目录结构展示了
SuperGluePretrainedNetwork项目的简化版布局。这是一个关于使用SuperGlue算法进行图像配对的深度学习项目,主要包括预训练的模型和执行配对的脚本。
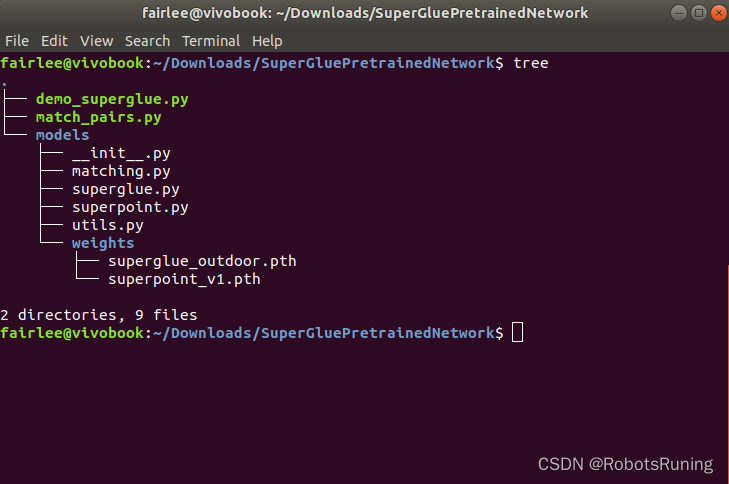
demo_superglue.py
demo_superglue.py脚本的主要作用是展示SuperGlue预训练网络在图像对上进行特征匹配的能力。通过接收实时摄像头输入、视频文件或图像目录作为输入,该脚本能够实时地检测和匹配图像中的特征点,并可视化匹配结果。它是一个交互式的演示,允许用户通过键盘控制来调整匹配参数,同时展示关键点和匹配过程。总结脚本功能:
输入处理:脚本接受多种形式的输入,包括USB摄像头、IP摄像头、图像目录或视频文件,支持通过命令行参数指定。
参数配置:用户可以通过命令行参数自定义多个匹配相关的配置,如关键点检测阈值、非极大值抑制(NMS)半径、Sinkhorn算法迭代次数、匹配阈值等。这些参数影响算法检测和匹配特征点的行为。
特征匹配:使用SuperPoint模型检测关键点和描述符,并通过SuperGlue模型进行特征点匹配。如果输入为视频或图像序列,脚本将连续匹配帧之间的特征点。
可视化:实时展示关键点检测和匹配结果,匹配的关键点会以连线形式显示。用户可以选择是否显示关键点。
交互式控制:提供键盘快捷键,允许用户实时调整关键点和匹配阈值,选择当前帧作为参考帧,以及开启或关闭关键点的可视化等。
输出:如果指定了输出目录,匹配结果将以图像形式保存。这些图像包含了原始图像、检测到的关键点和匹配的连线。
使用场景:
这个脚本非常适用于演示和评估SuperGlue算法在不同场景和条件下的特征匹配性能。它可以用于计算机视觉研究、机器人导航、增强现实应用等领域,为开发者和研究人员提供了一个便捷的工具来理解和利用SuperGlue模型的强大功能。
#! /usr/bin/env python3
# 这是一个 Python 脚本,声明使用 Python 3 作为解释器。
# 导入所需的模块和库。pathlib 用于处理文件路径,
# argparse 用于解析命令行参数,cv2 是 OpenCV 库用于图像处理,
# matplotlib.cm 用于获取颜色映射,torch 是 PyTorch 深度学习库。
from pathlib import Path
import argparse
import cv2
import matplotlib.cm as cm
import torch
# 从本地 models 包中导入 Matching 类和一些实用函数。具体来说:
# Matching 是一个类,用于将 SuperPoint 和 SuperGlue 模型组合在一起进行图像匹配。
# AverageTimer 是一个用于计时和统计平均时间的实用程序类。
# VideoStreamer 是一个用于从各种源读取视频帧或图像的实用程序类。
# make_matching_plot_fast 是一个函数,用于快速生成显示匹配结果的图像。
# frame2tensor 是一个函数,用于将图像帧转换为 PyTorch 张量。
from models.matching import Matching
from models.utils import (AverageTimer, VideoStreamer,
make_matching_plot_fast, frame2tensor)
# 禁用 PyTorch 中的自动求导,因为这是一个推理(inference)过程,不需要计算梯度。
torch.set_grad_enabled(False)
if __name__ == '__main__':
#创建一个 ArgumentParser 对象,用于解析命令行参数。
# description 描述了该程序的功能,formatter_class 指定了如何格式化帮助信息。
parser = argparse.ArgumentParser(
description='SuperGlue demo',
formatter_class=argparse.ArgumentDefaultsHelpFormatter)
# 添加一个命令行参数 --input。
# 它指定输入源,可以是 USB 摄像头 ID、IP 摄像头 URL、图像目录或视频文件路径。
# 默认值为 '0',表示使用默认的 USB 摄像头。
parser.add_argument(
'--input', type=str, default='0',
help='ID of a USB webcam, URL of an IP camera, '
'or path to an image directory or movie file')
# 添加一个命令行参数 --output_dir。它指定输出目录,如果为 None(默认值)则不输出任何帧。
parser.add_argument(
'--output_dir', type=str, default=None,
help='Directory where to write output frames (If None, no output)')
# 添加一个命令行参数 --image_glob。它指定图像文件扩展名类型,如果输入是图像目录。
# 默认值为 ['*.png', '*.jpg', '*.jpeg'],表示将读取 PNG、JPG 和 JPEG 格式的图像文件。
parser.add_argument(
'--image_glob', type=str, nargs='+', default=['*.png', '*.jpg', '*.jpeg'],
help='Glob if a directory of images is specified')
# 添加一个命令行参数 --skip。它指定跳过的帧数或图像数,如果输入是视频或图像目录。默认值为 1,表示不跳过任何帧或图像。
parser.add_argument(
'--skip', type=int, default=1,
help='Images to skip if input is a movie or directory')
# 添加一个命令行参数 --max_length。它指定最大长度,如果输入是视频或图像目录。默认值为 1000000,表示读取所有帧或图像。
parser.add_argument(
'--max_length', type=int, default=1000000,
help='Maximum length if input is a movie or directory')
# 添加一个命令行参数 --resize。它用于在运行推理前调整输入图像的大小。
# 如果提供两个数字,则调整到指定的宽高;如果提供一个数字,则调整最大维度;
# 如果为 -1,则不调整大小。默认值为 [640, 480],表示将图像调整为 640x480 的分辨率。
parser.add_argument(
'--resize', type=int, nargs='+', default=[640, 480],
help='Resize the input image before running inference. If two numbers, '
'resize to the exact dimensions, if one number, resize the max '
'dimension, if -1, do not resize')
# 添加一个命令行参数 --superglue。
# 它指定使用 SuperGlue 算法的室内或室外预训练权重。可选值为 'indoor' 和 'outdoor',默认值为 'indoor'。
parser.add_argument(
'--superglue', choices={'indoor', 'outdoor'}, default='indoor',
help='SuperGlue weights')
# 添加一个命令行参数 --max_keypoints。它指定保留的最大关键点数量。
# 如果设置为 -1(默认值),则保留所有检测到的关键点。
parser.add_argument(
'--max_keypoints', type=int, default=-1,
help='Maximum number of keypoints detected by Superpoint'
' (\'-1\' keeps all keypoints)')
# 添加一个命令行参数 --keypoint_threshold。它指定 SuperPoint 关键点检测器的置信度阈值。默认值为 0.005。
parser.add_argument(
'--keypoint_threshold', type=float, default=0.005,
help='SuperPoint keypoint detector confidence threshold')
# 添加一个命令行参数 --nms_radius。它指定 SuperPoint 算法中非最大值抑制(NMS)的半径。默认值为 4。注释说明该值必须为正数。
parser.add_argument(
'--nms_radius', type=int, default=4,
help='SuperPoint Non Maximum Suppression (NMS) radius'
' (Must be positive)')
# 添加一个命令行参数 --sinkhorn_iterations。它指定 SuperGlue 算法中 Sinkhorn 迭代的次数。默认值为 20。
parser.add_argument(
'--sinkhorn_iterations', type=int, default=20,
help='Number of Sinkhorn iterations performed by SuperGlue')
# 添加一个命令行参数 --match_threshold。它指定 SuperGlue 算法中匹配的阈值。默认值为 0.2。
parser.add_argument(
'--match_threshold', type=float, default=0.2,
help='SuperGlue match threshold')
# 添加一个命令行参数 --show_keypoints。它是一个布尔标志,用于指定是否在结果图像中显示检测到的关键点。如果设置该标志,则显示关键点。
parser.add_argument(
'--show_keypoints', action='store_true',
help='Show the detected keypoints')
# 添加一个命令行参数 --no_display。
# 它是一个布尔标志,用于指定是否不显示任何图像。如果设置该标志,则不显示任何图像,这在远程运行时可能会很有用。
parser.add_argument(
'--no_display', action='store_true',
help='Do not display images to screen. Useful if running remotely')
# 添加一个命令行参数 --force_cpu。
# 它是一个布尔标志,用于指定是否强制使用 CPU 模式运行推理,而不使用 GPU。如果设置该标志,则强制使用 CPU 模式。
parser.add_argument(
'--force_cpu', action='store_true',
help='Force pytorch to run in CPU mode.')
opt = parser.parse_args()
# 解析命令行参数并打印出解析后的结果。
print(opt)
# 对上面的处理 --resize 参数进行处理,确保其格式正确(因为--resize不能输错),并打印出将要执行的调整操作。
if len(opt.resize) == 2 and opt.resize[1] == -1:
opt.resize = opt.resize[0:1]
if len(opt.resize) == 2:
print('Will resize to {}x{} (WxH)'.format(
opt.resize[0], opt.resize[1]))
elif len(opt.resize) == 1 and opt.resize[0] > 0:
print('Will resize max dimension to {}'.format(opt.resize[0]))
elif len(opt.resize) == 1:
print('Will not resize images')
else:
raise ValueError('Cannot specify more than two integers for --resize')
# 根据 GPU 是否可用和是否强制使用 CPU 模式,确定运行推理的设备(CUDA 或 CPU)。然后打印出将在哪个设备上运行推理。
device = 'cuda' if torch.cuda.is_available() and not opt.force_cpu else 'cpu'
print('Running inference on device \"{}\"'.format(device))
# 创建一个配置字典,其中包含了 SuperPoint 和 SuperGlue 算法的相关参数。这些参数的值来自于命令行参数。
config = {
'superpoint': {
'nms_radius': opt.nms_radius,
'keypoint_threshold': opt.keypoint_threshold,
'max_keypoints': opt.max_keypoints
},
'superglue': {
'weights': opt.superglue,
'sinkhorn_iterations': opt.sinkhorn_iterations,
'match_threshold': opt.match_threshold,
}
}
# 实例化一个 Matching 对象,将其设置为评估模式,并移动到指定的设备上。同时定义了一个列表 keys,用于存储关键信息的键名。
matching = Matching(config).eval().to(device)
keys = ['keypoints', 'scores', 'descriptors']
# 实例化一个 VideoStreamer 对象,用于从指定的输入源读取帧或图像。
# 读取第一帧,并确保读取成功。如果读取失败,则打印一条错误消息,提示尝试使用不同的 --input 参数。
vs = VideoStreamer(opt.input, opt.resize, opt.skip,
opt.image_glob, opt.max_length)
frame, ret = vs.next_frame()
assert ret, 'Error when reading the first frame (try different --input?)'
# 将第一帧转换为张量,并使用 SuperPoint 模型进行处理。
# 将结果存储在 last_data 字典中,同时添加一些其他必需的键值对。保存第一帧的图像和帧 ID。
frame_tensor = frame2tensor(frame, device)
last_data = matching.superpoint({'image': frame_tensor})
last_data = {k+'0': last_data[k] for k in keys}
last_data['image0'] = frame_tensor
last_frame = frame
last_image_id = 0
# 如果指定了输出目录,则创建该目录(如果不存在),并打印一条消息,说明将输出写入该目录。
if opt.output_dir is not None:
print('==> Will write outputs to {}'.format(opt.output_dir))
Path(opt.output_dir).mkdir(exist_ok=True)
# 如果没有指定不显示图像,则创建一个名为 "SuperGlue matches" 的窗口,用于显示结果。
# 调整窗口大小为 1280x480 像素。否则,打印一条消息说明将跳过可视化,不会显示任何 GUI。
if not opt.no_display:
cv2.namedWindow('SuperGlue matches', cv2.WINDOW_NORMAL)
cv2.resizeWindow('SuperGlue matches', 640*2, 480)
else:
print('Skipping visualization, will not show a GUI.')
# 打印键盘控制说明,解释每个按键对应的操作。
print('==> Keyboard control:\n'
'\tn: select the current frame as the anchor\n'
'\te/r: increase/decrease the keypoint confidence threshold\n'
'\td/f: increase/decrease the match filtering threshold\n'
'\tk: toggle the visualization of keypoints\n'
'\tq: quit')
# 实例化一个 AverageTimer 对象,用于计时和统计每次迭代的耗时。
timer = AverageTimer()
# 进入主循环。读取下一帧,如果读取失败则退出循环并打印一条消息。更新计时器。计算当前帧和上一帧的 ID。
while True:
frame, ret = vs.next_frame()
if not ret:
print('Finished demo_superglue.py')
break
timer.update('data')
stem0, stem1 = last_image_id, vs.i - 1
# 这是主循环,会一直运行直到视频流结束。
# vs.next_frame()从视频流中获取下一帧并将其赋值给frame。
# ret是一个布尔值,表示帧是否成功获取。如果ret为False,意味着视频流已结束,因此会打印一条消息并跳出循环。
# timer.update('data')用于更新数据处理所用时间的计时器。stem0和stem1用于命名输出文件。
frame_tensor = frame2tensor(frame, device)
# 这一行将当前视频帧frame转换为PyTorch的张量格式。
# frame2tensor是一个自定义函数,它将图像帧数据转换为张量,以便输入到神经网络模型中进行处理。device是指定将张量放在CPU还是GPU上的参数。
pred = matching({**last_data, 'image1': frame_tensor})
# 这里调用了一个名为matching的函数,传入两个参数:
# **last_data - 这是一个Python的解包操作,将last_data字典中的键值对解包作为单独的参数传入。
# 'image1': frame_tensor - 将当前帧张量作为一个新的键值对添加到参数中。
# matching函数执行了SuperGlue算法,输入是之前的数据last_data和当前帧frame_tensor。
# 它的返回值pred是一个字典,包含了预测的关键点、匹配和匹配分数等。
kpts0 = last_data['keypoints0'][0].cpu().numpy()
kpts1 = pred['keypoints1'][0].cpu().numpy()
matches = pred['matches0'][0].cpu().numpy()
confidence = pred['matching_scores0'][0].cpu().numpy()
# 这四行代码从last_data和pred字典中提取关键点、匹配和置信度分数,并将它们转换为NumPy数组形式。
# kpts0是上一帧(last_data)中的关键点
# kpts1是当前帧中预测的关键点
# matches是当前帧中每个关键点与上一帧关键点的匹配索引,如果为-1则表示无匹配
# confidence是每个匹配的置信度分数
# 这些数据将用于后续的可视化和分析。最后的.cpu().numpy()是将PyTorch的张量数据转换为NumPy数组,以便进行后续的数值计算和操作。
timer.update('forward')
# 这一行更新一个计时器,用于记录模型的前向传播(即SuperGlue匹配算法)所用的时间,可用于性能分析和优化。
valid = matches > -1
mkpts0 = kpts0[valid]
mkpts1 = kpts1[matches[valid]]
color = cm.jet(confidence[valid])
text = [
'SuperGlue',
'Keypoints: {}:{}'.format(len(kpts0), len(kpts1)),
'Matches: {}'.format(len(mkpts0))
]
k_thresh = matching.superpoint.config['keypoint_threshold']
m_thresh = matching.superglue.config['match_threshold']
small_text = [
'Keypoint Threshold: {:.4f}'.format(k_thresh),
'Match Threshold: {:.2f}'.format(m_thresh),
'Image Pair: {:06}:{:06}'.format(stem0, stem1),
]
# 这部分准备可视化所需的数据。valid是一个布尔掩码,选择只有有效匹配(匹配值大于-1)。
# mkpts0和mkpts1分别是前一帧和当前帧中有效匹配的关键点。
# color是一个颜色列表,用于可视化匹配,颜色基于匹配的置信度。
# text是一个字符串列表,将在可视化中显示。
# k_thresh和m_thresh是SuperGlue算法使用的关键点和匹配阈值。
# small_text是一个字符串列表,将作为小字体显示在可视化中。
out = make_matching_plot_fast(
last_frame, frame, kpts0, kpts1, mkpts0, mkpts1, color, text,
path=None, show_keypoints=opt.show_keypoints, small_text=small_text)
# 该行调用make_matching_plot_fast函数创建前一帧和当前帧之间匹配的可视化图像。
# 它将前一帧、当前帧、关键点、有效关键点、颜色、文本和其他参数作为输入,并返回可视化图像out。
if not opt.no_display:
cv2.imshow('SuperGlue matches', out)
key = chr(cv2.waitKey(1) & 0xFF)
if key == 'q':
vs.cleanup()
print('Exiting (via q) demo_superglue.py')
break
elif key == 'n': # set the current frame as anchor
last_data = {k+'0': pred[k+'1'] for k in keys}
last_data['image0'] = frame_tensor
last_frame = frame
last_image_id = (vs.i - 1)
elif key in ['e', 'r']:
# Increase/decrease keypoint threshold by 10% each keypress.
d = 0.1 * (-1 if key == 'e' else 1)
matching.superpoint.config['keypoint_threshold'] = min(max(
0.0001, matching.superpoint.config['keypoint_threshold']*(1+d)), 1)
print('\nChanged the keypoint threshold to {:.4f}'.format(
matching.superpoint.config['keypoint_threshold']))
elif key in ['d', 'f']:
# Increase/decrease match threshold by 0.05 each keypress.
d = 0.05 * (-1 if key == 'd' else 1)
matching.superglue.config['match_threshold'] = min(max(
0.05, matching.superglue.config['match_threshold']+d), .95)
print('\nChanged the match threshold to {:.2f}'.format(
matching.superglue.config['match_threshold']))
elif key == 'k':
opt.show_keypoints = not opt.show_keypoints
# 这部分代码处理可视化的显示和用户输入。
# 如果opt.no_display为False,它会使用cv2.imshow显示可视化图像。
# 然后使用cv2.waitKey(1)等待按键。如果按下'q'键,它会清理视频流并退出循环。
# 如果按下'n'键,它会将当前帧设置为新的锚帧用于匹配。如果按下'e'或'r'键,它会将关键点阈值增加或减少10%。
# 如果按下'd'或'f'键,它会将匹配阈值增加或减少0.05。如果按下'k'键,它会切换是否在可视化中显示关键点。
timer.update('viz')
timer.print()
# 更新可视化步骤所用时间的计时器,并打印每个步骤(数据、前向传播、可视化)的计时。
if opt.output_dir is not None:
#stem = 'matches_{:06}_{:06}'.format(last_image_id, vs.i-1)
stem = 'matches_{:06}_{:06}'.format(stem0, stem1)
out_file = str(Path(opt.output_dir, stem + '.png'))
print('\nWriting image to {}'.format(out_file))
cv2.imwrite(out_file, out)
# 如果opt.output_dir不为None,它会使用stem0和stem1值构造输出图像的文件名,并使用cv2.imwrite将可视化图像out写入该文件。
cv2.destroyAllWindows()
vs.cleanup()
# 总的来说,这段代码演示了如何使用SuperGlue算法在视频流的帧之间进行特征匹配。
# 它提供了匹配的可视化效果,并允许用户调整关键点和匹配阈值,以及将可视化保存为文件。match_pairs.py
这段代码是用于评估
SuperGlue算法在图像对匹配和位姿估计方面的性能。主要流程包括读取图像对,使用SuperGlue进行特征匹配,可选地进行位姿估计评估,以及可视化匹配结果。下面是对其主要目的和功能的详细解释:主要目的和功能
图像对的处理:脚本从指定的文件读取图像对列表,这些图像对可能包含或不包含用于评估的地面真实位姿信息。
配置参数解析:通过命令行参数,用户可以自定义多个选项,包括输入输出路径、图像尺寸、
SuperGlue配置参数(如匹配阈值、关键点数量限制)、是否进行结果可视化、是否评估位姿估计准确性等。模型初始化:使用给定的配置参数(关键点检测阈值、NMS半径、
SuperGlue的权重等),初始化SuperPoint和SuperGlue模型。匹配和评估:对每对图像,执行以下步骤:
- 读取并预处理图像(可选地调整大小)。
- 使用
SuperPoint提取关键点和描述符,SuperGlue进行关键点匹配。- 如果启用评估(--eval),基于地面真实位姿和内参,估计图像对的相对位姿,并计算位姿估计误差和匹配精度。
结果保存:匹配结果(关键点、匹配对、匹配得分等)被保存到
.npz文件中。如果进行了评估,位姿估计误差和匹配精度也会被保存。可视化:如果启用可视化(--viz),匹配结果会以图像形式保存,展示匹配的关键点对。如果还进行了评估,还会展示位姿估计的评估结果。
性能评估报告:如果进行了评估,脚本最后会输出一个性能评估报告,包括位姿估计误差的AUC(Area Under the Curve)值和匹配精度。
总结
这段代码提供了一个完整的流程,用于评估
SuperGlue算法在特定数据集上处理图像对匹配和位姿估计的性能。它不仅能够处理图像对、执行特征匹配,还能根据地面真实数据评估算法的准确性,并通过图像可视化直观展示匹配效果。这对于算法开发者和研究者来说是一个非常有用的工具,可以帮助他们测试和改进SuperGlue算法在不同场景下的表现。
models
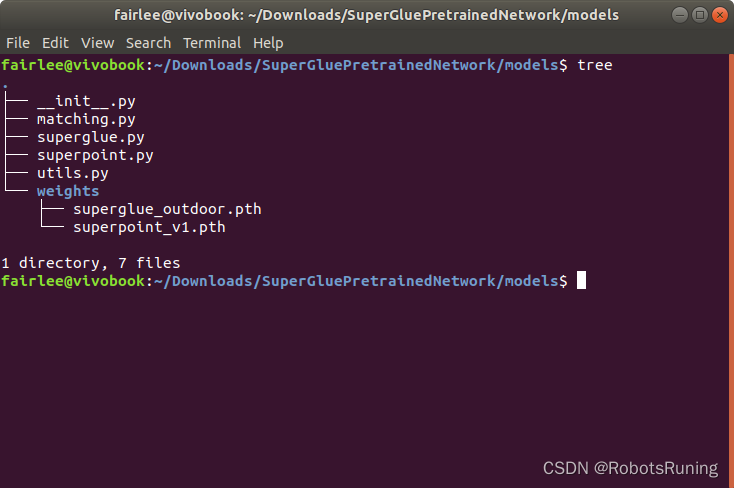
在
SuperGluePretrainedNetwork/models目录中,我们可以看到一个组织良好的模块结构,旨在提供图像特征匹配功能,主要利用SuperPoint和SuperGlue这两个深度学习模型。下面是对这个目录结构的详细分析,帮助你更好地理解每个组成部分的作用:文件和目录概览
__init__.py:这是一个空文件,其存在标志着models目录被Python视为一个包(Package)。这使得你可以从这个目录(包)中导入模块,比如matching.py或superglue.py。
matching.py:这个文件定义了Matching类,它是整个功能的核心。Matching类封装了特征点提取(通过SuperPoint模型)和特征点匹配(通过SuperGlue模型)的流程。简单来说,就是它负责接收图像,然后利用下面介绍的两个模型来找出图像间的匹配点。
superglue.py:定义了SuperGlue模型的结构和功能。SuperGlue用于匹配两组特征点(通常由SuperPoint提取),输出匹配对和每对匹配的置信度。SuperGlue在特征点匹配领域表现出色,能够处理复杂的场景和变化。
superpoint.py:定义了SuperPoint模型的结构和功能。SuperPoint主要用于从图像中提取特征点及其描述符。这些特征点和描述符随后可以用于匹配,以找出两个图像间相同的点。
utils.py:提供了一些辅助功能,如图像读取、预处理、评估函数等。这些工具函数支持上述模型的运行和结果的评估。
weights/目录:包含预训练模型权重文件,分别是:
superglue_outdoor.pth:用于SuperGlue模型的预训练权重,针对室外场景优化。superpoint_v1.pth:SuperPoint模型的预训练权重。总结
models目录提供了一套完整的工具,用于从图像中提取特征点(SuperPoint)、将这些特征点进行匹配(SuperGlue),并包含了必要的工具函数(utils.py)及预训练模型权重(weights/目录)以便直接使用。通过matching.py封装的Matching类,用户可以方便地实现图像匹配的端到端流程,无需深入了解每个模型的内部细节。对于初学者来说,理解每个文件的基本作用和如何协同工作是理解整个系统的关键。
__init__.py
__init__.py:这个文件通常用来将一个目录标记为Python的包。它可以为空,也可以用来写一些初始化代码或者为包定义一个方便的导入接口。首先查看这个文件,虽然它可能不包含对模型理解关键的信息,但它是理解包结构的起点。
superpoint.py
这段代码定义了
SuperPoint类,是一个用于计算机视觉任务的深度学习模型,主要用于关键点检测和特征描述。下面是对这段代码主要功能的解释:1. 模型的目的和功能
SuperPoint模型的核心功能是从输入的图像中自动检测出关键点(interest points 或 corners),并为每个检测到的关键点生成一个描述符(descriptor)。关键点检测允许模型识别图像中的显著特征位置,而描述符为这些关键点提供了一种量化的表示,使得模型可以比较不同图像中关键点的相似度。2. 模型结构和流程
- 编码器网络:模型通过一系列卷积层(
conv1a到conv4b)处理输入图像,这部分构成了共享的特征提取器或编码器。- 关键点检测头:接着,使用额外的卷积层(
convPa和convPb)从共享特征中预测每个像素是否为关键点以及其得分。这些得分经过非最大抑制(NMS)处理,以确保关键点的分布合理且不过于密集。- 描述符生成头:另一组卷积层(
convDa和convDb)用于生成每个位置的特征描述符,描述符通过插值操作在关键点的精确位置被采样。- 预处理和后处理:模型包含了几个关键的预处理和后处理步骤,如
simple_nms函数用于非最大抑制,remove_borders用于移除边界附近的关键点,top_k_keypoints用于选择得分最高的K个关键点。3. 使用预训练权重
- 通过加载
superpoint_v1.pth中的预训练权重,SuperPoint模型可以直接用于关键点检测和描述符计算,而无需从头开始训练。这使得模型在实际应用中更加高效和实用。4. 主要用途
SuperPoint模型的输出(关键点位置、得分和描述符)可以用于多种计算机视觉任务,如图像匹配、目标跟踪、三维重建等。描述符的匹配允许模型识别不同图像之间的相同特征,是许多视觉系统的基础。总结
这段代码实现了
SuperPoint模型,包含了从输入图像中检测关键点和生成描述符的完整流程,以及模型的加载和应用方法。通过预训练权重和详细的网络结构定义,它为进行高效的关键点检测和特征描述提供了强大的工具。
from pathlib import Path
# Path类属于pathlib模块,它提供了一种面向对象的方式来处理和构建文件系统路径。
# 相比于传统的文件路径操作,如使用字符串和os模块的函数,pathlib使得路径操作更加直观和易于理解。
# 可以用来创建新路径、修改路径、检查路径是否存在、列出目录内容等。
import torch
# torch是PyTorch的核心库,是一个广泛使用的开源机器学习库,尤其用于深度学习应用。
# 它提供了一个多维数组对象(称为张量),这个对象类似于NumPy的数组,但它还可以在GPU上运行以加速计算。
# 此外,torch还包括了自动微分功能,方便了神经网络训练中的梯度计算,以及一个全面的深度学习模型库。
from torch import nn
# nn是PyTorch中的一个子模块,全称为torch.nn。
# 它包含了构建神经网络所需的各种模块和类,例如各种层类型(全连接层、卷积层、池化层等)、激活函数、损失函数等。
# 这个模块的设计目的是为了简化和加速神经网络模型的开发过程。通过torch.nn,开发者可以以模块化的方式来构建复杂的网络结构。
def simple_nms(scores, nms_radius: int):
""" 这个函数实现了一个简单版本的非最大抑制(Non-Maximum Suppression)算法。
非最大抑制(NMS)是计算机视觉和图像处理中常用的一种技术,用于确保在目标检测等任务中,每个目标只被检测一次。
这种方法通常在检测到多个相邻的候选目标时使用,它会抑制(即置零)非最大的局部峰值点,只保留最强的信号点。
在这种情况下,simple_nms函数通过一种简易的方法实现了非最大抑制,用于降低关键点检测中的冗余。 """
# 参数:
# - scores: 输入的分数图,通常为二维张量,表示图像中每个像素的得分。
# - nms_radius: NMS操作的半径,确定了需要抑制的邻域大小。
#
# 返回:
# - 经过NMS处理后的分数图,邻近的非最大点被抑制为零。
assert(nms_radius >= 0)
def max_pool(x):
return torch.nn.functional.max_pool2d(
x, kernel_size=nms_radius*2+1, stride=1, padding=nms_radius)
zeros = torch.zeros_like(scores)
max_mask = scores == max_pool(scores)
for _ in range(2):
supp_mask = max_pool(max_mask.float()) > 0
supp_scores = torch.where(supp_mask, zeros, scores)
new_max_mask = supp_scores == max_pool(supp_scores)
max_mask = max_mask | (new_max_mask & (~supp_mask))
return torch.where(max_mask, scores, zeros)
def remove_borders(keypoints, scores, border: int, height: int, width: int):
# """ """
# 移除靠近边界的关键点。
#
# 参数:
# - keypoints: 关键点的坐标数组,形状为[N, 2],其中N是关键点的数量。
# - scores: 与关键点对应的分数数组,形状为[N]。
# - border: 边界宽度,函数将移除距离图像边界小于这个宽度的关键点。
# - height: 图像的高度。
# - width: 图像的宽度。
#
# 返回:
# - 移除靠近边界后的关键点坐标和分数数组。
# """ """
mask_h = (keypoints[:, 0] >= border) & (keypoints[:, 0] < (height - border))
mask_w = (keypoints[:, 1] >= border) & (keypoints[:, 1] < (width - border))
mask = mask_h & mask_w
return keypoints[mask], scores[mask]
def top_k_keypoints(keypoints, scores, k: int):
# """
# 从所有关键点中选出得分最高的前k个关键点。
#
# 参数:
# - keypoints: 关键点的坐标数组,形状通常为[N, 2],其中N是关键点的数量。
# - scores: 与关键点对应的得分数组,形状为[N]。
# - k: 指定想要选出的关键点的数量。
#
# 返回:
# - 根据得分筛选出的前k个关键点的坐标和得分。
# """
# 如果请求的关键点数量k不小于输入的关键点数量,则直接返回所有关键点和得分
if k >= len(keypoints):
return keypoints, scores
scores, indices = torch.topk(scores, k, dim=0)
return keypoints[indices], scores
def sample_descriptors(keypoints, descriptors, s: int = 8):
# """
# 在关键点的位置进行描述子的插值操作。
#
# 参数:
# - keypoints: 关键点的坐标数组,形状通常为 [N, 2],N为关键点数量。
# - descriptors: 描述子张量,形状为 [B, C, H, W],其中:
# B 是批次大小,
# C 是每个描述子的通道数,
# H 和 W 分别是描述子空间的高度和宽度。
# - s: 描述子的空间分辨率,默认值为 8。
#
# 返回:
# - 在关键点位置插值后的描述子张量。
# """
b, c, h, w = descriptors.shape
keypoints = keypoints - s / 2 + 0.5
keypoints /= torch.tensor([(w*s - s/2 - 0.5), (h*s - s/2 - 0.5)],
).to(keypoints)[None]
keypoints = keypoints*2 - 1 # normalize to (-1, 1)
args = {'align_corners': True} if torch.__version__ >= '1.3' else {}
descriptors = torch.nn.functional.grid_sample(
descriptors, keypoints.view(b, 1, -1, 2), mode='bilinear', **args)
descriptors = torch.nn.functional.normalize(
descriptors.reshape(b, c, -1), p=2, dim=1)
return descriptors
class SuperPoint(nn.Module):
"""SuperPoint Convolutional Detector and Descriptor
SuperPoint: Self-Supervised Interest Point Detection and
Description. Daniel DeTone, Tomasz Malisiewicz, and Andrew
Rabinovich. In CVPRW, 2019. https://arxiv.org/abs/1712.07629
"""
default_config = {
'descriptor_dim': 256,
'nms_radius': 4,
'keypoint_threshold': 0.005,
'max_keypoints': -1,
'remove_borders': 4,
}
#default_config 字典定义了一些默认配置,包括描述子维度、非极大值抑制半径、关键点阈值、最大关键点数量和边界删除范围。
def __init__(self, config):
super().__init__()
# 合并默认配置和用户配置
self.config = {**self.default_config, **config}
# 定义激活函数和池化层
self.relu = nn.ReLU(inplace=True)
self.pool = nn.MaxPool2d(kernel_size=2, stride=2)
# 定义不同层的通道数
c1, c2, c3, c4, c5 = 64, 64, 128, 128, 256
# 定义编码器网络
self.conv1a = nn.Conv2d(1, c1, kernel_size=3, stride=1, padding=1)
self.conv1b = nn.Conv2d(c1, c1, kernel_size=3, stride=1, padding=1)
self.conv2a = nn.Conv2d(c1, c2, kernel_size=3, stride=1, padding=1)
self.conv2b = nn.Conv2d(c2, c2, kernel_size=3, stride=1, padding=1)
self.conv3a = nn.Conv2d(c2, c3, kernel_size=3, stride=1, padding=1)
self.conv3b = nn.Conv2d(c3, c3, kernel_size=3, stride=1, padding=1)
self.conv4a = nn.Conv2d(c3, c4, kernel_size=3, stride=1, padding=1)
self.conv4b = nn.Conv2d(c4, c4, kernel_size=3, stride=1, padding=1)
# 定义关键点预测头
self.convPa = nn.Conv2d(c4, c5, kernel_size=3, stride=1, padding=1)
self.convPb = nn.Conv2d(c5, 65, kernel_size=1, stride=1, padding=0)
self.convDa = nn.Conv2d(c4, c5, kernel_size=3, stride=1, padding=1)
self.convDb = nn.Conv2d(
c5, self.config['descriptor_dim'],
kernel_size=1, stride=1, padding=0)
# 加载预训练权重
path = Path(__file__).parent / 'weights/superpoint_v1.pth'
self.load_state_dict(torch.load(str(path)))
# 检查最大关键点数配置,如果不合理则抛出异常。
mk = self.config['max_keypoints']
if mk == 0 or mk < -1:
raise ValueError('\"max_keypoints\" must be positive or \"-1\"')
print('Loaded SuperPoint model')
def forward(self, data):
# 计算图像的关键点、分数和描述子
# 共享编码器
x = self.relu(self.conv1a(data['image']))
x = self.relu(self.conv1b(x))
x = self.pool(x)
x = self.relu(self.conv2a(x))
x = self.relu(self.conv2b(x))
x = self.pool(x)
x = self.relu(self.conv3a(x))
x = self.relu(self.conv3b(x))
x = self.pool(x)
x = self.relu(self.conv4a(x))
x = self.relu(self.conv4b(x))
# 计算密集关键点分数
cPa = self.relu(self.convPa(x))
scores = self.convPb(cPa)
scores = torch.nn.functional.softmax(scores, 1)[:, :-1]
b, _, h, w = scores.shape
scores = scores.permute(0, 2, 3, 1).reshape(b, h, w, 8, 8)
scores = scores.permute(0, 1, 3, 2, 4).reshape(b, h*8, w*8)
scores = simple_nms(scores, self.config['nms_radius'])
# 提取关键点
keypoints = [
torch.nonzero(s > self.config['keypoint_threshold'])
for s in scores]
scores = [s[tuple(k.t())] for s, k in zip(scores, keypoints)]
# 去除靠近图像边界的关键点
keypoints, scores = list(zip(*[
remove_borders(k, s, self.config['remove_borders'], h*8, w*8)
for k, s in zip(keypoints, scores)]))
# 保留分数最高的 k 个关键点
if self.config['max_keypoints'] >= 0:
keypoints, scores = list(zip(*[
top_k_keypoints(k, s, self.config['max_keypoints'])
for k, s in zip(keypoints, scores)]))
# 将 (h, w) 转换为 (x, y)
keypoints = [torch.flip(k, [1]).float() for k in keypoints]
# Compute the dense descriptors
cDa = self.relu(self.convDa(x))
descriptors = self.convDb(cDa)
descriptors = torch.nn.functional.normalize(descriptors, p=2, dim=1)
# 计算密集描述子
descriptors = [sample_descriptors(k[None], d[None], 8)[0]
for k, d in zip(keypoints, descriptors)]
return {
'keypoints': keypoints,
'scores': scores,
'descriptors': descriptors,
}
superglue.py
SuperGlue用于对来自两个图像的关键点描述符进行匹配。它依赖于SuperPoint提取的特征。了解这个文件将帮助你理解如何从两组关键点中找到匹配对。
from copy import deepcopy
from pathlib import Path
from typing import List, Tuple
import torch
from torch import nn
def MLP(channels: List[int], do_bn: bool = True) -> nn.Module:
# 这个函数可以方便地创建一个多层感知器网络,每一层由一个全连接层(使用一维卷积实现)组成。
# 中间层可以选择是否添加批归一化,并且中间层都会使用 ReLU 激活函数。
n = len(channels)
layers = []
for i in range(1, n):
layers.append(
nn.Conv1d(channels[i - 1], channels[i], kernel_size=1, bias=True))
if i < (n-1):
if do_bn:
layers.append(nn.BatchNorm1d(channels[i]))
layers.append(nn.ReLU())
return nn.Sequential(*layers)
def normalize_keypoints(kpts, image_shape):
# 该函数 normalize_keypoints 是用来根据图像的尺寸来归一化关键点位置的。
_, _, height, width = image_shape
one = kpts.new_tensor(1)
size = torch.stack([one*width, one*height])[None]
center = size / 2
scaling = size.max(1, keepdim=True).values * 0.7
return (kpts - center[:, None, :]) / scaling[:, None, :]
class KeypointEncoder(nn.Module):
# 在Python中,类可以包含多个方法(函数),并且 KeypointEncoder 类包含了两个方法:__init__ 和 forward。
def __init__(self, feature_dim: int, layers: List[int]) -> None:
super().__init__()
self.encoder = MLP([3] + layers + [feature_dim])
nn.init.constant_(self.encoder[-1].bias, 0.0)
def forward(self, kpts, scores):
inputs = [kpts.transpose(1, 2), scores.unsqueeze(1)]
return self.encoder(torch.cat(inputs, dim=1))
def attention(query: torch.Tensor, key: torch.Tensor, value: torch.Tensor) -> Tuple[torch.Tensor,torch.Tensor]:
dim = query.shape[1]
scores = torch.einsum('bdhn,bdhm->bhnm', query, key) / dim**.5
prob = torch.nn.functional.softmax(scores, dim=-1)
return torch.einsum('bhnm,bdhm->bdhn', prob, value), prob
# 这个函数执行一个常见的注意力机制计算过程。它接收查询(query)、键(key)和值(value)作为输入,并返回注意力权重后的值以及注意力概率。
class MultiHeadedAttention(nn.Module):
# 这个类 MultiHeadedAttention 是一个PyTorch神经网络模块,
# 用于实现多头注意力机制,这是一种在各种序列到序列模型(如Transformer模型)中广泛使用的技术,可以提高模型的表达能力。
def __init__(self, num_heads: int, d_model: int):
super().__init__()
assert d_model % num_heads == 0
self.dim = d_model // num_heads
self.num_heads = num_heads
self.merge = nn.Conv1d(d_model, d_model, kernel_size=1)
self.proj = nn.ModuleList([deepcopy(self.merge) for _ in range(3)])
def forward(self, query: torch.Tensor, key: torch.Tensor, value: torch.Tensor) -> torch.Tensor:
batch_dim = query.size(0)
query, key, value = [l(x).view(batch_dim, self.dim, self.num_heads, -1)
for l, x in zip(self.proj, (query, key, value))]
x, _ = attention(query, key, value)
return self.merge(x.contiguous().view(batch_dim, self.dim*self.num_heads, -1))
class AttentionalPropagation(nn.Module):
def __init__(self, feature_dim: int, num_heads: int):
super().__init__()
self.attn = MultiHeadedAttention(num_heads, feature_dim)
self.mlp = MLP([feature_dim*2, feature_dim*2, feature_dim])
nn.init.constant_(self.mlp[-1].bias, 0.0)
def forward(self, x: torch.Tensor, source: torch.Tensor) -> torch.Tensor:
message = self.attn(x, source, source)
return self.mlp(torch.cat([x, message], dim=1))
class AttentionalGNN(nn.Module):
def __init__(self, feature_dim: int, layer_names: List[str]) -> None:
super().__init__()
self.layers = nn.ModuleList([
AttentionalPropagation(feature_dim, 4)
for _ in range(len(layer_names))])
self.names = layer_names
def forward(self, desc0: torch.Tensor, desc1: torch.Tensor) -> Tuple[torch.Tensor,torch.Tensor]:
for layer, name in zip(self.layers, self.names):
if name == 'cross':
src0, src1 = desc1, desc0
else: # if name == 'self':
src0, src1 = desc0, desc1
delta0, delta1 = layer(desc0, src0), layer(desc1, src1)
desc0, desc1 = (desc0 + delta0), (desc1 + delta1)
return desc0, desc1
def log_sinkhorn_iterations(Z: torch.Tensor, log_mu: torch.Tensor, log_nu: torch.Tensor, iters: int) -> torch.Tensor:
""" Perform Sinkhorn Normalization in Log-space for stability"""
u, v = torch.zeros_like(log_mu), torch.zeros_like(log_nu)
for _ in range(iters):
u = log_mu - torch.logsumexp(Z + v.unsqueeze(1), dim=2)
v = log_nu - torch.logsumexp(Z + u.unsqueeze(2), dim=1)
return Z + u.unsqueeze(2) + v.unsqueeze(1)
def log_optimal_transport(scores: torch.Tensor, alpha: torch.Tensor, iters: int) -> torch.Tensor:
""" Perform Differentiable Optimal Transport in Log-space for stability"""
b, m, n = scores.shape
one = scores.new_tensor(1)
ms, ns = (m*one).to(scores), (n*one).to(scores)
bins0 = alpha.expand(b, m, 1)
bins1 = alpha.expand(b, 1, n)
alpha = alpha.expand(b, 1, 1)
couplings = torch.cat([torch.cat([scores, bins0], -1),
torch.cat([bins1, alpha], -1)], 1)
norm = - (ms + ns).log()
log_mu = torch.cat([norm.expand(m), ns.log()[None] + norm])
log_nu = torch.cat([norm.expand(n), ms.log()[None] + norm])
log_mu, log_nu = log_mu[None].expand(b, -1), log_nu[None].expand(b, -1)
Z = log_sinkhorn_iterations(couplings, log_mu, log_nu, iters)
Z = Z - norm # multiply probabilities by M+N
return Z
def arange_like(x, dim: int):
return x.new_ones(x.shape[dim]).cumsum(0) - 1 # traceable in 1.1
class SuperGlue(nn.Module):
"""SuperGlue特征匹配中间层
SuperGlue是一种基于图神经网络的特征匹配算法,用于在两组关键点之间找到对应关系。
该类实现了SuperGlue的前向传播过程,包括关键点编码、图神经网络处理和最优传输匹配。
主要步骤:
1. 关键点归一化
2. 关键点MLP编码器
3. 多层Transformer网络
4. 最终MLP投影
5. 计算匹配描述符距离
6. 运行最优传输
7. 获取得分高于阈值的匹配
参数:
- config: SuperGlue的配置字典,包含以下keys:
- descriptor_dim: 描述符维度
- weights: 预训练权重的类型,可选'indoor'或'outdoor'
- keypoint_encoder: 关键点编码器的层次结构
- GNN_layers: 图神经网络的层次结构
- sinkhorn_iterations: Sinkhorn算法的迭代次数
- match_threshold: 匹配得分阈值
输入:
- data: 一个字典,包含以下keys:
- descriptors0: 第一组关键点的描述符
- descriptors1: 第二组关键点的描述符
- keypoints0: 第一组关键点的坐标
- keypoints1: 第二组关键点的坐标
- scores0: 第一组关键点的置信度得分
- scores1: 第二组关键点的置信度得分
- image0: 第一张图像
- image1: 第二张图像
输出:
一个字典,包含以下keys:
- matches0: 第一组关键点的匹配索引,未匹配的关键点索引为-1
- matches1: 第二组关键点的匹配索引,未匹配的关键点索引为-1
- matching_scores0: 第一组关键点的匹配得分
- matching_scores1: 第二组关键点的匹配得分
"""
default_config = {
'descriptor_dim': 256,# 描述符维度
'weights': 'indoor',# 预训练权重的类型
'keypoint_encoder': [32, 64, 128, 256],# 关键点编码器的层次结构
'GNN_layers': ['self', 'cross'] * 9,# 图神经网络的层次结构
'sinkhorn_iterations': 100,# Sinkhorn算法的迭代次数
'match_threshold': 0.2,# 匹配得分阈值
}
def __init__(self, config):
super().__init__()
self.config = {**self.default_config, **config}
# 关键点编码器
self.kenc = KeypointEncoder(
self.config['descriptor_dim'], self.config['keypoint_encoder'])
# 图神经网络
self.gnn = AttentionalGNN(
feature_dim=self.config['descriptor_dim'], layer_names=self.config['GNN_layers'])
# 最终投影层
self.final_proj = nn.Conv1d(
self.config['descriptor_dim'], self.config['descriptor_dim'],
kernel_size=1, bias=True)
# 双向匹配得分权重
bin_score = torch.nn.Parameter(torch.tensor(1.))
self.register_parameter('bin_score', bin_score)
# 加载预训练权重
assert self.config['weights'] in ['indoor', 'outdoor']
path = Path(__file__).parent
path = path / 'weights/superglue_{}.pth'.format(self.config['weights'])
self.load_state_dict(torch.load(str(path)))
print('Loaded SuperGlue model (\"{}\" weights)'.format(
self.config['weights']))
def forward(self, data):
"""Run SuperGlue on a pair of keypoints and descriptors"""
desc0, desc1 = data['descriptors0'], data['descriptors1']
kpts0, kpts1 = data['keypoints0'], data['keypoints1']
# 如果没有关键点,则返回空匹配结果
if kpts0.shape[1] == 0 or kpts1.shape[1] == 0: # no keypoints
shape0, shape1 = kpts0.shape[:-1], kpts1.shape[:-1]
return {
'matches0': kpts0.new_full(shape0, -1, dtype=torch.int),
'matches1': kpts1.new_full(shape1, -1, dtype=torch.int),
'matching_scores0': kpts0.new_zeros(shape0),
'matching_scores1': kpts1.new_zeros(shape1),
}
# Keypoint normalization.# 关键点归一化
kpts0 = normalize_keypoints(kpts0, data['image0'].shape)
kpts1 = normalize_keypoints(kpts1, data['image1'].shape)
# Keypoint MLP encoder.# 关键点MLP编码器
desc0 = desc0 + self.kenc(kpts0, data['scores0'])
desc1 = desc1 + self.kenc(kpts1, data['scores1'])
# Multi-layer Transformer network.# 多层Transformer网络
desc0, desc1 = self.gnn(desc0, desc1)
# Final MLP projection.# 最终MLP投影
mdesc0, mdesc1 = self.final_proj(desc0), self.final_proj(desc1)
# Compute matching descriptor distance.# 计算匹配描述符距离
scores = torch.einsum('bdn,bdm->bnm', mdesc0, mdesc1)
scores = scores / self.config['descriptor_dim']**.5
# Run the optimal transport.# 运行最优传输算法
scores = log_optimal_transport(
scores, self.bin_score,
iters=self.config['sinkhorn_iterations'])
# Get the matches with score above "match_threshold".# 获取得分高于阈值的匹配
max0, max1 = scores[:, :-1, :-1].max(2), scores[:, :-1, :-1].max(1)
indices0, indices1 = max0.indices, max1.indices
mutual0 = arange_like(indices0, 1)[None] == indices1.gather(1, indices0)
mutual1 = arange_like(indices1, 1)[None] == indices0.gather(1, indices1)
zero = scores.new_tensor(0)
mscores0 = torch.where(mutual0, max0.values.exp(), zero)
mscores1 = torch.where(mutual1, mscores0.gather(1, indices1), zero)
valid0 = mutual0 & (mscores0 > self.config['match_threshold'])
valid1 = mutual1 & valid0.gather(1, indices1)
indices0 = torch.where(valid0, indices0, indices0.new_tensor(-1))
indices1 = torch.where(valid1, indices1, indices1.new_tensor(-1))
return {
'matches0': indices0, # use -1 for invalid match
'matches1': indices1, # use -1 for invalid match
'matching_scores0': mscores0,
'matching_scores1': mscores1,
}
matching.py
matching.py文件的主要目的是将SuperPoint和SuperGlue两个模块组合在一起,实现图像匹配的完整流程。Matching类的作用是将图像匹配的整个流程封装起来,使得可以通过一次前向传播完成从图像到匹配结果的计算。它在内部调用了SuperPoint和SuperGlue两个子模块,分别完成关键点检测和描述符匹配的任务。这样的设计使得代码结构清晰,易于理解和使用。
import torch
from .superpoint import SuperPoint
from .superglue import SuperGlue
class Matching(torch.nn.Module):
""" 图像匹配前端(SuperPoint + SuperGlue) """
def __init__(self, config={}):
super().__init__()
# 初始化SuperPoint模块
self.superpoint = SuperPoint(config.get('superpoint', {}))
# 初始化SuperGlue模块
self.superglue = SuperGlue(config.get('superglue', {}))
def forward(self, data):
""" 运行SuperPoint(可选)和SuperGlue
如果输入中存在['keypoints0', 'keypoints1'],则跳过SuperPoint
参数:
data: 字典,最少需要包含以下键: ['image0', 'image1']
"""
pred = {}
# 如果没有提供'keypoints0',则使用SuperPoint提取关键点、得分和描述符
if 'keypoints0' not in data:
pred0 = self.superpoint({'image': data['image0']})
pred = {**pred, **{k+'0': v for k, v in pred0.items()}}
# 如果没有提供'keypoints1',则使用SuperPoint提取关键点、得分和描述符
if 'keypoints1' not in data:
pred1 = self.superpoint({'image': data['image1']})
pred = {**pred, **{k+'1': v for k, v in pred1.items()}}
# 批处理所有特征
# 我们应该有以下两种情况之一:
# i) 每个批次只有一张图像,或者
# ii) 批次中所有图像的局部特征数量相同
data = {**data, **pred}
# 将列表或元组类型的数据转换为PyTorch张量
for k in data:
if isinstance(data[k], (list, tuple)):
data[k] = torch.stack(data[k])
# 执行匹配
pred = {**pred, **self.superglue(data)}
return predutils.py
"utils"是"utilities"的缩写,翻译成汉语是“工具”或“实用程序”的意思。在编程和软件开发中,
utils通常指的是一组提供常用功能和辅助操作的函数、类或模块集合。这些工具函数或类设计用来处理一些常见的、重复性的任务,如字符串操作、文件处理、数学计算等,以提高代码的复用性和减少重复编写代码的工作量。











![[蓝桥杯 2020 省 AB1] 网络分析](https://img-blog.csdnimg.cn/direct/3f7f74889b51485aafbd4667fdf434ff.png)
