Multilingual Knowledge Graph Embeddings for Cross-lingual Knowledge Alignment
用于交叉知识对齐的多语言知识图谱嵌入(MTransE)
Abstract
最近的许多工作已经证明了知识图谱嵌入在完成单语知识图谱方面的好处。由于相关的知识库是用几种不同的语言构建的,因此实现跨语言知识对齐将有助于人们构建连贯的知识库,并帮助机器处理不同人类语言之间实体关系的不同表达。不幸的是,通过人工实现这种高度期望的跨舌对齐是非常昂贵且容易出错的。因此,我们提出了 M T r a n s E MTransE MTransE,一个基于推理的多语言知识图谱嵌入模型,以提供一个简单和自动化的解决方案。通过在单独的嵌入空间中编码每种语言的实体和关系, M T r a n s E MTransE MTransE为每个嵌入向量提供了到其他空间中的跨语言对应物的转换,同时保留了单语嵌入的功能。我们部署了三种不同的技术来表示跨语言的过渡,即轴校准,平移向量和线性变换,并得出五个变种 M T r a n s E MTransE MTransE使用不同的损失函数。我们的模型可以在部分对齐的图上进行训练,其中只有一小部分三元组与跨语言对应项对齐。跨语言实体匹配和三重对齐验证的实验显示了良好的效果,一些变体在不同的任务中始终优于其他变体。我们还探讨了 M T r a n s E MTransE MTransE如何保留其单语对应物 T r a n s E TransE TransE的关键属性。
1 Introduction
知识库被建模为知识图谱,存储两个方面的知识:单语知识,包括以三元组形式记录的实体和关系,以及跨语言知识,在各种人类语言中匹配单语知识。
基于嵌入的技术可以帮助提高单语知识的完整性,但将这些技术应用于跨语言知识的问题在很大程度上尚未探索(包括匹配相同实体的语言间链接(ILLs)和表示相同关系的三重对齐(TWA))。
利用知识图谱嵌入跨语言知识比较困难(不同语言的知识图谱中的实体和关系进行映射和转换的过程):
- 跨语言转换比任何单语言关系翻译都具有更大的域;
- 它适用于实体和关系,这些实体和关系在不同语言之间具有不连贯的词汇表;
- 用于训练这种转换的已知对齐通常占知识库的一小部分。
提出多语言知识图谱嵌入模型(MTransE),使用两个组件模型,即知识模型和对齐模型的组合来学习多语言知识图结构。知识模型以特定语言版本的知识图对实体和关系进行编码。对齐模型在不同的嵌入空间中学习实体和关系的跨语言转换,其中考虑了以下三种跨语言对齐的表示:基于距离的轴校准,平移向量和线性变换。
2 Related Work
知识图谱嵌入:
基于推理的方法:TransE、TransH、TransR
非基于翻译的方法:UM、SE、Billined
基于神经的模型:SLM、NTN
基于随机行走的模型:TADW
多语种单词嵌入:LM、CCA、OT
知识库对齐:基于嵌入的方法
3 Multilingual Knowledge Graph Embedding
3.1 Multilingual Knowledge Graphs
L
\mathcal L
L: 语言的集合
L
2
\mathcal L^2
L2: 表示
L
\mathcal L
L的2-组合(无序语言对的集合)
语言
L
∈
L
L \in \mathcal L
L∈L,
G
L
G_L
GL表示语言的专用知识图
E
L
E_L
EL: 实体表示
R
L
R_L
RL: 关系表示
T
=
(
h
,
r
,
t
)
T=(h, r, t)
T=(h,r,t)表示
G
L
G_L
GL中的三元组
h
,
t
∈
E
L
r
∈
R
L
h,t\in E_L \quad r\in R_L
h,t∈ELr∈RL
语言对
(
L
1
,
L
2
)
∈
L
2
,
δ
(
L
1
,
L
2
)
(L_1,L_2)\in \mathcal{L}^2, \delta(L_1,L_2)
(L1,L2)∈L2,δ(L1,L2)表示包含已经在
L
1
L_1
L1和
L
2
L_2
L2之间对齐的三元组对的集合
MTransE在知识库的两个方面进行学习:知识模型对来自每种语言特定的图结构的实体和关系进行编码,对齐模型从现有对齐学习跨语言转换。
3.2 Knowledge Model
损失函数:
S
K
=
∑
L
∈
{
L
i
,
L
j
}
∑
(
h
,
r
,
t
)
∈
G
L
∥
h
+
r
−
t
∥
S_K=\sum_{L\in\{L_i,L_j\}}\sum_{(h, r, t)\in G_L}\|\mathrm{\mathbf h+\mathbf r -\mathbf t}\|
SK=L∈{Li,Lj}∑(h,r,t)∈GL∑∥h+r−t∥
3.3 Alignment Model
配准模型的目标是构造
L
i
L_i
Li和
L
j
L_j
Lj向量空间之间的转换。其损失函数如下:
S
A
=
∑
(
T
,
T
′
)
∈
δ
(
L
i
,
L
j
)
S
a
(
T
,
T
′
)
S_A=\sum_{(T,T')\in\delta(L_i,L_j)}S_a(T,T')
SA=(T,T′)∈δ(Li,Lj)∑Sa(T,T′)
对齐分数 S a ( T , T ′ ) S_a(T,T') Sa(T,T′)迭代通过所有对齐的三元组。考虑了三种不同的对准评分技术:基于距离的轴校准、平移向量和线性变换。
基于距离的轴校准: 这种类型的对齐模型根据跨语言对应物的距离对对齐进行惩罚。
采用以下两种评分中的一种:
S
a
1
=
∥
h
−
h
′
∥
+
∥
t
−
t
′
∥
S_{a_1}=\|\mathbf{h}-\mathbf{h}'\|+\|\mathbf{t}-\mathbf{t}'\|
Sa1=∥h−h′∥+∥t−t′∥
S a 2 = ∥ h − h ′ ∥ + ∥ r − r ′ ∥ + ∥ t − t ′ ∥ S_{a_2}=\|\mathbf{h}-\mathbf{h}'\|+\|\mathbf{r}-\mathbf{r}'\|+\|\mathbf{t}-\mathbf{t}'\| Sa2=∥h−h′∥+∥r−r′∥+∥t−t′∥
S
a
1
S_{a1}
Sa1规定,同一实体的正确对齐的多语言表达往往具有紧密的嵌入向量。
S
a
2
S_{a2}
Sa2将关系对齐的惩罚叠加到
S
a
1
S_{a1}
Sa1,以显式收敛相同关系的坐标。
基于轴校准的对齐模型假定每种语言中的条目在空间上的出现情况类似。因此,它通过将给定实体或关系的向量从原语的空间推进到另一种语言的空间来实现跨语言的转换。
平移向量: 该模型将跨语言转换编码为向量。它将对齐整合到图形结构中,并将跨语言转换描述为常规的关系翻译。
这样的模型通过添加对应的平移向量来获得嵌入向量的跨语言转换。
S
a
3
=
∥
h
+
v
i
j
e
−
h
′
∥
+
∥
r
+
v
i
j
r
−
r
′
∥
+
∥
t
+
v
i
j
e
−
t
′
∥
S_{a_3}=\left\|\mathbf{h}+\mathbf{v}_{ij}^e-\mathbf{h}'\right\|+\left\|\mathbf{r}+\mathbf{v}_{ij}^r-\mathbf{r}'\right\|+\left\|\mathbf{t}+\mathbf{v}_{ij}^e-\mathbf{t}'\right\|
Sa3=
h+vije−h′
+
r+vijr−r′
+
t+vije−t′
线性变换: 最后一类对齐模型推导出嵌入空间之间的线性变换。如下所示,
S
a
4
S_{a4}
Sa4将
k
×
k
k\times k
k×k方阵
M
i
j
e
M_{ij}^e
Mije学习为从$ L_i$到
L
j
L_j
Lj的实体向量的线性变换,给定 k为嵌入空间的维度。
S
a
5
S_{a5}
Sa5还引入了关系向量的第二线性变换
M
i
j
r
M_{ij}^r
Mijr
与轴线校准不同,基于线性变换的对齐模型将跨语言转换视为嵌入空间的拓扑变换,而不假设空间涌现的相似性。
S
a
4
=
∥
M
i
j
e
h
−
h
′
∥
+
∥
M
i
j
e
t
−
t
′
∥
S_{a_4}=\begin{Vmatrix}\mathbf{M}_{ij}^e\mathbf{h}-\mathbf{h}'\end{Vmatrix}+\begin{Vmatrix}\mathbf{M}_{ij}^e\mathbf{t}-\mathbf{t}'\end{Vmatrix}
Sa4=
Mijeh−h′
+
Mijet−t′
S a 5 = ∥ M i j e h − h ′ ∥ + ∥ M i j r r − r ′ ∥ + ∥ M i j e t − t ′ ∥ S_{a_5}=\left\|\mathbf{M}_{ij}^e\mathbf{h}-\mathbf{h}'\right\|+\left\|\mathbf{M}_{ij}^r\mathbf{r}-\mathbf{r}'\right\|+\left\|\mathbf{M}_{ij}^e\mathbf{t}-\mathbf{t}'\right\| Sa5= Mijeh−h′ + Mijrr−r′ + Mijet−t′
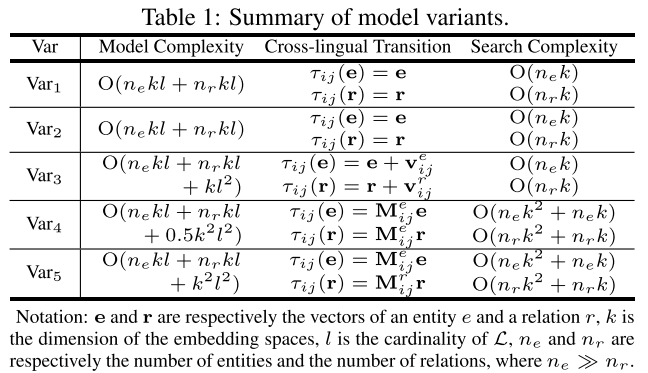
3.4 Variants of MTransE
结合上述两个分量模型,MTransE最小化如下损失函数 J = S K + α S A J=S_K + \alpha S_A J=SK+αSA,其中 α \alpha α是加权 S K S_K SK和 S A S_A SA的超参数。
3.5 Training
使用在线随机梯度下降来优化损失函数:
θ
←
θ
−
λ
∇
θ
J
\theta \leftarrow \theta − \lambda\nabla_{\theta}J
θ←θ−λ∇θJ
θ
←
θ
−
λ
∇
θ
J
\theta \leftarrow \theta − \lambda\nabla_{\theta}J
θ←θ−λ∇θJ 、
θ
←
θ
−
λ
∇
θ
α
S
A
\theta \leftarrow \theta − \lambda\nabla_{\theta}\alpha S_A
θ←θ−λ∇θαSA
强制任何实体嵌入向量的
l
2
l_2
l2范数为1的约束,从而将嵌入向量正则化到单位球面上:
(i)它有助于避免训练过程通过收缩嵌入向量的范数而使损失函数平凡地最小化的情况
(ii)它意味着
V
a
r
4
Var_4
Var4和
V
a
r
5
Var_5
Var5的线性变换的可逆性
4 Experiments
在两个跨语言任务上对所提出的方法进行评估:跨语言实体匹配和三对齐验证。为了显示MTransE的优势,将LM、CCA和OT改写为它们的知识图等效项。
数据集:WK31
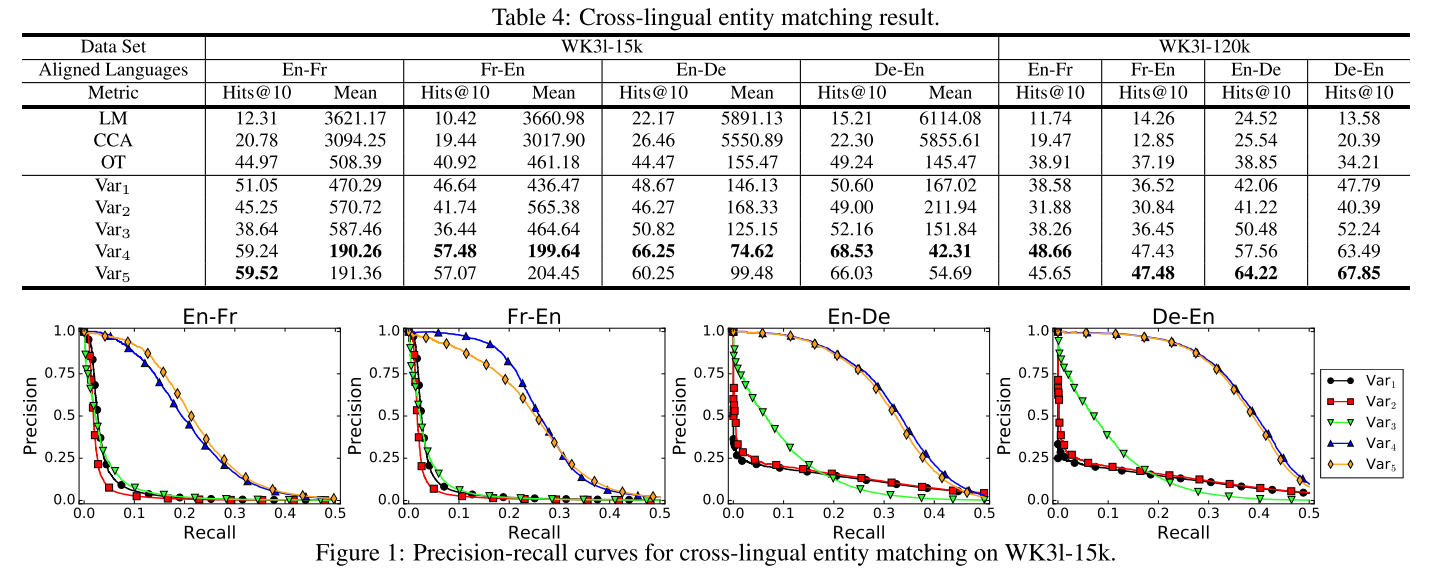
4.1 Cross-lingual Entity Matching
跨语言实体匹配
此任务的目标是在知识库中匹配来自不同语言的相同实体。
评估协议: 每个MTransE变体都是在一个完整的数据集上进行训练的。
结果:
4.2 Triple-wise Alignment Verification
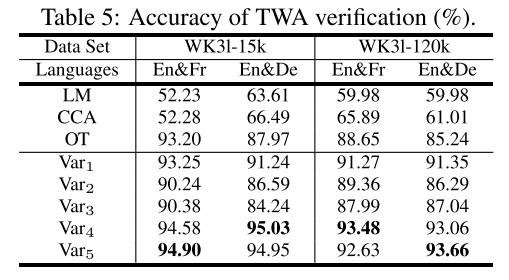
三重对齐验证
这项任务是验证给定的一对对齐的三元组是否是真正的跨语言对应。
评估协议: 通过隔离 20% 的比对集来创建正例。随机破坏正例以生成负例。使用一种简单的基于阈值的分类器。
结果:
4.3 Monolingual Tasks
单语任务
MTransE在处理跨语言任务方面具有很强的能力。MtransE很好地保留了单语知识的特征,在刻画单语关系方面,对齐模型对知识模型没有太大的干扰,但实际上可能会加强它,因为对齐模型统一了知识的连贯部分。
5 Conclusion and Future Work
语任务
MTransE在处理跨语言任务方面具有很强的能力。MtransE很好地保留了单语知识的特征,在刻画单语关系方面,对齐模型对知识模型没有太大的干扰,但实际上可能会加强它,因为对齐模型统一了知识的连贯部分。
5 Conclusion and Future Work
在跨语言实体匹配和三对齐验证任务上的大量实验表明,线性变换技术是这三种技术中最好的。此外,MTransE保留了单语知识图在单语任务中嵌入的关键特性。
深度学习小白,知识图谱方向,欢迎一起交流学习~