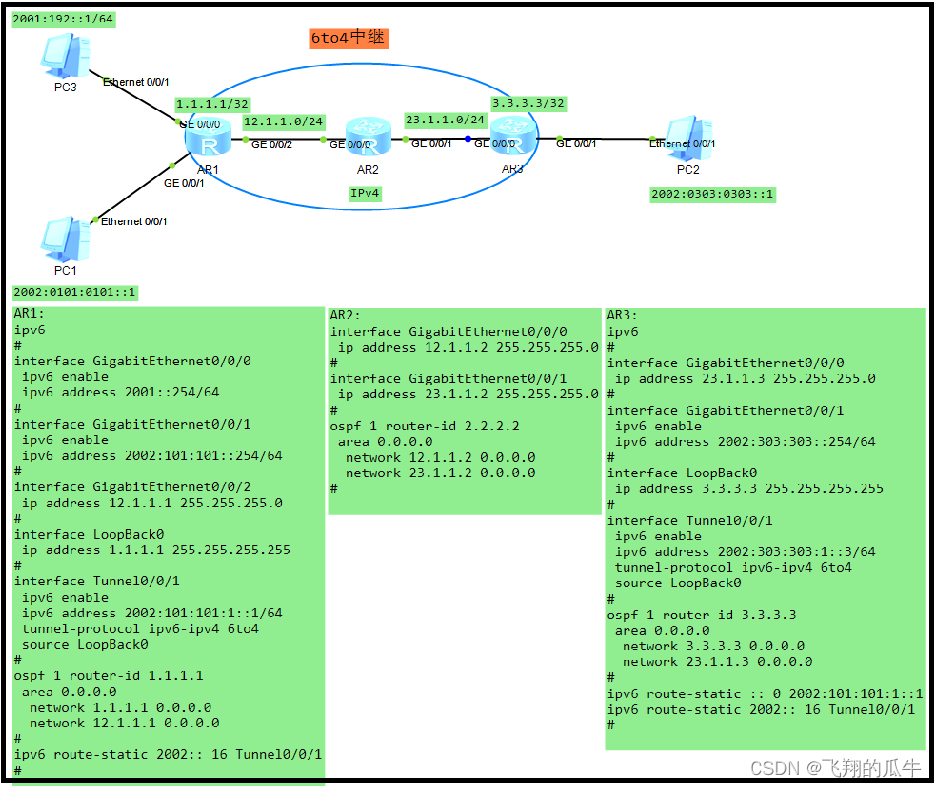
可以用到 scilit-learn 里的 make_blobs() 方法。这个方法用于生成聚类数据集,也用于测试和调试聚类算法。
import torch
import matplotlib.pyplot as plt
from sklearn.datasets import make_blobs
from sklearn.model_selection import train_test_split
NUM_CLASSES = 4
NUM_FEATURES = 2
RANDOM_SEED = 42
# 1. Create multi--class data
# 返回的结果,第一个元素是一个数组,包含生成的样本点的特征向量。第二个元素是一个数组,包含了每个样本点所属的类别标签
X_blob, y_blob = make_blobs(n_samples = 1000,
n_features = NUM_FEATURES,
centers = NUM_CLASSES,
cluster_std = 1.5,
random_state = RANDOM_SEED)
# 2. Turn data into tensors
X_blob = torch.from_numpy(X_blob).type(torch.float)
y_blob = torch.from_numpy(y_blob).type(torch.LongTensor)
# 3. Split into train and test sets
X_blob_train, X_blob_test, y_blob_train, y_blob_test = train_test_split(X_blob, y_blob, test_size = 0.2, random_state = RANDOM_SEED)
# 4. Plot data
plt.figure(figsize=(10, 7))
plt.scatter(X_blob[:, 0], X_blob[:, 1], c=y_blob, cmap = plt.cm.RdYlBu)
结果如下:

点个赞呗~