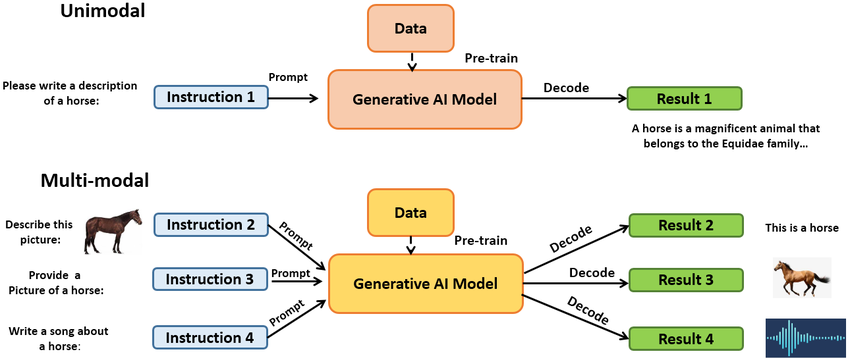
机器学习——随机森林
随机森林是一种强大的集成学习算法,能够用于分类和回归任务。它基于决策树构建,在集成学习框架下,通过Bagging算法和随机特征选择的方式,将多棵决策树组合成一个更强大的模型。本篇博客将介绍随机森林的原理、随机森林与Bagging的区别、随机森林中的相关性、每棵树的分类能力、以及随机森林的参数设置,并使用Python实现以上所有的算法。
1. 原理
1.1 集成学习
集成学习是一种将多个模型组合起来的机器学习方法,旨在提高模型的性能和泛化能力。常见的集成学习方法包括Bagging和Boosting。
1.2 Bagging算法
Bagging(Bootstrap Aggregating)算法是一种集成学习方法,通过对原始数据集进行有放回抽样,生成多个子数据集,然后分别训练多个基学习器,最后将它们的预测结果进行平均或投票,得到最终的预测结果。
1.3 随机森林
随机森林是Bagging算法的一种扩展,它基于决策树构建,对特征进行随机选择,生成多棵决策树,并将它们的预测结果进行平均或投票。
2. 随机森林
2.1 与Bagging的区别
随机森林在生成每棵决策树时,不仅对样本进行有放回抽样,还对特征进行有放回抽样,以降低树与树之间的相关性,进而提高模型的泛化能力。
2.2 任意两棵树的相关性
随机森林中的任意两棵树之间具有一定的相关性,但相比于单个决策树,随机森林的相关性更低,这是因为随机森林在生成每棵树时都对特征进行了随机选择。
2.3 每棵树的分类能力
随机森林中每棵树的分类能力相对较弱,但通过集成多棵树的预测结果,可以获得更强大的分类能力。
2.4 随机森林的参数
随机森林的参数包括决策树个数、每棵树的最大深度、每个节点的最小样本数等。
3. Python实现
接下来,让我们使用Python实现随机森林算法,并在一个示例数据集上进行训练和预测。
from sklearn.datasets import load_iris
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.colors import ListedColormap
# 加载数据集
iris = load_iris()
X, y = iris.data, iris.target
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 将数据集的特征维度降到2维
X_train_2d = X_train[:, :2] # 取前两个特征
# 构建随机森林模型
clf = RandomForestClassifier(n_estimators=100, max_depth=5, random_state=42)
clf.fit(X_train_2d, y_train)
# 绘制分类结果
def plot_decision_regions(X, y, classifier, test_idx=None, resolution=0.02):
markers = ('s', 'x', 'o', '^', 'v')
colors = ('red', 'blue', 'lightgreen', 'gray', 'cyan')
cmap = ListedColormap(colors[:len(np.unique(y))])
x1_min, x1_max = X[:, 0].min() - 1, X[:, 0].max() + 1
x2_min, x2_max = X[:, 1].min() - 1, X[:, 1].max() + 1
xx1, xx2 = np.meshgrid(np.arange(x1_min, x1_max, resolution),
np.arange(x2_min, x2_max, resolution))
Z = classifier.predict(np.array([xx1.ravel(), xx2.ravel()]).T)
Z = Z.reshape(xx1.shape)
plt.contourf(xx1, xx2, Z, alpha=0.3, cmap=cmap)
plt.xlim(xx1.min(), xx1.max())
plt.ylim(xx2.min(), xx2.max())
for idx, cl in enumerate(np.unique(y)):
plt.scatter(x=X[y == cl, 0], y=X[y == cl, 1],
alpha=0.8, c=[cmap(idx)],
marker=markers[idx], label=cl)
if test_idx:
X_test, y_test = X[test_idx, :], y[test_idx]
plt.scatter(X_test[:, 0], X_test[:, 1], c='',
alpha=1.0, linewidths=1, marker='o',
s=55, label='test set')
# 可视化分类结果
plt.figure(figsize=(10, 6))
plot_decision_regions(X_train_2d, y_train, classifier=clf)
plt.xlabel('Sepal length (cm)')
plt.ylabel('Sepal width (cm)')
plt.legend(loc='upper left')
plt.title('Random Forest Classification Result on Training Set')
plt.show()

这段代码实现了使用随机森林对鸢尾花数据集进行分类,并将分类结果可视化展示在二维平面上。
首先,我们加载了鸢尾花数据集,并将数据集划分为训练集和测试集,其中训练集占比80%。
接着,我们从原始数据集中提取了前两个特征,将数据集的特征维度降到了2维,以便后续可视化展示。
然后,我们构建了一个包含100棵决策树的随机森林模型,并使用训练集进行训练。
随后,定义了一个用于绘制分类结果的函数plot_decision_regions,其中使用了meshgrid生成了网格点,对每个网格点进行了预测,并绘制了分类边界。
最后,我们调用plot_decision_regions函数,将训练集上的分类结果进行可视化展示,同时添加了横坐标和纵坐标的标签,以及图例和标题。
通过运行以上代码,我们可以直观地观察到随机森林在训练集上的分类效果。
4. 总结
随机森林是一种强大的集成学习算法,通过对决策树进行Bagging和随机特征选择,能够有效地提高模型的性能和泛化能力。在实际应用中,随机森林通常表现出色,且不需要太多的调参,是一个十分实用的机器学习算法。