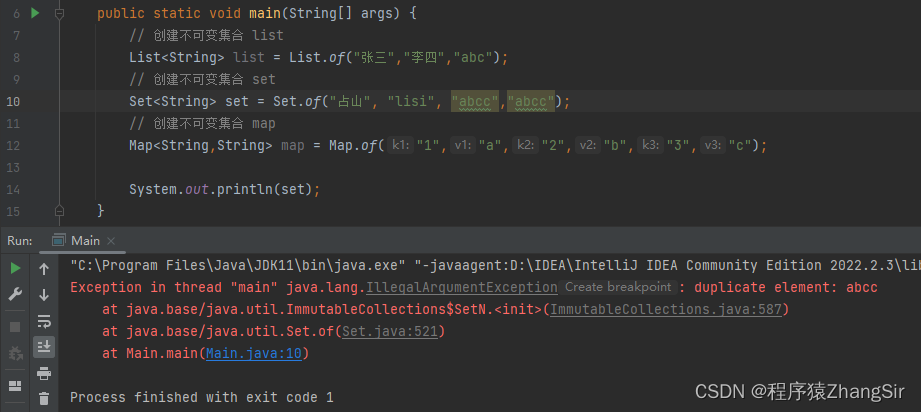
394. 字符串解码
中等
给定一个经过编码的字符串,返回它解码后的字符串。
编码规则为: k[encoded_string],表示其中方括号内部的 encoded_string 正好重复 k 次。注意 k 保证为正整数。
你可以认为输入字符串总是有效的;输入字符串中没有额外的空格,且输入的方括号总是符合格式要求的。
此外,你可以认为原始数据不包含数字,所有的数字只表示重复的次数 k ,例如不会出现像 3a 或 2[4] 的输入。
示例 1:
输入:s = "3[a]2[bc]"
输出:"aaabcbc"
示例 2:
输入:s = "3[a2[c]]"
输出:"accaccacc"
示例 3:
输入:s = "2[abc]3[cd]ef"
输出:"abcabccdcdcdef"
示例 4:
输入:s = "abc3[cd]xyz"
输出:"abccdcdcdxyz"
分析:
对于一个输入的原始字符串s,我的想法是:
1、先把这个字符串分解为基本的子字符串
基本的子字符串有以下几种形式:
(1)一是形如3[a],一个数字加上中括号中的字符或字符串
(2)一是形如3[ab2[c]3[bc]],除了有数字,中括号里面还嵌套的有数字和中括号,是一种复合形式,需要层层剥去中括号,直到不含中括号为止
(3)另一种是ef或xyz这种不含数字和中括号的纯字母字符串
2、然后对每一个子字符串分别进行解码处理
3、最后将解码之后的字符串按顺序拼合起来,即得到问题的结果。
下表可以看出这种处理的过程
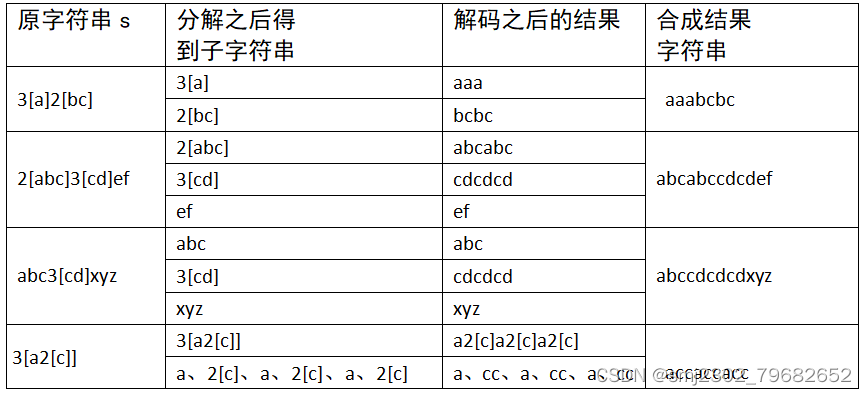
函数mdecode(s)可以对分解之后的子字符串进行解码处理
那么如何将一个原始字符串s分解为符合条件的子字符串呢?
为了使分割的方法更具有通用性,我们使用了一个列表a来记录分割的位置,首先把字符串s的0索引位置加入在a中,然后找到第一个数字的位置,并把这个位置索引加入a,如果0索引位置就是数字的话,则有重复的位置号,后面再去重即可解决。当找到“]”之后,将从之前找到的数字位置到这个“]”位置进行切片,注意要包含这个“]”字符,并判断切出的字符串中“[”“]”的个数是否相等,如果相等则将“]”的索引加入a列表。按照这个的方法重复操作直到s的结尾,最后再把结束索引加入列表a。
对a去重,通过a中给定的索引号位置,对s进行切片处理即可分割为一些基本的子字符串,并存储于列表b中
程序如下:
#函数mdecode(s),对形如‘abc'或3[bc]之类的字符串进行解码
def mdecode(s):
if '[' not in s and ']' not in s:
return s
else:
i=s.index('[')
n=s[:i]
ms=s[i+1:len(s)-1]
return ms*int(n)
def cl(s):
n=len(s)
a=[0]
flag=False #flag为False,则开始取子字符串,为True则还未到字符串结束位置
start=0
for i in range(n):
if s[i] in '123456789' and not flag:
a.append(i)
start=i
flag=True
elif s[i]==']':
x=s[start:i+1]
if x.count('[')==x.count(']'):
a.append(i+1)
flag=False
a.append(n)
#a去重
b=list(set(a))
for i in b:
if a.count(i)>1:
a.remove(i)
print('子字符串起始和结束位置索引号:',a)
b=[]
for i in range(len(a)-1):
x=s[a[i]:a[i+1]]
b.append(x)
print('子字符串列表:',b)
a=''
for i in b:
a+=mdecode(i)
return a
#输入字符串s
s=input('pls input s=')
while True:
a=cl(s)
if a.count('[')==0:
break
else:
s=cl(a)
print('解码之后的字符串:',a)运行实例1
pls input s=abc3[a]2[d]xy
子字符串起始和结束位置索引号: [0, 3, 7, 11, 13]
子字符串列表: ['abc', '3[a]', '2[d]', 'xy']
解码之后的字符串: abcaaaddxy
运行实例2
pls input s=3[a2[bc]3[b]]
子字符串起始和结束位置索引号: [0, 13]
子字符串列表: ['3[a2[bc]3[b]]']
子字符串起始和结束位置索引号: [0, 1, 6, 10, 11, 16, 20, 21, 26, 30]
子字符串列表: ['a', '2[bc]', '3[b]', 'a', '2[bc]', '3[b]', 'a', '2[bc]', '3[b]']
子字符串起始和结束位置索引号: [0, 24]
子字符串列表: ['abcbcbbbabcbcbbbabcbcbbb']
解码之后的字符串: abcbcbbbabcbcbbbabcbcbbb
运行实例3
pls input s=3[ab2[c]3[bc]ac]
子字符串起始和结束位置索引号: [0, 16]
子字符串列表: ['3[ab2[c]3[bc]ac]']
子字符串起始和结束位置索引号: [0, 2, 6, 11, 15, 19, 24, 28, 32, 37, 39]
子字符串列表: ['ab', '2[c]', '3[bc]', 'acab', '2[c]', '3[bc]', 'acab', '2[c]', '3[bc]', 'ac']
子字符串起始和结束位置索引号: [0, 36]
子字符串列表: ['abccbcbcbcacabccbcbcbcacabccbcbcbcac']
解码之后的字符串: abccbcbcbcacabccbcbcbcacabccbcbcbcac
运行实例4
pls input s=efg
子字符串起始和结束位置索引号: [0, 3]
子字符串列表: ['efg']
解码之后的字符串: efg
运行实例5
pls input s=3[2[ab2[b]2[c]]]
子字符串起始和结束位置索引号: [0, 16]
子字符串列表: ['3[2[ab2[b]2[c]]]']
子字符串起始和结束位置索引号: [0, 13, 26, 39]
子字符串列表: ['2[ab2[b]2[c]]', '2[ab2[b]2[c]]', '2[ab2[b]2[c]]']
子字符串起始和结束位置索引号: [0, 2, 6, 10, 12, 16, 20, 22, 26, 30, 32, 36, 40, 42, 46, 50, 52, 56, 60]
子字符串列表: ['ab', '2[b]', '2[c]', 'ab', '2[b]', '2[c]', 'ab', '2[b]', '2[c]', 'ab', '2[b]', '2[c]', 'ab', '2[b]', '2[c]', 'ab', '2[b]', '2[c]']
解码之后的字符串: abbbccabbbccabbbccabbbccabbbccabbbcc
感悟:
在解决问题的过程中,刚开始程序只能处理简单的情况,也就是只有一层中括号的情况,对于那种有中括号嵌套的复合字符串还是无法处理,让我好一阵失望,这才让我去思考更为通用的解码方法。
问题是慢慢解决的,不可能一口吃一个胖子。



![【[NOIP1999 普及组] Cantor 表】](https://img-blog.csdnimg.cn/img_convert/fc9afd6ffef3fe892fc72341b53f77b1.png)