Redis知识点总结(七)——缓存雪崩、缓存穿透、缓存击穿、Redis高级用法
- 缓存雪崩
- 缓存穿透
- 布隆过滤器
- 缓存击穿
- Redis高级用法
- bitmap
- HyperLogLog
缓存雪崩
缓存雪崩是指,同一时间有大量的缓存key失效,或者redis节点直接宕机了,造成大量的请求打向数据库,像雪崩一样。
原本我们的redis就像是数据库前面的一堵墙,挡住大量的请求,只有少量的请求打到数据库。

但是由于大量的缓存key在同一时间失效,相当于是redis这堵墙开了个大口,这时候大量的请求就会同一时刻打向数据库,有可能直接把数据库打挂掉。
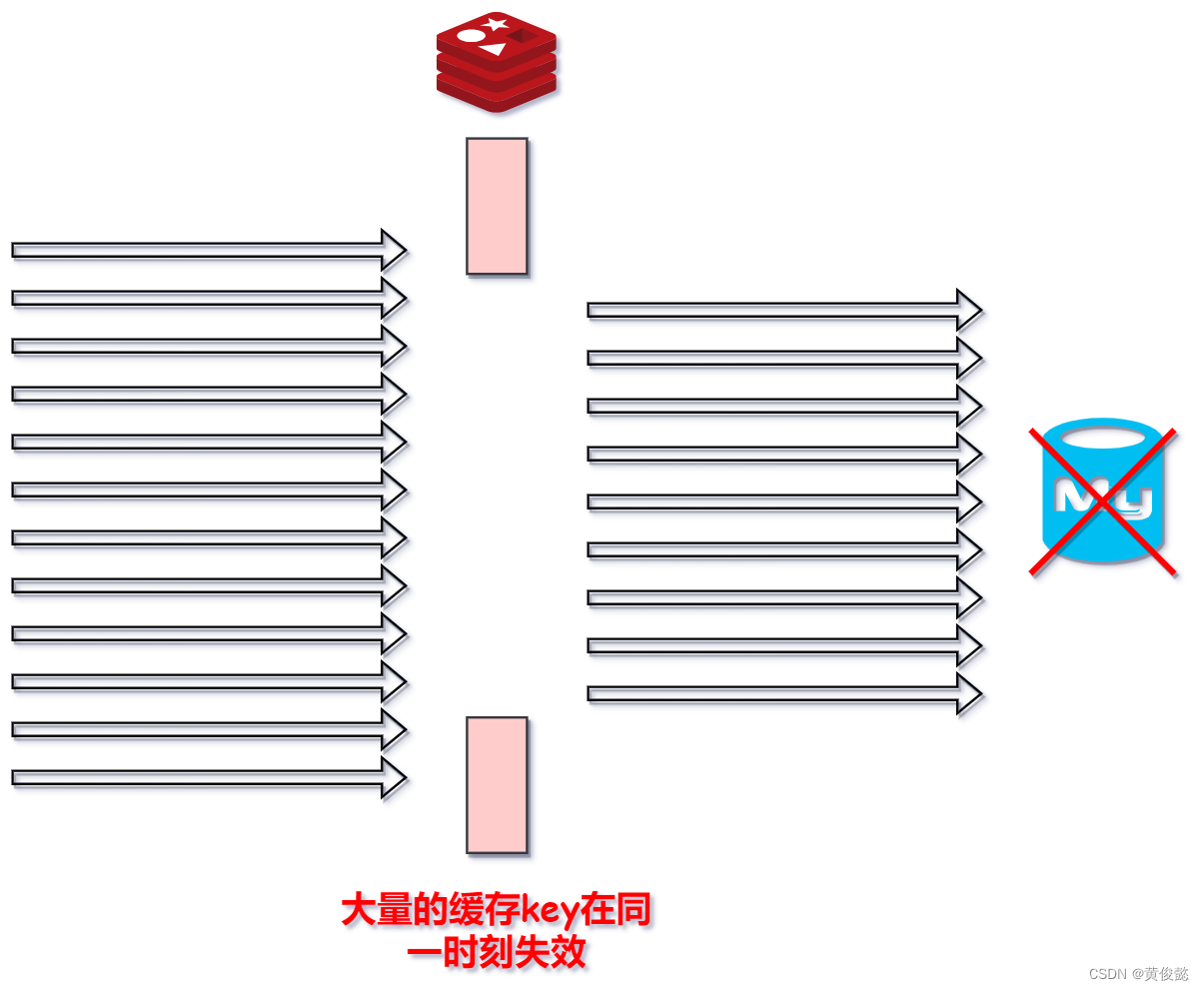
面对这种问题,解决办法就是给每一个key的过期时间添加一个随机值,然后redis要以集群方式部署,避免redis单点故障导致所有请求打向数据库。
缓存穿透
缓存穿透是指一个请求查询的数据在缓存中没有,在数据库中也没有,这种请求每次都会直达数据库,向穿过了缓存层一样。如果客户端不断的发起这样的请求,就会造成大量的无效查询,如果是黑客通过某种手段制造这种大量的无效请求打向数据库,也有可能把数据库打挂掉。

解决办法有如下几种:
- 添加校验规则,过滤无效请求
- 缓存一个空值到redis,并设置一个较短的过期时间
- 使用布隆过滤器
布隆过滤器
布隆过滤器是基于bitmap加多个hash函数组成的一个用于判断一个key是否存在的过滤器。当它判断该key不存在时,那就一定是不存在的;当它判断该key是存在的时候,大概率是存在的,但也有可能是误判。
原理如下:
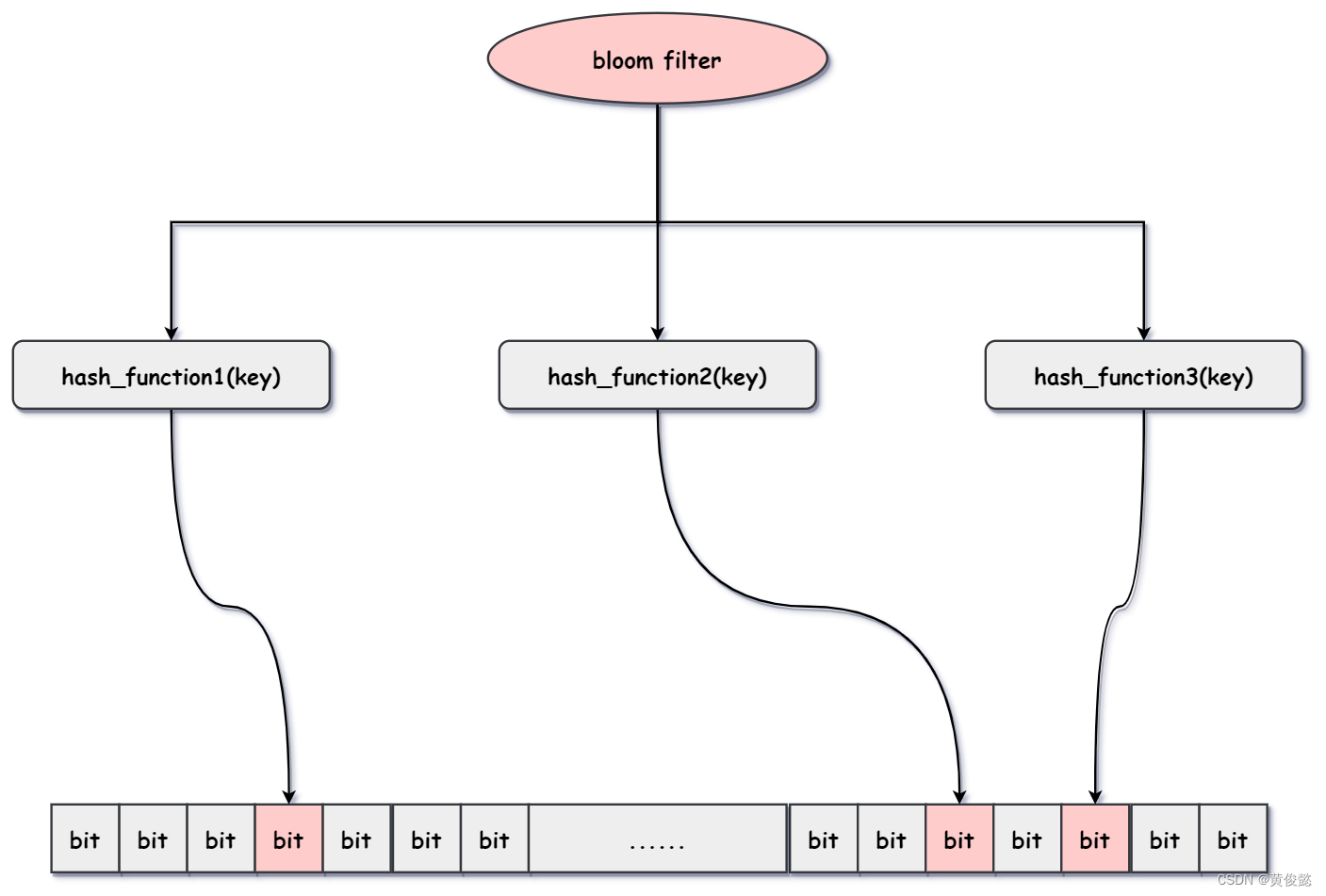
布隆过滤器包含多个hash函数和一个bitmap,比如有3个hash函数和一个bitmap。当我要通过布隆过滤器判断是一个key是否存在是,布隆过滤器会分别使用这三个hash函数算出三个bitmap的下标,然后到bitmap中查看对应的bit是否为1,如果三个bit都为1,则判断key存在,如果有至少其中一个bit是0,则判断key不存在。
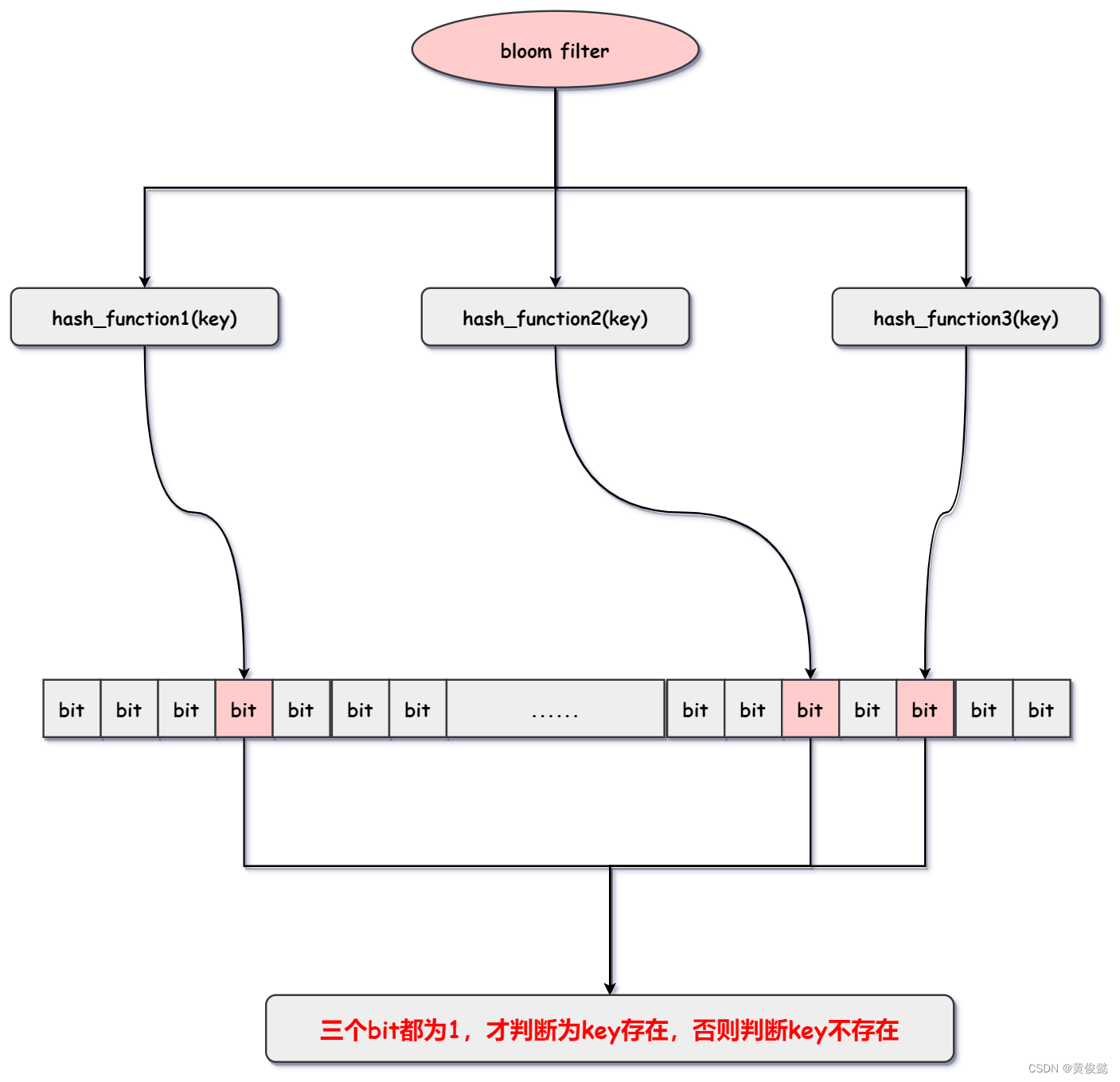
有了布隆过滤器之后,我们每次往数据库添加数据的时候,同时往布隆过滤器中添加一份,每次要向数据库查询数据的时候,先通过布隆过滤器判断是否存在,存在再去查,不存在就不去查了,这样就能过滤掉缓存穿透造成的无效查询请求。
缓存击穿
缓存击穿的意思是一个热点key在某个时间点突然失效了,因为它是热点key,因此大量请求同一时刻涌向数据库去查询这个key,把数据库打挂掉。
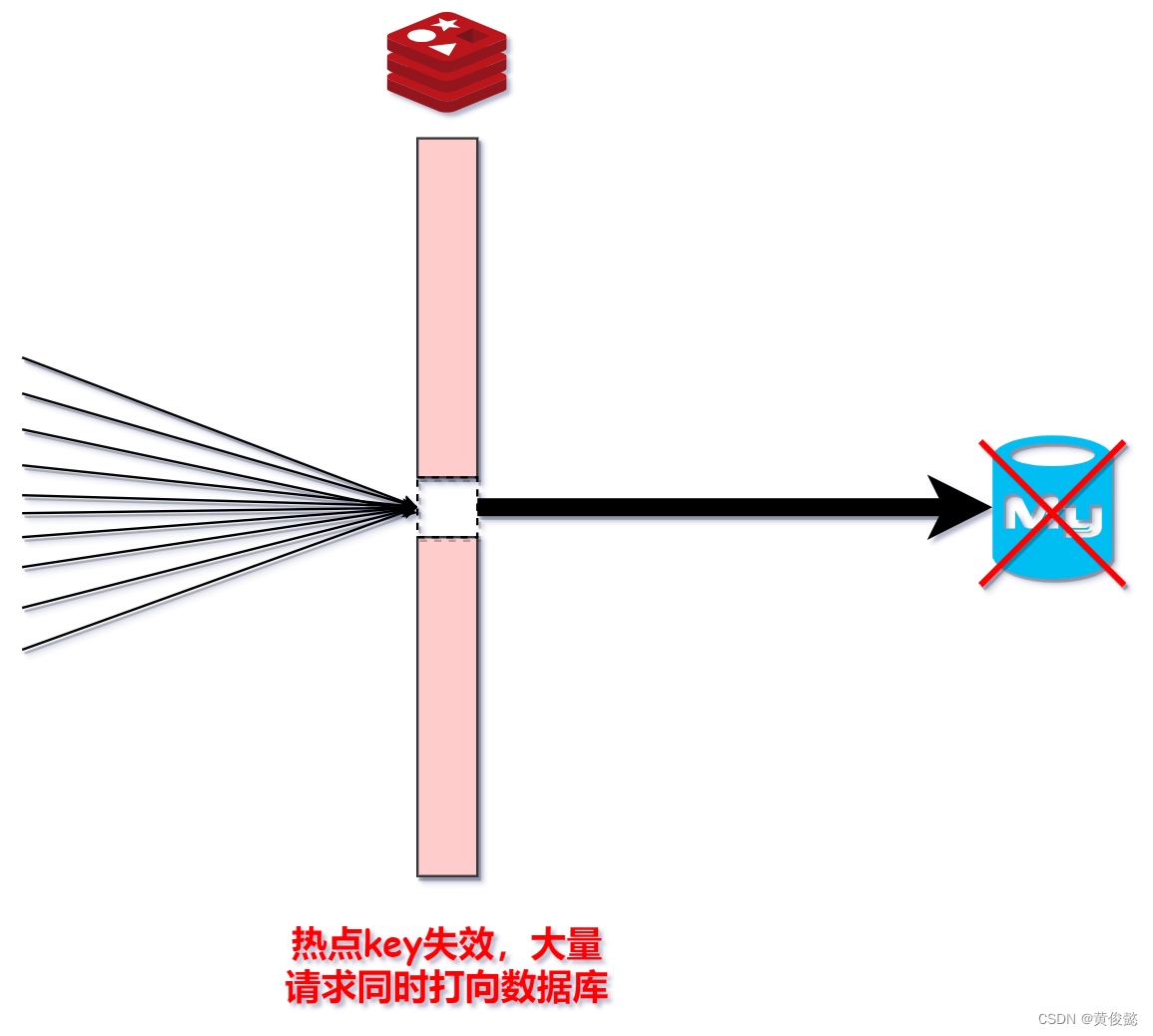
解决办法有两种:
- 设置热点key永不失效
- 添加分布式锁,每次查询数据前要先获取到锁,没抢到锁的则睡眠一会再重试
Redis高级用法
bitmap
上面说到布隆过滤器是基于bitmap实现的,这个bitmap其实就是基于redis的string类型的,因为string会保存二进制字节数组,所以自然可以用它来实现bitmap的功能。
当我们向bitmap中写入一个bit时,可以用以下命令:
setbit {bitmap} {offset} 1
查询一个bit时就这样:
getbit {bitmap} {offset}
这里的{bitmap}指的是这个bitmap的名字,由我们自己指定,{offset}则是bit在bitmap中的偏移量。
然后可以这样统计bitmap中共有多少个bit是1:
bitcount {bitmap}
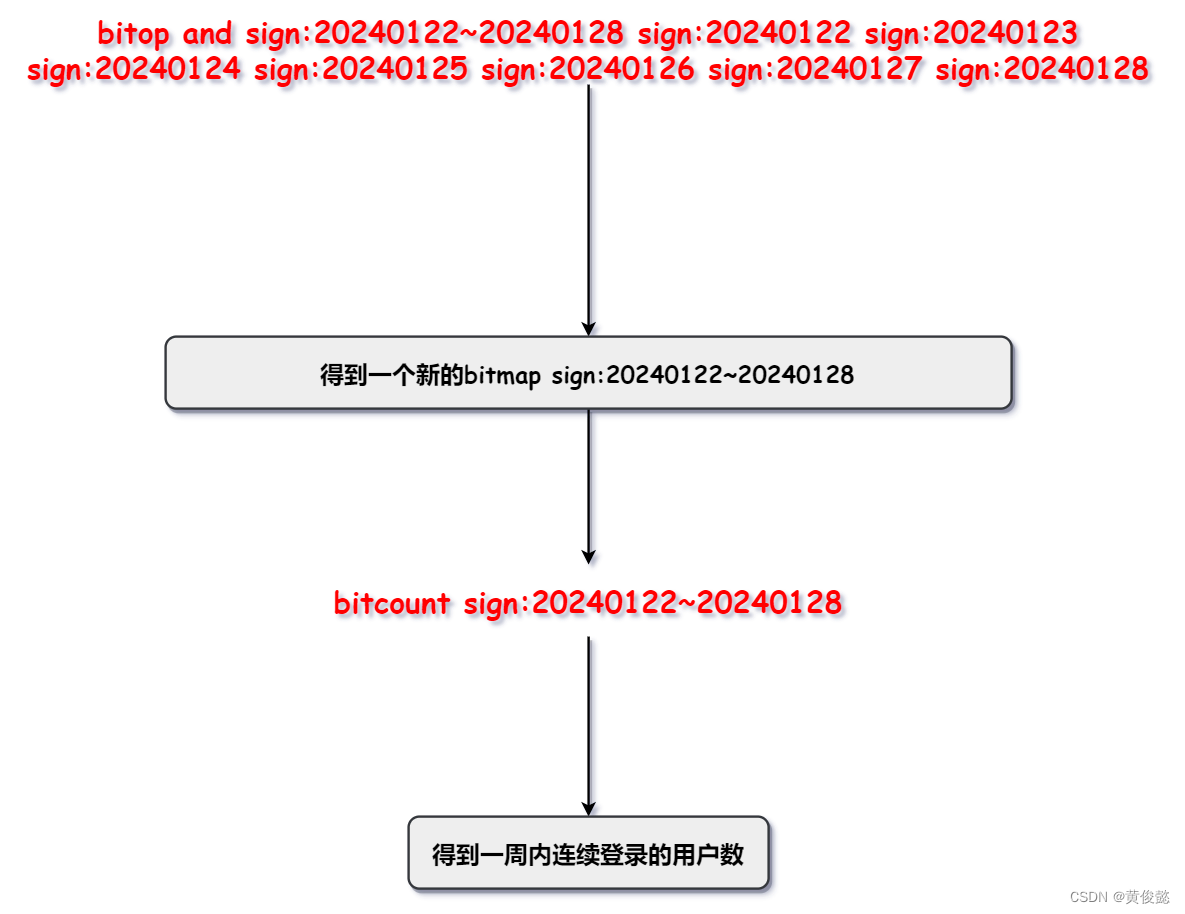
还可以通过以下这个命令对多个bitmap进行按位与运算,合并成一个新的bitmap。
bitop and {new_bitmap} {bitmap1} {bitmap2} {bitmap3}
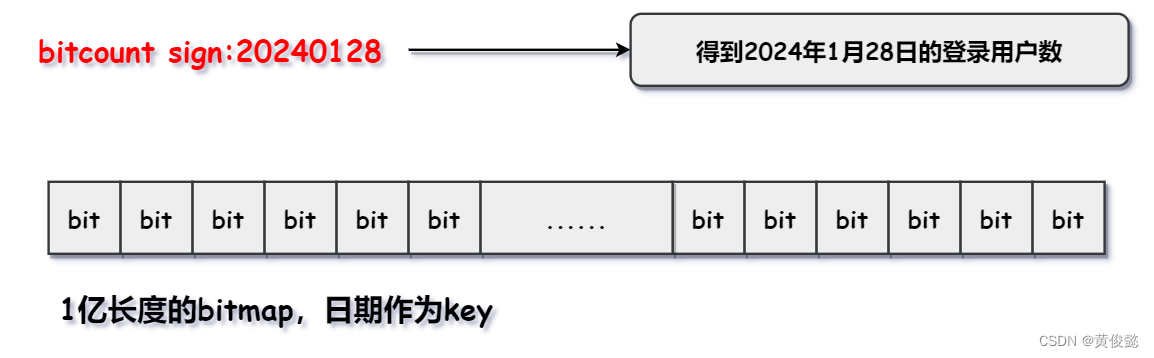
假设我们系统有1亿个用户,我们要统计在2024年1月28日当天这1亿个用户中有多少用户登录,我们可以用一个长度为1亿的bitmap,然后bitmap中每个bit对应一个用户当天的登录情况,登录了则置为1,否则该bit就是0,那么我们只要用一个bitcount命令就可以得到当天这1亿个用户的登录情况了。
那我们要统计一周内连续登录的用户数呢?我们只要使用 bitop and 命令把一周内的七天对应的七个bitmap按位与合并成一个新的bitmap,再用bitcount命令统计一下这个新的bitmap即可。
HyperLogLog
redis有一个高级功能HyperLogLog,可以用来做基数统计。基数统计的意思是求一个集合中不重复的元素个数。
比如我们现在要统计某网页的UV,UV就是一天之内访问当前页面的用户数,一个用户一天之内多次访问该页面,只能算作访问一次。
此时我们可以使用HyperLogLog完成网页UV的统计:
- 我们用网页名称做key,比如uv:{pageName}这样
- 一个用户访问该页面,我们就使用pfadd命令把该用户id添加进去,比如 pfadd uv:page1 uid1
- 如果要统计该页面的uv,我们使用pfcount命令,比如pfcount uv:page1这样

但是有一点要注意,HyperLogLog的统计不是精确的,有一定的误差,如果要精确统计,那么HyperLogLog就不适用了。