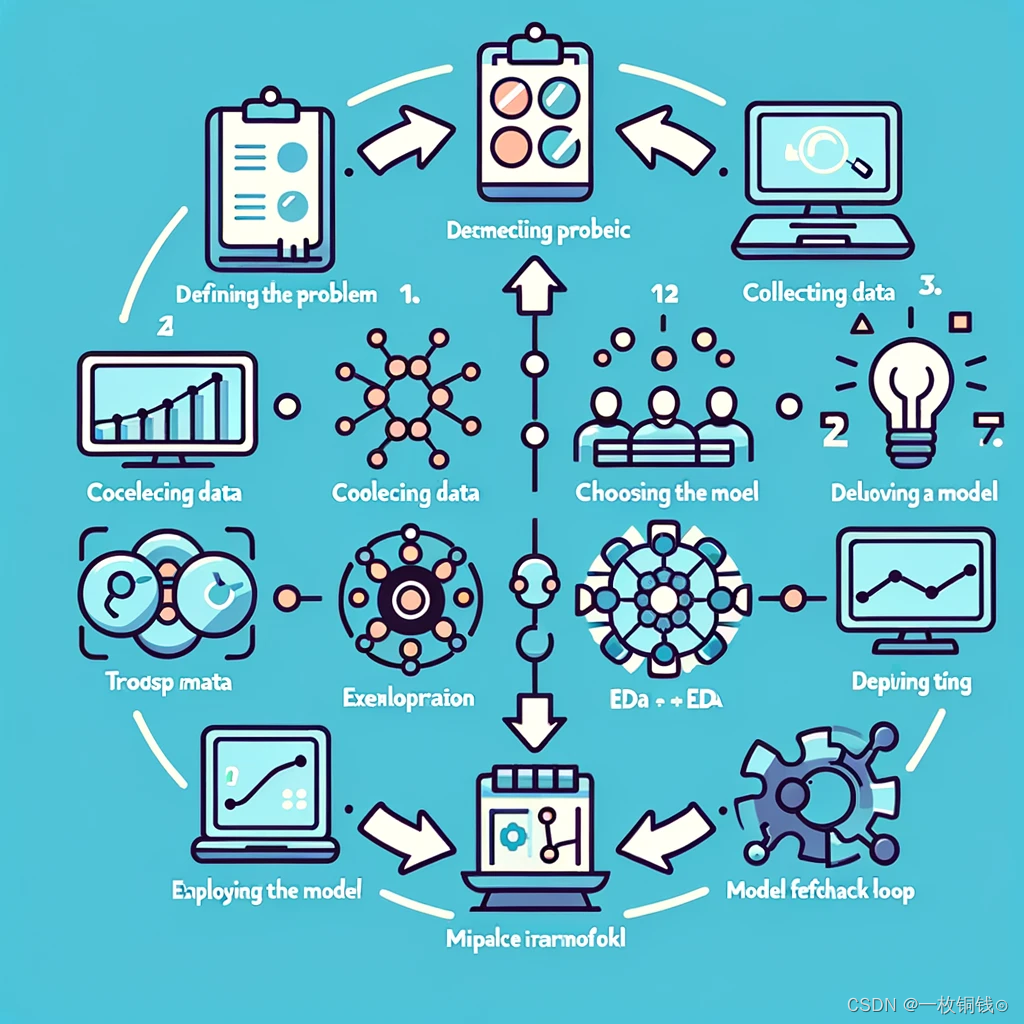
机器学习项目的成功实施依赖于一系列定义良好的步骤。
1. 定义问题
- 问题理解:首先要明确机器学习能够解决的问题。这包括对业务需求的理解,以及如何通过数据驱动的方式来解决这些需求。
- 目标设定:明确项目的目标,包括预期的输出、性能指标以及成功的标准。
2. 数据收集
- 数据源识别:确定数据的来源,这可能包括内部数据库、公开数据集、通过API获取的数据等。
- 数据获取:实际收集数据的过程,可能需要处理大量数据和不同格式的数据。
3. 数据预处理
- 数据清洗:处理缺失值、异常值、错误的数据输入等。确保数据的质量。
- 特征工程:从原始数据中提取特征,这可能包括特征选择、特征生成和特征转换。
- 数据划分:将数据集分为训练集、验证集和测试集,以支持模型的训练和评估。
4. 探索性数据分析(EDA)
- 数据探索:通过统计摘要和可视化手段探索数据,识别数据中的模式、异常和相关性。
- 假设测试:根据业务理解和数据探索的结果,形成关于数据和模型的假设。
5. 选择模型
- 模型对比:根据问题的类型(如分类、回归等)和数据的特性,选择一个或多个机器学习模型进行实验。
- 基线模型:建立一个或几个基线模型,作为性能比较的基准。
6. 训练模型
- 模型训练:使用训练数据集对模型进行训练,这个过程中模型会学习数据中的模式。
- 超参数调优:通过调整模型的参数来找到最佳的模型配置。
7. 评估模型
- 性能度量:使用预先定义的性能指标(如准确率、召回率、F1 分数等)来评估模型的性能。
- 交叉验证:应用交叉验证技术来确保模型的稳定性和泛化能力。
8. 模型改进
- 模型调优:基于评估结果进一步调整模型参数或进行特征工程。
- 集成学习:考虑使用集成学习方法来提高模型的性能。
9. 部署模型
- 模型部署:将训练好的模型部署到生产环境中,使其能够对新数据做出预测。
- 监控和维护:持续监控模型的性能,并根据需要对模型进行更新和维护。
10. 模型反馈循环
- 性能监控:持续收集模型在生产环境中的性能数据。
- 迭代改进:根据收集到的反馈,对模型进行迭代改进,确保其持续满足业务需求。
通过遵循这些步骤,机器学习项目能够更有效地从数据中学习,并提供有价值的预测或决策支持。