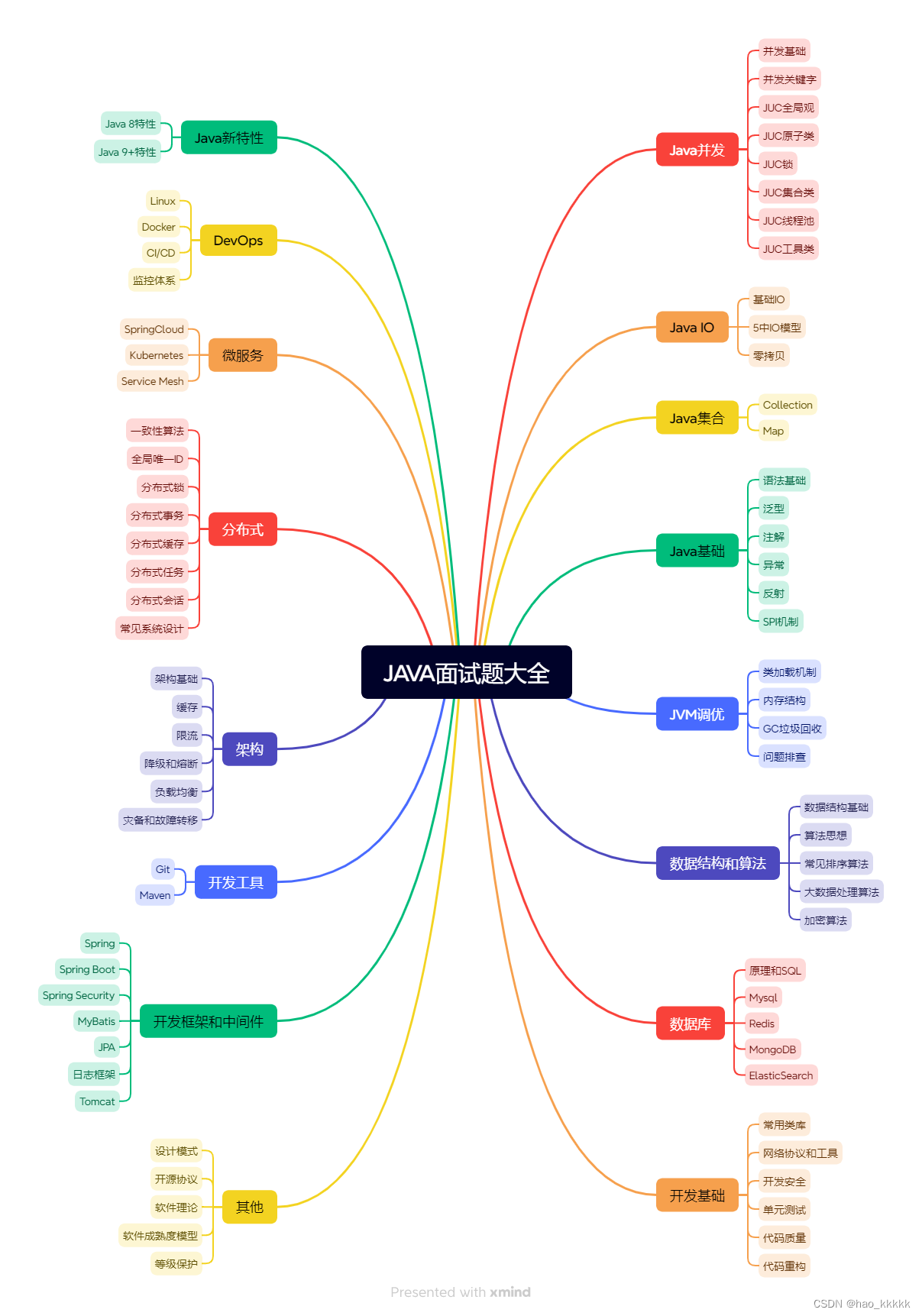
目录
1、并发基础
1.1、多线程的出现是要解决什么问题的? 本质什么?
1.2、Java是怎么解决并发问题的?
1.3、线程安全有哪些实现思路?
1.4、如何理解并发和并行的区别?
1.5、线程有哪几种状态? 分别说明从一种状态到另一种状态转变有哪些方式?
1.6、通常线程有哪几种使用方式?
1.7、基础线程机制有哪些?
1.8、线程的中断方式有哪些?
1.9、线程的互斥同步方式有哪些? 如何比较和选择?
1.10、线程之间有哪些协作方式?
2、并发关键字
2.1、Synchronized可以作用在哪里?
2.2、Synchronized本质上是通过什么保证线程安全的?
2.3、Synchronized使得同时只有一个线程可以执行,性能比较差,有什么提升的方法?
2.4、Synchronized由什么样的缺陷? Java Lock是怎么弥补这些缺陷的?
2.5、Synchronized和Lock的对比,和选择?
2.6、Synchronized在使用时有何注意事项?
2.7、Synchronized修饰的方法在抛出异常时,会释放锁吗?
2.8、多个线程等待同一个Synchronized锁的时候,JVM如何选择下一个获取锁的线程?
2.9、synchronized是公平锁吗?
2.10、volatile关键字的作用是什么?
2.11、volatile能保证原子性吗?
2.12、32位机器上共享的long和double变量的为什么要用volatile?
2.13、volatile是如何实现可见性的?
2.14、volatile是如何实现有序性的?
2.15、说下volatile的应用场景?
2.16、所有的final修饰的字段都是编译期常量吗?
2.17、如何理解private所修饰的方法是隐式的final?
2.18、说说final类型的类如何拓展?
2.19、final方法可以被重载吗?
2.20、父类的final方法能不能够被子类重写?
2.21、说说基本类型的final域重排序规则?
2.22、说说final的原理?
3、JUC全局观
3.1、JUC框架包含几个部分?
3.2、Lock框架和Tools哪些核心的类?
3.3、JUC并发集合哪些核心的类?
3.4、JUC原子类哪些核心的类?
3.5、JUC线程池哪些核心的类?
4、JUC原子类
4.1、线程安全的实现方法有哪些?
4.2、什么是CAS?
4.3、CAS使用示例,结合AtomicInteger给出示例?
4.4、CAS会有哪些问题?
4.5、AtomicInteger底层实现?
4.6、请阐述你对Unsafe类的理解?
4.7、说说你对Java原子类的理解?
4.8、AtomicStampedReference是怎么解决ABA的?
5、 JUC锁
5.1、为什么LockSupport也是核心基础类?
5.2、通过wait/notify实现同步?
5.3、通过LockSupport的park/unpark实现同步?
5.4、Thread.sleep()、Object.wait()、Condition.await()、LockSupport.park()的区别? 重点
5.5、如果在wait()之前执行了notify()会怎样?
5.6、如果在park()之前执行了unpark()会怎样?
5.7、什么是AQS? 为什么它是核心?
5.8、AQS的核心思想是什么?
5.9、AQS有哪些核心的方法?
5.10、AQS定义什么样的资源获取方式?
5.11、AQS底层使用了什么样的设计模式?
5.12、什么是可重入,什么是可重入锁? 它用来解决什么问题?
5.13、ReentrantLock的核心是AQS,那么它怎么来实现的,继承吗?
5.14、ReentrantLock是如何实现公平锁的?
5.15、ReentrantLock是如何实现非公平锁的?
5.16、ReentrantLock默认实现的是公平还是非公平锁?
5.17、为了有了ReentrantLock还需要ReentrantReadWriteLock?
5.18、ReentrantReadWriteLock底层实现原理?
5.19、ReentrantReadWriteLock底层读写状态如何设计的?
5.20、读锁和写锁的最大数量是多少?
5.21、本地线程计数器ThreadLocalHoldCounter是用来做什么的?
5.22、写锁的获取与释放是怎么实现的?
5.23、读锁的获取与释放是怎么实现的?
5.24、什么是锁的升降级?
6、JUC集合类
6.1、为什么HashTable慢? 它的并发度是什么? 那么ConcurrentHashMap并发度是什么?
6.2、ConcurrentHashMap在JDK1.7和JDK1.8中实现有什么差别? JDK1.8解決了JDK1.7中什么问题
6.3、ConcurrentHashMap JDK1.7实现的原理是什么?
6.4、ConcurrentHashMap JDK1.7中Segment数(concurrencyLevel)默认值是多少? 为何一旦初始化就不可再扩容?
6.5、ConcurrentHashMap JDK1.7说说其put的机制?
6.6、ConcurrentHashMap JDK1.7是如何扩容的?
6.7、ConcurrentHashMap JDK1.8实现的原理是什么?
6.8、ConcurrentHashMap JDK1.8是如何扩容的?
6.9、ConcurrentHashMap JDK1.8链表转红黑树的时机是什么? 临界值为什么是8?
6.10、ConcurrentHashMap JDK1.8是如何进行数据迁移的?
6.11、先说说非并发集合中Fail-fast机制?
6.12、CopyOnWriteArrayList的实现原理?
6.13、弱一致性的迭代器原理是怎么样的?
6.14、CopyOnWriteArrayList为什么并发安全且性能比Vector好?
6.15、CopyOnWriteArrayList有何缺陷,说说其应用场景?
6.16、要想用线程安全的队列有哪些选择?
6.17、ConcurrentLinkedQueue实现的数据结构?
6.18、ConcurrentLinkedQueue底层原理?
6.19、ConcurrentLinkedQueue的核心方法有哪些?
6.20、说说ConcurrentLinkedQueue的HOPS(延迟更新的策略)的设计?
6.21、ConcurrentLinkedQueue适合什么样的使用场景?
6.22、什么是BlockingDeque? 适合用在什么样的场景?
6.23、BlockingQueue大家族有哪些?
6.24、BlockingQueue常用的方法?
6.25、BlockingQueue 实现例子?
6.26、什么是BlockingDeque? 适合用在什么样的场景?
6.27、BlockingDeque 与BlockingQueue有何关系,请对比下它们的方法?
6.28、BlockingDeque大家族有哪些?
6.29、BlockingDeque 实现例子?
7、JUC线程池
7.1、FutureTask用来解决什么问题的? 为什么会出现?
7.2、FutureTask类结构关系怎么样的?
7.3、FutureTask的线程安全是由什么保证的?
7.4、FutureTask通常会怎么用? 举例说明。
7.5、为什么要有线程池?
7.6、Java是实现和管理线程池有哪些方式? 请简单举例如何使用。
7.7、ThreadPoolExecutor的原理?
7.8、ThreadPoolExecutor有哪些核心的配置参数? 请简要说明
7.9、ThreadPoolExecutor可以创建哪是哪三种线程池呢?
7.10、当队列满了并且worker的数量达到maxSize的时候,会怎么样?
7.11、说说ThreadPoolExecutor有哪些RejectedExecutionHandler策略? 默认是什么策略?
7.12、简要说下线程池的任务执行机制?
7.13、线程池中任务是如何提交的?
7.14、线程池中任务是如何关闭的?
7.15、在配置线程池的时候需要考虑哪些配置因素?
7.16、如何监控线程池的状态?
7.17、为什么很多公司不允许使用Executors去创建线程池? 那么推荐怎么使用呢?
7.18、ScheduledThreadPoolExecutor要解决什么样的问题?
7.19、ScheduledThreadPoolExecutor相比ThreadPoolExecutor有哪些特性?
7.20、ScheduledThreadPoolExecutor有什么样的数据结构,核心内部类和抽象类?
7.21、ScheduledThreadPoolExecutor有哪两个关闭策略? 区别是什么?
7.22、ScheduledThreadPoolExecutor中scheduleAtFixedRate 和 scheduleWithFixedDelay区别是什么?
7.23、为什么ThreadPoolExecutor 的调整策略却不适用于 ScheduledThreadPoolExecutor?
7.24、Executors 提供了几种方法来构造 ScheduledThreadPoolExecutor?
7.25、Fork/Join主要用来解决什么样的问题?
7.26、Fork/Join框架是在哪个JDK版本中引入的?
7.27、Fork/Join框架主要包含哪三个模块? 模块之间的关系是怎么样的?
7.28、ForkJoinPool类继承关系?
7.29、ForkJoinTask抽象类继承关系?
7.30、整个Fork/Join 框架的执行流程/运行机制是怎么样的?
7.31、具体阐述Fork/Join的分治思想和work-stealing 实现方式?
7.32、有哪些JDK源码中使用了Fork/Join思想?
7.33、如何使用Executors工具类创建ForkJoinPool?
7.34、写一个例子: 用ForkJoin方式实现1+2+3+...+100000?
7.35、Fork/Join在使用时有哪些注意事项? 结合JDK中的斐波那契数列实例具体说明。
8、JUC工具类
8.1、什么是CountDownLatch?
8.2、CountDownLatch底层实现原理?
8.3、CountDownLatch一次可以唤醒几个任务?
8.4、CountDownLatch有哪些主要方法?
8.5、写道题:实现一个容器,提供两个方法,add,size 写两个线程,线程1添加10个元素到容器中,线程2实现监控元素的个数,当个数到5个时,线程2给出提示并结束?
8.6、什么是CyclicBarrier?
8.7、CountDownLatch和CyclicBarrier对比?
8.8、什么是Semaphore?
8.9、Semaphore内部原理?
8.10、Semaphore常用方法有哪些? 如何实现线程同步和互斥的?
8.11、单独使用Semaphore是不会使用到AQS的条件队列?
8.12、Semaphore初始化有10个令牌,11个线程同时各调用1次acquire方法,会发生什么?
8.13、Semaphore初始化有10个令牌,一个线程重复调用11次acquire方法,会发生什么?
8.14、Semaphore初始化有1个令牌,1个线程调用一次acquire方法,然后调用两次release方法,之后另外一个线程调用acquire(2)方法,此线程能够获取到足够的令牌并继续运行吗?
8.15、Semaphore初始化有2个令牌,一个线程调用1次release方法,然后一次性获取3个令牌,会获取到吗?
8.16、Phaser主要用来解决什么问题?
8.17、Phaser与CyclicBarrier和CountDownLatch的区别是什么?
8.18、Phaser运行机制是什么样的?
8.19、给一个Phaser使用的示例?
8.20、Exchanger主要解决什么问题?
8.21、对比SynchronousQueue,为什么说Exchanger可被视为 SynchronousQueue 的双向形式?
8.22、Exchanger在不同的JDK版本中实现有什么差别?
8.23、Exchanger实现举例
8.24、什么是ThreadLocal? 用来解决什么问题的?
8.25、说说你对ThreadLocal的理解
8.26、ThreadLocal是如何实现线程隔离的?
8.27、为什么ThreadLocal会造成内存泄露? 如何解决
8.28、还有哪些使用ThreadLocal的应用场景?
9、Java面试题总述
致力于一个专栏将Java面试说的清清楚楚,从工作实践角度出发,尽量涵盖Java主流知识点,全面讲述Java面试题。
本篇讲述Java并发和多线程,总共涵盖8个知识点,161道热点面试题。
1、并发基础
1.1、多线程的出现是要解决什么问题的? 本质什么?
CPU、内存、I/O 设备的速度是有极大差异的,为了合理利用 CPU 的高性能,平衡这三者的速度差异,计算机体系结构、操作系统、编译程序都做出了贡献,主要体现为:
- CPU 增加了缓存,以均衡与内存的速度差异;// 导致可见性问题
- 操作系统增加了进程、线程,以分时复用 CPU,进而均衡 CPU 与 I/O 设备的速度差异;// 导致原子性问题
- 编译程序优化指令执行次序,使得缓存能够得到更加合理地利用。// 导致有序性问题
1.2、Java是怎么解决并发问题的?
Java 内存模型是个很复杂的规范,具体看Java 内存模型详解。
理解的第一个维度:核心知识点
JMM本质上可以理解为,Java 内存模型规范了 JVM 如何提供按需禁用缓存和编译优化的方法。具体来说,这些方法包括:
- volatile、synchronized 和 final 三个关键字
- Happens-Before 规则
理解的第二个维度:可见性,有序性,原子性
- 原子性
在Java中,对基本数据类型的变量的读取和赋值操作是原子性操作,即这些操作是不可被中断的,要么执行,要么不执行。 请分析以下哪些操作是原子性操作:
x = 10; //语句1: 直接将数值10赋值给x,也就是说线程执行这个语句的会直接将数值10写入到工作内存中
y = x; //语句2: 包含2个操作,它先要去读取x的值,再将x的值写入工作内存,虽然读取x的值以及 将x的值写入工作内存 这2个操作都是原子性操作,但是合起来就不是原子性操作了。
x++; //语句3: x++包括3个操作:读取x的值,进行加1操作,写入新的值。
x = x + 1; //语句4: 同语句3
上面4个语句只有语句1的操作具备原子性。
也就是说,只有简单的读取、赋值(而且必须是将数字赋值给某个变量,变量之间的相互赋值不是原子操作)才是原子操作。
从上面可以看出,Java内存模型只保证了基本读取和赋值是原子性操作,如果要实现更大范围操作的原子性,可以通过synchronized和Lock来实现。由于synchronized和Lock能够保证任一时刻只有一个线程执行该代码块,那么自然就不存在原子性问题了,从而保证了原子性。
- 可见性
Java提供了volatile关键字来保证可见性。
当一个共享变量被volatile修饰时,它会保证修改的值会立即被更新到主存,当有其他线程需要读取时,它会去内存中读取新值。
而普通的共享变量不能保证可见性,因为普通共享变量被修改之后,什么时候被写入主存是不确定的,当其他线程去读取时,此时内存中可能还是原来的旧值,因此无法保证可见性。
另外,通过synchronized和Lock也能够保证可见性,synchronized和Lock能保证同一时刻只有一个线程获取锁然后执行同步代码,并且在释放锁之前会将对变量的修改刷新到主存当中。因此可以保证可见性。
- 有序性
在Java里面,可以通过volatile关键字来保证一定的“有序性”。另外可以通过synchronized和Lock来保证有序性,很显然,synchronized和Lock保证每个时刻是有一个线程执行同步代码,相当于是让线程顺序执行同步代码,自然就保证了有序性。当然JMM是通过Happens-Before 规则来保证有序性的。
1.3、线程安全有哪些实现思路?
1、互斥同步
synchronized 和 ReentrantLock。
2、非阻塞同步
互斥同步最主要的问题就是线程阻塞和唤醒所带来的性能问题,因此这种同步也称为阻塞同步。
互斥同步属于一种悲观的并发策略,总是认为只要不去做正确的同步措施,那就肯定会出现问题。无论共享数据是否真的会出现竞争,它都要进行加锁(这里讨论的是概念模型,实际上虚拟机会优化掉很大一部分不必要的加锁)、用户态核心态转换、维护锁计数器和检查是否有被阻塞的线程需要唤醒等操作。
- CAS
随着硬件指令集的发展,我们可以使用基于冲突检测的乐观并发策略: 先进行操作,如果没有其它线程争用共享数据,那操作就成功了,否则采取补偿措施(不断地重试,直到成功为止)。这种乐观的并发策略的许多实现都不需要将线程阻塞,因此这种同步操作称为非阻塞同步。
乐观锁需要操作和冲突检测这两个步骤具备原子性,这里就不能再使用互斥同步来保证了,只能靠硬件来完成。硬件支持的原子性操作最典型的是: 比较并交换(Compare-and-Swap,CAS)。CAS 指令需要有 3 个操作数,分别是内存地址 V、旧的预期值 A 和新值 B。当执行操作时,只有当 V 的值等于 A,才将 V 的值更新为 B。
- AtomicInteger
J.U.C 包里面的整数原子类 AtomicInteger,其中的 compareAndSet() 和 getAndIncrement() 等方法都使用了 Unsafe 类的 CAS 操作。
3、无同步方案
要保证线程安全,并不是一定就要进行同步。如果一个方法本来就不涉及共享数据,那它自然就无须任何同步措施去保证正确性。
- 栈封闭
多个线程访问同一个方法的局部变量时,不会出现线程安全问题,因为局部变量存储在虚拟机栈中,属于线程私有的。
- 线程本地存储(Thread Local Storage)
如果一段代码中所需要的数据必须与其他代码共享,那就看看这些共享数据的代码是否能保证在同一个线程中执行。如果能保证,我们就可以把共享数据的可见范围限制在同一个线程之内,这样,无须同步也能保证线程之间不出现数据争用的问题。
1.4、如何理解并发和并行的区别?
并发是指一个处理器同时处理多个任务。
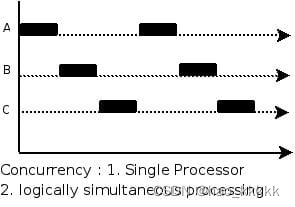
并行是指多个处理器或者是多核的处理器同时处理多个不同的任务。

1.5、线程有哪几种状态? 分别说明从一种状态到另一种状态转变有哪些方式?
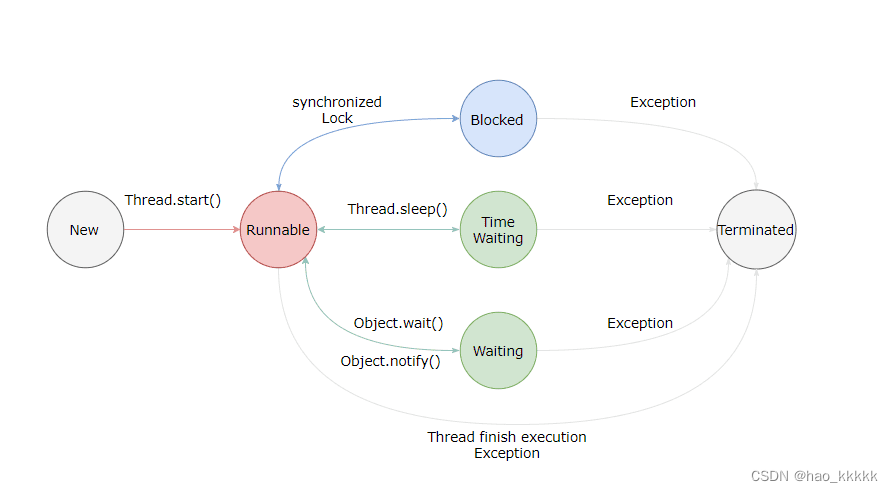
- 新建(New)
创建后尚未启动。
- 可运行(Runnable)
可能正在运行,也可能正在等待 CPU 时间片。
包含了操作系统线程状态中的 Running 和 Ready。
- 阻塞(Blocking)
等待获取一个排它锁,如果其线程释放了锁就会结束此状态。
- 无限期等待(Waiting)
等待其它线程显式地唤醒,否则不会被分配 CPU 时间片。
| 进入方法 | 退出方法 |
|---|---|
| 没有设置 Timeout 参数的 Object.wait() 方法 | Object.notify() / Object.notifyAll() |
| 没有设置 Timeout 参数的 Thread.join() 方法 | 被调用的线程执行完毕 |
| LockSupport.park() 方法 | - |
- 限期等待(Timed Waiting)
无需等待其它线程显式地唤醒,在一定时间之后会被系统自动唤醒。
调用 Thread.sleep() 方法使线程进入限期等待状态时,常常用“使一个线程睡眠”进行描述。
调用 Object.wait() 方法使线程进入限期等待或者无限期等待时,常常用“挂起一个线程”进行描述。
睡眠和挂起是用来描述行为,而阻塞和等待用来描述状态。
阻塞和等待的区别在于,阻塞是被动的,它是在等待获取一个排它锁。而等待是主动的,通过调用 Thread.sleep() 和 Object.wait() 等方法进入。
| 进入方法 | 退出方法 |
|---|---|
| Thread.sleep() 方法 | 时间结束 |
| 设置了 Timeout 参数的 Object.wait() 方法 | 时间结束 / Object.notify() / Object.notifyAll() |
| 设置了 Timeout 参数的 Thread.join() 方法 | 时间结束 / 被调用的线程执行完毕 |
| LockSupport.parkNanos() 方法 | - |
| LockSupport.parkUntil() 方法 | - |
- 死亡(Terminated)
可以是线程结束任务之后自己结束,或者产生了异常而结束。
1.6、通常线程有哪几种使用方式?
有三种使用线程的方法:
- 实现 Runnable 接口;
- 实现 Callable 接口;
- 继承 Thread 类。
实现 Runnable 和 Callable 接口的类只能当做一个可以在线程中运行的任务,不是真正意义上的线程,因此最后还需要通过 Thread 来调用。可以说任务是通过线程驱动从而执行的。
1.7、基础线程机制有哪些?
- Executor
Executor 管理多个异步任务的执行,而无需程序员显式地管理线程的生命周期。这里的异步是指多个任务的执行互不干扰,不需要进行同步操作。
主要有三种 Executor:
- CachedThreadPool: 一个任务创建一个线程;
- FixedThreadPool: 所有任务只能使用固定大小的线程;
- SingleThreadExecutor: 相当于大小为 1 的 FixedThreadPool。
- Daemon
守护线程是程序运行时在后台提供服务的线程,不属于程序中不可或缺的部分。
当所有非守护线程结束时,程序也就终止,同时会杀死所有守护线程。
main() 属于非守护线程。使用 setDaemon() 方法将一个线程设置为守护线程。
- sleep()
Thread.sleep(millisec) 方法会休眠当前正在执行的线程,millisec 单位为毫秒。
sleep() 可能会抛出 InterruptedException,因为异常不能跨线程传播回 main() 中,因此必须在本地进行处理。线程中抛出的其它异常也同样需要在本地进行处理。
- yield()
对静态方法 Thread.yield() 的调用声明了当前线程已经完成了生命周期中最重要的部分,可以切换给其它线程来执行。该方法只是对线程调度器的一个建议,而且也只是建议具有相同优先级的其它线程可以运行。
1.8、线程的中断方式有哪些?
一个线程执行完毕之后会自动结束,如果在运行过程中发生异常也会提前结束。
- InterruptedException
通过调用一个线程的 interrupt() 来中断该线程,如果该线程处于阻塞、限期等待或者无限期等待状态,那么就会抛出 InterruptedException,从而提前结束该线程。但是不能中断 I/O 阻塞和 synchronized 锁阻塞。
对于以下代码,在 main() 中启动一个线程之后再中断它,由于线程中调用了 Thread.sleep() 方法,因此会抛出一个 InterruptedException,从而提前结束线程,不执行之后的语句。
public class InterruptExample {
private static class MyThread1 extends Thread {
@Override
public void run() {
try {
Thread.sleep(2000);
System.out.println("Thread run");
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
public static void main(String[] args) throws InterruptedException {
Thread thread1 = new MyThread1();
thread1.start();
thread1.interrupt();
System.out.println("Main run");
}
}
Main run
java.lang.InterruptedException: sleep interrupted
at java.lang.Thread.sleep(Native Method)
at InterruptExample.lambda$main$0(InterruptExample.java:5)
at InterruptExample$$Lambda$1/713338599.run(Unknown Source)
at java.lang.Thread.run(Thread.java:745)
- interrupted()
如果一个线程的 run() 方法执行一个无限循环,并且没有执行 sleep() 等会抛出 InterruptedException 的操作,那么调用线程的 interrupt() 方法就无法使线程提前结束。
但是调用 interrupt() 方法会设置线程的中断标记,此时调用 interrupted() 方法会返回 true。因此可以在循环体中使用 interrupted() 方法来判断线程是否处于中断状态,从而提前结束线程。
- Executor 的中断操作
调用 Executor 的 shutdown() 方法会等待线程都执行完毕之后再关闭,但是如果调用的是 shutdownNow() 方法,则相当于调用每个线程的 interrupt() 方法。
1.9、线程的互斥同步方式有哪些? 如何比较和选择?
Java 提供了两种锁机制来控制多个线程对共享资源的互斥访问,第一个是 JVM 实现的 synchronized,而另一个是 JDK 实现的 ReentrantLock。
1. 锁的实现
synchronized 是 JVM 实现的,而 ReentrantLock 是 JDK 实现的。
2. 性能
新版本 Java 对 synchronized 进行了很多优化,例如自旋锁等,synchronized 与 ReentrantLock 大致相同。
3. 等待可中断
当持有锁的线程长期不释放锁的时候,正在等待的线程可以选择放弃等待,改为处理其他事情。
ReentrantLock 可中断,而 synchronized 不行。
4. 公平锁
公平锁是指多个线程在等待同一个锁时,必须按照申请锁的时间顺序来依次获得锁。
synchronized 中的锁是非公平的,ReentrantLock 默认情况下也是非公平的,但是也可以是公平的。
5. 锁绑定多个条件
一个 ReentrantLock 可以同时绑定多个 Condition 对象。
1.10、线程之间有哪些协作方式?
当多个线程可以一起工作去解决某个问题时,如果某些部分必须在其它部分之前完成,那么就需要对线程进行协调。
- join()
在线程中调用另一个线程的 join() 方法,会将当前线程挂起,而不是忙等待,直到目标线程结束。
对于以下代码,虽然 b 线程先启动,但是因为在 b 线程中调用了 a 线程的 join() 方法,b 线程会等待 a 线程结束才继续执行,因此最后能够保证 a 线程的输出先于 b 线程的输出。
public class JoinExample {
private class A extends Thread {
@Override
public void run() {
System.out.println("A");
}
}
private class B extends Thread {
private A a;
B(A a) {
this.a = a;
}
@Override
public void run() {
try {
a.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("B");
}
}
public void test() {
A a = new A();
B b = new B(a);
b.start();
a.start();
}
}
public static void main(String[] args) {
JoinExample example = new JoinExample();
example.test();
}
A
B
- wait() notify() notifyAll()
调用 wait() 使得线程等待某个条件满足,线程在等待时会被挂起,当其他线程的运行使得这个条件满足时,其它线程会调用 notify() 或者 notifyAll() 来唤醒挂起的线程。
它们都属于 Object 的一部分,而不属于 Thread。
只能用在同步方法或者同步控制块中使用,否则会在运行时抛出 IllegalMonitorStateExeception。
使用 wait() 挂起期间,线程会释放锁。这是因为,如果没有释放锁,那么其它线程就无法进入对象的同步方法或者同步控制块中,那么就无法执行 notify() 或者 notifyAll() 来唤醒挂起的线程,造成死锁。
wait() 和 sleep() 的区别
- wait() 是 Object 的方法,而 sleep() 是 Thread 的静态方法;
- wait() 会释放锁,sleep() 不会。
- await() signal() signalAll()
java.util.concurrent 类库中提供了 Condition 类来实现线程之间的协调,可以在 Condition 上调用 await() 方法使线程等待,其它线程调用 signal() 或 signalAll() 方法唤醒等待的线程。相比于 wait() 这种等待方式,await() 可以指定等待的条件,因此更加灵活。
2、并发关键字
2.1、Synchronized可以作用在哪里?
- 对象锁
- 方法锁
- 类锁
2.2、Synchronized本质上是通过什么保证线程安全的?
- 加锁和释放锁的原理
深入JVM看字节码,创建如下的代码:
public class SynchronizedDemo2 {
Object object = new Object();
public void method1() {
synchronized (object) {
}
}
}
使用javac命令进行编译生成.class文件
>javac SynchronizedDemo2.java
使用javap命令反编译查看.class文件的信息
>javap -verbose SynchronizedDemo2.class
得到如下的信息:
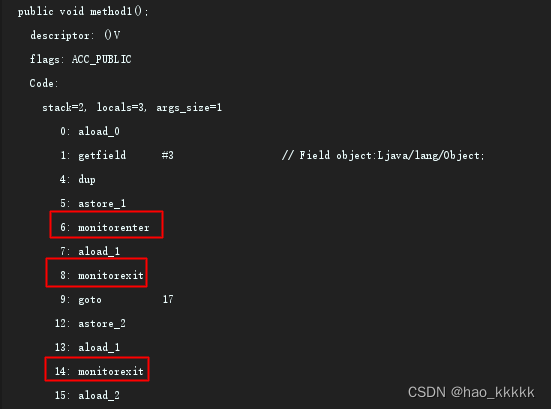
关注红色方框里的monitorenter和monitorexit即可。
Monitorenter和Monitorexit指令,会让对象在执行,使其锁计数器加1或者减1。每一个对象在同一时间只与一个monitor(锁)相关联,而一个monitor在同一时间只能被一个线程获得,一个对象在尝试获得与这个对象相关联的Monitor锁的所有权的时候,monitorenter指令会发生如下3中情况之一:
- monitor计数器为0,意味着目前还没有被获得,那这个线程就会立刻获得然后把锁计数器+1,一旦+1,别的线程再想获取,就需要等待
- 如果这个monitor已经拿到了这个锁的所有权,又重入了这把锁,那锁计数器就会累加,变成2,并且随着重入的次数,会一直累加
- 这把锁已经被别的线程获取了,等待锁释放
monitorexit指令:释放对于monitor的所有权,释放过程很简单,就是讲monitor的计数器减1,如果减完以后,计数器不是0,则代表刚才是重入进来的,当前线程还继续持有这把锁的所有权,如果计数器变成0,则代表当前线程不再拥有该monitor的所有权,即释放锁。
下图表现了对象,对象监视器,同步队列以及执行线程状态之间的关系:
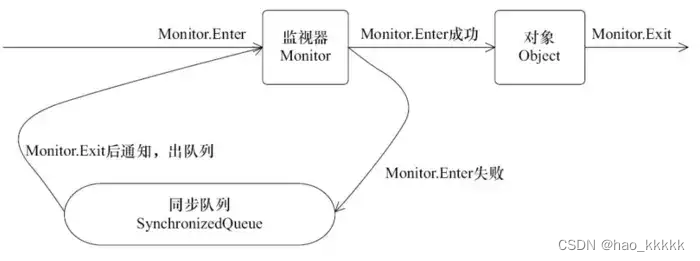
该图可以看出,任意线程对Object的访问,首先要获得Object的监视器,如果获取失败,该线程就进入同步状态,线程状态变为BLOCKED,当Object的监视器占有者释放后,在同步队列中得线程就会有机会重新获取该监视器。
- 可重入原理:加锁次数计数器
看如下的例子:
public class SynchronizedDemo {
public static void main(String[] args) {
synchronized (SynchronizedDemo.class) {
}
method2();
}
private synchronized static void method2() {
}
}
对应的字节码
public static void main(java.lang.String[]);
descriptor: ([Ljava/lang/String;)V
flags: (0x0009) ACC_PUBLIC, ACC_STATIC
Code:
stack=2, locals=3, args_size=1
0: ldc #2 // class tech/pdai/test/synchronized/SynchronizedDemo
2: dup
3: astore_1
4: monitorenter
5: aload_1
6: monitorexit
7: goto 15
10: astore_2
11: aload_1
12: monitorexit
13: aload_2
15: invokestatic #3 // Method method2:()V
Exception table:
from to target type
5 7 10 any
10 13 10 any
上面的SynchronizedDemo中在执行完同步代码块之后紧接着再会去执行一个静态同步方法,而这个方法锁的对象依然就这个类对象,那么这个正在执行的线程还需要获取该锁吗? 答案是不必的,从上图中就可以看出来,执行静态同步方法的时候就只有一条monitorexit指令,并没有monitorenter获取锁的指令。这就是锁的重入性,即在同一锁程中,线程不需要再次获取同一把锁。
Synchronized先天具有重入性。每个对象拥有一个计数器,当线程获取该对象锁后,计数器就会加一,释放锁后就会将计数器减一。
- 保证可见性的原理:内存模型和happens-before规则
Synchronized的happens-before规则,即监视器锁规则:对同一个监视器的解锁,happens-before于对该监视器的加锁。继续来看代码:
public class MonitorDemo {
private int a = 0;
public synchronized void writer() { // 1
a++; // 2
} // 3
public synchronized void reader() { // 4
int i = a; // 5
} // 6
}
该代码的happens-before关系如图所示:
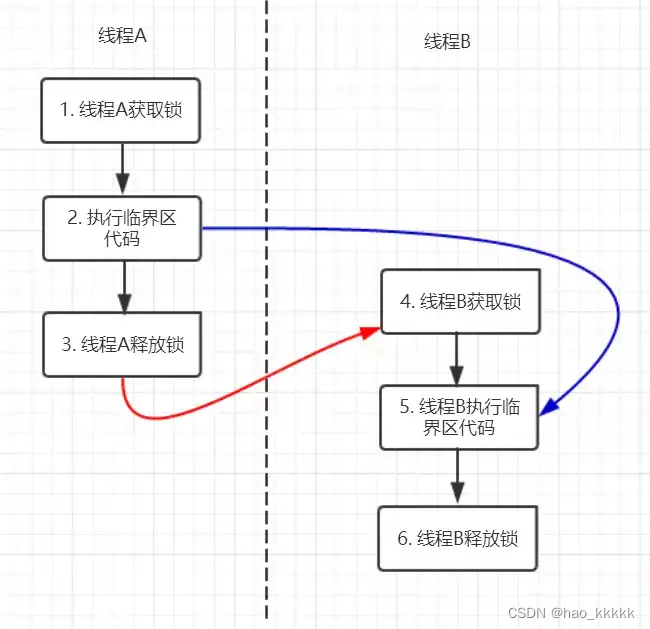
在图中每一个箭头连接的两个节点就代表之间的happens-before关系,黑色的是通过程序顺序规则推导出来,红色的为监视器锁规则推导而出:线程A释放锁happens-before线程B加锁,蓝色的则是通过程序顺序规则和监视器锁规则推测出来happens-befor关系,通过传递性规则进一步推导的happens-before关系。现在我们来重点关注2 happens-before 5,通过这个关系我们可以得出什么?
根据happens-before的定义中的一条:如果A happens-before B,则A的执行结果对B可见,并且A的执行顺序先于B。线程A先对共享变量A进行加一,由2 happens-before 5关系可知线程A的执行结果对线程B可见即线程B所读取到的a的值为1。
2.3、Synchronized使得同时只有一个线程可以执行,性能比较差,有什么提升的方法?
简单来说在JVM中monitorenter和monitorexit字节码依赖于底层的操作系统的Mutex Lock来实现的,但是由于使用Mutex Lock需要将当前线程挂起并从用户态切换到内核态来执行,这种切换的代价是非常昂贵的;然而在现实中的大部分情况下,同步方法是运行在单线程环境(无锁竞争环境)如果每次都调用Mutex Lock那么将严重的影响程序的性能。不过在jdk1.6中对锁的实现引入了大量的优化,如锁粗化(Lock Coarsening)、锁消除(Lock Elimination)、轻量级锁(Lightweight Locking)、偏向锁(Biased Locking)、适应性自旋(Adaptive Spinning)等技术来减少锁操作的开销。
-
锁粗化(Lock Coarsening):也就是减少不必要的紧连在一起的unlock,lock操作,将多个连续的锁扩展成一个范围更大的锁。
-
锁消除(Lock Elimination):通过运行时JIT编译器的逃逸分析来消除一些没有在当前同步块以外被其他线程共享的数据的锁保护,通过逃逸分析也可以在线程本地Stack上进行对象空间的分配(同时还可以减少Heap上的垃圾收集开销)。
-
轻量级锁(Lightweight Locking):这种锁实现的背后基于这样一种假设,即在真实的情况下我们程序中的大部分同步代码一般都处于无锁竞争状态(即单线程执行环境),在无锁竞争的情况下完全可以避免调用操作系统层面的重量级互斥锁,取而代之的是在monitorenter和monitorexit中只需要依靠一条CAS原子指令就可以完成锁的获取及释放。当存在锁竞争的情况下,执行CAS指令失败的线程将调用操作系统互斥锁进入到阻塞状态,当锁被释放的时候被唤醒。
-
偏向锁(Biased Locking):是为了在无锁竞争的情况下避免在锁获取过程中执行不必要的CAS原子指令,因为CAS原子指令虽然相对于重量级锁来说开销比较小但还是存在非常可观的本地延迟。
-
适应性自旋(Adaptive Spinning):当线程在获取轻量级锁的过程中执行CAS操作失败时,在进入与monitor相关联的操作系统重量级锁(mutex semaphore)前会进入忙等待(Spinning)然后再次尝试,当尝试一定的次数后如果仍然没有成功则调用与该monitor关联的semaphore(即互斥锁)进入到阻塞状态。
2.4、Synchronized由什么样的缺陷? Java Lock是怎么弥补这些缺陷的?
- synchronized的缺陷
- 效率低:锁的释放情况少,只有代码执行完毕或者异常结束才会释放锁;试图获取锁的时候不能设定超时,不能中断一个正在使用锁的线程,相对而言,Lock可以中断和设置超时
- 不够灵活:加锁和释放的时机单一,每个锁仅有一个单一的条件(某个对象),相对而言,读写锁更加灵活
- 无法知道是否成功获得锁,相对而言,Lock可以拿到状态
- Lock解决相应问题
Lock类这里不做过多解释,主要看里面的4个方法:
lock(): 加锁unlock(): 解锁tryLock(): 尝试获取锁,返回一个boolean值tryLock(long,TimeUtil): 尝试获取锁,可以设置超时
Synchronized只有锁只与一个条件(是否获取锁)相关联,不灵活,后来Condition与Lock的结合解决了这个问题。
多线程竞争一个锁时,其余未得到锁的线程只能不停的尝试获得锁,而不能中断。高并发的情况下会导致性能下降。ReentrantLock的lockInterruptibly()方法可以优先考虑响应中断。 一个线程等待时间过长,它可以中断自己,然后ReentrantLock响应这个中断,不再让这个线程继续等待。有了这个机制,使用ReentrantLock时就不会像synchronized那样产生死锁了。
2.5、Synchronized和Lock的对比,和选择?
- 存在层次上
synchronized: Java的关键字,在jvm层面上
Lock: 是一个接口
- 锁的释放
synchronized: 1、以获取锁的线程执行完同步代码,释放锁 2、线程执行发生异常,jvm会让线程释放锁
Lock: 在finally中必须释放锁,不然容易造成线程死锁
- 锁的获取
synchronized: 假设A线程获得锁,B线程等待。如果A线程阻塞,B线程会一直等待
Lock: 分情况而定,Lock有多个锁获取的方式,大致就是可以尝试获得锁,线程可以不用一直等待(可以通过tryLock判断有没有锁)
- 锁的释放(死锁产生)
synchronized: 在发生异常时候会自动释放占有的锁,因此不会出现死锁
Lock: 发生异常时候,不会主动释放占有的锁,必须手动unlock来释放锁,可能引起死锁的发生
- 锁的状态
synchronized: 无法判断
Lock: 可以判断
- 锁的类型
synchronized: 可重入 不可中断 非公平
Lock: 可重入 可判断 可公平(两者皆可)
- 性能
synchronized: 少量同步
Lock: 大量同步
Lock可以提高多个线程进行读操作的效率。(可以通过readwritelock实现读写分离) 在资源竞争不是很激烈的情况下,Synchronized的性能要优于ReetrantLock,但是在资源竞争很激烈的情况下,Synchronized的性能会下降几十倍,但是ReetrantLock的性能能维持常态;
ReentrantLock提供了多样化的同步,比如有时间限制的同步,可以被Interrupt的同步(synchronized的同步是不能Interrupt的)等。在资源竞争不激烈的情形下,性能稍微比synchronized差点点。但是当同步非常激烈的时候,synchronized的性能一下子能下降好几十倍。而ReentrantLock确还能维持常态。
- 调度
synchronized: 使用Object对象本身的wait 、notify、notifyAll调度机制
Lock: 可以使用Condition进行线程之间的调度
- 用法
synchronized: 在需要同步的对象中加入此控制,synchronized可以加在方法上,也可以加在特定代码块中,括号中表示需要锁的对象。
Lock: 一般使用ReentrantLock类做为锁。在加锁和解锁处需要通过lock()和unlock()显示指出。所以一般会在finally块中写unlock()以防死锁。
- 底层实现
synchronized: 底层使用指令码方式来控制锁的,映射成字节码指令就是增加来两个指令:monitorenter和monitorexit。当线程执行遇到monitorenter指令时会尝试获取内置锁,如果获取锁则锁计数器+1,如果没有获取锁则阻塞;当遇到monitorexit指令时锁计数器-1,如果计数器为0则释放锁。
Lock: 底层是CAS乐观锁,依赖AbstractQueuedSynchronizer类,把所有的请求线程构成一个CLH队列。而对该队列的操作均通过Lock-Free(CAS)操作。
2.6、Synchronized在使用时有何注意事项?
- 锁对象不能为空,因为锁的信息都保存在对象头里
- 作用域不宜过大,影响程序执行的速度,控制范围过大,编写代码也容易出错
- 避免死锁
- 在能选择的情况下,既不要用Lock也不要用synchronized关键字,用java.util.concurrent包中的各种各样的类,如果不用该包下的类,在满足业务的情况下,可以使用synchronized关键,因为代码量少,避免出错
2.7、Synchronized修饰的方法在抛出异常时,会释放锁吗?
会
2.8、多个线程等待同一个Synchronized锁的时候,JVM如何选择下一个获取锁的线程?
非公平锁,即抢占式
2.9、synchronized是公平锁吗?
synchronized实际上是非公平的,新来的线程有可能立即获得监视器,而在等待区中等候已久的线程可能再次等待,这样有利于提高性能,但是也可能会导致饥饿现象。
2.10、volatile关键字的作用是什么?
- 防重排序 我们从一个最经典的例子来分析重排序问题。大家应该都很熟悉单例模式的实现,而在并发环境下的单例实现方式,我们通常可以采用双重检查加锁(DCL)的方式来实现。其源码如下:
public class Singleton {
public static volatile Singleton singleton;
/**
* 构造函数私有,禁止外部实例化
*/
private Singleton() {};
public static Singleton getInstance() {
if (singleton == null) {
synchronized (singleton.class) {
if (singleton == null) {
singleton = new Singleton();
}
}
}
return singleton;
}
}
现在我们分析一下为什么要在变量singleton之间加上volatile关键字。要理解这个问题,先要了解对象的构造过程,实例化一个对象其实可以分为三个步骤:
- 分配内存空间。
- 初始化对象。
- 将内存空间的地址赋值给对应的引用。
但是由于操作系统可以对指令进行重排序,所以上面的过程也可能会变成如下过程:
- 分配内存空间。
- 将内存空间的地址赋值给对应的引用。
- 初始化对象
如果是这个流程,多线程环境下就可能将一个未初始化的对象引用暴露出来,从而导致不可预料的结果。因此,为了防止这个过程的重排序,我们需要将变量设置为volatile类型的变量。
- 实现可见性
可见性问题主要指一个线程修改了共享变量值,而另一个线程却看不到。引起可见性问题的主要原因是每个线程拥有自己的一个高速缓存区——线程工作内存。volatile关键字能有效的解决这个问题,我们看下下面的例子,就可以知道其作用:
public class TestVolatile {
private static boolean stop = false;
public static void main(String[] args) {
// Thread-A
new Thread("Thread A") {
@Override
public void run() {
while (!stop) {
}
System.out.println(Thread.currentThread() + " stopped");
}
}.start();
// Thread-main
try {
TimeUnit.SECONDS.sleep(1);
System.out.println(Thread.currentThread() + " after 1 seconds");
} catch (InterruptedException e) {
e.printStackTrace();
}
stop = true;
}
}
执行输出如下
Thread[main,5,main] after 1 seconds
// Thread A一直在loop, 因为Thread A 由于可见性原因看不到Thread Main 已经修改stop的值
可以看到 Thread-main 休眠1秒之后,设置 stop = ture,但是Thread A根本没停下来,这就是可见性问题。如果通过在stop变量前面加上volatile关键字则会真正stop:
Thread[main,5,main] after 1 seconds
Thread[Thread A,5,main] stopped
Process finished with exit code 0
- 保证原子性:单次读/写
volatile不能保证完全的原子性,只能保证单次的读/写操作具有原子性。
2.11、volatile能保证原子性吗?
不能完全保证,只能保证单次的读/写操作具有原子性。
2.12、32位机器上共享的long和double变量的为什么要用volatile?
因为long和double两种数据类型的操作可分为高32位和低32位两部分,因此普通的long或double类型读/写可能不是原子的。因此,鼓励大家将共享的long和double变量设置为volatile类型,这样能保证任何情况下对long和double的单次读/写操作都具有原子性。
如下是JLS中的解释:
17.7 Non-Atomic Treatment of double and long
- For the purposes of the Java programming language memory model, a single write to a non-volatile long or double value is treated as two separate writes: one to each 32-bit half. This can result in a situation where a thread sees the first 32 bits of a 64-bit value from one write, and the second 32 bits from another write.
- Writes and reads of volatile long and double values are always atomic.
- Writes to and reads of references are always atomic, regardless of whether they are implemented as 32-bit or 64-bit values.
- Some implementations may find it convenient to divide a single write action on a 64-bit long or double value into two write actions on adjacent 32-bit values. For efficiency’s sake, this behavior is implementation-specific; an implementation of the Java Virtual Machine is free to perform writes to long and double values atomically or in two parts.
- Implementations of the Java Virtual Machine are encouraged to avoid splitting 64-bit values where possible. Programmers are encouraged to declare shared 64-bit values as volatile or synchronize their programs correctly to avoid possible complications.
目前各种平台下的商用虚拟机都选择把 64 位数据的读写操作作为原子操作来对待,因此我们在编写代码时一般不把long 和 double 变量专门声明为 volatile多数情况下也是不会错的。
2.13、volatile是如何实现可见性的?
内存屏障。
2.14、volatile是如何实现有序性的?
happens-before等
2.15、说下volatile的应用场景?
使用 volatile 必须具备的条件
- 对变量的写操作不依赖于当前值。
- 该变量没有包含在具有其他变量的不变式中。
- 只有在状态真正独立于程序内其他内容时才能使用 volatile。
- 例子 1: 单例模式
单例模式的一种实现方式,但很多人会忽略 volatile 关键字,因为没有该关键字,程序也可以很好的运行,只不过代码的稳定性总不是 100%,说不定在未来的某个时刻,隐藏的 bug 就出来了。
class Singleton {
private volatile static Singleton instance;
private Singleton() {
}
public static Singleton getInstance() {
if (instance == null) {
syschronized(Singleton.class) {
if (instance == null) {
instance = new Singleton();
}
}
}
return instance;
}
}
- 例子2: volatile bean
在 volatile bean 模式中,JavaBean 的所有数据成员都是 volatile 类型的,并且 getter 和 setter 方法必须非常普通 —— 除了获取或设置相应的属性外,不能包含任何逻辑。此外,对于对象引用的数据成员,引用的对象必须是有效不可变的。(这将禁止具有数组值的属性,因为当数组引用被声明为 volatile 时,只有引用而不是数组本身具有 volatile 语义)。对于任何 volatile 变量,不变式或约束都不能包含 JavaBean 属性。
@ThreadSafe
public class Person {
private volatile String firstName;
private volatile String lastName;
private volatile int age;
public String getFirstName() { return firstName; }
public String getLastName() { return lastName; }
public int getAge() { return age; }
public void setFirstName(String firstName) {
this.firstName = firstName;
}
public void setLastName(String lastName) {
this.lastName = lastName;
}
public void setAge(int age) {
this.age = age;
}
}
2.16、所有的final修饰的字段都是编译期常量吗?
不是
2.17、如何理解private所修饰的方法是隐式的final?
类中所有private方法都隐式地指定为final的,由于无法取用private方法,所以也就不能覆盖它。可以对private方法增添final关键字,但这样做并没有什么好处。看下下面的例子:
public class Base {
private void test() {
}
}
public class Son extends Base{
public void test() {
}
public static void main(String[] args) {
Son son = new Son();
Base father = son;
//father.test();
}
}
Base和Son都有方法test(),但是这并不是一种覆盖,因为private所修饰的方法是隐式的final,也就是无法被继承,所以更不用说是覆盖了,在Son中的test()方法不过是属于Son的新成员罢了,Son进行向上转型得到father,但是father.test()是不可执行的,因为Base中的test方法是private的,无法被访问到。
2.18、说说final类型的类如何拓展?
比如String是final类型,我们想写个MyString复用所有String中方法,同时增加一个新的toMyString()的方法,应该如何做?
外观模式:
/**
* @pdai
*/
class MyString{
private String innerString;
// ...init & other methods
// 支持老的方法
public int length(){
return innerString.length(); // 通过innerString调用老的方法
}
// 添加新方法
public String toMyString(){
//...
}
}
2.19、final方法可以被重载吗?
我们知道父类的final方法是不能够被子类重写的,那么final方法可以被重载吗? 答案是可以的,下面代码是正确的。
public class FinalExampleParent {
public final void test() {
}
public final void test(String str) {
}
}2.20、父类的final方法能不能够被子类重写?
不可以
2.21、说说基本类型的final域重排序规则?
先看一段示例性的代码:
public class FinalDemo {
private int a; //普通域
private final int b; //final域
private static FinalDemo finalDemo;
public FinalDemo() {
a = 1; // 1. 写普通域
b = 2; // 2. 写final域
}
public static void writer() {
finalDemo = new FinalDemo();
}
public static void reader() {
FinalDemo demo = finalDemo; // 3.读对象引用
int a = demo.a; //4.读普通域
int b = demo.b; //5.读final域
}
}
假设线程A在执行writer()方法,线程B执行reader()方法。
- 写final域重排序规则
写final域的重排序规则禁止对final域的写重排序到构造函数之外,这个规则的实现主要包含了两个方面:
- JMM禁止编译器把final域的写重排序到构造函数之外;
- 编译器会在final域写之后,构造函数return之前,插入一个storestore屏障。这个屏障可以禁止处理器把final域的写重排序到构造函数之外。
我们再来分析writer方法,虽然只有一行代码,但实际上做了两件事情:
- 构造了一个FinalDemo对象;
- 把这个对象赋值给成员变量finalDemo。
我们来画下存在的一种可能执行时序图,如下:
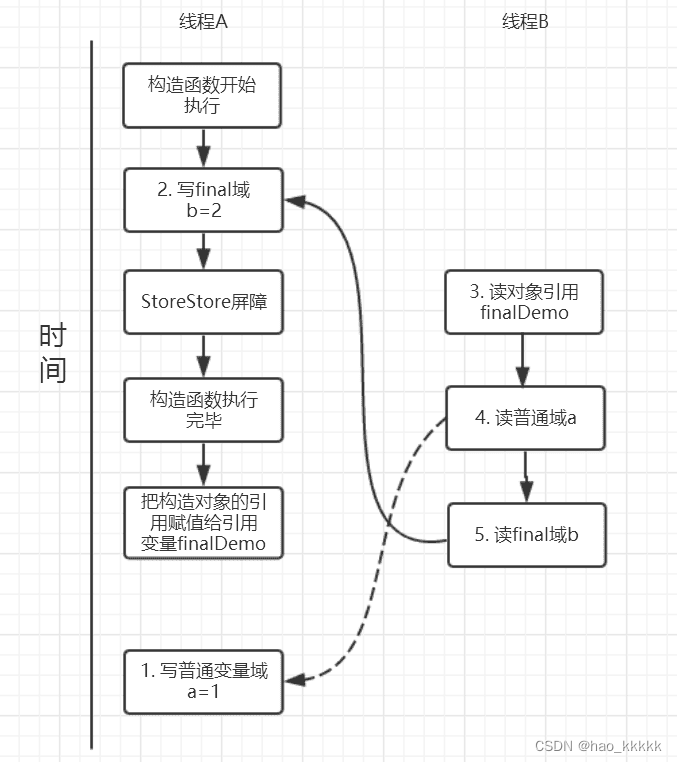
由于a,b之间没有数据依赖性,普通域(普通变量)a可能会被重排序到构造函数之外,线程B就有可能读到的是普通变量a初始化之前的值(零值),这样就可能出现错误。而final域变量b,根据重排序规则,会禁止final修饰的变量b重排序到构造函数之外,从而b能够正确赋值,线程B就能够读到final变量初始化后的值。
因此,写final域的重排序规则可以确保:在对象引用为任意线程可见之前,对象的final域已经被正确初始化过了,而普通域就不具有这个保障。比如在上例,线程B有可能就是一个未正确初始化的对象finalDemo。
- 读final域重排序规则
读final域重排序规则为:在一个线程中,初次读对象引用和初次读该对象包含的final域,JMM会禁止这两个操作的重排序。(注意,这个规则仅仅是针对处理器),处理器会在读final域操作的前面插入一个LoadLoad屏障。实际上,读对象的引用和读该对象的final域存在间接依赖性,一般处理器不会重排序这两个操作。但是有一些处理器会重排序,因此,这条禁止重排序规则就是针对这些处理器而设定的。
read()方法主要包含了三个操作:
- 初次读引用变量finalDemo;
- 初次读引用变量finalDemo的普通域a;
- 初次读引用变量finalDemo的final域b;
假设线程A写过程没有重排序,那么线程A和线程B有一种的可能执行时序为下图:

读对象的普通域被重排序到了读对象引用的前面就会出现线程B还未读到对象引用就在读取该对象的普通域变量,这显然是错误的操作。而final域的读操作就“限定”了在读final域变量前已经读到了该对象的引用,从而就可以避免这种情况。
读final域的重排序规则可以确保:在读一个对象的final域之前,一定会先读这个包含这个final域的对象的引用。
2.22、说说final的原理?
- 写final域会要求编译器在final域写之后,构造函数返回前插入一个StoreStore屏障。
- 读final域的重排序规则会要求编译器在读final域的操作前插入一个LoadLoad屏障。
PS:很有意思的是,如果以X86处理为例,X86不会对写-写重排序,所以StoreStore屏障可以省略。由于不会对有间接依赖性的操作重排序,所以在X86处理器中,读final域需要的LoadLoad屏障也会被省略掉。也就是说,以X86为例的话,对final域的读/写的内存屏障都会被省略!具体是否插入还是得看是什么处理器。
3、JUC全局观
3.1、JUC框架包含几个部分?
五个部分:
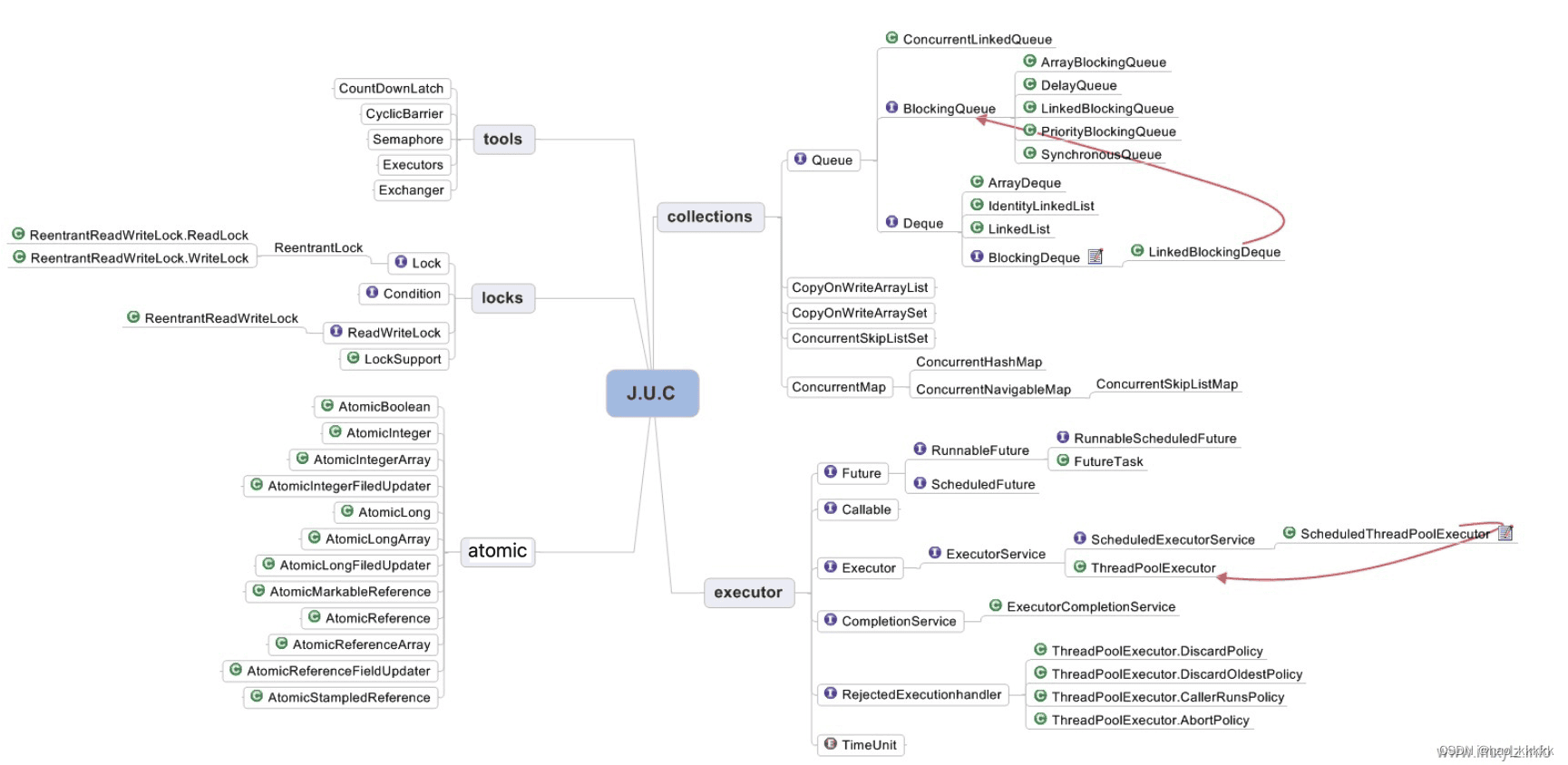
主要包含: (注意: 上图是网上找的图,无法表述一些继承关系,同时少了部分类;但是主体上可以看出其分类关系也够了)
- Lock框架和Tools类(把图中这两个放到一起理解)
- Collections: 并发集合
- Atomic: 原子类
- Executors: 线程池
3.2、Lock框架和Tools哪些核心的类?

- 接口: Condition, Condition为接口类型,它将 Object 监视器方法(wait、notify 和 notifyAll)分解成截然不同的对象,以便通过将这些对象与任意 Lock 实现组合使用,为每个对象提供多个等待 set (wait-set)。其中,Lock 替代了 synchronized 方法和语句的使用,Condition 替代了 Object 监视器方法的使用。可以通过await(),signal()来休眠/唤醒线程。
- 接口: Lock,Lock为接口类型,Lock实现提供了比使用synchronized方法和语句可获得的更广泛的锁定操作。此实现允许更灵活的结构,可以具有差别很大的属性,可以支持多个相关的Condition对象。
- 接口ReadWriteLock ReadWriteLock为接口类型, 维护了一对相关的锁,一个用于只读操作,另一个用于写入操作。只要没有 writer,读取锁可以由多个 reader 线程同时保持。写入锁是独占的。
- 抽象类: AbstractOwnableSynchonizer AbstractOwnableSynchonizer为抽象类,可以由线程以独占方式拥有的同步器。此类为创建锁和相关同步器(伴随着所有权的概念)提供了基础。AbstractOwnableSynchronizer 类本身不管理或使用此信息。但是,子类和工具可以使用适当维护的值帮助控制和监视访问以及提供诊断。
- 抽象类(long): AbstractQueuedLongSynchronizer AbstractQueuedLongSynchronizer为抽象类,以 long 形式维护同步状态的一个 AbstractQueuedSynchronizer 版本。此类具有的结构、属性和方法与 AbstractQueuedSynchronizer 完全相同,但所有与状态相关的参数和结果都定义为 long 而不是 int。当创建需要 64 位状态的多级别锁和屏障等同步器时,此类很有用。
- 核心抽象类(int): AbstractQueuedSynchronizer AbstractQueuedSynchronizer为抽象类,其为实现依赖于先进先出 (FIFO) 等待队列的阻塞锁和相关同步器(信号量、事件,等等)提供一个框架。此类的设计目标是成为依靠单个原子 int 值来表示状态的大多数同步器的一个有用基础。
- 锁常用类: LockSupport LockSupport为常用类,用来创建锁和其他同步类的基本线程阻塞原语。LockSupport的功能和"Thread中的 Thread.suspend()和Thread.resume()有点类似",LockSupport中的park() 和 unpark() 的作用分别是阻塞线程和解除阻塞线程。但是park()和unpark()不会遇到“Thread.suspend 和 Thread.resume所可能引发的死锁”问题。
- 锁常用类: ReentrantLock ReentrantLock为常用类,它是一个可重入的互斥锁 Lock,它具有与使用 synchronized 方法和语句所访问的隐式监视器锁相同的一些基本行为和语义,但功能更强大。
- 锁常用类: ReentrantReadWriteLock ReentrantReadWriteLock是读写锁接口ReadWriteLock的实现类,它包括Lock子类ReadLock和WriteLock。ReadLock是共享锁,WriteLock是独占锁。
- 锁常用类: StampedLock 它是java8在java.util.concurrent.locks新增的一个API。StampedLock控制锁有三种模式(写,读,乐观读),一个StampedLock状态是由版本和模式两个部分组成,锁获取方法返回一个数字作为票据stamp,它用相应的锁状态表示并控制访问,数字0表示没有写锁被授权访问。在读锁上分为悲观锁和乐观锁。
- 工具常用类: CountDownLatch CountDownLatch为常用类,它是一个同步辅助类,在完成一组正在其他线程中执行的操作之前,它允许一个或多个线程一直等待。
- 工具常用类: CyclicBarrier CyclicBarrier为常用类,其是一个同步辅助类,它允许一组线程互相等待,直到到达某个公共屏障点 (common barrier point)。在涉及一组固定大小的线程的程序中,这些线程必须不时地互相等待,此时 CyclicBarrier 很有用。因为该 barrier 在释放等待线程后可以重用,所以称它为循环 的 barrier。
- 工具常用类: Phaser Phaser是JDK 7新增的一个同步辅助类,它可以实现CyclicBarrier和CountDownLatch类似的功能,而且它支持对任务的动态调整,并支持分层结构来达到更高的吞吐量。
- 工具常用类: Semaphore Semaphore为常用类,其是一个计数信号量,从概念上讲,信号量维护了一个许可集。如有必要,在许可可用前会阻塞每一个 acquire(),然后再获取该许可。每个 release() 添加一个许可,从而可能释放一个正在阻塞的获取者。但是,不使用实际的许可对象,Semaphore 只对可用许可的号码进行计数,并采取相应的行动。通常用于限制可以访问某些资源(物理或逻辑的)的线程数目。
- 工具常用类: Exchanger Exchanger是用于线程协作的工具类, 主要用于两个线程之间的数据交换。它提供一个同步点,在这个同步点,两个线程可以交换彼此的数据。这两个线程通过exchange()方法交换数据,当一个线程先执行exchange()方法后,它会一直等待第二个线程也执行exchange()方法,当这两个线程到达同步点时,这两个线程就可以交换数据了。
3.3、JUC并发集合哪些核心的类?
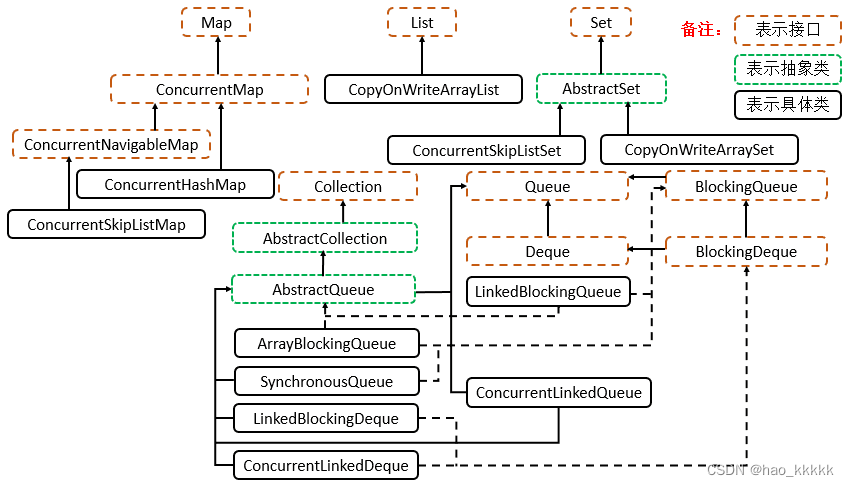
- Queue: ArrayBlockingQueue 一个由数组支持的有界阻塞队列。此队列按 FIFO(先进先出)原则对元素进行排序。队列的头部 是在队列中存在时间最长的元素。队列的尾部 是在队列中存在时间最短的元素。新元素插入到队列的尾部,队列获取操作则是从队列头部开始获得元素。
- Queue: LinkedBlockingQueue 一个基于已链接节点的、范围任意的 blocking queue。此队列按 FIFO(先进先出)排序元素。队列的头部 是在队列中时间最长的元素。队列的尾部 是在队列中时间最短的元素。新元素插入到队列的尾部,并且队列获取操作会获得位于队列头部的元素。链接队列的吞吐量通常要高于基于数组的队列,但是在大多数并发应用程序中,其可预知的性能要低。
- Queue: LinkedBlockingDeque 一个基于已链接节点的、任选范围的阻塞双端队列。
- Queue: ConcurrentLinkedQueue 一个基于链接节点的无界线程安全队列。此队列按照 FIFO(先进先出)原则对元素进行排序。队列的头部 是队列中时间最长的元素。队列的尾部 是队列中时间最短的元素。新的元素插入到队列的尾部,队列获取操作从队列头部获得元素。当多个线程共享访问一个公共 collection 时,ConcurrentLinkedQueue 是一个恰当的选择。此队列不允许使用 null 元素。
- Queue: ConcurrentLinkedDeque 是双向链表实现的无界队列,该队列同时支持FIFO和FILO两种操作方式。
- Queue: DelayQueue 延时无界阻塞队列,使用Lock机制实现并发访问。队列里只允许放可以“延期”的元素,队列中的head是最先“到期”的元素。如果队里中没有元素到“到期”,那么就算队列中有元素也不能获取到。
- Queue: PriorityBlockingQueue 无界优先级阻塞队列,使用Lock机制实现并发访问。priorityQueue的线程安全版,不允许存放null值,依赖于comparable的排序,不允许存放不可比较的对象类型。
- Queue: SynchronousQueue 没有容量的同步队列,通过CAS实现并发访问,支持FIFO和FILO。
- Queue: LinkedTransferQueue JDK 7新增,单向链表实现的无界阻塞队列,通过CAS实现并发访问,队列元素使用 FIFO(先进先出)方式。LinkedTransferQueue可以说是ConcurrentLinkedQueue、SynchronousQueue(公平模式)和LinkedBlockingQueue的超集, 它不仅仅综合了这几个类的功能,同时也提供了更高效的实现。
- List: CopyOnWriteArrayList ArrayList 的一个线程安全的变体,其中所有可变操作(add、set 等等)都是通过对底层数组进行一次新的复制来实现的。这一般需要很大的开销,但是当遍历操作的数量大大超过可变操作的数量时,这种方法可能比其他替代方法更 有效。在不能或不想进行同步遍历,但又需要从并发线程中排除冲突时,它也很有用。
- Set: CopyOnWriteArraySet 对其所有操作使用内部CopyOnWriteArrayList的Set。即将所有操作转发至CopyOnWriteArayList来进行操作,能够保证线程安全。在add时,会调用addIfAbsent,由于每次add时都要进行数组遍历,因此性能会略低于CopyOnWriteArrayList。
- Set: ConcurrentSkipListSet 一个基于ConcurrentSkipListMap 的可缩放并发 NavigableSet 实现。set 的元素可以根据它们的自然顺序进行排序,也可以根据创建 set 时所提供的 Comparator 进行排序,具体取决于使用的构造方法。
- Map: ConcurrentHashMap 是线程安全HashMap的。ConcurrentHashMap在JDK 7之前是通过Lock和segment(分段锁)实现,JDK 8 之后改为CAS+synchronized来保证并发安全。
- Map: ConcurrentSkipListMap 线程安全的有序的哈希表(相当于线程安全的TreeMap);映射可以根据键的自然顺序进行排序,也可以根据创建映射时所提供的 Comparator 进行排序,具体取决于使用的构造方法。
3.4、JUC原子类哪些核心的类?
其基本的特性就是在多线程环境下,当有多个线程同时执行这些类的实例包含的方法时,具有排他性,即当某个线程进入方法,执行其中的指令时,不会被其他线程打断,而别的线程就像自旋锁一样,一直等到该方法执行完成,才由JVM从等待队列中选择一个另一个线程进入,这只是一种逻辑上的理解。实际上是借助硬件的相关指令来实现的,不会阻塞线程(或者说只是在硬件级别上阻塞了)。
- 原子更新基本类型
- AtomicBoolean: 原子更新布尔类型。
- AtomicInteger: 原子更新整型。
- AtomicLong: 原子更新长整型。
- 原子更新数组
- AtomicIntegerArray: 原子更新整型数组里的元素。
- AtomicLongArray: 原子更新长整型数组里的元素。
- AtomicReferenceArray: 原子更新引用类型数组里的元素。
- 原子更新引用类型
- AtomicIntegerFieldUpdater: 原子更新整型的字段的更新器。
- AtomicLongFieldUpdater: 原子更新长整型字段的更新器。
- AtomicStampedFieldUpdater: 原子更新带有版本号的引用类型。
- AtomicReferenceFieldUpdater: 上面已经说过此处不在赘述
- 原子更新字段类
- AtomicReference: 原子更新引用类型。
- AtomicStampedReference: 原子更新引用类型, 内部使用Pair来存储元素值及其版本号。
- AtomicMarkableReferce: 原子更新带有标记位的引用类型。
3.5、JUC线程池哪些核心的类?
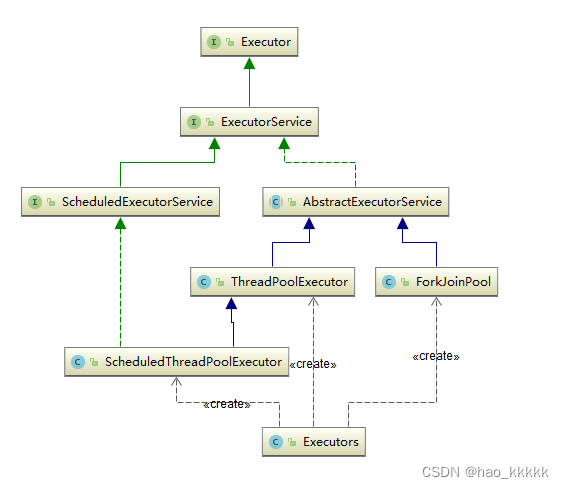
- 接口: Executor Executor接口提供一种将任务提交与每个任务将如何运行的机制(包括线程使用的细节、调度等)分离开来的方法。通常使用 Executor 而不是显式地创建线程。
- ExecutorService ExecutorService继承自Executor接口,ExecutorService提供了管理终止的方法,以及可为跟踪一个或多个异步任务执行状况而生成 Future 的方法。 可以关闭 ExecutorService,这将导致其停止接受新任务。关闭后,执行程序将最后终止,这时没有任务在执行,也没有任务在等待执行,并且无法提交新任务。
- ScheduledExecutorService ScheduledExecutorService继承自ExecutorService接口,可安排在给定的延迟后运行或定期执行的命令。
- AbstractExecutorService AbstractExecutorService继承自ExecutorService接口,其提供 ExecutorService 执行方法的默认实现。此类使用 newTaskFor 返回的 RunnableFuture 实现 submit、invokeAny 和 invokeAll 方法,默认情况下,RunnableFuture 是此包中提供的 FutureTask 类。
- FutureTask FutureTask 为 Future 提供了基础实现,如获取任务执行结果(get)和取消任务(cancel)等。如果任务尚未完成,获取任务执行结果时将会阻塞。一旦执行结束,任务就不能被重启或取消(除非使用runAndReset执行计算)。FutureTask 常用来封装 Callable 和 Runnable,也可以作为一个任务提交到线程池中执行。除了作为一个独立的类之外,此类也提供了一些功能性函数供我们创建自定义 task 类使用。FutureTask 的线程安全由CAS来保证。
- 核心: ThreadPoolExecutor ThreadPoolExecutor实现了AbstractExecutorService接口,也是一个 ExecutorService,它使用可能的几个池线程之一执行每个提交的任务,通常使用 Executors 工厂方法配置。 线程池可以解决两个不同问题: 由于减少了每个任务调用的开销,它们通常可以在执行大量异步任务时提供增强的性能,并且还可以提供绑定和管理资源(包括执行任务集时使用的线程)的方法。每个 ThreadPoolExecutor 还维护着一些基本的统计数据,如完成的任务数。
- 核心: ScheduledThreadExecutor ScheduledThreadPoolExecutor实现ScheduledExecutorService接口,可安排在给定的延迟后运行命令,或者定期执行命令。需要多个辅助线程时,或者要求 ThreadPoolExecutor 具有额外的灵活性或功能时,此类要优于 Timer。
- 核心: Fork/Join框架 ForkJoinPool 是JDK 7加入的一个线程池类。Fork/Join 技术是分治算法(Divide-and-Conquer)的并行实现,它是一项可以获得良好的并行性能的简单且高效的设计技术。目的是为了帮助我们更好地利用多处理器带来的好处,使用所有可用的运算能力来提升应用的性能。
- 工具类: Executors Executors是一个工具类,用其可以创建ExecutorService、ScheduledExecutorService、ThreadFactory、Callable等对象。它的使用融入到了ThreadPoolExecutor, ScheduledThreadExecutor和ForkJoinPool中。
4、JUC原子类
4.1、线程安全的实现方法有哪些?
线程安全的实现方法包含:
- 互斥同步: synchronized 和 ReentrantLock
- 非阻塞同步: CAS, AtomicXXXX
- 无同步方案: 栈封闭,Thread Local,可重入代码
4.2、什么是CAS?
CAS的全称为Compare-And-Swap,直译就是对比交换。是一条CPU的原子指令,其作用是让CPU先进行比较两个值是否相等,然后原子地更新某个位置的值,经过调查发现,其实现方式是基于硬件平台的汇编指令,就是说CAS是靠硬件实现的,JVM只是封装了汇编调用,那些AtomicInteger类便是使用了这些封装后的接口。 简单解释:CAS操作需要输入两个数值,一个旧值(期望操作前的值)和一个新值,在操作期间先比较下在旧值有没有发生变化,如果没有发生变化,才交换成新值,发生了变化则不交换。
CAS操作是原子性的,所以多线程并发使用CAS更新数据时,可以不使用锁。JDK中大量使用了CAS来更新数据而防止加锁(synchronized 重量级锁)来保持原子更新。
相信sql大家都熟悉,类似sql中的条件更新一样:update set id=3 from table where id=2。因为单条sql执行具有原子性,如果有多个线程同时执行此sql语句,只有一条能更新成功。
4.3、CAS使用示例,结合AtomicInteger给出示例?
如果不使用CAS,在高并发下,多线程同时修改一个变量的值我们需要synchronized加锁(可能有人说可以用Lock加锁,Lock底层的AQS也是基于CAS进行获取锁的)。
public class Test {
private int i=0;
public synchronized int add(){
return i++;
}
}
java中为我们提供了AtomicInteger 原子类(底层基于CAS进行更新数据的),不需要加锁就在多线程并发场景下实现数据的一致性。
public class Test {
private AtomicInteger i = new AtomicInteger(0);
public int add(){
return i.addAndGet(1);
}
}
4.4、CAS会有哪些问题?
CAS 方式为乐观锁,synchronized 为悲观锁。因此使用 CAS 解决并发问题通常情况下性能更优。
但使用 CAS 方式也会有几个问题:
- ABA问题
因为CAS需要在操作值的时候,检查值有没有发生变化,比如没有发生变化则更新,但是如果一个值原来是A,变成了B,又变成了A,那么使用CAS进行检查时则会发现它的值没有发生变化,但是实际上却变化了。
ABA问题的解决思路就是使用版本号。在变量前面追加上版本号,每次变量更新的时候把版本号加1,那么A->B->A就会变成1A->2B->3A。
从Java 1.5开始,JDK的Atomic包里提供了一个类AtomicStampedReference来解决ABA问题。这个类的compareAndSet方法的作用是首先检查当前引用是否等于预期引用,并且检查当前标志是否等于预期标志,如果全部相等,则以原子方式将该引用和该标志的值设置为给定的更新值。
- 循环时间长开销大
自旋CAS如果长时间不成功,会给CPU带来非常大的执行开销。如果JVM能支持处理器提供的pause指令,那么效率会有一定的提升。pause指令有两个作用:第一,它可以延迟流水线执行命令(de-pipeline),使CPU不会消耗过多的执行资源,延迟的时间取决于具体实现的版本,在一些处理器上延迟时间是零;第二,它可以避免在退出循环的时候因内存顺序冲突(Memory Order Violation)而引起CPU流水线被清空(CPU Pipeline Flush),从而提高CPU的执行效率。
- 只能保证一个共享变量的原子操作
当对一个共享变量执行操作时,我们可以使用循环CAS的方式来保证原子操作,但是对多个共享变量操作时,循环CAS就无法保证操作的原子性,这个时候就可以用锁。
还有一个取巧的办法,就是把多个共享变量合并成一个共享变量来操作。比如,有两个共享变量i = 2,j = a,合并一下ij = 2a,然后用CAS来操作ij。
从Java 1.5开始,JDK提供了AtomicReference类来保证引用对象之间的原子性,就可以把多个变量放在一个对象里来进行CAS操作。
4.5、AtomicInteger底层实现?
- CAS+volatile
- volatile保证线程的可见性,多线程并发时,一个线程修改数据,可以保证其它线程立马看到修改后的值CAS 保证数据更新的原子性。
4.6、请阐述你对Unsafe类的理解?
UnSafe类总体功能:
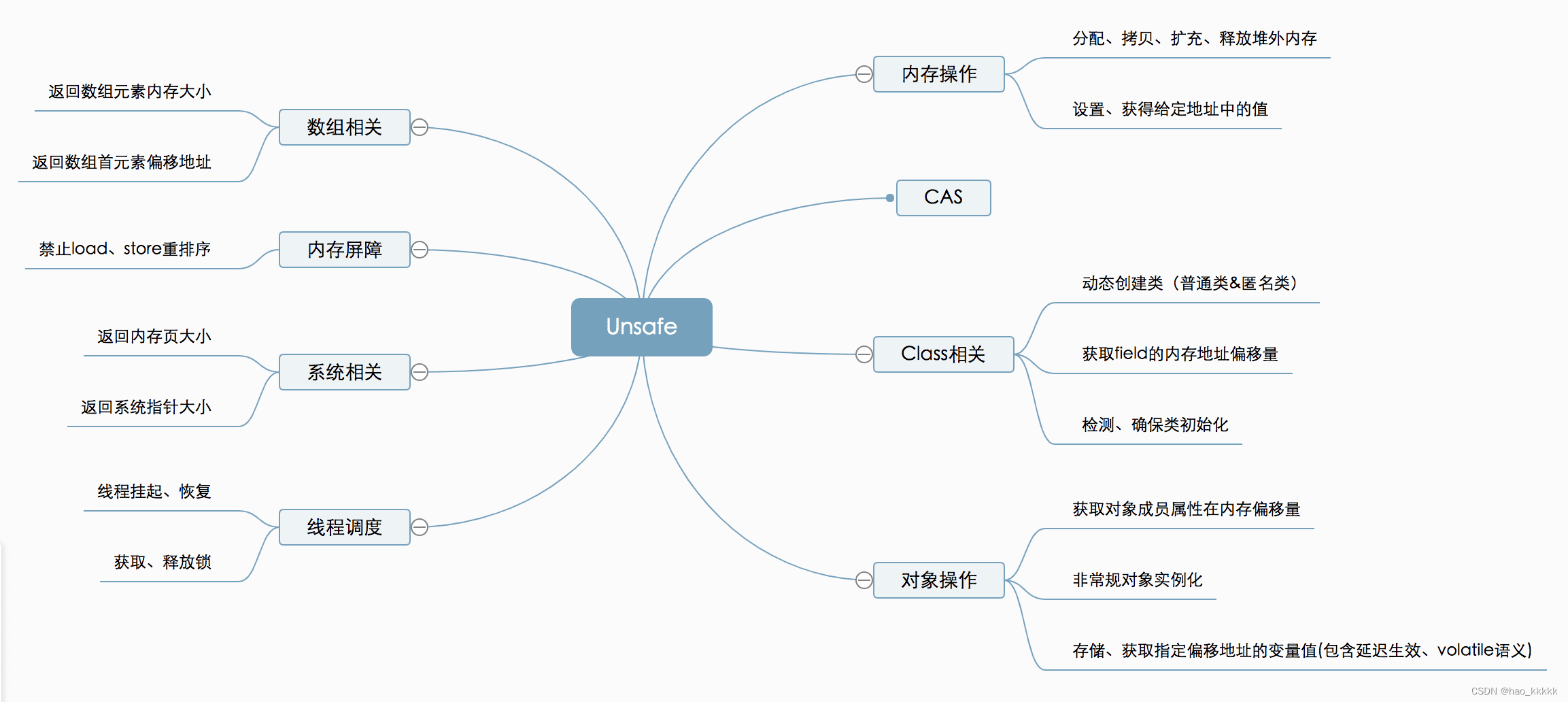
如上图所示,Unsafe提供的API大致可分为内存操作、CAS、Class相关、对象操作、线程调度、系统信息获取、内存屏障、数组操作等几类,下面将对其相关方法和应用场景进行详细介绍。
4.7、说说你对Java原子类的理解?
包含13个,4组分类,说说作用和使用场景。
- 原子更新基本类型
- AtomicBoolean: 原子更新布尔类型。
- AtomicInteger: 原子更新整型。
- AtomicLong: 原子更新长整型。
- 原子更新数组
- AtomicIntegerArray: 原子更新整型数组里的元素。
- AtomicLongArray: 原子更新长整型数组里的元素。
- AtomicReferenceArray: 原子更新引用类型数组里的元素。
- 原子更新引用类型
- AtomicIntegerFieldUpdater: 原子更新整型的字段的更新器。
- AtomicLongFieldUpdater: 原子更新长整型字段的更新器。
- AtomicStampedFieldUpdater: 原子更新带有版本号的引用类型。
- AtomicReferenceFieldUpdater: 上面已经说过此处不在赘述
- 原子更新字段类
- AtomicReference: 原子更新引用类型。
- AtomicStampedReference: 原子更新引用类型, 内部使用Pair来存储元素值及其版本号。
- AtomicMarkableReferce: 原子更新带有标记位的引用类型。
4.8、AtomicStampedReference是怎么解决ABA的?
AtomicStampedReference主要维护包含一个对象引用以及一个可以自动更新的整数"stamp"的pair对象来解决ABA问题。
5、 JUC锁
5.1、为什么LockSupport也是核心基础类?
AQS框架借助于两个类:Unsafe(提供CAS操作)和LockSupport(提供park/unpark操作)
5.2、通过wait/notify实现同步?
class MyThread extends Thread {
public void run() {
synchronized (this) {
System.out.println("before notify");
notify();
System.out.println("after notify");
}
}
}
public class WaitAndNotifyDemo {
public static void main(String[] args) throws InterruptedException {
MyThread myThread = new MyThread();
synchronized (myThread) {
try {
myThread.start();
// 主线程睡眠3s
Thread.sleep(3000);
System.out.println("before wait");
// 阻塞主线程
myThread.wait();
System.out.println("after wait");
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
运行结果
before wait
before notify
after notify
after wait
说明: 具体的流程图如下
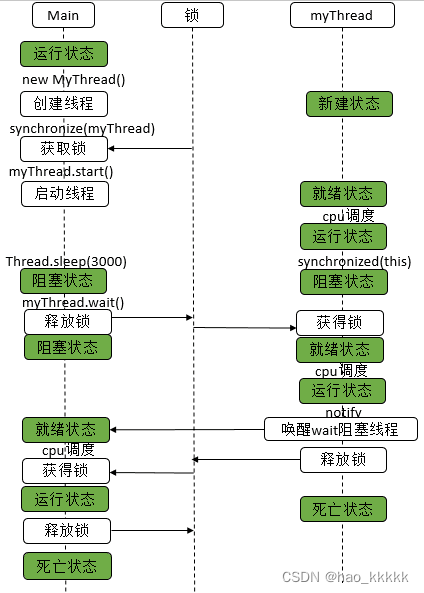
使用wait/notify实现同步时,必须先调用wait,后调用notify,如果先调用notify,再调用wait,将起不了作用。具体代码如下
class MyThread extends Thread {
public void run() {
synchronized (this) {
System.out.println("before notify");
notify();
System.out.println("after notify");
}
}
}
public class WaitAndNotifyDemo {
public static void main(String[] args) throws InterruptedException {
MyThread myThread = new MyThread();
myThread.start();
// 主线程睡眠3s
Thread.sleep(3000);
synchronized (myThread) {
try {
System.out.println("before wait");
// 阻塞主线程
myThread.wait();
System.out.println("after wait");
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
运行结果:
before notify
after notify
before wait
说明: 由于先调用了notify,再调用的wait,此时主线程还是会一直阻塞。
5.3、通过LockSupport的park/unpark实现同步?
import java.util.concurrent.locks.LockSupport;
class MyThread extends Thread {
private Object object;
public MyThread(Object object) {
this.object = object;
}
public void run() {
System.out.println("before unpark");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
// 获取blocker
System.out.println("Blocker info " + LockSupport.getBlocker((Thread) object));
// 释放许可
LockSupport.unpark((Thread) object);
// 休眠500ms,保证先执行park中的setBlocker(t, null);
try {
Thread.sleep(500);
} catch (InterruptedException e) {
e.printStackTrace();
}
// 再次获取blocker
System.out.println("Blocker info " + LockSupport.getBlocker((Thread) object));
System.out.println("after unpark");
}
}
public class test {
public static void main(String[] args) {
MyThread myThread = new MyThread(Thread.currentThread());
myThread.start();
System.out.println("before park");
// 获取许可
LockSupport.park("ParkAndUnparkDemo");
System.out.println("after park");
}
}
运行结果:
before park
before unpark
Blocker info ParkAndUnparkDemo
after park
Blocker info null
after unpark
说明: 本程序先执行park,然后在执行unpark,进行同步,并且在unpark的前后都调用了getBlocker,可以看到两次的结果不一样,并且第二次调用的结果为null,这是因为在调用unpark之后,执行了Lock.park(Object blocker)函数中的setBlocker(t, null)函数,所以第二次调用getBlocker时为null。
上例是先调用park,然后调用unpark,现在修改程序,先调用unpark,然后调用park,看能不能正确同步。具体代码如下
import java.util.concurrent.locks.LockSupport;
class MyThread extends Thread {
private Object object;
public MyThread(Object object) {
this.object = object;
}
public void run() {
System.out.println("before unpark");
// 释放许可
LockSupport.unpark((Thread) object);
System.out.println("after unpark");
}
}
public class ParkAndUnparkDemo {
public static void main(String[] args) {
MyThread myThread = new MyThread(Thread.currentThread());
myThread.start();
try {
// 主线程睡眠3s
Thread.sleep(3000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("before park");
// 获取许可
LockSupport.park("ParkAndUnparkDemo");
System.out.println("after park");
}
}
运行结果:
before unpark
after unpark
before park
after park
说明: 可以看到,在先调用unpark,再调用park时,仍能够正确实现同步,不会造成由wait/notify调用顺序不当所引起的阻塞。因此park/unpark相比wait/notify更加的灵活。
5.4、Thread.sleep()、Object.wait()、Condition.await()、LockSupport.park()的区别? 重点
- Thread.sleep()和Object.wait()的区别
首先,我们先来看看Thread.sleep()和Object.wait()的区别,这是一个烂大街的题目了,大家应该都能说上来两点。
- Thread.sleep()不会释放占有的锁,Object.wait()会释放占有的锁;
- Thread.sleep()必须传入时间,Object.wait()可传可不传,不传表示一直阻塞下去;
- Thread.sleep()到时间了会自动唤醒,然后继续执行;
- Object.wait()不带时间的,需要另一个线程使用Object.notify()唤醒;
- Object.wait()带时间的,假如没有被notify,到时间了会自动唤醒,这时又分好两种情况,一是立即获取到了锁,线程自然会继续执行;二是没有立即获取锁,线程进入同步队列等待获取锁;
其实,他们俩最大的区别就是Thread.sleep()不会释放锁资源,Object.wait()会释放锁资源。
- Object.wait()和Condition.await()的区别
Object.wait()和Condition.await()的原理是基本一致的,不同的是Condition.await()底层是调用LockSupport.park()来实现阻塞当前线程的。
实际上,它在阻塞当前线程之前还干了两件事,一是把当前线程添加到条件队列中,二是“完全”释放锁,也就是让state状态变量变为0,然后才是调用LockSupport.park()阻塞当前线程。
- Thread.sleep()和LockSupport.park()的区别 LockSupport.park()还有几个兄弟方法——parkNanos()、parkUtil()等,我们这里说的park()方法统称这一类方法。
- 从功能上来说,Thread.sleep()和LockSupport.park()方法类似,都是阻塞当前线程的执行,且都不会释放当前线程占有的锁资源;
- Thread.sleep()没法从外部唤醒,只能自己醒过来;
- LockSupport.park()方法可以被另一个线程调用LockSupport.unpark()方法唤醒;
- Thread.sleep()方法声明上抛出了InterruptedException中断异常,所以调用者需要捕获这个异常或者再抛出;
- LockSupport.park()方法不需要捕获中断异常;
- Thread.sleep()本身就是一个native方法;
- LockSupport.park()底层是调用的Unsafe的native方法;
- Object.wait()和LockSupport.park()的区别
二者都会阻塞当前线程的运行,他们有什么区别呢? 经过上面的分析相信你一定很清楚了,真的吗? 往下看!
- Object.wait()方法需要在synchronized块中执行;
- LockSupport.park()可以在任意地方执行;
- Object.wait()方法声明抛出了中断异常,调用者需要捕获或者再抛出;
- LockSupport.park()不需要捕获中断异常;
- Object.wait()不带超时的,需要另一个线程执行notify()来唤醒,但不一定继续执行后续内容;
- LockSupport.park()不带超时的,需要另一个线程执行unpark()来唤醒,一定会继续执行后续内容;
park()/unpark()底层的原理是“二元信号量”,你可以把它相像成只有一个许可证的Semaphore,只不过这个信号量在重复执行unpark()的时候也不会再增加许可证,最多只有一个许可证。
5.5、如果在wait()之前执行了notify()会怎样?
如果当前的线程不是此对象锁的所有者,却调用该对象的notify()或wait()方法时抛出IllegalMonitorStateException异常;
如果当前线程是此对象锁的所有者,wait()将一直阻塞,因为后续将没有其它notify()唤醒它。
5.6、如果在park()之前执行了unpark()会怎样?
线程不会被阻塞,直接跳过park(),继续执行后续内容
5.7、什么是AQS? 为什么它是核心?
AQS是一个用来构建锁和同步器的框架,使用AQS能简单且高效地构造出应用广泛的大量的同步器,比如我们提到的ReentrantLock,Semaphore,其他的诸如ReentrantReadWriteLock,SynchronousQueue,FutureTask等等皆是基于AQS的。
AQS核心思想是,如果被请求的共享资源空闲,则将当前请求资源的线程设置为有效的工作线程,并且将共享资源设置为锁定状态。如果被请求的共享资源被占用,那么就需要一套线程阻塞等待以及被唤醒时锁分配的机制,这个机制AQS是用CLH队列锁实现的,即将暂时获取不到锁的线程加入到队列中。
AbstractQueuedSynchronizer类底层的数据结构是使用CLH(Craig,Landin,and Hagersten)队列是一个虚拟的双向队列(虚拟的双向队列即不存在队列实例,仅存在结点之间的关联关系)。AQS是将每条请求共享资源的线程封装成一个CLH锁队列的一个结点(Node)来实现锁的分配。其中Sync queue,即同步队列,是双向链表,包括head结点和tail结点,head结点主要用作后续的调度。而Condition queue不是必须的,其是一个单向链表,只有当使用Condition时,才会存在此单向链表。并且可能会有多个Condition queue。
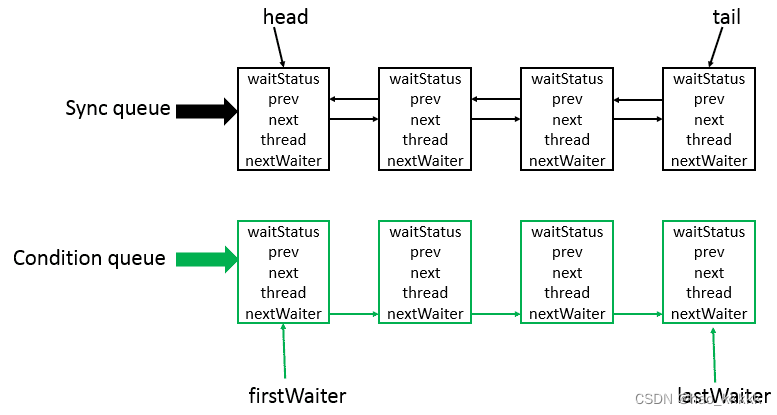
5.8、AQS的核心思想是什么?
底层数据结构: AQS核心思想是,如果被请求的共享资源空闲,则将当前请求资源的线程设置为有效的工作线程,并且将共享资源设置为锁定状态。如果被请求的共享资源被占用,那么就需要一套线程阻塞等待以及被唤醒时锁分配的机制,这个机制AQS是用CLH队列锁实现的,即将暂时获取不到锁的线程加入到队列中。
5.9、AQS有哪些核心的方法?
isHeldExclusively()//该线程是否正在独占资源。只有用到condition才需要去实现它。
tryAcquire(int)//独占方式。尝试获取资源,成功则返回true,失败则返回false。
tryRelease(int)//独占方式。尝试释放资源,成功则返回true,失败则返回false。
tryAcquireShared(int)//共享方式。尝试获取资源。负数表示失败;0表示成功,但没有剩余可用资源;正数表示成功,且有剩余资源。
tryReleaseShared(int)//共享方式。尝试释放资源,成功则返回true,失败则返回false。5.10、AQS定义什么样的资源获取方式?
AQS定义了两种资源获取方式:
- 独占(只有一个线程能访问执行,又根据是否按队列的顺序分为公平锁和非公平锁,如
ReentrantLock) - 共享(多个线程可同时访问执行,如
Semaphore、CountDownLatch、CyclicBarrier)。ReentrantReadWriteLock可以看成是组合式,允许多个线程同时对某一资源进行读。
5.11、AQS底层使用了什么样的设计模式?
模板, 共享锁和独占锁在一个接口类中。
- JUC锁: ReentrantLock详解
5.12、什么是可重入,什么是可重入锁? 它用来解决什么问题?
可重入:(来源于维基百科)若一个程序或子程序可以“在任意时刻被中断然后操作系统调度执行另外一段代码,这段代码又调用了该子程序不会出错”,则称其为可重入(reentrant或re-entrant)的。即当该子程序正在运行时,执行线程可以再次进入并执行它,仍然获得符合设计时预期的结果。与多线程并发执行的线程安全不同,可重入强调对单个线程执行时重新进入同一个子程序仍然是安全的。
可重入锁:又名递归锁,是指在同一个线程在外层方法获取锁的时候,再进入该线程的内层方法会自动获取锁(前提锁对象得是同一个对象或者class),不会因为之前已经获取过还没释放而阻塞。
5.13、ReentrantLock的核心是AQS,那么它怎么来实现的,继承吗?
ReentrantLock总共有三个内部类,并且三个内部类是紧密相关的,下面先看三个类的关系。
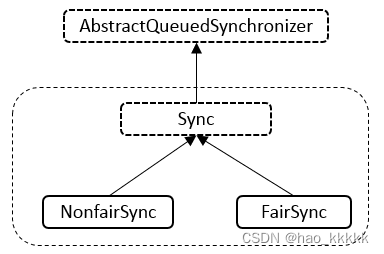
说明: ReentrantLock类内部总共存在Sync、NonfairSync、FairSync三个类,NonfairSync与FairSync类继承自Sync类,Sync类继承自AbstractQueuedSynchronizer抽象类。下面逐个进行分析。
5.14、ReentrantLock是如何实现公平锁的?
FairSync
5.15、ReentrantLock是如何实现非公平锁的?
UnFairSync
5.16、ReentrantLock默认实现的是公平还是非公平锁?
非公平锁
5.17、为了有了ReentrantLock还需要ReentrantReadWriteLock?
读锁和写锁分离:ReentrantReadWriteLock表示可重入读写锁,ReentrantReadWriteLock中包含了两种锁,读锁ReadLock和写锁WriteLock,可以通过这两种锁实现线程间的同步。
5.18、ReentrantReadWriteLock底层实现原理?
ReentrantReadWriteLock有五个内部类,五个内部类之间也是相互关联的。内部类的关系如下图所示。
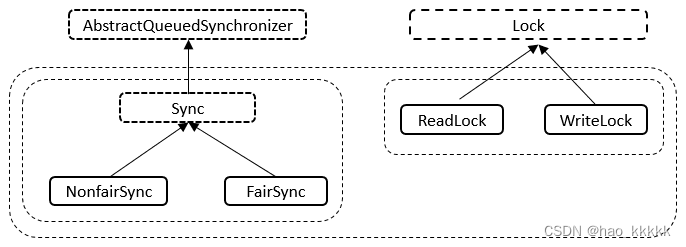
说明: 如上图所示,Sync继承自AQS、NonfairSync继承自Sync类、FairSync继承自Sync类;ReadLock实现了Lock接口、WriteLock也实现了Lock接口。
5.19、ReentrantReadWriteLock底层读写状态如何设计的?
高16位为读锁,低16位为写锁
5.20、读锁和写锁的最大数量是多少?
2的16次方-1
5.21、本地线程计数器ThreadLocalHoldCounter是用来做什么的?
本地线程计数器,与对象绑定(线程-》线程重入的次数)
5.22、写锁的获取与释放是怎么实现的?
tryAcquire/tryRelease
5.23、读锁的获取与释放是怎么实现的?
tryAcquireShared/tryReleaseShared
5.24、什么是锁的升降级?
RentrantReadWriteLock为什么不支持锁升级? RentrantReadWriteLock不支持锁升级(把持读锁、获取写锁,最后释放读锁的过程)。目的也是保证数据可见性,如果读锁已被多个线程获取,其中任意线程成功获取了写锁并更新了数据,则其更新对其他获取到读锁的线程是不可见的。
6、JUC集合类
6.1、为什么HashTable慢? 它的并发度是什么? 那么ConcurrentHashMap并发度是什么?
Hashtable之所以效率低下主要是因为其实现使用了synchronized关键字对put等操作进行加锁,而synchronized关键字加锁是对整个对象进行加锁,也就是说在进行put等修改Hash表的操作时,锁住了整个Hash表,从而使得其表现的效率低下。
6.2、ConcurrentHashMap在JDK1.7和JDK1.8中实现有什么差别? JDK1.8解決了JDK1.7中什么问题
HashTable: 使用了synchronized关键字对put等操作进行加锁;ConcurrentHashMap JDK1.7: 使用分段锁机制实现;ConcurrentHashMap JDK1.8: 则使用数组+链表+红黑树数据结构和CAS原子操作实现;
6.3、ConcurrentHashMap JDK1.7实现的原理是什么?
在JDK1.5~1.7版本,Java使用了分段锁机制实现ConcurrentHashMap.
简而言之,ConcurrentHashMap在对象中保存了一个Segment数组,即将整个Hash表划分为多个分段;而每个Segment元素,它通过继承 ReentrantLock 来进行加锁,所以每次需要加锁的操作锁住的是一个 segment,这样只要保证每个 Segment 是线程安全的,也就实现了全局的线程安全;这样,在执行put操作时首先根据hash算法定位到元素属于哪个Segment,然后对该Segment加锁即可。因此,ConcurrentHashMap在多线程并发编程中可是实现多线程put操作。
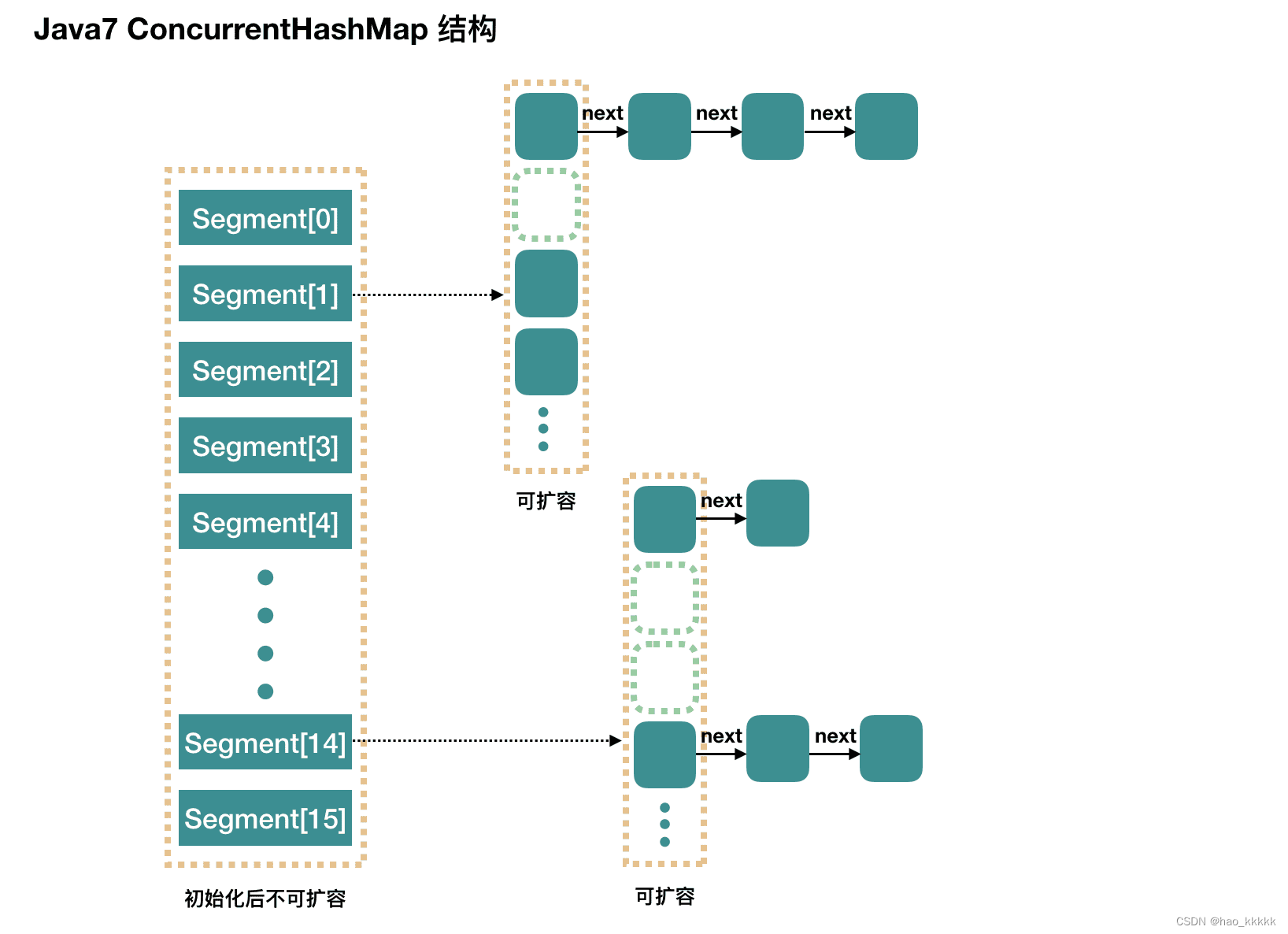
concurrencyLevel: Segment 数(并行级别、并发数)。默认是 16,也就是说 ConcurrentHashMap 有 16 个 Segments,所以理论上,这个时候,最多可以同时支持 16 个线程并发写,只要它们的操作分别分布在不同的 Segment 上。这个值可以在初始化的时候设置为其他值,但是一旦初始化以后,它是不可以扩容的。
6.4、ConcurrentHashMap JDK1.7中Segment数(concurrencyLevel)默认值是多少? 为何一旦初始化就不可再扩容?
默认是 16
6.5、ConcurrentHashMap JDK1.7说说其put的机制?
整体流程还是比较简单的,由于有独占锁的保护,所以 segment 内部的操作并不复杂
- 计算 key 的 hash 值
- 根据 hash 值找到 Segment 数组中的位置 j; ensureSegment(j) 对 segment[j] 进行初始化(Segment 内部是由 数组+链表 组成的)
- 插入新值到 槽 s 中
6.6、ConcurrentHashMap JDK1.7是如何扩容的?
rehash(注:segment 数组不能扩容,扩容是 segment 数组某个位置内部的数组 HashEntry<K,V>[] 进行扩容)
6.7、ConcurrentHashMap JDK1.8实现的原理是什么?
在JDK1.7之前,ConcurrentHashMap是通过分段锁机制来实现的,所以其最大并发度受Segment的个数限制。因此,在JDK1.8中,ConcurrentHashMap的实现原理摒弃了这种设计,而是选择了与HashMap类似的数组+链表+红黑树的方式实现,而加锁则采用CAS和synchronized实现。
简而言之:数组+链表+红黑树,CAS
6.8、ConcurrentHashMap JDK1.8是如何扩容的?
tryPresize, 扩容也是做翻倍扩容的,扩容后数组容量为原来的 2 倍
6.9、ConcurrentHashMap JDK1.8链表转红黑树的时机是什么? 临界值为什么是8?
size = 8, log(N)
6.10、ConcurrentHashMap JDK1.8是如何进行数据迁移的?
transfer, 将原来的 tab 数组的元素迁移到新的 nextTab 数组中
6.11、先说说非并发集合中Fail-fast机制?
快速失败
6.12、CopyOnWriteArrayList的实现原理?
COW基于拷贝
// 将toCopyIn转化为Object[]类型数组,然后设置当前数组
setArray(Arrays.copyOf(toCopyIn, toCopyIn.length, Object[].class));
属性中有一个可重入锁,用来保证线程安全访问,还有一个Object类型的数组,用来存放具体的元素。当然,也使用到了反射机制和CAS来保证原子性的修改lock域。
// 可重入锁
final transient ReentrantLock lock = new ReentrantLock();
// 对象数组,用于存放元素
private transient volatile Object[] array;
// 反射机制
private static final sun.misc.Unsafe UNSAFE;
// lock域的内存偏移量
private static final long lockOffset;
6.13、弱一致性的迭代器原理是怎么样的?
COWIterator<E>
COWIterator表示迭代器,其也有一个Object类型的数组作为CopyOnWriteArrayList数组的快照,这种快照风格的迭代器方法在创建迭代器时使用了对当时数组状态的引用。此数组在迭代器的生存期内不会更改,因此不可能发生冲突,并且迭代器保证不会抛出 ConcurrentModificationException。创建迭代器以后,迭代器就不会反映列表的添加、移除或者更改。在迭代器上进行的元素更改操作(remove、set 和 add)不受支持。这些方法将抛出 UnsupportedOperationException。
6.14、CopyOnWriteArrayList为什么并发安全且性能比Vector好?
Vector对单独的add,remove等方法都是在方法上加了synchronized; 并且如果一个线程A调用size时,另一个线程B 执行了remove,然后size的值就不是最新的,然后线程A调用remove就会越界(这时就需要再加一个Synchronized)。这样就导致有了双重锁,效率大大降低,何必呢。于是vector废弃了,要用就用CopyOnWriteArrayList 吧。
6.15、CopyOnWriteArrayList有何缺陷,说说其应用场景?
CopyOnWriteArrayList 有几个缺点:
-
由于写操作的时候,需要拷贝数组,会消耗内存,如果原数组的内容比较多的情况下,可能导致young gc或者full gc
-
不能用于实时读的场景,像拷贝数组、新增元素都需要时间,所以调用一个set操作后,读取到数据可能还是旧的,虽然CopyOnWriteArrayList 能做到最终一致性,但是还是没法满足实时性要求;
CopyOnWriteArrayList 合适读多写少的场景,不过这类慎用
因为谁也没法保证CopyOnWriteArrayList 到底要放置多少数据,万一数据稍微有点多,每次add/set都要重新复制数组,这个代价实在太高昂了。在高性能的互联网应用中,这种操作分分钟引起故障。
6.16、要想用线程安全的队列有哪些选择?
Vector,Collections.synchronizedList( List<T> list), ConcurrentLinkedQueue等
6.17、ConcurrentLinkedQueue实现的数据结构?
ConcurrentLinkedQueue的数据结构与LinkedBlockingQueue的数据结构相同,都是使用的链表结构。ConcurrentLinkedQueue的数据结构如下:

说明: ConcurrentLinkedQueue采用的链表结构,并且包含有一个头节点和一个尾结点。
6.18、ConcurrentLinkedQueue底层原理?
// 反射机制
private static final sun.misc.Unsafe UNSAFE;
// head域的偏移量
private static final long headOffset;
// tail域的偏移量
private static final long tailOffset;
说明: 属性中包含了head域和tail域,表示链表的头节点和尾结点,同时,ConcurrentLinkedQueue也使用了反射机制和CAS机制来更新头节点和尾结点,保证原子性。
6.19、ConcurrentLinkedQueue的核心方法有哪些?
offer(),poll(),peek(),isEmpty()等队列常用方法
6.20、说说ConcurrentLinkedQueue的HOPS(延迟更新的策略)的设计?
通过上面对offer和poll方法的分析,我们发现tail和head是延迟更新的,两者更新触发时机为:
-
tail更新触发时机:当tail指向的节点的下一个节点不为null的时候,会执行定位队列真正的队尾节点的操作,找到队尾节点后完成插入之后才会通过casTail进行tail更新;当tail指向的节点的下一个节点为null的时候,只插入节点不更新tail。
-
head更新触发时机:当head指向的节点的item域为null的时候,会执行定位队列真正的队头节点的操作,找到队头节点后完成删除之后才会通过updateHead进行head更新;当head指向的节点的item域不为null的时候,只删除节点不更新head。
并且在更新操作时,源码中会有注释为:hop two nodes at a time。所以这种延迟更新的策略就被叫做HOPS的大概原因是这个(猜的 😃),从上面更新时的状态图可以看出,head和tail的更新是“跳着的”即中间总是间隔了一个。那么这样设计的意图是什么呢?
如果让tail永远作为队列的队尾节点,实现的代码量会更少,而且逻辑更易懂。但是,这样做有一个缺点,如果大量的入队操作,每次都要执行CAS进行tail的更新,汇总起来对性能也会是大大的损耗。如果能减少CAS更新的操作,无疑可以大大提升入队的操作效率,所以doug lea大师每间隔1次(tail和队尾节点的距离为1)进行才利用CAS更新tail。对head的更新也是同样的道理,虽然,这样设计会多出在循环中定位队尾节点,但总体来说读的操作效率要远远高于写的性能,因此,多出来的在循环中定位尾节点的操作的性能损耗相对而言是很小的。
6.21、ConcurrentLinkedQueue适合什么样的使用场景?
ConcurrentLinkedQueue通过无锁来做到了更高的并发量,是个高性能的队列,但是使用场景相对不如阻塞队列常见,毕竟取数据也要不停的去循环,不如阻塞的逻辑好设计,但是在并发量特别大的情况下,是个不错的选择,性能上好很多,而且这个队列的设计也是特别费力,尤其的使用的改良算法和对哨兵的处理。整体的思路都是比较严谨的,这个也是使用了无锁造成的,我们自己使用无锁的条件的话,这个队列是个不错的参考。
6.22、什么是BlockingDeque? 适合用在什么样的场景?
BlockingQueue 通常用于一个线程生产对象,而另外一个线程消费这些对象的场景。下图是对这个原理的阐述:

一个线程往里边放,另外一个线程从里边取的一个 BlockingQueue。
一个线程将会持续生产新对象并将其插入到队列之中,直到队列达到它所能容纳的临界点。也就是说,它是有限的。如果该阻塞队列到达了其临界点,负责生产的线程将会在往里边插入新对象时发生阻塞。它会一直处于阻塞之中,直到负责消费的线程从队列中拿走一个对象。 负责消费的线程将会一直从该阻塞队列中拿出对象。如果消费线程尝试去从一个空的队列中提取对象的话,这个消费线程将会处于阻塞之中,直到一个生产线程把一个对象丢进队列。
6.23、BlockingQueue大家族有哪些?
ArrayBlockingQueue, DelayQueue, LinkedBlockingQueue, SynchronousQueue...
6.24、BlockingQueue常用的方法?
BlockingQueue 具有 4 组不同的方法用于插入、移除以及对队列中的元素进行检查。如果请求的操作不能得到立即执行的话,每个方法的表现也不同。这些方法如下:
| 抛异常 | 特定值 | 阻塞 | 超时 | |
|---|---|---|---|---|
| 插入 | add(o) | offer(o) | put(o) | offer(o, timeout, timeunit) |
| 移除 | remove() | poll() | take() | poll(timeout, timeunit) |
| 检查 | element() | peek() |
四组不同的行为方式解释:
- 抛异常: 如果试图的操作无法立即执行,抛一个异常。
- 特定值: 如果试图的操作无法立即执行,返回一个特定的值(常常是 true / false)。
- 阻塞: 如果试图的操作无法立即执行,该方法调用将会发生阻塞,直到能够执行。
- 超时: 如果试图的操作无法立即执行,该方法调用将会发生阻塞,直到能够执行,但等待时间不会超过给定值。返回一个特定值以告知该操作是否成功(典型的是 true / false)。
6.25、BlockingQueue 实现例子?
这里是一个 Java 中使用 BlockingQueue 的示例。本示例使用的是 BlockingQueue 接口的 ArrayBlockingQueue 实现。 首先,BlockingQueueExample 类分别在两个独立的线程中启动了一个 Producer 和 一个 Consumer。Producer 向一个共享的 BlockingQueue 中注入字符串,而 Consumer 则会从中把它们拿出来。
public class BlockingQueueExample {
public static void main(String[] args) throws Exception {
BlockingQueue queue = new ArrayBlockingQueue(1024);
Producer producer = new Producer(queue);
Consumer consumer = new Consumer(queue);
new Thread(producer).start();
new Thread(consumer).start();
Thread.sleep(4000);
}
}
以下是 Producer 类。注意它在每次 put() 调用时是如何休眠一秒钟的。这将导致 Consumer 在等待队列中对象的时候发生阻塞。
public class Producer implements Runnable{
protected BlockingQueue queue = null;
public Producer(BlockingQueue queue) {
this.queue = queue;
}
public void run() {
try {
queue.put("1");
Thread.sleep(1000);
queue.put("2");
Thread.sleep(1000);
queue.put("3");
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
以下是 Consumer 类。它只是把对象从队列中抽取出来,然后将它们打印到 System.out。
public class Consumer implements Runnable{
protected BlockingQueue queue = null;
public Consumer(BlockingQueue queue) {
this.queue = queue;
}
public void run() {
try {
System.out.println(queue.take());
System.out.println(queue.take());
System.out.println(queue.take());
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
6.26、什么是BlockingDeque? 适合用在什么样的场景?
java.util.concurrent 包里的 BlockingDeque 接口表示一个线程安放入和提取实例的双端队列。
BlockingDeque 类是一个双端队列,在不能够插入元素时,它将阻塞住试图插入元素的线程;在不能够抽取元素时,它将阻塞住试图抽取的线程。 deque(双端队列) 是 "Double Ended Queue" 的缩写。因此,双端队列是一个你可以从任意一端插入或者抽取元素的队列。
在线程既是一个队列的生产者又是这个队列的消费者的时候可以使用到 BlockingDeque。如果生产者线程需要在队列的两端都可以插入数据,消费者线程需要在队列的两端都可以移除数据,这个时候也可以使用 BlockingDeque。BlockingDeque 图解:

6.27、BlockingDeque 与BlockingQueue有何关系,请对比下它们的方法?
BlockingDeque 接口继承自 BlockingQueue 接口。这就意味着你可以像使用一个 BlockingQueue 那样使用 BlockingDeque。如果你这么干的话,各种插入方法将会把新元素添加到双端队列的尾端,而移除方法将会把双端队列的首端的元素移除。正如 BlockingQueue 接口的插入和移除方法一样。
以下是 BlockingDeque 对 BlockingQueue 接口的方法的具体内部实现:
| BlockingQueue | BlockingDeque |
|---|---|
| add() | addLast() |
| offer() x 2 | offerLast() x 2 |
| put() | putLast() |
| remove() | removeFirst() |
| poll() x 2 | pollFirst() |
| take() | takeFirst() |
| element() | getFirst() |
| peek() | peekFirst() |
6.28、BlockingDeque大家族有哪些?
LinkedBlockingDeque 是一个双端队列,在它为空的时候,一个试图从中抽取数据的线程将会阻塞,无论该线程是试图从哪一端抽取数据。
6.29、BlockingDeque 实现例子?
既然 BlockingDeque 是一个接口,那么你想要使用它的话就得使用它的众多的实现类的其中一个。java.util.concurrent 包提供了以下 BlockingDeque 接口的实现类: LinkedBlockingDeque。
以下是如何使用 BlockingDeque 方法的一个简短代码示例:
BlockingDeque<String> deque = new LinkedBlockingDeque<String>();
deque.addFirst("1");
deque.addLast("2");
String two = deque.takeLast();
String one = deque.takeFirst();
7、JUC线程池
7.1、FutureTask用来解决什么问题的? 为什么会出现?
FutureTask 为 Future 提供了基础实现,如获取任务执行结果(get)和取消任务(cancel)等。如果任务尚未完成,获取任务执行结果时将会阻塞。一旦执行结束,任务就不能被重启或取消(除非使用runAndReset执行计算)。FutureTask 常用来封装 Callable 和 Runnable,也可以作为一个任务提交到线程池中执行。除了作为一个独立的类之外,此类也提供了一些功能性函数供我们创建自定义 task 类使用。FutureTask 的线程安全由CAS来保证。
7.2、FutureTask类结构关系怎么样的?

可以看到,FutureTask实现了RunnableFuture接口,则RunnableFuture接口继承了Runnable接口和Future接口,所以FutureTask既能当做一个Runnable直接被Thread执行,也能作为Future用来得到Callable的计算结果。
7.3、FutureTask的线程安全是由什么保证的?
FutureTask 的线程安全由CAS来保证。
7.4、FutureTask通常会怎么用? 举例说明。
import java.util.concurrent.*;
public class CallDemo {
public static void main(String[] args) throws ExecutionException, InterruptedException {
/**
* 第一种方式:Future + ExecutorService
* Task task = new Task();
* ExecutorService service = Executors.newCachedThreadPool();
* Future<Integer> future = service.submit(task1);
* service.shutdown();
*/
/**
* 第二种方式: FutureTask + ExecutorService
* ExecutorService executor = Executors.newCachedThreadPool();
* Task task = new Task();
* FutureTask<Integer> futureTask = new FutureTask<Integer>(task);
* executor.submit(futureTask);
* executor.shutdown();
*/
/**
* 第三种方式:FutureTask + Thread
*/
// 2. 新建FutureTask,需要一个实现了Callable接口的类的实例作为构造函数参数
FutureTask<Integer> futureTask = new FutureTask<Integer>(new Task());
// 3. 新建Thread对象并启动
Thread thread = new Thread(futureTask);
thread.setName("Task thread");
thread.start();
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("Thread [" + Thread.currentThread().getName() + "] is running");
// 4. 调用isDone()判断任务是否结束
if(!futureTask.isDone()) {
System.out.println("Task is not done");
try {
Thread.sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
int result = 0;
try {
// 5. 调用get()方法获取任务结果,如果任务没有执行完成则阻塞等待
result = futureTask.get();
} catch (Exception e) {
e.printStackTrace();
}
System.out.println("result is " + result);
}
// 1. 继承Callable接口,实现call()方法,泛型参数为要返回的类型
static class Task implements Callable<Integer> {
@Override
public Integer call() throws Exception {
System.out.println("Thread [" + Thread.currentThread().getName() + "] is running");
int result = 0;
for(int i = 0; i < 100;++i) {
result += i;
}
Thread.sleep(3000);
return result;
}
}
}
7.5、为什么要有线程池?
线程池能够对线程进行统一分配,调优和监控:
- 降低资源消耗(线程无限制地创建,然后使用完毕后销毁)
- 提高响应速度(无须创建线程)
- 提高线程的可管理性
7.6、Java是实现和管理线程池有哪些方式? 请简单举例如何使用。
从JDK 5开始,把工作单元与执行机制分离开来,工作单元包括Runnable和Callable,而执行机制由Executor框架提供。
- WorkerThread
public class WorkerThread implements Runnable {
private String command;
public WorkerThread(String s){
this.command=s;
}
@Override
public void run() {
System.out.println(Thread.currentThread().getName()+" Start. Command = "+command);
processCommand();
System.out.println(Thread.currentThread().getName()+" End.");
}
private void processCommand() {
try {
Thread.sleep(5000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
@Override
public String toString(){
return this.command;
}
}
- SimpleThreadPool
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
public class SimpleThreadPool {
public static void main(String[] args) {
ExecutorService executor = Executors.newFixedThreadPool(5);
for (int i = 0; i < 10; i++) {
Runnable worker = new WorkerThread("" + i);
executor.execute(worker);
}
executor.shutdown(); // This will make the executor accept no new threads and finish all existing threads in the queue
while (!executor.isTerminated()) { // Wait until all threads are finish,and also you can use "executor.awaitTermination();" to wait
}
System.out.println("Finished all threads");
}
}
程序中我们创建了固定大小为五个工作线程的线程池。然后分配给线程池十个工作,因为线程池大小为五,它将启动五个工作线程先处理五个工作,其他的工作则处于等待状态,一旦有工作完成,空闲下来工作线程就会捡取等待队列里的其他工作进行执行。
这里是以上程序的输出。
pool-1-thread-2 Start. Command = 1
pool-1-thread-4 Start. Command = 3
pool-1-thread-1 Start. Command = 0
pool-1-thread-3 Start. Command = 2
pool-1-thread-5 Start. Command = 4
pool-1-thread-4 End.
pool-1-thread-5 End.
pool-1-thread-1 End.
pool-1-thread-3 End.
pool-1-thread-3 Start. Command = 8
pool-1-thread-2 End.
pool-1-thread-2 Start. Command = 9
pool-1-thread-1 Start. Command = 7
pool-1-thread-5 Start. Command = 6
pool-1-thread-4 Start. Command = 5
pool-1-thread-2 End.
pool-1-thread-4 End.
pool-1-thread-3 End.
pool-1-thread-5 End.
pool-1-thread-1 End.
Finished all threads
输出表明线程池中至始至终只有五个名为 "pool-1-thread-1" 到 "pool-1-thread-5" 的五个线程,这五个线程不随着工作的完成而消亡,会一直存在,并负责执行分配给线程池的任务,直到线程池消亡。
Executors 类提供了使用了 ThreadPoolExecutor 的简单的 ExecutorService 实现,但是 ThreadPoolExecutor 提供的功能远不止于此。我们可以在创建 ThreadPoolExecutor 实例时指定活动线程的数量,我们也可以限制线程池的大小并且创建我们自己的 RejectedExecutionHandler 实现来处理不能适应工作队列的工作。
这里是我们自定义的 RejectedExecutionHandler 接口的实现。
- RejectedExecutionHandlerImpl.java
import java.util.concurrent.RejectedExecutionHandler;
import java.util.concurrent.ThreadPoolExecutor;
public class RejectedExecutionHandlerImpl implements RejectedExecutionHandler {
@Override
public void rejectedExecution(Runnable r, ThreadPoolExecutor executor) {
System.out.println(r.toString() + " is rejected");
}
}
ThreadPoolExecutor 提供了一些方法,我们可以使用这些方法来查询 executor 的当前状态,线程池大小,活动线程数量以及任务数量。因此我是用来一个监控线程在特定的时间间隔内打印 executor 信息。
- MyMonitorThread.java
import java.util.concurrent.ThreadPoolExecutor;
public class MyMonitorThread implements Runnable
{
private ThreadPoolExecutor executor;
private int seconds;
private boolean run=true;
public MyMonitorThread(ThreadPoolExecutor executor, int delay)
{
this.executor = executor;
this.seconds=delay;
}
public void shutdown(){
this.run=false;
}
@Override
public void run()
{
while(run){
System.out.println(
String.format("[monitor] [%d/%d] Active: %d, Completed: %d, Task: %d, isShutdown: %s, isTerminated: %s",
this.executor.getPoolSize(),
this.executor.getCorePoolSize(),
this.executor.getActiveCount(),
this.executor.getCompletedTaskCount(),
this.executor.getTaskCount(),
this.executor.isShutdown(),
this.executor.isTerminated()));
try {
Thread.sleep(seconds*1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
这里是使用 ThreadPoolExecutor 的线程池实现例子。
- WorkerPool.java
import java.util.concurrent.ArrayBlockingQueue;
import java.util.concurrent.Executors;
import java.util.concurrent.ThreadFactory;
import java.util.concurrent.ThreadPoolExecutor;
import java.util.concurrent.TimeUnit;
public class WorkerPool {
public static void main(String args[]) throws InterruptedException{
//RejectedExecutionHandler implementation
RejectedExecutionHandlerImpl rejectionHandler = new RejectedExecutionHandlerImpl();
//Get the ThreadFactory implementation to use
ThreadFactory threadFactory = Executors.defaultThreadFactory();
//creating the ThreadPoolExecutor
ThreadPoolExecutor executorPool = new ThreadPoolExecutor(2, 4, 10, TimeUnit.SECONDS, new ArrayBlockingQueue<Runnable>(2), threadFactory, rejectionHandler);
//start the monitoring thread
MyMonitorThread monitor = new MyMonitorThread(executorPool, 3);
Thread monitorThread = new Thread(monitor);
monitorThread.start();
//submit work to the thread pool
for(int i=0; i<10; i++){
executorPool.execute(new WorkerThread("cmd"+i));
}
Thread.sleep(30000);
//shut down the pool
executorPool.shutdown();
//shut down the monitor thread
Thread.sleep(5000);
monitor.shutdown();
}
}
注意在初始化 ThreadPoolExecutor 时,我们保持初始池大小为 2,最大池大小为 4 而工作队列大小为 2。因此如果已经有四个正在执行的任务而此时分配来更多任务的话,工作队列将仅仅保留他们(新任务)中的两个,其他的将会被 RejectedExecutionHandlerImpl 处理。
上面程序的输出可以证实以上观点。
pool-1-thread-1 Start. Command = cmd0
pool-1-thread-4 Start. Command = cmd5
cmd6 is rejected
pool-1-thread-3 Start. Command = cmd4
pool-1-thread-2 Start. Command = cmd1
cmd7 is rejected
cmd8 is rejected
cmd9 is rejected
[monitor] [0/2] Active: 4, Completed: 0, Task: 6, isShutdown: false, isTerminated: false
[monitor] [4/2] Active: 4, Completed: 0, Task: 6, isShutdown: false, isTerminated: false
pool-1-thread-4 End.
pool-1-thread-1 End.
pool-1-thread-2 End.
pool-1-thread-3 End.
pool-1-thread-1 Start. Command = cmd3
pool-1-thread-4 Start. Command = cmd2
[monitor] [4/2] Active: 2, Completed: 4, Task: 6, isShutdown: false, isTerminated: false
[monitor] [4/2] Active: 2, Completed: 4, Task: 6, isShutdown: false, isTerminated: false
pool-1-thread-1 End.
pool-1-thread-4 End.
[monitor] [4/2] Active: 0, Completed: 6, Task: 6, isShutdown: false, isTerminated: false
[monitor] [2/2] Active: 0, Completed: 6, Task: 6, isShutdown: false, isTerminated: false
[monitor] [2/2] Active: 0, Completed: 6, Task: 6, isShutdown: false, isTerminated: false
[monitor] [2/2] Active: 0, Completed: 6, Task: 6, isShutdown: false, isTerminated: false
[monitor] [2/2] Active: 0, Completed: 6, Task: 6, isShutdown: false, isTerminated: false
[monitor] [2/2] Active: 0, Completed: 6, Task: 6, isShutdown: false, isTerminated: false
[monitor] [0/2] Active: 0, Completed: 6, Task: 6, isShutdown: true, isTerminated: true
[monitor] [0/2] Active: 0, Completed: 6, Task: 6, isShutdown: true, isTerminated: true
注意 executor 的活动任务、完成任务以及所有完成任务,这些数量上的变化。我们可以调用 shutdown() 方法来结束所有提交的任务并终止线程池。
7.7、ThreadPoolExecutor的原理?
其实java线程池的实现原理很简单,说白了就是一个线程集合workerSet和一个阻塞队列workQueue。当用户向线程池提交一个任务(也就是线程)时,线程池会先将任务放入workQueue中。workerSet中的线程会不断的从workQueue中获取线程然后执行。当workQueue中没有任务的时候,worker就会阻塞,直到队列中有任务了就取出来继续执行。

当一个任务提交至线程池之后:
- 线程池首先当前运行的线程数量是否少于corePoolSize。如果是,则创建一个新的工作线程来执行任务。如果都在执行任务,则进入2.
- 判断BlockingQueue是否已经满了,倘若还没有满,则将线程放入BlockingQueue。否则进入3.
- 如果创建一个新的工作线程将使当前运行的线程数量超过maximumPoolSize,则交给RejectedExecutionHandler来处理任务。
当ThreadPoolExecutor创建新线程时,通过CAS来更新线程池的状态ctl.
7.8、ThreadPoolExecutor有哪些核心的配置参数? 请简要说明
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
RejectedExecutionHandler handler)
-
corePoolSize线程池中的核心线程数,当提交一个任务时,线程池创建一个新线程执行任务,直到当前线程数等于corePoolSize, 即使有其他空闲线程能够执行新来的任务, 也会继续创建线程;如果当前线程数为corePoolSize,继续提交的任务被保存到阻塞队列中,等待被执行;如果执行了线程池的prestartAllCoreThreads()方法,线程池会提前创建并启动所有核心线程。 -
workQueue用来保存等待被执行的任务的阻塞队列. 在JDK中提供了如下阻塞队列: 具体可以参考JUC 集合: BlockQueue详解ArrayBlockingQueue: 基于数组结构的有界阻塞队列,按FIFO排序任务;LinkedBlockingQueue: 基于链表结构的阻塞队列,按FIFO排序任务,吞吐量通常要高于ArrayBlockingQueue;SynchronousQueue: 一个不存储元素的阻塞队列,每个插入操作必须等到另一个线程调用移除操作,否则插入操作一直处于阻塞状态,吞吐量通常要高于LinkedBlockingQueue;PriorityBlockingQueue: 具有优先级的无界阻塞队列;
LinkedBlockingQueue比ArrayBlockingQueue在插入删除节点性能方面更优,但是二者在put(), take()任务的时均需要加锁,SynchronousQueue使用无锁算法,根据节点的状态判断执行,而不需要用到锁,其核心是Transfer.transfer().
-
maximumPoolSize线程池中允许的最大线程数。如果当前阻塞队列满了,且继续提交任务,则创建新的线程执行任务,前提是当前线程数小于maximumPoolSize;当阻塞队列是无界队列, 则maximumPoolSize则不起作用, 因为无法提交至核心线程池的线程会一直持续地放入workQueue. -
keepAliveTime线程空闲时的存活时间,即当线程没有任务执行时,该线程继续存活的时间;默认情况下,该参数只在线程数大于corePoolSize时才有用, 超过这个时间的空闲线程将被终止; -
unitkeepAliveTime的单位 -
threadFactory创建线程的工厂,通过自定义的线程工厂可以给每个新建的线程设置一个具有识别度的线程名。默认为DefaultThreadFactory -
handler线程池的饱和策略,当阻塞队列满了,且没有空闲的工作线程,如果继续提交任务,必须采取一种策略处理该任务,线程池提供了4种策略:AbortPolicy: 直接抛出异常,默认策略;CallerRunsPolicy: 用调用者所在的线程来执行任务;DiscardOldestPolicy: 丢弃阻塞队列中靠最前的任务,并执行当前任务;DiscardPolicy: 直接丢弃任务;
当然也可以根据应用场景实现RejectedExecutionHandler接口,自定义饱和策略,如记录日志或持久化存储不能处理的任务。
7.9、ThreadPoolExecutor可以创建哪是哪三种线程池呢?
- newFixedThreadPool
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
}
线程池的线程数量达corePoolSize后,即使线程池没有可执行任务时,也不会释放线程。
FixedThreadPool的工作队列为无界队列LinkedBlockingQueue(队列容量为Integer.MAX_VALUE), 这会导致以下问题:
- 线程池里的线程数量不超过corePoolSize,这导致了maximumPoolSize和keepAliveTime将会是个无用参数
- 由于使用了无界队列, 所以FixedThreadPool永远不会拒绝, 即饱和策略失效
- newSingleThreadExecutor
public static ExecutorService newSingleThreadExecutor() {
return new FinalizableDelegatedExecutorService
(new ThreadPoolExecutor(1, 1,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>()));
}
初始化的线程池中只有一个线程,如果该线程异常结束,会重新创建一个新的线程继续执行任务,唯一的线程可以保证所提交任务的顺序执行.
由于使用了无界队列, 所以SingleThreadPool永远不会拒绝, 即饱和策略失效
- newCachedThreadPool
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>());
}
线程池的线程数可达到Integer.MAX_VALUE,即2147483647,内部使用SynchronousQueue作为阻塞队列; 和newFixedThreadPool创建的线程池不同,newCachedThreadPool在没有任务执行时,当线程的空闲时间超过keepAliveTime,会自动释放线程资源,当提交新任务时,如果没有空闲线程,则创建新线程执行任务,会导致一定的系统开销; 执行过程与前两种稍微不同:
- 主线程调用SynchronousQueue的offer()方法放入task, 倘若此时线程池中有空闲的线程尝试读取 SynchronousQueue的task, 即调用了SynchronousQueue的poll(), 那么主线程将该task交给空闲线程. 否则执行(2)
- 当线程池为空或者没有空闲的线程, 则创建新的线程执行任务.
- 执行完任务的线程倘若在60s内仍空闲, 则会被终止. 因此长时间空闲的CachedThreadPool不会持有任何线程资源.
7.10、当队列满了并且worker的数量达到maxSize的时候,会怎么样?
当队列满了并且worker的数量达到maxSize的时候,执行具体的拒绝策略
private volatile RejectedExecutionHandler handler;
7.11、说说ThreadPoolExecutor有哪些RejectedExecutionHandler策略? 默认是什么策略?
- AbortPolicy, 默认
该策略是线程池的默认策略。使用该策略时,如果线程池队列满了丢掉这个任务并且抛出RejectedExecutionException异常。 源码如下:
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
//不做任何处理,直接抛出异常
throw new RejectedExecutionException("xxx");
}
- DiscardPolicy
这个策略和AbortPolicy的slient版本,如果线程池队列满了,会直接丢掉这个任务并且不会有任何异常。 源码如下:
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
//就是一个空的方法
}
- DiscardOldestPolicy
这个策略从字面上也很好理解,丢弃最老的。也就是说如果队列满了,会将最早进入队列的任务删掉腾出空间,再尝试加入队列。 因为队列是队尾进,队头出,所以队头元素是最老的,因此每次都是移除对头元素后再尝试入队。 源码如下:
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
if (!e.isShutdown()) {
//移除队头元素
e.getQueue().poll();
//再尝试入队
e.execute(r);
}
}
- CallerRunsPolicy
使用此策略,如果添加到线程池失败,那么主线程会自己去执行该任务,不会等待线程池中的线程去执行。就像是个急脾气的人,我等不到别人来做这件事就干脆自己干。 源码如下:
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
if (!e.isShutdown()) {
//直接执行run方法
r.run();
}
}
7.12、简要说下线程池的任务执行机制?
execute –> addWorker –>runworker (getTask)
- 线程池的工作线程通过Woker类实现,在ReentrantLock锁的保证下,把Woker实例插入到HashSet后,并启动Woker中的线程。
- 从Woker类的构造方法实现可以发现: 线程工厂在创建线程thread时,将Woker实例本身this作为参数传入,当执行start方法启动线程thread时,本质是执行了Worker的runWorker方法。
- firstTask执行完成之后,通过getTask方法从阻塞队列中获取等待的任务,如果队列中没有任务,getTask方法会被阻塞并挂起,不会占用cpu资源;
7.13、线程池中任务是如何提交的?
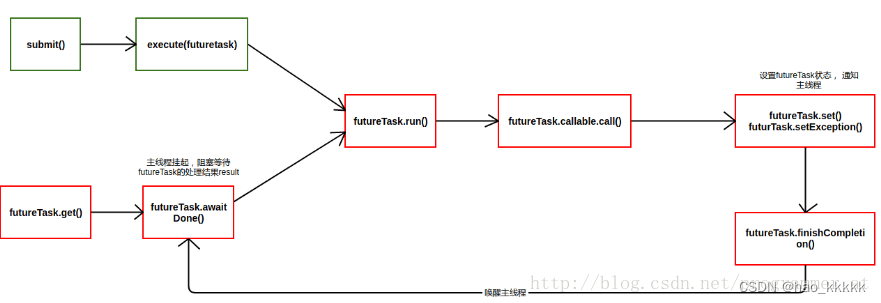
- submit任务,等待线程池execute
- 执行FutureTask类的get方法时,会把主线程封装成WaitNode节点并保存在waiters链表中, 并阻塞等待运行结果;
- FutureTask任务执行完成后,通过UNSAFE设置waiters相应的waitNode为null,并通过LockSupport类unpark方法唤醒主线程;
public class Test{
public static void main(String[] args) {
ExecutorService es = Executors.newCachedThreadPool();
Future<String> future = es.submit(new Callable<String>() {
@Override
public String call() throws Exception {
try {
TimeUnit.SECONDS.sleep(2);
} catch (InterruptedException e) {
e.printStackTrace();
}
return "future result";
}
});
try {
String result = future.get();
System.out.println(result);
} catch (Exception e) {
e.printStackTrace();
}
}
}
在实际业务场景中,Future和Callable基本是成对出现的,Callable负责产生结果,Future负责获取结果。
- Callable接口类似于Runnable,只是Runnable没有返回值。
- Callable任务除了返回正常结果之外,如果发生异常,该异常也会被返回,即Future可以拿到异步执行任务各种结果;
- Future.get方法会导致主线程阻塞,直到Callable任务执行完成;
7.14、线程池中任务是如何关闭的?
- shutdown
将线程池里的线程状态设置成SHUTDOWN状态, 然后中断所有没有正在执行任务的线程.
- shutdownNow
将线程池里的线程状态设置成STOP状态, 然后停止所有正在执行或暂停任务的线程. 只要调用这两个关闭方法中的任意一个, isShutDown() 返回true. 当所有任务都成功关闭了, isTerminated()返回true.
7.15、在配置线程池的时候需要考虑哪些配置因素?
从任务的优先级,任务的执行时间长短,任务的性质(CPU密集/ IO密集),任务的依赖关系这四个角度来分析。并且近可能地使用有界的工作队列。
性质不同的任务可用使用不同规模的线程池分开处理:
- CPU密集型: 尽可能少的线程,Ncpu+1
- IO密集型: 尽可能多的线程, Ncpu*2,比如数据库连接池
- 混合型: CPU密集型的任务与IO密集型任务的执行时间差别较小,拆分为两个线程池;否则没有必要拆分。
7.16、如何监控线程池的状态?
可以使用ThreadPoolExecutor以下方法:
getTaskCount()Returns the approximate total number of tasks that have ever been scheduled for execution.getCompletedTaskCount()Returns the approximate total number of tasks that have completed execution. 返回结果少于getTaskCount()。getLargestPoolSize()Returns the largest number of threads that have ever simultaneously been in the pool. 返回结果小于等于maximumPoolSizegetPoolSize()Returns the current number of threads in the pool.getActiveCount()Returns the approximate number of threads that are actively executing tasks.
7.17、为什么很多公司不允许使用Executors去创建线程池? 那么推荐怎么使用呢?
线程池不允许使用Executors去创建,而是通过ThreadPoolExecutor的方式,这样的处理方式让写的同学更加明确线程池的运行规则,规避资源耗尽的风险。 说明:Executors各个方法的弊端:
-
newFixedThreadPool和newSingleThreadExecutor: 主要问题是堆积的请求处理队列可能会耗费非常大的内存,甚至OOM。
-
newCachedThreadPool和newScheduledThreadPool: 主要问题是线程数最大数是Integer.MAX_VALUE,可能会创建数量非常多的线程,甚至OOM。
-
推荐方式 1 首先引入:commons-lang3包
ScheduledExecutorService executorService = new ScheduledThreadPoolExecutor(1,
new BasicThreadFactory.Builder().namingPattern("example-schedule-pool-%d").daemon(true).build());
- 推荐方式 2 首先引入:com.google.guava包
ThreadFactory namedThreadFactory = new ThreadFactoryBuilder().setNameFormat("demo-pool-%d").build();
//Common Thread Pool
ExecutorService pool = new ThreadPoolExecutor(5, 200, 0L, TimeUnit.MILLISECONDS, new LinkedBlockingQueue<Runnable>(1024), namedThreadFactory, new ThreadPoolExecutor.AbortPolicy());
// excute
pool.execute(()-> System.out.println(Thread.currentThread().getName()));
//gracefully shutdown
pool.shutdown();
- 推荐方式 3 spring配置线程池方式:自定义线程工厂bean需要实现ThreadFactory,可参考该接口的其它默认实现类,使用方式直接注入bean调用execute(Runnable task)方法即可
<bean id="userThreadPool" class="org.springframework.scheduling.concurrent.ThreadPoolTaskExecutor">
<property name="corePoolSize" value="10" />
<property name="maxPoolSize" value="100" />
<property name="queueCapacity" value="2000" />
<property name="threadFactory" value= threadFactory />
<property name="rejectedExecutionHandler">
<ref local="rejectedExecutionHandler" />
</property>
</bean>
//in code
userThreadPool.execute(thread);
7.18、ScheduledThreadPoolExecutor要解决什么样的问题?
在很多业务场景中,我们可能需要周期性的运行某项任务来获取结果,比如周期数据统计,定时发送数据等。在并发包出现之前,Java 早在1.3就提供了 Timer 类(只需要了解,目前已渐渐被 ScheduledThreadPoolExecutor 代替)来适应这些业务场景。随着业务量的不断增大,我们可能需要多个工作线程运行任务来尽可能的增加产品性能,或者是需要更高的灵活性来控制和监控这些周期业务。这些都是 ScheduledThreadPoolExecutor 诞生的必然性。
7.19、ScheduledThreadPoolExecutor相比ThreadPoolExecutor有哪些特性?
ScheduledThreadPoolExecutor继承自 ThreadPoolExecutor,为任务提供延迟或周期执行,属于线程池的一种。和 ThreadPoolExecutor 相比,它还具有以下几种特性:
- 使用专门的任务类型—ScheduledFutureTask 来执行周期任务,也可以接收不需要时间调度的任务(这些任务通过 ExecutorService 来执行)。
- 使用专门的存储队列—DelayedWorkQueue 来存储任务,DelayedWorkQueue 是无界延迟队列DelayQueue 的一种。相比ThreadPoolExecutor也简化了执行机制(delayedExecute方法,后面单独分析)。
- 支持可选的run-after-shutdown参数,在池被关闭(shutdown)之后支持可选的逻辑来决定是否继续运行周期或延迟任务。并且当任务(重新)提交操作与 shutdown 操作重叠时,复查逻辑也不相同。
7.20、ScheduledThreadPoolExecutor有什么样的数据结构,核心内部类和抽象类?

ScheduledThreadPoolExecutor继承自 ThreadPoolExecutor:
- 详情请参考: JUC线程池: ThreadPoolExecutor详解
ScheduledThreadPoolExecutor 内部构造了两个内部类 ScheduledFutureTask 和 DelayedWorkQueue:
-
ScheduledFutureTask: 继承了FutureTask,说明是一个异步运算任务;最上层分别实现了Runnable、Future、Delayed接口,说明它是一个可以延迟执行的异步运算任务。 -
DelayedWorkQueue: 这是 ScheduledThreadPoolExecutor 为存储周期或延迟任务专门定义的一个延迟队列,继承了 AbstractQueue,为了契合 ThreadPoolExecutor 也实现了 BlockingQueue 接口。它内部只允许存储 RunnableScheduledFuture 类型的任务。与 DelayQueue 的不同之处就是它只允许存放 RunnableScheduledFuture 对象,并且自己实现了二叉堆(DelayQueue 是利用了 PriorityQueue 的二叉堆结构)。
7.21、ScheduledThreadPoolExecutor有哪两个关闭策略? 区别是什么?
shutdown: 在shutdown方法中调用的关闭钩子onShutdown方法,它的主要作用是在关闭线程池后取消并清除由于关闭策略不应该运行的所有任务,这里主要是根据 run-after-shutdown 参数(continueExistingPeriodicTasksAfterShutdown和executeExistingDelayedTasksAfterShutdown)来决定线程池关闭后是否关闭已经存在的任务。
showDownNow: 立即关闭
7.22、ScheduledThreadPoolExecutor中scheduleAtFixedRate 和 scheduleWithFixedDelay区别是什么?
注意scheduleAtFixedRate和scheduleWithFixedDelay的区别: 乍一看两个方法一模一样,其实,在unit.toNanos这一行代码中还是有区别的。没错,scheduleAtFixedRate传的是正值,而scheduleWithFixedDelay传的则是负值,这个值就是 ScheduledFutureTask 的period属性。
7.23、为什么ThreadPoolExecutor 的调整策略却不适用于 ScheduledThreadPoolExecutor?
例如: 由于 ScheduledThreadPoolExecutor 是一个固定核心线程数大小的线程池,并且使用了一个无界队列,所以调整maximumPoolSize对其没有任何影响(所以 ScheduledThreadPoolExecutor 没有提供可以调整最大线程数的构造函数,默认最大线程数固定为Integer.MAX_VALUE)。此外,设置corePoolSize为0或者设置核心线程空闲后清除(allowCoreThreadTimeOut)同样也不是一个好的策略,因为一旦周期任务到达某一次运行周期时,可能导致线程池内没有线程去处理这些任务。
7.24、Executors 提供了几种方法来构造 ScheduledThreadPoolExecutor?
- newScheduledThreadPool: 可指定核心线程数的线程池。
- newSingleThreadScheduledExecutor: 只有一个工作线程的线程池。如果内部工作线程由于执行周期任务异常而被终止,则会新建一个线程替代它的位置。
7.25、Fork/Join主要用来解决什么样的问题?
ForkJoinPool 是JDK 7加入的一个线程池类。Fork/Join 技术是分治算法(Divide-and-Conquer)的并行实现,它是一项可以获得良好的并行性能的简单且高效的设计技术。目的是为了帮助我们更好地利用多处理器带来的好处,使用所有可用的运算能力来提升应用的性能。
7.26、Fork/Join框架是在哪个JDK版本中引入的?
JDK 7
7.27、Fork/Join框架主要包含哪三个模块? 模块之间的关系是怎么样的?
Fork/Join框架主要包含三个模块:
- 任务对象:
ForkJoinTask(包括RecursiveTask、RecursiveAction和CountedCompleter) - 执行Fork/Join任务的线程:
ForkJoinWorkerThread - 线程池:
ForkJoinPool
这三者的关系是: ForkJoinPool可以通过池中的ForkJoinWorkerThread来处理ForkJoinTask任务。
7.28、ForkJoinPool类继承关系?
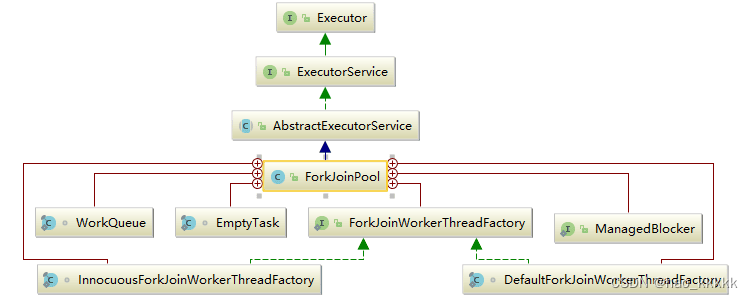
内部类介绍:
-
ForkJoinWorkerThreadFactory: 内部线程工厂接口,用于创建工作线程ForkJoinWorkerThread
-
DefaultForkJoinWorkerThreadFactory: ForkJoinWorkerThreadFactory 的默认实现类
-
InnocuousForkJoinWorkerThreadFactory: 实现了 ForkJoinWorkerThreadFactory,无许可线程工厂,当系统变量中有系统安全管理相关属性时,默认使用这个工厂创建工作线程。
-
EmptyTask: 内部占位类,用于替换队列中 join 的任务。
-
ManagedBlocker: 为 ForkJoinPool 中的任务提供扩展管理并行数的接口,一般用在可能会阻塞的任务(如在 Phaser 中用于等待 phase 到下一个generation)。
-
WorkQueue: ForkJoinPool 的核心数据结构,本质上是work-stealing 模式的双端任务队列,内部存放 ForkJoinTask 对象任务,使用 @Contented 注解修饰防止伪共享。
- 工作线程在运行中产生新的任务(通常是因为调用了 fork())时,此时可以把 WorkQueue 的数据结构视为一个栈,新的任务会放入栈顶(top 位);工作线程在处理自己工作队列的任务时,按照 LIFO 的顺序。
- 工作线程在处理自己的工作队列同时,会尝试窃取一个任务(可能是来自于刚刚提交到 pool 的任务,或是来自于其他工作线程的队列任务),此时可以把 WorkQueue 的数据结构视为一个 FIFO 的队列,窃取的任务位于其他线程的工作队列的队首(base位)。
-
伪共享状态: 缓存系统中是以缓存行(cache line)为单位存储的。缓存行是2的整数幂个连续字节,一般为32-256个字节。最常见的缓存行大小是64个字节。当多线程修改互相独立的变量时,如果这些变量共享同一个缓存行,就会无意中影响彼此的性能,这就是伪共享。
7.29、ForkJoinTask抽象类继承关系?

ForkJoinTask 实现了 Future 接口,说明它也是一个可取消的异步运算任务,实际上ForkJoinTask 是 Future 的轻量级实现,主要用在纯粹是计算的函数式任务或者操作完全独立的对象计算任务。fork 是主运行方法,用于异步执行;而 join 方法在任务结果计算完毕之后才会运行,用来合并或返回计算结果。 其内部类都比较简单,ExceptionNode 是用于存储任务执行期间的异常信息的单向链表;其余四个类是为 Runnable/Callable 任务提供的适配器类,用于把 Runnable/Callable 转化为 ForkJoinTask 类型的任务(因为 ForkJoinPool 只可以运行 ForkJoinTask 类型的任务)。
7.30、整个Fork/Join 框架的执行流程/运行机制是怎么样的?
- 首先介绍任务的提交流程 - 外部任务(external/submissions task)提交
- 然后介绍任务的提交流程 - 子任务(Worker task)提交
- 再分析任务的执行过程(ForkJoinWorkerThread.run()到ForkJoinTask.doExec()这一部分);
- 最后介绍任务的结果获取(ForkJoinTask.join()和ForkJoinTask.invoke())
7.31、具体阐述Fork/Join的分治思想和work-stealing 实现方式?
- 分治算法(Divide-and-Conquer)
分治算法(Divide-and-Conquer)把任务递归的拆分为各个子任务,这样可以更好的利用系统资源,尽可能的使用所有可用的计算能力来提升应用性能。首先看一下 Fork/Join 框架的任务运行机制:
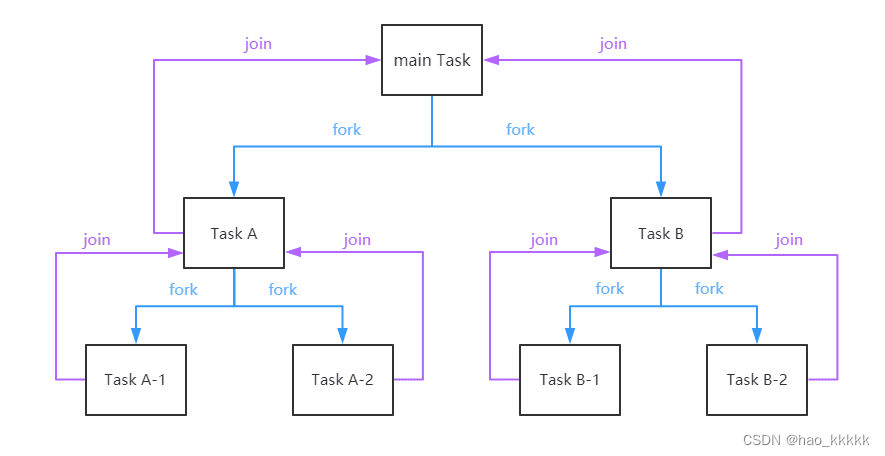
- work-stealing(工作窃取)算法
work-stealing(工作窃取)算法: 线程池内的所有工作线程都尝试找到并执行已经提交的任务,或者是被其他活动任务创建的子任务(如果不存在就阻塞等待)。这种特性使得 ForkJoinPool 在运行多个可以产生子任务的任务,或者是提交的许多小任务时效率更高。尤其是构建异步模型的 ForkJoinPool 时,对不需要合并(join)的事件类型任务也非常适用。
在 ForkJoinPool 中,线程池中每个工作线程(ForkJoinWorkerThread)都对应一个任务队列(WorkQueue),工作线程优先处理来自自身队列的任务(LIFO或FIFO顺序,参数 mode 决定),然后以FIFO的顺序随机窃取其他队列中的任务。
具体思路如下:
- 每个线程都有自己的一个WorkQueue,该工作队列是一个双端队列。
- 队列支持三个功能push、pop、poll
- push/pop只能被队列的所有者线程调用,而poll可以被其他线程调用。
- 划分的子任务调用fork时,都会被push到自己的队列中。
- 默认情况下,工作线程从自己的双端队列获出任务并执行。
- 当自己的队列为空时,线程随机从另一个线程的队列末尾调用poll方法窃取任务。

7.32、有哪些JDK源码中使用了Fork/Join思想?
我们常用的数组工具类 Arrays 在JDK 8之后新增的并行排序方法(parallelSort)就运用了 ForkJoinPool 的特性,还有 ConcurrentHashMap 在JDK 8之后添加的函数式方法(如forEach等)也有运用。
7.33、如何使用Executors工具类创建ForkJoinPool?
Java8在Executors工具类中新增了两个工厂方法:
// parallelism定义并行级别
public static ExecutorService newWorkStealingPool(int parallelism);
// 默认并行级别为JVM可用的处理器个数
// Runtime.getRuntime().availableProcessors()
public static ExecutorService newWorkStealingPool();
7.34、写一个例子: 用ForkJoin方式实现1+2+3+...+100000?
public class Test {
static final class SumTask extends RecursiveTask<Integer> {
private static final long serialVersionUID = 1L;
final int start; //开始计算的数
final int end; //最后计算的数
SumTask(int start, int end) {
this.start = start;
this.end = end;
}
@Override
protected Integer compute() {
//如果计算量小于1000,那么分配一个线程执行if中的代码块,并返回执行结果
if(end - start < 1000) {
System.out.println(Thread.currentThread().getName() + " 开始执行: " + start + "-" + end);
int sum = 0;
for(int i = start; i <= end; i++)
sum += i;
return sum;
}
//如果计算量大于1000,那么拆分为两个任务
SumTask task1 = new SumTask(start, (start + end) / 2);
SumTask task2 = new SumTask((start + end) / 2 + 1, end);
//执行任务
task1.fork();
task2.fork();
//获取任务执行的结果
return task1.join() + task2.join();
}
}
public static void main(String[] args) throws InterruptedException, ExecutionException {
ForkJoinPool pool = new ForkJoinPool();
ForkJoinTask<Integer> task = new SumTask(1, 10000);
pool.submit(task);
System.out.println(task.get());
}
}
- 执行结果
ForkJoinPool-1-worker-1 开始执行: 1-625
ForkJoinPool-1-worker-7 开始执行: 6251-6875
ForkJoinPool-1-worker-6 开始执行: 5626-6250
ForkJoinPool-1-worker-10 开始执行: 3751-4375
ForkJoinPool-1-worker-13 开始执行: 2501-3125
ForkJoinPool-1-worker-8 开始执行: 626-1250
ForkJoinPool-1-worker-11 开始执行: 5001-5625
ForkJoinPool-1-worker-3 开始执行: 7501-8125
ForkJoinPool-1-worker-14 开始执行: 1251-1875
ForkJoinPool-1-worker-4 开始执行: 9376-10000
ForkJoinPool-1-worker-8 开始执行: 8126-8750
ForkJoinPool-1-worker-0 开始执行: 1876-2500
ForkJoinPool-1-worker-12 开始执行: 4376-5000
ForkJoinPool-1-worker-5 开始执行: 8751-9375
ForkJoinPool-1-worker-7 开始执行: 6876-7500
ForkJoinPool-1-worker-1 开始执行: 3126-3750
50005000
7.35、Fork/Join在使用时有哪些注意事项? 结合JDK中的斐波那契数列实例具体说明。
斐波那契数列: 1、1、2、3、5、8、13、21、34、…… 公式 : F(1)=1,F(2)=1, F(n)=F(n-1)+F(n-2)(n>=3,n∈N*)
public static void main(String[] args) {
ForkJoinPool forkJoinPool = new ForkJoinPool(4); // 最大并发数4
Fibonacci fibonacci = new Fibonacci(20);
long startTime = System.currentTimeMillis();
Integer result = forkJoinPool.invoke(fibonacci);
long endTime = System.currentTimeMillis();
System.out.println("Fork/join sum: " + result + " in " + (endTime - startTime) + " ms.");
}
//以下为官方API文档示例
static class Fibonacci extends RecursiveTask<Integer> {
final int n;
Fibonacci(int n) {
this.n = n;
}
@Override
protected Integer compute() {
if (n <= 1) {
return n;
}
Fibonacci f1 = new Fibonacci(n - 1);
f1.fork();
Fibonacci f2 = new Fibonacci(n - 2);
return f2.compute() + f1.join();
}
}
当然你也可以两个任务都fork,要注意的是两个任务都fork的情况,必须按照f1.fork(),f2.fork(), f2.join(),f1.join()这样的顺序,不然有性能问题,详见上面注意事项中的说明。
官方API文档是这样写到的,所以平日用invokeAll就好了。invokeAll会把传入的任务的第一个交给当前线程来执行,其他的任务都fork加入工作队列,这样等于利用当前线程也执行任务了。
{
// ...
Fibonacci f1 = new Fibonacci(n - 1);
Fibonacci f2 = new Fibonacci(n - 2);
invokeAll(f1,f2);
return f2.join() + f1.join();
}
public static void invokeAll(ForkJoinTask<?>... tasks) {
Throwable ex = null;
int last = tasks.length - 1;
for (int i = last; i >= 0; --i) {
ForkJoinTask<?> t = tasks[i];
if (t == null) {
if (ex == null)
ex = new NullPointerException();
}
else if (i != 0) //除了第一个都fork
t.fork();
else if (t.doInvoke() < NORMAL && ex == null) //留一个自己执行
ex = t.getException();
}
for (int i = 1; i <= last; ++i) {
ForkJoinTask<?> t = tasks[i];
if (t != null) {
if (ex != null)
t.cancel(false);
else if (t.doJoin() < NORMAL)
ex = t.getException();
}
}
if (ex != null)
rethrow(ex);
}8、JUC工具类
8.1、什么是CountDownLatch?
CountDownLatch底层也是由AQS,用来同步一个或多个任务的常用并发工具类,强制它们等待由其他任务执行的一组操作完成。
8.2、CountDownLatch底层实现原理?
其底层是由AQS提供支持,所以其数据结构可以参考AQS的数据结构,而AQS的数据结构核心就是两个虚拟队列: 同步队列sync queue 和条件队列condition queue,不同的条件会有不同的条件队列。CountDownLatch典型的用法是将一个程序分为n个互相独立的可解决任务,并创建值为n的CountDownLatch。当每一个任务完成时,都会在这个锁存器上调用countDown,等待问题被解决的任务调用这个锁存器的await,将他们自己拦住,直至锁存器计数结束。
8.3、CountDownLatch一次可以唤醒几个任务?
多个
8.4、CountDownLatch有哪些主要方法?
await(), 此函数将会使当前线程在锁存器倒计数至零之前一直等待,除非线程被中断。
countDown(), 此函数将递减锁存器的计数,如果计数到达零,则释放所有等待的线程
8.5、写道题:实现一个容器,提供两个方法,add,size 写两个线程,线程1添加10个元素到容器中,线程2实现监控元素的个数,当个数到5个时,线程2给出提示并结束?
说出使用CountDownLatch 代替wait notify 好处?
import java.util.ArrayList;
import java.util.List;
import java.util.concurrent.CountDownLatch;
/**
* 使用CountDownLatch 代替wait notify 好处是通讯方式简单,不涉及锁定 Count 值为0时当前线程继续执行,
*/
public class T3 {
volatile List list = new ArrayList();
public void add(int i){
list.add(i);
}
public int getSize(){
return list.size();
}
public static void main(String[] args) {
T3 t = new T3();
CountDownLatch countDownLatch = new CountDownLatch(1);
new Thread(() -> {
System.out.println("t2 start");
if(t.getSize() != 5){
try {
countDownLatch.await();
System.out.println("t2 end");
} catch (InterruptedException e) {
e.printStackTrace();
}
}
},"t2").start();
new Thread(()->{
System.out.println("t1 start");
for (int i = 0;i<9;i++){
t.add(i);
System.out.println("add"+ i);
if(t.getSize() == 5){
System.out.println("countdown is open");
countDownLatch.countDown();
}
}
System.out.println("t1 end");
},"t1").start();
}
}
8.6、什么是CyclicBarrier?
-
对于CountDownLatch,其他线程为游戏玩家,比如英雄联盟,主线程为控制游戏开始的线程。在所有的玩家都准备好之前,主线程是处于等待状态的,也就是游戏不能开始。当所有的玩家准备好之后,下一步的动作实施者为主线程,即开始游戏。
-
对于CyclicBarrier,假设有一家公司要全体员工进行团建活动,活动内容为翻越三个障碍物,每一个人翻越障碍物所用的时间是不一样的。但是公司要求所有人在翻越当前障碍物之后再开始翻越下一个障碍物,也就是所有人翻越第一个障碍物之后,才开始翻越第二个,以此类推。类比地,每一个员工都是一个“其他线程”。当所有人都翻越的所有的障碍物之后,程序才结束。而主线程可能早就结束了,这里我们不用管主线程。
8.7、CountDownLatch和CyclicBarrier对比?
- CountDownLatch减计数,CyclicBarrier加计数。
- CountDownLatch是一次性的,CyclicBarrier可以重用。
- CountDownLatch和CyclicBarrier都有让多个线程等待同步然后再开始下一步动作的意思,但是CountDownLatch的下一步的动作实施者是主线程,具有不可重复性;而CyclicBarrier的下一步动作实施者还是“其他线程”本身,具有往复多次实施动作的特点。
8.8、什么是Semaphore?
Semaphore底层是基于AbstractQueuedSynchronizer来实现的。Semaphore称为计数信号量,它允许n个任务同时访问某个资源,可以将信号量看做是在向外分发使用资源的许可证,只有成功获取许可证,才能使用资源
8.9、Semaphore内部原理?
Semaphore总共有三个内部类,并且三个内部类是紧密相关的,下面先看三个类的关系。
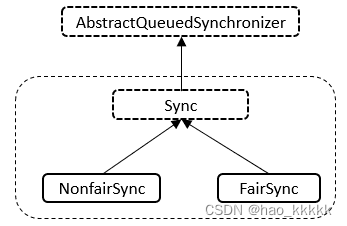
说明: Semaphore与ReentrantLock的内部类的结构相同,类内部总共存在Sync、NonfairSync、FairSync三个类,NonfairSync与FairSync类继承自Sync类,Sync类继承自AbstractQueuedSynchronizer抽象类。下面逐个进行分析。
8.10、Semaphore常用方法有哪些? 如何实现线程同步和互斥的?
8.11、单独使用Semaphore是不会使用到AQS的条件队列?
不同于CyclicBarrier和ReentrantLock,单独使用Semaphore是不会使用到AQS的条件队列的,其实,只有进行await操作才会进入条件队列,其他的都是在同步队列中,只是当前线程会被park。
8.12、Semaphore初始化有10个令牌,11个线程同时各调用1次acquire方法,会发生什么?
拿不到令牌的线程阻塞,不会继续往下运行。
8.13、Semaphore初始化有10个令牌,一个线程重复调用11次acquire方法,会发生什么?
线程阻塞,不会继续往下运行。可能你会考虑类似于锁的重入的问题,很好,但是,令牌没有重入的概念。你只要调用一次acquire方法,就需要有一个令牌才能继续运行。
8.14、Semaphore初始化有1个令牌,1个线程调用一次acquire方法,然后调用两次release方法,之后另外一个线程调用acquire(2)方法,此线程能够获取到足够的令牌并继续运行吗?
能,原因是release方法会添加令牌,并不会以初始化的大小为准。
8.15、Semaphore初始化有2个令牌,一个线程调用1次release方法,然后一次性获取3个令牌,会获取到吗?
能,原因是release会添加令牌,并不会以初始化的大小为准。Semaphore中release方法的调用并没有限制要在acquire后调用。
具体示例如下,如果不相信的话,可以运行一下下面的demo,在做实验之前,笔者也认为应该是不允许的。。
public class TestSemaphore2 {
public static void main(String[] args) {
int permitsNum = 2;
final Semaphore semaphore = new Semaphore(permitsNum);
try {
System.out.println("availablePermits:"+semaphore.availablePermits()+",semaphore.tryAcquire(3,1, TimeUnit.SECONDS):"+semaphore.tryAcquire(3,1, TimeUnit.SECONDS));
semaphore.release();
System.out.println("availablePermits:"+semaphore.availablePermits()+",semaphore.tryAcquire(3,1, TimeUnit.SECONDS):"+semaphore.tryAcquire(3,1, TimeUnit.SECONDS));
}catch (Exception e) {
}
}
}
8.16、Phaser主要用来解决什么问题?
Phaser是JDK 7新增的一个同步辅助类,它可以实现CyclicBarrier和CountDownLatch类似的功能,而且它支持对任务的动态调整,并支持分层结构来达到更高的吞吐量。
8.17、Phaser与CyclicBarrier和CountDownLatch的区别是什么?
Phaser 和 CountDownLatch、CyclicBarrier 都有很相似的地方。
Phaser 顾名思义,就是可以分阶段的进行线程同步。
- CountDownLatch 只能在创建实例时,通过构造方法指定同步数量;
- Phaser 支持线程动态地向它注册。
利用这个动态注册的特性,可以达到分阶段同步控制的目的:
注册一批操作,等待它们执行结束;再注册一批操作,等它们结束...
8.18、Phaser运行机制是什么样的?
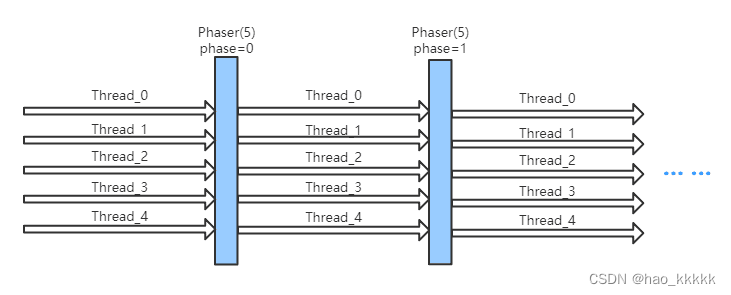
- Registration(注册)
跟其他barrier不同,在phaser上注册的parties会随着时间的变化而变化。任务可以随时注册(使用方法register,bulkRegister注册,或者由构造器确定初始parties),并且在任何抵达点可以随意地撤销注册(方法arriveAndDeregister)。就像大多数基本的同步结构一样,注册和撤销只影响内部count;不会创建更深的内部记录,所以任务不能查询他们是否已经注册。(不过,可以通过继承来实现类似的记录)
- Synchronization(同步机制)
和CyclicBarrier一样,Phaser也可以重复await。方法arriveAndAwaitAdvance的效果类似CyclicBarrier.await。phaser的每一代都有一个相关的phase number,初始值为0,当所有注册的任务都到达phaser时phase+1,到达最大值(Integer.MAX_VALUE)之后清零。使用phase number可以独立控制 到达phaser 和 等待其他线程 的动作,通过下面两种类型的方法:
Arrival(到达机制) arrive和arriveAndDeregister方法记录到达状态。这些方法不会阻塞,但是会返回一个相关的arrival phase number;也就是说,phase number用来确定到达状态。当所有任务都到达给定phase时,可以执行一个可选的函数,这个函数通过重写onAdvance方法实现,通常可以用来控制终止状态。重写此方法类似于为CyclicBarrier提供一个barrierAction,但比它更灵活。
Waiting(等待机制) awaitAdvance方法需要一个表示arrival phase number的参数,并且在phaser前进到与给定phase不同的phase时返回。和CyclicBarrier不同,即使等待线程已经被中断,awaitAdvance方法也会一直等待。中断状态和超时时间同样可用,但是当任务等待中断或超时后未改变phaser的状态时会遭遇异常。如果有必要,在方法forceTermination之后可以执行这些异常的相关的handler进行恢复操作,Phaser也可能被ForkJoinPool中的任务使用,这样在其他任务阻塞等待一个phase时可以保证足够的并行度来执行任务。
- Termination(终止机制) :
可以用isTerminated方法检查phaser的终止状态。在终止时,所有同步方法立刻返回一个负值。在终止时尝试注册也没有效果。当调用onAdvance返回true时Termination被触发。当deregistration操作使已注册的parties变为0时,onAdvance的默认实现就会返回true。也可以重写onAdvance方法来定义终止动作。forceTermination方法也可以释放等待线程并且允许它们终止。
- Tiering(分层结构) :
Phaser支持分层结构(树状构造)来减少竞争。注册了大量parties的Phaser可能会因为同步竞争消耗很高的成本, 因此可以设置一些子Phaser来共享一个通用的parent。这样的话即使每个操作消耗了更多的开销,但是会提高整体吞吐量。 在一个分层结构的phaser里,子节点phaser的注册和取消注册都通过父节点管理。子节点phaser通过构造或方法register、bulkRegister进行首次注册时,在其父节点上注册。子节点phaser通过调用arriveAndDeregister进行最后一次取消注册时,也在其父节点上取消注册。
- Monitoring(状态监控) :
由于同步方法可能只被已注册的parties调用,所以phaser的当前状态也可能被任何调用者监控。在任何时候,可以通过getRegisteredParties获取parties数,其中getArrivedParties方法返回已经到达当前phase的parties数。当剩余的parties(通过方法getUnarrivedParties获取)到达时,phase进入下一代。这些方法返回的值可能只表示短暂的状态,所以一般来说在同步结构里并没有啥卵用。
8.19、给一个Phaser使用的示例?
模拟了100米赛跑,10名选手,
只等裁判一声令下。当所有人都到达终点时,比赛结束。
public class Match {
// 模拟了100米赛跑,10名选手,只等裁判一声令下。当所有人都到达终点时,比赛结束。
public static void main(String[] args) throws InterruptedException {
final Phaser phaser=new Phaser(1) ;
// 十名选手
for (int index = 0; index < 10; index++) {
phaser.register();
new Thread(new player(phaser),"player"+index).start();
}
System.out.println("Game Start");
//注销当前线程,比赛开始
phaser.arriveAndDeregister();
//是否非终止态一直等待
while(!phaser.isTerminated()){
}
System.out.println("Game Over");
}
}
class player implements Runnable{
private final Phaser phaser ;
player(Phaser phaser){
this.phaser=phaser;
}
@Override
public void run() {
try {
// 第一阶段——等待创建好所有线程再开始
phaser.arriveAndAwaitAdvance();
// 第二阶段——等待所有选手准备好再开始
Thread.sleep((long) (Math.random() * 10000));
System.out.println(Thread.currentThread().getName() + " ready");
phaser.arriveAndAwaitAdvance();
// 第三阶段——等待所有选手准备好到达,到达后,该线程从phaser中注销,不在进行下面的阶段。
Thread.sleep((long) (Math.random() * 10000));
System.out.println(Thread.currentThread().getName() + " arrived");
phaser.arriveAndDeregister();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
8.20、Exchanger主要解决什么问题?
Exchanger用于进行两个线程之间的数据交换。它提供一个同步点,在这个同步点,两个线程可以交换彼此的数据。这两个线程通过exchange()方法交换数据,当一个线程先执行exchange()方法后,它会一直等待第二个线程也执行exchange()方法,当这两个线程到达同步点时,这两个线程就可以交换数据了。
8.21、对比SynchronousQueue,为什么说Exchanger可被视为 SynchronousQueue 的双向形式?
Exchanger是一种线程间安全交换数据的机制。可以和之前分析过的SynchronousQueue对比一下:线程A通过SynchronousQueue将数据a交给线程B;线程A通过Exchanger和线程B交换数据,线程A把数据a交给线程B,同时线程B把数据b交给线程A。可见,SynchronousQueue是交给一个数据,Exchanger是交换两个数据。
8.22、Exchanger在不同的JDK版本中实现有什么差别?
- 在JDK5中Exchanger被设计成一个容量为1的容器,存放一个等待线程,直到有另外线程到来就会发生数据交换,然后清空容器,等到下一个到来的线程。
- 从JDK6开始,Exchanger用了类似ConcurrentMap的分段思想,提供了多个slot,增加了并发执行时的吞吐量。
8.23、Exchanger实现举例
来一个非常经典的并发问题:你有相同的数据buffer,一个或多个数据生产者,和一个或多个数据消费者。只是Exchange类只能同步2个线程,所以你只能在你的生产者和消费者问题中只有一个生产者和一个消费者时使用这个类。
public class Test {
static class Producer extends Thread {
private Exchanger<Integer> exchanger;
private static int data = 0;
Producer(String name, Exchanger<Integer> exchanger) {
super("Producer-" + name);
this.exchanger = exchanger;
}
@Override
public void run() {
for (int i=1; i<5; i++) {
try {
TimeUnit.SECONDS.sleep(1);
data = i;
System.out.println(getName()+" 交换前:" + data);
data = exchanger.exchange(data);
System.out.println(getName()+" 交换后:" + data);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
static class Consumer extends Thread {
private Exchanger<Integer> exchanger;
private static int data = 0;
Consumer(String name, Exchanger<Integer> exchanger) {
super("Consumer-" + name);
this.exchanger = exchanger;
}
@Override
public void run() {
while (true) {
data = 0;
System.out.println(getName()+" 交换前:" + data);
try {
TimeUnit.SECONDS.sleep(1);
data = exchanger.exchange(data);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(getName()+" 交换后:" + data);
}
}
}
public static void main(String[] args) throws InterruptedException {
Exchanger<Integer> exchanger = new Exchanger<Integer>();
new Producer("", exchanger).start();
new Consumer("", exchanger).start();
TimeUnit.SECONDS.sleep(7);
System.exit(-1);
}
}
可以看到,其结果可能如下:
Consumer- 交换前:0
Producer- 交换前:1
Consumer- 交换后:1
Consumer- 交换前:0
Producer- 交换后:0
Producer- 交换前:2
Producer- 交换后:0
Consumer- 交换后:2
Consumer- 交换前:0
Producer- 交换前:3
Producer- 交换后:0
Consumer- 交换后:3
Consumer- 交换前:0
Producer- 交换前:4
Producer- 交换后:0
Consumer- 交换后:4
Consumer- 交换前:0
8.24、什么是ThreadLocal? 用来解决什么问题的?
我们在Java 并发 - 并发理论基础总结过线程安全(是指广义上的共享资源访问安全性,因为线程隔离是通过副本保证本线程访问资源安全性,它不保证线程之间还存在共享关系的狭义上的安全性)的解决思路:
- 互斥同步: synchronized 和 ReentrantLock
- 非阻塞同步: CAS, AtomicXXXX
- 无同步方案: 栈封闭,本地存储(Thread Local),可重入代码
ThreadLocal是通过线程隔离的方式防止任务在共享资源上产生冲突, 线程本地存储是一种自动化机制,可以为使用相同变量的每个不同线程都创建不同的存储。
ThreadLocal是一个将在多线程中为每一个线程创建单独的变量副本的类; 当使用ThreadLocal来维护变量时, ThreadLocal会为每个线程创建单独的变量副本, 避免因多线程操作共享变量而导致的数据不一致的情况。
8.25、说说你对ThreadLocal的理解
提到ThreadLocal被提到应用最多的是session管理和数据库链接管理,这里以数据访问为例帮助你理解ThreadLocal:
- 如下数据库管理类在单线程使用是没有任何问题的
class ConnectionManager {
private static Connection connect = null;
public static Connection openConnection() {
if (connect == null) {
connect = DriverManager.getConnection();
}
return connect;
}
public static void closeConnection() {
if (connect != null)
connect.close();
}
}
很显然,在多线程中使用会存在线程安全问题:第一,这里面的2个方法都没有进行同步,很可能在openConnection方法中会多次创建connect;第二,由于connect是共享变量,那么必然在调用connect的地方需要使用到同步来保障线程安全,因为很可能一个线程在使用connect进行数据库操作,而另外一个线程调用closeConnection关闭链接。
- 为了解决上述线程安全的问题,第一考虑:互斥同步
你可能会说,将这段代码的两个方法进行同步处理,并且在调用connect的地方需要进行同步处理,比如用Synchronized或者ReentrantLock互斥锁。
- 这里再抛出一个问题:这地方到底需不需要将connect变量进行共享?
事实上,是不需要的。假如每个线程中都有一个connect变量,各个线程之间对connect变量的访问实际上是没有依赖关系的,即一个线程不需要关心其他线程是否对这个connect进行了修改的。即改后的代码可以这样:
class ConnectionManager {
private Connection connect = null;
public Connection openConnection() {
if (connect == null) {
connect = DriverManager.getConnection();
}
return connect;
}
public void closeConnection() {
if (connect != null)
connect.close();
}
}
class Dao {
public void insert() {
ConnectionManager connectionManager = new ConnectionManager();
Connection connection = connectionManager.openConnection();
// 使用connection进行操作
connectionManager.closeConnection();
}
}
这样处理确实也没有任何问题,由于每次都是在方法内部创建的连接,那么线程之间自然不存在线程安全问题。但是这样会有一个致命的影响:导致服务器压力非常大,并且严重影响程序执行性能。由于在方法中需要频繁地开启和关闭数据库连接,这样不仅严重影响程序执行效率,还可能导致服务器压力巨大。
- 这时候ThreadLocal登场了
那么这种情况下使用ThreadLocal是再适合不过的了,因为ThreadLocal在每个线程中对该变量会创建一个副本,即每个线程内部都会有一个该变量,且在线程内部任何地方都可以使用,线程之间互不影响,这样一来就不存在线程安全问题,也不会严重影响程序执行性能。下面就是网上出现最多的例子:
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.SQLException;
public class ConnectionManager {
private static final ThreadLocal<Connection> dbConnectionLocal = new ThreadLocal<Connection>() {
@Override
protected Connection initialValue() {
try {
return DriverManager.getConnection("", "", "");
} catch (SQLException e) {
e.printStackTrace();
}
return null;
}
};
public Connection getConnection() {
return dbConnectionLocal.get();
}
}
8.26、ThreadLocal是如何实现线程隔离的?
ThreadLocalMap
8.27、为什么ThreadLocal会造成内存泄露? 如何解决
网上有这样一个例子:
import java.util.concurrent.LinkedBlockingQueue;
import java.util.concurrent.ThreadPoolExecutor;
import java.util.concurrent.TimeUnit;
public class ThreadLocalDemo {
static class LocalVariable {
private Long[] a = new Long[1024 * 1024];
}
// (1)
final static ThreadPoolExecutor poolExecutor = new ThreadPoolExecutor(5, 5, 1, TimeUnit.MINUTES,
new LinkedBlockingQueue<>());
// (2)
final static ThreadLocal<LocalVariable> localVariable = new ThreadLocal<LocalVariable>();
public static void main(String[] args) throws InterruptedException {
// (3)
Thread.sleep(5000 * 4);
for (int i = 0; i < 50; ++i) {
poolExecutor.execute(new Runnable() {
public void run() {
// (4)
localVariable.set(new LocalVariable());
// (5)
System.out.println("use local varaible" + localVariable.get());
localVariable.remove();
}
});
}
// (6)
System.out.println("pool execute over");
}
}
如果用线程池来操作ThreadLocal 对象确实会造成内存泄露, 因为对于线程池里面不会销毁的线程, 里面总会存在着<ThreadLocal, LocalVariable>的强引用, 因为final static 修饰的 ThreadLocal 并不会释放, 而ThreadLocalMap 对于 Key 虽然是弱引用, 但是强引用不会释放, 弱引用当然也会一直有值, 同时创建的LocalVariable对象也不会释放, 就造成了内存泄露; 如果LocalVariable对象不是一个大对象的话, 其实泄露的并不严重, 泄露的内存 = 核心线程数 * LocalVariable对象的大小;
所以, 为了避免出现内存泄露的情况, ThreadLocal提供了一个清除线程中对象的方法, 即 remove, 其实内部实现就是调用 ThreadLocalMap 的remove方法:
private void remove(ThreadLocal<?> key) {
Entry[] tab = table;
int len = tab.length;
int i = key.threadLocalHashCode & (len-1);
for (Entry e = tab[i];
e != null;
e = tab[i = nextIndex(i, len)]) {
if (e.get() == key) {
e.clear();
expungeStaleEntry(i);
return;
}
}
}
找到Key对应的Entry, 并且清除Entry的Key(ThreadLocal)置空, 随后清除过期的Entry即可避免内存泄露。
8.28、还有哪些使用ThreadLocal的应用场景?
- 每个线程维护了一个“序列号”
public class SerialNum {
// The next serial number to be assigned
private static int nextSerialNum = 0;
private static ThreadLocal serialNum = new ThreadLocal() {
protected synchronized Object initialValue() {
return new Integer(nextSerialNum++);
}
};
public static int get() {
return ((Integer) (serialNum.get())).intValue();
}
}
+ 经典的另外一个例子:
```java
private static final ThreadLocal threadSession = new ThreadLocal();
public static Session getSession() throws InfrastructureException {
Session s = (Session) threadSession.get();
try {
if (s == null) {
s = getSessionFactory().openSession();
threadSession.set(s);
}
} catch (HibernateException ex) {
throw new InfrastructureException(ex);
}
return s;
}
- 看看阿里巴巴 java 开发手册中推荐的 ThreadLocal 的用法:
import java.text.DateFormat;
import java.text.SimpleDateFormat;
public class DateUtils {
public static final ThreadLocal<DateFormat> df = new ThreadLocal<DateFormat>(){
@Override
protected DateFormat initialValue() {
return new SimpleDateFormat("yyyy-MM-dd");
}
};
}
然后我们再要用到 DateFormat 对象的地方,这样调用:
DateUtils.df.get().format(new Date());