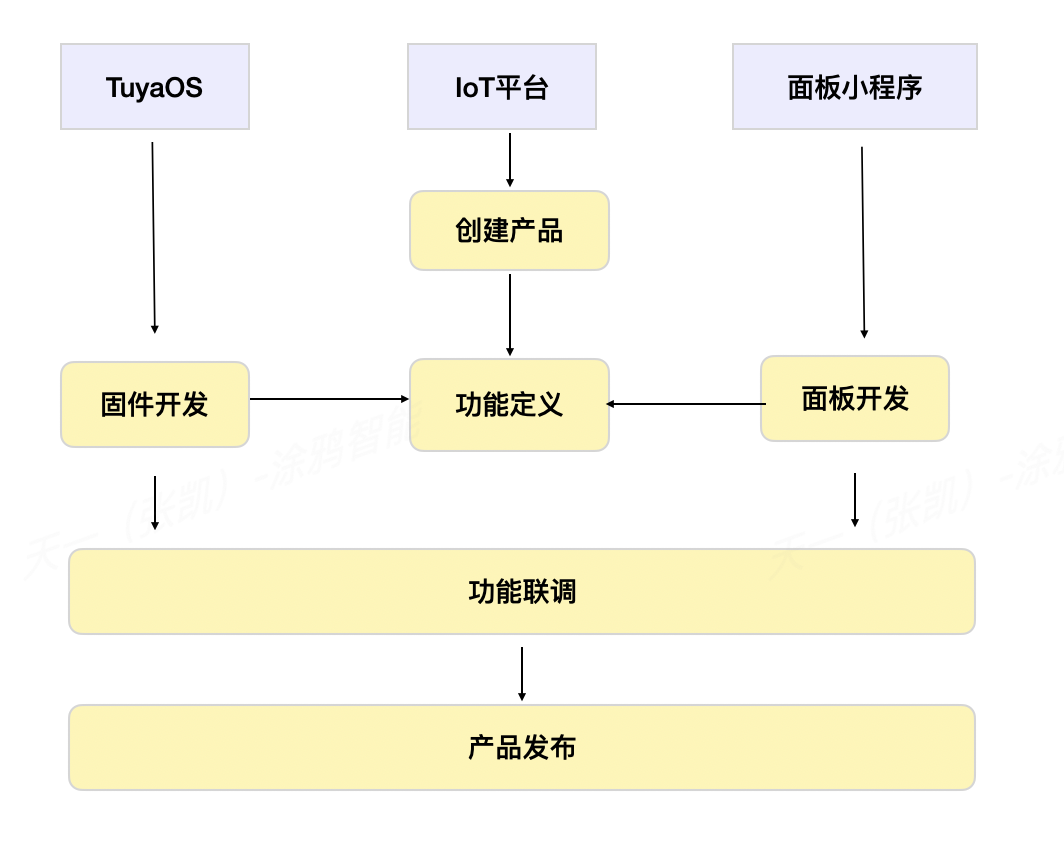
目录
🌞一、实验目的
🌞二、实验准备
🌞三、实验内容
🌼1. 线性回归
🌻1.1 矢量化加速
🌻1.2 正态分布与平方损失
🌼2. 线性回归的从零开始实现
🌻2.1. 生成数据集
🌻2.2 读取数据集
🌻2.3. 初始化模型参数
🌻2.4. 定义模型
🌻2.5. 定义损失函数
🌻2.6. 定义优化算法
🌻2.7. 训练
🌻2.8 小结
🌻2.9 练习
🌼3. 线性回归的简洁实现
🌻3.1. 生成数据集
🌻3.2. 读取数据集
🌻3.3 定义模型
🌻3.4 初始化模型参数
🌻3.5 定义损失函数
🌻3.6 定义优化算法
🌻3.7 训练
🌻3.8 小结
🌻3.9 练习
🌞四、实验心得
🌞一、实验目的
- 熟悉PyTorch框架:了解PyTorch的基本概念、数据结构和核心函数;
- 创建线性回归模型:使用PyTorch构建一个简单的线性回归模型,该模型能够学习输入特征和目标变量之间的线性关系;
- 线性回归从零开始实现及其简洁实现,并完成章节后习题。
🌞二、实验准备
- 根据GPU安装pytorch版本实现GPU运行实验代码;
- 配置环境用来运行 Python、Jupyter Notebook和相关库等相关库。
🌞三、实验内容
资源获取:关注公众号【科创视野】回复 深度学习
🌼1. 线性回归
(1)使用jupyter notebook新增的pytorch环境新建ipynb文件,完成线性回归从零开始实现的实验代码与练习结果如下:
🌻1.1 矢量化加速
%matplotlib inline
import math
import time
import numpy as np
import torch
from d2l import torch as d2l
n = 10000
a = torch.ones([n])
b = torch.ones([n])
class Timer: #@save
"""记录多次运行时间"""
def __init__(self):
self.times = []
self.start()
def start(self):
"""启动计时器"""
self.tik = time.time()
def stop(self):
"""停止计时器并将时间记录在列表中"""
self.times.append(time.time() - self.tik)
return self.times[-1]
def avg(self):
"""返回平均时间"""
return sum(self.times) / len(self.times)
def sum(self):
"""返回时间总和"""
return sum(self.times)
def cumsum(self):
"""返回累计时间"""
return np.array(self.times).cumsum().tolist()
c = torch.zeros(n)
timer = Timer()
for i in range(n):
c[i] = a[i] + b[i]
f'{timer.stop():.5f} sec'输出结果

🌻1.2 正态分布与平方损失
def normal(x, mu, sigma):
p = 1 / math.sqrt(2 * math.pi * sigma**2)
return p * np.exp(-0.5 / sigma**2 * (x - mu)**2)
# 再次使用numpy进行可视化
x = np.arange(-7, 7, 0.01)
# 均值和标准差对
params = [(0, 1), (0, 2), (3, 1)]
d2l.plot(x, [normal(x, mu, sigma) for mu, sigma in params], xlabel='x',
ylabel='p(x)', figsize=(4.5, 2.5),
legend=[f'mean {mu}, std {sigma}' for mu, sigma in params])输出结果

🌼2. 线性回归的从零开始实现
%matplotlib inline
import random
import torch
from d2l import torch as d2l🌻2.1. 生成数据集
def synthetic_data(w, b, num_examples): #@save
"""生成y=Xw+b+噪声"""
X = torch.normal(0, 1, (num_examples, len(w)))
y = torch.matmul(X, w) + b
y += torch.normal(0, 0.01, y.shape)
return X, y.reshape((-1, 1))
true_w = torch.tensor([2, -3.4])
true_b = 4.2
features, labels = synthetic_data(true_w, true_b, 1000)
print('features:', features[0],'\nlabel:', labels[0])输出结果

d2l.set_figsize()
d2l.plt.scatter(features[:, 1].detach().numpy(), labels.detach().numpy(), 1);输出结果
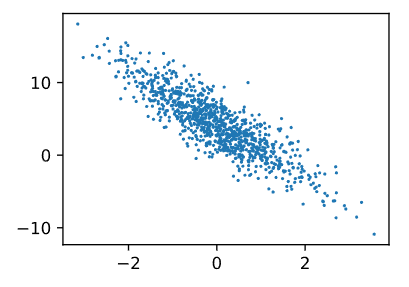
🌻2.2 读取数据集
def data_iter(batch_size, features, labels):
num_examples = len(features)
indices = list(range(num_examples))
# 这些样本是随机读取的,没有特定的顺序
random.shuffle(indices)
for i in range(0, num_examples, batch_size):
batch_indices = torch.tensor(
indices[i: min(i + batch_size, num_examples)])
yield features[batch_indices], labels[batch_indices]
batch_size = 10
for X, y in data_iter(batch_size, features, labels):
print(X, '\n', y)
break输出结果

🌻2.3. 初始化模型参数
w = torch.normal(0, 0.01, size=(2,1), requires_grad=True)
b = torch.zeros(1, requires_grad=True)
w,b输出结果

🌻2.4. 定义模型
def linreg(X, w, b): #@save
"""线性回归模型"""
return torch.matmul(X, w) + b🌻2.5. 定义损失函数
def squared_loss(y_hat, y): #@save
"""均方损失"""
return (y_hat - y.reshape(y_hat.shape)) ** 2 / 2🌻2.6. 定义优化算法
def sgd(params, lr, batch_size): #@save
"""小批量随机梯度下降"""
with torch.no_grad():
for param in params:
param -= lr * param.grad / batch_size
param.grad.zero_()🌻2.7. 训练
lr = 0.03
num_epochs = 3
net = linreg
loss = squared_loss
for epoch in range(num_epochs):
for X, y in data_iter(batch_size, features, labels):
l = loss(net(X, w, b), y) # X和y的小批量损失
# 因为l形状是(batch_size,1),而不是一个标量。l中的所有元素被加到一起,
# 并以此计算关于[w,b]的梯度
l.sum().backward()
sgd([w, b], lr, batch_size) # 使用参数的梯度更新参数
with torch.no_grad():
train_l = loss(net(features, w, b), labels)
print(f'epoch {epoch + 1}, loss {float(train_l.mean()):f}')输出结果

print(f'w的估计误差: {true_w - w.reshape(true_w.shape)}')
print(f'b的估计误差: {true_b - b}')输出结果

🌻2.8 小结
我们学习了深度网络是如何实现和优化的。在这一过程中只使用张量和自动微分,不需要定义层或复杂的优化器。这一节只触及到了表面知识。在下面的部分中,我们将基于刚刚介绍的概念描述其他模型,并学习如何更简洁地实现其他模型。
🌻2.9 练习
1.如果我们将权重初始化为零,会发生什么。算法仍然有效吗?
# 在单层网络中(一层线性回归层),将权重初始化为零时可以的,但是网络层数加深后,在全连接的情况下,
# 在反向传播的时候,由于权重的对称性会导致出现隐藏神经元的对称性,使得多个隐藏神经元的作用就如同
# 1个神经元,算法还是有效的,但是效果不大好。参考:https://zhuanlan.zhihu.com/p/75879624。2.假设试图为电压和电流的关系建立一个模型。自动微分可以用来学习模型的参数吗?
# 可以的,建立模型U=IW+b,然后采集(U,I)的数据集,通过自动微分即可学习W和b的参数。
import torch
import random
from d2l import torch as d2l
#生成数据集
def synthetic_data(r, b, num_examples):
I = torch.normal(0, 1, (num_examples, len(r)))
u = torch.matmul(I, r) + b
u += torch.normal(0, 0.01, u.shape) # 噪声
return I, u.reshape((-1, 1)) # 标量转换为向量
true_r = torch.tensor([20.0])
true_b = 0.01
features, labels = synthetic_data(true_r, true_b, 1000)
#读取数据集
def data_iter(batch_size, features, labels):
num_examples = len(features)
indices = list(range(num_examples))
random.shuffle(indices)
for i in range(0, num_examples, batch_size):
batch_indices = torch.tensor(indices[i: min(i + batch_size, num_examples)])
yield features[batch_indices],labels[batch_indices]
batch_size = 10
# 初始化权重
r = torch.normal(0,0.01,size = ((1,1)), requires_grad = True)
b = torch.zeros(1, requires_grad = True)
# 定义模型
def linreg(I, r, b):
return torch.matmul(I, r) + b
# 损失函数
def square_loss(u_hat, u):
return (u_hat - u.reshape(u_hat.shape)) ** 2/2
# 优化算法
def sgd(params, lr, batch_size):
with torch.no_grad():
for param in params:
param -= lr * param.grad/batch_size
param.grad.zero_()
lr = 0.03
num_epochs = 10
net = linreg
loss = square_loss
for epoch in range(num_epochs):
for I, u in data_iter(batch_size, features, labels):
l = loss(net(I, r, b), u)
l.sum().backward()
sgd([r, b], lr, batch_size)
with torch.no_grad():
train_l = loss(net(features, r, b), labels)
print(f'epoch {epoch + 1}, loss {float(train_l.mean()):f}')
print(r)
print(b)
print(f'r的估计误差: {true_r - r.reshape(true_r.shape)}')
print(f'b的估计误差: {true_b - b}')
输出结果

3.能基于普朗克定律使用光谱能量密度来确定物体的温度吗?
# 3
# 普朗克公式
# x:波长
# T:温度
import torch
import random
from d2l import torch as d2l
#生成数据集
def synthetic_data(x, num_examples):
T = torch.normal(0, 1, (num_examples, len(x)))
u = c1 / ((x ** 5) * ((torch.exp(c2 / (x * T))) - 1));
u += torch.normal(0, 0.01, u.shape) # 噪声
return T, u.reshape((-1, 1)) # 标量转换为向量
c1 = 3.7414*10**8 # c1常量
c2 = 1.43879*10**4 # c2常量
true_x = torch.tensor([500.0])
features, labels = synthetic_data(true_x, 1000)
#读取数据集
def data_iter(batch_size, features, labels):
num_examples = len(features)
indices = list(range(num_examples))
random.shuffle(indices)
for i in range(0, num_examples, batch_size):
batch_indices = torch.tensor(indices[i: min(i + batch_size, num_examples)])
yield features[batch_indices],labels[batch_indices]
batch_size = 10
# 初始化权重
x = torch.normal(0,0.01,size = ((1,1)), requires_grad = True)
# 定义模型
def planck_formula(T, x):
return c1 / ((x ** 5) * ((torch.exp(c2 / (x * T))) - 1))
# 损失函数
def square_loss(u_hat, u):
return (u_hat - u.reshape(u_hat.shape)) ** 2/2
# 优化算法
def sgd(params, lr, batch_size):
with torch.no_grad():
for param in params:
param -= lr * param.grad/batch_size
param.grad.zero_()
lr = 0.001
num_epochs = 10
net = planck_formula
loss = square_loss
for epoch in range(num_epochs):
for T, u in data_iter(batch_size, features, labels):
l = loss(net(T, x), u)
l.sum().backward()
sgd([x], lr, batch_size)
with torch.no_grad():
train_l = loss(net(features, x), labels)
print(f'epoch {epoch + 1}, loss {float(train_l.mean()):f}')
print(f'r的估计误差: {true_x - x.reshape(true_x.shape)}')
输出结果

4.计算二阶导数时可能会遇到什么问题?这些问题可以如何解决?
# 一阶导数的正向计算图无法直接获得,可以通过保存一阶导数的计算图使得可以求二阶导数(create_graph和retain_graph都置为True,
# 保存原函数和一阶导数的正向计算图)。实验如下:
import torch
x = torch.randn((2), requires_grad=True)
y = x**3
dy = torch.autograd.grad(y, x, grad_outputs=torch.ones(x.shape),
retain_graph=True, create_graph=True)
dy2 = torch.autograd.grad(dy, x, grad_outputs=torch.ones(x.shape))
dy_ = 3*x**2
dy2_ = 6*x
print("======================================================")
print(dy, dy_)
print("======================================================")
print(dy2, dy2_)
输出结果

5.为什么在squared_loss函数中需要使用reshape函数?
# 以防y^和y,一个是行向量、一个是列向量,使用reshape,可以确保shape一样。6.尝试使用不同的学习率,观察损失函数值下降的快慢。
# ①学习率过大前期下降很快,但是后面不容易收敛;
# ②学习率过小损失函数下降会很慢。7.如果样本个数不能被批量大小整除,data_iter函数的行为会有什么变化?
# 报错。🌼3. 线性回归的简洁实现
(1)使用jupyter notebook新增的pytorch环境新建ipynb文件,完成线性回归的简洁实现的实验代码与练习结果如下:
🌻3.1. 生成数据集
import numpy as np
import torch
from torch.utils import data
from d2l import torch as d2l
true_w = torch.tensor([2, -3.4])
true_b = 4.2
features, labels = d2l.synthetic_data(true_w, true_b, 1000)🌻3.2. 读取数据集
def load_array(data_arrays, batch_size, is_train=True): #@save
"""构造一个PyTorch数据迭代器"""
dataset = data.TensorDataset(*data_arrays)
return data.DataLoader(dataset, batch_size, shuffle=is_train)
batch_size = 10
data_iter = load_array((features, labels), batch_size)
next(iter(data_iter))输出结果

🌻3.3 定义模型
# nn是神经网络的缩写
from torch import nn
net = nn.Sequential(nn.Linear(2, 1))🌻3.4 初始化模型参数
net[0].weight.data.normal_(0, 0.01)
net[0].bias.data.fill_(0)输出结果
![]()
🌻3.5 定义损失函数
loss = nn.MSELoss()🌻3.6 定义优化算法
trainer = torch.optim.SGD(net.parameters(), lr=0.03)🌻3.7 训练
num_epochs = 3
for epoch in range(num_epochs):
for X, y in data_iter:
l = loss(net(X) ,y)
trainer.zero_grad()
l.backward()
trainer.step()
l = loss(net(features), labels)
print(f'epoch {epoch + 1}, loss {l:f}')输出结果

w = net[0].weight.data
print('w的估计误差:', true_w - w.reshape(true_w.shape))
b = net[0].bias.data
print('b的估计误差:', true_b - b)输出结果
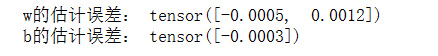
🌻3.8 小结
- 我们可以使用PyTorch的高级API更简洁地实现模型。
- 在PyTorch中,data模块提供了数据处理工具,nn模块定义了大量的神经网络层和常见损失函数。
- 我们可以通过_结尾的方法将参数替换,从而初始化参数。
🌻3.9 练习
1.如果将小批量的总损失替换为小批量损失的平均值,需要如何更改学习率?
# 将学习率除以batchsize。2.查看深度学习框架文档,它们提供了哪些损失函数和初始化方法?
用Huber损失代替原损失,即
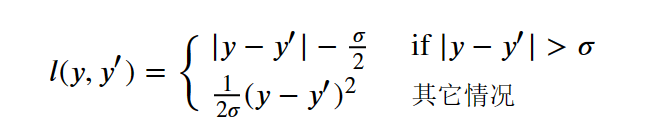
# Huber损失可以用torch自带的函数解决
torch.nn.SmoothL1Loss()
# 也可以自己写
import torch.nn as nn
import torch.nn.functional as F
class HuberLoss(nn.Module):
def __init__(self, sigma):
super(HuberLoss, self).__init__()
self.sigma = sigma
def forward(self, y, y_hat):
if F.l1_loss(y, y_hat) > self.sigma:
loss = F.l1_loss(y, y_hat) - self.sigma/2
else:
loss = (1/(2*self.sigma))*F.mse_loss(y, y_hat)
return loss
#%%
import numpy as np
import torch
from torch.utils import data
from d2l import torch as d2l
#%%
true_w = torch.tensor([2, -3.4])
true_b = 4.2
features, labels = d2l.synthetic_data(true_w, true_b, 1000)
def load_array(data_arrays, batch_size, is_train = True): #@save
'''pytorch数据迭代器'''
dataset = data.TensorDataset(*data_arrays) # 把输入的两类数据一一对应;*表示对list解开入参
return data.DataLoader(dataset, batch_size, shuffle = is_train) # 重新排序
batch_size = 10
data_iter = load_array((features, labels), batch_size) # 和手动实现中data_iter使用方法相同
#%%
# 构造迭代器并验证data_iter的效果
next(iter(data_iter)) # 获得第一个batch的数据
#%% 定义模型
from torch import nn
net = nn.Sequential(nn.Linear(2, 1)) # Linear中两个参数一个表示输入形状一个表示输出形状
# sequential相当于一个存放各层数据的list,单层时也可以只用Linear
#%% 初始化模型参数
# 使用net[0]选择神经网络中的第一层
net[0].weight.data.normal_(0, 0.01) # 正态分布
net[0].bias.data.fill_(0)
#%% 定义损失函数
loss = torch.nn.HuberLoss()
#%% 定义优化算法
trainer = torch.optim.SGD(net.parameters(), lr=0.03) # optim module中的SGD
#%% 训练
num_epochs = 3
for epoch in range(num_epochs):
for X, y in data_iter:
l = loss(net(X), y)
trainer.zero_grad()
l.backward()
trainer.step()
l = loss(net(features), labels)
print(f'epoch {epoch+1}, loss {l:f}')
#%% 查看误差
w = net[0].weight.data
print('w的估计误差:', true_w - w.reshape(true_w.shape))
b = net[0].bias.data
print('b的估计误差:', true_b - b)
输出结果

3.如何访问线性回归的梯度?
#假如是多层网络,可以用一个self.xxx=某层,然后在外面通过net.xxx.weight.grad和net.xxx.bias.grad把梯度给拿出来。
net[0].weight.grad
net[0].bias.grad
输出结果
![]()
🌞四、实验心得
通过此次实验,我熟悉了PyTorch框架以及PyTorch的基本概念、数据结构和核心函数;创建了线性回归模型,使用PyTorch构建一个简单的线性回归模型;完成了线性回归从零开始实现及其简洁实现以及章节后习题。明白了以下几点:
1.深度学习的关键要素包括训练数据、损失函数、优化算法以及模型本身。这些要素相互作用,共同决定了模型的性能和表现。
2.矢量化是一种重要的数学表达方式,它能使数学计算更加简洁高效。通过使用向量和矩阵运算,可以将复杂的计算过程转化为简单的线性代数运算,从而提高计算效率。
3.最小化目标函数和执行极大似然估计是等价的。在机器学习中,通常通过最小化损失函数来优化模型。而在概率统计中,可以通过最大化似然函数来估计模型参数。这两种方法在数学上是等价的,都可以用于优化模型。
4.线性回归模型可以被看作是一个简单的神经网络模型。它只包含一个输入层和一个输出层,其中输入层的神经元数量与输入特征的维度相同,输出层的神经元数量为1。线性回归模型可以用于解决回归问题,通过学习输入特征与输出之间的线性关系来进行预测。
5.在深度学习中,学习了如何实现和优化深度神经网络。在这个过程中,只使用张量(Tensor)和自动微分(Automatic Differentiation),而不需要手动定义神经网络层或复杂的优化器。张量是深度学习中的基本数据结构,它可以表示多维数组,并支持各种数学运算。自动微分是一种计算梯度的技术,它能够自动计算函数相对于输入的导数,从而实现了反向传播算法。
6.为了更加简洁地实现模型,可以利用PyTorch的高级API。在PyTorch中,data模块提供了数据处理工具,包括数据加载、预处理和批处理等功能,使得数据的处理变得更加方便和高效。nn模块则提供了大量的神经网络层和常见损失函数的定义,可以直接使用这些层和函数来构建和训练模型,无需手动实现。此外还可以通过使用_结尾的方法来进行参数的替换和初始化,从而更加灵活地管理模型的参数。