- 3.3 Position-wise Feed-Forward Networks
- 3.4 Embeddings and Softmax
- 3.5 Positional Encoding
- 4 Why Self-Attention
- 5 Training
摘要
主流序列转录模型使用rnn或cnn,使用encoder和decoder,在好的模型中通常也会使用注意力机制。本文提出一个简单的架构,仅仅依赖注意力机制,并行度更好,训练更快。在机器翻译上结果很好。
结论
1.本文提出的Transformer是第一个纯注意力机制的序列转录模型,使用multi-head self-attention替代了之前的r循环层RNN结构。
2.在机器翻译上,比其他架构都要快,效果较好。
3.使用在其他数据领域上,文本以外的数据。
1 Introduction (导言)
1.RNN、CNN以及encoder-decoder架构
2.RNN特点缺点:对第t个词会计算隐藏状态ht,由前一个词的ht-1和当前词t决定。
- 时序一步步计算,难以并行
- 历史信息一步步向后传续,时序信息较长时,容易遗忘
3.attentionj机制在rnn上的应用。
4.提出新的架构transformer
2 Background
如何使用CNN 替换RNN减少时序计算,对长序列难以兼容;CNN计算通过较小的窗口,长距离需要交多卷积层。但卷积优点多通道机制,可以识别不同的模式。提出多头注意力机制multi-head self-attention,模拟CNN多通道输出的效果。
3 Model Architecture
1.encoder-decoder
编码器:input为(x1,…xn),输出为z=(z1,…zn)的向量
解码器:拿到encoder输出,生成长为m的序列(y1,…ym),词一个个生成,自回归auto-regressive的方式来输出的,过去时刻的输出也会作为当前时刻的输入。
2.Transformer是一个encoder-decoder的架构,主要组成是self-attention和point-wise fully connected layer,结构如下:
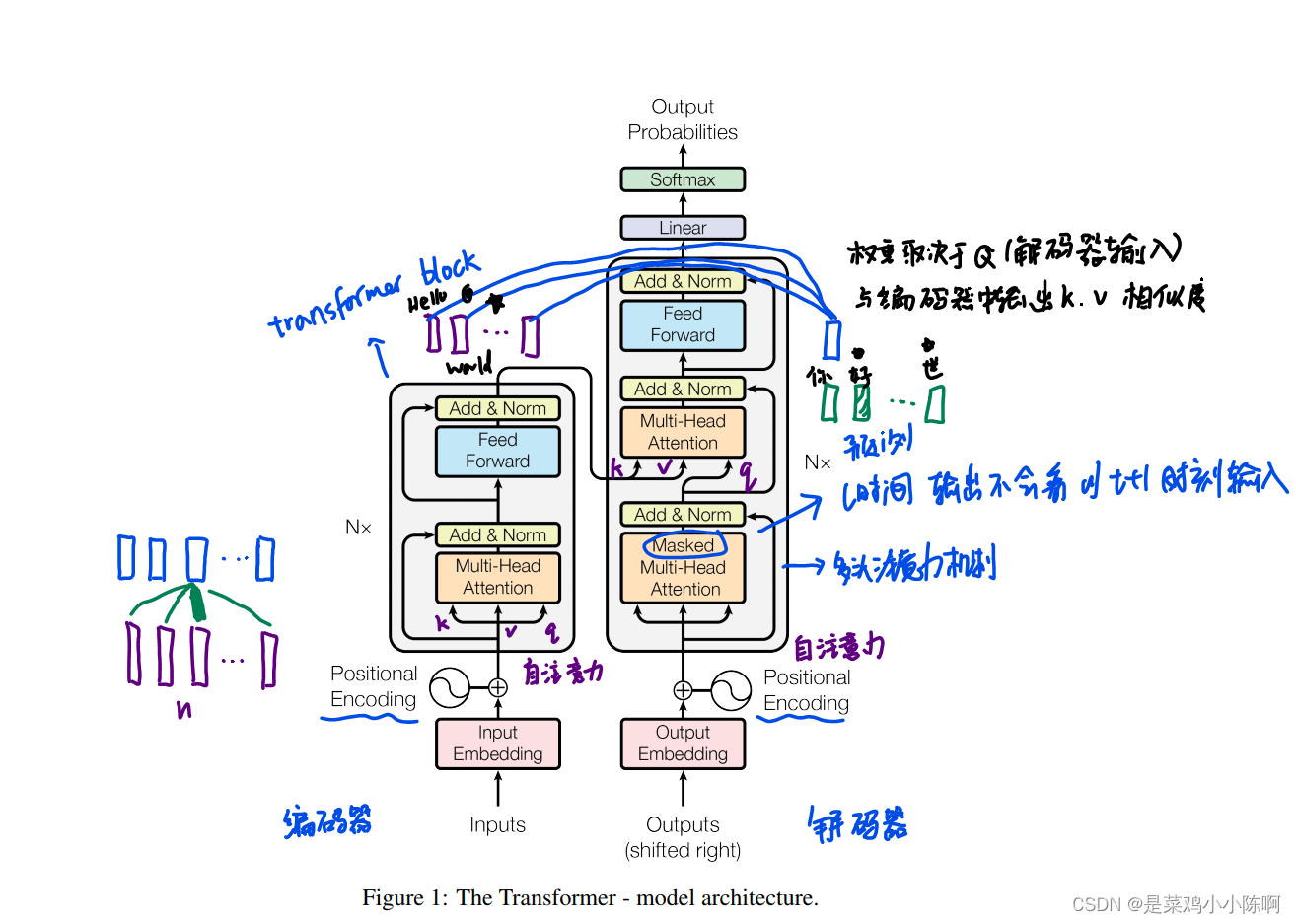
3.1 Encoder and Decoder Stacks
Encoder
1.Encoder由N=6个一模一样的层组成;
2.每个层包含2个子层:①multi-head self-attention layer,②position-wise fully connected feed-forward network (就是个MLP);
3.每个子层,使用residual connection和layer norm来处理,子层的输出都可以表示为:LayerNorm(x + Sublayer(x))
为了方便残差连接,所有的层都使用d=512作为输出维度。
Encoder就俩超参数:N和d。这种设计直接影响了后面各种基于Transformer的模型设计,比如BERT,GPT等等,都主要调节这两个参数。
Layer Norm
- Batch Norm
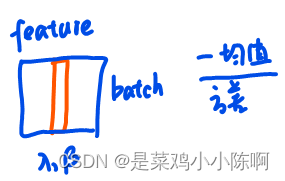
- Layer Norm
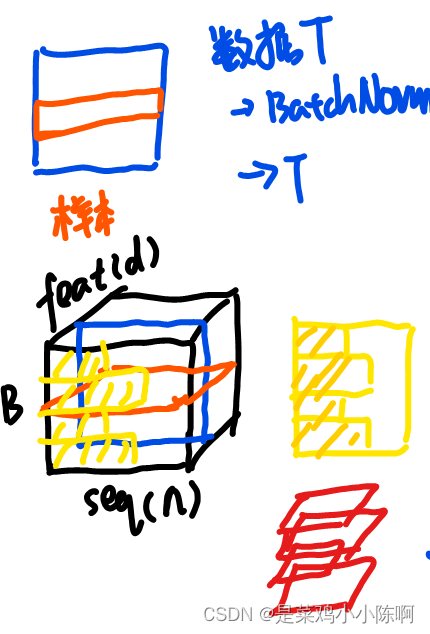
因为序列的长度会变化,如果使用batch norm的话,可能导致均值方差波动很大,从而影响效果,而layer norm则是逐个样本去进行的,就不会受影响。
Decoder
1.跟Encoder一样由N=6个一模一样的层构成;
2.每个层包含3个子层,比Encoder中多了一个multi-head attention layer;
3.为了防止Decoder在处理时之后输入,使用了一个mask的注意力机制。保证在t时间不会看到t时间以后输入。
3.2 Attention
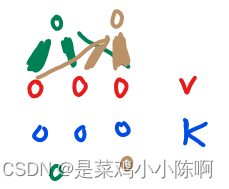
将query和一些key-value对映射成一个输出的函数。
output是value的加权和,output D=value D
value的权重,value对应的key和查询的query的相似度计算而来。
3.2.1 Scaled Dot-Product Attention
queries 和 keys维度相等都是dk。value和output维度为dv。query和每个key做内积再除以根号dk ,在利用softmax得到一个权重。
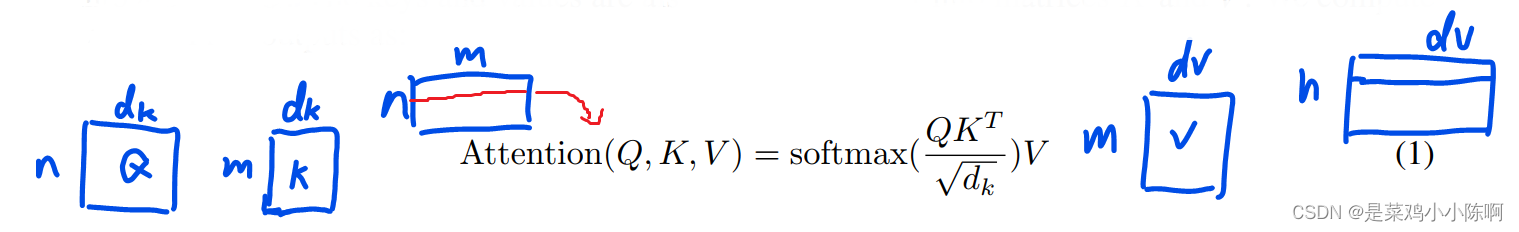
常用两种注意力机制:
additive attention加性注意力机制,处理query和key代码不等长情况;
dot-product Attention点积注意力机制
与dot-product Attention区别和原因:
多了一个scale项
1.当dk不是很大,影响较小
2.当dk较大时,内积的值的范围就会变得很大,值较大的差距也会拉大,做出的softmax加靠近语义,其他值更加靠近0。值更加向两端靠拢,此时梯度较小。
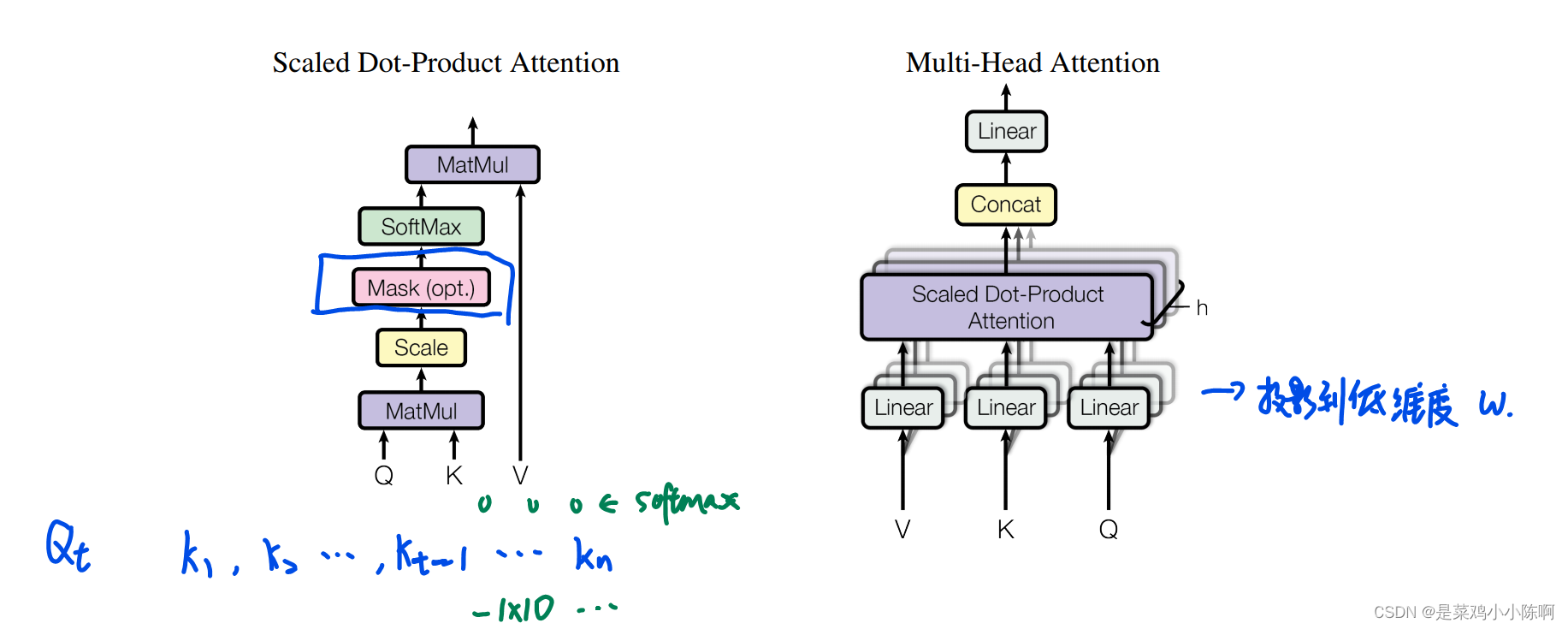
在计算权重输出时,不要用到后面的值。加入mask,对于Qt和Kt之后计算的值,赋值为非常大的负数,在softmax时会变为0。
3.2.2 Scaled Dot-Product Attention
整个query、key、value投影到一个低维度 ,投影h次,再做h次注意力机制,每个输出contact 再投影回来得到最终输出。

投影到低维w,h次机会学习不同投影的方法,使得在投影进去的度量空间中能匹配不同模式需要的相似函数。类型与CNN多个输出通道。
3.2.3 Applications of Attention in our Model
三种使用情况
1.encoder,key、query、value是同一个。自注意力机制。
2.decoder, 自注意力机制+mask
3.decoder, 多头注意力机制,key 、value来自encoder输出,query是解码器下一个attention输入
3.3 Position-wise Feed-Forward Networks
对每个position(词)都分开、独立地处理。
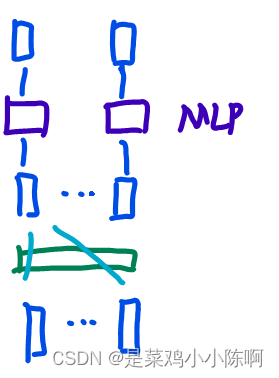
attention:把整个序列信息抓取做aggregation。因此,投影做mlp中,只需要对每个点独立做就可以了。
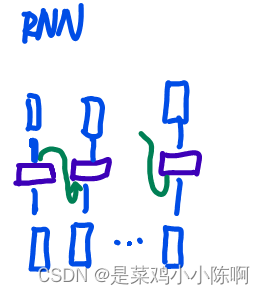
Transformer是通过attention来全局地聚合序列的信息,通过MLP进行语义空间的转换;
RNN把上一时刻的信息传入下一时刻的单元,通过MLP进行语义空间转换。二者本质区别在于如何使用序列的信息。
3.4 Embeddings and Softmax
embedding:任何一个词,学习成一个向量d来表示
三个embedding:对input和output的token进行embedding,以及在softmax前面的Linear transformation中使用embedding
三个embedding使用相同的权重。
embedding都乘上了,
1.embedding学习时将每个向量的L2 norm,权重值归一化
2.维度越大的向量归一化后其单个值越小
3.时序信息是递增的整数
乘以根号d后放大,让embedding的数值范围position embedding的数值范围在一个scale
d
m
o
d
e
l
\sqrt{d_{model}}
dmodel
3.5 Positional Encoding
attention没有序列信息,输入加入时序信息
周期不同的sin和cos函数来计算得到每个position的Embedding:
P
E
(
p
o
s
,
2
i
)
=
s
i
n
(
p
o
s
/
1000
0
2
i
/
d
m
o
d
e
l
)
PE(pos,2i)=sin(pos/10000^{2i/d_{model}})
PE(pos,2i)=sin(pos/100002i/dmodel)
P E ( p o s , 2 i + 1 ) = c o s ( p o s / 1000 0 2 i / d m o d e l ) PE(pos,2i+1)=cos(pos/10000^{2i/d_{model}}) PE(pos,2i+1)=cos(pos/100002i/dmodel)
position encoding跟embedding相加,输入到模型中。
4 Why Self-Attention
1.计算复杂度
2.顺序的计算
3.两点传递信息的最大距离

5 Training
1.数据:英语-德语WMT2014,bpe,英语-法语
2.硬件:8个P100 GPU
3.优化器:adam.β1 = 0.9, β2 = 0.98 and = 10-9. lr 根据模型宽度的-0.5次方,warmup
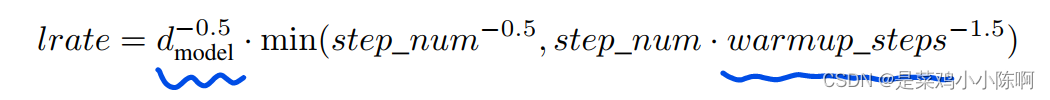
4.正则化:
(1)Residual dropout:对每个子层的输出上进入残差和layer norm之前使用dropout;embedding层、positional encodings层使用dropout,Pdrop=0.1
(2)Label Smoothing :value ls = 0.1
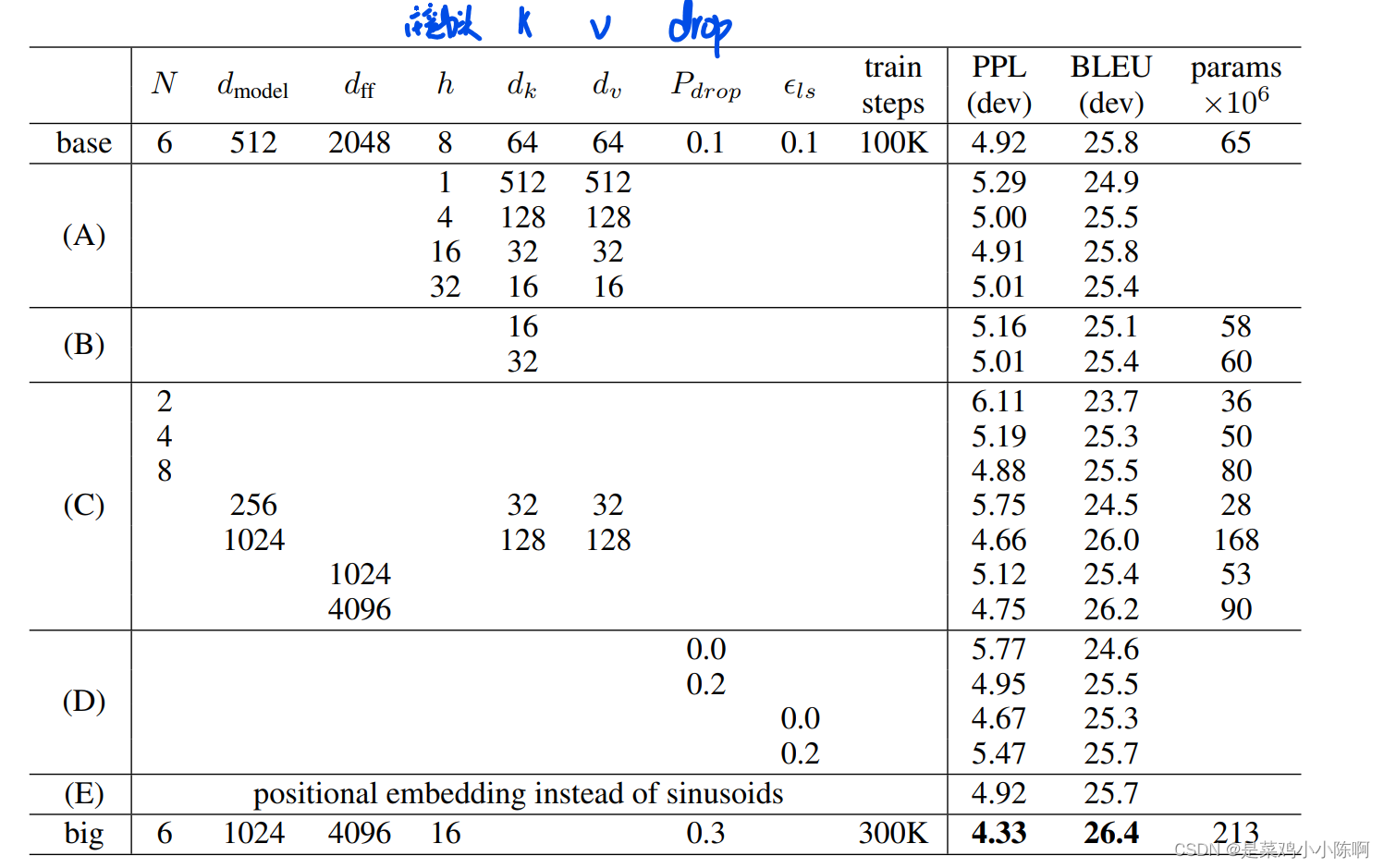
下表展示了不同的模型结构超参数的性能差别: