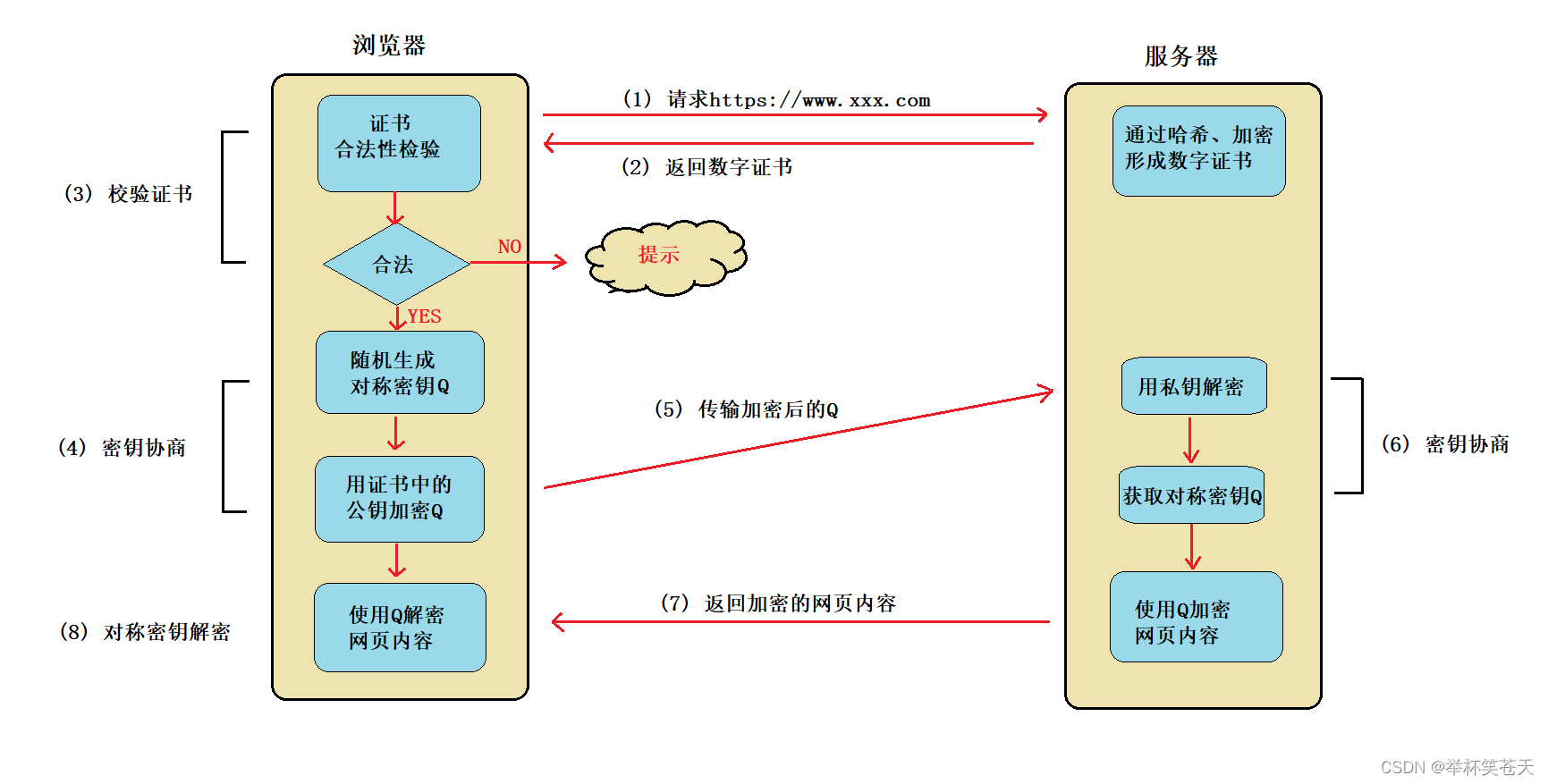
Kafka表引擎也是一种常见的表引擎,在很多大数据量的场景下,会从源通过Kafka将数据输送到ClickHouse,Kafka作为输送的方式,ClickHouse作为存储引擎与查询引擎,大数据量的数据可以得到快速的、高压缩的存储。

Kafka大家肯定不陌生:
- 它可以用于发布和订阅数据流,是常见的队列使用方式
- 它可以组织容错存储,是常见的容错存储的使用方式
- 它可以在流可用时对其进行处理,是常见的大数据处理的使用方式
全文概览:
- 基本语法
- 从 Kafka 写入到 ClickHouse
- 从 ClickHouse 写入到 Kafka
- 测试1:queue->ck->queue
- 测试2:ck->queue
基本语法
分为定义表结构和定义Kafka的接入参数,Kafka的接入参数都是常见的字段
CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster]
(
name1 [type1] [ALIAS expr1],
name2 [type2] [ALIAS expr2],
...
) ENGINE = Kafka()
SETTINGS
kafka_broker_list = 'host:port',
kafka_topic_list = 'topic1,topic2,...',
kafka_group_name = 'group_name',
kafka_format = 'data_format'[,]
[kafka_schema = '',]
[kafka_num_consumers = N,]
[kafka_max_block_size = 0,]
[kafka_skip_broken_messages = N,]
[kafka_commit_every_batch = 0,]
[kafka_client_id = '',]
[kafka_poll_timeout_ms = 0,]
[kafka_poll_max_batch_size = 0,]
[kafka_flush_interval_ms = 0,]
[kafka_thread_per_consumer = 0,]
[kafka_handle_error_mode = 'default',]
[kafka_commit_on_select = false,]
[kafka_max_rows_per_message = 1];
示例:
CREATE TABLE IF NOT EXISTS test_ck_sync1
(
`sys_time` Datetime COMMENT '',
`num` UInt32 COMMENT ''
)
ENGINE = Kafka
SETTINGS kafka_broker_list = '127.0.0.1:9092', kafka_topic_list = 'test_ck_sync1', kafka_group_name = 'ck_test_ck_sync1', kafka_format = 'CSV', kafka_max_block_size = 200000, kafka_skip_broken_messages = 1000, kafka_row_delimiter = '\n', format_csv_delimiter = '|'
从 Kafka 写入到 ClickHouse
创建topic:
bin/kafka-topics.sh --create --bootstrap-server 127.0.0.1:9092 --replication-factor 1 --partitions 1 --topic test_ck_sync1
创建同步表:
CREATE TABLE IF NOT EXISTS test_ck_sync1
(
`sys_time` Datetime COMMENT '',
`num` UInt32 COMMENT ''
)
ENGINE = Kafka
SETTINGS kafka_broker_list = '127.0.0.1:9092', kafka_topic_list = 'test_ck_sync1', kafka_group_name = 'ck_test_ck_sync1', kafka_format = 'CSV', kafka_max_block_size = 200000, kafka_skip_broken_messages = 1000, kafka_row_delimiter = '\n', format_csv_delimiter = '|'
CREATE TABLE IF NOT EXISTS test_ck_sync1_res
(
`sys_time` Datetime COMMENT '',
`num` UInt32 COMMENT ''
)
ENGINE = MergeTree
PARTITION BY toYYYYMMDD(sys_time)
ORDER BY tuple()
创建物化视图,进行数据样式的转换:
CREATE MATERIALIZED VIEW test_ck_sync1_mv TO test_ck_sync1_res AS
SELECT
sys_time,
num
FROM test_ck_sync1
通过console写入数据:
[$ kafka_2.13-3.6.1]# bin/kafka-console-producer.sh --broker-list 127.0.0.1:9092 --topic test_ck_sync1
>2024-01-01 00:00:01|89
验证数据:
$ :) select * from test_ck_sync1_res;
SELECT *
FROM test_ck_sync1_res
Query id: a666f893-5be9-4022-9327-3a1507aa5485
┌────────────sys_time─┬─num─┐
│ 2024-01-01 00:00:01 │ 89 │
└─────────────────────┴─────┘
┌────────────sys_time─┬─num─┐
│ 2024-01-01 00:00:00 │ 88 │
└─────────────────────┴─────┘
2 rows in set. Elapsed: 0.049 sec.
从 ClickHouse 写入到 Kafka
kafka_writers_reader --(view)--> kafka_writers_queue --->
创建一个队列:
bin/kafka-topics.sh --topic kafka_writers --create -bootstrap-server 127.0.0.1:9092 --partitions 1 --replication-factor 1
创建同步表:
CREATE TABLE kafka_writers_reader ( `id` Int, `platForm` String, `appname` String, `time` DateTime )
ENGINE = Kafka SETTINGS kafka_broker_list = '127.0.0.1:9092', kafka_topic_list = 'kafka_writers_reader', kafka_group_name = 'kafka_writers_reader_group', kafka_format = 'CSV';
CREATE TABLE kafka_writers_queue ( id Int, platForm String, appname String, time DateTime )
ENGINE = Kafka SETTINGS kafka_broker_list = '127.0.0.1:9092', kafka_topic_list = 'kafka_writers', kafka_group_name = 'kafka_writers_group', kafka_format = 'CSV', kafka_max_block_size = 1048576;
测试1:queue->ck->queue
通过写入队列kafka_writers_reader,借助ClickHouse写入队列kafka_writers
bin/kafka-topics.sh --topic kafka_writers_reader --create -bootstrap-server 127.0.0.1:9092 --partitions 1 --replication-factor 1
bin/kafka-console-producer.sh --broker-list 127.0.0.1:9092 --topic kafka_writers_reader
bin/kafka-console-consumer.sh --bootstrap-server 127.0.0.1:9092 --topic kafka_writers
测试2:ck->queue
通过写入表kafka_writers_reader,写入队列kafka_writers
$ :) INSERT INTO kafka_writers_reader (id, platForm, appname, time)
VALUES (8,'Data','Test','2020-12-23 14:45:31'),
(9,'Plan','Test1','2020-12-23 14:47:32'),
(10,'Plan','Test2','2020-12-23 14:52:15'),
(11,'Data','Test3','2020-12-23 14:54:39');
INSERT INTO kafka_writers_reader (id, platForm, appname, time) FORMAT Values
Query id: 223a63ab-97fa-488d-8ea7-c2e194155d26
Ok.
4 rows in set. Elapsed: 1.054 sec.
[$ kafka_2.13-3.6.1]# bin/kafka-console-consumer.sh --bootstrap-server 127.0.0.1:9092 --topic kafka_writers
8,"Data","Test","1970-01-01 08:00:00"
9,"Plan","Test1","1970-01-01 08:00:00"
10,"Plan","Test2","1970-01-01 08:00:00"
11,"Data","Test3","1970-01-01 08:00:00"
如果喜欢我的文章的话,可以去GitHub上给一个免费的关注吗?