作者:洪波,数据库爱好者
最新版 V4.2.2 已上线,其新增的数据生命周期管理功能颇具吸引力。据官方资料显示,ODC现支持将源数据库中的表数据,无论是单次还是周期性地,归档至其它目标数据库。这一设计旨在解决线上数据日益增长对查询性能及业务运行带来的挑战。
此功能的引入意味着,我们可以轻松地将大量历史数据,从主集群中迁移至专门的历史归档集群。否则线上数据库的数据量会随着时间推移不断膨胀,而许多历史数据的查询频率逐渐降低,这会拖慢表的查询速度。而通过数据归档,线上数据库仅需保留数月或一年的数据,超出此时间范围的数据都可以归档并删除。这样便能确保线上数据库始终保持高性能。那么,这个功能具体是如何实现的呢?接下来,就让我为大家率先体验并详细解析这一新功能。
原理介绍
这块根据官网介绍,先简单了解下原理。
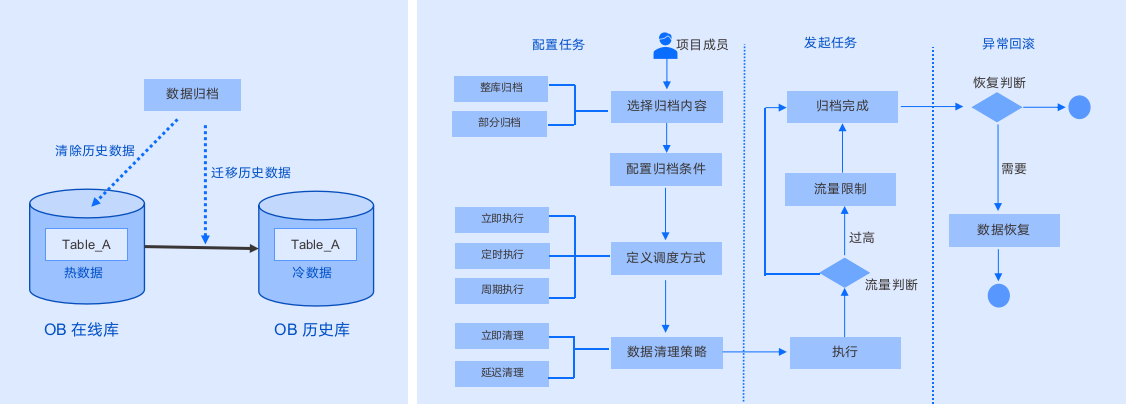
如上图所示,简单理解就是有两个任务,根据条件,把历史数据从在线库迁移到归档库,然后再将历史数据从在线库中删除,总体需要经过几个步骤的配置,包括选择归档内容 -> 配置归档条件 -> 定义调度方式 -> 数据清理策略 -> 最终执行,这中间也包含了一些流量的限制,以及任务的回滚,下面就边演示边介绍。
不过根据官网介绍,这里面也是有一些限制,可以看一下:
- 前置条件:
- OceanBase 数据源必须通过 OBproxy 连接(暂不支持对直连的 OceanBase 进行归档操作)。
- OceanBase 数据源目前仅支持集群实例,新建数据源时必须配置集群名称。
- OceanBase 数据源必须配置 sys 租户账号。
- 非同类型数据源,数据归档不支持自动创建目标表。
- 需保证源端表字段在目标端兼容,数据归档不处理字段兼容性问题。
- MySQL 数据源暂不支持 CPU 内存防爆能力。
- 归档链路支持:
- OceanBase MySQL 到 OceanBase MySQL 。
- MySQL 到 MySQL。
- MySQL 到 OceanBase MySQL 。
- OceanBase MySQL 到 MySQL。
- 以下情况不支持归档:
- 若表中不包含主键 PRIMARY KEY,不支持进行归档。
- 若表中包含 bit、enum、set、xml 、geometry字段类型,不支持进行归档。
- 若归档条件中包含 limit 语句,不支持进行归档。
- 若表中包含外键,不支持进行归档。
环境信息
这里有两个OceanBase集群,就简单模拟一个在线库和一个历史归档库
| 在线库 | 127.xx.xx.90 | 租户:obtest | 归档表:test.custom |
| 历史归档库 | 127.xx.xx.89 | 租户:obtest | 归档表:test.custom |
| ODC服务 | 127.xx.xx.89 |
测试表为custom,表结构如下,总共有10万行数据
obclient [test]> desc custom;
+----------+--------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+----------+--------------+------+-----+---------+-------+
| id | int(11) | NO | PRI | NULL | |
| name | varchar(200) | YES | | NULL | |
| birthday | datetime | YES | | NULL | |
+----------+--------------+------+-----+---------+-------+
3 rows in set (0.002 sec)
obclient [test]> select count(*) from custom;
+----------+
| count(*) |
+----------+
| 100000 |
+----------+
1 row in set (0.027 sec)配置过程
ODC的部署非常简单,可以使用docker方式部署,也可以直接下载安装包,在mac或者windows机器上部署,具体部署方式可以查看官方文档:ODC部署
数据源管理
首先需要在ODC将两个集群添加到数据源中,在ODC数据源页面,新建数据源即可,选择OceanBase MySQL,填入对应的数据库信息
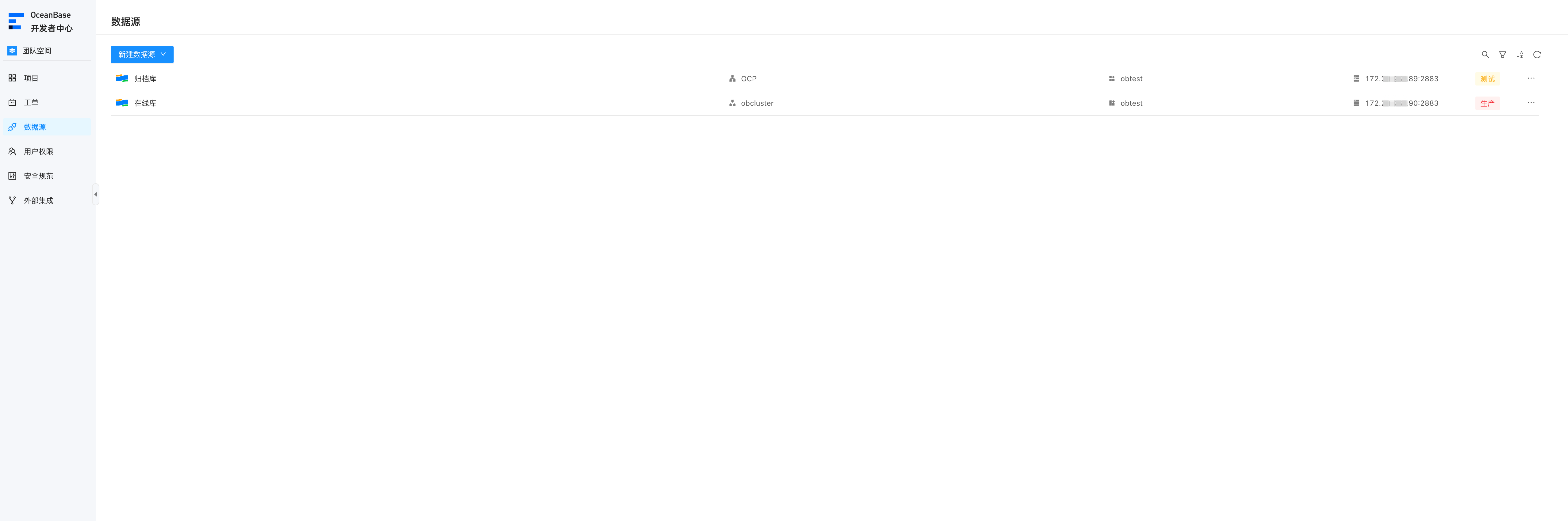
填写完成之后,就开始创建项目
创建项目
在创建归档任务工单之前,需要先创建一个项目
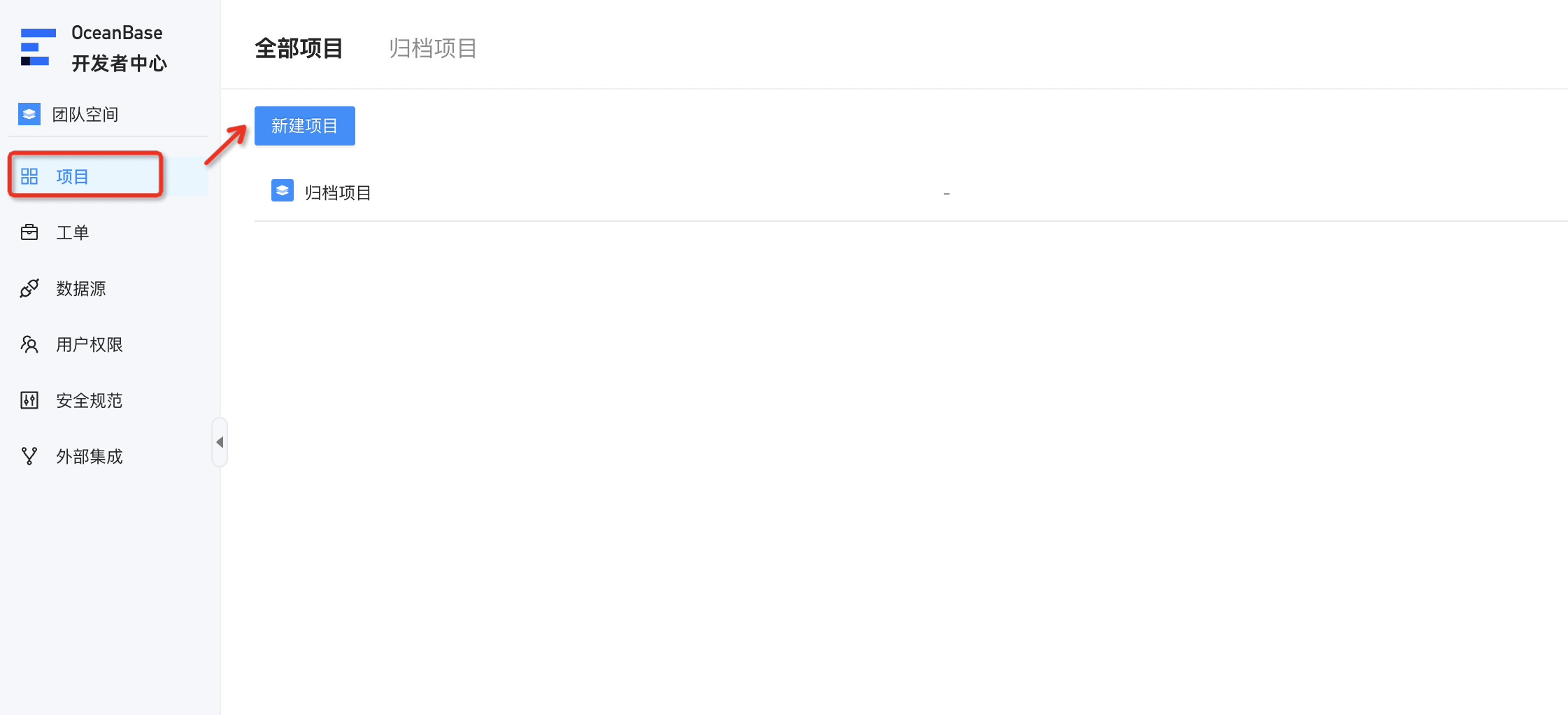
然后在项目中添加数据源和数据库,这块应该主要是做一些权限限制,防止登录ODC的用户有操作所有数据源的权限,因此可以将用户权限和项目绑定,只能操作项目中的数据库。
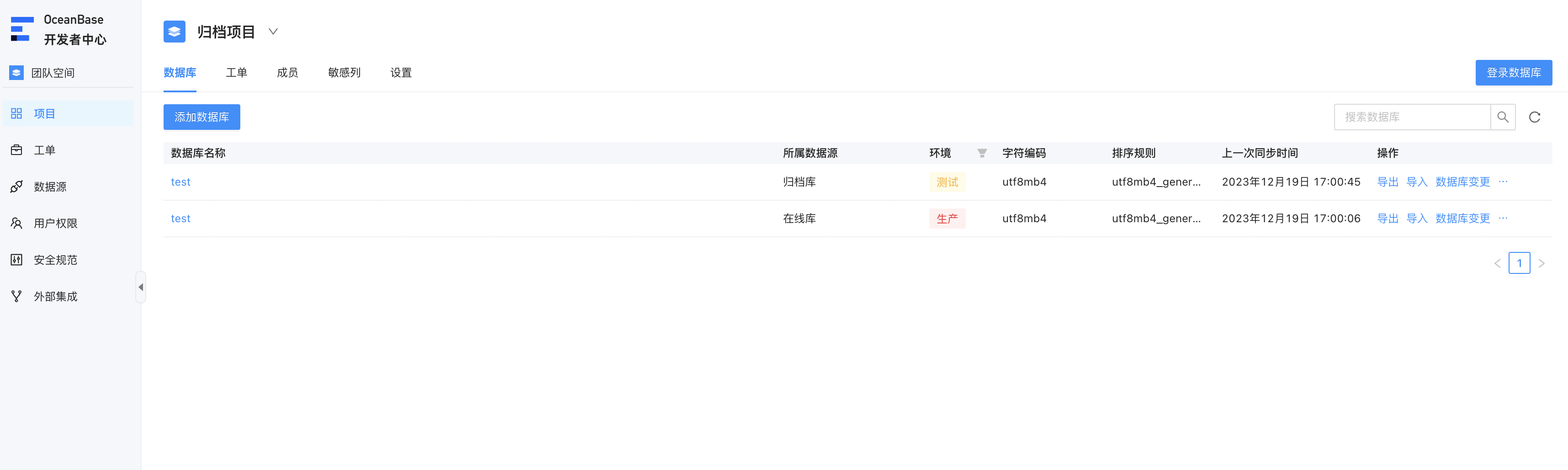
创建归档工单
一次性归档
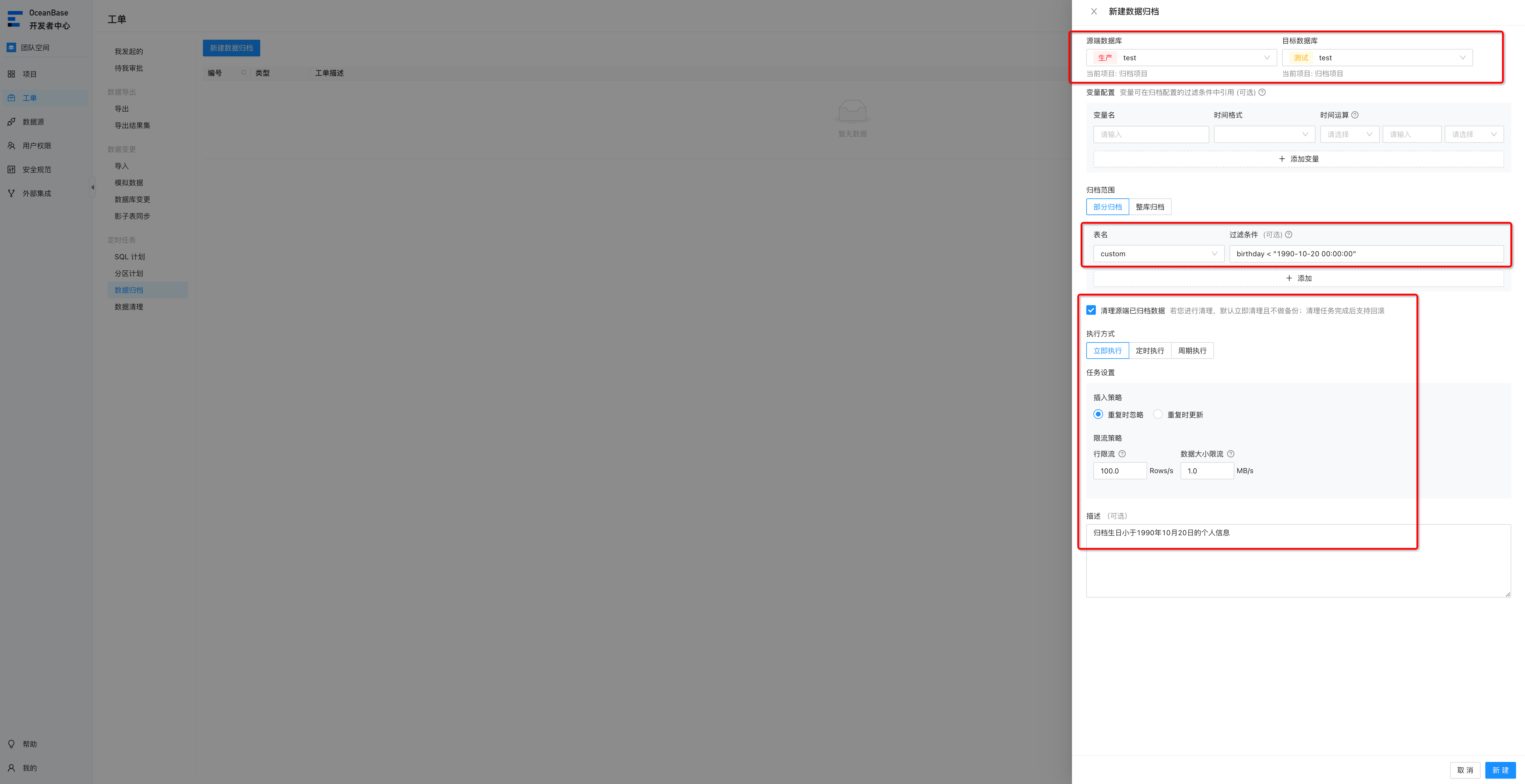
在这里我们先创建一个立即执行的工单,在工单页面中,创建数据归档的工单,工单中选择对应的线上集群和归档集群。
变量配置:因为我们创建的是只执行一次的工单,所以这里可以不用填写,后续创建周期性的工单时,我们再利用变量来配置。
归档范围:选择部分归档或者整库归档,整库归档的话,会把所有数据都归档到归档库中,这里我们选择部分归档,然后填写表名,选择过滤条件。当然也可以选择多张表,每张表指定不同的过滤条件。
清理源端已归档数据:这里是当数据归档完之后,是否需要在在线库中清理,这里我们勾选上。
执行方式:我们这里为了演示,就选择立即执行,当然也可以定时执行。
任务设置:插入策略,表示数据在归档库中主键或者非空唯一键出现冲突时,如何处理,忽略或者更新,这里选择忽略,我们在使用时可根据实际情况选择。
限流策略:可以同时配置行限流和数据大小限流,最终根据最小限额进行限制。
这些配置完成之后大概如下图:
归档前,我们先登录数据库,根据过滤条件确认下数据,等归档完成之后,再看下数据是否正常,可以看到,根据我们的归档条件,生日小于1990年10月20日的有13487人
obclient [test]> select count(*) from custom where birthday < "1990-10-20 00:00:00";
+----------+
| count(*) |
+----------+
| 13487 |
+----------+
1 row in set (0.035 sec)然后点击确认,就会立即执行这个归档和清理工作,在工单中也可以看到这个任务的执行情况。

归档完成之后,再登录数据库查看数据归档情况,在线库中被归档的数据都已经被删除。
obclient [test]> select count(*) from custom where birthday < "1990-10-20 00:00:00";
+----------+
| count(*) |
+----------+
| 0 |
+----------+
1 row in set (0.035 sec)
obclient [test]> select count(*) from custom;
+----------+
| count(*) |
+----------+
| 86513 |
+----------+
1 row in set (0.028 sec)登录归档库,查看数据是否归档成功,如下图,可以看到数据已经全部归档成功
obclient [test]> select count(*) from custom;
+----------+
| count(*) |
+----------+
| 13487 |
+----------+
1 row in set (0.005 sec)对于上述的归档任务,如果想回滚,也可以在工单中,直接点击回滚,将整个任务回滚掉。
周期性归档
配置周期执行的归档任务,方便我们经常要做数据归档,每次归档都要配置比较麻烦,因此可以直接配置周期性执行的归档任务。
在这里我们就可以利用变量名,来实现周期性任务,这里配置多个变量名,例如指定变量名为create_time,选择格式为 yyyy-MM-dd HH:mm:ss, 时间运算栏,则以系统默认变量“archive_date”时间点为基准设置偏移信息,archive_date可以理解为任务触发时的时间,例如下面的配置
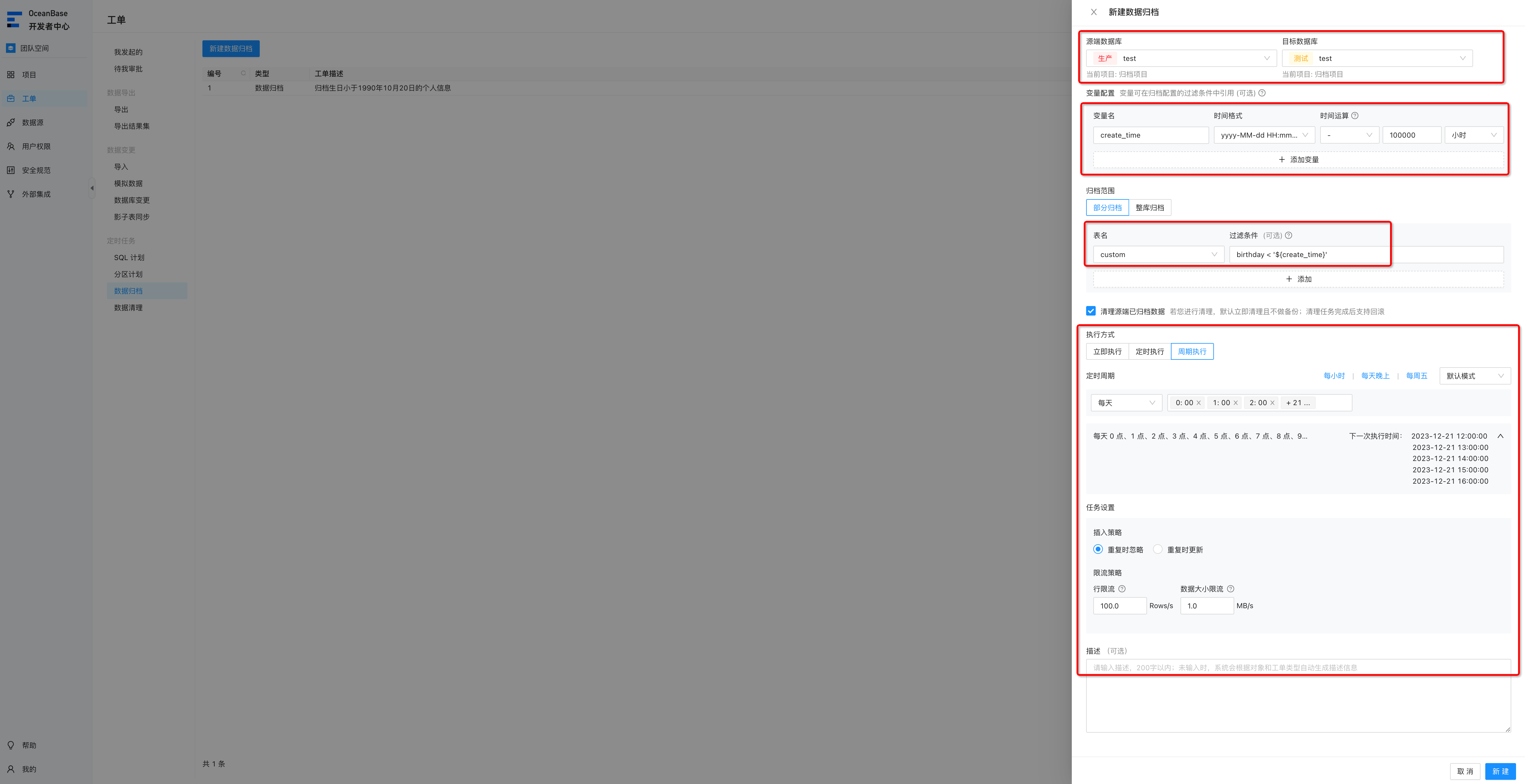
页面上的配置含义从上往下介绍下:指定 create_time = current_time - 100000h,然后过滤条件则是birthday < create_time,周期执行,每小时执行一次。总体含义就是归档 小于 任务触发事件往前100000小时 的数据。
从数据库中我们查看,小于当前时间往前100000小时的数据量,有 40546 条
obclient [test]> select count(*) from custom where birthday < date_sub(curdate(),interval 100000 hour);
+----------+
| count(*) |
+----------+
| 40546 |
+----------+
1 row in set (0.036 sec)等归档任务整点触发完成之后,对比下数据是否归档正确。
obclient [test]> select count(*) from custom where birthday < date_sub(curdate(),interval 100000 hour);
+----------+
| count(*) |
+----------+
| 0 |
+----------+
1 row in set (0.039 sec)
obclient [test]> select count(*) from custom;
+----------+
| count(*) |
+----------+
| 59454 |
+----------+
1 row in set (0.031 sec)可以看到在线库中的数据符合条件的数据已经被清理,而归档后的数据在归档库中:
obclient [test]> select count(*) from custom;
+----------+
| count(*) |
+----------+
| 40546 |
+----------+
1 row in set (0.012 sec)并且这个任务还在周期性被调度,在执行记录中可以看到

以上就是归档功能的简单介绍,各位感兴趣的话,也可以在本地测试和使用。除了归档能力,另外还可以创建单独的数据清理任务,只做清理。配置方式也是类似的。
ODC中也有很多其他强大的功能,目前官方宣布也兼容了mysql,可以将mysql接入进来。另外像数据变更,影子表同步等功能都很有用,后续有机会也可以跟大家分享下这些功能。