NVIDIA H200 Tensor Core GPU 和 NVIDIA TensorRT-LLM 创下 MLPerf LLM 最新推理记录

生成式人工智能正在解锁新的计算应用程序,通过持续的模型创新来极大地增强人类的能力。 生成式 AI 模型(包括大型语言模型 (LLM))用于制作营销文案、编写计算机代码、渲染详细图像、创作音乐、生成视频等。 最新模型所需的计算量是巨大的,并且随着新模型的发明而不断增长。
生成式人工智能推理的计算强度要求芯片、系统和软件都具有卓越的性能。 MLPerf Inference 是一个基准套件,可衡量多个流行深度学习用例的推理性能。 基准套件的最新版本——MLPerf Inference v4.0——添加了两个新的工作负载,代表流行的现代生成人工智能用例。 第一个是基于 Meta Llama 2 系列大型语言模型 (LLM) 中最大的 Llama 2 70B 的 LLM 基准。 第二个是基于 Stable Diffusion XL 的文本到图像测试。
NVIDIA 加速计算平台在使用 NVIDIA H200 Tensor Core GPU 的两个新工作负载上均创下了性能记录。 而且,使用 NVIDIA TensorRT-LLM 软件,NVIDIA H100 Tensor Core GPU 在 GPT-J LLM 测试中的性能几乎提高了两倍。 NVIDIA Hopper 架构 GPU 继续为数据中心类别中的所有 MLPerf 推理工作负载提供每个加速器的最高性能。 此外,NVIDIA还在MLPerf Inference开放部门提交了多份参赛作品,展示了其模型和算法创新。
在这篇文章中,我们将介绍这些创纪录的生成式人工智能推理性能成就背后的一些全栈技术。
TensorRT-LLM 使 LLM 推理性能提高了近三倍
基于 LLM 的服务(例如聊天机器人)必须能够快速响应用户查询并且具有成本效益,这需要高推理吞吐量。 生产推理解决方案必须能够同时以低延迟和高吞吐量为尖端的LLM提供服务。
TensorRT-LLM 是一个高性能开源软件库,在 NVIDIA GPU 上运行最新的 LLM 时可提供最先进的性能。
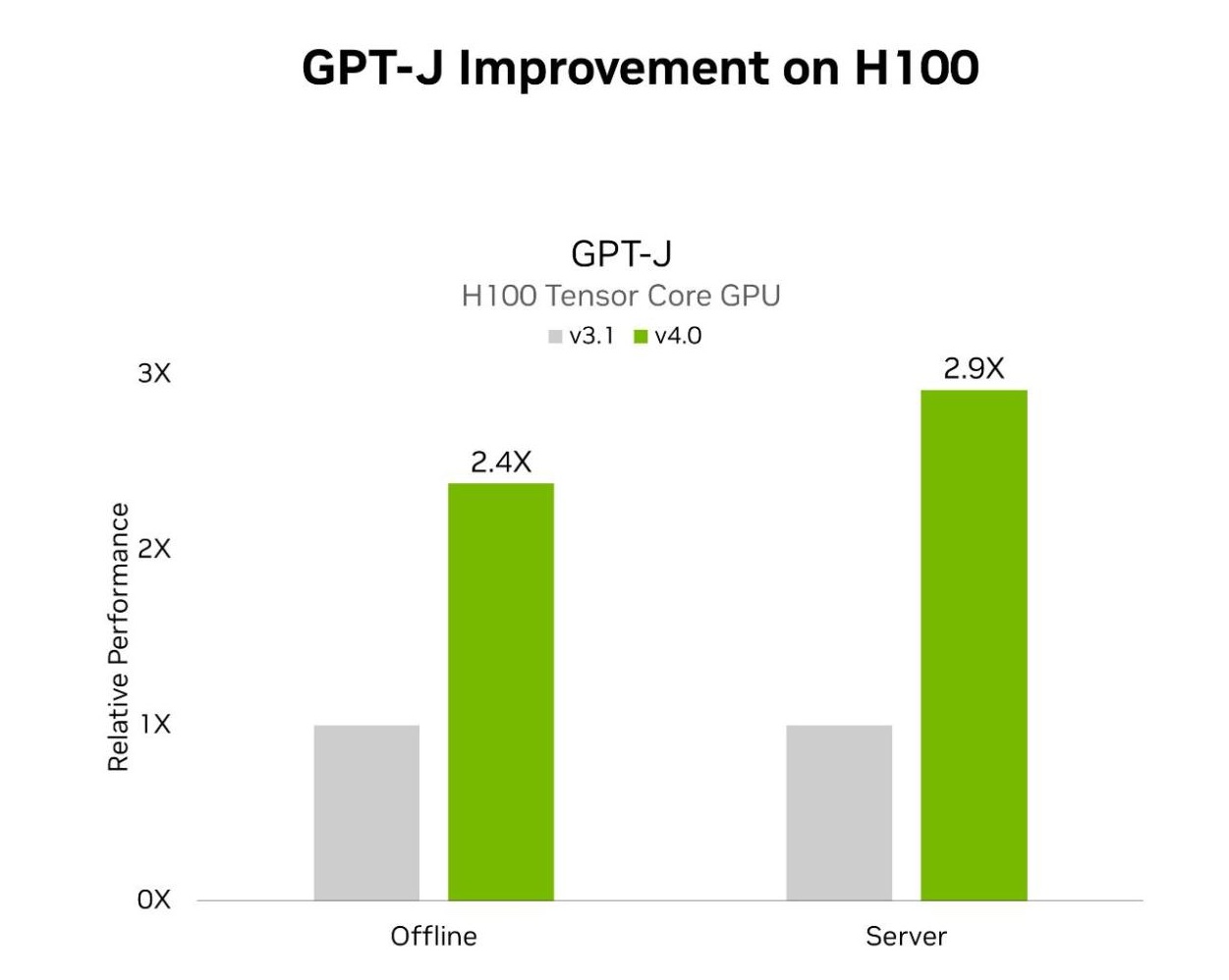
MLPerf Inference v4.0 包括两项 LLM 测试。 第一个是上一轮 MLPerf 中引入的 GPT-J,第二个是新添加的 Llama 2 70B 基准测试。 使用 TensorRT-LLM 的 H100 Tensor Core GPU 在离线和服务器场景中分别在 GPT-J 上实现了 2.4 倍和 2.9 倍的加速。 与上一轮提交的作品相比。 TensorRT-LLM 也是 NVIDIA 平台在 Llama 2 70B 测试中表现出色的核心。
以下是 TensorRT-LLM 实现这些出色性能结果的一些关键功能:
- Inflight sequence batching通过更好地交错推理请求并在完成处理后立即逐出批处理中的请求并在其位置插入新请求,增加了 LLM 推理期间的 GPU 使用率。
- Paged KV cache 通过将 KV 缓存分区和存储到不连续的内存块、按需分配和逐出块以及在注意力计算期间动态访问块来改善内存消耗和使用。
- 张量并行性支持使用 NCCL 进行通信,在 GPU 和节点之间分配权重,从而实现大规模高效推理。
- 量化支持 FP8 量化,该量化使用 NVIDIA Hopper 架构中的第四代 Tensor Core 来减小模型大小并提高性能。
- XQA 内核高性能注意力实现,支持 MHA、MQA 和 GQA,以及波束搜索,在给定的延迟预算内显着提高吞吐量。
有关 TensorRT-LLM 功能的更多详细信息,请参阅这篇文章,深入探讨 TensorRT-LLM 如何增强 LLM 推理。
H200 Tensor Core GPU 增强了 LLM 推理能力
H200基于Hopper架构,是全球首款使用业界最先进HBM3e显存的GPU。 H200 采用 141 GB HBM3e 和 4.8 TB/s 内存带宽,与 H100 相比,GPU 内存增加近 1.8 倍,GPU 内存带宽增加近 1.4 倍。
与本轮提交的 H100 相比,更大、更快的内存和新的定制散热解决方案的结合使 H200 GPU 在 Llama 2 70B 基准测试中展示了巨大的性能改进。
HBM3e 实现更高性能
与 H100 相比,H200 升级的 GPU 内存有助于在 Llama 2 70B 工作负载上通过两个重要方式释放更多性能。
它无需张量并行或管道并行执行,即可在 MLPerf Llama 2 70B 基准测试中获得最佳性能。 这减少了通信开销并提高了推理吞吐量。
其次,与 H100 相比,H200 GPU 具有更大的内存带宽,缓解了工作负载中受内存带宽限制的部分的瓶颈,并提高了 Tensor Core 的使用率。 这产生了更大的推理吞吐量。
定制冷却设计进一步提高性能
TensorRT-LLM 的广泛优化加上 H200 的升级内存,意味着 H200 上的 Llama 2 70B 执行受计算性能限制,而不是受内存带宽或通信瓶颈的限制。
由于 NVDIAIA HGX H200 与 NVIDIA HGX H100 直接兼容,因此系统制造商能够对系统进行资格认证,从而加快上市速度。 而且,正如本轮 NVIDIA MLPerf 提交文件所证明的那样,H200 在与 H100 相同的 700 W 热设计功率 (TDP) 下,可将 Llama 2 70B 推理性能提高高达 28%。
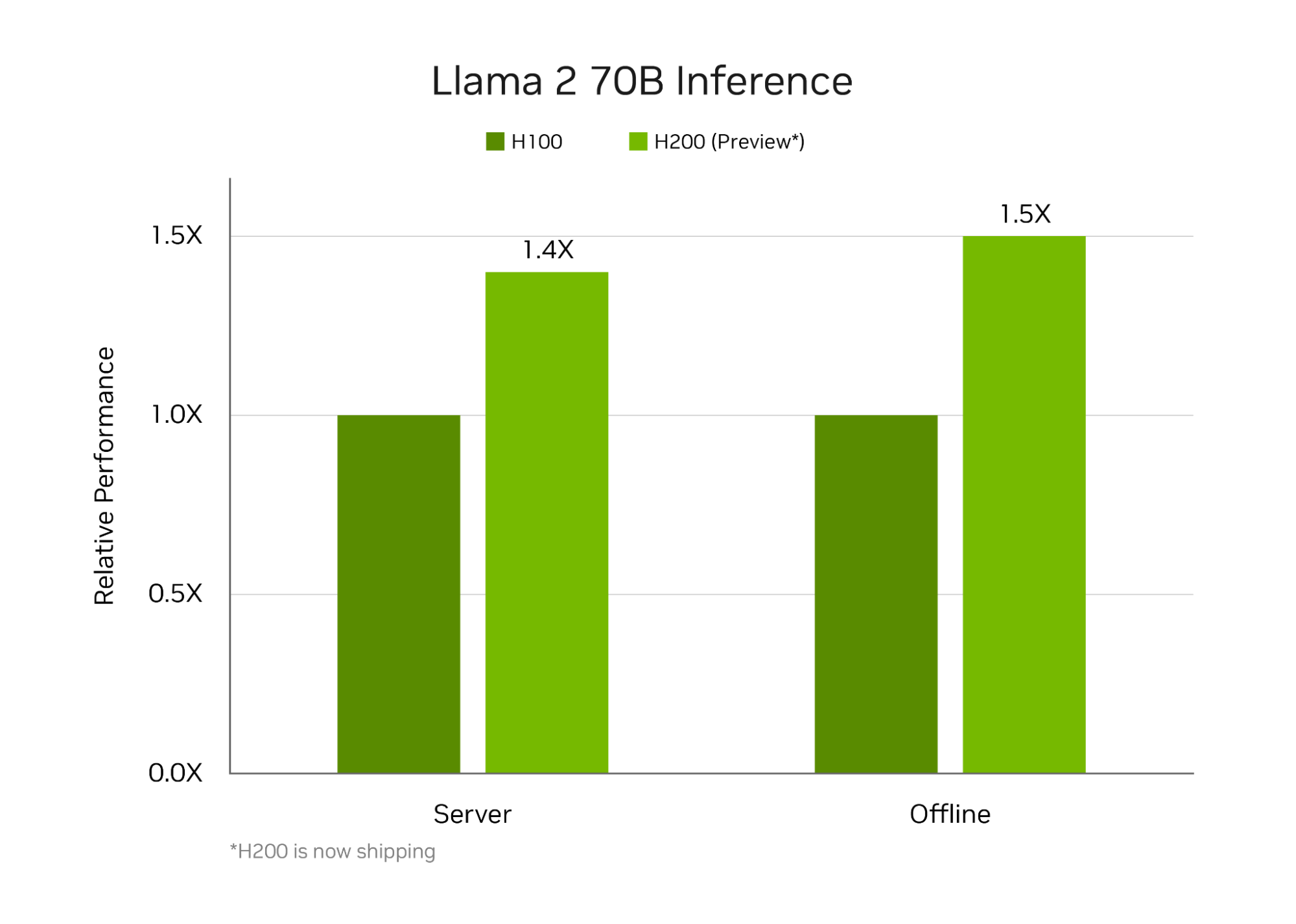
借助 NVIDIA MGX,系统构建商可以通过可实现更高 GPU 热量的定制冷却设计为客户提供更多价值。 在这一轮中,NVIDIA 还使用 H200 进行了定制散热设计,使 GPU 能够以更高的 1,000 W TDP 运行。 运行 Llama 2 70B 基准测试时,这使得服务器和离线场景的性能分别提高了 11% 和 14%,与 H100 相比,总速度分别提高了 43% 和 45%。
设定 Stable Diffusion XL 性能的标准
Stable Diffusion XL 是一种文本到图像生成 AI 模型,由以下部分组成:
- 用于将提示文本转换为嵌入的两个 CLIP 模型。
- 由残差块 (ResBlocks) 和转换器组成的 UNet 模型,可迭代地对较低分辨率潜在空间中的图像进行去噪。
- 变分自动编码器 (VAE),将潜在空间图像解码为 1024×1024 分辨率的 RGB 图像输出。
在 MLPerf Inference v4.0 中,Stable Diffusion XL 用于文本到图像测试,根据提供的文本提示生成图像。
配备 TensorRT 软件的 NVIDIA GPU 在 MLPerf Inference v4.0 文本到图像测试中提供了最高性能。 GPU 配置为 700W TDP 的 8-GPU NVIDIA HGX H200 系统在服务器和离线场景中分别实现了 13.8 个查询/秒和 13.7 个样本/秒的性能。
L40S 是性能最高的通用 NVIDIA GPU,专为在 AI 计算、图形和媒体加速方面实现突破性的多工作负载性能而设计。 使用配备 8 个 L40S GPU 的系统提交的 Stable Diffusion XL 在服务器和离线场景中也分别展示了 4.9 个查询/秒和 5 个样本/秒的性能。

NVIDIA 提交的核心内容是一个创新方案,该方案将 UNet 中的 ResBlock 和转换器部分量化为 INT8 精度。 在 ResBlocks 中,卷积层被量化为 INT8,而在 Transformer 中,查询键值块和前馈网络线性层被量化为 INT8。 INT8 绝对最大值仅从前 8 个去噪步骤(总共 20 个)中收集。 SmoothQuant 应用于量化线性层的激活,克服了将激活量化为 INT8 的挑战,同时保持了原始精度。
与 FP16 基准(不属于 NVIDIA MLPerf 提交的一部分)相比,这项工作在 H100 GPU 上将性能提高了 20%。
此外,TensorRT 中对扩散模型的 FP8 量化的支持即将推出,这将提高性能和图像质量。
开放式创新
除了在 MLPerf Inference 封闭组中提交世界一流的性能外,NVIDIA还在开放组中提交了多项成绩。 MLCommons 表示,开放式“旨在促进创新,并允许使用不同的模型或进行再培训。”
在这一轮中,NVIDIA提交了利用TensorRT中的各种模型优化功能(例如稀疏化、剪枝和缓存)的开放划分结果。 这些用于 Llama 2 70B、GPT-J 和 Stable Diffusion XL 工作负载,在保持高精度的同时展示了出色的性能。 以下小节概述了支持这些提交的创新。
具有结构化稀疏性的 Llama 2 70B
NVIDIA 开放部门提交的 H100 GPU 展示了使用 Hopper Tensor Core 的结构化稀疏功能对稀疏 Llama 2 70B 模型进行的推理。 对模型的所有注意力和 MLP 块进行结构化稀疏,并且该过程是在训练后完成的,不需要对模型进行任何微调。
这种稀疏模型有两个主要好处。 首先,模型本身缩小了 37%。 尺寸的减小使得模型和 KVCache 能够完全适应 H100 的 GPU 内存,从而无需张量并行性。
接下来,使用 2:4 稀疏 GEMM 内核提高了计算吞吐量并更有效地利用了内存带宽。 与 NVIDIA 闭分区提交相比,在同一 H100 系统上,离线场景下的总体吞吐量高出 33%。 通过这些加速,稀疏模型仍然满足 MLPerf 封闭部门设定的严格的 99.9% 准确度目标。 稀疏模型为每个样本生成的标记比封闭划分中使用的模型更少,从而导致对查询的响应更短。
带修剪和蒸馏的 GPT-J
在开放分区 GPT-J 提交中,使用了修剪后的 GPT-J 模型。 该技术大大减少了模型中的头数和层数,与在 H100 GPU 上运行模型时的封闭除法提交相比,推理吞吐量提高了近 40%。 自从 NVIDIA 在本轮 MLPerf 中提交结果以来,性能进一步提高。
然后使用知识蒸馏对修剪后的模型进行微调,实现了 98.5% 的出色准确率。
具有 DeepCache 的Stable Diffusion XL
Stable Diffusion XL 工作负载的大约 90% 的端到端处理都花在使用 UNet 运行迭代去噪步骤上。 它具有 U 形层拓扑,其中潜伏值首先被下转换,然后上转换回原始分辨率。
DeepCache 是本文描述的一种技术,建议使用两种不同的 UNet 结构。 第一个是原始的 UNet——在我们的提交实现中称为 Deep UNet。 第二个是单层 UNet,称为 Shallow UNet 或 Shallow UNet,它重用(或绕过)最新 Deep UNet 中的中间张量,从而显着减少计算量。
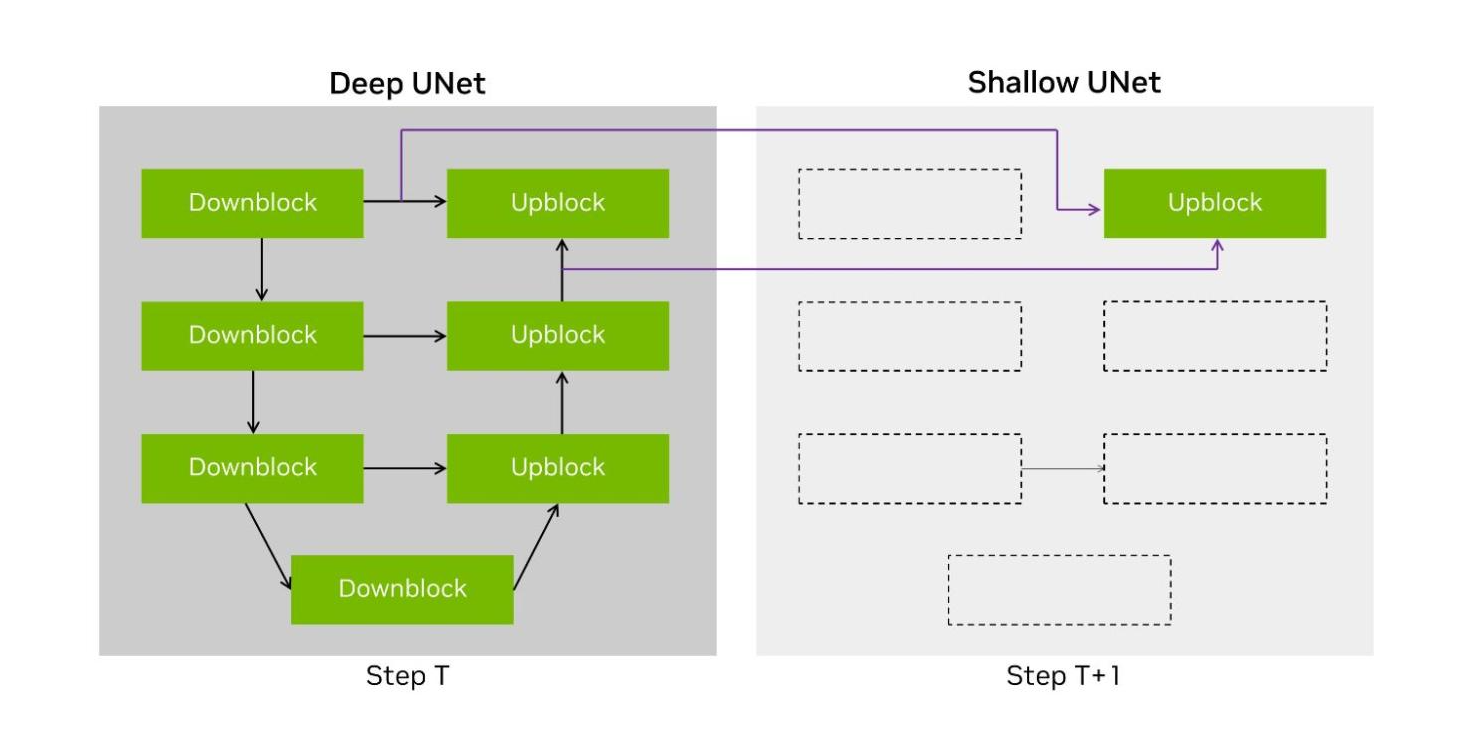
NVIDIA 开放分区提交实现了 DeepCache 的变体,其中我们将两个输入缓存到最后一个上转换层,并在去噪步骤中在 Deep UNet 和 Shallow UNet 之间交替。 这使得运行模型的 UNet 部分所需的计算量减少了一半,在 H100 上将端到端性能提高了 74%。
无与伦比的推理性能
NVIDIA 平台在整个 MLPerf Inference v4.0 基准测试中展示了卓越的推理性能,Hopper 架构可在每个工作负载上实现每个 GPU 的最高性能。
使用 TensorRT-LLM 软件使 H100 在 GPT-J 工作负载上实现了显着的性能提升,在短短 6 个月内性能几乎提高了两倍。 H200 是全球首款 HBM3e GPU,配备 TensorRT-LLM 软件,在离线和服务器场景下的 Llama 2 70B 工作负载上提供了创纪录的推理性能。 而且,在首次针对文本到图像生成 AI 的 Stable Diffusion XL 测试中,NVIDIA 平台提供了最高的性能。
要重现 NVIDIA MLPerf Inference v4.0 提交中展示的令人难以置信的性能,请参阅 MLPerf 存储库。