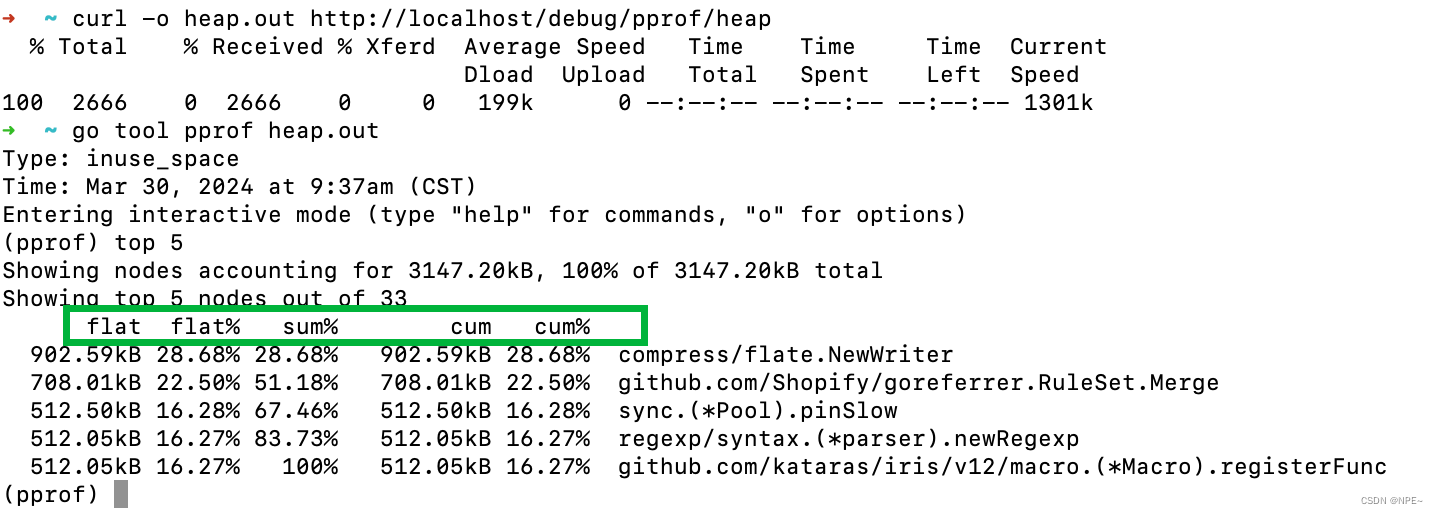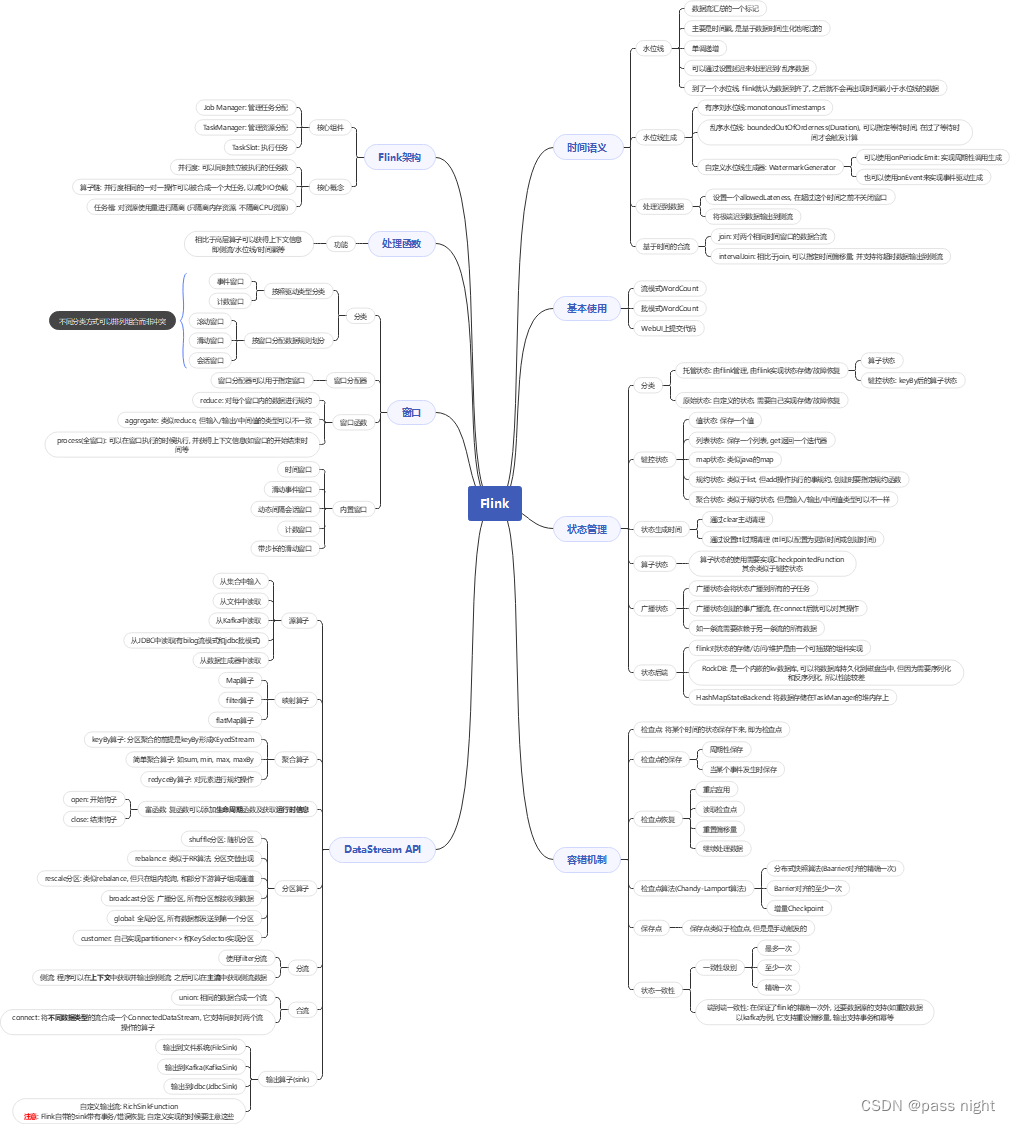
文章目录
- 认识`Flink`
- Docker安装Flink
- 基本概念
- Flink的特点
- Flink 和 Spark Streaming 对比
- 基本使用
- `WordCount`实现
- 依赖
- 批模式代码
- 流模式代码
- 网络流模式代码
- 在web UI上提交代码
- 创建项目[^1]
- 编写代码
- 配置打包
- 在Web UI上提交
- Flink 架构
- 系统架构
- 核心概念
- 并行度
- 算子链(Opeartor Chain)
- 任务槽
- Flink作业提交流程
- Standalone会话模式提交流程
- YARN应用模式作业提交流程
- DataStream API
- 源算子
- 从集合中输入
- 从文件读取
- 从Kafka中读取
- 从数据生成器读取
- 映射算子
- Map算子
- Filter算子
- FlatMap算子
- 聚合算子
- KeyBy算子
- 简单聚合算子
- reduceBy算子
- UDF
- 富函数
- 分区算子
- `shuffle`分区
- `rebalance`分区
- `rescale`分区
- `boardcast`分区
- `global`分区
- 自定义分区器
- 分流
- Filter实现分流
- 侧输出流实现分流
- 合流
- 使用`union`合流
- Connect
- 输出算子(sink)
- 输出到文件系统
- 输出到Kafka
- 输出到jdbc
- 自定义输出流
- 窗口
- 基本概念
- 分类
- 窗口分配器
- 窗口函数
- `reduce`函数
- `aggreage`函数
- 全窗口(`process`)函数
- 不同窗口类型
- 时间窗口
- 滑动时间窗口
- 会话窗口
- 动态间隔的会话窗口
- 计数窗口
- 简单滑动窗口
- 带步长的滑动窗口
- 时间语义
- 水位线
- 有序流中的水位线
- 实际状态下的水位线:
- 水位线和窗口的关系
- 水位线生成
- 有序流水位线
- 乱序流水位线
- 自定义周期性生成器
- 自定义断点式水位生成器
- 水位线的传递
- 迟到数据的处理
- 基于时间的合流
- 窗口联结
- 间隔联结
- 处理函数
- 基本使用
- 状态管理
- 键控状态(Keyed State)
- 值状态 (Value State)
- 列表状态
- Map状态
- 规约状态
- 聚合状态
- 状态生存时间
- 算子状态
- 列表状态&联合列表状态
- 广播状态
- 状态后端
- 容错机制
- 检查点
- 检查点的保存
- 检查点恢复
- 检查点算法
- 基本概念
- 分布式快照算法(Barrier对齐的精确一次)
- Barrier对齐至少一次
- 非Barrier对齐的精确一次
- 增量CheckPoint
- 检查点使用
- 最终检查点
- 保存点
- 状态一致性
- 一致性的概念和级别
- 端到端的状态一致性
- 端到端精确一次
- Kafka和flink实现精确一次
- 代码实现
- 引用
认识Flink
Docker安装Flink
version: "2.1"
services:
jobmanager:
image: flink
expose:
- "6123"
ports:
- "20010:8081"
command: jobmanager
environment:
- JOB_MANAGER_RPC_ADDRESS=jobmanager
taskmanager:
image: flink
expose:
- "6121"
- "6122"
depends_on:
- jobmanager
command: taskmanager
links:
- "jobmanager:jobmanager"
environment:
- JOB_MANAGER_RPC_ADDRESS=jobmanager
docker-compose up -d
基本概念
- 核心目标: 数据流上有状态的计算 Stateful computation over data stream
- Flink: 一个框架和分布式处理引擎, 对有界和无界的数据流进行有状态计算 Flink是事件驱动型的应用
- 有界数据流: 有定义流的开始, 但没有定义流的结束; 而有界数据流即有流的开始, 也有结束
- 状态: 把流处理需要的而外数据保存成一个状态, 然后针对这条数据处理, 并更新状态
Flink的特点
- 高吞吐低延迟: 每秒处理百万个事件, 毫秒级延迟
- 结果的准确性: Flink提供了事件时间和处理时间的语义, 对乱序事件流, 事件事件语义热能能够提供一致且准确的结果
- 精确一次: 精确一次的状态一致性保证 不丢数, 不重复
- 可以连接到常用的存储系系统, 如
Kafka,JDBC,redis,Hive,HDFS等 - 高可用: 本身具有高可用设置, 且可以与
K8s/YARN/Mesos紧密集成
Flink 和 Spark Streaming 对比
| Flink | Spark Streaming | |
|---|---|---|
| 计算模型 | Flink以流处理为本; 一个事件在一个节点处理完后可以直接发往下一个节点进行处理 | Spark 以批处理为本, 其本质是微批次 |
| 时间语义 | 事件时间, 处理事件 | 只有处理时间 |
| 窗口 | 多, 灵活 | 少, 不灵活 窗口时间必须是批次的整数倍 |
| 状态 | 有 | 无 |
| 流式SQL | 有 | 无 |
基本使用
WordCount实现
依赖
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-streaming-java -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java</artifactId>
<version>1.17.1</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-clients -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients</artifactId>
<version>1.17.1</version>
</dependency>
批模式代码
public class WordCount {
public static void main(String[] args) throws Exception {
// 创建执行环境
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
// 读取文件
DataSource<String> lines = env.readTextFile("bigdata/src/test/resources/word list.txt");
// 文本拆分, 转化为词频元组
lines.flatMap((FlatMapFunction<String, Tuple2<String, Integer>>) (line, out) -> {
// 按照空格切分单词
Arrays.stream(line.split(" "))
.map(word -> Tuple2.of(word, 1)) // 将单词转化为词频元组
.forEach(out::collect); // 向下游发送数据
}).returns(new TypeHint<>() { // 需要有这个, 否则会报错
}).groupBy(0) // 根据元组的索引0元素进行分组
.sum(1) // 根据元组的索引1元素求和
.print();
}
}
输出
# 这里去除了一些日志
(passnight,2)
(hadoop,2)
(like,2)
(love,2)
(I,4)
流模式代码
public class StreamWordCount {
public static void main(String[] args) throws Exception {
// 创建流式处理环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 从文件读取数据
env.readTextFile("bigdata/src/test/resources/word list.txt")
// 将数据分词, 并转化为词频二元组
.flatMap((FlatMapFunction<String, Tuple2<String, Integer>>) (line, out) -> Arrays.stream(line.split(" "))
.map(word -> Tuple2.of(word, 1)) // 转化为词频二元组
.forEach(out::collect)) // 将数据传给下游
.returns(new TypeHint<>() {
// 根据key进行分组
}).keyBy((KeySelector<Tuple2<String, Integer>, String>) value -> value.f0)
.sum(1) // 分组后根据索引为0的元素进行聚合
.print();
env.execute(); // 启动任务
}
}
输出
17> (like,1)
11> (passnight,1)
6> (I,1)
11> (passnight,2)
13> (love,1)
6> (I,2)
6> (I,3)
18> (hadoop,1)
18> (hadoop,2)
13> (love,2)
6> (I,4)
17> (like,2)
可见不同线程以流的方式一条一条处理文件中的数据
网络流模式代码
package com.passnight.bigdata.flink;
import lombok.Cleanup;
import org.apache.flink.api.common.typeinfo.TypeHint;
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
import java.util.Arrays;
public class SocketStreamWordCount {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.socketTextStream("server.passnight.local", 30000)
.flatMap((String line, Collector<Tuple2<String, Integer>> out) -> Arrays.stream(line.split(" "))
.map((String word) -> Tuple2.of(word, 1))
.forEach(out::collect)).returns(new TypeHint<>() {
}).keyBy((KeySelector<Tuple2<String, Integer>, String>) value -> value.f0)
.sum(1)
.print();
env.execute();
}
}
启动netcat生成文本流
passnight@passnight-s600:~$ netcat -lk 30000
输出
# netcat中输入 "hello world"
6> (hello,1)
11> (world,1)
# 输入 "hello flink"
16> (flink,1)
6> (hello,2)
在web UI上提交代码
创建项目1
mvn archetype:generate \
-DarchetypeGroupId=org.apache.flink \
-DarchetypeArtifactId=flink-quickstart-java \
-DarchetypeVersion=1.4.2
将Flink版本修改到``与上面匹配
<flink.version>1.7.1</flink.version>
编写代码
package com.passnight.bigdata.flink;
import org.apache.flink.api.common.typeinfo.TypeHint;
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
import java.util.Arrays;
public class SocketStreamWordCount {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.socketTextStream("server.passnight.local", 30000)
.flatMap((String line, Collector<Tuple2<String, Integer>> out) -> Arrays.stream(line.split(" "))
.map((String word) -> Tuple2.of(word, 1))
.forEach(out::collect)).returns(new TypeHint<>() {
}).keyBy((KeySelector<Tuple2<String, Integer>, String>) value -> value.f0)
.sum(1)
.print();
env.execute();
}
}
配置打包
<mainClass>com.passnight.monitor.SocketStreamWordCount</mainClass>
将启动类设置成我们的启动类
在Web UI上提交
Flink 架构
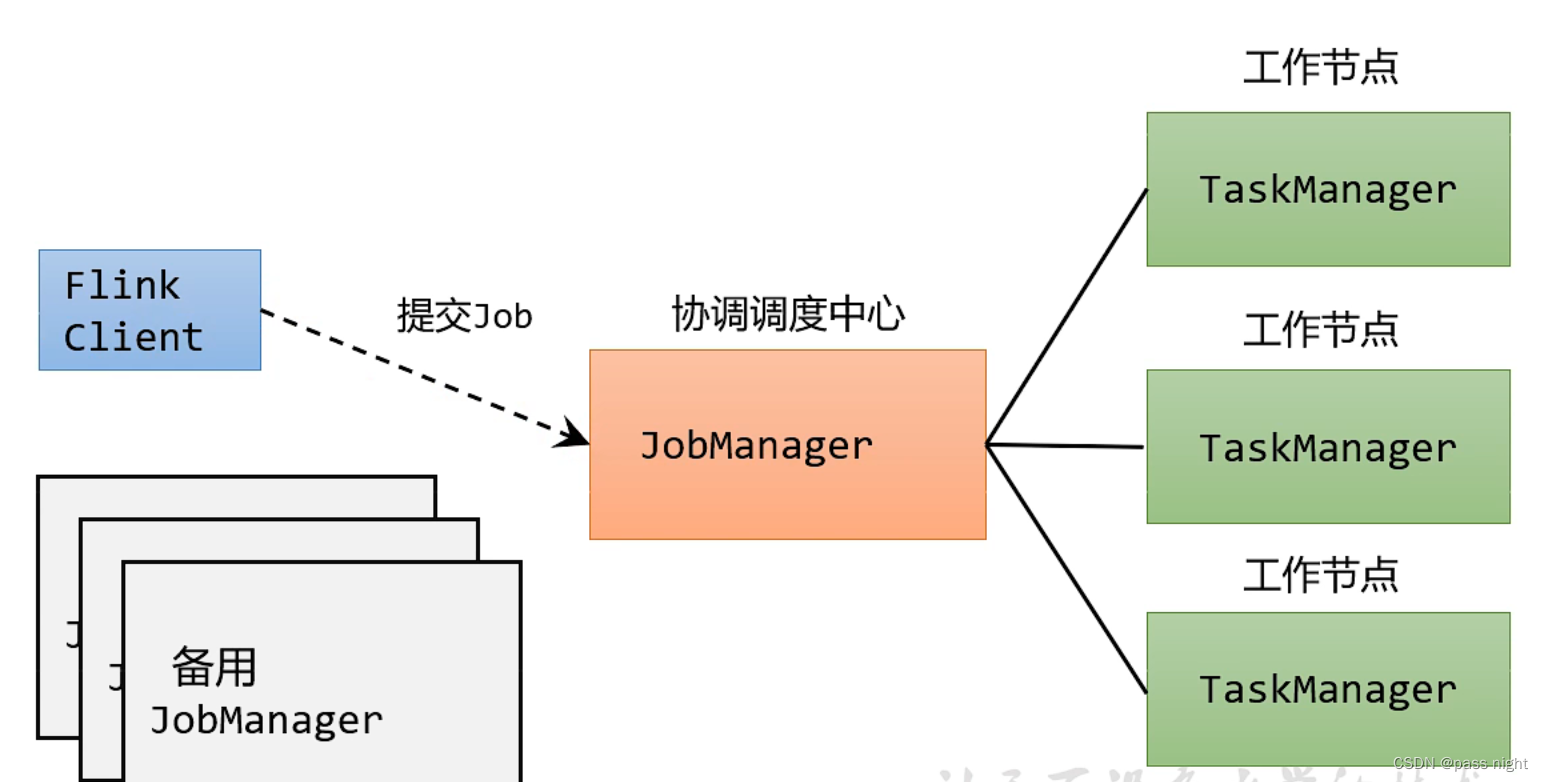
系统架构
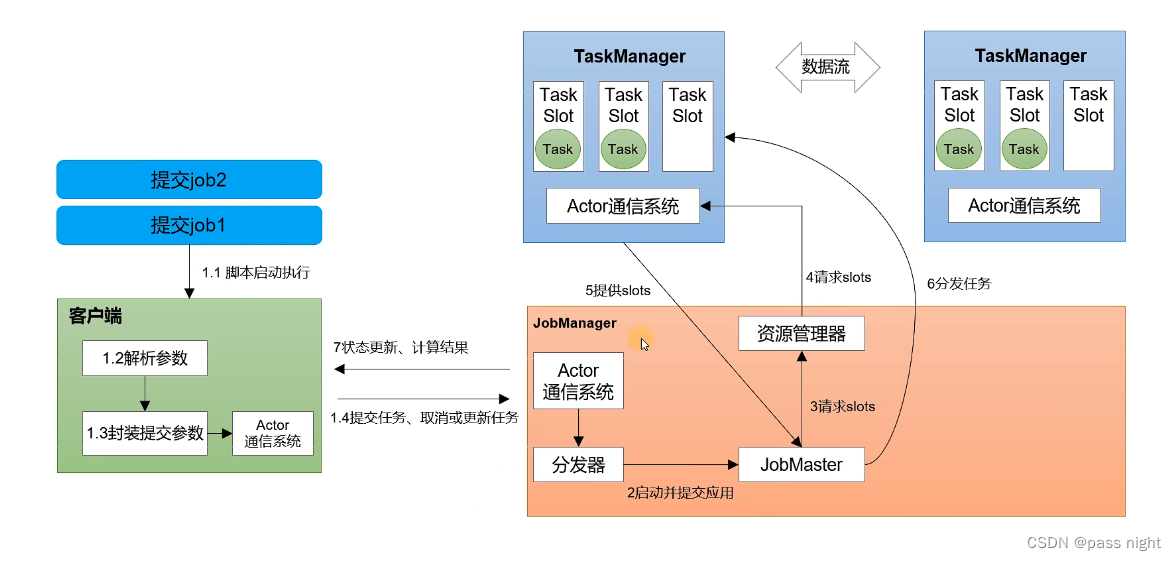
执行流程:
- 客户端解析提供的参数, 将其封装为一个任务, 发送给JobManager
- JobManager会将任务提交到JobMaster
- JobMaster之后会向资源管理器申请资源
- 资源管理器之后会向TaskManager发送请求, 在可以接受请求, TaskManager会返回信息, 这样资源管理器就可以分发任务
核心概念
并行度
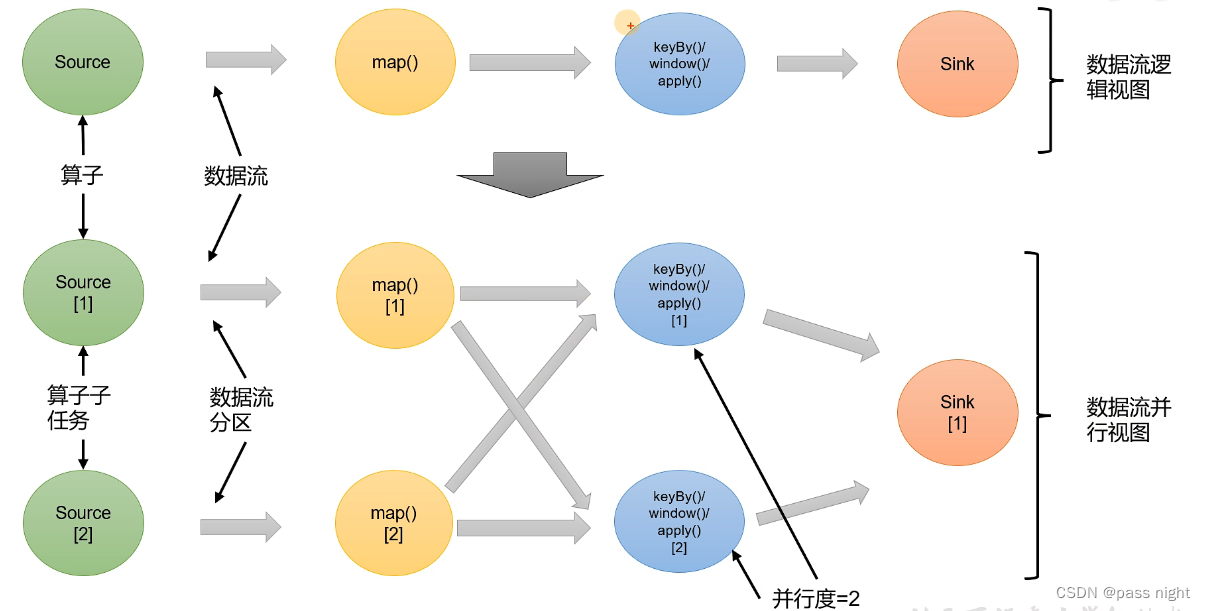
并行度: 同时独立被执行的任务数 一个流程序的并行度, 一般被认为所有算子最大的并行度
-
大数据环境下, 可以将一个算子复制到多个节点, 这样一个算子就被拆成了多个子任务, 由不同节点并行执行
-
这些子任务在不同线程/不同物理机/不同容器中完全独立运行
-
下图是并行度为1和并行度为2的区别:
-
所有的算子的并行度都可以通过
setParalism命令配置 -
实验:
-
添加以下依赖, 就可以在单机模式中看到web UI:
<dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-runtime-web</artifactId> <version>1.17.1</version> </dependency> -
并且调用
setParalism将flatMap算子的并行度设置为2class ParallelSocketStreamWordCount { public static void main(String[] args) throws Exception { @Cleanup StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(new Configuration()); env.socketTextStream("server.passnight.local", 30000) .flatMap((String line, Collector<Tuple2<String, Integer>> out) -> Arrays.stream(line.split(" ")) .map((String word) -> Tuple2.of(word, 1)) .forEach(out::collect)).returns(new TypeHint<>() { }).setParallelism(2) // 设置并行度为2 .keyBy((KeySelector<Tuple2<String, Integer>, String>) value -> value.f0) .sum(1) .print(); env.execute(); } } -
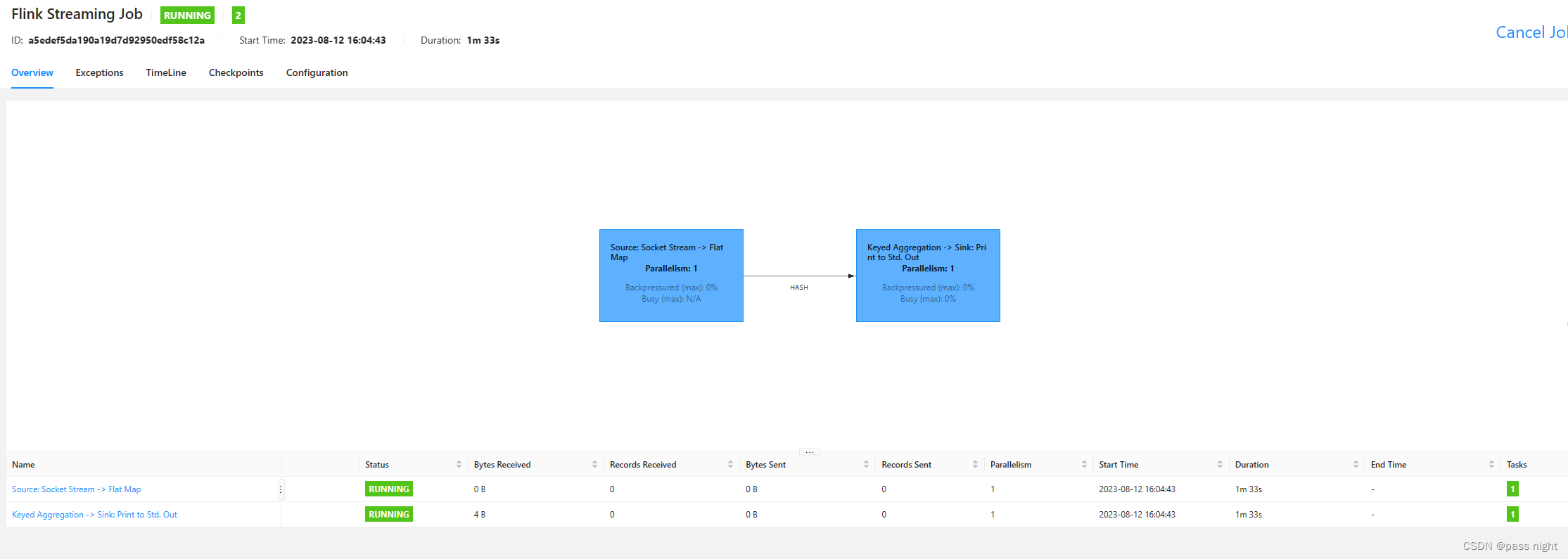
可以在Web UI中看到结果:
-
这里也可以看到默认的并行度是核心数
-
同样的可以全局设置, 通过调用
env.envParallelism()设置, 也可以在提交的时候设置参数-p来配置webUI页面也有对应的参数配置框; 算子的优先级遵循越局部越有限的原则
-
算子链(Opeartor Chain)
-
数据可能由多个算子操作, 这些算子会形成算子链
-
数据流在算子之间的传输形式可能会死一对一的直通模式, 也可能是打乱的重分区模式
- 一对一: 这种模式, 算子读取数据之后, 直接发送给map算子做处理, 不需要经过重分区, 也不需要**调整数据的顺序 ** 类似Spark的窄依赖
- 重分区: 这会根据数据流的特征发生变化, 如
keyBy操作, 会根据key的特征对数据重分区; Flink会根据数据传输策略, 把数据发送给不同的下游任务 除了forward都是重分区
-
合并算子链: 并行度相同的一对一操作, 可以被合并成一个大任务 这是Flink自带的优化, 可以减少IO负载, 及内存交换负载
-
有两种方式禁用这样的优化, 分别是通过
disableOperatorChanning和disableChanningapi; 也可以使用startNewChain开启新链条, 以达到类似禁用的效果 -
默认情况下,
map和flatenMap被分为一组,keyBy和print被分为一组: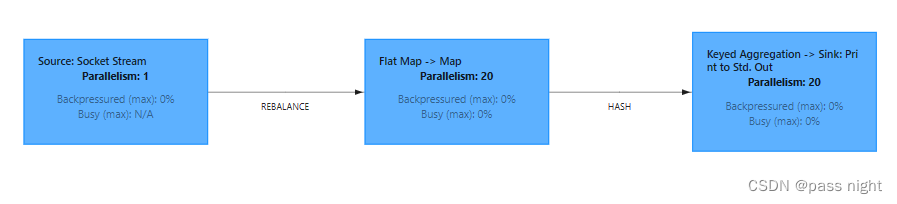
-
在调用
env.disableOperatorChaining();后, 可以全局禁止任务合并:
-
或是调用
disableChanning禁止某一个算子的合并: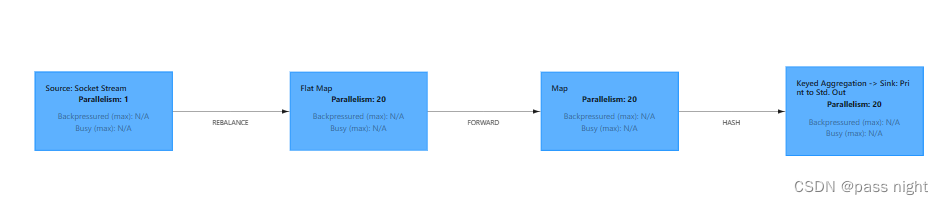
-
还可以通过创建新链达到类似的效果
startNewChain:
-
代码:
public class OperatorChain { public static void main(String[] args) throws Exception { @Cleanup StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(new Configuration()); // env.disableOperatorChaining(); // 全局禁用算子链 env.socketTextStream("server.passnight.local", 30000) .flatMap((String line, Collector<String> out) -> Arrays.stream(line.split(" ")) .forEach(out::collect)) .returns(new TypeHint<>() { }) // .disableChaining() 局部禁用算子链 .map((String word) -> Tuple2.of(word, 1)) .startNewChain() // 开启一个新的算子链 .returns(new TypeHint<>() { }).keyBy((KeySelector<Tuple2<String, Integer>, String>) value -> value.f0) .sum(1) .print(); env.execute(); } }
-
任务槽
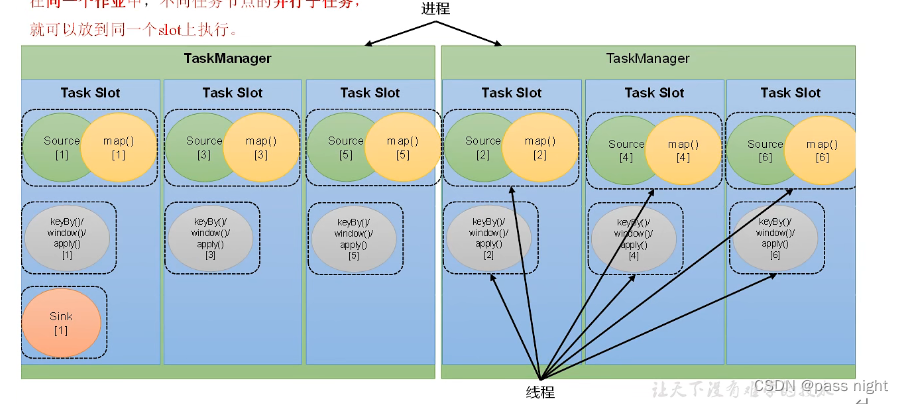
- 一个TaskManager的计算资源是有限的, 并行的任务越多, 每个线程的资源越少. 为了控制并发量, 任务槽对每个任务所占用的资源做出了划分. 任务槽表示TaskManager拥有资源的固定大小; 其资源分配主要针对内存
- 一般来说, 任务槽的数量是CPU的核心数; 具体可以通过
taskmanager.numberOfTaskSlots=1进行配置 slot划分内存, 但是不划分CPU - 同一个作业中, 同一个slot上, 不同算子的子任务是同时运行的 默认情况下, 同一个slot共享组的slot是共享的(默认都是Default组), 但也可以通过
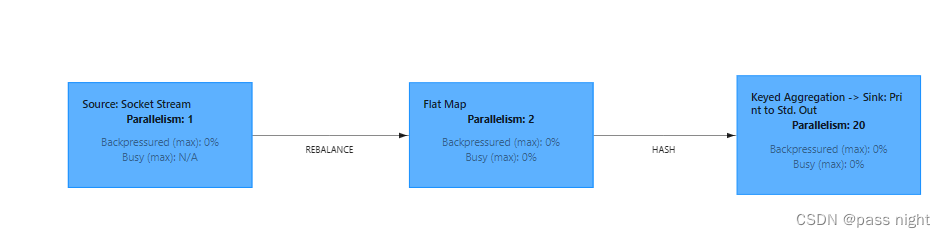
slotSharingGroup配置 - slot和并行度: slot是静态的概念, 而并行度是动态概念; 并行度指实际上同时进行的任务数, 一般来说slot决定并行度的上限; 上图souce+map算子链和keyby+window+apply算子链的并行度为6, sink的并行度为1 flink不支持并行度大于任务槽的情况, 提交会抛出
NoResourceAvaiableException异常 - Yarn模式下会动态申请TM, 其数量为 申请 T M 数量 = ⌈ j o b 并行度 每个 T M s l o t 数 ⌉ 申请TM数量=\lceil\frac{job并行度}{每个TM slot数}\rceil 申请TM数量=⌈每个TMslot数job并行度⌉
Flink作业提交流程
Standalone会话模式提交流程
-
客户端会根据参数生成逻辑流图, 再生成作业流图 这个过程会进行算子优化
-
然后向JobManager提交, 生成执行图
-
之后资源管理器会向TaskManager请求并分配任务, 此时TaskManager会生成物理流图
-
各种图的创建顺序为:
YARN应用模式作业提交流程
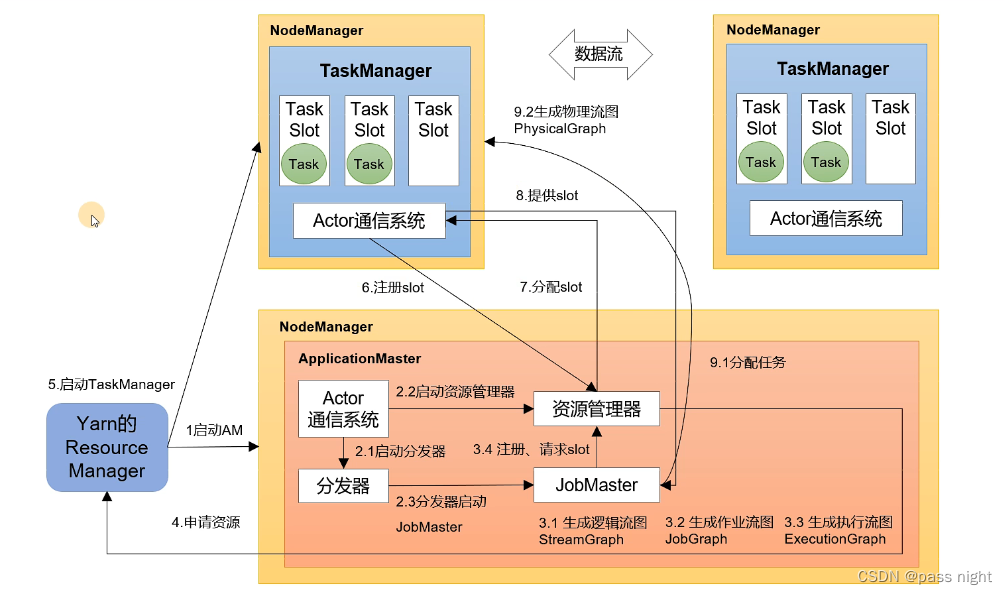
- 向YARN的Resource Manager提交节点, 然后在NodeManager中启动ApplicationMaster的容器
- 之后ApplicationMaster会启动资源管理器和分发器; JobMaster生成逻辑流图, 再生成作业流图/执行流图
- 生成了执行流图后会向资源管理器申请/请求slot资源;
- 该资源管理器会向YARN的ResourceManager申请资源, ResourceManager再实际分配资源, 并返回给Flink的资源管理器
DataStream API
源算子
从集合中输入
class ReadFromCollection {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.fromCollection(IntStream.range(0, 10)
.boxed()
.collect(Collectors.toUnmodifiableList()))
.print();
env.execute();
}
}
输出结果为:
4> 0
6> 2
7> 3
5> 1
10> 6
9> 5
8> 4
11> 7
12> 8
13> 9
从文件读取
从文件读取需要添加相应的connector
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-files</artifactId>
<version>1.17.1</version>
</dependency>
代码为
class ReadFromFile {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
FileSource<String> fileSource = FileSource.forRecordStreamFormat(new TextLineInputFormat(),
new Path("bigdata/src/main/resources/word list.txt")).build();
env.fromSource(fileSource, WatermarkStrategy.noWatermarks(), "fileSource")
.print();
env.execute();
}
}
输出为:
12> I love passnight
12> I like passnight
12> I love hadoop
12> I like hadoop
从Kafka中读取
从kafka中读取需要导入依赖 (注意: flink-connector-kafka中依赖的kafka-client版本太低, 需要手动导入更高版本的kafka-client)
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka</artifactId>
<version>1.17.1</version>
</dependency>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>3.6.0</version>
</dependency>
代码为
class ReadFromKafka {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
KafkaSource<String> kafkaSource = KafkaSource.<String>builder()
.setBootstrapServers("server.passnight.local:20015") // 指定连接url
.setGroupId("testGroup") // 指定消费者组
.setTopics("test") // 指定topic
.setValueOnlyDeserializer(new SimpleStringSchema()) // 指定反序列化其
.setStartingOffsets(OffsetsInitializer.latest()) // 指定消费偏移量
.build();
env.fromSource(kafkaSource, WatermarkStrategy.noWatermarks(), "kafkaSource")
.print();
env.execute();
}
}
从数据生成器读取
从数据生成器中读取需要导入依赖
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-datagen</artifactId>
<version>1.17.1</version>
</dependency>
代码为:
class ReadFromDataGenerator {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataGeneratorSource<String> dataGeneratorSource = new DataGeneratorSource<>(
(GeneratorFunction<Long, String>) aLong -> String.format("Id: %d", aLong), // 生成器方法, 主要重写里面的map
10, // 自动生成的序列号的最大值, 达到这个值之后就停止生成
RateLimiterStrategy.perSecond(1), // 限速, 限制每秒钟生成的数据量
Types.STRING);
env.fromSource(dataGeneratorSource, WatermarkStrategy.noWatermarks(), "dataGenerator")
.print();
env.execute();
}
}
输出为:
6> Id: 5
14> Id: 7
9> Id: 6
4> Id: 2
20> Id: 0
2> Id: 1
18> Id: 4
3> Id: 3
8> Id: 9
15> Id: 8
可以看到一共生成了10条数据就停止了; 且限速也成功生效
映射算子
用于测试的pojo
@Data
@Builder
@AllArgsConstructor
@NoArgsConstructor
public class WaterSensor {
private String id;
private Long ts;
private Integer vc;
}
Map算子
class Map {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.fromCollection(IntStream.range(0, 10)
.boxed()
.map(integer -> new WaterSensor(String.format("s%d", integer), Long.valueOf(integer), integer))
.collect(Collectors.toUnmodifiableList()))
.map(WaterSensor::getId)
.print();
env.execute();
}
}
输出为:
19> s4
20> s5
18> s3
1> s6
17> s2
4> s9
15> s0
16> s1
3> s8
2> s7
可以看到已经将WaterSensor的id转换并输出了
Filter算子
class Filter {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.fromCollection(IntStream.range(0, 10)
.boxed()
.map(integer -> new WaterSensor(String.format("s%d", integer), Long.valueOf(integer), integer))
.collect(Collectors.toUnmodifiableList()))
.filter(waterSensor -> waterSensor.getTs() > 5)
.print();
env.execute();
}
}
输出为:
10> WaterSensor(id=s9, ts=9, vc=9)
7> WaterSensor(id=s6, ts=6, vc=6)
8> WaterSensor(id=s7, ts=7, vc=7)
9> WaterSensor(id=s8, ts=8, vc=8)
FlatMap算子
class FlatMap {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.fromCollection(Arrays.asList("1 2 3 4", "5 6 7", "8 9"))
.flatMap((FlatMapFunction<String, String>) (value, out) -> Arrays.stream(value.split(" ")).forEach(out::collect))
.returns(Types.STRING)
.print();
env.execute();
}
}
输出为:
10> 1
11> 5
10> 2
10> 3
10> 4
11> 6
12> 8
12> 9
11> 7
聚合算子
- 在Flink当中, 若要做聚合, 先要对数据进行分区, 该操作就是通过
keyBy算子完成的 - 在相同key的数据被发送到一个分区后, 对该分区的数据计算, 便完成了聚合操作
KeyBy算子
class KeyBy {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.fromElements(
new WaterSensor("s1", 1L, 1),
new WaterSensor("s1", 11L, 11),
new WaterSensor("s2", 2L, 2),
new WaterSensor("s3", 3L, 3)
)
.keyBy(WaterSensor::getId)
/*
* 调用keyBy后返回`KeyedStream`, 之后就有一系列聚合函数
* 它在执行流图中体现为**箭头**而非流程框
*/
.print()
.setParallelism(2);
env.execute();
}
}
输出为:
2> WaterSensor(id=s1, ts=1, vc=1)
1> WaterSensor(id=s2, ts=2, vc=2)
2> WaterSensor(id=s1, ts=11, vc=11)
2> WaterSensor(id=s3, ts=3, vc=3)
可以看到相同Key的数据在同一分区
简单聚合算子
class SimpleAggregation {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.fromElements(
new WaterSensor("s1", 1L, 1),
new WaterSensor("s1", 11L, 11),
new WaterSensor("s2", 2L, 2),
new WaterSensor("s3", 3L, 3)
)
.keyBy(WaterSensor::getId)
// .sum("vc")
// .min("vc")
// .max("vc")
.maxBy("vc")
.print();
env.execute();
}
}
输出结果为
####################### sum算子
18> WaterSensor(id=s3, ts=3, vc=3)
20> WaterSensor(id=s1, ts=1, vc=1)
5> WaterSensor(id=s2, ts=2, vc=2)
20> WaterSensor(id=s1, ts=1, vc=12) # 第二次出现"s1", 值=1+11=12
##################### min算子
20> WaterSensor(id=s1, ts=1, vc=1)
5> WaterSensor(id=s2, ts=2, vc=2)
18> WaterSensor(id=s3, ts=3, vc=3)
20> WaterSensor(id=s1, ts=1, vc=1) # 第二次出现"s1", 第一次出现的更小, 因此还是1
#################### max算子
18> WaterSensor(id=s3, ts=3, vc=3)
20> WaterSensor(id=s1, ts=1, vc=1)
5> WaterSensor(id=s2, ts=2, vc=2)
20> WaterSensor(id=s1, ts=1, vc=11) # 第二次出现"s1", 第2次出现的更大, 因此还是11
################## maxBy算子, max只会取比较字段的最大值, 非比较字段保留; 而maxBy非比较字段也会取比较字段的最大值
5> WaterSensor(id=s2, ts=2, vc=2)
20> WaterSensor(id=s1, ts=1, vc=1)
18> WaterSensor(id=s3, ts=3, vc=3)
20> WaterSensor(id=s1, ts=11, vc=11) # 可以看到ts也变成了11
reduceBy算子
class Reduce {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.fromElements(
new WaterSensor("s1", 1L, 1),
new WaterSensor("s1", 11L, 11),
new WaterSensor("s2", 2L, 2),
new WaterSensor("s3", 3L, 3)
)
.keyBy(WaterSensor::getId)
.reduce((x, y) -> new WaterSensor(x.getId(), y.getTs(), x.getVc() + y.getVc()))
.print();
env.execute();
}
}
输出结果为:
20> WaterSensor(id=s1, ts=1, vc=1)
5> WaterSensor(id=s2, ts=2, vc=2)
18> WaterSensor(id=s3, ts=3, vc=3)
20> WaterSensor(id=s1, ts=11, vc=12)
可以看到vc执行了求和操作; 而ts每次都取后者 注意每个组的第一条数据不会进入聚合方法
UDF
用户可以实现Flink提供的接口实现自定义函数
class UDF {
public static class MyFilterFunction implements FilterFunction<WaterSensor> {
private static final String id = "s1";
@Override
public boolean filter(WaterSensor value) {
return Objects.equals(id, value.getId());
}
}
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.fromElements(
new WaterSensor("s1", 1L, 1),
new WaterSensor("s1", 11L, 11),
new WaterSensor("s2", 2L, 2),
new WaterSensor("s3", 3L, 3)
)
.filter(new MyFilterFunction())
.print();
env.execute();
}
}
输出结果为:
4> WaterSensor(id=s1, ts=1, vc=1)
5> WaterSensor(id=s1, ts=11, vc=11)
富函数
在执行算子的时候, 可以使用富函数以添加生命周期函数及获取运行时信息
class RichFunction {
public static void main(String[] args) throws Exception {
@Cleanup
StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(new Configuration());
env.fromElements(
new WaterSensor("s1", 1L, 1),
new WaterSensor("s1", 11L, 11),
new WaterSensor("s2", 2L, 2),
new WaterSensor("s3", 3L, 3)
)
.map(new RichMapFunction<WaterSensor, Integer>() {
@Override
public Integer map(WaterSensor value) throws Exception {
return value.getVc();
}
// 富函数带的钩子
@Override
public void open(Configuration parameters) {
RuntimeContext context = getRuntimeContext();
System.out.printf("[open()] 子任务编号: %s, 子任务名称: %s%n",
context.getIndexOfThisSubtask(),
context.getTaskNameWithSubtasks());
}
@Override
public void close() {
RuntimeContext context = getRuntimeContext();
System.out.printf("[close()] 子任务编号: %s, 子任务名称: %s%n",
context.getIndexOfThisSubtask(),
context.getTaskNameWithSubtasks());
}
})
.print();
env.execute();
TimeUnit.DAYS.sleep(1);
}
}
输出为:
[open()] 子任务编号: 10, 子任务名称: Map -> Sink: Print to Std. Out (11/20)#0
[open()] 子任务编号: 4, 子任务名称: Map -> Sink: Print to Std. Out (5/20)#0
[open()] 子任务编号: 12, 子任务名称: Map -> Sink: Print to Std. Out (13/20)#0
[open()] 子任务编号: 11, 子任务名称: Map -> Sink: Print to Std. Out (12/20)#0
[open()] 子任务编号: 9, 子任务名称: Map -> Sink: Print to Std. Out (10/20)#0
[open()] 子任务编号: 7, 子任务名称: Map -> Sink: Print to Std. Out (8/20)#0
[open()] 子任务编号: 16, 子任务名称: Map -> Sink: Print to Std. Out (17/20)#0
[open()] 子任务编号: 15, 子任务名称: Map -> Sink: Print to Std. Out (16/20)#0
[open()] 子任务编号: 3, 子任务名称: Map -> Sink: Print to Std. Out (4/20)#0
[open()] 子任务编号: 8, 子任务名称: Map -> Sink: Print to Std. Out (9/20)#0
[open()] 子任务编号: 5, 子任务名称: Map -> Sink: Print to Std. Out (6/20)#0
[open()] 子任务编号: 18, 子任务名称: Map -> Sink: Print to Std. Out (19/20)#0
[open()] 子任务编号: 19, 子任务名称: Map -> Sink: Print to Std. Out (20/20)#0
[open()] 子任务编号: 6, 子任务名称: Map -> Sink: Print to Std. Out (7/20)#0
[open()] 子任务编号: 13, 子任务名称: Map -> Sink: Print to Std. Out (14/20)#0
[open()] 子任务编号: 14, 子任务名称: Map -> Sink: Print to Std. Out (15/20)#0
[open()] 子任务编号: 2, 子任务名称: Map -> Sink: Print to Std. Out (3/20)#0
[open()] 子任务编号: 17, 子任务名称: Map -> Sink: Print to Std. Out (18/20)#0
[open()] 子任务编号: 1, 子任务名称: Map -> Sink: Print to Std. Out (2/20)#0
[open()] 子任务编号: 0, 子任务名称: Map -> Sink: Print to Std. Out (1/20)#0
16> 2
14> 1
15> 11
17> 3
[close()] 子任务编号: 9, 子任务名称: Map -> Sink: Print to Std. Out (10/20)#0
[close()] 子任务编号: 7, 子任务名称: Map -> Sink: Print to Std. Out (8/20)#0
[close()] 子任务编号: 0, 子任务名称: Map -> Sink: Print to Std. Out (1/20)#0
[close()] 子任务编号: 1, 子任务名称: Map -> Sink: Print to Std. Out (2/20)#0
[close()] 子任务编号: 5, 子任务名称: Map -> Sink: Print to Std. Out (6/20)#0
[close()] 子任务编号: 10, 子任务名称: Map -> Sink: Print to Std. Out (11/20)#0
[close()] 子任务编号: 6, 子任务名称: Map -> Sink: Print to Std. Out (7/20)#0
[close()] 子任务编号: 8, 子任务名称: Map -> Sink: Print to Std. Out (9/20)#0
[close()] 子任务编号: 2, 子任务名称: Map -> Sink: Print to Std. Out (3/20)#0
[close()] 子任务编号: 3, 子任务名称: Map -> Sink: Print to Std. Out (4/20)#0
[close()] 子任务编号: 4, 子任务名称: Map -> Sink: Print to Std. Out (5/20)#0
[close()] 子任务编号: 12, 子任务名称: Map -> Sink: Print to Std. Out (13/20)#0
[close()] 子任务编号: 13, 子任务名称: Map -> Sink: Print to Std. Out (14/20)#0
[close()] 子任务编号: 16, 子任务名称: Map -> Sink: Print to Std. Out (17/20)#0
[close()] 子任务编号: 11, 子任务名称: Map -> Sink: Print to Std. Out (12/20)#0
[close()] 子任务编号: 15, 子任务名称: Map -> Sink: Print to Std. Out (16/20)#0
[close()] 子任务编号: 14, 子任务名称: Map -> Sink: Print to Std. Out (15/20)#0
[close()] 子任务编号: 17, 子任务名称: Map -> Sink: Print to Std. Out (18/20)#0
[close()] 子任务编号: 19, 子任务名称: Map -> Sink: Print to Std. Out (20/20)#0
[close()] 子任务编号: 18, 子任务名称: Map -> Sink: Print to Std. Out (19/20)#0
可以注意到:
- 一共调用了
20次open和close, 因为默认的并行度为20 open和close相当于生命周期函数, 每个子任务启动和关闭时会调用一次- 在富函数中可以获取运行时上下文中的一些信息
分区算子
测试代码:
public class Partition {
public static Partitioner<String> partitioner = (key, numPartitions) -> Integer.parseInt(key) % numPartitions;
public static KeySelector<String, String> keySelector = value -> value;
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(2)
.socketTextStream("server.passnight.local", 30000)
// .shuffle() // 随机分区
// .rebalance() // 轮询算法
// .rescale()
// .broadcast() // 广播分区
// .global() // 全局分区
.partitionCustom(Partition.partitioner, Partition.keySelector)// 自定义分区
.print();
env.execute();
}
}
shuffle分区
输出结果为:
2> 1
1> 1
2> 1
1> 1
2> 1
2> 1
2> 1
2> 1
2> 1
可以看到分区没有任何规律, 因为选择分区是随机的"如下代码", 因为分区算法为: return random.nextInt(numberOfChannels);
rebalance分区
输出结果为
1> 1
2> 1
1> 1
2> 1
1> 1
2> 1
#
可以看到分区交替出现; 因为选自分区的时如下代码; 这样可以解决固定分区读取kafka数据倾斜的问题; 因为分区算法为: nextChannelToSendTo = (nextChannelToSendTo + 1) % numberOfChannels;
rescale分区
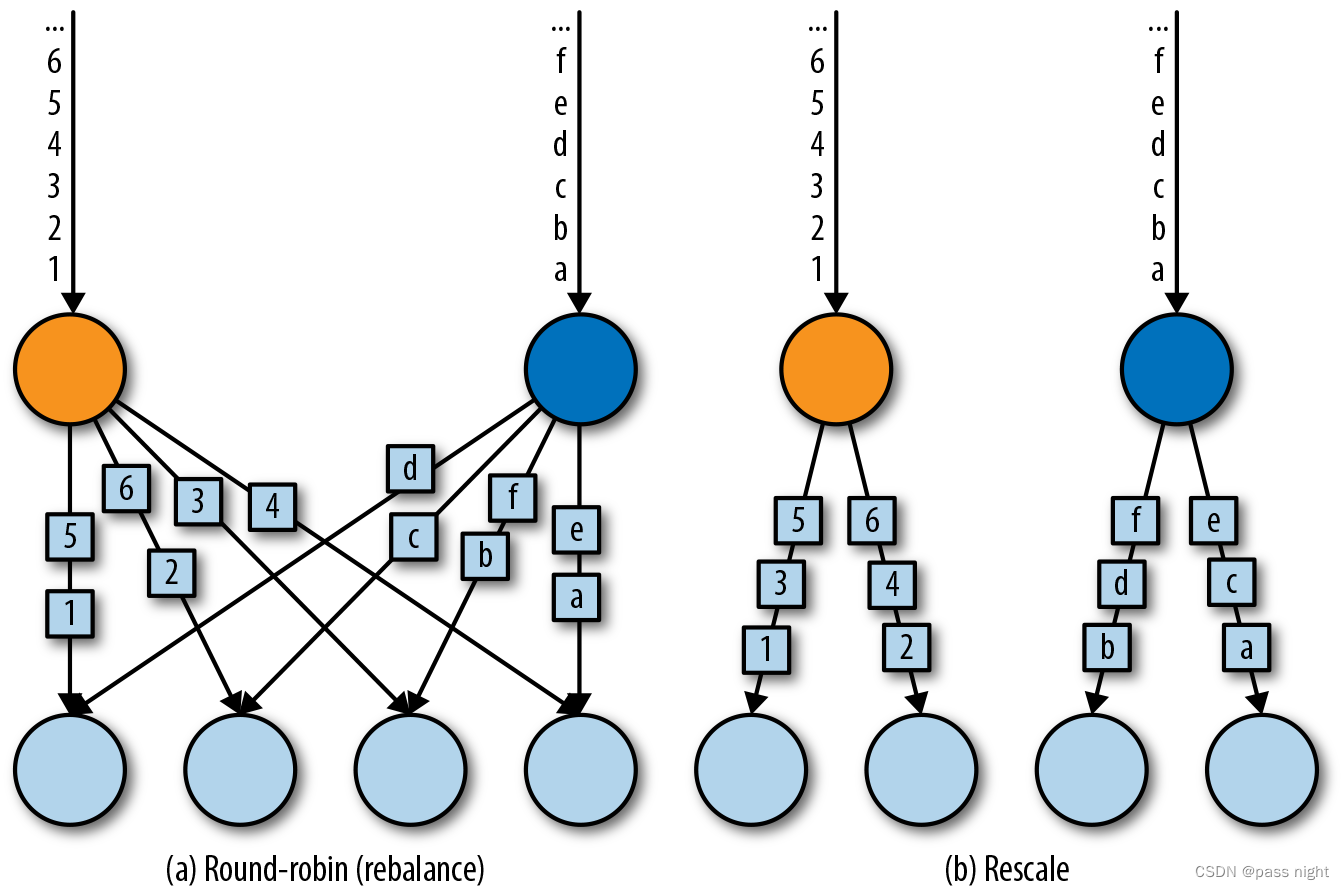
输出结果为:
2> 1
1> 1
2> 1
1> 1
2> 1
类似rebalance它会局部组队, 然后在组内轮询. 因为它只会和部分下游算子组成通道
boardcast分区
输出结果为:
# 发送了1, 2, 3
2> 1
1> 1
1> 2
2> 2
1> 3
2> 3
可以看到, 所有的分区都接收到了数据
global分区
输出结果为:
1> 1
1> 1
1> 1
1> 1
1> 1
1> 1
将使用全局分区算子之后, 所有的数据都只会发送到第一个分区; 所有的分区号都为1
自定义分区器
自定义分区器:
public static Partitioner<String> partitioner = (key, numPartitions) -> Integer.parseInt(key) % numPartitions;
public static KeySelector<String, String> keySelector = value -> value;
输出为:
2> 1
2> 1
1> 2
1> 2
2> 3
2> 3
1> 4
1> 4
可以看到, 数据选择的流和其值符合Integer.parseInt(key) % numPartitions方法计算的结果
分流
分流算子可以将一条数据流转化为完全独立的两条
下面是对数字分流的一个例子: 将数字流划分为奇数流和偶数流
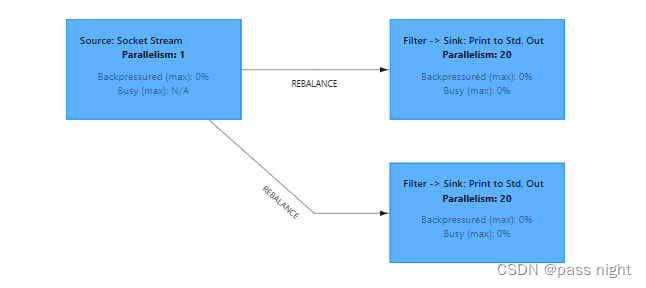
Filter实现分流
可以对数据流分别使用不同的条件进行过滤, 数据被过滤器给过滤成了两个流; 这样实现性能较差, 因为每个过滤器都要处理所有的数据
class SplitByFilter {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(new Configuration());
DataStreamSource<String> dataStream = env.socketTextStream("server.passnight.local", 30000);
// 使用filter分流
dataStream.filter(x -> Integer.parseInt(x) % 2 == 0).print("EvenStream");
dataStream.filter(x -> Integer.parseInt(x) % 2 == 1).print("OddStream");
env.execute();
}
}
输出为:
# 输入1-5的数字
OddStream:5> 1
EvenStream:17> 2
OddStream:7> 3
EvenStream:19> 4
OddStream:9> 5
从webUI中可以看到已经分成两个流了
侧输出流实现分流
假设有程序的上下文, 便可以调用上下文的output; 这样就可以输出任何类型的数据到任意流中了
class SplitBySideOutput {
public static void main(String[] args) throws Exception {
final OutputTag<WaterSensor> stream1Tag = new OutputTag<>("stream1", Types.POJO(WaterSensor.class));
final OutputTag<WaterSensor> stream2Tag = new OutputTag<>("stream2", Types.POJO(WaterSensor.class));
@Cleanup
StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(new Configuration());
SingleOutputStreamOperator<WaterSensor> process = env.socketTextStream("server.passnight.local", 30000)
.map(value -> new WaterSensor("s" + Integer.parseInt(value) % 3, Long.parseLong(value), Integer.parseInt(value)))
.process(new ProcessFunction<>() {
@Override
public void processElement(WaterSensor waterSensor, ProcessFunction<WaterSensor, WaterSensor>.Context ctx, Collector<WaterSensor> out) throws Exception {
if (waterSensor.getVc() < 5 && waterSensor.getVc() > 0) {
// 当 waterSensor.vc in (0,5)时走这条支流
ctx.output(stream1Tag, waterSensor);
} else if (waterSensor.getVc() > 5 && waterSensor.getVc() < 10) {
// 当 waterSensor.vc in (5,10)时走这条支流
ctx.output(stream2Tag, waterSensor);
} else {
// 默认走主流
out.collect(waterSensor);
}
}
});
process.print(); // 打印主流的数据
// 从主流中获取测流数据
process.getSideOutput(stream1Tag).print("侧流1");
process.getSideOutput(stream2Tag).print("侧流2");
env.execute();
}
}
输出结果为:
输入为: 8,9,10,11,12
侧流1:8> WaterSensor(id=s1, ts=1, vc=1)
9> WaterSensor(id=s1, ts=10, vc=10)
侧流2:10> WaterSensor(id=s2, ts=8, vc=8)
11> WaterSensor(id=s2, ts=5, vc=5)
侧流1:12> WaterSensor(id=s1, ts=1, vc=1)
合流
使用union合流
class CombineByUnion {
public static void main(String[] args) throws Exception {
@Cleanup
StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(new Configuration());
DataStreamSource<Integer> dataStream1 = env.fromElements(1, 2, 3, 4, 5, 6);
DataStreamSource<Integer> dataStream2 = env.fromElements(11, 22, 33, 44, 55, 66);
DataStreamSource<String> dataStream3 = env.fromElements("111", "222", "333", "444", "555", "666");
dataStream1.union(dataStream2)
.union(dataStream3.map(Integer::parseInt))
.print();
env.execute();
}
}
输出结果为:
4> 11
5> 22
6> 33
7> 44
7> 111
8> 55
8> 222
9> 66
9> 333
10> 444
11> 555
12> 666
13> 1
14> 2
15> 3
16> 4
17> 5
18> 6
Connect
Union只支持相同数据类型的合流, 而Connect支持不同数据类型的合流, 但是它得到的不是DataStream而是连接流, 它们形式上再一个流中, 但数据时分开的.
class CombineByConnect {
public static class Map {
public static void main(String[] args) throws Exception {
@Cleanup
StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(new Configuration());
DataStreamSource<Integer> dataStream1 = env.fromElements(1, 2, 3);
DataStreamSource<String> dataStream3 = env.fromElements("a", "b", "c");
// connect支持类型不一样的数据类型的流
// connect只能执行一次
dataStream1.connect(dataStream3)
.map(new CoMapFunction<Integer, String, String>() {
@Override
public String map1(Integer value) {
return String.valueOf(value * 10);
}
@Override
public String map2(String value) {
return value;
}
}).print();
env.execute();
}
}
}
输出结果为:
20> a
10> 10
2> c
11> 20
1> b
12> 30
输出算子(sink)
输出到文件系统
class FileSinkOutput {
public static void main(String[] args) throws Exception {
@Cleanup
StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(new Configuration());
DataGeneratorSource<Long> dataSource = new DataGeneratorSource<>(x -> x, Long.MAX_VALUE, RateLimiterStrategy.perSecond(1000), Types.LONG);
env.enableCheckpointing(2000, CheckpointingMode.EXACTLY_ONCE); // 必须开启CheckPoint, 否则文件一直都处于in progress状态
env.fromSource(dataSource, WatermarkStrategy.noWatermarks(), "dataGenerator")
.sinkTo(FileSink.<Long>forRowFormat(new Path("output"),
new SimpleStringEncoder<>(StandardCharsets.UTF_8.name()))
// 添加配置
.withOutputFileConfig(OutputFileConfig.builder()
.withPartPrefix("passnight-")
.withPartSuffix(".log")
.build())
// 根据日期文件分桶
.withBucketAssigner(new DateTimeBucketAssigner<>("yyyy-MM-dd HH", ZoneId.systemDefault()))
// 设置滚动策略
.withRollingPolicy(DefaultRollingPolicy.builder()
.withRolloverInterval(Duration.ofSeconds(10)) // 每10s一个滚动
.withMaxPartSize(new MemorySize(1024)) // 每1Kb一个滚动
.build())
.build());
env.execute();
}
}
可以看到数据已经成功输出到文件系统

输出到Kafka
注意假设要配置精确一次, 要开启CheckPoint/事务时间及事务前缀
class KafkaSinkOutput {
public static void main(String[] args) throws Exception {
@Cleanup
StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(new Configuration());
env.enableCheckpointing(2000, CheckpointingMode.EXACTLY_ONCE); // 精确一次必须开启check pint
KafkaSink<String> kafkaSink = KafkaSink.<String>builder()
// 指定kafka地址
.setBootstrapServers("server.passnight.local:20015,replica.passnight.local:20015,follower.passnight.local:20015")
.setRecordSerializer(KafkaRecordSerializationSchema.<String>builder()
.setTopic("test") // 设置主题
.setValueSerializationSchema(new SimpleStringSchema()) // 设置序列化其
.build())
.setDeliveryGuarantee(DeliveryGuarantee.EXACTLY_ONCE) // 配置"精确一次"
.setTransactionalIdPrefix("passnight-") // 若要配置精确一次, 必须设置事务
// 若要配置精确一次, 必须配置事务超时时间; 这个值必须小于transaction.max.timeout.ms=15min
.setProperty(ProducerConfig.TRANSACTION_TIMEOUT_CONFIG, String.valueOf(10 * 60 * 1000))
.build();
env.socketTextStream("server.passnight.local", 30000)
.sinkTo(kafkaSink);
env.execute();
}
}
可以看到数据已经成功被Kafka 消费者消费

输出到jdbc
先在数据库创建对应的表
CREATE TABLE flink_output
(
id INT PRIMARY KEY AUTO_INCREMENT,
value VARCHAR(32)
)
之后编写java代码操作flink
class JdbcSinkOutput {
public static void main(String[] args) throws Exception {
@Cleanup
StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(new Configuration());
env.enableCheckpointing(2000, CheckpointingMode.EXACTLY_ONCE);
SinkFunction<String> jdbcSinkFunction = JdbcSink.sink("INSERT INTO flink_output (value) VALUES (?);",
(JdbcStatementBuilder<String>) (preparedStatement, s) -> preparedStatement.setString(1, s),
JdbcExecutionOptions.builder()
.withMaxRetries(3) // 最多重试3次
.withBatchSize(100) // 达到100条一批
.withBatchIntervalMs(3000) // **或**3s一批
.build(),
new JdbcConnectionOptions.JdbcConnectionOptionsBuilder()
.withUrl("jdbc:mysql://localhost/test")
.withUsername("test")
.withPassword("123456")
.withConnectionCheckTimeoutSeconds(60) // mysql连接会超时, 因此需要心跳保活(默认是8h)
.build());
env.socketTextStream("server.passnight.local", 30000)
.addSink(jdbcSinkFunction);
env.execute();
}
}
使用netcat发送数据后, 可以看到已经有数据被存储到MySQL中了
自定义输出流
对于flink来说, 一般无需使用自定义的输出流, 因为流式处理系统的错误恢复/事务实现非常复杂, 且一般不宜从头开始; 以下是一个可以将数据输出到标准输出的简单例子
class CustomerSinkOutput {
public static void main(String[] args) throws Exception {
SinkFunction<String> mySinkFunction = new RichSinkFunction<>() {
PrintStream output;
@Override
public void open(Configuration parameters) throws Exception {
super.open(parameters);
// 创建输出流
output = System.out;
}
/**
* 调用这个方法输出到标准输出流
* @param value The input record.
* @param context Additional context about the input record.
* @throws Exception 继承父类异常
*/
@Override
public void invoke(String value, Context context) throws Exception {
super.invoke(value, context);
output.printf("MySink: %s%n", value);
}
@Override
public void close() throws Exception {
super.close();
// 关闭输出流
output = null;
}
};
@Cleanup
StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(new Configuration());
env.enableCheckpointing(2000, CheckpointingMode.EXACTLY_ONCE);
env.socketTextStream("server.passnight.local", 30000)
.addSink(mySinkFunction);
env.execute();
}
}
标准输出打印了
MySink: 123132
窗口
- Flink是一个流式计算引擎, 面对的数据对象是无界数据流; 为了更好地管理和处理该无界流, 可以将无限的数据切割成有限的数据块进行处理, 这个数据块就是窗口
基本概念
分类
-
按照驱动类型划分
-
事件窗口(IMEI Window: 时间窗口是以时间点来定义开始和节数
-
计数窗口(Count Window): 基于元素的个数获取数据, 当达到设定的个数时就触发计算并关闭窗口
-
-
按照窗口分配数据的规则划分
-
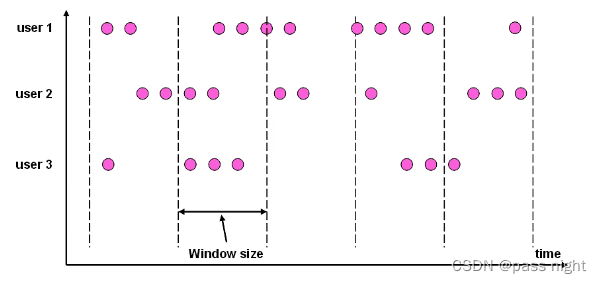
滚动窗口(Tumbling Window): 是一种对数据的均匀切片的划分方式, 窗口之间没有重叠 例如每一个小时划分一个窗口就是一个典型的滚动窗口
-
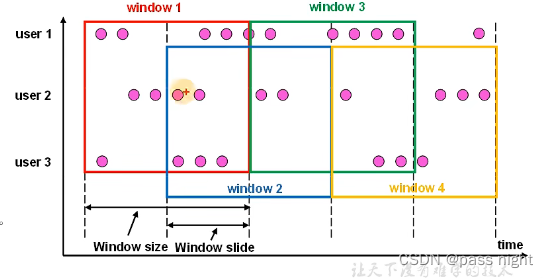
滑动窗口: 滑动窗口的大小是固定的, 但是窗口之间不是首尾相接而是重叠的 如下图
- 滑动窗口有两个参数: 窗口大小和滑动步长
- 这样数据可能属于多个窗口
- 滚动窗口可以看做特殊的滑动窗口 窗口大小 ≤ \le ≤滑动步长
-
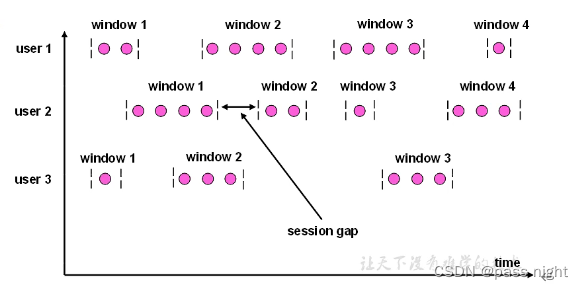
会话窗口: 会话窗口是基于会话对数据进行分组的, 会话窗口只能基于时间来定义
- 会话的特点有: 长度不固定, 事件不固定, 不会重叠
-
全局窗口: 即将所有的数据都分配到一个窗口, 这种窗口没有结束的时候因此也不会触发计算
-
窗口分配器
- 窗口的操作主要分为两个部分: 窗口分配器和窗口函数
- 窗口分配器指定窗口类型
- 窗口分配器除了上一节介绍的分类方式以外, 还有是否有
keyBy的窗口, 没有keyBy的窗口所有数据都进入到一个子任务, 且并行度为1
- 窗口分配器除了上一节介绍的分类方式以外, 还有是否有
- 以下是各种类型的窗口声明
dataSource.keyBy(t -> t).window(TumblingProcessingTimeWindows.of(Time.seconds(10))); // 窗口长度为10的滚动窗口
dataSource.keyBy(t -> t).window(SlidingProcessingTimeWindows.of(Time.seconds(10), Time.seconds(2))); // 窗口长度为10, 步长为2的滑动窗口
dataSource.keyBy(t -> t).window(ProcessingTimeSessionWindows.withGap(Time.seconds(5))); // 超时时长为5s的会话窗口
dataSource.keyBy(t -> t).countWindow(5); // 窗口长度为5的滚动计数窗口
dataSource.keyBy(t -> t).countWindow(5, 2); // 窗口长度为5, 滑动步长为2的滑动窗口
dataSource.keyBy(t -> t).window(GlobalWindows.create()); // 全局窗口(计数窗口的底层就是这个)
窗口函数
- 窗口函数指定对数据的计算逻辑
reduce函数
class Reduce {
public static void main(String[] args) throws Exception {
@Cleanup
StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(new Configuration());
env.socketTextStream("server.passnight.local", 30000)
.keyBy(t -> t)
.window(TumblingProcessingTimeWindows.of(Time.seconds(3)))
.reduce((ReduceFunction<String>) (value1, value2) -> value1 + "|" + value2)
.print();
env.execute();
}
}
对于输入:
passnight@passnight-s600:~$ netcat -lk 30000
# 前3s输入
1
1
1
# 后3s输入
2
2
23
输出结果为:
# 第1个3s输出
9> 1|1|1
# 第2个3s输出
5> 2|2
10> 23
可以看到每3s对所有的输入进行keyBy后reduce
aggreage函数
reduce的输入/中间结果/输出的数据类型必须是一致的, 为aggregate的三个类型都可以不一样; 下面是一个统计单词词频的例子
static void main(String[] args) throws Exception {
@Cleanup
StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(new Configuration());
env.socketTextStream("server.passnight.local", 30000)
.keyBy(t -> t)
.window(TumblingProcessingTimeWindows.of(Time.seconds(3)))
// 第1个类型: 输入数据类型, 代表单词
// 第2个类型: 累加器类型(即中间结果类型); 这里代表词频
// 第3个类型: 输出类型, 这里代表格式化后的词频表示
.aggregate(new AggregateFunction<String, Integer, String>() {
@Override
public Integer createAccumulator() {
System.out.println("WindowAggregate.createAccumulator");
return 0;
}
@Override
public Integer add(String value, Integer accumulator) {
System.out.println("WindowAggregate.add");
return accumulator + 1;
}
@Override
public String getResult(Integer accumulator) {
System.out.println("WindowAggregate.getResult");
return String.format("词频: %d", accumulator);
}
// 这个一般只有会话窗口会用到
@Override
public Integer merge(Integer a, Integer b) {
System.out.println("WindowAggregate.merge");
return null;
}
})
.print();
env.execute();
}
输入为:
1
1
2
34
5
6
6
64
2
4
2
# 第1个3s
3
3
3
3
3
3
3
# 第2个3s
3
3
3
3
3
# 第3个3s
3
输出为:
WindowAggregate.createAccumulator
WindowAggregate.add
WindowAggregate.getResult
9> 词频: 1
WindowAggregate.createAccumulator
WindowAggregate.add
WindowAggregate.createAccumulator
WindowAggregate.add
WindowAggregate.createAccumulator
WindowAggregate.add
WindowAggregate.createAccumulator
WindowAggregate.add
WindowAggregate.getResult
WindowAggregate.getResult
9> 词频: 1
15> 词频: 1
WindowAggregate.getResult
13> 词频: 1
WindowAggregate.getResult
5> 词频: 1
WindowAggregate.createAccumulator
WindowAggregate.add
WindowAggregate.add
WindowAggregate.createAccumulator
WindowAggregate.add
WindowAggregate.createAccumulator
WindowAggregate.add
WindowAggregate.getResult
WindowAggregate.getResult
10> 词频: 1
3> 词频: 2
WindowAggregate.getResult
5> 词频: 1
WindowAggregate.createAccumulator
WindowAggregate.add
WindowAggregate.createAccumulator
WindowAggregate.add
5> 词频: 1
1> 词频: 1
WindowAggregate.createAccumulator
WindowAggregate.add
WindowAggregate.add
WindowAggregate.add
WindowAggregate.add
WindowAggregate.add
WindowAggregate.add
WindowAggregate.add
WindowAggregate.getResult
6> 词频: 7
WindowAggregate.createAccumulator
WindowAggregate.add
WindowAggregate.add
WindowAggregate.add
WindowAggregate.add
WindowAggregate.add
WindowAggregate.getResult
6> 词频: 5
WindowAggregate.createAccumulator
WindowAggregate.add
WindowAggregate.add
WindowAggregate.getResult
6> 词频: 1
可以看到每3s调用一个createAccumulate, 并重置计数器
全窗口(process)函数
全窗口函数可以在窗口执行的时候运行, 并且获得全窗口对象等上下文信息
class Process {
public static void main(String[] args) throws Exception {
@Cleanup
StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(new Configuration());
env.socketTextStream("server.passnight.local", 30000)
.keyBy(t -> t)
.window(TumblingProcessingTimeWindows.of(Time.seconds(3)))
.process(new ProcessWindowFunction<String, String, String, TimeWindow>() {
/**
* @param s The key for which this window is evaluated.
* @param context The context in which the window is being evaluated.
* @param elements The elements in the window being evaluated.
* @param out A collector for emitting elements.
*/
@Override
public void process(String s, ProcessWindowFunction<String, String, String, TimeWindow>.Context context, Iterable<String> elements, Collector<String> out) {
String startTimestamp = DateFormatUtils.format(context.window().getStart(), "yyyy-MM-dd HH:mm:ss.SSS");
String endTimestamp = DateFormatUtils.format(context.window().getEnd(), "yyyy-MM-dd HH:mm:ss.SSS");
long count = elements.spliterator().estimateSize();
out.collect(String.format("startTimestamp: %s, endTimestamp: %s, count: %d", startTimestamp, endTimestamp, count));
}
})
.print();
env.execute();
}
}
输入为:
# 第1个3s
1
# 第2个3s
1
1
1
1
1
1
输出为:
9> startTimestamp: 2023-11-12 15:06:03.000, endTimestamp: 2023-11-12 15:06:06.000, count: 1
9> startTimestamp: 2023-11-12 15:06:18.000, endTimestamp: 2023-11-12 15:06:21.000, count: 5
不同窗口类型
时间窗口
static class AllTimeWindow {
public static void main(String[] args) throws Exception {
@Cleanup
StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(new Configuration());
env.socketTextStream("server.passnight.local", 30000)
.keyBy(t -> t)
// .window(TumblingProcessingTimeWindows.of(Time.seconds(3))) // 滚动窗口
// .window(SlidingProcessingTimeWindows.of(Time.seconds(10), Time.seconds(5))) // 长度10s, 步长5s的滑动窗口
// .window(ProcessingTimeSessionWindows.withGap(Time.seconds(5))) // 间隔5s的会话窗口
.window(ProcessingTimeSessionWindows.withDynamicGap((SessionWindowTimeGapExtractor<String>) element -> Integer.parseInt(element) * 1000L)) // 动态调整间隔时间的会话窗口
.reduce((ReduceFunction<String>) (value1, value2) -> value1 + "|" + value2, new ProcessWindowFunction<String, String, String, TimeWindow>() {
@Override
public void process(String s, ProcessWindowFunction<String, String, String, TimeWindow>.Context context, Iterable<String> elements, Collector<String> out) {
String startTimestamp = DateFormatUtils.format(context.window().getStart(), "yyyy-MM-dd HH:mm:ss.SSS");
String endTimestamp = DateFormatUtils.format(context.window().getEnd(), "yyyy-MM-dd HH:mm:ss.SSS");
long count = elements.spliterator().estimateSize();
out.collect(String.format("startTimestamp: %s, endTimestamp: %s, count: %d, data: %s", startTimestamp, endTimestamp, count, elements));
}
})
.print();
env.execute();
}
}
滑动时间窗口
可以看到一个数据被消费了两次, 因为窗口长度是步长的2倍
5> startTimestamp: 2023-11-12 15:24:15.000, endTimestamp: 2023-11-12 15:24:25.000, count: 1, data: [2|2|2|2]
6> startTimestamp: 2023-11-12 15:24:15.000, endTimestamp: 2023-11-12 15:24:25.000, count: 1, data: [3|3|3]
9> startTimestamp: 2023-11-12 15:24:15.000, endTimestamp: 2023-11-12 15:24:25.000, count: 1, data: [1|1|1]
1> startTimestamp: 2023-11-12 15:24:20.000, endTimestamp: 2023-11-12 15:24:30.000, count: 1, data: [4|4|4]
18> startTimestamp: 2023-11-12 15:24:20.000, endTimestamp: 2023-11-12 15:24:30.000, count: 1, data: [7]
6> startTimestamp: 2023-11-12 15:24:20.000, endTimestamp: 2023-11-12 15:24:30.000, count: 1, data: [3|3|3|3]
13> startTimestamp: 2023-11-12 15:24:20.000, endTimestamp: 2023-11-12 15:24:30.000, count: 1, data: [5|5]
9> startTimestamp: 2023-11-12 15:24:20.000, endTimestamp: 2023-11-12 15:24:30.000, count: 1, data: [1|1|1]
5> startTimestamp: 2023-11-12 15:24:20.000, endTimestamp: 2023-11-12 15:24:30.000, count: 1, data: [2|2|2|2]
3> startTimestamp: 2023-11-12 15:24:20.000, endTimestamp: 2023-11-12 15:24:30.000, count: 1, data: [6|6]
9> startTimestamp: 2023-11-12 15:24:25.000, endTimestamp: 2023-11-12 15:24:35.000, count: 1, data: [1]
13> startTimestamp: 2023-11-12 15:24:25.000, endTimestamp: 2023-11-12 15:24:35.000, count: 1, data: [5|5]
3> startTimestamp: 2023-11-12 15:24:25.000, endTimestamp: 2023-11-12 15:24:35.000, count: 1, data: [6|6]
1> startTimestamp: 2023-11-12 15:24:25.000, endTimestamp: 2023-11-12 15:24:35.000, count: 1, data: [4|4|4|4]
18> startTimestamp: 2023-11-12 15:24:25.000, endTimestamp: 2023-11-12 15:24:35.000, count: 1, data: [7]
6> startTimestamp: 2023-11-12 15:24:25.000, endTimestamp: 2023-11-12 15:24:35.000, count: 1, data: [3|3]
6> startTimestamp: 2023-11-12 15:24:30.000, endTimestamp: 2023-11-12 15:24:40.000, count: 1, data: [3]
9> startTimestamp: 2023-11-12 15:24:30.000, endTimestamp: 2023-11-12 15:24:40.000, count: 1, data: [1]
1> startTimestamp: 2023-11-12 15:24:30.000, endTimestamp: 2023-11-12 15:24:40.000, count: 1, data: [4]
13> startTimestamp: 2023-11-12 15:24:30.000, endTimestamp: 2023-11-12 15:24:40.000, count: 1, data: [5]
会话窗口
会话窗口的输出与输入相关, 当5s没有接受到新的输入, 窗口调用一次处理函数
13> startTimestamp: 2023-11-12 15:28:00.116, endTimestamp: 2023-11-12 15:28:12.426, count: 1, data: [5|5|5|5|5|5|5|5|5|5|5]
13> startTimestamp: 2023-11-12 15:28:13.835, endTimestamp: 2023-11-12 15:28:20.638, count: 1, data: [5|5|5|5]
13> startTimestamp: 2023-11-12 15:28:33.563, endTimestamp: 2023-11-12 15:28:41.769, count: 1, data: [5|5|5|5|5|5|5|5|5|5|5]
动态间隔的会话窗口
动态间隔的会话窗口可以根据输入调整间隔时间, 在该例子中, 间隔时间是输入的值Integer.parseInt(element) * 1000L 默认单位是毫秒
6> startTimestamp: 2023-11-12 15:32:48.005, endTimestamp: 2023-11-12 15:32:53.409, count: 1, data: [3|3|3|3|3|3|3|3|3|3|3]
6> startTimestamp: 2023-11-12 15:32:57.121, endTimestamp: 2023-11-12 15:33:01.524, count: 1, data: [3|3|3|3|3|3|3]
13> startTimestamp: 2023-11-12 15:33:20.658, endTimestamp: 2023-11-12 15:33:27.261, count: 1, data: [5|5|5|5|5|5|5|5]
13> startTimestamp: 2023-11-12 15:33:42.489, endTimestamp: 2023-11-12 15:33:55.503, count: 1, data: [5|5|5|5|5|5|5|5|5|5|5|5|5|5|5|5|5]
# 这个输出的时间间隔是8s, 因为flink会按照最新的输入来调整会话时间间隔
3> startTimestamp: 2023-11-12 15:35:39.736, endTimestamp: 2023-11-12 15:35:45.736, count: 1, data: [6]
18> startTimestamp: 2023-11-12 15:35:40.136, endTimestamp: 2023-11-12 15:35:47.136, count: 1, data: [7]
11> startTimestamp: 2023-11-12 15:35:35.350, endTimestamp: 2023-11-12 15:35:50.340, count: 1, data: [8|8|8|8|8|8|8|8]
计数窗口
static class AllCountWindow {
public static void main(String[] args) throws Exception {
@Cleanup
StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(new Configuration());
env.socketTextStream("server.passnight.local", 30000)
.keyBy(t -> t)
.countWindow(5)
.reduce((ReduceFunction<String>) (value1, value2) -> value1 + "|" + value2, new ProcessWindowFunction<String, String, String, GlobalWindow>() {
@Override
public void process(String s, ProcessWindowFunction<String, String, String, GlobalWindow>.Context context, Iterable<String> elements, Collector<String> out) {
String currentTimestamp = DateFormatUtils.format(new Date(), "yyyy-MM-dd HH:mm:ss.SSS");
long count = elements.spliterator().estimateSize();
out.collect(String.format("currentTimestamp: %s, count: %d, data: %s", currentTimestamp, count, elements));
}
})
.print();
env.execute();
}
}
}
简单滑动窗口
计数窗口的执行和时间没有关系, 只和数量有关系, 下面每有5个元素就完成一次输出
9> currentTimestamp: 2023-11-12 15:44:56.391, count: 1, data: [1|1|1|1|1]
9> currentTimestamp: 2023-11-12 15:44:59.464, count: 1, data: [1|1|1|1|1]
9> currentTimestamp: 2023-11-12 15:45:00.566, count: 1, data: [1|1|1|1|1]
9> currentTimestamp: 2023-11-12 15:45:03.771, count: 1, data: [1|1|1|1|1]
带步长的滑动窗口
滑动窗口每经过一个步长会触发一次, 下面蓝色的代表着滑动窗口

时间语义
Flink中的时间大致可以分为两类; 而具体使用哪种时间作为衡量标准, 就是时间语义:
- 事件事件: 数据产生的时间
- 处理时间: 数据开始被处理的时间
水位线
- 在Flink中, 用来衡量事件事件进展的标记, 被称为水位线
有序流中的水位线
- 理想状态下:
- 数据按照生成的先后顺序进入流中, 每条数据产生一个水位线

实际状态下的水位线:
-
如果当前&数据量非常大, 且同时涌来的数据时间差非常小, 其对处理计算没有什么影响, 为了提高效率, 每隔一段时间生成一个水位线:

-
乱序流中的水位线
- 在分布式系统中, 数据在节点间传输, 可能会因为网络延迟的不确定性, 导致数据顺序发生改变, 这就是所谓的乱序数据

-
乱序+数据量小: 为数据添加一个时间戳, 当新的数据到达时, 倘若时间戳是否比之前大, 若比之前小则不生成新的水位线 即只有更大的时间戳到达时才生成新的水位线:

-
乱序+数据量大: 因为数据量过大, 只能周期性地生成水位线, 即取当前时间间隔到达的的最大时间戳为水位线:

-
乱序+数据量大+迟到数据: 为了让窗口能够接收到迟到数据, 可以等待一段时间, 即将当前间隔时间最大的时间戳减去几秒作为水位线
-
如下图, W(9)发生了数据迟到:

-
为了能够包括迟到的8和9, 可以将前四个元素的水位线设置为 w ( 9 − 2 ) w(9-2) w(9−2), 这样当8和9到达时, 也不会被丢弃 触发窗口会触发数据执行及窗口关闭
-

-
-
水位线特性:
- 水位线时插入到数据流中的一个标记, 可以认为是特殊的数据
- 水位线主要的内容是一个时间戳, 用来表示当前事件时间的进展
- 水位线是基于数据的时间戳生成的
- 水位线的时间戳必须单调递增, 以确保任务的事件时间始终一直向前推进
- 水位线可以通过设置延迟来保证正确处理乱序数据
- 一个水位线, 刚表示当前流中的事件时间已经达到了时间戳t, 这代表t之前的所有数据都到齐了, 之后流中就不会出现时间戳小于水位线的数据 这个等待机制是flink实现对乱序数据处理的方法
水位线和窗口的关系
- 误解: flink中窗口是用来处理无界流的核心, 数据源源源不断地流过来, 到某个时间点窗口该关闭了, 就停止收集数据并触发计算及数据结果 窗口是包含水位线等待的数据的
- 窗口是多个存储桶, 数据会被发送到对应的存储桶当中 ,当到达窗口的时间结束时, 就对每个桶汇总的数据进行计算处理 如下图, 等待时间接收到超前的数据应该放到下一个水位线的桶当中:

水位线生成
- 生成原则:
- 保证能够处理的数据是正确的, 到齐的, 之后不会在出现该事件区间的数据
- 但实际情况下, 为了保证绝对正确, 就必须等待足够长的数据, 这样会带来更高的延迟 因此正确性和性能是一对互斥的需求
- 生成策略: flink当中, 可以对流调用
assignTimestampsAndWatermarks()来为数据分配时间戳
有序流水位线
class OrderedWatermark {
public static void main(String[] args) throws Exception {
@Cleanup
StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(new Configuration());
env.socketTextStream("server.passnight.local", 30000)
.assignTimestampsAndWatermarks(WatermarkStrategy.<String>forMonotonousTimestamps()
/* 指定时间戳提取器, 可以从element中提取参数, 也可以直接定义为recordTimestamp
* @param element The element that the timestamp will be assigned to.
* @param recordTimestamp The current internal timestamp of the element, or a negative value, if
* no timestamp has been assigned yet.
*/
.withTimestampAssigner((SerializableTimestampAssigner<String>) (element, recordTimestamp) -> Integer.parseInt(element.split(" ")[1]) * 1000L))
.keyBy(t -> t)
// 要使用Watermark, 需要指定事件时间的窗口
.window(TumblingEventTimeWindows.of(Time.seconds(3)))
.process(new ProcessWindowFunction<String, String, String, TimeWindow>() {
@Override
public void process(String s, ProcessWindowFunction<String, String, String, TimeWindow>.Context context, Iterable<String> elements, Collector<String> out) {
String startTimestamp = DateFormatUtils.format(context.window().getStart(), "yyyy-MM-dd HH:mm:ss.SSS");
String endTimestamp = DateFormatUtils.format(context.window().getEnd(), "yyyy-MM-dd HH:mm:ss.SSS");
long count = elements.spliterator().estimateSize();
out.collect(String.format("startTimestamp: %s, endTimestamp: %s, count: %d, elements: %s", startTimestamp, endTimestamp, count, elements));
}
})
.print();
env.execute();
}
}
输入为:
1 1
1 1
1 2
1 3
因为时间被定义为第二个数字秒, 所以只有当1 4输入时, 才会产生关闭窗口, 触发计算; 且
10> startTimestamp: 1970-01-01 08:00:00.000, endTimestamp: 1970-01-01 08:00:03.000, count: 2, elements: [1 1, 1 1]
1> startTimestamp: 1970-01-01 08:00:00.000, endTimestamp: 1970-01-01 08:00:03.000, count: 1, elements: [1 2]
乱序流水位线
class UnorderedWatermark {
public static void main(String[] args) throws Exception {
@Cleanup
StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(new Configuration());
env.socketTextStream("server.passnight.local", 30000)
// 等待3秒时间
.assignTimestampsAndWatermarks(WatermarkStrategy.<String>forBoundedOutOfOrderness(Duration.ofSeconds(3))
.withTimestampAssigner((SerializableTimestampAssigner<String>) (element, recordTimestamp) -> Integer.parseInt(element.split(" ")[1]) * 1000L))
.keyBy(t -> t)
// 要使用Watermark, 需要指定事件时间的窗口
.window(TumblingEventTimeWindows.of(Time.seconds(3)))
.process(new ProcessWindowFunction<String, String, String, TimeWindow>() {
@Override
public void process(String s, ProcessWindowFunction<String, String, String, TimeWindow>.Context context, Iterable<String> elements, Collector<String> out) {
String startTimestamp = DateFormatUtils.format(context.window().getStart(), "yyyy-MM-dd HH:mm:ss.SSS");
String endTimestamp = DateFormatUtils.format(context.window().getEnd(), "yyyy-MM-dd HH:mm:ss.SSS");
long count = elements.spliterator().estimateSize();
out.collect(String.format("startTimestamp: %s, endTimestamp: %s, count: %d, elements: %s", startTimestamp, endTimestamp, count, elements));
}
})
.print();
env.execute();
}
}
输入为:
1 1
1 2
1 4
1 2
1 3
1 6
可以看到,1 4并没有触发窗口计算, 而是等到1 6到达时才触发了计算
10> startTimestamp: 1970-01-01 08:00:00.000, endTimestamp: 1970-01-01 08:00:03.000, count: 1, elements: [1 1]
1> startTimestamp: 1970-01-01 08:00:00.000, endTimestamp: 1970-01-01 08:00:03.000, count: 2, elements: [1 2, 1 2]
自定义周期性生成器
可以通过实现WatermarkGenerator实现一个自定义的水位线生成器, 下面是一个实现有序流水线生成器的例子
class CustomWatermark {
public static class MyWatermarkGenerator<T> implements WatermarkGenerator<T> {
/**
* 乱序等待时间
*/
private final long delayTs;
/**
* 当前位置最大的事件时间
*/
private long maxTs;
public MyWatermarkGenerator(long delayTs) {
this.delayTs = delayTs;
this.maxTs = delayTs + Long.MIN_VALUE + 1;
}
/**
* 每条数据到来都会调用, 用于提取并保存最大的事件时间
*
* @param eventTimestamp 提取到的事件时间
*/
@Override
public void onEvent(T event, long eventTimestamp, WatermarkOutput output) {
maxTs = Math.max(maxTs, eventTimestamp);
}
/**
* 周期性调用, 发送watermark
*/
@Override
public void onPeriodicEmit(WatermarkOutput output) {
System.out.printf("[%d] MyWatermarkGenerator.onPeriodicEmit%n", System.currentTimeMillis());
output.emitWatermark(new org.apache.flink.api.common.eventtime.Watermark(maxTs - delayTs - 1));
}
}
public static void main(String[] args) throws Exception {
@Cleanup
StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(new Configuration());
env.getConfig().setAutoWatermarkInterval(2000); // 设置Watermark发射周期为2s
env.socketTextStream("server.passnight.local", 30000)
// 等待3秒时间
.assignTimestampsAndWatermarks(WatermarkStrategy.forGenerator((WatermarkGeneratorSupplier<String>) context -> new MyWatermarkGenerator<>(3000L))
.withTimestampAssigner((SerializableTimestampAssigner<String>) (element, recordTimestamp) -> Integer.parseInt(element.split(" ")[1]) * 1000L))
.keyBy(t -> t)
.window(TumblingEventTimeWindows.of(Time.seconds(3)))
.process(new ProcessWindowFunction<String, String, String, TimeWindow>() {
@Override
public void process(String s, ProcessWindowFunction<String, String, String, TimeWindow>.Context context, Iterable<String> elements, Collector<String> out) {
String startTimestamp = DateFormatUtils.format(context.window().getStart(), "yyyy-MM-dd HH:mm:ss.SSS");
String endTimestamp = DateFormatUtils.format(context.window().getEnd(), "yyyy-MM-dd HH:mm:ss.SSS");
long count = elements.spliterator().estimateSize();
out.collect(String.format("startTimestamp: %s, endTimestamp: %s, count: %d, elements: %s", startTimestamp, endTimestamp, count, elements));
}
})
.print();
env.execute();
}
}
输入为
1 1
1 2
1 1
1 3
1 4
1 7
可以看到, 大约每200ms就自动调用一次onPeriodicEmit
[1699799485198] MyWatermarkGenerator.onPeriodicEmit
[1699799487199] MyWatermarkGenerator.onPeriodicEmit
[1699799489201] MyWatermarkGenerator.onPeriodicEmit
[1699799491202] MyWatermarkGenerator.onPeriodicEmit
[1699799493204] MyWatermarkGenerator.onPeriodicEmit
10> startTimestamp: 1970-01-01 08:00:00.000, endTimestamp: 1970-01-01 08:00:03.000, count: 2, elements: [1 1, 1 1]
1> startTimestamp: 1970-01-01 08:00:00.000, endTimestamp: 1970-01-01 08:00:03.000, count: 1, elements: [1 2]
自定义断点式水位生成器
水位线不仅可以定时发送, 也可以使用事件驱动的模式; 实现方式非常类似于周期发送, 但是其发送是在onEvent中相应事件
class EventDrivenWatermark {
public static class MyWatermarkGenerator<T> implements WatermarkGenerator<T> {
/**
* 乱序等待时间
*/
private final long delayTs;
/**
* 当前位置最大的事件时间
*/
private long maxTs;
public MyWatermarkGenerator(long delayTs) {
this.delayTs = delayTs;
this.maxTs = delayTs + Long.MIN_VALUE + 1;
}
/**
* 每条数据到来都会调用, 用于提取并保存最大的事件时间
* 直接在这里发送, 即可实现事件驱动
*
* @param eventTimestamp 提取到的事件时间
*/
@Override
public void onEvent(T event, long eventTimestamp, WatermarkOutput output) {
maxTs = Math.max(maxTs, eventTimestamp);
output.emitWatermark(new org.apache.flink.api.common.eventtime.Watermark(maxTs - delayTs - 1));
System.out.println("MyWatermarkGenerator.onEvent");
}
@Override
public void onPeriodicEmit(WatermarkOutput output) {
}
}
public static void main(String[] args) throws Exception {
@Cleanup
StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(new Configuration());
env.getConfig().setAutoWatermarkInterval(2000); // 设置Watermark发射周期为2s
env.socketTextStream("server.passnight.local", 30000)
// 等待3秒时间
.assignTimestampsAndWatermarks(WatermarkStrategy.forGenerator((WatermarkGeneratorSupplier<String>) context -> new MyWatermarkGenerator<>(3000L))
.withTimestampAssigner((SerializableTimestampAssigner<String>) (element, recordTimestamp) -> Integer.parseInt(element.split(" ")[1]) * 1000L))
.keyBy(t -> t)
.window(TumblingEventTimeWindows.of(Time.seconds(3)))
.process(new ProcessWindowFunction<String, String, String, TimeWindow>() {
@Override
public void process(String s, ProcessWindowFunction<String, String, String, TimeWindow>.Context context, Iterable<String> elements, Collector<String> out) {
String startTimestamp = DateFormatUtils.format(context.window().getStart(), "yyyy-MM-dd HH:mm:ss.SSS");
String endTimestamp = DateFormatUtils.format(context.window().getEnd(), "yyyy-MM-dd HH:mm:ss.SSS");
long count = elements.spliterator().estimateSize();
out.collect(String.format("startTimestamp: %s, endTimestamp: %s, count: %d, elements: %s", startTimestamp, endTimestamp, count, elements));
}
})
.print();
env.execute();
}
}
输入为
1 1
1 2
1 5
1 6
每有一条数据输入, 都会触发一次onEvent, 在该函数中, 则会发送水位线
MyWatermarkGenerator.onEvent
MyWatermarkGenerator.onEvent
MyWatermarkGenerator.onEvent
MyWatermarkGenerator.onEvent
1> startTimestamp: 1970-01-01 08:00:00.000, endTimestamp: 1970-01-01 08:00:03.000, count: 1, elements: [1 2]
10> startTimestamp: 1970-01-01 08:00:00.000, endTimestamp: 1970-01-01 08:00:03.000, count: 1, elements: [1 1]
水位线的传递
- 在多分区的情况下, 一个窗口的水位线取决于窗口中各个分区水位线的最小值; 因此假设数据存在偏斜, 可能会导致水位线一直无法被触发
- 为了解决这个问题, 可以设置水位线的空闲等待, 当等待一段时间后
迟到数据的处理
- 实际情况中的数据可能会迟到, 倘若严格按照预定时间关闭窗口, 可能会导致数据丢失 这里注意乱序和迟到区别
- 为了解决这个问题, 可以对到来的时间戳统一减去一个值
- 也可以延迟窗口的关闭; 在延迟时间内再次接收到数据, 窗口可以再次触发执行; 可以通过
allowedLateness进行配置; 只有在超过lateness才会真正关闭窗口 同延迟之前不同, 这个时候是来一条计算一次 - 使用侧流接收数据: 尽管延迟窗口关闭可能还有数据丢失, 这里可以使用测输出流来处理延迟的数据
- 同时存在水位线等待和窗口迟到的原因: 设置watermark等待过高可能会导致数据延迟过高, 因此需要设置窗口允许迟到; 而窗口迟到会及时处理每一条数据, 性能又较差 极端迟到数据可以放到测输出流中输出
基于时间的合流
窗口联结
除了普通的合流功能外, flink还提供了基于时间的合流; 可以对两个相同时间窗口的数据进行合流
public class WindowJoin {
public static void main(String[] args) throws Exception {
@Cleanup
StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(new Configuration());
env.setParallelism(1);
SingleOutputStreamOperator<Tuple2<String, Integer>> dataSource1 = env.fromElements(
Tuple2.of("a", 1),
Tuple2.of("a", 2),
Tuple2.of("b", 1),
Tuple2.of("c", 1))
.assignTimestampsAndWatermarks(WatermarkStrategy.<Tuple2<String, Integer>>forMonotonousTimestamps()
.withTimestampAssigner((SerializableTimestampAssigner<Tuple2<String, Integer>>) (element, recordTimestamp) -> element.f1 * 1000L));
SingleOutputStreamOperator<Tuple3<String, Integer, Integer>> dataSource2 = env.fromElements(Tuple3.of("a", 1, 1),
Tuple3.of("a", 1, 1),
Tuple3.of("a", 11, 1),
Tuple3.of("b", 2, 1),
Tuple3.of("b", 12, 1),
Tuple3.of("c", 14, 1),
Tuple3.of("d", 15, 1))
.assignTimestampsAndWatermarks(WatermarkStrategy.<Tuple3<String, Integer, Integer>>forMonotonousTimestamps()
.withTimestampAssigner((SerializableTimestampAssigner<Tuple3<String, Integer, Integer>>) (element, recordTimestamp) -> element.f1 * 1000L));
// window join
dataSource1.join(dataSource2)
// 获取左侧流的key
.where(tuple -> tuple.f0)
.equalTo(tuple -> tuple.f0)
.window(TumblingEventTimeWindows.of(Time.seconds(5)))
.apply(new FlatJoinFunction<Tuple2<String, Integer>, Tuple3<String, Integer, Integer>, String>() {
/**
* 相当于inner join; 关联的数据会自动调用join方法
* @param first The element from first input.
* @param second The element from second input.
* @param out The collector used to return zero, one, or more elements.
*/
@Override
public void join(Tuple2<String, Integer> first, Tuple3<String, Integer, Integer> second, Collector<String> out) {
System.out.printf("%s<--------->%s%n", first, second);
}
}).print();
env.execute();
}
}
可以看到只有在同一时间窗口的key相同的数据被连接在一起并调用了join方法 这里watermark设置为5, 因此只有第一批数据能被输出
(a,1)<--------->(a,1,1)
(a,1)<--------->(a,1,1)
(a,2)<--------->(a,1,1)
(a,2)<--------->(a,1,1)
(b,1)<--------->(b,2,1)
间隔联结
- 在某些场景下, 要处理的时间间隔是不固定的, 倘若使用滚动窗口或滑动窗口处理, 匹配的数据可能卡在窗口的边缘, 这样这些数据就没有机会匹配了
- 因此可以对时间添加间隔以扩大匹配范围, 这就是间隔联结 因此, 间隔联结只适用事件时间语义
- 对于b匹配a, 匹配条件为: a . t i m e s t a m p + l o w e r B o u n d ≤ b . t i m e s t a m p ≤ a . t i m e s t a m p + u p p d e r B o u n d a.timestamp + lowerBound \le b.timestamp \le a.timestamp + uppderBound a.timestamp+lowerBound≤b.timestamp≤a.timestamp+uppderBound
- flink中支持通过配置
sideOutputLeftLateData和sideOutputRightLateData来将超过时间区间的数据输出到测输出流
class IntervalJoin {
public static void main(String[] args) throws Exception {
@Cleanup
StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(new Configuration());
env.setParallelism(1);
SingleOutputStreamOperator<Tuple2<String, Integer>> dataSource1 = env.fromElements(
Tuple2.of("a", 1),
Tuple2.of("a", 2),
Tuple2.of("b", 3),
Tuple2.of("c", 4))
.assignTimestampsAndWatermarks(WatermarkStrategy.<Tuple2<String, Integer>>forMonotonousTimestamps()
.withTimestampAssigner((SerializableTimestampAssigner<Tuple2<String, Integer>>) (element, recordTimestamp) -> element.f1 * 1000L));
SingleOutputStreamOperator<Tuple3<String, Integer, Integer>> dataSource2 = env.fromElements(Tuple3.of("a", 1, 1),
Tuple3.of("a", 1, 1),
Tuple3.of("a", 11, 1),
Tuple3.of("b", 2, 1),
Tuple3.of("b", 12, 1),
Tuple3.of("c", 14, 1),
Tuple3.of("d", 15, 1))
.assignTimestampsAndWatermarks(WatermarkStrategy.<Tuple3<String, Integer, Integer>>forMonotonousTimestamps()
.withTimestampAssigner((SerializableTimestampAssigner<Tuple3<String, Integer, Integer>>) (element, recordTimestamp) -> element.f1 * 1000L));
OutputTag<Tuple2<String, Integer>> leftLateDataTag = new OutputTag<>("leftLateDataTag", Types.TUPLE(Types.STRING, Types.INT));
OutputTag<Tuple3<String, Integer, Integer>> rightLateDataTag = new OutputTag<>("rightLateDataTag", Types.TUPLE(Types.STRING, Types.INT, Types.INT));
// interval join; 只有keyBy后才能进行interval join
SingleOutputStreamOperator<String> process = dataSource1.keyBy(tuple -> tuple.f0)
.intervalJoin(dataSource2.keyBy(tuple -> tuple.f0))
.between(Time.seconds(-2), Time.seconds(2)) // 指定偏移量的上下界
.sideOutputLeftLateData(leftLateDataTag)
.sideOutputRightLateData(rightLateDataTag)
.process(new ProcessJoinFunction<Tuple2<String, Integer>, Tuple3<String, Integer, Integer>, String>() {
/**
* 对匹配的数据调用process方法
* @param left The left element of the joined pair.
* @param right The right element of the joined pair.
* @param ctx A context that allows querying the timestamps of the left, right and joined pair.
* In addition, this context allows to emit elements on a side output.
* @param out The collector to emit resulting elements to.
*/
@Override
public void processElement(Tuple2<String, Integer> left, Tuple3<String, Integer, Integer> right, ProcessJoinFunction<Tuple2<String, Integer>, Tuple3<String, Integer, Integer>, String>.Context ctx, Collector<String> out) {
out.collect(String.format("%s<--------->%s", left, right));
}
});
process.getSideOutput(leftLateDataTag).print("leftLateDataTag");
process.getSideOutput(rightLateDataTag).print("rightLateDataTag");
process.print("mainStream");
env.execute();
}
}
输出为:
mainStream> (a,1)<--------->(a,1,1)
mainStream> (a,1)<--------->(a,1,1)
mainStream> (a,2)<--------->(a,1,1)
mainStream> (a,2)<--------->(a,1,1)
mainStream> (b,3)<--------->(b,2,1)
处理函数
- 相对于一些较高层次的算子, 许多上下文信息都无法获得如
map无法获得测输出流 - 此时需要使用底层的处理函数, 处理函数提供了一个定时服务, 可以通过它访问流中的事件/时间戳/水位线; 甚至可以注册定时事件
- 事件时间是通过水位线触发的
- 处理时间是根据真实的时间戳触发的
- 使用处理函数一般要实现
ProcessFunction, 它包含了两个抽象方法:processElement和onTimer可以实现一些复杂功能 - 处理函数主要有以下分类:
ProcessFunction: 最基本的处理函数,DataStream直接调用process()时作为参数传入KeyedProcessFucntion: 对流按键分区后的处理函数, 基于KeyedStream调用process()作为参数传入ProcessWindowFunction: 开窗后的处理函数, 也是全窗口函数的代表. 基于WindowedStream调用process()时作为参数传入ProcessAllWindowFunction: 同样时开窗后的函数, 基于AllWindowdStream调用process()作为参数传入CoProcessFunction: 合流后的处理函数ProcessJoinFunction: 间隔连接两条留后的处理函数BroadcastProcessFunction: 广播连接流处理函数KeyedBroadcastProcessFunction: 按键分区后的广播连接流处理函数
基本使用
class KeyedProcess {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
env.socketTextStream("server.passnight.local", 30000)
.map(new WaterSensorMapper())
.assignTimestampsAndWatermarks(WatermarkStrategy.<WaterSensor>forBoundedOutOfOrderness(Duration.ofSeconds(3))
.withTimestampAssigner(((element, recordTimestamp) -> element.getTs() * 1000)))
.keyBy(WaterSensor::getId)
.process(new KeyedProcessFunction<String, WaterSensor, String>() {
/**
* 对每条到达的数据调用{@code processElement}
* @param value The input value.
* @param ctx A {@link Context} that allows querying the timestamp of the element and getting a
* {@link TimerService} for registering timers and querying the time. The context is only
* valid during the invocation of this method, do not store it.
* @param out The collector for returning result values.
*/
@Override
public void processElement(WaterSensor value, KeyedProcessFunction<String, WaterSensor, String>.Context ctx, Collector<String> out) {
// 事件时间, 若没有为null
Long timestamp = ctx.timestamp();
TimerService timerService = ctx.timerService();
long currentProcessingTime = timerService.currentProcessingTime();
// 注册事件时间定时器
timerService.registerEventTimeTimer(5000L);
System.out.printf("KeyedProcess.processElement: 当前时间是%s, 注册了1个5s的定时器%n", timestamp);
// 注册处理时间定时器
timerService.registerProcessingTimeTimer(currentProcessingTime + 5000L);
// // 删除注册时间定时器
// timerService.deleteEventTimeTimer();
// // 删除处理时间定时器
// timerService.deleteProcessingTimeTimer();
// 获取水位线和处理时间
System.out.println("timerService.currentProcessingTime() = " + currentProcessingTime);
System.out.println("timerService.currentWatermark() = " + timerService.currentWatermark());
}
/**
* 当时间进展到定时器注册的时间, 调用该方法
* @param timestamp The timestamp of the firing timer.
* @param ctx An {@link OnTimerContext} that allows querying the timestamp, the {@link
* TimeDomain}, and the key of the firing timer and getting a {@link TimerService} for
* registering timers and querying the time. The context is only valid during the invocation
* of this method, do not store it.
* @param out The collector for returning result values.
*/
@Override
public void onTimer(long timestamp, KeyedProcessFunction<String, WaterSensor, String>.OnTimerContext ctx, Collector<String> out) {
System.out.printf("现在时间是%d, 该方法由定时器触发%n", timestamp);
}
})
.print();
env.execute();
}
}
输入为:
s1 1 1
s1 3 3
s1 8 8 # 注意这个无法触发定时器, 因为水位线默认会-1ms(从输出中也可以看到)
s1 10 10
输出为:
KeyedProcess.processElement: 当前时间是1000, 注册了1个5s的定时器
timerService.currentProcessingTime() = 1699968597609
timerService.currentWatermark() = -9223372036854775808
KeyedProcess.processElement: 当前时间是3000, 注册了1个5s的定时器
timerService.currentProcessingTime() = 1699968599111
timerService.currentWatermark() = -2001
KeyedProcess.processElement: 当前时间是8000, 注册了1个5s的定时器
timerService.currentProcessingTime() = 1699968601515
timerService.currentWatermark() = -1
现在时间是1699968602609, 该方法由定时器触发 # 固定等待5s后会自动触发
KeyedProcess.processElement: 当前时间是9000, 注册了1个5s的定时器
timerService.currentProcessingTime() = 1699968603418
timerService.currentWatermark() = 4999
现在时间是5000, 该方法由定时器触发
现在时间是1699968604111, 该方法由定时器触发
现在时间是1699968606515, 该方法由定时器触发
KeyedProcess.processElement: 当前时间是10000, 注册了1个5s的定时器
timerService.currentProcessingTime() = 1699968606823
timerService.currentWatermark() = 5999
现在时间是5000, 该方法由定时器触发
现在时间是1699968608418, 该方法由定时器触发
现在时间是1699968611823, 该方法由定时器触发
状态管理
-
在flink中, 算子任务可以分为有状态和无状态两种情况
-
无状态的算子任务只需要观察每个独立事件, 然后根据输入的数据直接转换成结果; 如
map,filter,flatMap等不依赖其他数据的算子都属于无状态算子 -
而有状态算子的任务, 除了当前数据之外, 还需要一些其他的数据来得到计算结果, 这里的其他数据就是所谓的状态
-
对于有状态算子, 一般处理流程如下:
- 算子接受上游发来的数据
- 获取当前的状态
- 根据业务逻辑来计算/更新状态
- 得到计算结果, 输出发送到下游任务
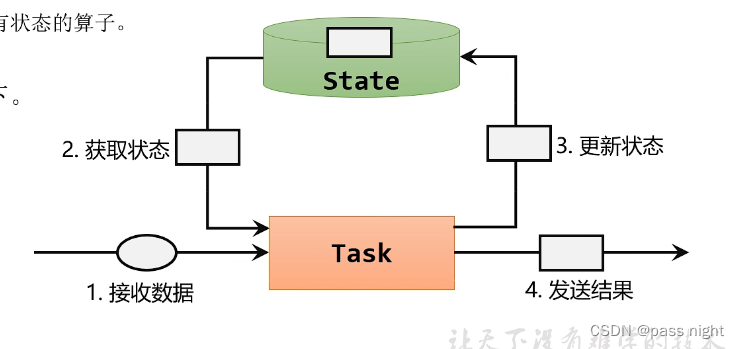
-
状态主要可以分为: 托管状态和原始状态
- 托管状态: 有flink统一管理, 状态的存储访问/故障恢复和重组等一系列问题都由flink实现, 我们只需要调用接口
- 托管状态又可以分为两类: 算子状态和键控状态 后者是经过keyBy算子后的状态
- 原始状态: 是自己定义的, 相当于开辟了一块内存, 有我们自己实现状态管理/序列化和故障恢复
键控状态(Keyed State)
键控状态是按照键来访问和维护的状态
值状态 (Value State)
案例: 检测传感器的水位值, 若连续两个水位差值大于10则报警
class ValueStateExample {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
env.socketTextStream("server.passnight.local", 30000)
.map(new WaterSensorMapper())
.assignTimestampsAndWatermarks(WatermarkStrategy.<WaterSensor>forBoundedOutOfOrderness(Duration.ofSeconds(3))
.withTimestampAssigner(((element, recordTimestamp) -> element.getTs() * 1000)))
.keyBy(WaterSensor::getId)
.process(new KeyedProcessFunction<String, WaterSensor, String>() {
ValueState<Integer> lastVc;
@Override
public void open(Configuration parameters) {
// 通过上下文创建状态, 参数为状态描述器
// 描述器有两个参数: 名称和类型
lastVc = getRuntimeContext().getState(new ValueStateDescriptor<>("lastVc", Types.INT));
}
@Override
public void processElement(WaterSensor waterSensor, KeyedProcessFunction<String, WaterSensor, String>.Context ctx, Collector<String> out) throws Exception {
// 取出上一条数据的水位值
Integer lastVcValue = Objects.requireNonNullElse(lastVc.value(), 0);
// 判断差值是否大于10, 若差值大于10则告警
if (Math.abs(waterSensor.getVc() - lastVcValue) > 10) {
out.collect(String.format("[传感器id %s], 当前水位值: %d, 与上一条水位值: %d, 相差超过10!!!", waterSensor.getId(), waterSensor.getVc(), lastVcValue));
}
// 更新水位值状态
lastVc.update(waterSensor.getVc());
}
}).print();
env.execute();
}
}
输入输出为:
s1 1 1
s1 2 11
s1 3 30
# [传感器id s1], 当前水位值: 30, 与上一条水位值: 11, 相差超过10!!!
s1 4 10
# [传感器id s1], 当前水位值: 10, 与上一条水位值: 30, 相差超过10!!!
s5 5 30
# [传感器id s5], 当前水位值: 30, 与上一条水位值: 0, 相差超过10!!! (初始值为0, 因此输出, 也可以看到flink状态是按键分区的)
列表状态
列表状态存的是列表, 而非元素, 其get方法返回的是一个Iterable对象
案例: 针对每个传感器输出最高的三个水位值
class ListStateExample {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
env.socketTextStream("server.passnight.local", 30000)
.map(new WaterSensorMapper())
.assignTimestampsAndWatermarks(WatermarkStrategy.<WaterSensor>forBoundedOutOfOrderness(Duration.ofSeconds(3))
.withTimestampAssigner(((element, recordTimestamp) -> element.getTs() * 1000)))
.keyBy(WaterSensor::getId)
.process(new KeyedProcessFunction<String, WaterSensor, String>() {
ListState<Integer> top3Vc;
@Override
public void open(Configuration parameters) {
top3Vc = getRuntimeContext().getListState(new ListStateDescriptor<>("top3Vc", Types.INT));
}
@Override
public void processElement(WaterSensor waterSensor, KeyedProcessFunction<String, WaterSensor, String>.Context ctx, Collector<String> out) throws Exception {
// 每来一条数据, 更新top3值
top3Vc.add(waterSensor.getVc());
List<Integer> newTop3 = StreamSupport.stream(top3Vc.get().spliterator(), false)
.sorted(Comparator.reverseOrder())
.limit(3)
.collect(Collectors.toUnmodifiableList());
top3Vc.update(newTop3);
out.collect(String.format("[传感器id %s], top3水位值为: [%s]", waterSensor.getId(), newTop3));
}
}).print();
env.execute();
}
}
输入输出为:
s1 1 1
# [传感器id s1], top3水位值为: [[1]]
s1 2 2
# [传感器id s1], top3水位值为: [[2, 1]]
s1 3 3
# [传感器id s1], top3水位值为: [[3, 2, 1]]
s1 4 4 # 每次只保留top3
# [传感器id s1], top3水位值为: [[4, 3, 2]]
s2 2 2 # 可以看到列表状态是有分组的
# [传感器id s2], top3水位值为: [[2]]
Map状态
类似于java的map
案例: 统计每种水位值出现的次数
class MapStateExample {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
env.socketTextStream("server.passnight.local", 30000)
.map(new WaterSensorMapper())
.assignTimestampsAndWatermarks(WatermarkStrategy.<WaterSensor>forBoundedOutOfOrderness(Duration.ofSeconds(3))
.withTimestampAssigner(((element, recordTimestamp) -> element.getTs() * 1000)))
.keyBy(WaterSensor::getId)
.process(new KeyedProcessFunction<String, WaterSensor, String>() {
MapState<Integer, Integer> frequency;
@Override
public void open(Configuration parameters) {
frequency = getRuntimeContext().getMapState(new MapStateDescriptor<>("frequency", Types.INT, Types.INT));
}
@Override
public void processElement(WaterSensor waterSensor, KeyedProcessFunction<String, WaterSensor, String>.Context ctx, Collector<String> out) throws Exception {
// 每来一条数据, 更新top3值
if (!frequency.contains(waterSensor.getVc())) {
frequency.put(waterSensor.getVc(), 1);
} else {
frequency.put(waterSensor.getVc(), frequency.get(waterSensor.getVc()) + 1);
}
out.collect(String.format("[传感器id %s], 水位频率为: [%s]", waterSensor.getId(),
StreamSupport.stream(frequency.entries().spliterator(), false)
.map(String::valueOf)
.collect(Collectors.joining(","))));
}
}).print();
env.execute();
}
}
输入输出为:
s1 1 1
# [传感器id s1], 水位频率为: [1=1]
s1 2 2
# [传感器id s1], 水位频率为: [1=1,2=1]
s1 1 1
# [传感器id s1], 水位频率为: [1=2,2=1]
s1 1 1
# [传感器id s1], 水位频率为: [1=3,2=1]
s2 1 1 # 可以看到Map状态也按键分区
# [传感器id s2], 水位频率为: [1=1]
s3 1 3
# [传感器id s3], 水位频率为: [3=1]
规约状态
类似于list状态, 但是对于进入的数据都立即规约
案例: 计算每种传感器的水位和
class ReduceStateExample {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
env.socketTextStream("server.passnight.local", 30000)
.map(new WaterSensorMapper())
.assignTimestampsAndWatermarks(WatermarkStrategy.<WaterSensor>forBoundedOutOfOrderness(Duration.ofSeconds(3))
.withTimestampAssigner(((element, recordTimestamp) -> element.getTs() * 1000)))
.keyBy(WaterSensor::getId)
.process(new KeyedProcessFunction<String, WaterSensor, String>() {
ReducingState<Integer> vcSum;
@Override
public void open(Configuration parameters) {
vcSum = getRuntimeContext().getReducingState(new ReducingStateDescriptor<>("vcSum", Integer::sum, Types.INT));
}
@Override
public void processElement(WaterSensor waterSensor, KeyedProcessFunction<String, WaterSensor, String>.Context ctx, Collector<String> out) throws Exception {
vcSum.add(waterSensor.getVc());
out.collect(String.format("[传感器id %s], 水位和为: [%d]", waterSensor.getId(), vcSum.get()));
}
}).print();
env.execute();
}
}
输入为:
s1 1 1
s1 2 2
s1 3 10
s2 1 1
s2 2 10
输出为, 可以看到已经根据key分组并求和规约:
[传感器id s1], 水位和为: [1]
[传感器id s1], 水位和为: [3]
[传感器id s1], 水位和为: [13]
[传感器id s2], 水位和为: [1]
[传感器id s2], 水位和为: [11]
聚合状态
聚合状态类似于聚合操作, 同reduce一样, 累加器, 输入输出值类型可以不一样
案例: 计算每种传感器的平均水位
class AggregationStateExample {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
env.socketTextStream("server.passnight.local", 30000)
.map(new WaterSensorMapper())
.assignTimestampsAndWatermarks(WatermarkStrategy.<WaterSensor>forBoundedOutOfOrderness(Duration.ofSeconds(3))
.withTimestampAssigner(((element, recordTimestamp) -> element.getTs() * 1000)))
.keyBy(WaterSensor::getId)
.process(new KeyedProcessFunction<String, WaterSensor, String>() {
AggregatingState<Integer, Double> vcAvg;
@Override
public void open(Configuration parameters) {
vcAvg = getRuntimeContext().getAggregatingState(new AggregatingStateDescriptor<Integer, Tuple2<Integer, Integer>, Double>("vcAvg",
new AggregateFunction<>() {
@Override
public Tuple2<Integer, Integer> createAccumulator() {
return Tuple2.of(0, 0);
}
@Override
public Tuple2<Integer, Integer> add(Integer value, Tuple2<Integer, Integer> accumulator) {
return Tuple2.of(accumulator.f0 + value, accumulator.f1 + 1);
}
@Override
public Double getResult(Tuple2<Integer, Integer> accumulator) {
return accumulator.f0 * 1D / accumulator.f1;
}
@Override
public Tuple2<Integer, Integer> merge(Tuple2<Integer, Integer> a, Tuple2<Integer, Integer> b) {
return Tuple2.of(a.f0 + b.f0, a.f1 + b.f1);
}
},
Types.TUPLE(Types.INT, Types.INT)));
}
@Override
public void processElement(WaterSensor waterSensor, KeyedProcessFunction<String, WaterSensor, String>.Context ctx, Collector<String> out) throws Exception {
vcAvg.add(waterSensor.getVc());
out.collect(String.format("[传感器id %s], 水位平均值: %d", waterSensor.getId(), vcAvg.get()));
}
}).print();
env.execute();
}
}
输入为:
s1 1 1
s1 1 3
s1 1 3
s2 1 1
s2 1 4
s1 1 5
输出为, 可以看到已经实现分组求平均值了:
[传感器id s1], 水位平均值: 1.000000
[传感器id s1], 水位平均值: 2.000000
[传感器id s1], 水位平均值: 2.333333
[传感器id s2], 水位平均值: 1.000000
[传感器id s2], 水位平均值: 2.500000
[传感器id s1], 水位平均值: 3.000000
状态生存时间
- 一般情况下, 可以调用
clear清理状态 - 但是有的时候, 不能直接清楚, 这是需要配置一个状态的生存时间(time to live), 到期后清楚状态
- 状态的删除并不是开一个线程不断扫描状态是否过期, 而是给状态附加一个属性, 当对状态访问或修改时可以对失效时间更新, 当清除条件被触发时, 就可以判断状态是否失效, 并进行清除
- 状态生存时间主要有几个配置:
newBuilder: 设定生存时间setUpdateType: 指定什么时候更新失效时间, 可以指定OnCreateAndWrite/OnReadAndWrite等, 默认是前者setStateVisibility: 设置可见性, 因为清除并不是实时的, 所以当状态过期后依旧可能访问到未清除的过期状态, 此时可以配置NeverReturnExpired表示从不返回过期值即过期即清除; 还可以配置ReturnExpireDefNotCleanedUp表示若未清理, 则返回它的值
class ValueStateTtl {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
env.socketTextStream("server.passnight.local", 30000)
.map(new WaterSensorMapper())
.assignTimestampsAndWatermarks(WatermarkStrategy.<WaterSensor>forBoundedOutOfOrderness(Duration.ofSeconds(3))
.withTimestampAssigner(((element, recordTimestamp) -> element.getTs() * 1000)))
.keyBy(WaterSensor::getId)
.process(new KeyedProcessFunction<String, WaterSensor, String>() {
ValueState<Integer> lastVc;
@Override
public void open(Configuration parameters) {
StateTtlConfig ttlConfig = StateTtlConfig
.newBuilder(Time.seconds(5)) // 过期时间为5s
.setUpdateType(StateTtlConfig.UpdateType.OnCreateAndWrite) // 创建/写入(更新)时更新过期时间
.setStateVisibility(StateTtlConfig.StateVisibility.NeverReturnExpired) // 不返回过期的状态值
.build();
ValueStateDescriptor<Integer> stateDescriptor = new ValueStateDescriptor<>("lastVc", Types.INT);
stateDescriptor.enableTimeToLive(ttlConfig);
lastVc = getRuntimeContext().getState(stateDescriptor);
}
@Override
public void processElement(WaterSensor waterSensor, KeyedProcessFunction<String, WaterSensor, String>.Context ctx, Collector<String> out) throws Exception {
out.collect(String.format("[传感器id %s], 当前水位值: %d, 与上一条水位值: %d", waterSensor.getId(), waterSensor.getVc(), lastVc.value()));
lastVc.update(waterSensor.getVc());
}
}).print();
env.execute();
}
}
输入输出为:
s1 1 1
[传感器id s1], 当前水位值: 1, 与上一条水位值: null
s1 2 2 # 等待5s, 状态被清除了
[传感器id s1], 当前水位值: 2, 与上一条水位值: null
s1 3 3
[传感器id s1], 当前水位值: 3, 与上一条水位值: 2
s1 4 4 # 等待5s, 状态被清除了
[传感器id s1], 当前水位值: 4, 与上一条水位值: null
s1 5 5
[传感器id s1], 当前水位值: 5, 与上一条水位值: 4
s1 6 6
[传感器id s1], 当前水位值: 6, 与上一条水位值: 5
s1 7 7
[传感器id s1], 当前水位值: 7, 与上一条水位值: 6
算子状态
- 算子状态是算子并行实例上定义的状态, 作用范围被限定为当前算子任务
- 算子状态和key无关, 只要key数据被分发到同一个并行算子任务, 就会访问同一个Operator State
列表状态&联合列表状态
案例: 在map算子中计算数据的条数
这里使用List而非UnionList, 因为后者在重分区会将合并后的状态发送到所有分区, 而前者在合并后, 通过轮询分配到新的分区; 后者存在资源浪费的
class OperatorListStateExample {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(2);
env.socketTextStream("server.passnight.local", 30000)
.map(new MyCountMapFunction())
.print();
env.execute();
}
// 要使用算子状态, 需要实现`CheckpointedFunction`
public static class MyCountMapFunction implements MapFunction<String, Long>, CheckpointedFunction {
private Long count = 0L;
private ListState<Long> countState;
@Override
public Long map(String value) throws Exception {
return count++;
}
/**
* 保存状态快照, 即将本地变量拷贝到算子状态中
*
* @param context the context for drawing a snapshot of the operator
* @throws Exception 异常
*/
@Override
public void snapshotState(FunctionSnapshotContext context) throws Exception {
System.out.println("保存状态快照");
// 清空算子状态
countState.clear();
// 将本地变量添加到算子状态中
countState.add(count);
}
/**
* 初始化状态, 从状态中把数据拷贝到本地变量, 每个子任务会调用一次
*
* @param context the context for initializing the operator
* @throws Exception 异常
*/
@Override
public void initializeState(FunctionInitializationContext context) throws Exception {
System.out.println("初始化装状态");
// 使用上下文初始化算子状态
countState = context.getOperatorStateStore()
.getListState(new ListStateDescriptor<>("countState", Types.LONG));
if (context.isRestored()) {
for (Long l : countState.get()) {
count += l;
}
}
}
}
}
输出为:
# 程序开始执行时, 会调用"并行度次"初始化状态方法
初始化装状态
初始化装状态
# 在不断输入数据后(任意数据), 可以看到不同分区会访问并累加同一个状态
2> 0
1> 0
2> 1
1> 1
2> 2
1> 2
2> 3
1> 3
广播状态
- 列表状态和联合列表状态在不同的子任务中具有独立的拷贝, 而广播状态会将状态广播到所有的子任务, 所有并行的子任务都会访问同一状态
- 因为广播状态是全局一致的, 因此并行度改变时, 只需要简单拷贝状态或删除状态即可
案例: 水位超过指定阈值则发送告警, 其中阈值可以修改
class OperationBroadcastExample {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(2);
SingleOutputStreamOperator<WaterSensor> sensorDs = env.socketTextStream("server.passnight.local", 30000)
.map(new WaterSensorMapper());
DataStreamSource<String> configDs = env.socketTextStream("server.passnight.local", 30001);
// 广播配置
BroadcastStream<String> configBs = configDs.broadcast(new MapStateDescriptor<>("broadcast-state", Types.STRING, Types.INT));
// 把数据流和广播后的配置流连接起来
BroadcastConnectedStream<WaterSensor, String> sensorBcs = sensorDs.connect(configBs);
// 调用广播链接流
sensorBcs.process(new BroadcastProcessFunction<WaterSensor, String, String>() {
/**
* 数据流的处理方法
* @param waterSensor The stream element.
* @param ctx A {@link ReadOnlyContext} that allows querying the timestamp of the element,
* querying the current processing/event time and updating the broadcast state. The context
* is only valid during the invocation of this method, do not store it.
* @param out The collector to emit resulting elements to
* @throws Exception 父类异常
*/
@Override
public void processElement(WaterSensor waterSensor, BroadcastProcessFunction<WaterSensor, String, String>.ReadOnlyContext ctx, Collector<String> out) throws Exception {
ReadOnlyBroadcastState<String, Integer> broadcastState = ctx.getBroadcastState(new MapStateDescriptor<>("broadcast-state", Types.STRING, Types.INT));
Integer threshold = Objects.requireNonNullElse(broadcastState.get("threshold"), 0);
if (waterSensor.getVc() > threshold) {
out.collect(String.format("[%s], 水位大于阈值%d", waterSensor, threshold));
}
}
/**
* 广播配置流的处理方法
* @param value The stream element.
* @param ctx A {@link Context} that allows querying the timestamp of the element, querying the
* current processing/event time and updating the broadcast state. The context is only valid
* during the invocation of this method, do not store it.
* @param out The collector to emit resulting elements to
* @throws Exception 父类异常
*/
@Override
public void processBroadcastElement(String value, BroadcastProcessFunction<WaterSensor, String, String>.Context ctx, Collector<String> out) throws Exception {
// 获取广播状态
BroadcastState<String, Integer> broadcastState = ctx.getBroadcastState(new MapStateDescriptor<>("broadcast-state", Types.STRING, Types.INT));
// 往广播流中写数据
broadcastState.put("threshold", Integer.valueOf(value));
}
}).print();
env.execute();
}
}
输入输出为:
s1 1 1 # 初始为空, Objects.requireNonNullElse(broadcastState.get("threshold"), 0);
`2> [WaterSensor(id=s1, ts=1, vc=1)], 水位大于阈值0`
10 # 30001端口输入10, 将阈值改为10
s1 1 1 # 1小于新阈值, 不输出
s1 1 15 # 15大于阈值10, 输出
`2> [WaterSensor(id=s1, ts=1, vc=15)], 水位大于阈值10`
状态后端
- 在flink中, 对状态的存储/访问/维护状态是由一个可拔插组件提供的, 这个组件就是状态后端, 其主要职责是: 管理本地状态的存储方式和配置
- 状态后端主要可以分为两个:
HashMapStateBackend是把状态保存在内存当中, 他会将状态保存在Taskmanager的JVM堆上RockDB: 是一个内嵌的Key-Value存储数据库, 可以将数据持久化到磁盘中, 配置了EmbeddedRocksDBStateBackends后, flink就会将处理中的数据放入RocksDB中, 而RockDB默认存储在TaskMaanger的本地数据目录中; RocksDB保存的是被序列化的字节数组, 因此读写需要序列化和反序列化, 由于需要访问磁盘和序列化的缘故, 其性能较差 但其始终执行的是异步快照, 还提供增量式保存检查点, 所以性能也不会太差- 状态后端可以使用
setStateBackend进行配置或指定提交参数-D/flink-config.yaml中配置state.back.type - 注意: 使用rocksDB需要导入依赖
flink-statebackend-rocksdb
容错机制
flink中有一套完整的容错机制来保证故障后的恢复, 其中最重要的就是检查点
检查点
- 在流处理中, 可以使用存档/读档的思路, 将之前某个时间点的所有状态保存下来, 这份存档就是所谓的**检查点 **(CheckPoint)
- 如下图所示, 可以将状态保存在一个外部存储中 如源任务的偏移量/对key的分区信息
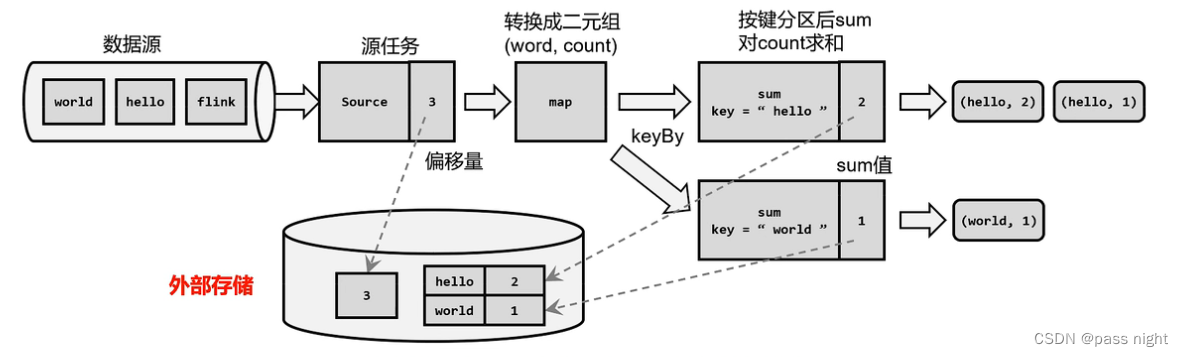
检查点的保存
- 周期性触发保存: 触发保存的频率太低可能会导致故障恢复困难, 而频率太高可能会影响到数据处理的性能. 因此在flink中可以配置周期性的检查点保存, 而且这个间隔时间是可以配置的
- 保存时间点: 所有算子都恰好处理完同一个输入的数据时; 这样如果出现故障, 就可以重新提交偏移量并读取状态重新计算数据 重置偏移量也需要数据源支持, 如kafka的seek
- 保存的具体流程: 当一条数据被处理完成后保存 以WordCount为例, 当一条数据被
map/keyBy/sum和pring之后就会触发保存
检查点恢复
- 重启应用: 当遇到故障后, 第一步就是重启, 但重启后, 所有任务的状态都是空
- 读取检查点, 重置状态: 找到最近一次保存的任务状态的快照, 并将之填充到对应的状态中
- 重置偏移量: 假设继续处理数据而不重置偏移量的话, 快照保存后处理的部分数据就丢失了, 因此需要将偏移量重置到检查点保存时候的偏移量
- 继续处理数据: 在恢复了状态和偏移量之后, 系统就完成了恢复, 可以继续处理数据了
检查点算法
flink基于Chandy-Lamport算法实现了分布式快照, 可以不暂停整体流处理的前提下, 将状态备份到检查点
基本概念
- 检查点分界线(Barrier): 类似水位线, flink会在数据流中插入一个特殊的数据结构, 专门用来触发检查点保存的时间点.
- 收到保存检查点的执行后, Source任务就可以在当前数据流中中插入这个结构; 后续任务只要遇到这个标记就对状态做持久化保存
- 这种特殊的数据形式, 将一条流上的数据按照不同的检查点分隔开, 这就是所谓的检查点的分界线
分布式快照算法(Barrier对齐的精确一次)
- 当barrier经过时, 说明barrier后面的数据都已经完成处理了; 但在多并行度场景下, 还需要考虑:
- 上游任务项多个并行下游发送barrier时, 需要广播出去
- 当上游任务向多个下游任务传递时, 还需要对分界线对齐, 只有对齐后才能进行快照保存
- 算法的具体流程为:
-
JobManager发送指令, 触发检查点保存, 向Source任务中插入边界线; 并将偏移量持久化到存储中
-
之后将偏移量持久化到存储中
-

-
在完成偏移量的存储后, Source任务就会向JobManager确认检查点完成, 然后分界线就会随着流向下游传递
-
map任务没有状态, 因此持久化很容易; 但下一步keyBy会根据key进行分区, sum任务可能会收到上游两个并行map任务的barrier下图红色和蓝色的barrier; 只有所有的barrier都到达后才能进行保存
-
假设上面的分区收到蓝色的barrier但是没有收到红色的barrier的期间, 收到上分区的数据要进行处理因为还没收到分界线说明还没完成计算, 而收到下分区的数据就不处理了, 而是缓存起来再处理 即等待barrier对齐
-
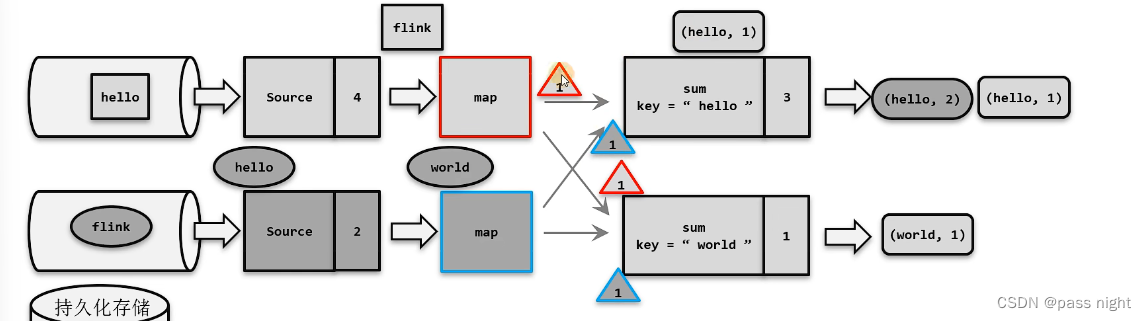
-
当存储完成之后, barrier继续向下游传递, 并向JobManager通知完毕
-
完成检查点保存后, 还要先处理缓存数据再继续处理新的数据
-
Barrier对齐至少一次
至少一次和精确一次非常类似, 这里就简写了
- JobManager发送指令, 插入Barrier, 并持久化偏移量
- 完成持久化后, 通知JobManager存储完成, 并将barrier传到下游
- 当遇到
keyBy算子之后, 需要进行分界线对齐操作; 与精确一次不同的是, 在分界线对齐的过程中, 尽管已经到达的分界线的分区有数据到达后, 会直接计算 这样重启后, 重置偏移量, 就会导致这些数据被计算多次 - 直接计算会提高性能, 但是会降低数据完整性
非Barrier对齐的精确一次
-
JobManager发送指令, 插入Barrier, 并持久化偏移量; 完成持久化后, 通知JobManager存储完成, 并将barrier传到下游
-
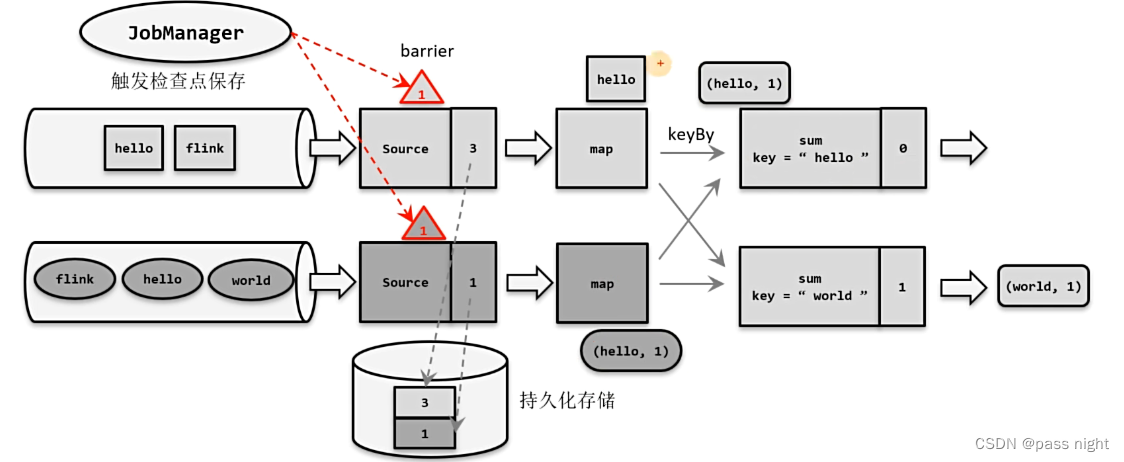
-
此时假设下分区的数据已经完成处理, 并可以进行快照保存, 而上分区
map到上分区sum还在map的输出缓冲区, 而下分区map到上分区sum的数据已经到达sum的输入缓冲区 -
当map向下游广播barrier时, 下分区
sum直接完成状态持久化; 此时秉持这只要in-flinght的数据也保存到状态里, barrier就可以越过所有in-flinght数据继续往下游传递的思想- 上分区直接将barrier放到输出缓冲区末端, 向下游传递 见蓝色三角形
- 这是在标记下分区源越过的输入缓冲区和输出缓冲区的数据, 即其他barrier之前的所有数据 放大的元组
- 此时将所有标记好的数据保存到CheckPoint中, 从CheckPoint恢复时, 这些数据也会一起恢复到对应的位置 该恢复到输入缓冲区的恢复到输入缓冲区, 并可以重新计算, 而该恢复到输出缓冲区的无需重新计算
-
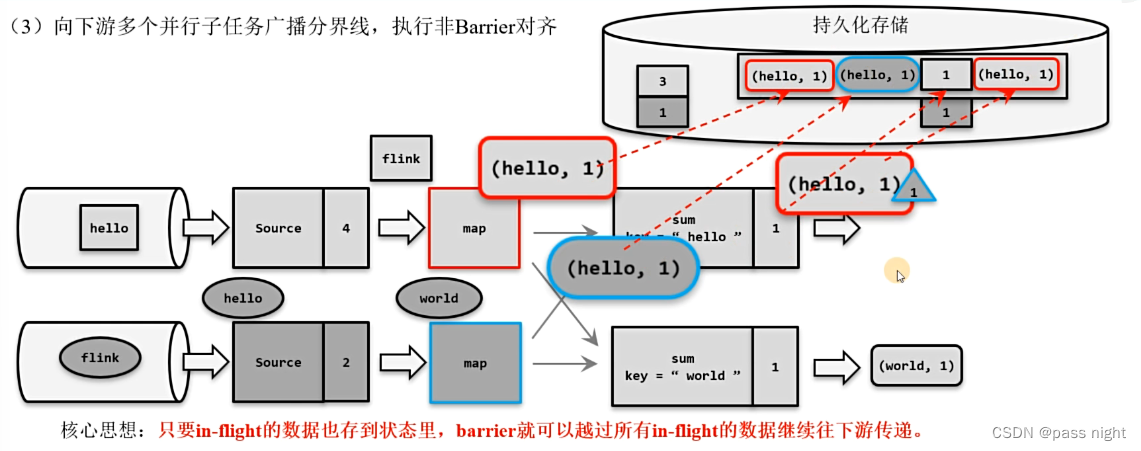
增量CheckPoint
-
执行流程:
-
记录状态: 将带状态的算子任务状态写入变更日志, 变更日志会不断地持久化到检查点存储中, 之后将变更应用到状态表当中
-
状态物化: 定期保存状态表 注意这个独立于检查点, 而是周期性执行
-
当状态物化完成之后, 变更日志就可以截断到相应的点
-
-
特点:
- 会导致文件系统/io/CPU序列化资源/TaskMaanger状态缓存压力变大
- 且不支持CheckPoint并发/
NO_CLAIM模式
-
启动方式
- 启动:
state.backend.changelog.enabled=true - 配置存储方式:
dstl.dfs.base-path - 设置CheckPoint并发为1: ``execution.checkpointing.max-concurrent-checkpoints=1` 增量模式不支持CheckPoint并发
- 启动:
检查点使用
public class FlinkCheckpoint {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(new Configuration());
env.setParallelism(3);
// 开启检查点
// 5s执行一次检查点; 并启动精确一次模式
env.enableCheckpointing(5000, CheckpointingMode.EXACTLY_ONCE);
// 开启变更日志(开启增量CheckPoint)
// env.enableChangelogStateBackend(true);
// 指定检查点的存储位置
CheckpointConfig checkpointConfig = env.getCheckpointConfig();
checkpointConfig.setCheckpointStorage("hdfs://server.passnight.local/test");
// 设置checkpoint的超时时间, 默认为10min
checkpointConfig.setCheckpointTimeout(6000);
// 同时运行的CheckPoint最大数量; 一般来说尽量不要两个CheckPoint并行, 所以设置为1
checkpointConfig.setMaxConcurrentCheckpoints(1);
// 设置最小等待时间, 即两次CheckPoint最小的间隔时间(注意这个值只要大于0, 并发就会强制被置为1
checkpointConfig.setMinPauseBetweenCheckpoints(1000);
// 取消作业时, CheckPoint的数据保是否留在外部系统
checkpointConfig.setExternalizedCheckpointCleanup(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);
// 设置容忍CheckPoint失败的次数; 置为0表示不允许检查点失败, 检查点失败则报告作业失败
checkpointConfig.setTolerableCheckpointFailureNumber(0);
// 开启非对齐检查点(barrier非对齐算法)
// NOTICE: 开启之后会自动设置: 精确一次, CheckPoint并发为1
checkpointConfig.enableUnalignedCheckpoints();
// 若检查点超时则将CheckPoint置为非对齐状态 (否则会根据TolerableCheckpointFailureNumber而退出作业)
checkpointConfig.setAlignedCheckpointTimeout(Duration.ofSeconds(1));
env.socketTextStream("server.passnight.local", 30000)
.flatMap((String line, Collector<Tuple2<String, Integer>> out) -> Arrays.stream(line.split(" "))
.map((String word) -> Tuple2.of(word, 1))
.forEach(out::collect))
.returns(Types.TUPLE(Types.STRING, Types.INT))
.keyBy((KeySelector<Tuple2<String, Integer>, String>) value -> value.f0)
.sum(1)
.print();
env.execute();
}
}
可以在WebUI中看到CheckPoint的保存情况
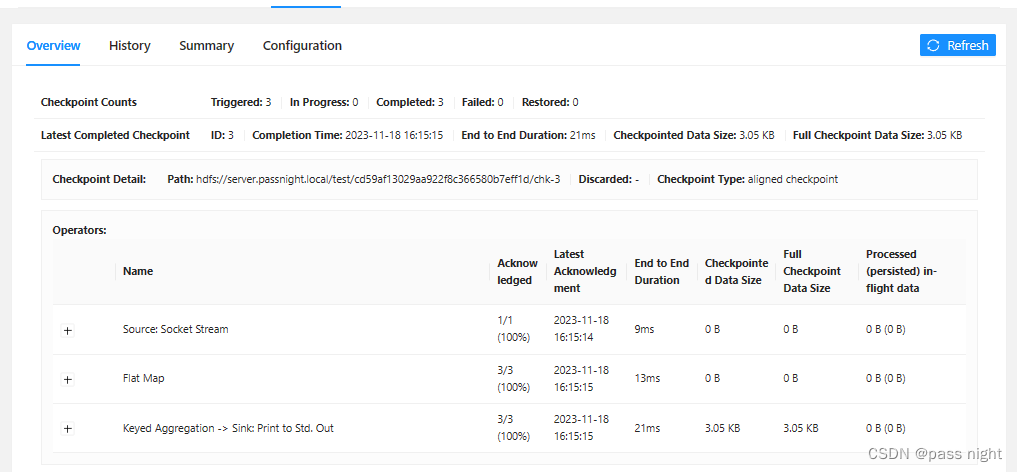
最终检查点
- 若数据是有界流, 当数据完成处理后, 算子状态会变成
finished, 这样可能会导致下游检查失败, 因此可以开启最终检查点使finished状态的任务也可以继续执行检查点 - 可以通过
configuration.set("ENABLE_CHECKPOINTS_AFTER_TASK_ENABLE", false)来关闭 默认是开启
保存点
- 除了CheckPoint以外, flink还提供了保存点用于状态恢复
- flink还提供了一个镜像保存功能-保存点, 它的原理和算法与检查点完全相同, 只是多了一些数据
- 检查点和保存点最大的区别就是: 保存点是用户手动触发的
- 其主要功能是flink的归档或是调整一些需要重启应用的配置
- 这里需要通过
uid指定id, 这样修改算子恢复的时候才能找到对应的算子 还可以通过name指定名称, 便于阅读 - 这里可以通过
flink stop -p <position>或flink cancel -s <position>在关闭任务时指定保存点 前者是优雅停止, 后者是强制关闭; 这样重启就可以通过-s position来指定从保存点恢复了 也可以指定检查点恢复, 但是检查点没有办法切换状态后端
状态一致性
一致性的概念和级别
- 概念: 一致性一般从数据丢失/数据重复来评估
- 为了保障故障恢复后还能保证数据的一致性, 需要通过检查点保存状态, 使恢复后的结果正确.
- 一般来说, 状态一致性有以下三个级别
- 最多一次
- 至少一次
- 精确一次
端到端的状态一致性
- 检查点可以实现精确一次, 这样开启了检查点就可以保障flink可以正常从故障恢复, 进而flink任务的一致性可以保障
- 但是, 在实际应用中, 数据的一致还涉及了输出/输入端的一致性; 而端到端的状态一致性指的就是这整个流程的一致性
- 一般来说, 要保障至少一次, 主要取决于数据源是否能够重放数据, 而要实现精确一次, 需要考虑流处理器内部/数据源/外部存储等部分
端到端精确一次
要实现端到端精确一次, 需要实现:
- 输入端: 数据可重放 如kafka可以重置偏移量
- flink处理端: 开启CheckPoint并开启CheckPoint精确一次模式 使用barrier对齐算法, 或非barrier对齐精确一次算法
- 输出端实现幂等或事务: 使用mysql的upsert或hbase的rowkey保证写操作幂等; 或使用kafka的两段提交/myslq的XA实现事务
- Write Ahead Log算法: 先写日志, 然后再落盘
- 先写日志, 当日志写完后再写入到持久话系统; 并将检查点信息做持久化存储
- 在成功写入后, 再一次性将数据写入外部系统,
- 在成功写入所有数据后, 在内部再次确认所有的检查点, 并将这些数据持久化保存
- Two Phase Commit算法这种事务需要外部系统的支持: 外部系统支持预提交和正式提交及事务恢复, 其中提交必须是幂等的, 否则提交过程故障也可能会导致事务失败:
- 上一次检查点完成,barrier后续的数据开始预提交 sink的多个子任务开始写数据
- 当新的检查点完成时, 各个节点进行正式提交
- flink提供了
TwoPhaseCommitSinkFunction接口
- Write Ahead Log算法: 先写日志, 然后再落盘
Kafka和flink实现精确一次
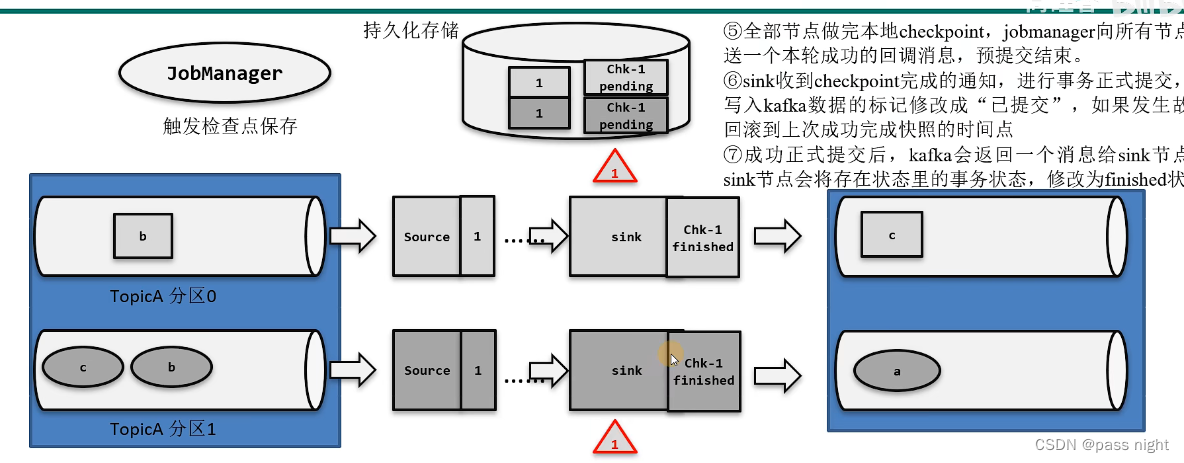
- JobManager发送指令, 触发检查点保存 注意这里要持久化偏移量
- 每个sink节点在收到第一条数据后, 开启kafka第一次事务, 预提交开始
- 到达sink的数据调用kafka producer的
send, 并调用flush刷入磁盘; 此时若任意一个节点提交失败, 则整个预提交过程都会失败 注意此时数据是预提交状态, 用虚线表示 - 当barrier到达sink节点, 会触发barrier节点的本地状态保存到检查点, 同时开启一个新事务, 用于后续数据的预提交 注意只有第一次由sink节点开启事务, 后面都由barrier开启
- sink全部节点都做完本地CheckPoint后, JobManager发送一个本轮成功的回调消息, 预提交结束
- sink收到CheckPoint完成的消息, 进行事务正式提交, 将写入kafka的数据标记为已提交; 若发生故障, 则回滚到上次完成快照的时间点
- 当成功正式提交之后, kafka会返回一个消息给sink节点, sink节点会将事务状态修改为
finished状态
代码实现
public class KafkaEndToEndExactlyOnce {
public static void main(String[] args) throws Exception {
@Cleanup
StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(new Configuration());
// 开启检查点, 设置为精确一次, 并配置检查点保存位置
env.enableCheckpointing(5000, CheckpointingMode.EXACTLY_ONCE);
CheckpointConfig checkpointConfig = env.getCheckpointConfig();
checkpointConfig.setCheckpointStorage("hdfs://server.passnight.local/test");
checkpointConfig.setExternalizedCheckpointCleanup(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);
// 读取kafka
KafkaSource<String> kafkaSource = KafkaSource.<String>builder()
.setBootstrapServers("server.passnight.local:20015") // 指定连接url
.setGroupId("testGroup") // 指定消费者组
.setTopics("wc-input") // 指定topic
.setValueOnlyDeserializer(new SimpleStringSchema()) // 指定反序列化其
.setStartingOffsets(OffsetsInitializer.latest()) // 指定消费偏移量
.build();
SingleOutputStreamOperator<String> result = env.fromSource(kafkaSource, WatermarkStrategy.noWatermarks(), "kafkaSource")
.flatMap((String line, Collector<Tuple2<String, Integer>> out) -> Arrays.stream(line.split(" "))
.map((String word) -> Tuple2.of(word, 1))
.forEach(out::collect))
.returns(Types.TUPLE(Types.STRING, Types.INT))
.keyBy((KeySelector<Tuple2<String, Integer>, String>) value -> value.f0)
.sum(1)
.map(Object::toString);
//写入到kafka
KafkaSink<String> kafkaSink = KafkaSink.<String>builder()
// 指定kafka地址
.setBootstrapServers("server.passnight.local:20015,replica.passnight.local:20015,follower.passnight.local:20015")
.setRecordSerializer(KafkaRecordSerializationSchema.<String>builder()
.setTopic("wc-output") // 设置主题
.setValueSerializationSchema(new SimpleStringSchema()) // 设置序列化其
.build())
.setDeliveryGuarantee(DeliveryGuarantee.EXACTLY_ONCE) // 配置"精确一次"
.setTransactionalIdPrefix("passnight-") // 若要配置精确一次, 必须设置事务
// 若要配置精确一次, 必须配置事务超时时间; 这个值必须小于transaction.max.timeout.ms=15min
.setProperty(ProducerConfig.TRANSACTION_TIMEOUT_CONFIG, String.valueOf(10 * 60 * 1000))
.build();
result.sinkTo(kafkaSink);
env.execute();
}
}
这里注意kafka消费者要开启read_committed模式, 否则会消费到未提交的数据

引用
Apache Flink 1.4 Documentation: Project Template for Java ↩︎




![[C++初阶] 爱上C++ : 与C++的第一次约会](https://img-blog.csdnimg.cn/direct/e6b7de6df3ca49cba01fe2d41bd77a72.png)