目录
797.所有可能得路径
200.岛屿数量
695.岛屿的最大面积
1020.飞地的数量
130.被围绕的区域
417.太平洋大西洋水流问题
827.最大人工岛
127.单词接龙
841.钥匙和房间
463.岛屿的周长
797.所有可能得路径
797. 所有可能的路径
中等
给你一个有 n 个节点的 有向无环图(DAG),请你找出所有从节点 0 到节点 n-1 的路径并输出(不要求按特定顺序)
graph[i] 是一个从节点 i 可以访问的所有节点的列表(即从节点 i 到节点 graph[i][j]存在一条有向边)。
示例 1:
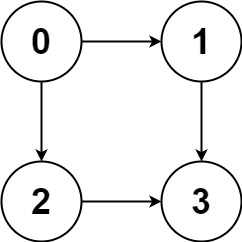
输入:graph = [[1,2],[3],[3],[]] 输出:[[0,1,3],[0,2,3]] 解释:有两条路径 0 -> 1 -> 3 和 0 -> 2 -> 3
示例 2:
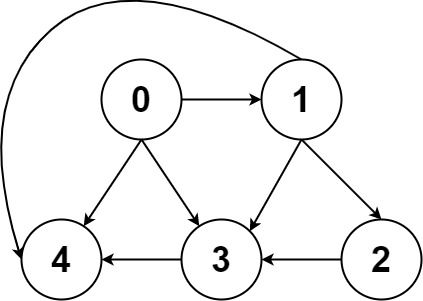
输入:graph = [[4,3,1],[3,2,4],[3],[4],[]] 输出:[[0,4],[0,3,4],[0,1,3,4],[0,1,2,3,4],[0,1,4]]
提示:
n == graph.length2 <= n <= 150 <= graph[i][j] < ngraph[i][j] != i(即不存在自环)graph[i]中的所有元素 互不相同- 保证输入为 有向无环图(DAG)
dfs + 回溯
class Solution {
List<List<Integer>> result; // 存储所有路径的结果集
List<Integer> path; // 存储当前路径的列表
public List<List<Integer>> allPathsSourceTarget(int[][] graph) {
result = new ArrayList<>(); // 初始化结果集
path = new ArrayList<>(); // 初始化当前路径
path.add(0); // 将起始节点添加到当前路径中
dfs(graph, 0); // 开始深度优先搜索
return result; // 返回结果集
}
public void dfs(int[][] graph, int node) {
if (node == graph.length - 1) { // 如果当前节点是目标节点
result.add(new ArrayList<>(path)); // 将当前路径添加到结果集中
return; // 返回
}
// 遍历当前节点的邻居节点
for (int i = 0; i < graph[node].length; i++) {
int nextNode = graph[node][i]; // 获取下一个节点
path.add(nextNode); // 将下一个节点添加到当前路径中
dfs(graph, nextNode); // 递归搜索以下一个节点为起点的路径
path.remove(path.size() - 1); // 回溯,移除当前路径中的最后一个节点
}
}
}
200.岛屿数量
200. 岛屿数量
中等
给你一个由 '1'(陆地)和 '0'(水)组成的的二维网格,请你计算网格中岛屿的数量。
岛屿总是被水包围,并且每座岛屿只能由水平方向和/或竖直方向上相邻的陆地连接形成。
此外,你可以假设该网格的四条边均被水包围。
示例 1:
输入:grid = [ ["1","1","1","1","0"], ["1","1","0","1","0"], ["1","1","0","0","0"], ["0","0","0","0","0"] ] 输出:1
示例 2:
输入:grid = [ ["1","1","0","0","0"], ["1","1","0","0","0"], ["0","0","1","0","0"], ["0","0","0","1","1"] ] 输出:3
提示:
m == grid.lengthn == grid[i].length1 <= m, n <= 300grid[i][j]的值为'0'或'1'
dfs
逐个遍历元素,遍历到为1的元素岛屿数量就+1,通过dfs向上下左右方向的位置dfs搜索,将该岛屿首个元素能辐射到的范围中的为1的陆地全部修改为‘0’,这样该元素在再次被访问到的时候就不会计数或者向四周访问(因为每个位置向上下左右访问,访问道德位置又向上下左右访问,这样会一直访问,导致栈溢出)。
或者使用Boolean+‘0’数组来记录访问状态是一样的
class Solution {
public int numIslands(char[][] grid) {
int result = 0; // 记录岛屿数量
for(int i = 0; i < grid.length; i++) {
for(int j = 0; j < grid[0].length; j++) {
if(grid[i][j] == '1') { // 如果当前位置是陆地
result++; // 岛屿数量加一
dfs(grid, i, j); // 对当前岛屿进行深度优先搜索
}
}
}
return result; // 返回岛屿数量
}
// 深度优先搜索函数,用于将当前岛屿所有相连的陆地转换为水域
public void dfs(char[][] grid, int i, int j) {
// 边界条件检查:索引越界或当前位置是水域
if(i < 0 || i >= grid.length || j < 0 || j >= grid[0].length || grid[i][j] == '0') {
return;
}
// 将当前位置标记为水域
grid[i][j] = '0';
// 对当前位置的上下左右四个相邻位置进行深度优先搜索
dfs(grid, i - 1, j); // 上
dfs(grid, i + 1, j); // 下
dfs(grid, i, j - 1); // 左
dfs(grid, i, j + 1); // 右
}
}
class Solution {
boolean[][] visited; // 记录访问状态的二维数组
int dir[][] = {
{0, 1}, // 右
{1, 0}, // 下
{-1, 0}, // 上
{0, -1} // 左
};
public int numIslands(char[][] grid) {
int count = 0; // 记录岛屿数量
visited = new boolean[grid.length][grid[0].length]; // 初始化访问状态数组
// 遍历整个二维网格
for(int i = 0; i < grid.length; i++) {
for(int j = 0; j < grid[0].length; j++) {
if(visited[i][j] == false && grid[i][j] == '1') { // 如果当前位置未访问过且为陆地
count++; // 岛屿数量加一
dfs(grid, i, j); // 进行深度优先搜索
}
}
}
return count; // 返回岛屿数量
}
// 深度优先搜索函数,用于访问当前岛屿上的所有陆地
private void dfs(char[][] grid, int x, int y) {
// 边界条件检查:索引越界、当前位置已访问、当前位置为水域
if(x < 0 || y < 0 || x >= grid.length || y >= grid[0].length || visited[x][y] == true || grid[x][y] == '0') {
return;
}
visited[x][y] = true; // 标记当前位置为已访问
// 遍历四个方向
for(int i = 0; i < 4; i++) {
int nextX = x + dir[i][0]; // 下一个位置的行索引
int nextY = y + dir[i][1]; // 下一个位置的列索引
dfs(grid, nextX, nextY); // 递归访问下一个位置
}
// 对当前位置的上下左右四个相邻位置进行深度优先搜索,遍历或者这种方式都可以
//dfs(grid, x - 1, y); // 上
//dfs(grid, x + 1, y); // 下
//dfs(grid, x, y - 1); // 左
//dfs(grid, x, y + 1); // 右
}
}
广度优先遍历,遇到‘1’的情况就将岛屿数量+1, 并广度优先遍历上下左右的元素,遇到‘1’就标记已经访问过,遇到‘0’就停止向下访问。
或者使用标记为‘0’的方式来标记访问过也是可以的。
class Solution {
boolean[][] visited; // 记录已访问的位置
int[][] move = {{0, 1}, {0, -1}, {1, 0}, {-1, 0}}; // 上下左右四个方向的移动数组
public int numIslands(char[][] grid) {
int res = 0; // 记录岛屿数量
visited = new boolean[grid.length][grid[0].length]; // 初始化已访问数组
for(int i = 0; i < grid.length; i++) {
for(int j = 0; j < grid[0].length; j++) {
if(!visited[i][j] && grid[i][j] == '1') { // 如果当前位置是未访问过的陆地
bfs(grid, i, j); // 进行广度优先搜索,将当前岛屿所有陆地访问到
res++; // 岛屿数量加一
}
}
}
return res; // 返回岛屿数量
}
// 广度优先搜索函数,用于将当前岛屿上的所有陆地都访问到
public void bfs(char[][] grid, int x, int y) {
Deque<int[]> queue = new ArrayDeque<>(); // 使用双端队列保存待访问的陆地位置
queue.offer(new int[]{x, y}); // 将当前位置加入队列
visited[x][y] = true; // 标记当前位置为已访问
while(!queue.isEmpty()) { // 当队列不为空时循环
int[] cur = queue.poll(); // 弹出队首位置
int m = cur[0]; // 当前位置的行坐标
int n = cur[1]; // 当前位置的列坐标
for(int i = 0; i < 4; i++) { // 遍历四个方向
int nextx = m + move[i][0]; // 计算下一个位置的行坐标
int nexty = n + move[i][1]; // 计算下一个位置的列坐标
// 检查下一个位置是否越界或已访问,如果没有则将其加入队列并标记为已访问
if(nextx < 0 || nextx == grid.length || nexty < 0 || nexty == grid[0].length || visited[nextx][nexty] || grid[nextx][nexty] == '0') continue;
queue.offer(new int[]{nextx, nexty}); // 将下一个位置加入队列
visited[nextx][nexty] = true; // 标记下一个位置为已访问
}
}
}
}
class Solution {
int[][] move = {{0, 1}, {0, -1}, {1, 0}, {-1, 0}}; // 上下左右四个方向的移动数组
public int numIslands(char[][] grid) {
int res = 0; // 记录岛屿数量
for(int i = 0; i < grid.length; i++) {
for(int j = 0; j < grid[0].length; j++) {
if(grid[i][j] == '1') { // 如果当前位置是未访问过的陆地
bfs(grid, i, j); // 进行广度优先搜索,将当前岛屿所有陆地访问到
res++; // 岛屿数量加一
}
}
}
return res; // 返回岛屿数量
}
// 广度优先搜索函数,用于将当前岛屿上的所有陆地都访问到
public void bfs(char[][] grid, int x, int y) {
Deque<int[]> queue = new ArrayDeque<>(); // 使用双端队列保存待访问的陆地位置
queue.offer(new int[]{x, y}); // 将当前位置加入队列
grid[x][y] = '0'; // 标记当前位置为已访问
while(!queue.isEmpty()) { // 当队列不为空时循环
int[] cur = queue.poll(); // 弹出队首位置
int m = cur[0]; // 当前位置的行坐标
int n = cur[1]; // 当前位置的列坐标
for(int i = 0; i < 4; i++) { // 遍历四个方向
int nextx = m + move[i][0]; // 计算下一个位置的行坐标
int nexty = n + move[i][1]; // 计算下一个位置的列坐标
// 检查下一个位置是否越界或已访问,如果没有则将其加入队列并标记为已访问
if(nextx < 0 || nextx == grid.length || nexty < 0 || nexty == grid[0].length || grid[nextx][nexty] == '0') continue;
queue.offer(new int[]{nextx, nexty}); // 将下一个位置加入队列
grid[nextx][nexty] = '0'; // 标记下一个位置为已访问
}
}
}
}
695.岛屿的最大面积
695. 岛屿的最大面积
中等
给你一个大小为 m x n 的二进制矩阵 grid 。
岛屿 是由一些相邻的 1 (代表土地) 构成的组合,这里的「相邻」要求两个 1 必须在 水平或者竖直的四个方向上 相邻。你可以假设 grid 的四个边缘都被 0(代表水)包围着。
岛屿的面积是岛上值为 1 的单元格的数目。
计算并返回 grid 中最大的岛屿面积。如果没有岛屿,则返回面积为 0 。
示例 1:
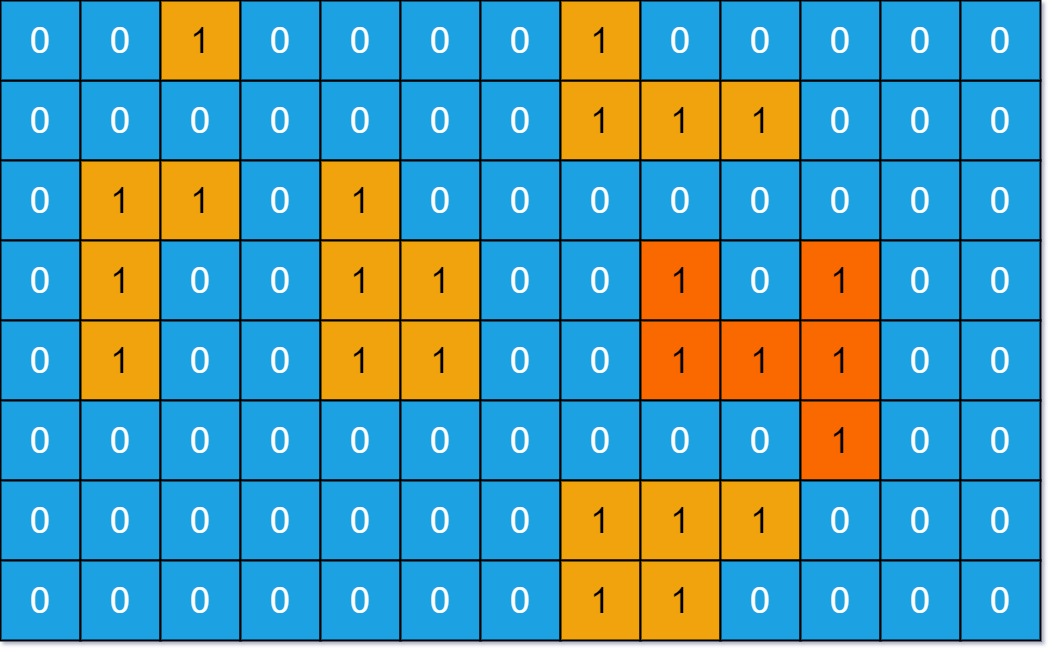
输入:grid = [[0,0,1,0,0,0,0,1,0,0,0,0,0],[0,0,0,0,0,0,0,1,1,1,0,0,0],[0,1,1,0,1,0,0,0,0,0,0,0,0],[0,1,0,0,1,1,0,0,1,0,1,0,0],[0,1,0,0,1,1,0,0,1,1,1,0,0],[0,0,0,0,0,0,0,0,0,0,1,0,0],[0,0,0,0,0,0,0,1,1,1,0,0,0],[0,0,0,0,0,0,0,1,1,0,0,0,0]] 输出:6 解释:答案不应该是11,因为岛屿只能包含水平或垂直这四个方向上的1。
示例 2:
输入:grid = [[0,0,0,0,0,0,0,0]] 输出:0
提示:
m == grid.lengthn == grid[i].length1 <= m, n <= 50grid[i][j]为0或1
感觉还是用dfs+赋零淹没这样的思路比较简单,设定一个curArea值储存当前海岛的面积,dfs来计算面积,计算完毕后重新赋值result(最大海岛面积),处理完这个海岛后重置当前岛屿面积
class Solution {
int result = 0; // 存储最大岛屿面积的变量
int curArea = 0; // 存储当前岛屿的面积的变量
// 计算最大岛屿面积的方法
public int maxAreaOfIsland(int[][] grid) {
// 遍历整个网格
for(int i = 0; i < grid.length; i++){
for(int j = 0; j < grid[0].length; j++){
// 如果当前位置是陆地(值为1)
if(grid[i][j] == 1){
// 进行深度优先搜索
dfs(grid,i,j);
// 更新最大岛屿面积
result = Math.max(result,curArea);
// 重置当前岛屿面积
curArea = 0;
}
}
}
// 返回最大岛屿面积
return result;
}
// 深度优先搜索方法
public void dfs(int[][] grid, int i, int j){
// 如果当前位置超出了网格范围或者当前位置是水(值为0),则返回
if(i < 0 || i >= grid.length || j < 0 || j >= grid[0].length || grid[i][j] == 0){
return;
}
// 将当前位置标记为已访问(水)
grid[i][j] = 0;
// 当前岛屿面积加一
curArea++;
// 继续向四个方向进行深度优先搜索
dfs(grid,i - 1, j);
dfs(grid,i, j + 1);
dfs(grid,i, j - 1);
dfs(grid,i + 1, j);
}
}
1020.飞地的数量
1020. 飞地的数量
中等
提示
给你一个大小为 m x n 的二进制矩阵 grid ,其中 0 表示一个海洋单元格、1 表示一个陆地单元格。
一次 移动 是指从一个陆地单元格走到另一个相邻(上、下、左、右)的陆地单元格或跨过 grid 的边界。
返回网格中 无法 在任意次数的移动中离开网格边界的陆地单元格的数量。
示例 1:
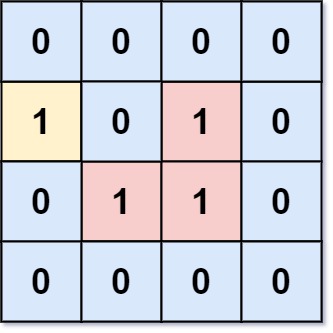
输入:grid = [[0,0,0,0],[1,0,1,0],[0,1,1,0],[0,0,0,0]] 输出:3 解释:有三个 1 被 0 包围。一个 1 没有被包围,因为它在边界上。
示例 2:
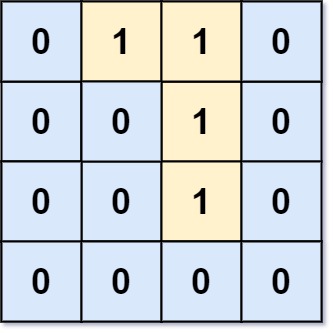
输入:grid = [[0,1,1,0],[0,0,1,0],[0,0,1,0],[0,0,0,0]] 输出:0 解释:所有 1 都在边界上或可以到达边界。
提示:
m == grid.lengthn == grid[i].length1 <= m, n <= 500grid[i][j]的值为0或1
从该网格的边界开始遍历,因为如果一个位置不是飞地,那他不断向上下左右访问就会访问到边界的陆地,同样通过边界的陆地也可以访问到这个不是飞地的位置,继而将这些位置的值都设为0,下次不会访问,同时防止重复访问导致栈溢出,这样操作完后剩下的标记为1的地方都是飞地。
class Solution {
// 计算被海洋包围的陆地数量的方法
public int numEnclaves(int[][] grid) {
int n = grid.length; // 获取网格的行数
int m = grid[0].length; // 获取网格的列数
// 从上下两侧开始,将与边界相连的陆地标记为已访问
for (int i = 0; i < n; i++) {
dfs(grid, i, 0); // 从第一列开始深度优先搜索
dfs(grid, i, m - 1); // 从最后一列开始深度优先搜索
}
// 从左右两侧开始,将与边界相连的陆地标记为已访问
for (int j = 0; j < m; j++) {
dfs(grid, 0, j); // 从第一行开始深度优先搜索
dfs(grid, n - 1, j); // 从最后一行开始深度优先搜索
}
int res = 0; // 初始化结果变量,用于计算未被海洋包围的陆地数量
// 统计未被标记为已访问的陆地数量
for (int i = 0; i < n; i++) {
for (int j = 0; j < m; j++) {
if (grid[i][j] == 1) { // 如果该位置为陆地
res++; // 未被海洋包围的陆地数量加一
}
}
}
return res; // 返回未被海洋包围的陆地数量
}
// 深度优先搜索函数,用于标记与当前位置相连的陆地
void dfs(int[][] grid, int i, int j) {
int n = grid.length; // 获取网格的行数
int m = grid[0].length; // 获取网格的列数
// 如果当前位置超出了网格边界,或者当前位置为海洋,直接返回
if (i < 0 || i >= n || j < 0 || j >= m || grid[i][j] == 0) {
return;
}
grid[i][j] = 0; // 将当前位置标记为已访问
// 对当前位置的上下左右四个方向进行深度优先搜索
dfs(grid, i + 1, j); // 向下搜索
dfs(grid, i - 1, j); // 向上搜索
dfs(grid, i, j - 1); // 向左搜索
dfs(grid, i, j + 1); // 向右搜索
}
}
笨办法,我自己的思路,去访问每一个位置,如果能到达网格外,就代表不是飞地,这里为了避免重复访问使用了一个visited数组,每个位置访问的时候都要新建一个。或者说每次访问都去复制一个grip数组,然后通过赋值为0的方式去避免重复访问。
import java.util.Arrays;
class Solution {
boolean[][] visited; // 用于记录已访问的位置
public int numEnclaves(int[][] grid) {
int result = 0;
// 遍历二维网格
for(int i = 0; i < grid.length; i++){
for(int j = 0; j < grid[0].length; j++){
// 如果当前位置是陆地且未被访问过
if(grid[i][j] == 1){
visited = new boolean[grid.length][grid[0].length];
// 进行深度优先搜索
if(!dfs(grid,i,j)){
result++;
}
}
}
}
return result;
}
// 深度优先搜索方法
public boolean dfs(int[][] grid, int i, int j){
// 判断当前位置是否超出网格范围
if(i < 0 || i >= grid.length || j < 0 || j >= grid[0].length){
return true;
}
// 如果当前位置是海洋或已被访问过,则返回false
if(grid[i][j] == 0 || visited[i][j]){
return false;
}
// 将当前位置标记为已访问
visited[i][j] = true; // 将当前陆地标记为已访问
// 递归地向四个方向进行深度优先搜索
boolean up = dfs(grid,i - 1,j);
boolean down = dfs(grid,i + 1,j);
boolean left = dfs(grid,i,j - 1);
boolean right = dfs(grid,i,j + 1);
// 如果上下左右任意一个方向上有陆地,则当前陆地不会被包围
return up || down || left || right;
}
}
130.被围绕的区域
130. 被围绕的区域
中等
给你一个 m x n 的矩阵 board ,由若干字符 'X' 和 'O' ,找到所有被 'X' 围绕的区域,并将这些区域里所有的 'O' 用 'X' 填充。
示例 1:
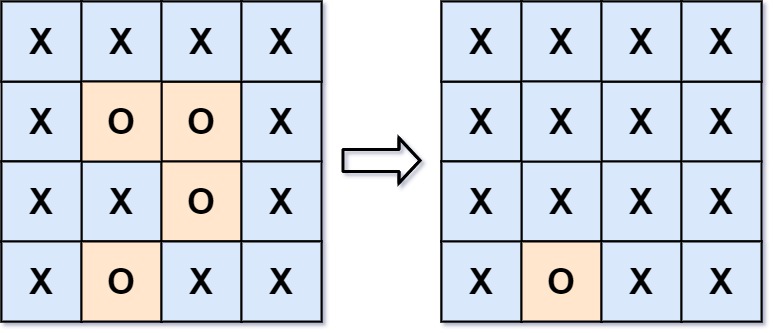
输入:board = [["X","X","X","X"],["X","O","O","X"],["X","X","O","X"],["X","O","X","X"]] 输出:[["X","X","X","X"],["X","X","X","X"],["X","X","X","X"],["X","O","X","X"]] 解释:被围绕的区间不会存在于边界上,换句话说,任何边界上的'O'都不会被填充为'X'。 任何不在边界上,或不与边界上的'O'相连的'O'最终都会被填充为'X'。如果两个元素在水平或垂直方向相邻,则称它们是“相连”的。
示例 2:
输入:board = [["X"]] 输出:[["X"]]
提示:
m == board.lengthn == board[i].length1 <= m, n <= 200board[i][j]为'X'或'O'
先遍历网格边缘上的位置,向四周遍历,能遍历到的位置就不是被x包围的位置,重新赋值为A为标记,遍历完网格边缘上的值后对整个网格进行遍历,遇到O就说明是被X包围的值,改为X,遇到X不变,遇到A改回为O。
class Solution {
int m, n; // 定义行数和列数
public void solve(char[][] board) {
m = board.length; // 获取行数
n = board[0].length; // 获取列数
// 从四条边界开始进行深度优先搜索
for (int i = 0; i < m; i++) {
dfs(board, i, 0); // 从左边界开始搜索
dfs(board, i, n - 1); // 从右边界开始搜索
}
for (int j = 0; j < n; j++) {
dfs(board, 0, j); // 从上边界开始搜索
dfs(board, m - 1, j); // 从下边界开始搜索
}
// 将未被标记的 'O' 修改为 'X',标记的 'A' 修改为 'O'
for (int i = 0; i < m; i++) {
for (int j = 0; j < n; j++) {
if (board[i][j] == 'A') {
board[i][j] = 'O'; // 'A' 表示与边界相连的 'O'
} else if (board[i][j] == 'O') {
board[i][j] = 'X'; // 'O' 表示未被包围的 'O'
}
}
}
}
// 深度优先搜索函数
void dfs(char[][] board, int i, int j) {
// 判断边界条件和当前字符是否为 'O'
if (i < 0 || i >= m || j < 0 || j >= n || board[i][j] != 'O') {
return; // 越界或已访问过的位置直接返回
}
board[i][j] = 'A'; // 标记当前位置为与边界相连的 'O'
// 对当前位置的上、下、左、右四个方向进行递归搜索
dfs(board, i - 1, j); // 上
dfs(board, i + 1, j); // 下
dfs(board, i, j - 1); // 左
dfs(board, i, j + 1); // 右
}
}
417.太平洋大西洋水流问题
417. 太平洋大西洋水流问题
中等
有一个 m × n 的矩形岛屿,与 太平洋 和 大西洋 相邻。 “太平洋” 处于大陆的左边界和上边界,而 “大西洋” 处于大陆的右边界和下边界。
这个岛被分割成一个由若干方形单元格组成的网格。给定一个 m x n 的整数矩阵 heights , heights[r][c] 表示坐标 (r, c) 上单元格 高于海平面的高度 。
岛上雨水较多,如果相邻单元格的高度 小于或等于 当前单元格的高度,雨水可以直接向北、南、东、西流向相邻单元格。水可以从海洋附近的任何单元格流入海洋。
返回网格坐标 result 的 2D 列表 ,其中 result[i] = [ri, ci] 表示雨水从单元格 (ri, ci) 流动 既可流向太平洋也可流向大西洋 。
示例 1:
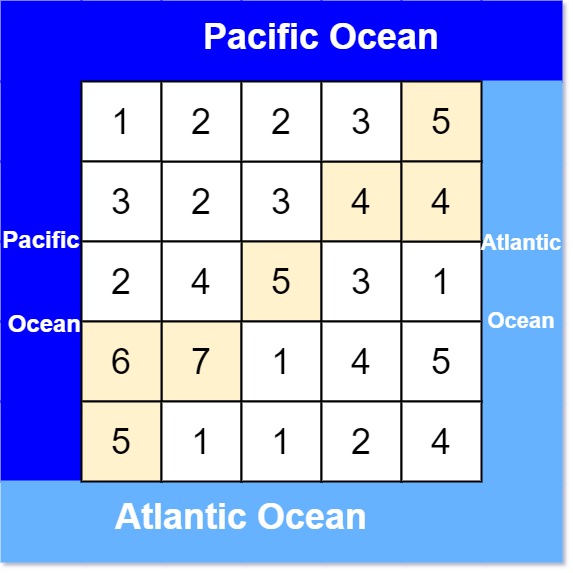
输入: heights = [[1,2,2,3,5],[3,2,3,4,4],[2,4,5,3,1],[6,7,1,4,5],[5,1,1,2,4]] 输出: [[0,4],[1,3],[1,4],[2,2],[3,0],[3,1],[4,0]]
示例 2:
输入: heights = [[2,1],[1,2]] 输出: [[0,0],[0,1],[1,0],[1,1]]
提示:
m == heights.lengthn == heights[r].length1 <= m, n <= 2000 <= heights[r][c] <= 105
这道题还是通过边界向内访问,使用了两个数组来标记大西洋和太平洋的到达情况,与前一个位置的高度比较我采用了两个参数来传递,最后遍历两个访问情况的数组,均为true则满足情况,放入结果数组集中,注意在访问判断大西洋到达情况和太平洋到达情况的时候需要分别有一个visited数组
class Solution {
List<List<Integer>> result; // 用于存储结果的列表
boolean[][] pacific; // 用于标记能流入太平洋的位置
boolean[][] atlantic; // 用于标记能流入大西洋的位置
boolean[][] visited; // 用于标记已访问过的位置
public List<List<Integer>> pacificAtlantic(int[][] heights) {
result = new ArrayList<>(); // 初始化结果列表
pacific = new boolean[heights.length][heights[0].length]; // 初始化太平洋标记数组
atlantic = new boolean[heights.length][heights[0].length]; // 初始化大西洋标记数组
visited = new boolean[heights.length][heights[0].length]; // 初始化访问标记数组
// 从太平洋边界开始进行深度优先搜索
for(int i = 0; i < heights.length; i++){
dfs(heights, i, 0, true, i, 0); // 从左边界开始搜索
}
for(int j = 0; j < heights[0].length; j++){
dfs(heights, 0, j, true, 0, j); // 从上边界开始搜索
}
//因为一次是求大西洋的情况,一个是求太平洋的情况,需要两个visited数组
visited = new boolean[heights.length][heights[0].length]; // 重置访问标记数组
// 从大西洋边界开始进行深度优先搜索
for(int i = 0; i < heights.length; i++){
dfs(heights, i, heights[0].length - 1, false, i, heights[0].length - 1); // 从右边界开始搜索
}
for(int j = 0; j < heights[0].length; j++){
dfs(heights, heights.length - 1, j, false, heights.length - 1, j); // 从下边界开始搜索
}
// 找到能同时流入太平洋和大西洋的位置
for(int i = 0; i < heights.length; i++){
for(int j = 0; j < heights[0].length; j++){
if(pacific[i][j] && atlantic[i][j]){ // 如果当前位置能同时流入太平洋和大西洋
List<Integer> place = new ArrayList<>(); // 创建一个位置列表
place.add(i); // 添加当前位置的行索引
place.add(j); // 添加当前位置的列索引
result.add(place); // 将该位置添加到结果列表中
}
}
}
return result; // 返回结果列表
}
// 深度优先搜索函数
public void dfs(int[][] heights, int i, int j, boolean choose, int prei, int prej){
// 如果当前位置越界、高度小于前一个位置或已访问过,则返回
if (i < 0 || i >= heights.length || j < 0 || j >= heights[0].length || heights[i][j] < heights[prei][prej] || visited[i][j]) {
return;
}
visited[i][j] = true; // 标记当前位置为已访问
if(choose){
pacific[i][j] = true; // 标记当前位置能流入太平洋
} else {
atlantic[i][j] = true; // 标记当前位置能流入大西洋
}
// 对当前位置的上、下、左、右四个方向进行递归搜索
dfs(heights, i - 1, j, choose, i, j); // 上
dfs(heights, i + 1, j, choose, i, j); // 下
dfs(heights, i, j - 1, choose, i, j); // 左
dfs(heights, i, j + 1, choose, i, j); // 右
}
}
827.最大人工岛
827. 最大人工岛
困难
给你一个大小为 n x n 二进制矩阵 grid 。最多 只能将一格 0 变成 1 。
返回执行此操作后,grid 中最大的岛屿面积是多少?
岛屿 由一组上、下、左、右四个方向相连的 1 形成。
示例 1:
输入: grid = [[1, 0], [0, 1]] 输出: 3 解释: 将一格0变成1,最终连通两个小岛得到面积为 3 的岛屿。
示例 2:
输入: grid = [[1, 1], [1, 0]] 输出: 4 解释: 将一格0变成1,岛屿的面积扩大为 4。
示例 3:
输入: grid = [[1, 1], [1, 1]] 输出: 4 解释: 没有0可以让我们变成1,面积依然为 4。
提示:
n == grid.lengthn == grid[i].length1 <= n <= 500grid[i][j]为0或1
最直观的方法是遍历数组,找到0的话就去访问周围的位置,找出将该0视为陆地的岛屿面积,然后找出最大的那一个。(我这里没有写)
优化方案:先找出每个岛屿的面积,并且将其标记存入Map数组中,修改该位置的值为mark值。(mark的值大于2,这样不会和原来的0和1冲突),完成后遍历整个数组,遇到0的情况向四周寻找一圈,即和它上下左右相邻的陆地,将该陆地所在的岛屿加入面积中(这里使用list来去重,防止该水域有两面或多面挨着的是一个岛屿),比较求出最大值
class Solution {
Map<Integer,Integer> map; // 存储岛屿面积的映射
int curArea = 0; // 存储当前岛屿的面积的变量
boolean[][] visited; // 记录网格中的位置是否已经访问过
int[][] position = {{-1, 0}, {0, 1}, {1, 0}, {0, -1}}; // 四个方向的偏移量
// 计算最大岛屿面积的方法
public int largestIsland(int[][] grid) {
map = new HashMap<>(); // 初始化岛屿面积的映射
int result = Integer.MIN_VALUE; // 存储最大岛屿面积的变量
int mark = 2; // 标记每个岛屿
visited = new boolean[grid.length][grid[0].length]; // 初始化访问记录数组
// 遍历整个网格,进行岛屿面积计算和标记
for(int i = 0; i < grid.length; i++){
for(int j = 0; j < grid[0].length; j++){
// 如果当前位置是陆地(值为1)
if(grid[i][j] == 1){
// 进行深度优先搜索
dfs(grid,i,j,mark);
// 更新最大岛屿面积
map.put(mark++,curArea);
// 重置当前岛屿面积
curArea = 0;
}
}
}
// 计算每个水域周围的相邻岛屿面积,找出最大的岛屿面积
int nowMaxArea = 1; // 当前水域的面积,初始化为1是因为将当前位置的0变为1
List<Integer> list = new ArrayList<>(); // 记录周围相邻的岛屿的标记
for(int i = 0; i < grid.length; i++){
for(int j = 0; j < grid[0].length; j++){
if(grid[i][j] == 0){
// 遍历当前水域周围的相邻位置
for (int[] current: position) {
int curRow = i + current[0], curCol = j + current[1];
// 检查相邻位置是否越界
if (curRow < 0 || curRow >= grid.length || curCol < 0 || curCol >= grid[0].length){
continue;
}
int curMark = grid[curRow][curCol]; // 获取相邻位置的标记
// 如果标记存在list中说明该标记被记录过一次,如果不存在map中说明该标记是无效标记(此时curMark=0)
if (list.contains(curMark) || !map.containsKey(curMark)){
continue;
}
list.add(curMark); // 将相邻岛屿的标记加入list中
nowMaxArea += map.get(curMark); // 更新当前水域的面积
}
// 更新最大岛屿面积
result = Math.max(result,nowMaxArea);
// 重置当前水域面积
nowMaxArea = 1;
list.clear(); // 清空相邻岛屿的标记
}
}
}
// 返回最大岛屿面积,如果不存在岛屿则返回整个网格的面积
return result == Integer.MIN_VALUE ? grid.length * grid[0].length : result;
}
// 深度优先搜索方法
public void dfs(int[][] grid, int i, int j, int mark){
// 如果当前位置超出了网格范围或者当前位置是水(值为0),或者已经访问过,则返回
if(i < 0 || i >= grid.length || j < 0 || j >= grid[0].length || grid[i][j] == 0 || visited[i][j]){
return;
}
// 将当前位置标记为已访问(水)
visited[i][j] = true;
grid[i][j] = mark; // 标记当前位置属于的岛屿
// 当前岛屿面积加一
curArea++;
// 继续向四个方向进行深度优先搜索
dfs(grid,i - 1, j, mark); // 上
dfs(grid,i, j + 1, mark); // 右
dfs(grid,i, j - 1, mark); // 左
dfs(grid,i + 1, j, mark); // 下
}
}
127.单词接龙
127. 单词接龙
困难
字典 wordList 中从单词 beginWord 和 endWord 的 转换序列 是一个按下述规格形成的序列 beginWord -> s1 -> s2 -> ... -> sk:
- 每一对相邻的单词只差一个字母。
- 对于
1 <= i <= k时,每个si都在wordList中。注意,beginWord不需要在wordList中。 sk == endWord
给你两个单词 beginWord 和 endWord 和一个字典 wordList ,返回 从 beginWord 到 endWord 的 最短转换序列 中的 单词数目 。如果不存在这样的转换序列,返回 0 。
示例 1:
输入:beginWord = "hit", endWord = "cog", wordList = ["hot","dot","dog","lot","log","cog"] 输出:5 解释:一个最短转换序列是 "hit" -> "hot" -> "dot" -> "dog" -> "cog", 返回它的长度 5。
示例 2:
输入:beginWord = "hit", endWord = "cog", wordList = ["hot","dot","dog","lot","log"] 输出:0 解释:endWord "cog" 不在字典中,所以无法进行转换。
提示:
1 <= beginWord.length <= 10endWord.length == beginWord.length1 <= wordList.length <= 5000wordList[i].length == beginWord.lengthbeginWord、endWord和wordList[i]由小写英文字母组成beginWord != endWordwordList中的所有字符串 互不相同
class Solution {
public int ladderLength(String beginWord, String endWord, List<String> wordList) {
HashSet<String> wordSet = new HashSet<>(wordList); //转换为hashset 加快速度
if (wordSet.size() == 0 || !wordSet.contains(endWord)) { //特殊情况判断
return 0;
}
Queue<String> queue = new LinkedList<>(); //bfs 队列
queue.offer(beginWord);
Map<String, Integer> map = new HashMap<>(); //记录单词对应路径长度
map.put(beginWord, 1);
while (!queue.isEmpty()) {
String word = queue.poll(); //取出队头单词
int path = map.get(word); //获取到该单词的路径长度
for (int i = 0; i < word.length(); i++) { //遍历单词的每个字符
char[] chars = word.toCharArray(); //将单词转换为char array,方便替换
for (char k = 'a'; k <= 'z'; k++) { //从'a' 到 'z' 遍历替换
chars[i] = k; //替换第i个字符
String newWord = String.valueOf(chars); //得到新的字符串
if (newWord.equals(endWord)) { //如果新的字符串值与endWord一致,返回当前长度+1
return path + 1;
}
if (wordSet.contains(newWord) && !map.containsKey(newWord)) { //如果新单词在set中,但是没有访问过
map.put(newWord, path + 1); //记录单词对应的路径长度
queue.offer(newWord);//加入队尾
}
}
}
}
return 0; //未找到
}
}841.钥匙和房间
841. 钥匙和房间
中等
有 n 个房间,房间按从 0 到 n - 1 编号。最初,除 0 号房间外的其余所有房间都被锁住。你的目标是进入所有的房间。然而,你不能在没有获得钥匙的时候进入锁住的房间。
当你进入一个房间,你可能会在里面找到一套不同的钥匙,每把钥匙上都有对应的房间号,即表示钥匙可以打开的房间。你可以拿上所有钥匙去解锁其他房间。
给你一个数组 rooms 其中 rooms[i] 是你进入 i 号房间可以获得的钥匙集合。如果能进入 所有 房间返回 true,否则返回 false。
示例 1:
输入:rooms = [[1],[2],[3],[]] 输出:true 解释: 我们从 0 号房间开始,拿到钥匙 1。 之后我们去 1 号房间,拿到钥匙 2。 然后我们去 2 号房间,拿到钥匙 3。 最后我们去了 3 号房间。 由于我们能够进入每个房间,我们返回 true。
示例 2:
输入:rooms = [[1,3],[3,0,1],[2],[0]] 输出:false 解释:我们不能进入 2 号房间。
提示:
n == rooms.length2 <= n <= 10000 <= rooms[i].length <= 10001 <= sum(rooms[i].length) <= 30000 <= rooms[i][j] < n- 所有
rooms[i]的值 互不相同
这道题目用dfs或者bfs都可以,思路就是对整个图进行搜索,用一个visited数组来标记是否被访问过,最后遍历整个集合看看是否每个元素都被访问过。
dfs:
class Solution {
boolean[] visited; // 记录房间是否被访问过的数组
/**
* 判断是否能够访问所有房间的方法
* @param rooms 房间的列表
* @return 是否能够访问所有房间
*/
public boolean canVisitAllRooms(List<List<Integer>> rooms) {
visited = new boolean[rooms.size()]; // 初始化访问记录数组
dfs(rooms, 0); // 从第一个房间开始进行深度优先搜索
// 检查是否所有房间都被访问过
for(int i = 0; i < visited.length; i++){
if(!visited[i]){
return false;
}
}
return true;
}
/**
* 深度优先搜索方法
* @param rooms 房间的列表
* @param node 当前节点(房间)
*/
public void dfs(List<List<Integer>> rooms, int node){
if(visited[node]){ // 如果当前节点已经被访问过,则返回
return;
}
visited[node] = true; // 将当前节点标记为已访问
// 遍历当前房间中的钥匙,继续向下搜索
for(int i:rooms.get(node)){
dfs(rooms, i);
}
}
}
bfs:
class Solution {
/**
* 判断是否能够访问所有房间的方法
* @param rooms 房间的列表,每个房间中包含了可以访问的其他房间的钥匙列表
* @return 是否能够访问所有房间
*/
public boolean canVisitAllRooms(List<List<Integer>> rooms) {
boolean[] visited = new boolean[rooms.size()]; // 用一个 visited 数组记录房间是否被访问
visited[0] = true; // 将第 0 个房间标记为已访问
Queue<Integer> queue = new LinkedList<>(); // 使用队列进行广度优先搜索
queue.add(0); // 将第 0 个房间加入队列
// 遍历队列中的房间,查看它们可以访问的其他房间
while (!queue.isEmpty()) {
int curKey = queue.poll(); // 取出队首的房间
// 遍历当前房间中的钥匙,将未访问过的房间加入队列
for (int key: rooms.get(curKey)) {
if (visited[key]) continue; // 如果房间已经访问过,则跳过
visited[key] = true; // 标记房间为已访问
queue.add(key); // 将该房间加入队列
}
}
// 检查是否所有房间都被访问过
for (boolean key: visited) {
if (!key) return false; // 如果有房间未被访问过,则返回 false
}
return true; // 如果所有房间都被访问过,则返回 true
}
}
463.岛屿的周长
463. 岛屿的周长
简单
给定一个 row x col 的二维网格地图 grid ,其中:grid[i][j] = 1 表示陆地, grid[i][j] = 0 表示水域。
网格中的格子 水平和垂直 方向相连(对角线方向不相连)。整个网格被水完全包围,但其中恰好有一个岛屿(或者说,一个或多个表示陆地的格子相连组成的岛屿)。
岛屿中没有“湖”(“湖” 指水域在岛屿内部且不和岛屿周围的水相连)。格子是边长为 1 的正方形。网格为长方形,且宽度和高度均不超过 100 。计算这个岛屿的周长。
示例 1:
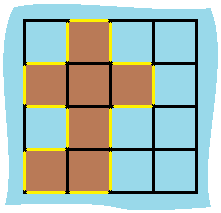
输入:grid = [[0,1,0,0],[1,1,1,0],[0,1,0,0],[1,1,0,0]] 输出:16 解释:它的周长是上面图片中的 16 个黄色的边
示例 2:
输入:grid = [[1]] 输出:4
示例 3:
输入:grid = [[1,0]] 输出:4
提示:
row == grid.lengthcol == grid[i].length1 <= row, col <= 100grid[i][j]为0或1
遍历数组直到找到一个陆地,根据题意,只有一个岛屿,那么我们dfs完这个陆地就可以跳出循环了,因为不会有更多的岛屿,在遍历寻找岛屿陆地的时候,如果遇到了海洋或者索引越界,就说明到达了陆地的边界,遇到一次就将周长加一。
class Solution {
boolean[][] visited; // 二维数组,用于记录已访问的单元格
int perimeter = 0; // 岛屿的周长
// 计算岛屿周长的主要函数
public int islandPerimeter(int[][] grid) {
visited = new boolean[grid.length][grid[0].length]; // 初始化访问数组
// 遍历网格中的每个单元格
for(int i = 0; i < grid.length; i++) {
for(int j = 0; j < grid[0].length; j++) {
if(grid[i][j] == 1) { // 如果单元格包含陆地
dfs(grid, i, j); // 从该单元格开始执行深度优先搜索
return perimeter; // 搜索结束后返回周长
}
}
}
return perimeter; // 返回周长(如果没有找到陆地则为0)
}
// 深度优先搜索(DFS)函数,用于遍历岛屿
public void dfs(int[][] grid, int i, int j) {
// 基本情况:如果单元格越界或者是水域
if(i < 0 || i >= grid.length || j < 0 || j >= grid[0].length || grid[i][j] == 0) {
perimeter++; // 增加周长
return; // 退出DFS
}
if(visited[i][j]) {
return; // 如果单元格已被访问过,则退出DFS
}
visited[i][j] = true; // 标记当前单元格为已访问
// 递归访问相邻单元格
dfs(grid, i - 1, j); // 上
dfs(grid, i + 1, j); // 下
dfs(grid, i, j - 1); // 左
dfs(grid, i, j + 1); // 右
}
}