大家好,我是带我去滑雪!
Word2Vec模型能够将词语映射到高维空间中的向量表示,同时保留了词语之间的语义信息和上下文关系。这使得模型能够更好地理解评论中的语境和含义。LSTM模型是一种适用于处理序列数据的深度学习模型,能够有效处理文本数据中的变长序列。这意味着模型可以处理不同长度的评论,并且不需要固定长度的输入。基于Word2Vec和LSTM模型的恶意评论预测具有较好的效果和性能,能够有效地识别和过滤百度贴吧中的恶意评论,提升用户体验和社区环境。下面开始代码实现:
目录
(1)导入文本数据
(2)文本分词与清理
(3)训练词向量word2vec
(4)导入相关模块并划分训练集与测试集
(5)模型构建
(6)绘制图像
(1)导入文本数据
import pandas as pd
real_news = pd.read_csv('E:\工作\硕士\博客\博客79-真假新闻检测\积极评论.csv',encoding="ANSI")
fake_news = pd.read_csv('E:\工作\硕士\博客\博客79-真假新闻检测\消极评论.csv',encoding="ANSI")
#积极评论为1
df_real = pd.DataFrame(columns = ['text', 'cls'])
df_real['text'] = real_news['评论']
df_real['cls'] = 1
#恶意评论编码为0
df_fake = pd.DataFrame(columns = ['text', 'cls'])
df_fake['text'] = fake_news['评论']
df_fake['cls'] = 0
#合并评论
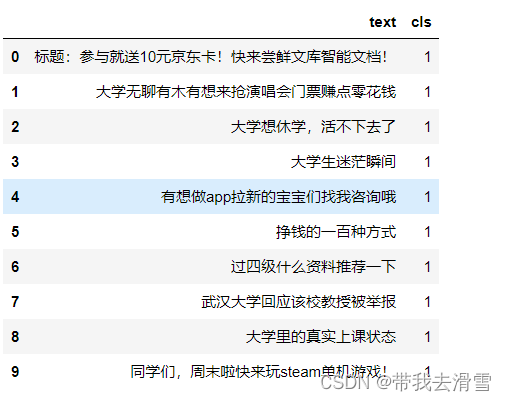
all_data = pd.concat([df_real, df_fake], ignore_index = True)
all_data.head(10)输出结果展示:
(2)文本分词与清理
text_clean = pd.DataFrame([w.replace('\n' or '\'' or '\\n' or '\r' or '\0' or ' ', '') for w in all_data['text']], columns = ['clean'])
import jieba
stoplist = list(pd.read_csv('E:\工作\硕士\博客\博客79-真假新闻检测\停用词.txt',
names = ['w'], sep = 'aaa', encoding = 'utf-8', engine= 'python').w)
cuttxt = lambda x: [x for x in jieba.lcut(x) if x not in stoplist]
text_list = text_clean['clean'].apply(cuttxt)
text_list.head(10) 输出结果:
0 [标题, 参与, 送, 10, 元, 京东, 卡, 尝鲜, 文库, 智能, 文档] 1 [大学, 无聊, 有木有, 想来, 抢, 演唱会, 门票, 赚点, 零花钱] 2 [大学, 想, 休学, 活不下去] 3 [大学生, 迷茫, 瞬间] 4 [想, 做, app, 拉新, 宝宝, 找, 咨询] 5 [挣钱, 一百种, 方式] 6 [四级, 资料, 推荐] 7 [武汉大学, 回应, 该校, 教授, 举报] 8 [大学, 里, 真实, 上课, 状态] 9 [同学, 周末, 玩, steam, 单机游戏] Name: clean, dtype: object
(3)训练词向量word2vec
from gensim.models import Word2Vec
w2vmodel = Word2Vec(vector_size=100) #训练n_dim为100
w2vmodel.build_vocab(text_list)
%time w2vmodel.train(text_list,\
total_examples = w2vmodel.corpus_count, epochs = 10)
def m_avgvec(words, w2vmodel):
return pd.DataFrame([w2vmodel.wv[w]
for w in words if w in w2vmodel.wv]).agg("mean")
# 生成建模用矩阵
%time train_vec = pd.DataFrame([m_avgvec(s, w2vmodel) for s in text_list])
train_vec.head()输出结果展示:

(4)导入相关模块并划分训练集与测试集
import os
from keras.preprocessing.text import Tokenizer
from keras_preprocessing.sequence import pad_sequences
from keras.preprocessing import sequence
from keras.models import Sequential
from keras.utils import np_utils
from keras.layers.core import Dropout, Activation, Lambda
from keras.layers import Dense, Embedding, LSTM
from keras.utils.np_utils import to_categorical
from keras.callbacks import ModelCheckpoint
from keras.models import load_model
from keras.optimizers import Adam
#划分训练集和测试集
from sklearn.model_selection import train_test_split
x_train_lstm, x_test_lstm, y_train_lstm, y_test_lstm = train_test_split(text_list, all_data['cls'], test_size = 0.3)
(5)模型构建
embedding_matrix = w2vmodel.wv.syn0
#使用embedding_matrix的长度作为top_words
top_words_w2v = embedding_matrix.shape[0]
#以下参数设置同上
maxlen = 100
batch_size = 32
nb_classes = 2
nb_epoch = 10
tokenizer1 = Tokenizer(nb_words = top_words_w2v)
tokenizer1.fit_on_texts(x_train_lstm)
sequences_train1 = tokenizer1.texts_to_sequences(x_train_lstm)
sequences_test1 = tokenizer1.texts_to_sequences(x_test_lstm)
x_train_seq1 = sequence.pad_sequences(sequences_train1, maxlen=maxlen)
x_test_seq1 = sequence.pad_sequences(sequences_test1, maxlen=maxlen)
y_train_seq1 = np_utils.to_categorical(y_train_lstm, nb_classes)
y_test_seq1 = np_utils.to_categorical(y_test_lstm, nb_classes)
#模型评价
score1 = lstm_model.evaluate(x_test_seq1, y_test_seq1, batch_size=batch_size)
print('测试集loss : {:.4f}'.format(score1[0]))
print('测试集accuracy : {:.4f}'.format(score1[1]))
输出结果展示:
Model: "sequential_1" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= embedding_1 (Embedding) (None, None, 100) 114700 lstm_1 (LSTM) (None, 128) 117248 dense_1 (Dense) (None, 2) 258 activation_1 (Activation) (None, 2) 0 ================================================================= Total params: 232,206 Trainable params: 232,206 Non-trainable params: 0 _________________________________________________________________ Epoch 1/10 165/165 [==============================] - 16s 85ms/step - loss: 0.6351 - accuracy: 0.6466 Epoch 2/10 165/165 [==============================] - 14s 84ms/step - loss: 0.4543 - accuracy: 0.7739 Epoch 3/10 165/165 [==============================] - 14s 84ms/step - loss: 0.3687 - accuracy: 0.8170 Epoch 4/10 165/165 [==============================] - 14s 84ms/step - loss: 0.3379 - accuracy: 0.8356 Epoch 5/10 165/165 [==============================] - 15s 91ms/step - loss: 0.3247 - accuracy: 0.8409 Epoch 6/10 165/165 [==============================] - 14s 86ms/step - loss: 0.3091 - accuracy: 0.8544 Epoch 7/10 165/165 [==============================] - 15s 90ms/step - loss: 0.3012 - accuracy: 0.8498 Epoch 8/10 165/165 [==============================] - 14s 85ms/step - loss: 0.2908 - accuracy: 0.8530 Epoch 9/10 165/165 [==============================] - 14s 83ms/step - loss: 0.2846 - accuracy: 0.8616 Epoch 10/10 165/165 [==============================] - 14s 85ms/step - loss: 0.2764 - accuracy: 0.862171/71 [==============================] - 1s 16ms/step - loss: 0.7499 - accuracy: 0.7668 测试集loss : 0.7499 测试集accuracy : 0.7668
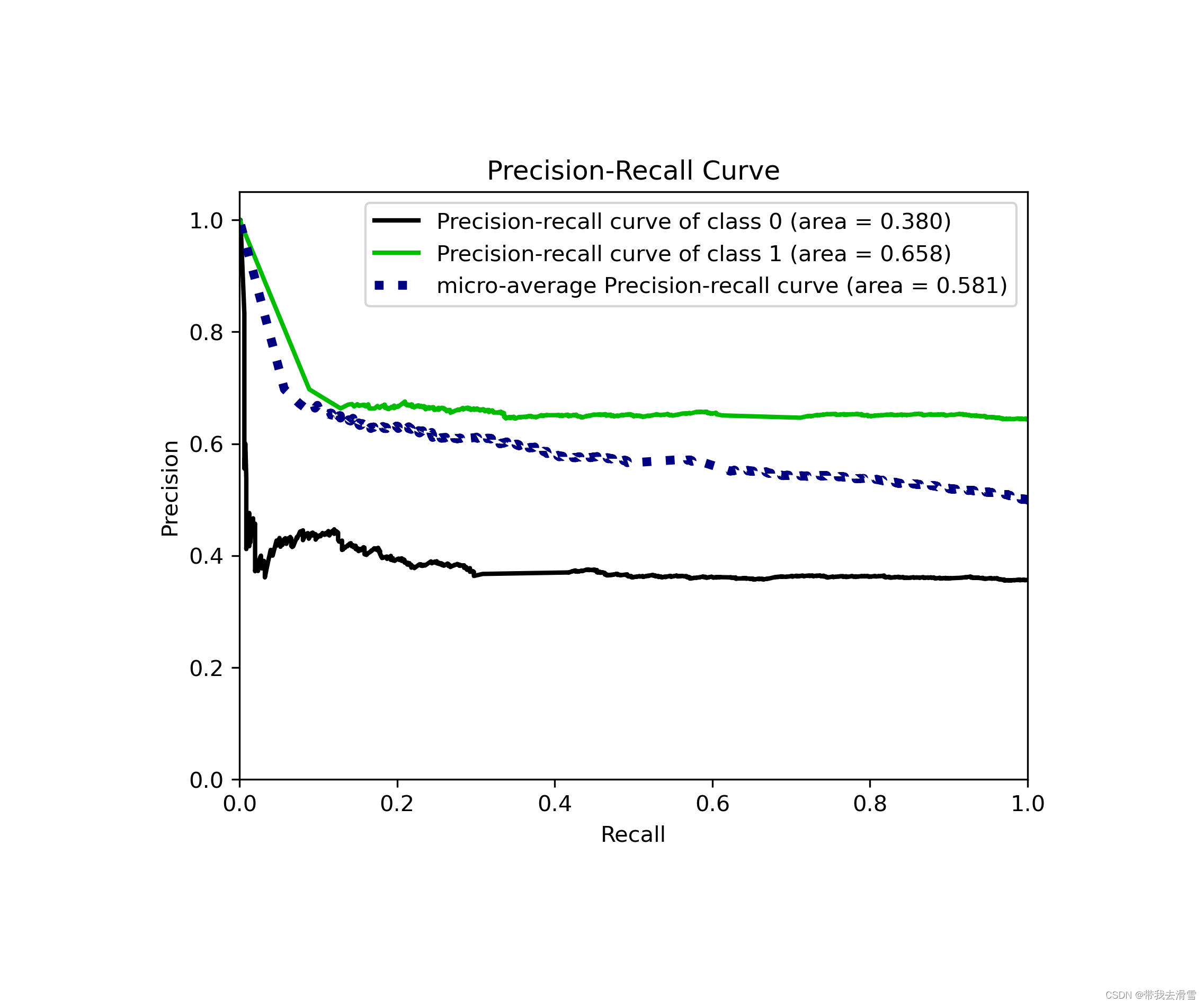
(6)绘制图像
skplt.metrics.plot_precision_recall(y_test, y_lstm_w2v_prob)
plt.savefig(r'E:\工作\硕士\博客\博客79-真假新闻检测\lstm_w2v 精确率与召回率曲线.png',
bbox_inches ="tight",
pad_inches = 1,
transparent = True,
facecolor ="w",
edgecolor ='w',
dpi=300,
orientation ='landscape')输出结果展示:
需要数据集的家人们可以去百度网盘(永久有效)获取:
链接:https://pan.baidu.com/s/173deLlgLYUz789M3KHYw-Q?pwd=0ly6
提取码:2138
更多优质内容持续发布中,请移步主页查看。
博主的WeChat:TCB1736732074
点赞+关注,下次不迷路!