库、表、记录的概念
库(Database):库是一个容器,用于存储表和其他对象(如视图、存储过程等)
表(Table):表是一个由列和行组成的矩阵,其中每列都定义了表中的一种数据类型,每行则表示表中的一个记录。
记录(Record):记录是表中的一行数据。
------------------------------------------------------------
修改数据库表中的字段
【1】添加新的字段
alter table 表名 add 新字段名(列名) 数据类型;
alter table person add teacher varchar(255);
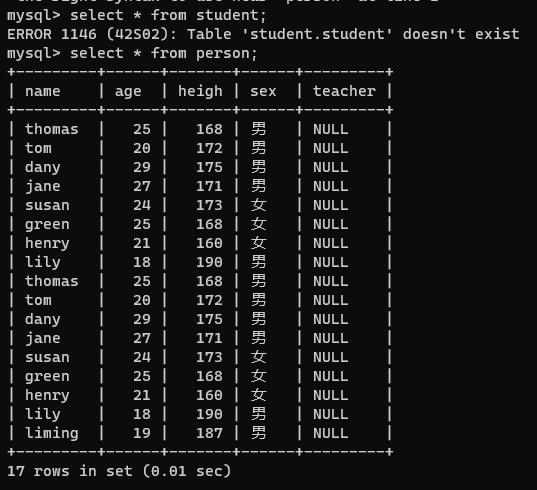
【2】修改字段的数据类型
alter table 表名 modify 字段名(列名) 新数据类型;
alter table person modify teacher varchar(200);
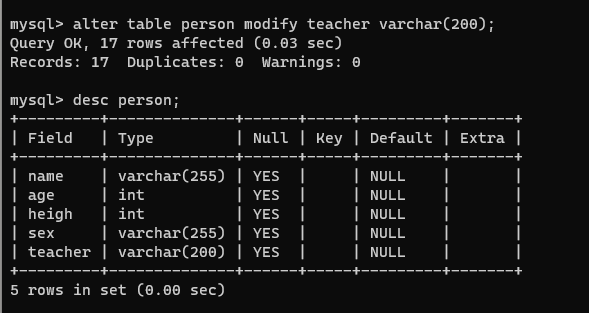
【3】修改字段名(列名)
alter table 表名 change 旧字段名 新字段名 数据类型;
alter table person change teacher teacher_name varchar(150);
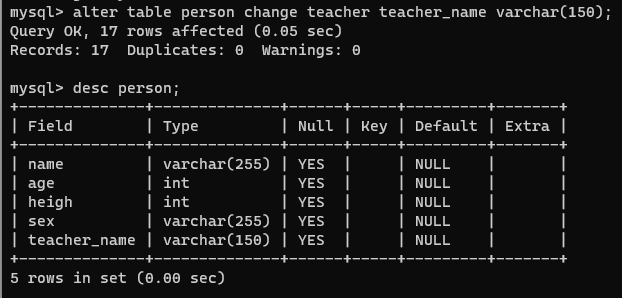
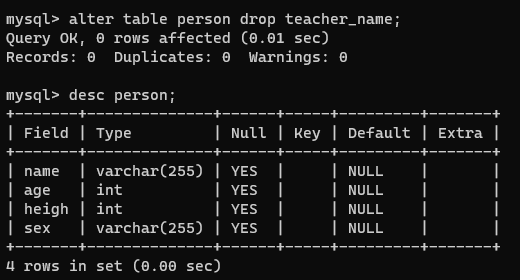
【4】删除字段
alter table 表名 drop 字段名;
alter table person drop teacher_name;
【5】将新列中添加新
update person set teacher = '某某老师' where teacher is null;
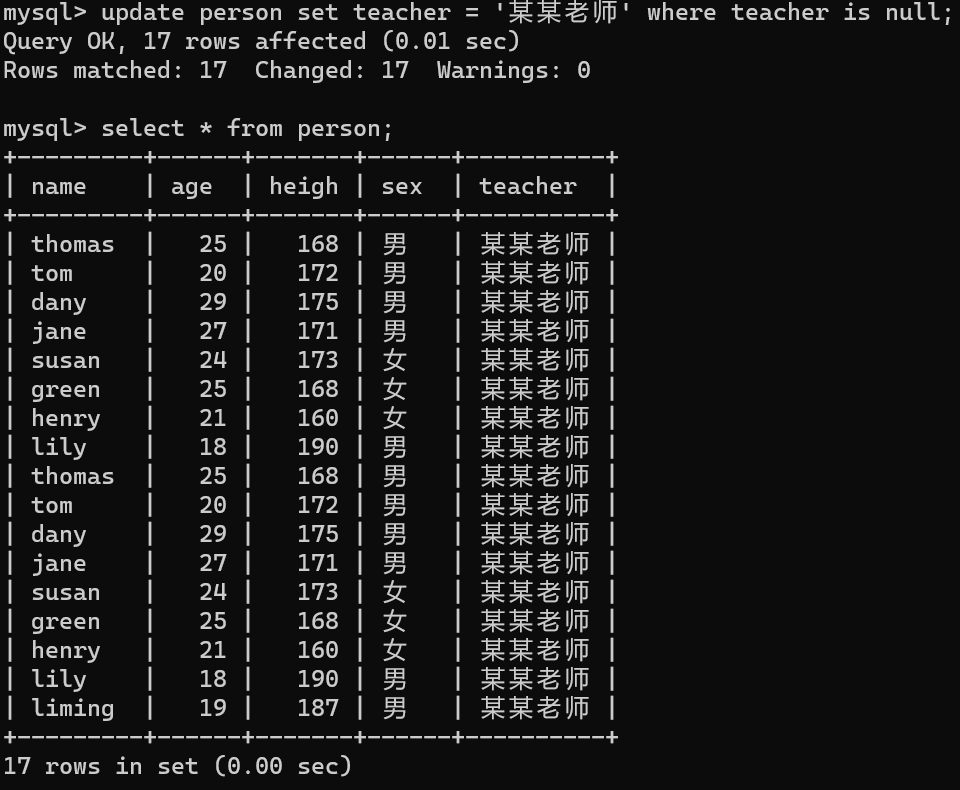
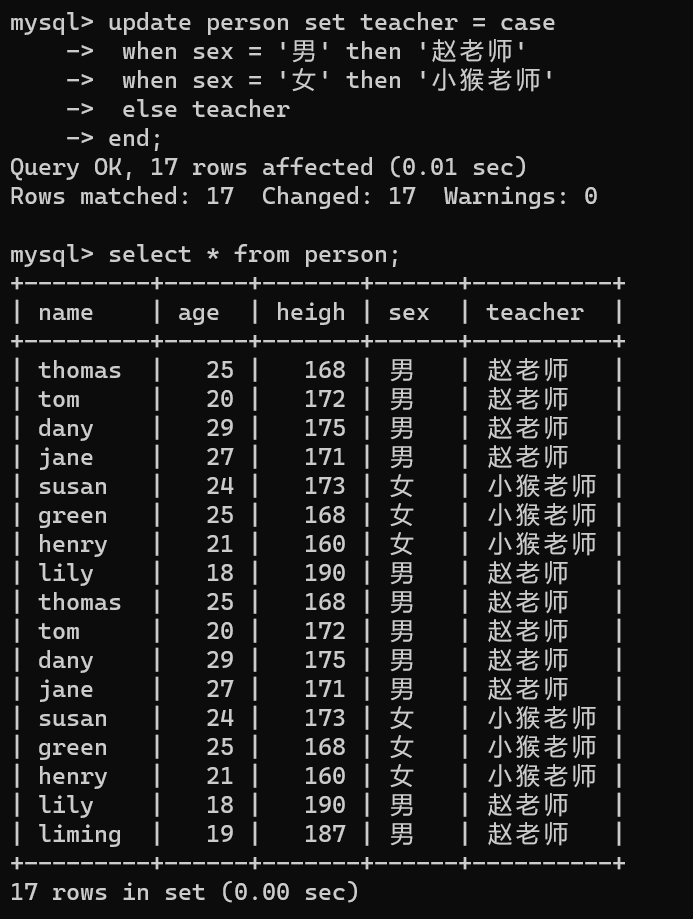
update person set teacher = case
when sex = '男' then '赵老师'
when sex = '女' then '小猴老师'
else teacher
end;
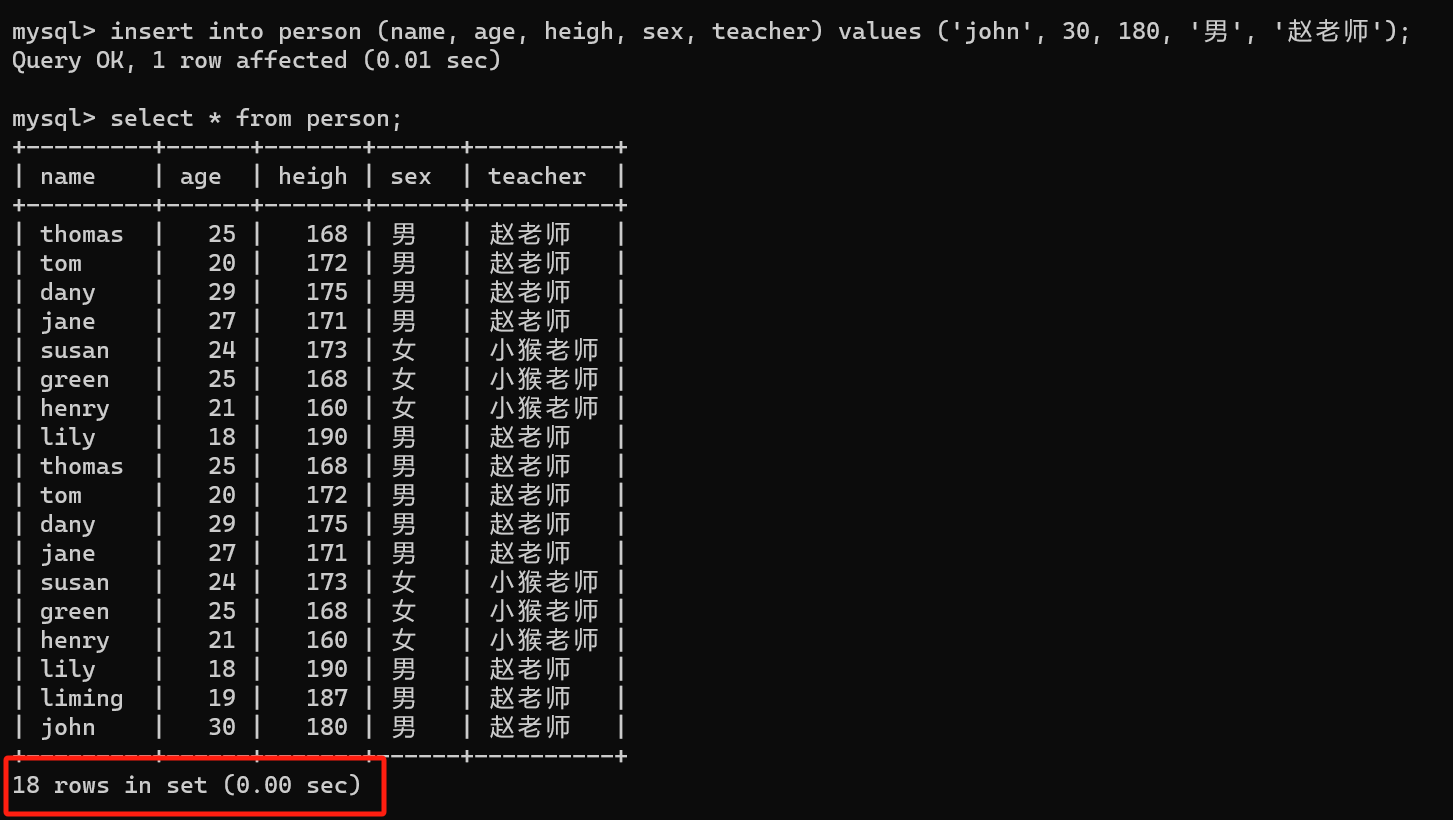
【6】插入新的字段
insert into 表名 (列1, 列2, 列3, ...) values (值1, 值2, 值3, ...);
insert into person (name, age, heigh, sex, teacher) values ('john', 30, 180, '男', '赵老师');
查看数据库的信息
- show用于显示数据库服务器状态或元数据信息。
- desc用于描述表的结构,包括字段名、数据类型等。
- select用于从数据库表中查询数据。
SQL操作数据库基础
查看所有的数据库
show databases;
创建数据库
create database 数据库名字;
create database today01;
删除数据库
drop database [if exists]数据库库名
drop database today01
更改数据库
alter database 数据库名 character set 编码集;
--------------------------------------------------------------------
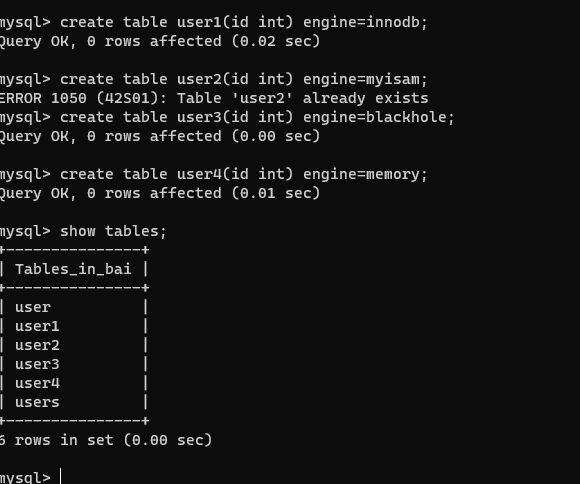
查看所有表
show tables;
创建表
create table 表名(
username varchar(255),
password int(11)
);
# 1. create table 表名
# 字段名 字段类型(字段长度)字段约束条件
# 2. null / not null / zerofill
# 3. 每个字段定义要用 , 隔开
# 4. 最后一个点不能有符号结尾
查看表的结构
describe user;
desc user;
Feild: 字段名称
Type: 字段类型
Null: 是否可以为空
Key: 是否为主键
Default: 默认值
Extra: 注释
查看创建表语句
show create table 表名;
show create table user;
show create table user \g;
show create table user \G;
删除表
drop table 表名
修改表
alter table 表名 modify 字段名 字段类型;
alter table user modify password char;
重置表的信息
truncate table 表名;
----------------------------------------------------------------------------------------------------------------------------------------
插入数据
insert into 表名(字段1,字段2) values(字段值1,字段值2);
insert inot 表名 values(字段值1,字段值2); -- 只能按照字段位置插入
insert into user(id,username,password) values(1,'mao','');
insert inot user values(2,'jing','123');
查询数据
查看当前表下面的所有数据
select * from 表名;
查询当前表下面的指定字段的数据
select 字段名 from 表名;
select username from user;
更改数据
updata 表名 set 需要更改的值 where 筛选条件;
updata user set username where id =2;
删除数据
delete from 表名 where 筛选条件
delete user set username where id =2;
【1】创建数据库
-
MySQL:
使用MySQL命令行工具,可以按如下方式创建数据库:
bashCopy Codemysql -u username -p # 输入密码后登录到MySQL CREATE DATABASE database_name;其中,
username是你的MySQL用户名,database_name是要创建的数据库名称。 -
PostgreSQL:
使用PostgreSQL命令行工具,可以按如下方式创建数据库:
bashCopy Codecreatedb -U username database_name其中,
username是你的PostgreSQL用户名,database_name是要创建的数据库名称。 -
SQLite:
使用SQLite命令行工具,可以按如下方式创建数据库:
bashCopy Codesqlite3 database_name.db其中,
database_name是要创建的数据库文件名。
我这里用MySQL数据库来作示例
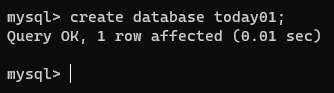
create database 数据库名;
create database today01
【2】查看数据库
show databases;
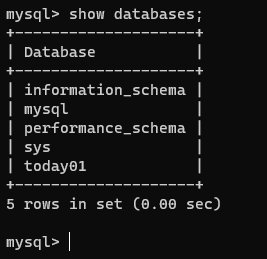
查看指定库:
show create database bai;
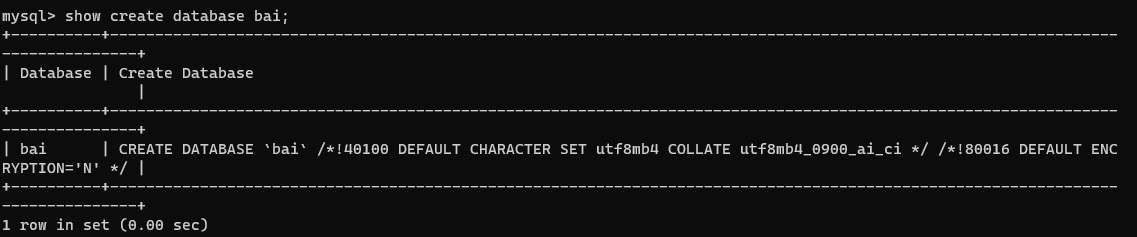
查看当前数据库的字符集和排序规则:
SELECT DEFAULT_CHARACTER_SET_NAME, DEFAULT_COLLATION_NAME FROM INFORMATION_SCHEMA.SCHEMATA WHERE SCHEMA_NAME = 'bai';

【3】修改数据库
(1)
语法:
alter database 数据库名 [character set 编码字符集];
示例:
这将显示数据库 “bai” 的默认字符集和排序规则
ALTER DATABASE bai CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci;

(2)
alter database db2 charset set ='utf8';

【4】删除数据库
drop database 数据库名字;
-- 判断当前数据库是否存在,如果存在则删除
drop database if exists 数据库名字;
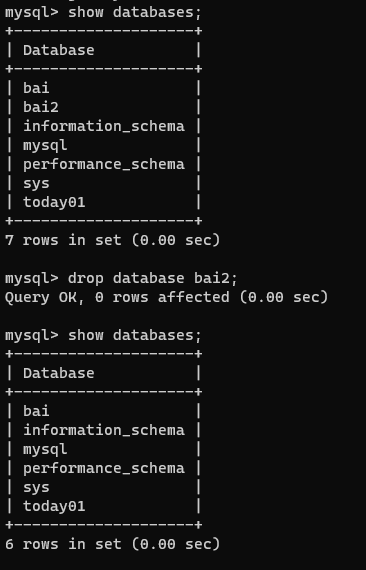
切换数据库
【1】切换数据库
use 数据库名字;
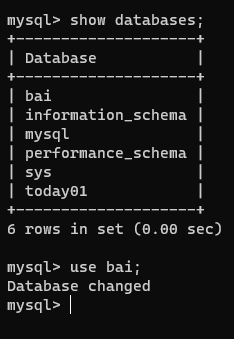
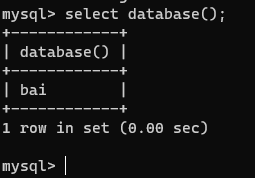
【2】查看当前数据库所在的名字
select database();
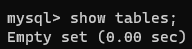
【3】查看当前数据库下的所有库
show tables;
【4】创建数据库下面的表
create table 表名(
字段名1 数据类型1[(存储空间) 字段约束],
字段名2 数据类型2[(存储空间) 字段约束]
);
create table users(
id int primary key,
name varchar(50),
age int
);
create table user (
username varchar(255),
password varchar(255)
);
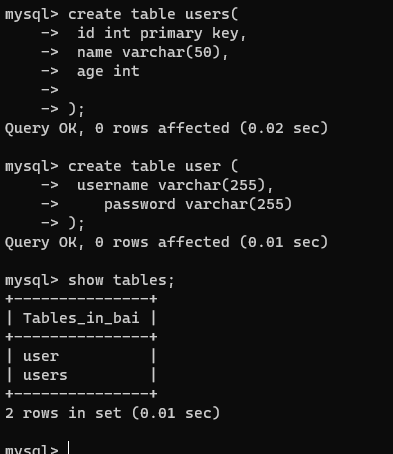
我创建了两个table表
【5】查看当前表的详细信息
describe 表名;
desc 表名;
desc user;
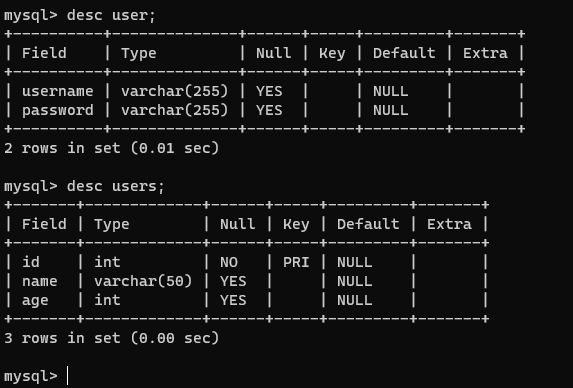
-
查看我创建的表的语句
-
show create table 表名 \G;show create table user \G;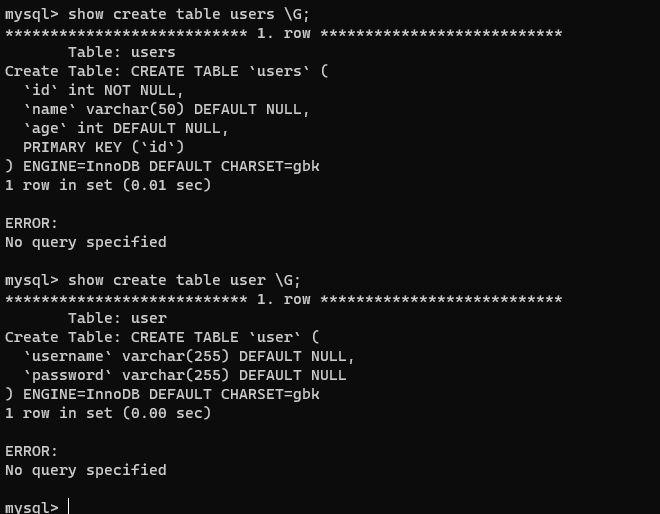
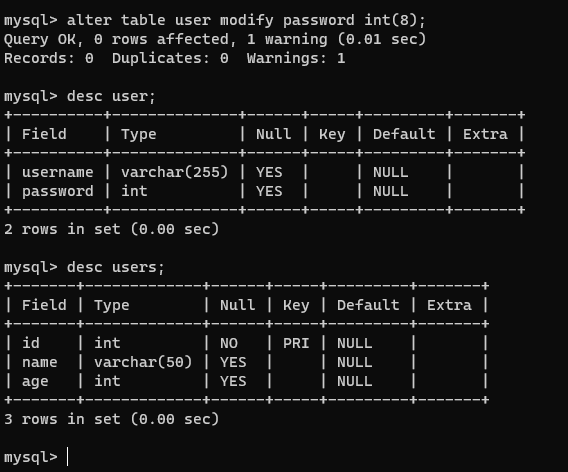
【6】修改表的字段
alter table 表名 modify 字段名 字段类型;
alter table user modify passowrd int(4);
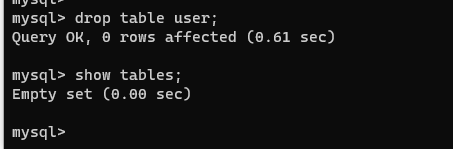
【7】删除表
drop table 表名;
drop table user;
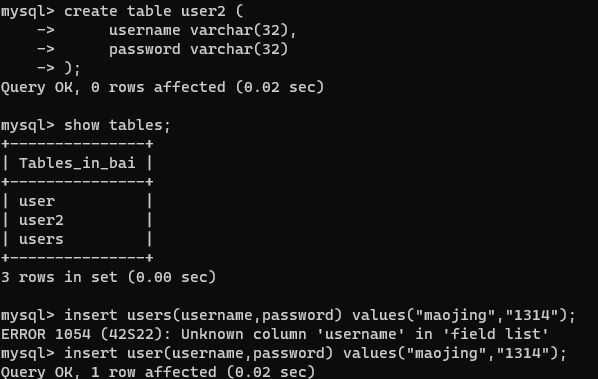
插入表中的数据
【1】插入数据
insert 表名(字段名) values(值)
create table user2 (
username varchar(32),
password varchar(32)
);
insert users(username,password) values("maojing","1314");
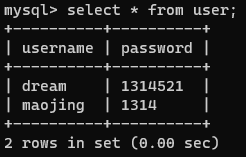
【2】查看表中的数据
select * from user;
【3】更改表中的数据
update 表名 set 需要改的数据 where 筛选条件;
这个是更改一个
update user set password="123" where username="tian";
这个是更改两个
UPDATE user SET password = '520' WHERE username IN ('tian', 'maojing');

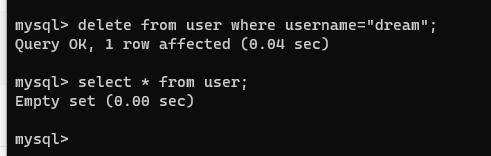
【4】删除数据
-- 按照指定条件删除数据
delete from 表名 where 筛选条件;
-- 直接清空表
delete from 表名;
delete from user where username="dream";
【一】什么是存储引擎
存储引擎是数据库系统中负责管理数据的核心组件之一。它定义了数据库如何在磁盘上存储和访问数据。
- 日常生活中文件格式有很多,并且针对不同的文件格式会有对应不同的存储方式和处理机制
- 针对不同的数据应该有对应的不同的处理机制
存储引擎就是不同的处理机制
【二】MySQL主要的存储引擎
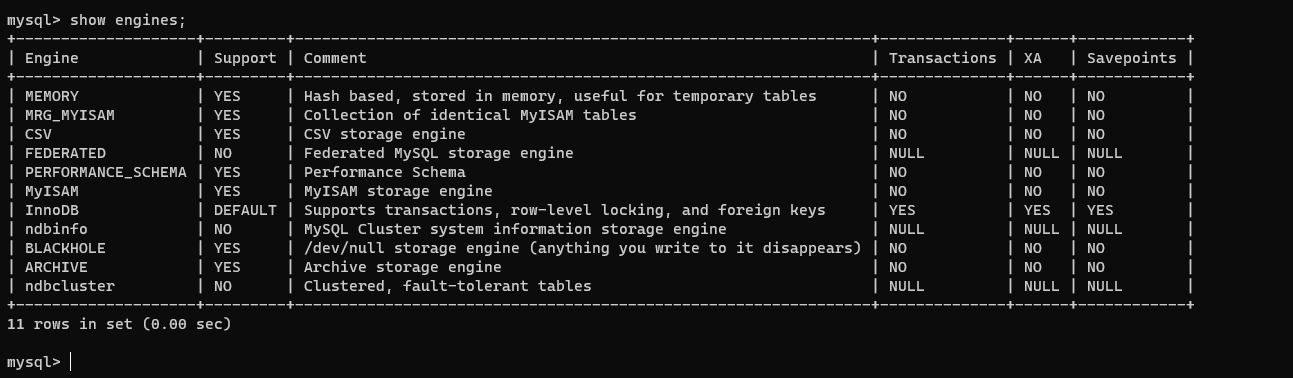
- InnoDB(默认引擎):
- 支持事务处理,具有ACID(原子性、一致性、隔离性和持久性)特性。
- 支持行级锁定,提供高并发性能。
- 支持外键约束和关联关系。
- 支持崩溃恢复和故障转移。
- 使用聚簇索引来加速查询。
- MyISAM:
- 不支持事务处理,不具备ACID特性。
- 支持表级锁定,对于并发性能较差。
- 不支持外键约束和关联关系。
- 适用于读密集型应用,如数据仓库、报告等。
- 以表文件的形式存储数据,易于备份和迁移。
- Memory(也称为Heap):
- 将表数据存储在内存中,速度非常快。
- 不支持事务处理,不具备持久性。
- 表数据在服务器重启后会丢失。
- 适用于临时数据存储、缓存或者需要高速读写操作的场景。
- blackhole (黑洞引擎)
- 无论存什么都会立刻消失
【三】如何查看数据库引擎
show engines;
【四】不同引擎下的表的特性
【1】创建表
create table user1(id int) engine=innodb;
create table user2(id int) engine=myisam;
create table user3(id int) engine=blackhole;
create table user4(id int) engine=memory;
(1)Innodb
- user1.frm
- 表结构
- user1.ibd
- 表结构
Innodb:默认的引擎
(2)myisam
- user2.frm
- 表结构
- user2.MYD
- 表数据
- user2.MYI
- 索引(index),类似于书的目录,基于目录查找数据的速度会很快
myisam:数据具有索引,读取数据快
(3)blackhole
- user3.frm
- 表结构
blackhole:黑洞引擎,存什么数据都会消失
(4)memory
- user4.frm
- 表结构
memory:数据缓存到内存
【2】插入数据
insert into user1 values(123);
insert into user2 values(123);
insert into user3 values(123);
insert into user4 values(123);
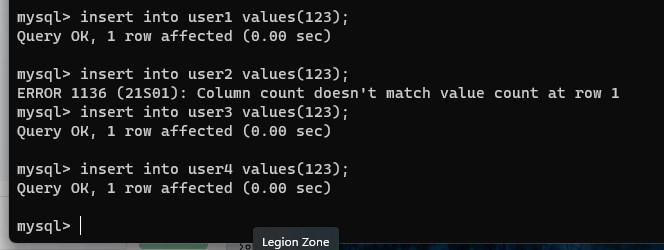
【3】查看数据
select * from user1;
select * from user2;
select * from user3;
select * from user4;
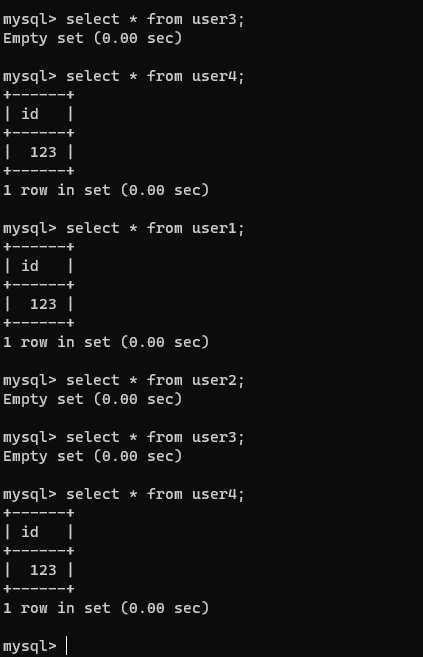
除了黑洞引擎都存在数据
memory 数据是存在内存中的,如何印证?
- 重启mysql服务
【一】创建表的完整语法
create table 表名 (
字段名 字段类型(宽度) 约束条件
);
-- 最后一个字段不能以 , 结尾
-- 字段名和字段类型是必须的条件
CREATE TABLE 表的名称 (
column1 datatype constraint,
# 字段名 字段类型(宽度) 约束条件
column2 datatype constraint
...
CONSTRAINT constraint_name,
# 是对列的约束条件
... ) ENGINE = storage_engine;
# 存储引擎
- 约束条件可选,约束条件可以写多个
表的名称:替换为你想要创建的表的名称。column1、column2:替换为表中的列名。datatype:替换为对应列的数据类型。constraint:替换为对列的约束条件。constraint_name:替换为约束条件的名称。storage_engine:替换为你想要使用的存储引擎,如 InnoDB、MyISAM 等。
【二】基础语法
-- 这三个条件必须存在
create table 表名(
字段名 字段类型
);
create table user(id int);
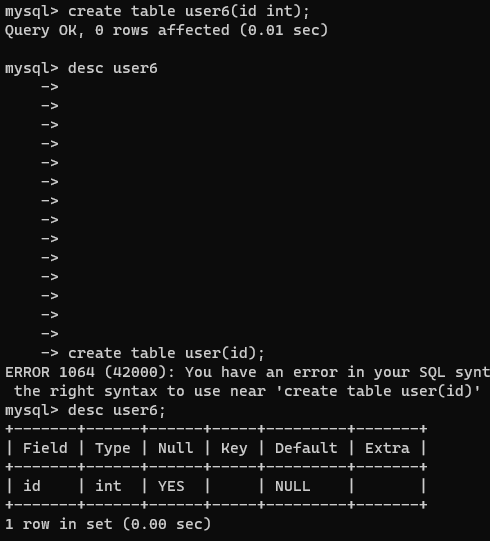
【三】什么是宽度
- 一般情况下指的是对存储数据的限制
- 默认宽度为 1(只能存一个字符)
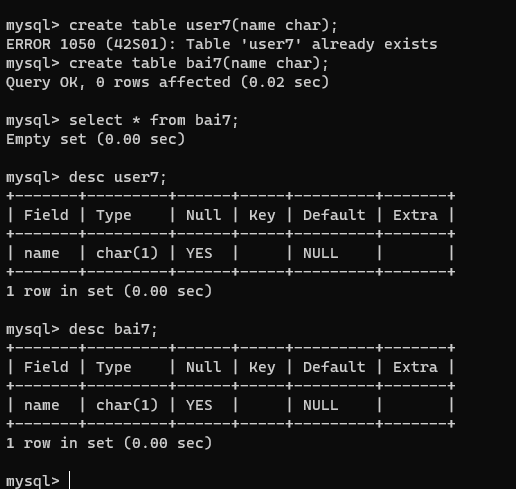
- 创建表
create table user7(name char);
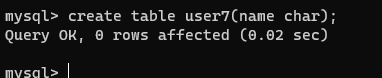
- 查看表的详细信息
desc user7;
desc bai7;
【四】null 和 not null
- not null 约束当前字段条件不能为空
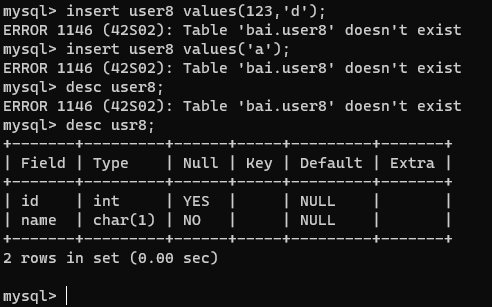
create table usr8(id int,name char not null);
insert user8 values(123,'d');
insert user8 values('a');
【五】严格模式
本质上是为了约束我们sql语法规范的,我们可以不按照约束做事,修改他的约束。
%:匹配任意个字符
_:匹配当前字符
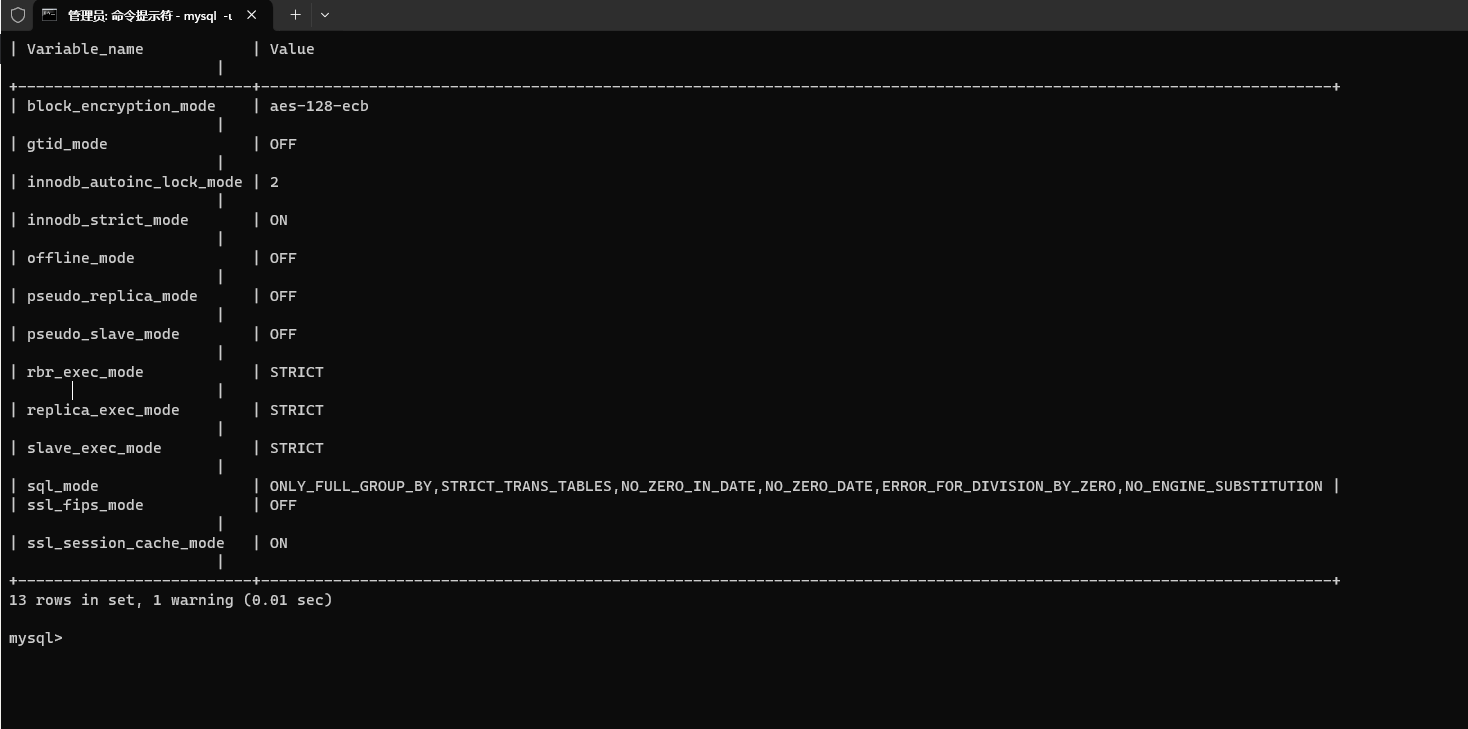
【1】查看严格模式
show variables like "%mode";
【2】修改严格模式
- 全局生效
set global sql_mode = 'ONLY_FULL_GROUP_BY,STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_AUTO_CREATE_USER,NO_EN'
- 只对当前窗口生效
set session sql_mode = 'ONLY_FULL_GROUP_BY,STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_AUTO_CREATE_USER,NO_EN'
【3】严格模式到底开启还是不开启
- 5.7 之后的版本默认都是开启严格模式的
- 尽量减轻数据库的负担,不给数据库增加额外的压力
基本数据类型之整型
【1】整型的分类
tinyint smallint mediumint int bigint
【2】整型的符号
符号不是用来限制位数的而是用来控制显示长度的
【3】tinyint
- 是否带符号
- 默认情况下是带符号, 默认带的符号是 + 号
- 超出最大范围
- 超出会报错
【4】unsigned(无符号)
- 每个整数类型都有无符号的取值范围,超出指定范围就会报错
基本数据类型之浮点型
【1】浮点型的作用
- 为了更高的精确度
【2】浮点数的分类
-
float double decimal
【3】浮点数的精确度标准
double 16
decimal
基本数据类型值字符类型
【1】字符的分类
- char —> 默认长度是1个单位
- varchar —>必须给长度
create table a1(
age char
);
create table a2(
age varchar(255)
);
【2】char 和 varchar 的区别
- char :定长 超出长度会报错, 不够机会用空格补 -----以前常用
- varchar: 不定长 超出长度会报错 ----- 现在常用
【3】char_length : 统计字段长度
select char_length(字段名) from 表名;
select char_length(age) from a2;
【4】char跟varchar 的优缺点:
(1)char
- 缺点:浪费空间
- 优点:存储简单
- 直接按照固定的字符存储数据即可
(2)varchar
- 优点:节省空间
- 缺点:存储麻烦
- 存的时候,在真正数据的前面加报头(表示数据真正大小)
- 取的时候,需要先读取报头,才能读取真实的数据
以前用 char 现在 varchar 使用较多
基本数据类型之时间类型
【1】时间类型的分类
- date
- 年月日
- datetime
- 年月日时分秒
- time
- 时分秒
- year
- 年
【2】时间类型的创建
create table student(
id int,
name varchar(16),
born_year year,
birth date,
study_time time,
reg_time datetime
);
【3】插入数据
insert into student values(
1,
'mao',
'2001',
'2001-1-31',
'11:11:11',
'2023-6-30 11:11:11'
);
基本数据类型之枚举与集合类型
【1】枚举
(1)枚举类型
enum: 多选一: 多个选择条件只能选择其中一个
(2)集合类型
set: 多选多
【2】枚举的使用方法
create table user(
id int,
name char(16),
gender enum('male','female','others')
);
插入数据
insert into user values(1,'mao','male')
insert into user values(1,'mao','male'),(2,'jing','female'),(3,'yi','others')
-
只能插入我 定义的 gender enum('male','female','others')
【2】集合类型
create table teacher(
id int,
name varchar(16),
gender enum('male','female','others'),
hobby set('read books','listen music','play games')
);
插入数据
insert into teacher values('1','bai,'male','read books');
insert into teacher values('2','zhi,'male','listen music');
约束条件
【一】什么是约束条件
-
约束条件:限制表中的数据,保证添加到数据表中的数据准确和可靠性!凡是不符合约束的数据,插入时就会失败!
-
约束条件在创建表时可以使用,也可以修改表的时候添加约束条件
【二】约束条件概览
- 主键约束(primary key)
- 外键约束(foreign key)
- 唯一约束(unique)
- 非空约束(not null / null)
- 零值填充(zerofill)
- 无符号(unsigned)
- 组合约束(not null + unique)
【1】非空约束(not null)
( 1 ) 作用
非空约束要求某个字段的值不能为NULL,即不能为空。
( 2 ) 案例
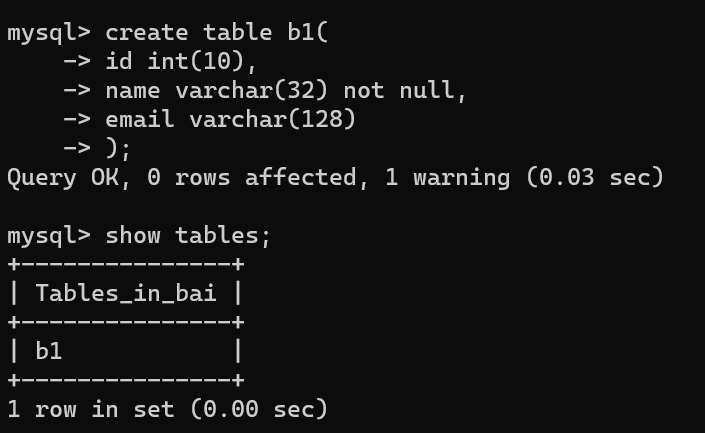
创建 user 表(id ,name, email), name不为空
varchar(字符长度)
create table t_user(
id int(10) ,
name varchar(32) not null,
email varchar(128)
);
【2】唯一约束(unique)
( 1 ) 作用
唯一约束确保了列中的值是唯一的,但可以为空。与主键约束不同,唯一约束允许空值。
( 2 ) 案例
alter table b1 modify email varchar(255) unique;
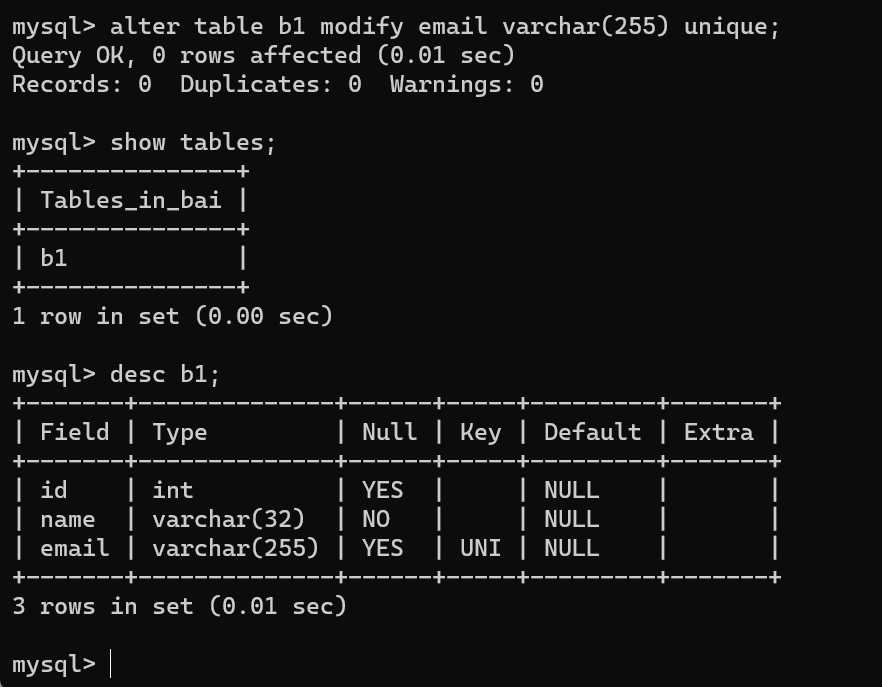
创建表时指定唯一约束
create table table_name (
id int,
column1 data_type unique,
...
);
修改表结构时指定唯一约束
alter table table_name
add unique (column1);
【3】zerofill
填充字段长度的,当字段值不够字段长度的时候会使用0填充至指定长度。
案例:创建表时指定零值填充
create table table_name (
id int,
column1 int zerofill,
...
);
修改表结构时指定零值填充:
alter table table_name
modify column1 int zerofill;
---------------------------------------------------------------------------------------------------------------------------------------------------
【4】组合使用
( 1 ) 作用
- 组合约束是指多个约束的组合使用。使用表级约束给多个字段联合添加约束,unique (name,email) 名字和邮箱这两个字段不能同时重复,但是名字和邮箱字段可以单独重复。
- 可以给表级约束起名字,这样可以便于操作这个操作(删除、修改等)
( 2 ) 案例 not null 和 unique 同时使用(列级约束)
- 被 not null 和 unique 约束的字段,该字段即不能为 NULL 也不能重复;
创建表
create table b2(
id int(10),
name varchar(98) not null unique
);
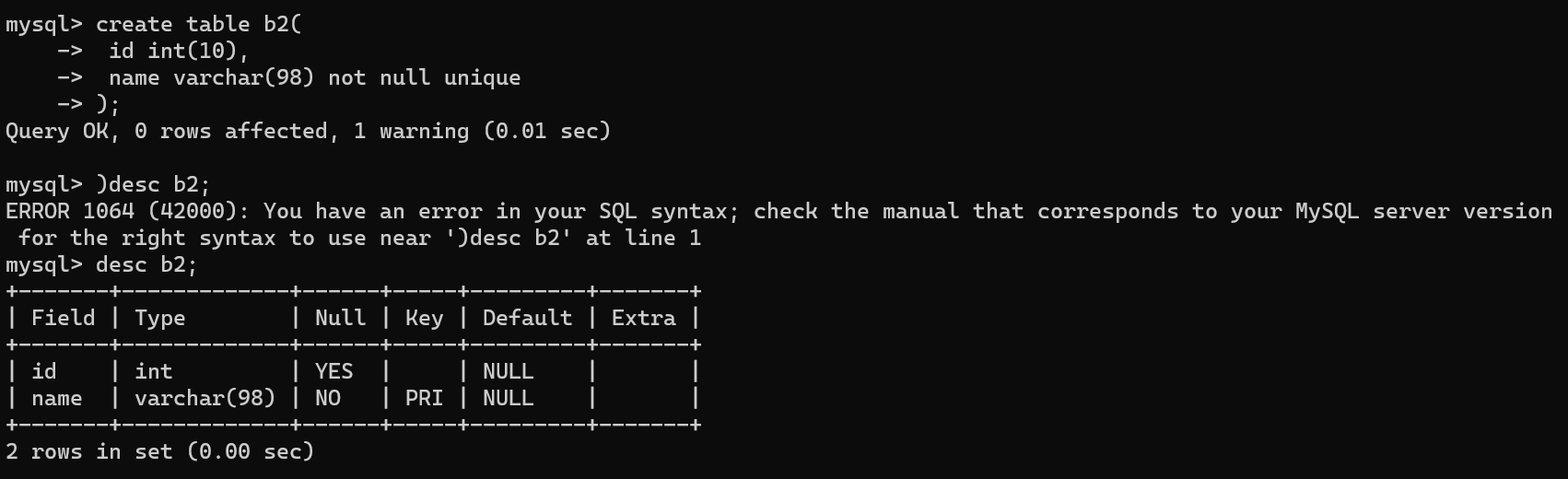
插入数据
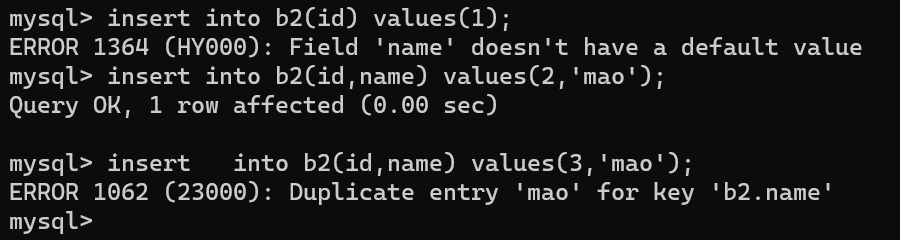
insert into b2(id) values(1);
# ERROR 1364 (HY000): Field 'name' doesn't have a default value 由于name字段不能为空,所以会报错
insert into b2(id,name) values(2,'mao');
insert into b2(id,name) values(3,'mao');
# ERROR 1062 (23000): Duplicate entry 'mao' for key 'b2.name' 由于name字段唯一,所以重复数据会报错
【5】查看当前表的约束条件
- 给约束条件添加名字
查看数据库
show databases;
切换数据库
use information_schema;

show tables;
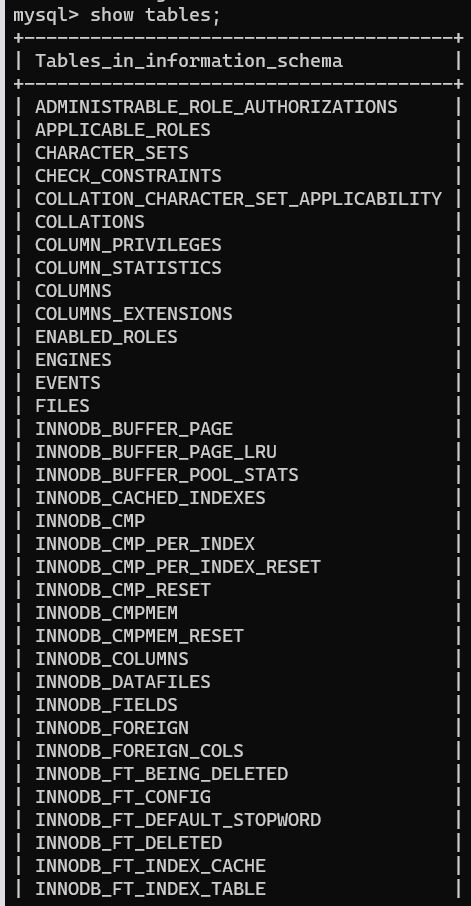
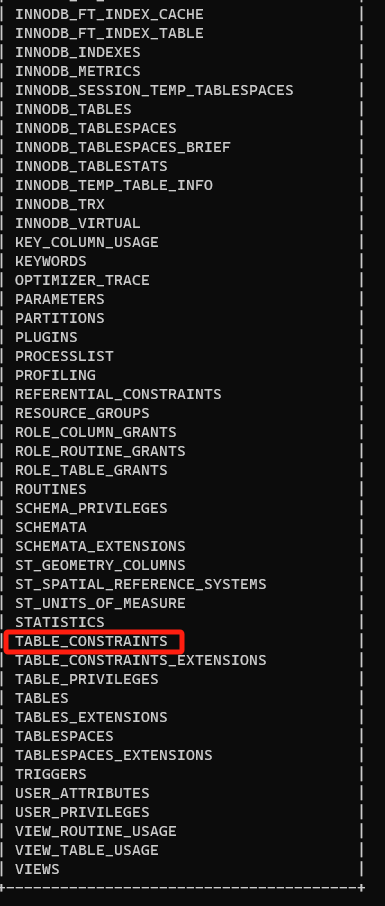
table_constraints 该表专门存储约束信息
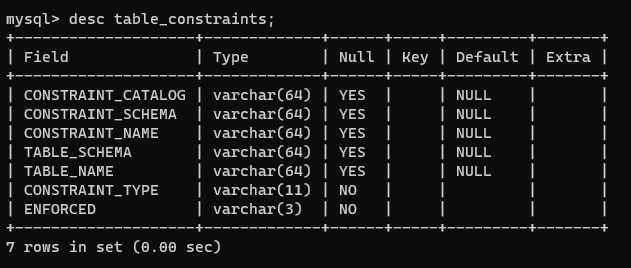
desc table_constraints;
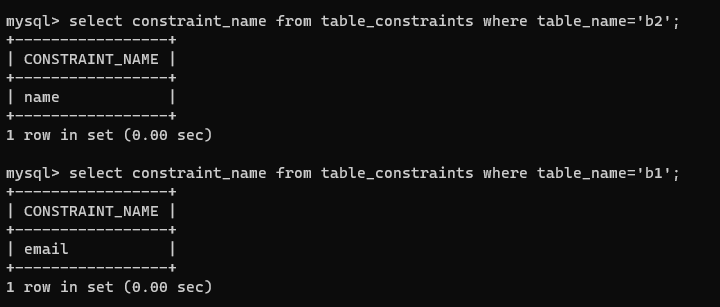
查看某张表存在哪些约束条件?
select constraint_name from table_constraints where table_name='表名';
select constraint_name from table_constraints where table_name='b2';
---------------------------------------------------------------------------------------------------------------------------------------------------
【6】主键约束(primary key + auto_increment)
( 1 ) 主键约束、主键字段、主键值三者之间关系
- 表中某个字段添加主键约束之后,该字段被称为主键字段
- 主键字段中出现的每一个数据都被称为主键值;
主键是一种唯一标识符,用于在表中标识每一行数据。主键约束确保了主键列中的值是唯一的,且不能为空。
( 2 ) 案例
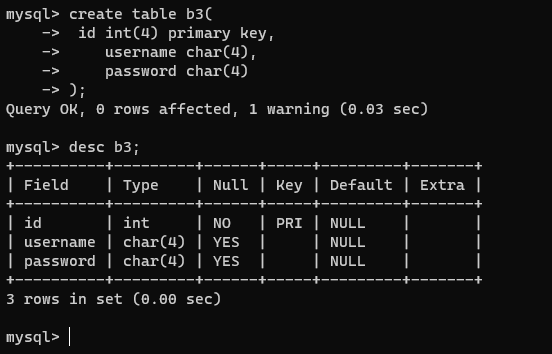
- 单一约束:加载建表字段的约束条件里
create table b3(
id int(4) primary key,
username char(4),
password char(4)
);
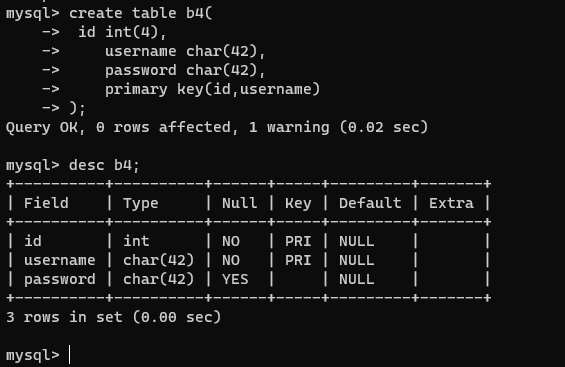
- 复合约束:可以给多个字段同时加主键约束
create table b4(
id int(4),
username char(42),
password char(42),
primary key(id,username)
);
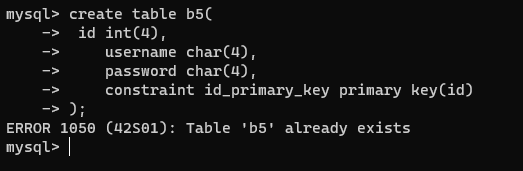
- 先创建一个b5
create table b5(
id int(10) primary key,
name varchar(98)
);
# ERROR 1050 (42S01): Table 'b5' already exists
# 已经存在名为b5的表。在MySQL中,每个表的名称必须是唯一的,所以无法创建一个已经存在的表。
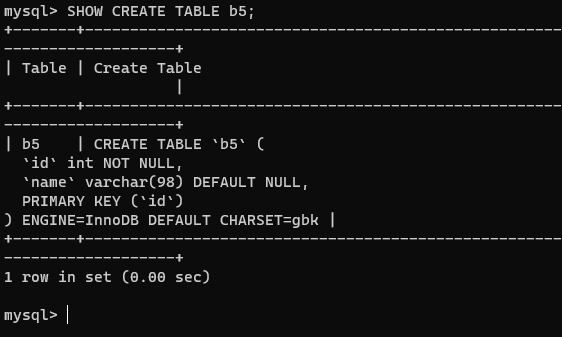
- 查看现有表的创建语句,以获得主键的名称。
show create table b5;
- 然后,使用
ALTER TABLE语句删除现有的主键约束,并使用新的名称创建一个新的主键约束。例如,假设主键约束的名称为id_primary_key,你想将其重命名为new_primary_key:
alter table b5
drop primary key,
add constraint null primary key(id);
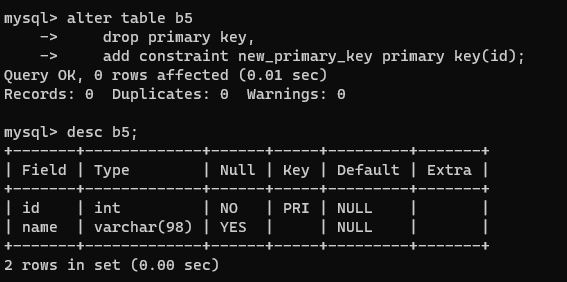
- 给列重命名
如果你想给已经存在的表中的列重命名,可以使用alter table语句。以下是将b5表中的id列重命名为pass的示例:
alter table b5 change column id pass int(4);
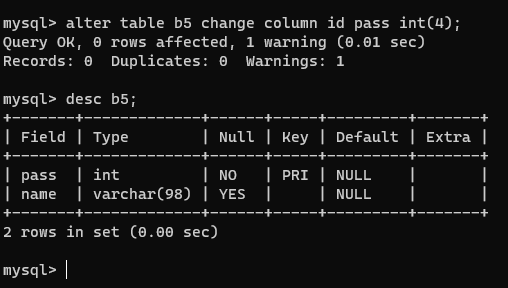
- 修改主键约束的名称
alter table b5 drop primary key, add constraint id_primary_key primary key(pass);
# primary key(pass) 这个就是键的值 你要确定id里面有没有pass这个值。
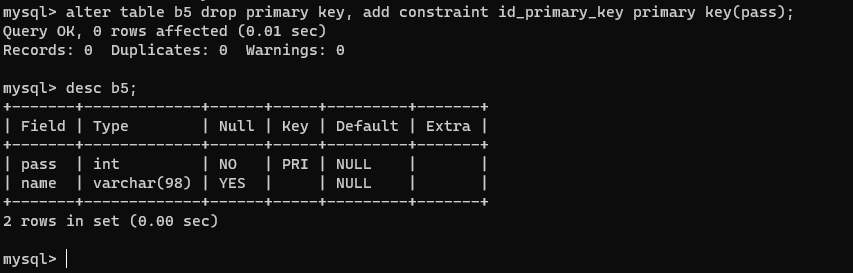
【7】主键根据性质分类
- 自然主键:主键值若是一个自然数,并且这个自然数与业务没有任何关系,这种主键称为自然主键;
- 业务主键:主键值若和当前表中的业务紧密相关,那么这种主键值被业务主键;如果业务发生改变时,业务主键往往会受到影响,所以业务主键使用较少,大多情况使用自然主键。
【8】自动生成主键 auto_increment
创建一个新的表
create table b6 (
id int auto_increment primary key,
name varchar(50),
age int
);
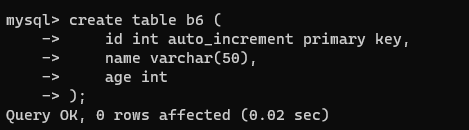
插入数据时,在需要自动生成主键的列上插入NULL值。MySQL会自动为该列生成唯一的主键值。
insert into b6(name, age) values ('mao', 25),('jing',18);
“b6” 的数据库表中检索所有的数据行和列。
select * from b6;
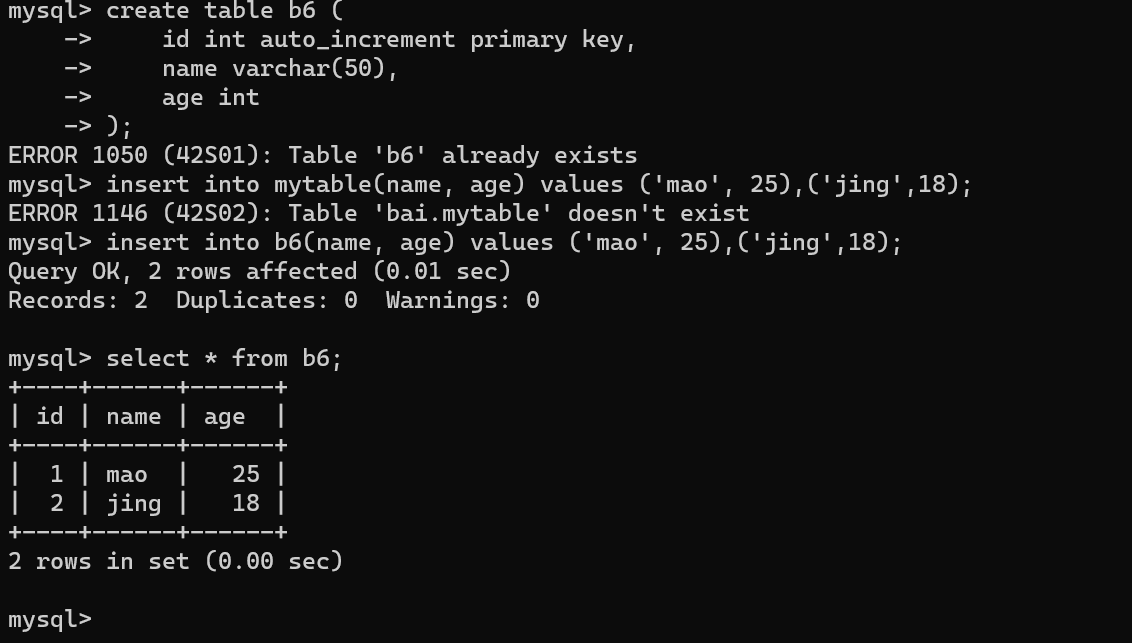
- AUTO_INCREMENT 自动递增表示自动递增。这意味着每次向数据表插入新记录时,该字段的值会自动递增生成,而不需要手动指定具体的值。
- 自增主键的特点就是
- 在插入数据的时候不指定自增主键的值,就会默认向上增加
- 再删除该数据后,会发现原来的自增还在,新数据在旧数据的id基础上自增
- 重置表信息
truncate b6;
# 会将原来的表里面的所有数据都清空,包括你的自增逐渐ID重置为1
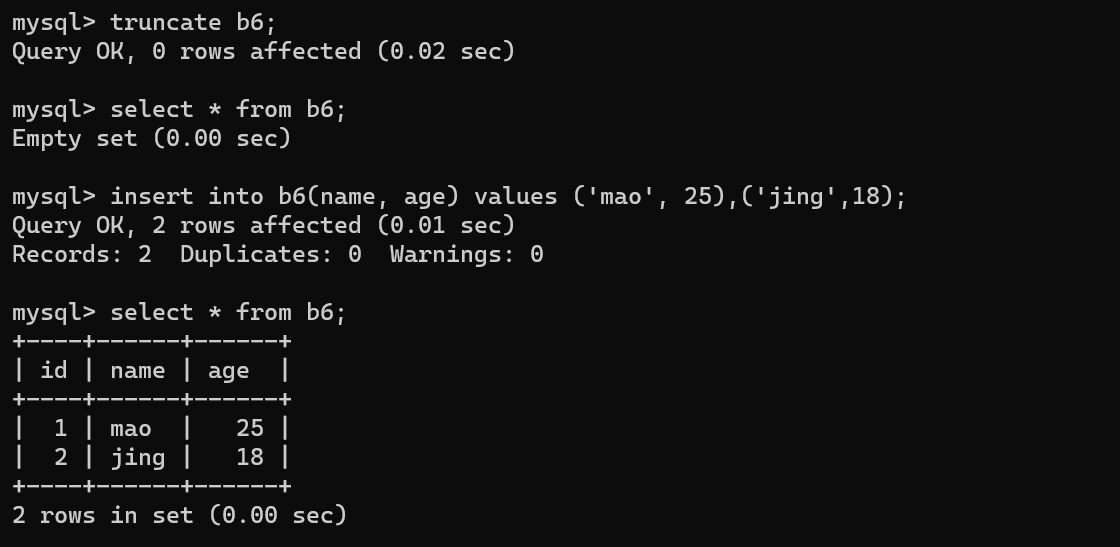
---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
【9】外键约束FK (foreign key)
外键约束用于定义表之间的关系,在一个表中创建一个外键指向另一个表的主键。它可以保证数据之间的引用完整性,例如在两个表之间建立关联关系、实现级联删除等。
三个概念
- 外键约束,外键字段,外键值
- 外键约束:添加在建表语句字段类型后面的约束条件 foreign key
- 外键字段:某个·字段添加外键约束之后,该字段为外键字段。
- 外键值:外键字段中的每一个数据都是外键值。
外键类型
- 外键字段
- 逻辑性外键:理论上存在外键关系,实际上没有建立外键联系
- 物理性外键:理论上存在外键关系,并且字段具有外键约束
【10】外键语法
- 先要创建表
- 先有了需要被建立关系的表才能让建立关系的表和他建立关系
create table 表名1 (
-- 外键自增字段
id int(4) primary key auto_increment,
字段名1 字段类型1 约束条件1 comment 注释1,
字段名2 字段类型2 约束条件2 comment 注释2
);
create table 表名2 (
id int(4) primary key auto_increment,
字段名1 字段类型1 约束条件1 comment 注释1,
字段名2 字段类型2 约束条件2 comment 注释2,
foreign key(在表名2中现实的字段名) references 表名1(表名1中需要建立外键关系的字段名)
);
comment 就是在后面添加注释用的参数
references 这个是必备参数。如果你不使用 REFERENCES 关键字,就无法创建外键约束,因为它是必需的参数之一。
【11】一对多关系的建表思路
- 先创建两个表,一个为主表(one)和一个为从表(many)
- 在“从表”中 创建一个外键列,该外键列引用了“主表”的主键列。
- 将外键约束添加到“从表”的外键列上,以确定引用的完整性和一致性。
主表:
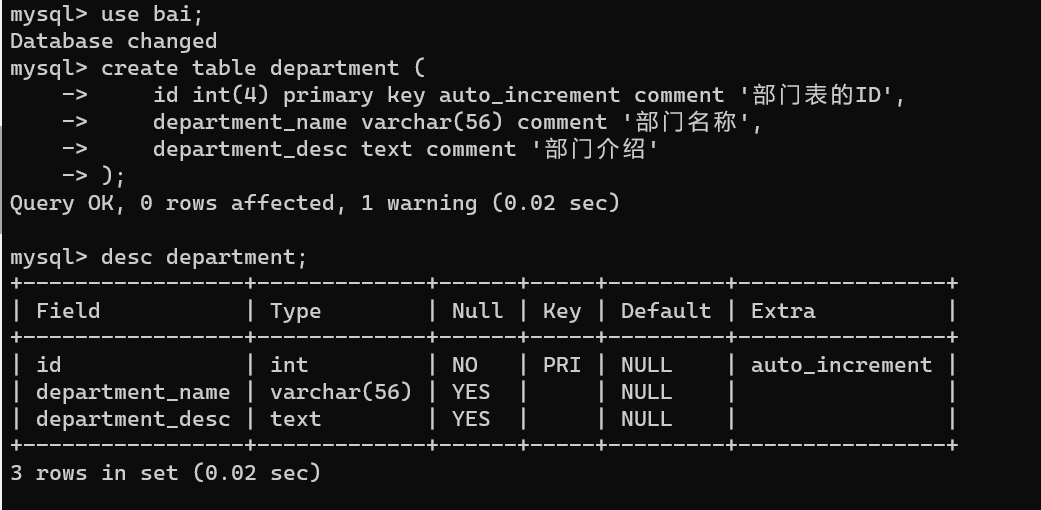
create table department (
id int(4) primary key auto_increment comment '部门表的ID',
department_name varchar(56) comment '部门名称',
department_desc text comment '部门介绍'
);
从表:
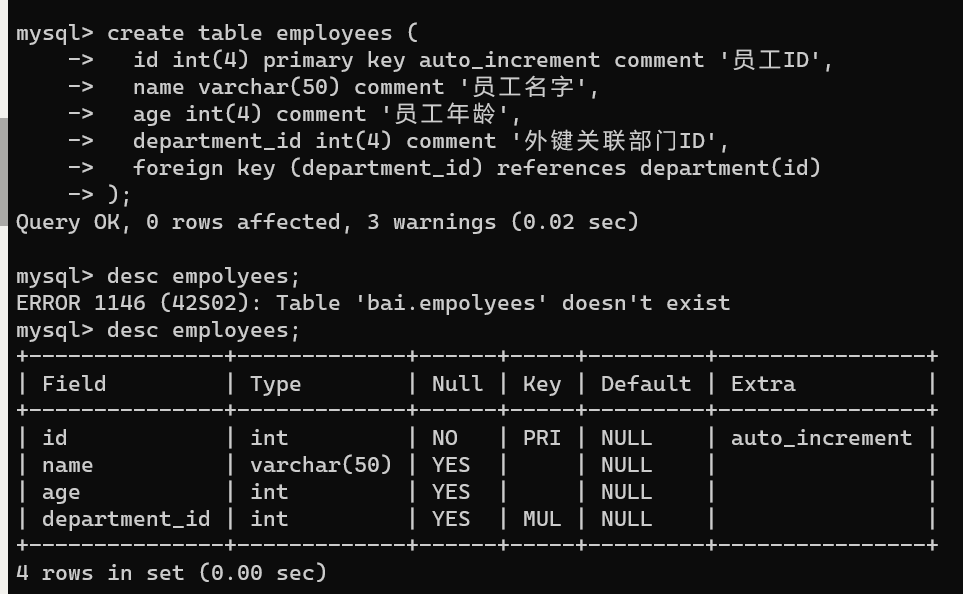
create table employees (
id int(4) primary key auto_increment comment '员工ID',
name varchar(50) comment '员工名字',
age int(4) comment '员工年龄',
department_id int(4) comment '外键关联部门ID',
foreign key (department_id) references department(id)
);
如果你不使用 references 关键字,就无法创建外键约束,因为它是必需的参数之一。
drop table employees;
drop table department;
- 创建顺序
- 先创建被关联的表
- 再创建需要添加外键字段的表
- 删除顺序
- 先删除添加外键字段的表
- 再删除被关联的表
【12】外键联系的分类
-
一张表和另一张表建立联系
-
一对一
-
一对多
-
多对多
-
没关系
-
【1】一对多关系
- 以员工表和部门表来说
- 员工可不可以只对应一个部门?
- 默认是可以的
- 部门是不是可以有多个员工?
- 部门可以有多个员工
- 员工可不可以只对应一个部门?
- 总结
- 部门是一
- 员工是多
- 一对多关系将外键建立在哪一方?
- 将外键建在多的这一方
上面建立部门与员工的表就是一对多的关系
# 员工表
id name age
# 部门表
id department_name department_desc
create table department (
id int(4) primary key auto_increment comment '部门表的ID',
department_name varchar(56) comment '部门名称',
department_desc text comment '部门介绍'
);
create table employees (
id int(4) primary key auto_increment comment '员工ID',
name varchar(50) comment '员工名字',
age int(4) comment '员工年龄',
department_id int(4) comment '外键关联部门ID',
foreign key (department_id) references department(id)
);
【2】多对多关系
- 以学生表和课程表来说
- 一个学生可不可以选择多门课程
- 默认是可以的
- 一门课程是不是可以被多名学生选择?
- 一门课程可以被多名课程选择
- 一个学生可不可以选择多门课程
- 总结
- 学生是多
- 课程是多
- 学生跟课程之间的关系就是多对多
-- 建立在第三张表中
第一种:
create table student(
student_id int primary key auto_increment,
student_name varchar(23),
student_grade varcahr(8),
course_id int,
foreign key(course_id) references course(id)
);
create table course(
course_id int primary key auto_increment,
course_name varchar(23),
course_grade varcahr(8),
student_id int,
foreign key(student_id) references student(id)
);
# 这个示例中,你试图在学生表和课程表中都添加了一个外键,以建立多对多关系。这样的设计是不正确的,因为它会导致循环依赖和无法创建外键约束。
第二种 针对多对多关系 需要单独开设第三张表专门存储关系
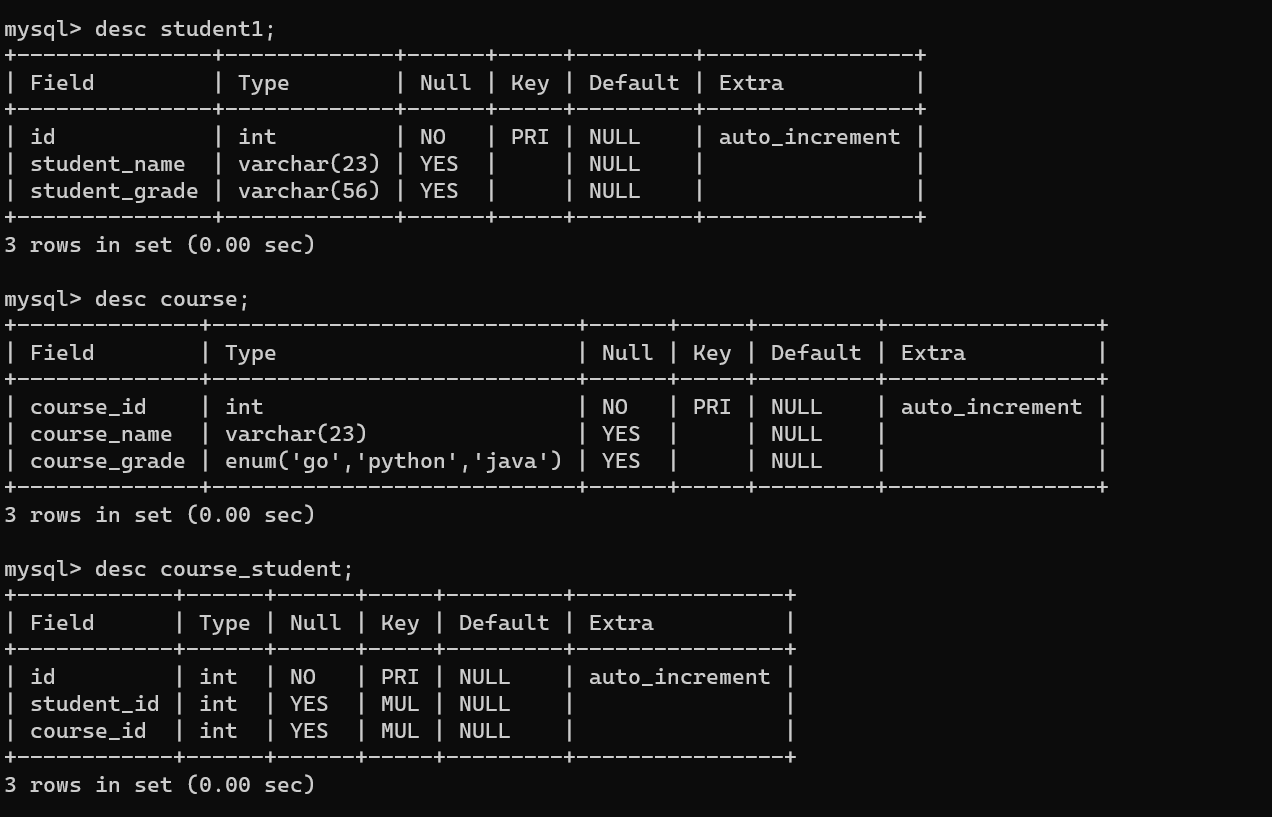
create table student1(
id int primary key auto_increment,
student_name varchar(23),
student_grade varchar(56)
);
create table course(
course_id int primary key auto_increment,
course_name varchar(23),
course_grade enum('go','python','java')
);
create table course_student(
id int primary key auto_increment,
student_id int,
foreign key(student_id) references student1(id),
course_id int,
foreign key(course_id) references course(course_id)
);
【3】一对一关系
原则是那张使用频率搞,外键字段就在哪一方。
-
一个是员工表(employee):包含员工的基本信息,如员工编号、姓名等
-
另一个是工资表(salary):包含员工的薪资信息,如基本工资、津贴等。
其中,每个员工只有一条薪资记录,一个薪资记录也只对应一个员工。
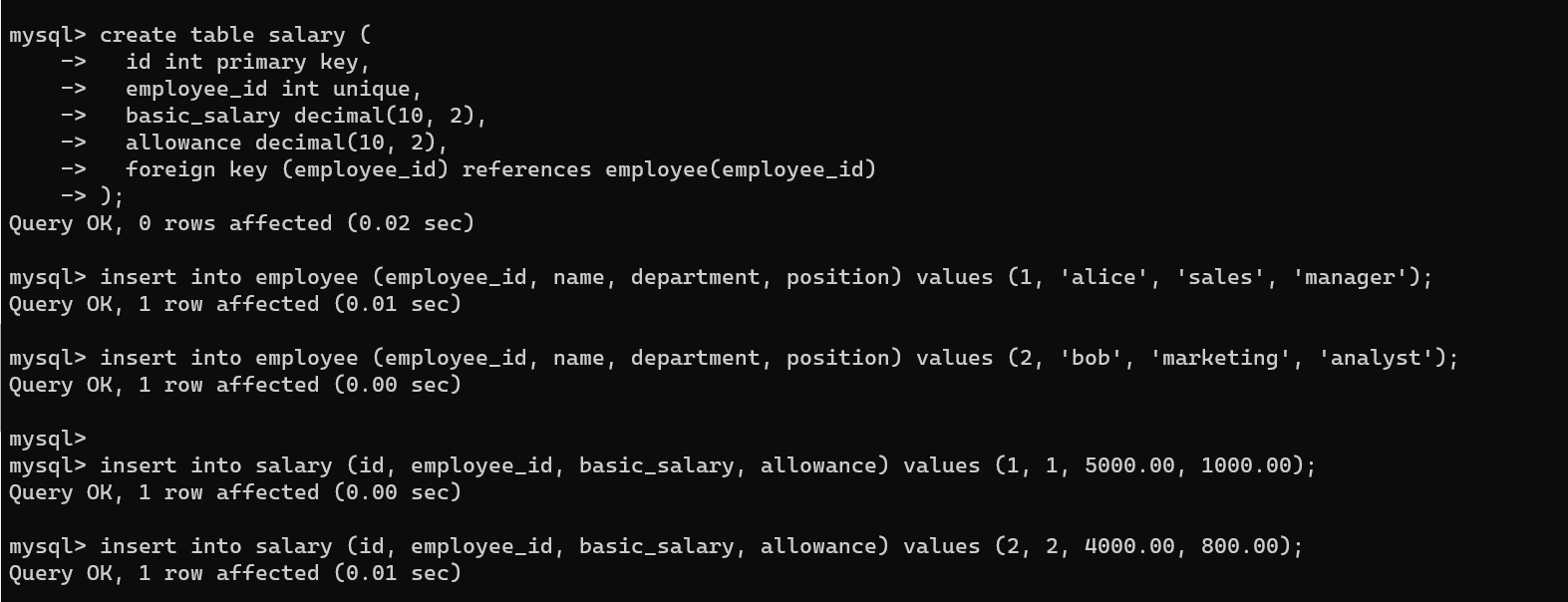
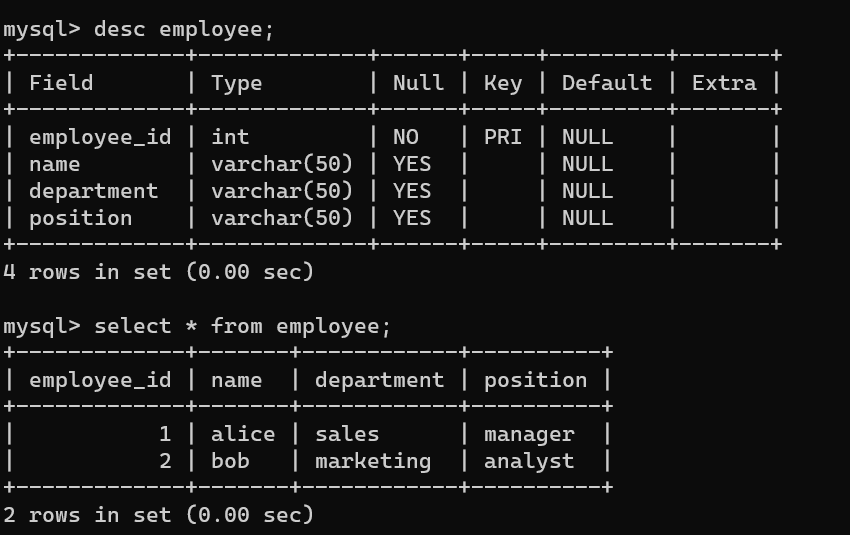
create table employee (
employee_id int primary key,
name varchar(50),
department varchar(50),
position varchar(50)
);
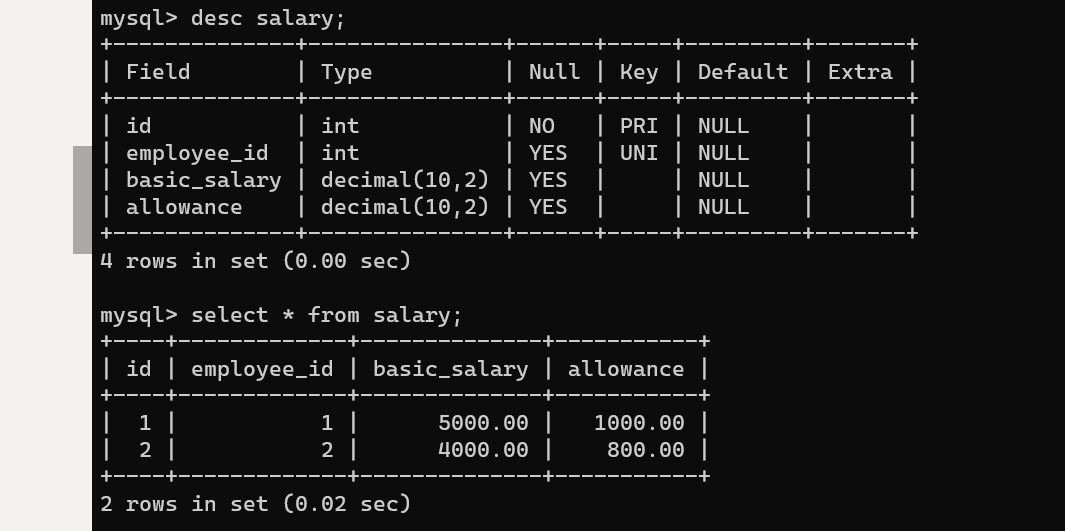
create table salary (
id int primary key,
employee_id int unique,
basic_salary decimal(10, 2),
allowance decimal(10, 2),
foreign key (employee_id) references employee(employee_id)
);
insert into employee (employee_id, name, department, position) values (1, 'alice', 'sales', 'manager');
insert into employee (employee_id, name, department, position) values (2, 'bob', 'marketing', 'analyst');
insert into salary (id, employee_id, basic_salary, allowance) values (1, 1, 5000.00, 1000.00);
insert into salary (id, employee_id, basic_salary, allowance) values (2, 2, 4000.00, 800.00);
数据分类
- 存储和使用频率高的数据称之为热数据
- 存储和使用频率低的数据称之为冷数据
【13】级联更新和级联删除
当两个或者多个表之间存在关联关系,且启用了级联更新或者级联删除规则时,对主表中的数据进行更新或者删除操作时,相关联的从表中的数据也会相应进行更新或者删除。
具体来说:
- 级联更新(on update cascade):当主表中的某一行数据的关联字段(外键字段)发生了更新时,所有相关联的从表中的对应的关联字段也会进行相应的更新。这样可以保证从表中的数据与主表的数据保持一致。
- 级联删除(on delete cascade):当主表中的某一行数据被删除时,所有相关联的从表中的对应行也会被自动删除。这样可以确保主表和从表之间的数据的完整性,避免出现孤立的数据。
需要注意的是,启用级联更新或级联删除规则需要谨慎操作,因为它们可能会导致连锁反应,对数据库的性能产生影响。
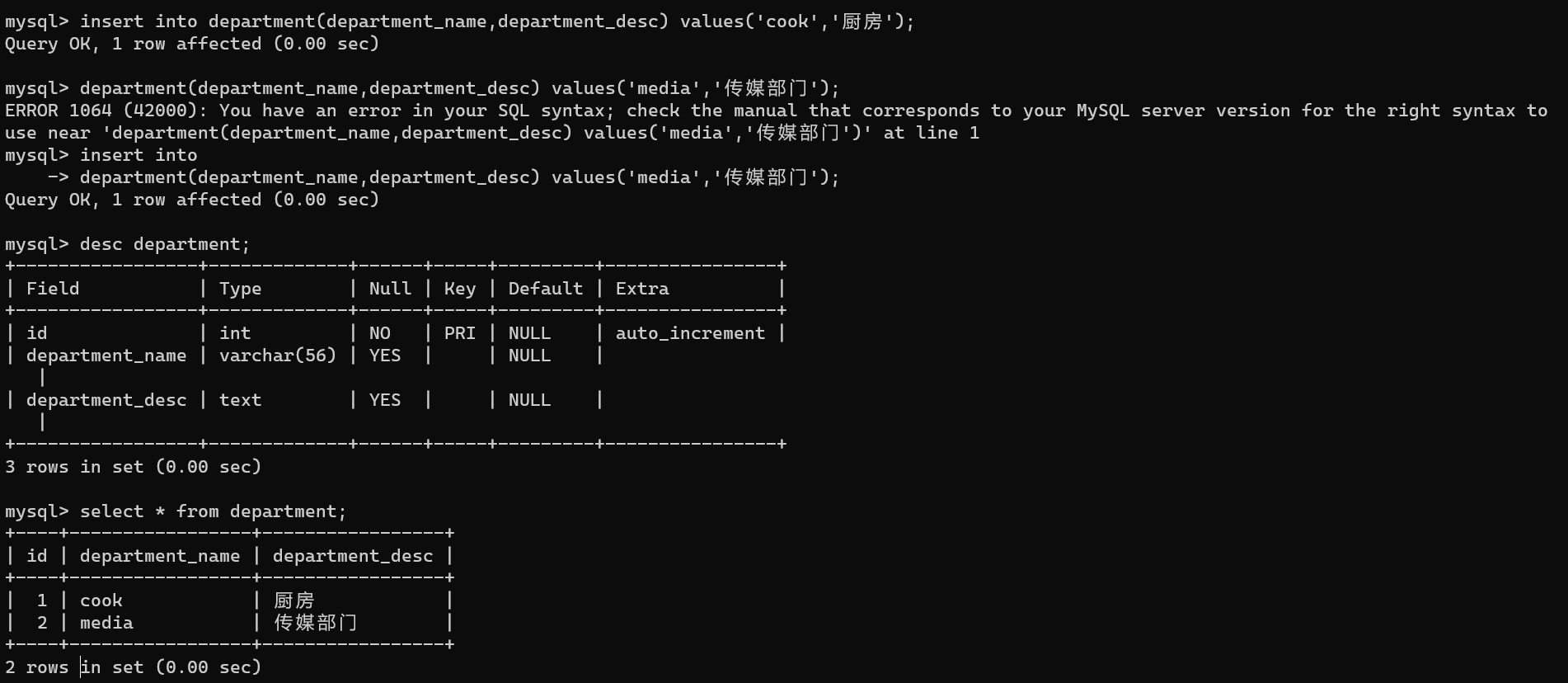
insert into department(department_name,department_desc) values('cook','厨房');
insert into
department(department_name,department_desc) values('media','传媒部门');
插入employees表中的数据
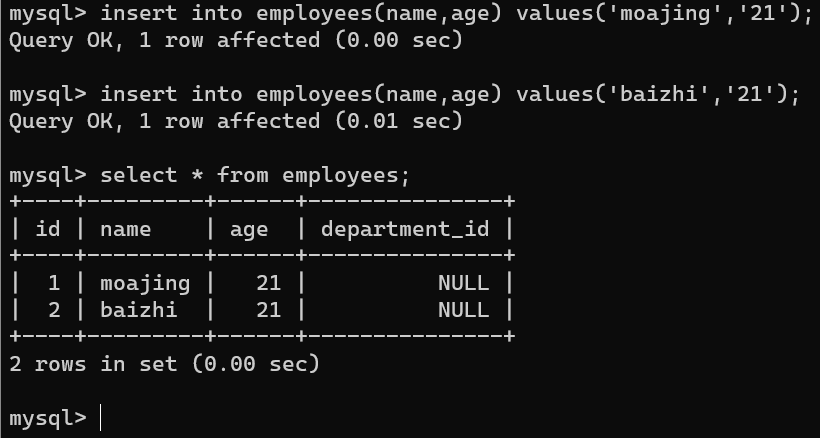
insert into employees(name,age) values('moajing','21');
insert into employees(name,age) values('baizhi','21');
你可以这样添加级联更新和级联删除 (这种方法是在表没有创建的情况下)
# 创建被约束的表
create table department(
id int(4) primary key auto_increment comment "部门表id",
department_name varchar(32) comment "部门名称",
department_desc text comment "部门介绍"
);
# 创建外键约束的表,前提是被建立连接的表先创建
create table employees(
id int(4) primary key auto_increment comment "员工id",
name varchar(32) comment "员工名字",
age int(4) comment "员工年龄",
department_id int(4) comment "外键关联部门id",
foreign key(department_id) references department(id)
on update cascade
on delete cascade
);
如果你已经创建表了
alter table employees
# 添加外键约束的语句,并给外键约束命名为"fk_department":
add constraint fk_department
foreign key (department_id)
references department(id)
on update cascade
on delete cascade;
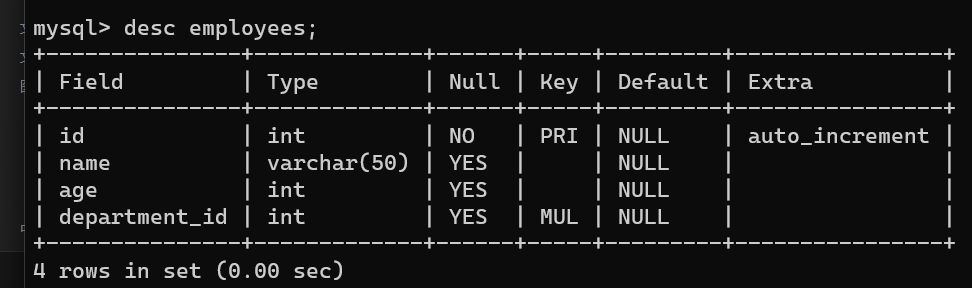
查看表的结构
desc employees;
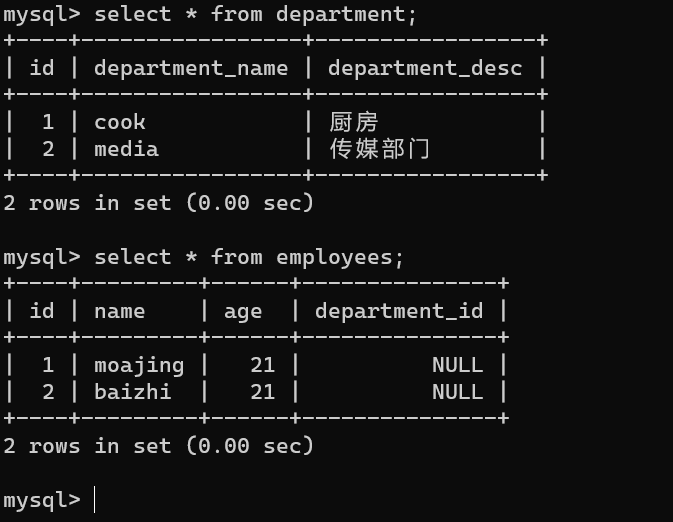
查看表中的所有数据
select * from employees;
select * from department;
查看特定部门的信息
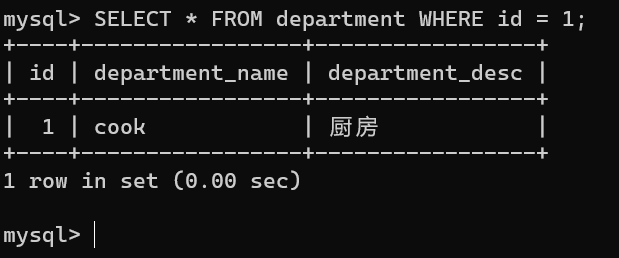
select * from department where id = 1;
关联的从表中的对应行也会被自动删除。这样可以确保主表和从表之间的数据的完整性,避免出现孤立的数据。
需要注意的是,启用级联更新或级联删除规则需要谨慎操作,因为它们可能会导致连锁反应,对数据库的性能产生影响。
insert into department(department_name,department_desc) values('cook','厨房');
insert into
department(department_name,department_desc) values('media','传媒部门');
[外链图片转存中…(img-otDzVHGw-1710985515770)]
插入employees表中的数据
insert into employees(name,age) values('moajing','21');
insert into employees(name,age) values('baizhi','21');
[外链图片转存中…(img-zTMYO4Xj-1710985515771)]
你可以这样添加级联更新和级联删除 (这种方法是在表没有创建的情况下)
# 创建被约束的表
create table department(
id int(4) primary key auto_increment comment "部门表id",
department_name varchar(32) comment "部门名称",
department_desc text comment "部门介绍"
);
# 创建外键约束的表,前提是被建立连接的表先创建
create table employees(
id int(4) primary key auto_increment comment "员工id",
name varchar(32) comment "员工名字",
age int(4) comment "员工年龄",
department_id int(4) comment "外键关联部门id",
foreign key(department_id) references department(id)
on update cascade
on delete cascade
);
如果你已经创建表了
alter table employees
# 添加外键约束的语句,并给外键约束命名为"fk_department":
add constraint fk_department
foreign key (department_id)
references department(id)
on update cascade
on delete cascade;
查看表的结构
desc employees;
[外链图片转存中…(img-HvgLcyZV-1710985515771)]
查看表中的所有数据
select * from employees;
select * from department;
[外链图片转存中…(img-PllMFdfU-1710985515771)]
查看特定部门的信息
select * from department where id = 1;
[外链图片转存中…(img-bNcIc9JV-1710985515771)]