目录
背景
embedding
求最相似的 topk
结果查看
背景
想要求两个文本的相似度,就单纯相似度,不要语义相似度,直接使用 bert 先 embedding 然后找出相似的文本,效果都不太好,试过 bert-base-chinese,bert-wwm,robert-wwm 这些,都有一个问题,那就是明明不相似的文本却在结果中变成了相似,真正相似的有没有,
例如:手机壳迷你版,与这条数据相似的应该都是跟手机壳有关的才合理,但结果不太好,明明不相关的,余弦相似度都能有有 0.9 以上的,所以问题出在 embedding 上,找了适合做 embedding 的模型,再去计算相似效果好了很多,合理很多。
之前写了一篇 bert+np.memap+faiss文本相似度匹配 topN-CSDN博客 是把流程打通,现在是找适合文本相似的来操作。
模型:
bge-small-zh-v1.5
bge-large-zh-v1.5
embedding
数据弄的几条测试数据,方便看那些相似
我用 bge-large-zh-v1.5 来操作,embedding 代码,为了知道 embedding 进度,加了进度条功能,同时打印了当前使用 embedding 的 bert 模型输出为度,这很重要,会影响求相似的 topk
import numpy as np
import pandas as pd
import time
from tqdm.auto import tqdm
from transformers import AutoTokenizer, AutoModel
import torch
class TextEmbedder():
def __init__(self, model_name="./bge-large-zh-v1.5"):
# self.device = torch.device("cuda" if torch.cuda.is_available() else "cpu") # 自己电脑跑不起来 gpu
self.device = torch.device("cpu")
self.tokenizer = AutoTokenizer.from_pretrained(model_name)
self.model = AutoModel.from_pretrained(model_name).to(self.device)
self.model.eval()
# 没加进度条的
# def embed_sentences(self, sentences):
# encoded_input = self.tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# with torch.no_grad():
# model_output = self.model(**encoded_input)
# sentence_embeddings = model_output[0][:, 0]
# sentence_embeddings = torch.nn.functional.normalize(sentence_embeddings, p=2, dim=1)
#
# return sentence_embeddings
# 加进度条
def embed_sentences(self, sentences):
embedded_sentences = []
for sentence in tqdm(sentences):
encoded_input = self.tokenizer([sentence], padding=True, truncation=True, return_tensors='pt')
with torch.no_grad():
model_output = self.model(**encoded_input)
sentence_embedding = model_output[0][:, 0]
sentence_embedding = torch.nn.functional.normalize(sentence_embedding, p=2)
embedded_sentences.append(sentence_embedding.cpu().numpy())
print('当前 bert 模型输出维度为,', embedded_sentences[0].shape[1])
return np.array(embedded_sentences)
def save_embeddings_to_memmap(self, sentences, output_file, dtype=np.float32):
embeddings = self.embed_sentences(sentences)
shape = embeddings.shape
embeddings_memmap = np.memmap(output_file, dtype=dtype, mode='w+', shape=shape)
embeddings_memmap[:] = embeddings[:]
del embeddings_memmap # 关闭并确保数据已写入磁盘
def read_data():
data = pd.read_excel('新建 XLSX 工作表.xlsx')
return data['addr'].to_list()
def main():
# text_data = ["这是第一个句子", "这是第二个句子", "这是第三个句子"]
text_data = read_data()
embedder = TextEmbedder()
# 设置输出文件路径
output_filepath = 'sentence_embeddings.npy'
# 将文本数据向量化并保存到内存映射文件
embedder.save_embeddings_to_memmap(text_data, output_filepath)
if __name__ == "__main__":
start = time.time()
main()
end = time.time()
print(end - start)求最相似的 topk
使用 faiss 索引需要设置 bert 模型的维度,所以我们前面打印出来了,要不然会报错,像这样的:
ValueError: cannot reshape array of size 10240 into shape (768)所以 print('当前 bert 模型输出维度为,', embedded_sentences[0].shape[1]) 的值换上去,我这里打印的 1024
index = faiss.IndexFlatL2(1024) # 假设BERT输出维度是768
# 确保embeddings_memmap是二维数组,如有需要转换
if len(embeddings_memmap.shape) == 1:
embeddings_memmap = embeddings_memmap.reshape(-1, 1024)完整代码
import pandas as pd
import numpy as np
import faiss
from tqdm import tqdm
def search_top4_similarities(index_path, data, topk=4):
embeddings_memmap = np.memmap(index_path, dtype=np.float32, mode='r')
index = faiss.IndexFlatL2(768) # 假设BERT输出维度是768
# 确保embeddings_memmap是二维数组,如有需要转换
if len(embeddings_memmap.shape) == 1:
embeddings_memmap = embeddings_memmap.reshape(-1, 768)
index.add(embeddings_memmap)
results = []
for i, text_emb in enumerate(tqdm(embeddings_memmap)):
D, I = index.search(np.expand_dims(text_emb, axis=0), topk) # 查找前topk个最近邻
# 获取对应的 nature_df_img_id 的索引
top_k_indices = I[0][:topk] #
# 根据索引提取 nature_df_img_id
top_k_ids = [data.iloc[index]['index'] for index in top_k_indices]
# 计算余弦相似度并构建字典
cosine_similarities = [cosine_similarity(text_emb, embeddings_memmap[index]) for index in top_k_indices]
top_similarity = dict(zip(top_k_ids, cosine_similarities))
results.append((data['index'].to_list()[i], top_similarity))
return results
# 使用余弦相似度公式,这里假设 cosine_similarity 是一个计算两个向量之间余弦相似度的函数
def cosine_similarity(vec1, vec2):
return np.dot(vec1, vec2) / (np.linalg.norm(vec1) * np.linalg.norm(vec2))
def main_search():
data = pd.read_excel('新建 XLSX 工作表.xlsx')
data['index'] = data.index
similarities = search_top4_similarities('sentence_embeddings.npy', data)
# 输出结果
similar_df = pd.DataFrame(similarities, columns=['id', 'top'])
similar_df.to_csv('similarities.csv', index=False)
# 执行搜索并保存结果
main_search()结果查看
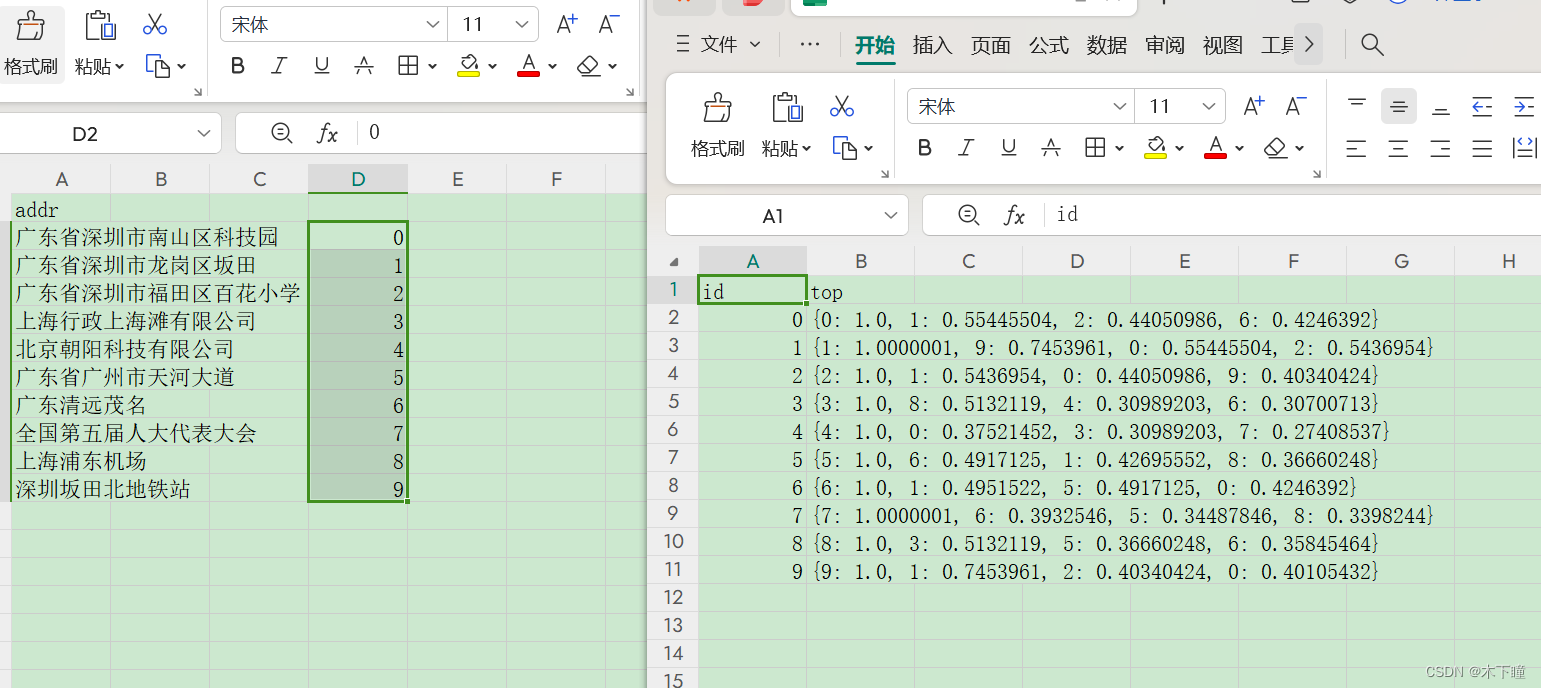
看一看到余弦数值还是比较合理的,没有那种明明不相关但余弦值是 0.9 的情况了,这两个模型还是可以的