本文首发于公众号:机器感知
HiRoPE、MoDiTalker、RecDiffusion、DreamSalon、InterDreamer、BAMM
Lift3D: Zero-Shot Lifting of Any 2D Vision Model to 3D
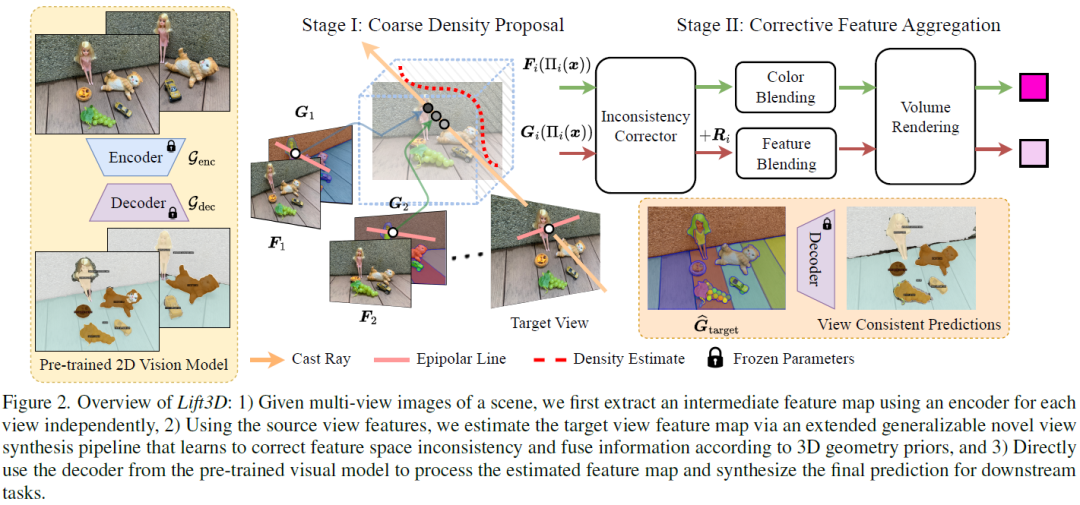
In recent years, there has been an explosion of 2D vision models for numerous tasks such as semantic segmentation, style transfer or scene editing, enabled by large-scale 2D image datasets. At the same time, there has been renewed interest in 3D scene representations such as neural radiance fields from multi-view images. However, the availability of 3D or multiview data is still substantially limited compared to 2D image datasets, making extending 2D vision models to 3D data highly desirable but also very challenging. Indeed, extending a single 2D vision operator like scene editing to 3D typically requires a highly creative method specialized to that task and often requires per-scene optimization. In this paper, we ask the question of whether any 2D vision model can be lifted to make 3D consistent predictions. We answer this question in the affirmative; our new Lift3D method trains to predict unseen views on feature spaces generated by a few visual models (i.e. DINO and CLIP)......
Low-Rank Rescaled Vision Transformer Fine-Tuning: A Residual Design Approach
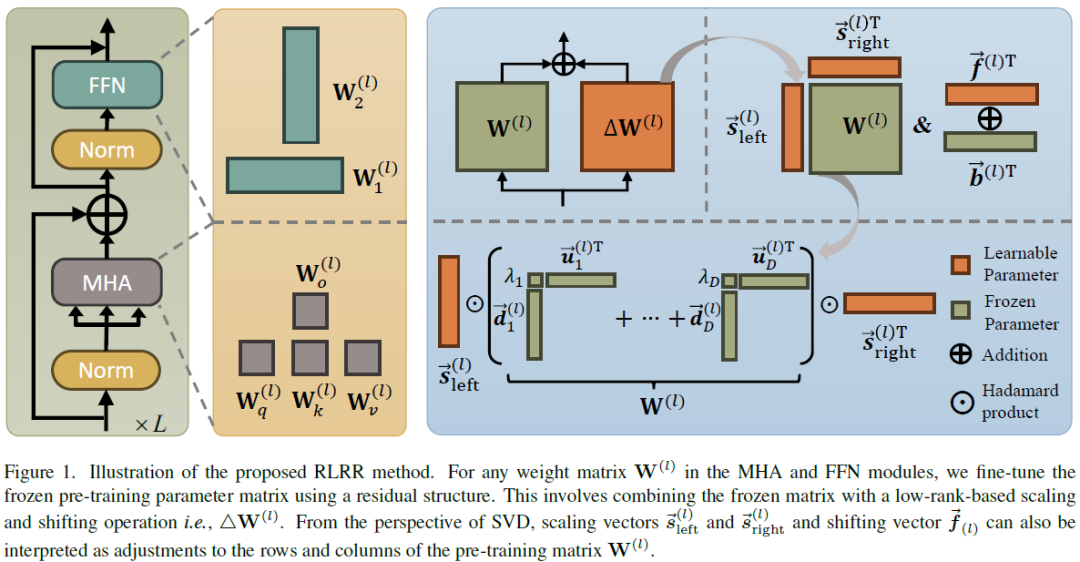
Parameter-efficient fine-tuning for pre-trained Vision Transformers aims to adeptly tailor a model to downstream tasks by learning a minimal set of new adaptation parameters while preserving the frozen majority of pre-trained parameters. Striking a balance between retaining the generalizable representation capacity of the pre-trained model and acquiring task-specific features poses a key challenge. Currently, there is a lack of focus on guiding this delicate trade-off. In this study, we approach the problem from the perspective of Singular Value Decomposition (SVD) of pre-trained parameter matrices, providing insights into the tuning dynamics of existing methods. Building upon this understanding, we propose a Residual-based Low-Rank Rescaling (RLRR) fine-tuning strategy. This strategy not only enhances flexibility in parameter tuning but also ensures that new parameters do not deviate excessively from the pre-trained model through a residual design. Extensive experiments demo......
Automated Black-box Prompt Engineering for Personalized Text-to-Image Generation

Prompt engineering is effective for controlling the output of text-to-image (T2I) generative models, but it is also laborious due to the need for manually crafted prompts. This challenge has spurred the development of algorithms for automated prompt generation. However, these methods often struggle with transferability across T2I models, require white-box access to the underlying model, and produce non-intuitive prompts. In this work, we introduce PRISM, an algorithm that automatically identifies human-interpretable and transferable prompts that can effectively generate desired concepts given only black-box access to T2I models. Inspired by large language model (LLM) jailbreaking, PRISM leverages the in-context learning ability of LLMs to iteratively refine the candidate prompts distribution for given reference images. Our experiments demonstrate the versatility and effectiveness of PRISM in generating accurate prompts for objects, styles and images across multiple T2I models......
HiRoPE: Length Extrapolation for Code Models
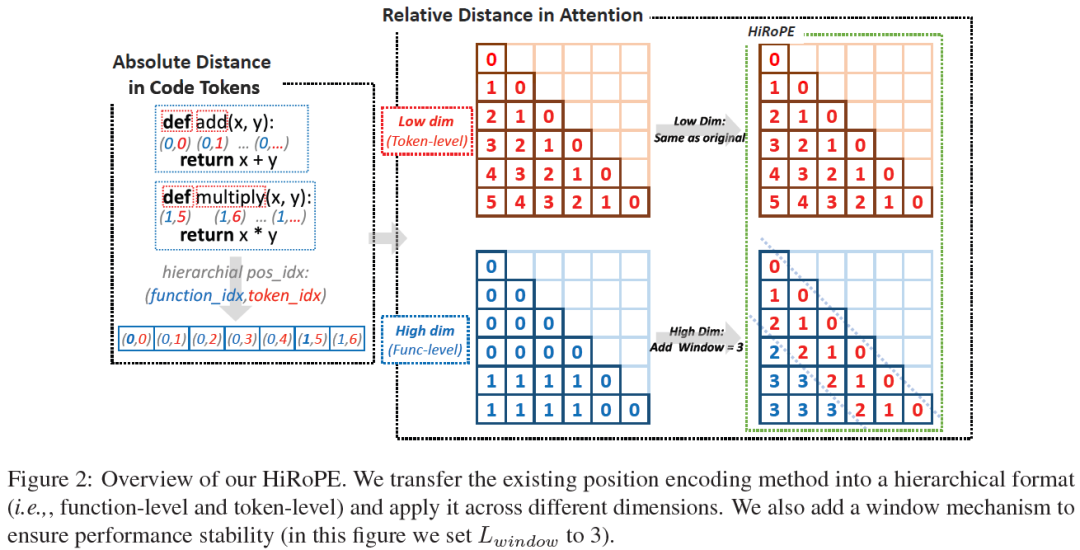
Addressing the limitation of context length in large language models for code-related tasks is the primary focus of this paper. Existing LLMs are constrained by their pre-trained context lengths, leading to performance issues in handling long complex code sequences. Inspired by how human programmers navigate code, we introduce Hierarchical Rotary Position Embedding (HiRoPE), a novel approach that enhances the traditional rotary position embedding into a hierarchical format based on the hierarchical structure of source code. HiRoPE offers easy integration into existing LLMs without extra training costs. Our method is extensively evaluated with various LLMs, demonstrating stable performance in tasks such as language modeling and long code completion. We also introduce a new long code understanding task with real-world code projects, in hopes of promoting further development in this code-related field. Theoretically and experimentally, we find that HiRoPE also addresses the out-......
MoDiTalker: Motion-Disentangled Diffusion Model for High-Fidelity Talking Head Generation
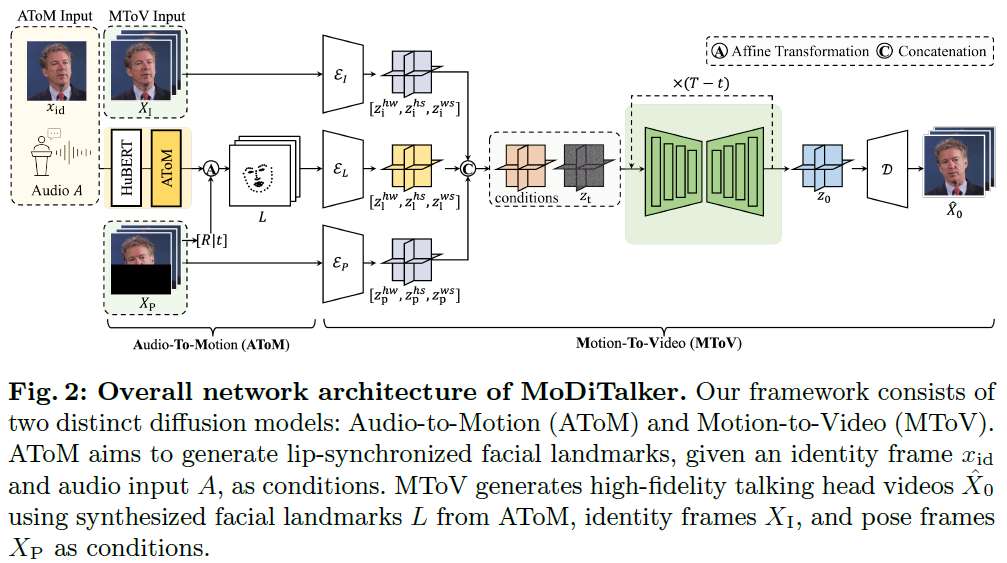
Conventional GAN-based models for talking head generation often suffer from limited quality and unstable training. Recent approaches based on diffusion models aimed to address these limitations and improve fidelity. However, they still face challenges, including extensive sampling times and difficulties in maintaining temporal consistency due to the high stochasticity of diffusion models. To overcome these challenges, we propose a novel motion-disentangled diffusion model for high-quality talking head generation, dubbed MoDiTalker. We introduce the two modules: audio-to-motion (AToM), designed to generate a synchronized lip motion from audio, and motion-to-video (MToV), designed to produce high-quality head video following the generated motion. AToM excels in capturing subtle lip movements by leveraging an audio attention mechanism. In addition, MToV enhances temporal consistency by leveraging an efficient tri-plane representation. Our experiments conducted on standard benchm......
RecDiffusion: Rectangling for Image Stitching with Diffusion Models
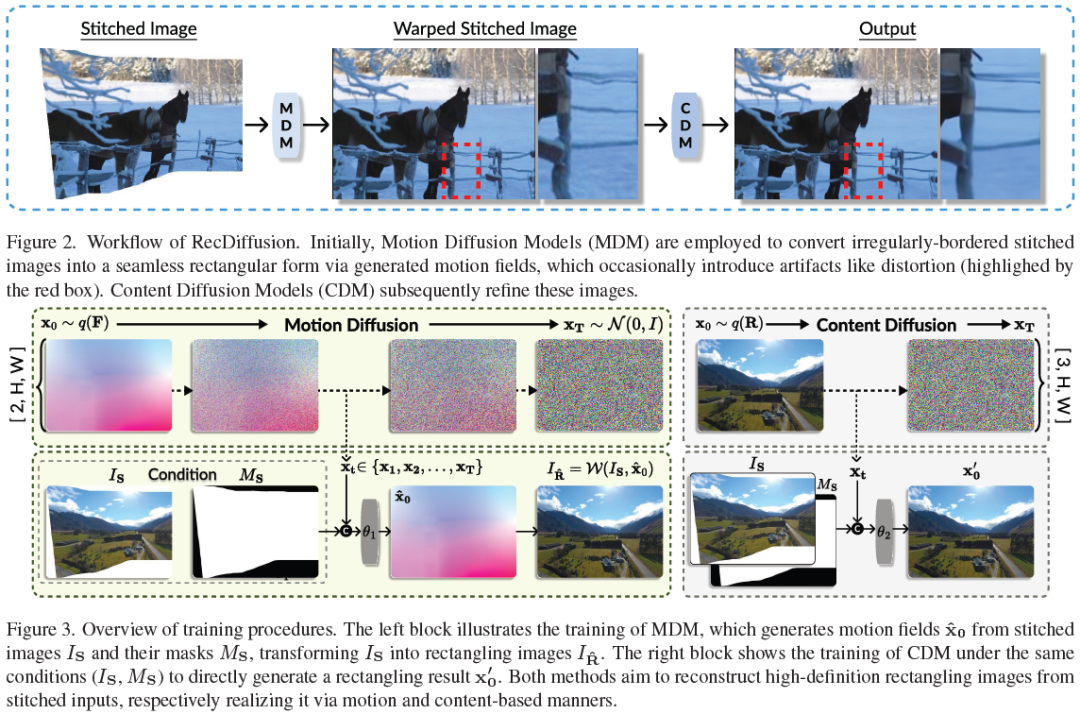
Image stitching from different captures often results in non-rectangular boundaries, which is often considered unappealing. To solve non-rectangular boundaries, current solutions involve cropping, which discards image content, inpainting, which can introduce unrelated content, or warping, which can distort non-linear features and introduce artifacts. To overcome these issues, we introduce a novel diffusion-based learning framework, \textbf{RecDiffusion}, for image stitching rectangling. This framework combines Motion Diffusion Models (MDM) to generate motion fields, effectively transitioning from the stitched image's irregular borders to a geometrically corrected intermediary. Followed by Content Diffusion Models (CDM) for image detail refinement. Notably, our sampling process utilizes a weighted map to identify regions needing correction during each iteration of CDM. Our RecDiffusion ensures geometric accuracy and overall visual appeal, surpassing all previous methods in bot......
DreamSalon: A Staged Diffusion Framework for Preserving Identity-Context in Editable Face Generation
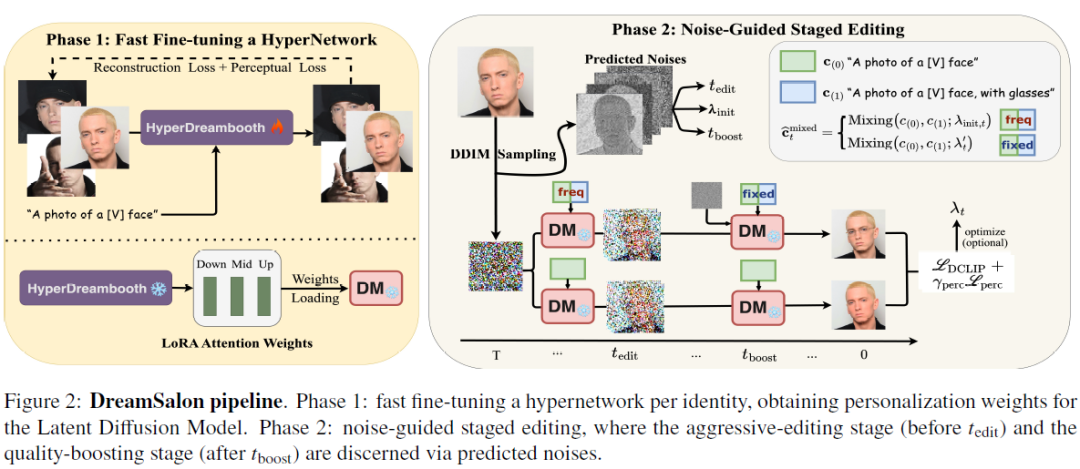
While large-scale pre-trained text-to-image models can synthesize diverse and high-quality human-centered images, novel challenges arise with a nuanced task of "identity fine editing": precisely modifying specific features of a subject while maintaining its inherent identity and context. Existing personalization methods either require time-consuming optimization or learning additional encoders, adept in "identity re-contextualization". However, they often struggle with detailed and sensitive tasks like human face editing. To address these challenges, we introduce DreamSalon, a noise-guided, staged-editing framework, uniquely focusing on detailed image manipulations and identity-context preservation. By discerning editing and boosting stages via the frequency and gradient of predicted noises, DreamSalon first performs detailed manipulations on specific features in the editing stage, guided by high-frequency information, and then employs stochastic denoising in the boosting sta......
Burst Super-Resolution with Diffusion Models for Improving Perceptual Quality
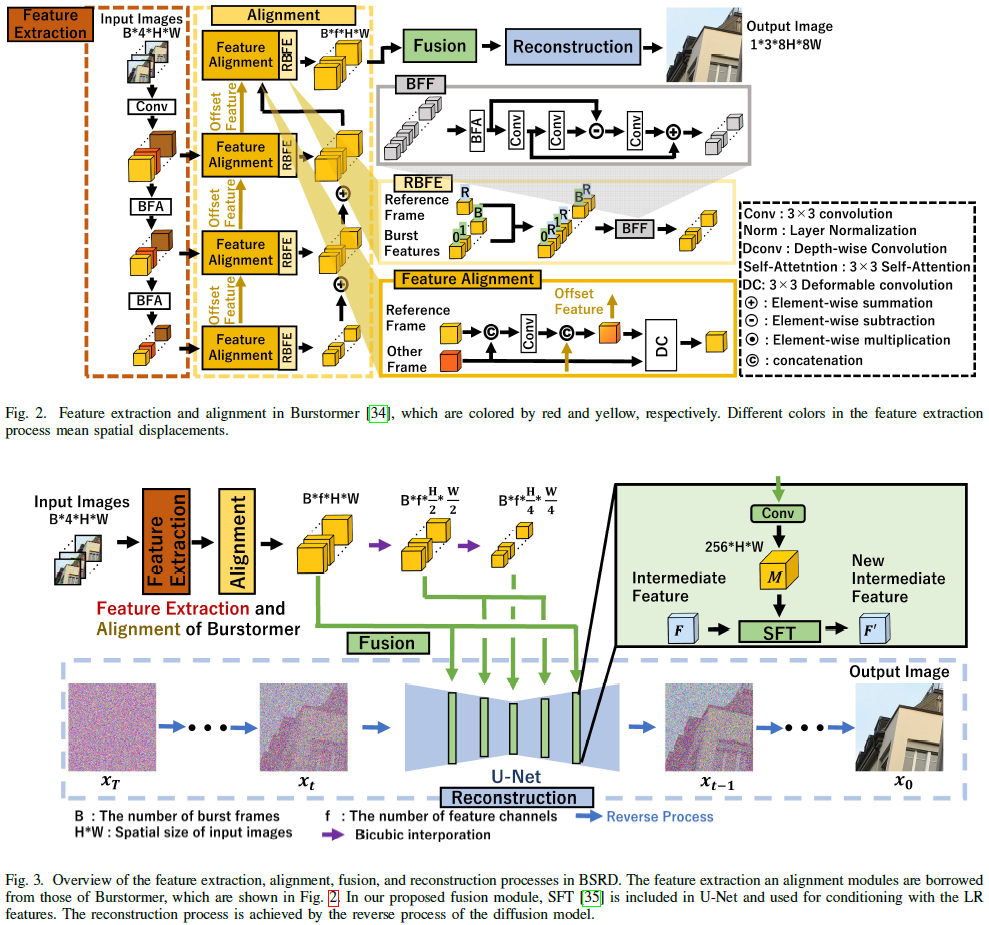
While burst LR images are useful for improving the SR image quality compared with a single LR image, prior SR networks accepting the burst LR images are trained in a deterministic manner, which is known to produce a blurry SR image. In addition, it is difficult to perfectly align the burst LR images, making the SR image more blurry. Since such blurry images are perceptually degraded, we aim to reconstruct the sharp high-fidelity boundaries. Such high-fidelity images can be reconstructed by diffusion models. However, prior SR methods using the diffusion model are not properly optimized for the burst SR task. Specifically, the reverse process starting from a random sample is not optimized for image enhancement and restoration methods, including burst SR. In our proposed method, on the other hand, burst LR features are used to reconstruct the initial burst SR image that is fed into an intermediate step in the diffusion model. This reverse process from the intermediate step 1) sk......
BAMM: Bidirectional Autoregressive Motion Model
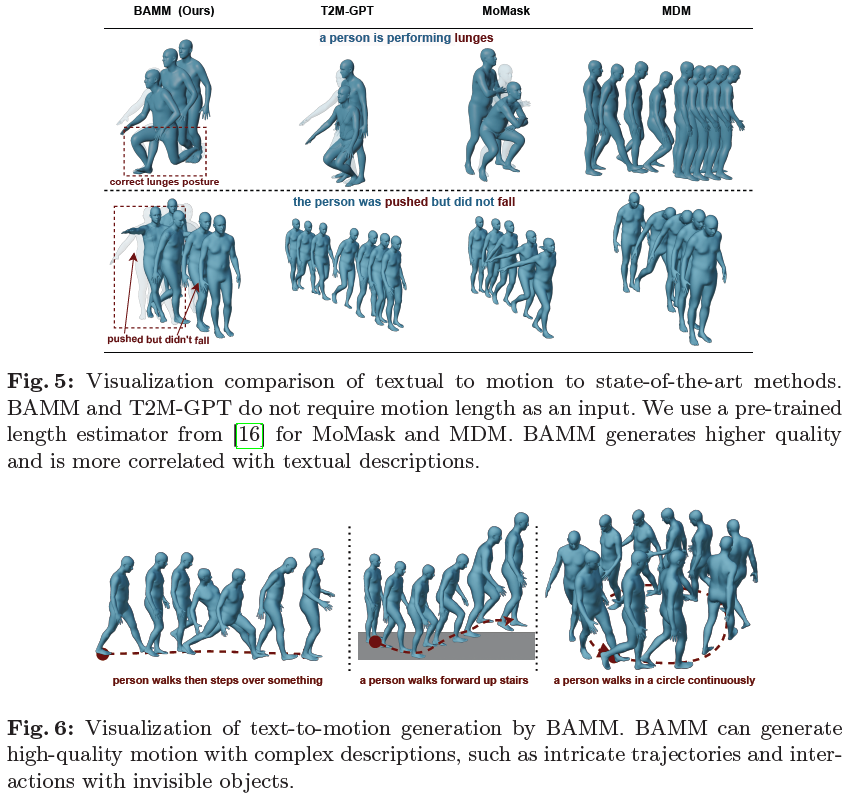
Generating human motion from text has been dominated by denoising motion models either through diffusion or generative masking process. However, these models face great limitations in usability by requiring prior knowledge of the motion length. Conversely, autoregressive motion models address this limitation by adaptively predicting motion endpoints, at the cost of degraded generation quality and editing capabilities. To address these challenges, we propose Bidirectional Autoregressive Motion Model (BAMM), a novel text-to-motion generation framework. BAMM consists of two key components: (1) a motion tokenizer that transforms 3D human motion into discrete tokens in latent space, and (2) a masked self-attention transformer that autoregressively predicts randomly masked tokens via a hybrid attention masking strategy. By unifying generative masked modeling and autoregressive modeling, BAMM captures rich and bidirectional dependencies among motion tokens, while learning the probab......
Break-for-Make: Modular Low-Rank Adaptations for Composable Content-Style Customization

Personalized generation paradigms empower designers to customize visual intellectual properties with the help of textual descriptions by tuning or adapting pre-trained text-to-image models on a few images. Recent works explore approaches for concurrently customizing both content and detailed visual style appearance. However, these existing approaches often generate images where the content and style are entangled. In this study, we reconsider the customization of content and style concepts from the perspective of parameter space construction. Unlike existing methods that utilize a shared parameter space for content and style, we propose a learning framework that separates the parameter space to facilitate individual learning of content and style, thereby enabling disentangled content and style. To achieve this goal, we introduce "partly learnable projection" (PLP) matrices to separate the original adapters into divided sub-parameter spaces. We propose "break-for-make" customi......
Beyond Talking -- Generating Holistic 3D Human Dyadic Motion for Communication
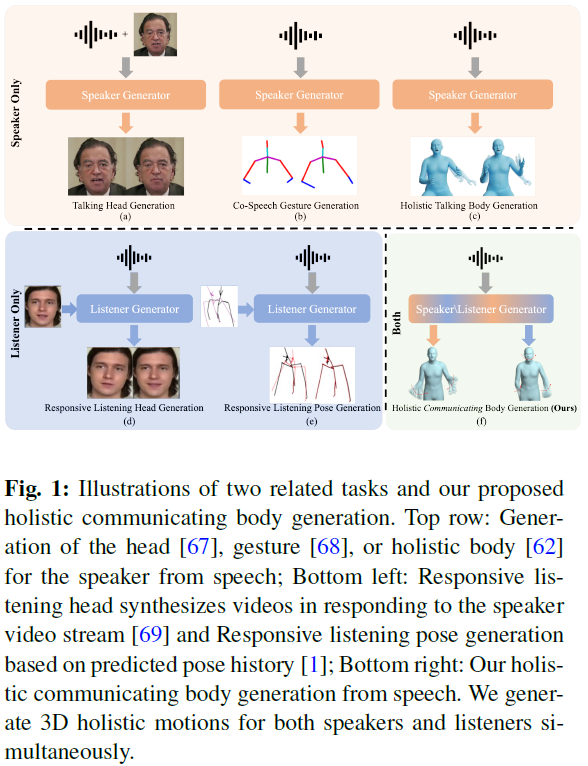
In this paper, we introduce an innovative task focused on human communication, aiming to generate 3D holistic human motions for both speakers and listeners. Central to our approach is the incorporation of factorization to decouple audio features and the combination of textual semantic information, thereby facilitating the creation of more realistic and coordinated movements. We separately train VQ-VAEs with respect to the holistic motions of both speaker and listener. We consider the real-time mutual influence between the speaker and the listener and propose a novel chain-like transformer-based auto-regressive model specifically designed to characterize real-world communication scenarios effectively which can generate the motions of both the speaker and the listener simultaneously. These designs ensure that the results we generate are both coordinated and diverse. Our approach demonstrates state-of-the-art performance on two benchmark datasets. Furthermore, we introduce the H......
GANTASTIC: GAN-based Transfer of Interpretable Directions for Disentangled Image Editing in Text-to-Image Diffusion Models

The rapid advancement in image generation models has predominantly been driven by diffusion models, which have demonstrated unparalleled success in generating high-fidelity, diverse images from textual prompts. Despite their success, diffusion models encounter substantial challenges in the domain of image editing, particularly in executing disentangled edits-changes that target specific attributes of an image while leaving irrelevant parts untouched. In contrast, Generative Adversarial Networks (GANs) have been recognized for their success in disentangled edits through their interpretable latent spaces. We introduce GANTASTIC, a novel framework that takes existing directions from pre-trained GAN models-representative of specific, controllable attributes-and transfers these directions into diffusion-based models. This novel approach not only maintains the generative quality and diversity that diffusion models are known for but also significantly enhances their capability to pe......
InterDreamer: Zero-Shot Text to 3D Dynamic Human-Object Interaction
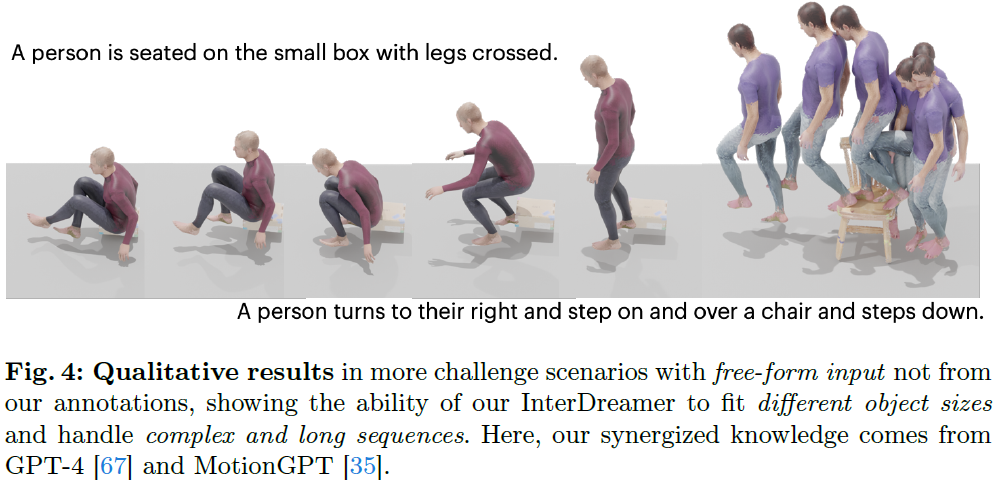
Text-conditioned human motion generation has experienced significant advancements with diffusion models trained on extensive motion capture data and corresponding textual annotations. However, extending such success to 3D dynamic human-object interaction (HOI) generation faces notable challenges, primarily due to the lack of large-scale interaction data and comprehensive descriptions that align with these interactions. This paper takes the initiative and showcases the potential of generating human-object interactions without direct training on text-interaction pair data. Our key insight in achieving this is that interaction semantics and dynamics can be decoupled. Being unable to learn interaction semantics through supervised training, we instead leverage pre-trained large models, synergizing knowledge from a large language model and a text-to-motion model. While such knowledge offers high-level control over interaction semantics, it cannot grasp the intricacies of low-level ......