Spark spark-submit 提交应用程序
Spark支持三种集群管理方式
- Standalone—Spark自带的一种集群管理方式,易于构建集群。
- Apache Mesos—通用的集群管理,可以在其上运行Hadoop MapReduce和一些服务应用。
- Hadoop YARN—Hadoop2中的资源管理器。
注意:
1、在集群不是特别大,并且没有mapReduce和Spark同时运行的需求的情况下,用Standalone模式效率最高。
2、Spark可以在应用间(通过集群管理器)和应用中(如果一个SparkContext中有多项计算任务)进行资源调度。
Running Spark on YARN
cluster mode
./bin/spark-submit --class org.apache.spark.examples.SparkPi \
--master yarn \
--deploy-mode cluster \
--driver-memory 4g \
--executor-memory 2g \
--executor-cores 1 \
lib/spark-examples*.jar \
10
client mode
./bin/spark-submit --class org.apache.spark.examples.SparkPi \
--master yarn \
--deploy-mode client \
--driver-memory 4g \
--executor-memory 2g \
--executor-cores 1 \
lib/spark-examples*.jar \
10
spark-submit 详细参数说明
| 参数名 | 参数说明 |
|---|---|
| —master | master 的地址,提交任务到哪里执行,例如 spark://host:port, yarn, local。具体指可参考下面关于Master_URL的列表 |
| —deploy-mode | 在本地 (client) 启动 driver 或在 cluster 上启动,默认是 client |
| —class | 应用程序的主类,仅针对 java 或 scala 应用 |
| —name | 应用程序的名称 |
| —jars | 用逗号分隔的本地 jar 包,设置后,这些 jar 将包含在 driver 和 executor 的 classpath 下 |
| —packages | 包含在driver 和executor 的 classpath 中的 jar 的 maven 坐标 |
| —exclude-packages | 为了避免冲突 而指定不包含的 package |
| —repositories | 远程 repository |
| —conf PROP=VALUE | 指定 spark 配置属性的值, 例如 -conf spark.executor.extraJavaOptions=”-XX:MaxPermSize=256m” |
| —properties-file | 加载的配置文件,默认为 conf/spark-defaults.conf |
| —driver-memory | Driver内存,默认 1G |
| —driver-java-options | 传给 driver 的额外的 Java 选项 |
| —driver-library-path | 传给 driver 的额外的库路径 |
| —driver-class-path | 传给 driver 的额外的类路径 |
| —driver-cores | Driver 的核数,默认是1。在 yarn 或者 standalone 下使用 |
| —executor-memory | 每个 executor 的内存,默认是1G |
| —total-executor-cores | 所有 executor 总共的核数。仅仅在 mesos 或者 standalone 下使用 |
| —num-executors | 启动的 executor 数量。默认为2。在 yarn 下使用 |
| —executor-core | 每个 executor 的核数。在yarn或者standalone下使用 |
Master_URL的值
| Master URL | 含义 |
|---|---|
| local | 使用1个worker线程在本地运行Spark应用程序 |
| local[K] | 使用K个worker线程在本地运行Spark应用程序 |
| local | 使用所有剩余worker线程在本地运行Spark应用程序 |
| spark://HOST:PORT | 连接到Spark Standalone集群,以便在该集群上运行Spark应用程序 |
| mesos://HOST:PORT | 连接到Mesos集群,以便在该集群上运行Spark应用程序 |
| yarn-client | 以client方式连接到YARN集群,集群的定位由环境变量HADOOP_CONF_DIR定义,该方式driver在client运行。 |
| yarn-cluster | 以cluster方式连接到YARN集群,集群的定位由环境变量HADOOP_CONF_DIR定义,该方式driver也在集群中运行。 |
区分client,cluster,本地模式
下图是典型的client模式,spark的drive在任务提交的本机上。

下图是cluster模式,spark drive在yarn上。
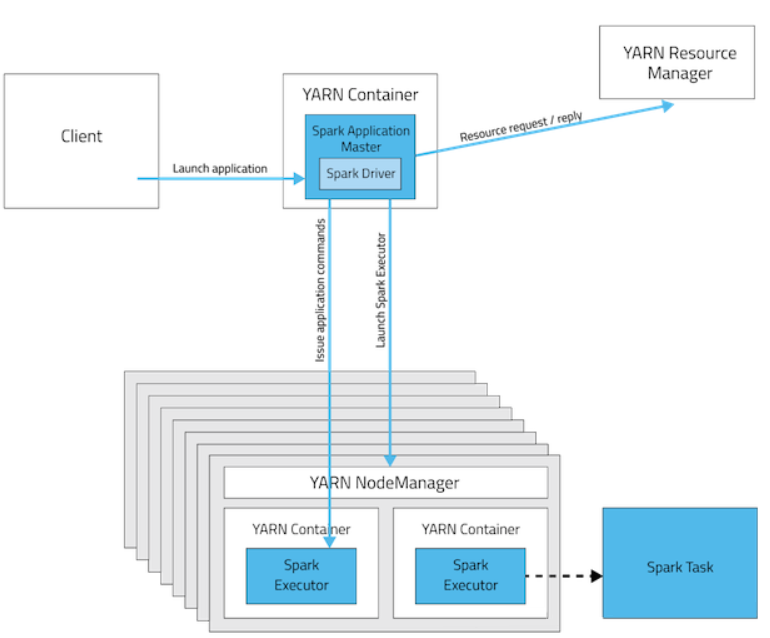
三种模式的比较
| Yarn Cluster | Yarn Client | Spark Standalone | |
|---|---|---|---|
| Driver在哪里运行 | Application Master | Client | Client |
| 谁请求资源 | Application Master | Application Master | Client |
| 谁启动executor进程 | Yarn NodeManager | Yarn NodeManager | Spark Slave |
| 驻内存进程 | 1.Yarn ResourceManager 2.NodeManager | 1.Yarn ResourceManager 2.NodeManager | 1.Spark Master 2.Spark Worker |
| 是否支持Spark Shell | No | Yes | Yes |
spark-submit提交应用程序示例
# Run application locally on 8 cores(本地模式8核)
./bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master local[8] \
/path/to/examples.jar \
100
# Run on a Spark standalone cluster in client deploy mode(standalone client模式)
./bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://207.184.161.138:7077 \
--executor-memory 20G \
--total-executor-cores 100 \
/path/to/examples.jar \
1000
# Run on a Spark standalone cluster in cluster deploy mode with supervise(standalone cluster模式使用supervise)
./bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://207.184.161.138:7077 \
--deploy-mode cluster \
--supervise \
--executor-memory 20G \
--total-executor-cores 100 \
/path/to/examples.jar \
1000
# Run on a YARN cluster(YARN cluster模式)
export HADOOP_CONF_DIR=XXX
./bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master yarn \
--deploy-mode cluster \ # can be client for client mode
--executor-memory 20G \
--num-executors 50 \
/path/to/examples.jar \
1000
# Run on a Mesos cluster in cluster deploy mode with supervise(Mesos cluster模式使用supervise)
./bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master mesos://207.184.161.138:7077 \
--deploy-mode cluster \
--supervise \
--executor-memory 20G \
--total-executor-cores 100 \
http://path/to/examples.jar \
1000
# Run a Python application on a Spark standalone cluster(standalone cluster模式提交python application)
./bin/spark-submit \
--master spark://207.184.161.138:7077 \
examples/src/main/python/pi.py \
1000
一个例子
spark-submit \
--master yarn \
--queue root.sparkstreaming \
--deploy-mode cluster \
--supervise \
--name spark-job \
--num-executors 20 \
--executor-cores 2 \
--executor-memory 4g \
--conf spark.dynamicAllocation.maxExecutors=9 \
--files commons.xml \
--class com.***.realtime.helper.HelperHandle \
BSS-ONSS-Spark-Realtime-1.0-SNAPSHOT.jar 500






![[蓝桥杯 2020 省 AB1] 网络分析](https://img-blog.csdnimg.cn/direct/3f7f74889b51485aafbd4667fdf434ff.png)