一、总体介绍
1.1 背景介绍
Apache Spark是专为大规模数据计算而设计的快速通用的计算引擎,是一种与 Hadoop 相似的开源集群计算环境,但是两者之间还存在一些不同之处,这些不同之处使 Spark 在某些工作负载方面表现得更加优越。换句话说,Spark 启用了内存分布数据集,除了能够提供交互式查询外,它还可以优化迭代工作负载。Spark SQL是Spark的计算模块之一,专门用于处理结构化的数据。Spark SQL允许用户使用标准的SQL语句来执行SQL的查询和读写,也可以使用Hive SQL来执行对Hive仓库的查询和读写。
在Spark作业中,数据通常在内存中进行计算和操作,并且通过网络进行节点间的数据传输。Snappy压缩算法已经被广泛应用于各种大数据处理框架中,并且通常是默认的压缩选项。在Spark系统中,用户无需额外的配置即可使用Snappy压缩算法,这使得它成为Spark处理数据的首选压缩方式之一。
Snappy压缩算法是一种同时具备非常高的压缩速度,和较为合理的压缩率的压缩算法。Snappy压缩具有速度快、占用内存小、通用性强的优点,被广泛应用于大规模数据处理、网络传输、数据库存储、机器学习、图像处理等多个领域。
目前使用Snappy算法进行压缩解压缩的场景全部基于CPU进行,CPU除了需要维持整个计算场景的数据调度,还需要额外的算力进行压缩解压缩计算。CPU作为通用处理芯片,在大数据高密集型的数据计算上并无明显优势,这使得大部分应用场景下基于CPU运算时计算算力成为性能的主要瓶颈。
中科驭数自研的基于KPU架构的DPU芯片作为专用的数据处理芯片,在处理复杂的数据计算时相比于CPU拥有极高的性能提升。因此将Snappy压缩解压缩算法由CPU卸载到DPU,可以极大的提升计算性能。在复杂场景下,CPU专注于数据传递和计算任务调度,DPU专注于压缩解压缩计算。
中科驭数HADOS是一款敏捷异构软件平台,能够为网络、存储、安全、大数据计算等场景进行提速。对于大数据计算场景,HADOS可以认为是一个异构执行库,提供了数据类型、向量数据结构、表达式计算、IO和资源管理等功能。为了发挥CPU与DPU各自的性能优势,我们开发了HADOS-RACE项目,结合HADOS平台,既能够发挥CPU高速稳定的计算调度能力,又可以发挥DPU的向量化执行能力。
我们通过实验发现,Spark读数据的解压和写数据的压缩过程,在耗时上占比比较高,将Snappy压缩解压缩的计算任务通过HADOS-RACE卸载到DPU上, 相比于纯CPU计算,性能可提升约2倍。
本文将简单介绍基于DPU的Snappy压缩解压缩计算原理,并介绍如何基于DPU和HADOS-RACE来加速Snappy压缩解压缩计算,为大规模数据分析和处理提供更可靠的解决方案。
1.2 挑战和困难
在数据处理和传输的领域,快速且高效的压缩算法对于提高系统性能至关重要。然而,尽管Snappy压缩解压缩算法以其快速的压缩和解压缩速度而闻名,但其却存在一个不容忽视的挑战,即对CPU和内存资源的大量占用,从而导致性能下降的问题。
Snappy算法在压缩和解压缩数据时需要进行复杂的计算和处理。虽然它以其高效的算法设计和优化而著称,但在处理大量数据时,仍会对CPU提出较高的要求。特别是在需要快速压缩或解压缩大文件时,Snappy算法的CPU消耗可能会变得更为显著,从而导致系统整体性能的下降。对于CPU性能较低的系统而言,这一挑战尤为严峻,可能导致系统响应变慢,甚至造成任务阻塞和性能瓶颈。
综上所述,Snappy压缩解压缩算法的高效性和速度带来了性能优势,但其对CPU的大量占用也成为其性能低下的一个主要挑战。
二、整体方案
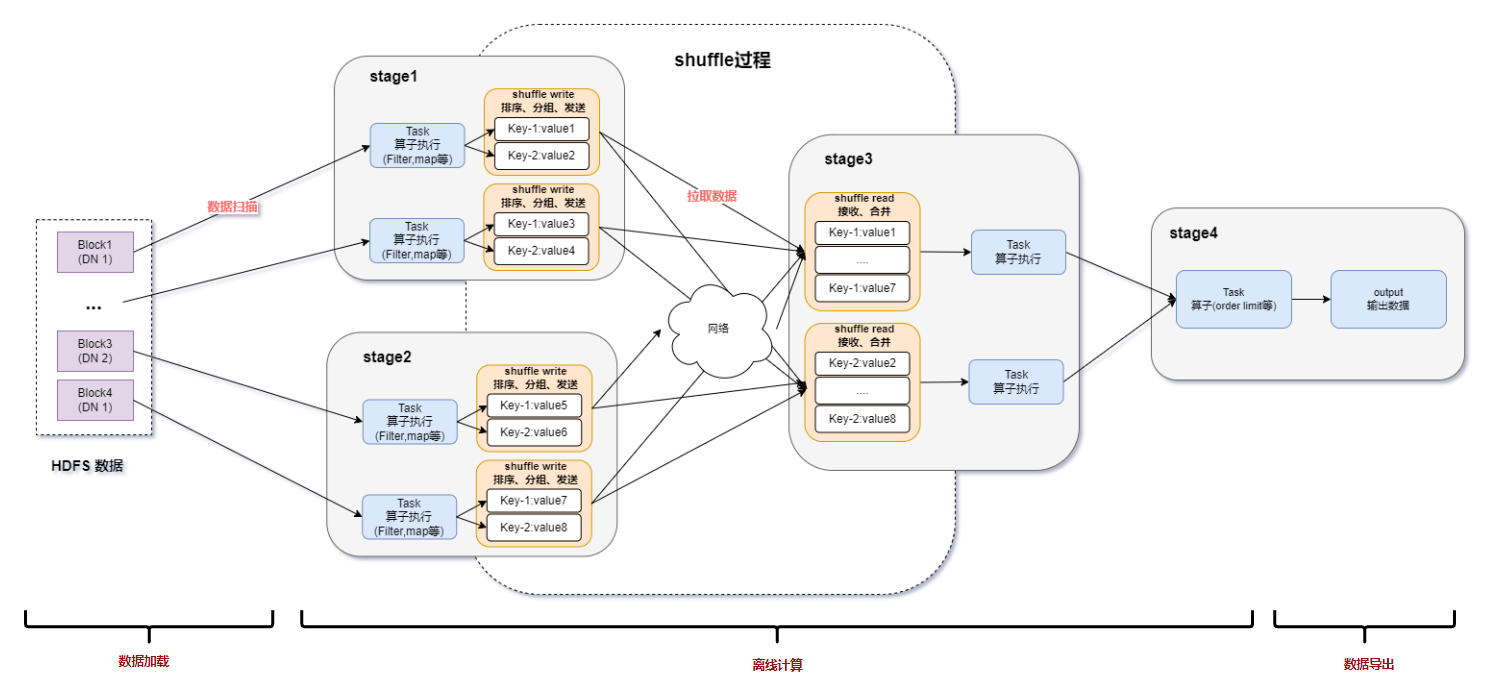
图一:Spark基于DPU Snappy压缩算法的异构加速整体方案
上图所示为Spark SQL的一个涉及FileScan、Shuffle、Aggregate、OrderBy计算的完整数据流转过程,Spark SQL的数据处理首先需要读取HDFS分布式文件存储系统中的Snappy压缩文件,然后会对Snappy压缩文件进行解压缩处理,从而得到计算所需的数据。拿到数据后根据SQL的逻辑进行相应的计算,常见的计算比如Filter、Aggregate、Join、Order By等,经过数据计算拿到想要输出的结果数据。最后会将结果数据写出并按Snappy格式进行压缩,得到的压缩文件会写回到HDFS中存储。
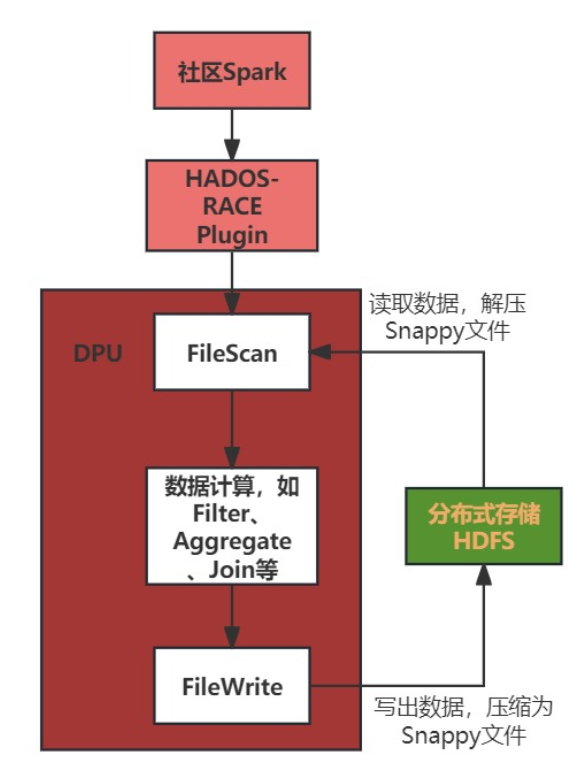
图二:基于DPU的算子卸载加速流程
上图所示为Spark将算子卸载到DPU进行计算的一个通用流程。首先Spark将SQL进行解析并得到最终的物理执行计划,然后将物理执行计划转化为具体的算子操作,Spark会通过HADOS-RACE Plugin将具体算子卸载到DPU进行处理。在DPU处理过程中,首先需要执行FileScan算子,将数据从HDFS文件系统中读取出来并对Snappy压缩文件执行解压缩操作。中间过程是对解压缩的数据进行计算,得到最终的结果数据。最后会将结果数据按Snappy格式压缩并导出到HDFS中存储。
在对整个Spark计算过程进行性能分析后,发现Snappy压缩和解压缩是两个耗时非常高的过程,占整个计算过程的比重较高。因此我们需要对Snappy的压缩和解压缩过程进行加速。
我们采用软硬件结合的方式,在数据压缩解压缩链路的软硬件两大方面都进行了全面提升和加速。
在软件方面,基于硬件对不同场景、数据量的压缩解压缩表现,HADOS-RACE可以灵活选择合适的压缩、解压缩的硬件平台。
在硬件方面,自研的DPU计算引擎拥有强大的Snappy压缩、解压缩能力,满足日益复杂的计算场景。
三、核心加速阶段
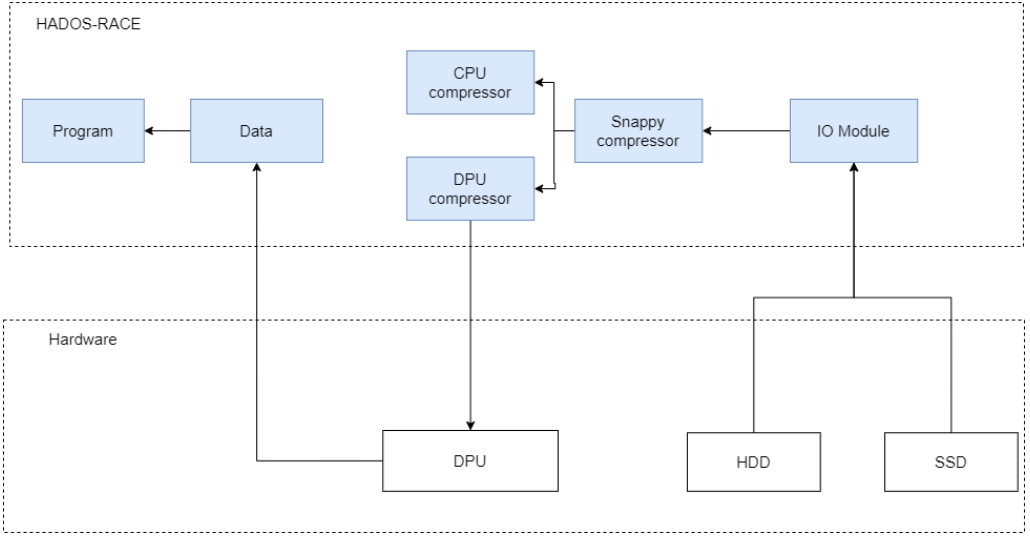
图三:基于DPU的整体加速流程图
加速阶段如上图所示,核心数据加速方案分为两个阶段,分别为 1.智能压缩解压缩策略选择阶段;2.对数据压缩解压缩阶段。
3.1 策略选择阶段
3.1.1 面临挑战
在数据压缩解压缩过程中,压缩解压缩策略选择阶段是整个过程的开始。传统的硬件体系结构中,数据的压缩和解压缩过程通常只能依赖CPU完成,没有其他策略可以选择,从而无法利用GPU、DPU等其他处理器资源。这种局限性导致数据压缩解压缩过程会大量占用CPU资源,从而降低系统的性能。
3.1.2 解决方案与原理
近年来,随着数据处理领域的不断发展和硬件技术的进步,DPU、GPU等计算资源的加入为数据压缩解压缩带来了新的可能性。这些不同的硬件平台具有各自独特的特点和优势,可以根据不同的场景和需求来选择合适的硬件平台进行数据压缩解压缩。
HADOS-RACE的IO模块负责将数据从硬盘读入内存中,并将其交由Compressor模块进行卸载策略判断。通过IO模块的数据加载过程,系统能够根据数据的特点和硬件平台的性能选择合适的压缩解压缩策略,从而实现数据处理的优化和提升。
在HADOS-RACE中,基于硬件对不同场景、数据量的性能表现,可以灵活配置压缩解压缩策略。例如,当数据量比较小的时候,可以直接通过CPU进行压缩解压缩,减少了内存和DPU硬件之间的数据传输,从而提高了系统的性能和效率。而对于大规模数据处理的场景,可以利用DPU等硬件资源进行并行计算,加速数据的处理速度。
3.1.3 优势与效果
HADOS-RACE的智能策略选择模块在数据加载过程中发挥了重要作用,通过分析数据的特征和硬件平台的性能,实现了对压缩解压缩策略的选择。这种灵活配置的策略不仅提高了数据处理的效率,也降低了系统的资源消耗,为数据处理和应用提供了更好的支持。
我们可以根据一定的策略选择合适的硬件平台来进行数据压缩解压缩,从而实现数据压缩解压缩的优化和提升。这为未来的数据压缩解压缩领域的发展带来了新的机遇和挑战,也为用户提供了更加灵活和高效的数据压缩解压缩方案。
3.2 压缩解压缩阶段
3.2.1 面临挑战
由于CPU在数据处理方面具有较强的通用性和灵活性,因此压缩解压缩算法通常被设计为在CPU上执行。然而,与DPU相比,CPU的并行处理能力相对较弱,无法充分发挥硬件资源的潜力。在大规模数据处理的场景下,数据压缩解压缩过程可能成为CPU的瓶颈,导致系统性能下降。此外,由于数据压缩解压缩是一个计算密集型任务,当系统中同时存在其他需要CPU资源的任务时,压缩解压缩过程可能会与其他任务产生竞争,进一步加剧了CPU资源的紧张程度,导致系统整体的响应速度变慢。
3.2.2 解决方案与原理
在传统的硬件体系结构中,数据的压缩和解压缩过程通常只能依赖CPU完成。然而,随着芯片技术的不断发展和创新,现代计算机系统已经实现了DPU等计算资源的利用,从而在数据处理领域带来了革命性的变化。DPU的并行计算能力远远超过CPU,使得它成为处理大规模数据的理想选择。近年来,随着DPU技术的日益成熟和运用,数据压缩解压缩过程已经可以借助DPU来执行,从而大大减少了对CPU资源的占用,提升了系统的性能和效率。
随着DPU芯片技术的不断发展和成熟,DPU已经成为了处理大规模数据的强大工具。DPU的并行计算能力远远超过CPU,能够同时处理大量数据,极大地加快了数据处理的速度。因此,现在可以利用DPU来执行数据的压缩和解压缩过程,从而减少了对CPU资源的占用,提升了系统的性能和效率。
3.2.3 优势与效果
DPU在数据压缩解压缩中的应用,主要体现在以下几个方面:
首先,DPU能够同时处理多个数据块,实现真正的并行计算。在数据压缩解压缩过程中,可以将大规模数据划分成多个小块,然后通过DPU同时对这些数据块进行压缩或解压缩,极大地提高了处理速度。
此外,DPU的计算能力可以轻松处理大规模数据,从而满足了现代大数据处理的需求。可以利用DPU来执行数据的压缩和解压缩过程,从而提高系统的性能和效率。
综上所述,利用DPU进行数据压缩解压缩等算力的卸载,已经成为了计算机系统的重要趋势。通过充分利用DPU的并行计算能力和卡上内存,可以大大减少对CPU资源的占用,提升系统的性能和效率。相信在未来的snappy数据压缩解压缩领域,DPU将会发挥越来越重要的作用。
四、加速效果
基于目前HADOS-RACE已经实现的Snappy压缩解压缩方案,制定了对应的性能测试计划。首先生成snappy测试数据,使用基于CPU和DPU的Spark分别对数据进行处理,记录各自的Snappy压缩解压缩阶段和Spark整体端到端的耗时和吞吐。执行的测试语句为:select * from table where a1 is not null and a2 is not null(尽量减少中间的计算过程,突出Snappy压缩解压缩的过程)。
4.1 压缩解压缩加速效果
单独分析Snappy压缩解压缩阶段,基于CPU的Snappy解压缩,吞吐量为300MB/s。而将解压缩任务卸载到DPU后,DPU核内计算的吞吐量可达到1585MB/s。可以看到,基于DPU进行Snappy解压缩,相比基于CPU进行Snappy解压缩,性能可提升约5倍。
对于系统整体而言,压缩解压缩计算的输入数据和输出数据,如果需要传输到CPU继续做计算,则有额外的PCIe数据传输的时间损耗,由于不同的数据量及压缩比带来的整体效果差别较大,所以以下测试数据仅供参考。表格中的DPU数据均为结合PCIe传输消耗的结果。压缩前的数据量均为128MB,但是由于数据内容不同导致压缩比不同,进而导致吞吐的不同,从以下测试结果中可以看出,压缩率越大,计算占比越高,DPU表现的越好。
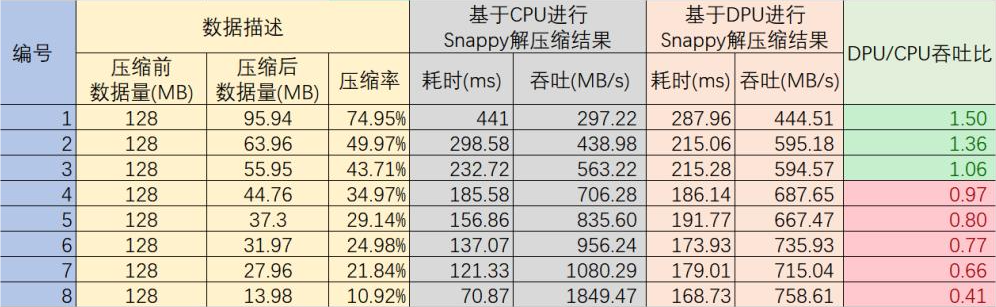
图四:基于DPU的Snappy压缩解压缩方案测试结果
4.2 端到端整体加速效果
基于CPU的Spark计算过程总体比基于DPU的Spark计算过程耗时减少了约50%。相当于基于DPU的端到端执行性能是基于CPU端到端性能的两倍。详细测试结果如下所示:
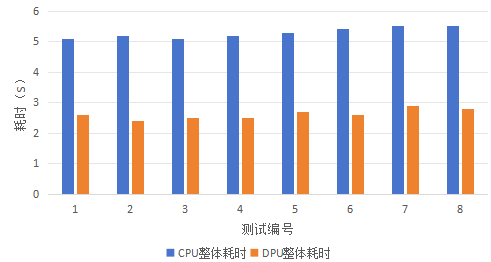
图五:基于DPU加速的端到端方案测试结果
4.3 结果分析
从测试结果中可以看到,在压缩率约为50%至70%时,基于DPU进行Snappy解压缩相比基于CPU进行Snappy解压缩,性能有1.1至1.5倍提升,其他情况下解压缩性能均有下降。造成这一现象的原因是,此次测试没有对DPU进行流程优化,从主机向DPU板卡传输数据时,DPU并没有并发执行计算任务。DPU的计算流程还有着极大的优化空间,优化后,DPU中的计算任务可以以流水线的形式进行调度,则数据传输过程将不会占用整体计算时间。
从Spark整个执行过程来看,基于DPU的Spark计算过程总体比基于CPU的Spark计算过程有2倍的性能提升。单独从Snappy压缩解压缩阶段看,在压缩率20%至100%之间,基于DPU的Snappy解压缩,相比于基于CPU的Snappy解压缩,性能上可以有1.5至5倍的性能提升。
五、未来规划
5.1 现有优势
性能方面,得益于DPU做算力卸载的高效性和智能策略选择算法,相对于传统压缩解压缩方式,基于DPU进行snappy压缩解压缩具备较为明显的性能优势。
资源占用方面,得益于将CPU的计算卸载到DPU上执行,服务器的CPU、内存、IO和网络资源占用等方面都有明显降低。特别是CPU资源,可以将压缩解压缩卸载到DPU的同时完成其他数据计算处理任务。
5.2 未来规划
优化和完善现有功能,继续增加其他算力的卸载。
未来计划在存算分离场景下适配snappy压缩解压缩功能。从远端读取数据后,首先数据会直接经过压缩或解压缩计算,从DPU卡出来的数据已经是经过压缩解压缩的,无需多余的数据传输和计算。




![[NKCTF 2024]web解析](https://img-blog.csdnimg.cn/direct/30d11b0ba6c145d9819bf9d169a944eb.png)