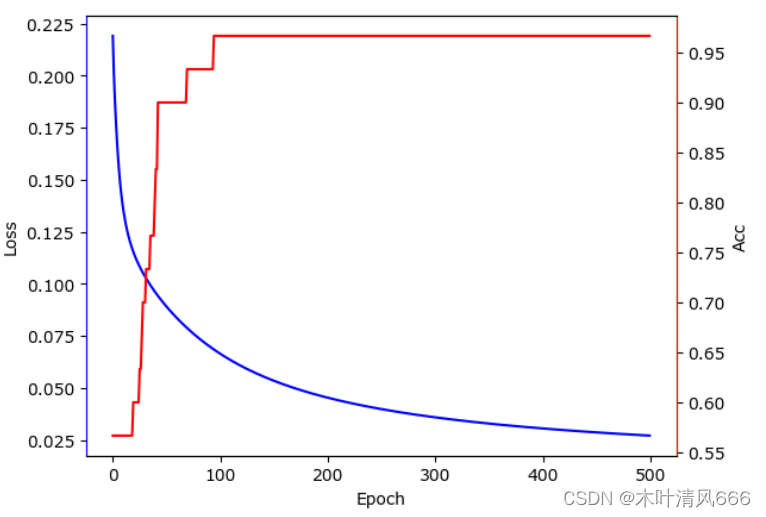
本节将介绍一种
2.1 准备
2.1.1 数据集
(1)MNIST
只要学习过深度学习相关理论的人,都一定听说过名字叫做LeNet-5模型,它是深度学习三巨头只有Yann Lecun在1998年提出的一个CNN模型(很多人认为这是第一个具有实际应用价值的CNN模型)。在当年使用该模型可以很好地完成手写体数字的识别,而该模型所处理的手写体数字数据库称为MNIST。
MNIST全称是:Mixed National Institute of Standards and Technology databas,它包含70000张手写数字的灰度图片,每一张图片包含 28 X 28 个像素点。数据集被分为两部分,其中训练(mnist.train)集包括60000样本,测试集(mnist.test)包含10000样本。训练集又进一步封你为 55000 个样本用于训练,5000样本用于验证。下图是MNIST样本实例图。

MNIST数据集虽然经典,但也有问题。最主要的问题是,它太简单了!相对于现在动辄上百万个参数的“大”模型,MNIST数据集要小很多,且只是简单的十类问题,因此导致现有的模型在MNIST上的分类精度都超过了95%。为了更直观地观察不同算法间的性能差异,需要用一个更复杂一点的数据集,这时Fashion-MNIST出现了。
(2)Fashion-MNIST
FashionMNIST是一个替代MNIST的图像数据集。 它是由一家德国科技公司(Zalando)整理提供。FashionMNIST 的大小、格式和训练集/测试集划分与原始的 MNIST 完全一致。60000/10000 的训练测试数据划分,28x28 的灰度图片。因此,能跑MNIST数据集的代码,只需稍加改动,就可以跑新的数据集。两个数据集的不同之处主要有两点,一是虽然两者都是以灰度图像呈现的,但MNIST呈现的是数字,背景设为0,前景设为1,FashionMNIST则是真正意义的灰度数据集。二是两者内容不同,前者被分类的是手写体数字,后者则是十类衣物服饰(分别是:T恤、裤子、套头衫、连衣裙、大衣、凉鞋、衬衫、运动鞋、包、短靴),其内容的复杂程度远高于手写体数字。下图是FashionMNIST的一个图示。
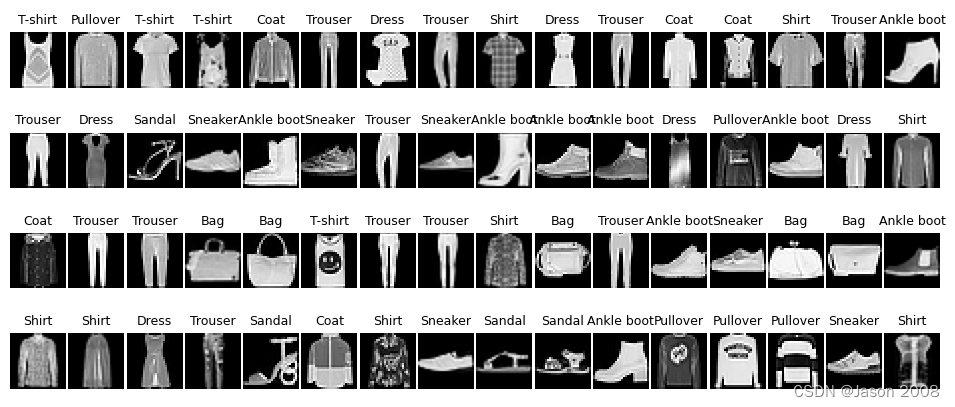
网上有很多基于FashionMNIST数据集的实例,在此就不再重复介绍。
本节实例选用的是中国版的MNIST,由英国纽卡斯尔大学整理并提供,我们不妨将其称为CHN-MNIST数据集。
(3)CHN-MNIST
该数据集共由100人书写,每人重复书写10遍,因此数据集样本数为1000组,每组包括15个汉字的数字,即“零、一、二、三、四、五、六、七、八、九、十、百、千、万、亿”,总样本数为15000。图像的分辨率为300*300。

2.1.2 模型
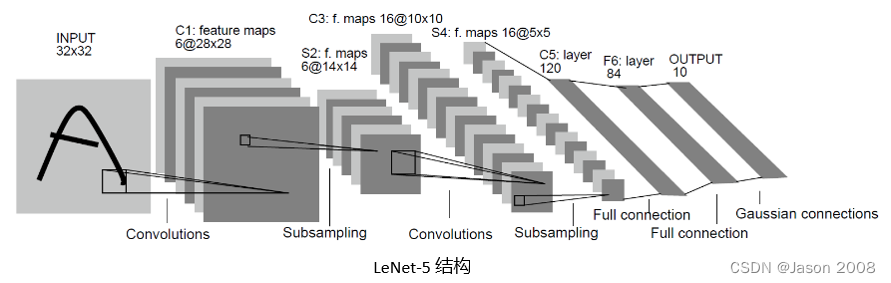
对于这样一个简单的分类任务,不需要使用太复杂的网络,前面提到的LeNet-5足能胜任。
对于LeNet-5网络模型的介绍,网上一搜一大把,在此不再赘述,只贴出该模型的示意图,供大家参考。
2.2 代码解析
下面将结合代码,一部分一部分的介绍具体的过程。
(1)载入必要的扩展库
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import torch
import torch.nn as nn
from PIL import Image
from torch.utils.data import Dataset, DataLoader
from tqdm import tqdm由于是第一个例程,我们对所使用的扩展库详细加以介绍:
- matplotlib库:用于绘图
- numpy库:用于数值计算
- pandas库:用于数据分析
- torch库:提供Pytorch支持
- PIL库:用于图像绘制
- tqdm库:Python提供的进度条空间库
(2)设置参数
这一部分完成的是设置一些与模型训练有关的超参数。如下面代码所示:
batch_size = 32 # 批次大小
lr = 0.003 # 学习率
epochs = 10 # 迭代轮数
save_path = './best_model.pkl' # 模型保存路径
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu') # 设备各个参数的功能见注释,至于各个参数数值大小对最终结果的影响,将放在后续的章节介绍。其中最后一行是自动检测是否安装了cuda,如果是,则启动gpu加速。
(3)加载数据集
这一部分完成的是设置一些与模型训练有关的超参数。如下面代码所示:
class CustomDataset(Dataset):
def __init__(self, k, l, csv_file='./chinese_mnist.csv'):
self.df = pd.read_csv(csv_file)
self.k = {'九': int(9), '十': int(10), '百': int(11), '千': int(12), '万': int(13), '亿': int(14), '零': int(0),
'一': int(1), '二': int(2), '三': int(3), '四': int(4), '五': int(5), '六': int(6), '七': int(7),
'八': int(8)}
self.target = 'character'
self.features = ['suite_id', 'sample_id', 'code', ]
self.labels = np.asarray(self.df.iloc[:, 4])
self.y = df[self.target]
self.X = df.drop(self.target, axis=1)
def __getitem__(self, idx):
single_image_label = self.labels[idx]
class_id = self.k[single_image_label]
img = Image.open(f"./data/data/input_{self.X.iloc[idx, 0]}_{self.X.iloc[idx, 1]}_{self.X.iloc[idx, 2]}.jpg")
img = np.array(img)
return img, class_id
def __len__(self):
return len(self.X)还需要对数据集进行一下预处理,便于后面的训练过程g
# 1.构建索引到汉字的映射字典
num2char = {int(9): '九', int(10): '十', int(11): '百',
int(12): '千', int(13): '万', int(14): '亿',
int(0): '零', int(1): '一', int(2): '二',
int(3): '三', int(4): '四', int(5): '五',
int(6): '六', int(7): '七', int(8): '八'}
# 2.读取csv处理文件
df = pd.read_csv('./chinese_mnist.csv', sep=',')
# 3.处理数据
train_df = df.groupby('value').apply(lambda x: x.sample(700, random_state=42)).reset_index(drop=True)
x_train, y_train = train_df.iloc[:, :-2], train_df.iloc[:, -2]
test_df = df.groupby('value').apply(lambda x: x.sample(300, random_state=42)).reset_index(drop=True)
x_test, y_test = test_df.iloc[:, :-2], test_df.iloc[:, -2](未完,待续)

![[Java基础揉碎]抽象类](https://img-blog.csdnimg.cn/direct/1a994685cd48474aaf28ee5f11aa82a0.png)