Frida 英文文档:https://frida.re/docs/home/
Frida 中文文档:https://pypi.org/project/frida-zhongwen-wendang/
目的:给自己一个认真阅读文档的机会!!!
- 部分名词找不到合适的中文表达,直接使用原英文名词。
- 如果发现中文表述难以理解,可查看英文原版表述。
1、开始
Frida 是什么
Frida 是一个动态代码插桩工具包。何为插桩:就是把自己写的代码,在不知道别人源码的情况下,动态的插入到别人的二进制程序中,从而改变程序的执行流程。 Frida 可以将JavaScript代码或你自己的库注入到 Windows、macOS、GNU/Linux、iOS、watchOS、tvOS、Android、FreeBSD 和 QNX 等平台的应用程序中。通俗一点讲:Frida 就像是一把瑞士军刀,处理的对象就是 "各个平台的程序"。Frida 之于 各个平台的程序,就相当于 Tampermonkey(油猴) 之于 web页面。
- Tampermonkey 可以加载各种 js 脚本,然后注入到 web 页面,从而对 web 页面增删改查
- Frida 也可以加载各种 js 脚本,注入到程序中,对程序的各种行为进行增删改查。
为什么需要 Frida
这个问题很实际, 来看几个实际的使用场景就大致明白了
- 假如现在市面上有个很火的 App,目前只有 iOS 版本的, 现在你对这个 App 比较感兴趣,想了解下大致的实现逻辑。 通过抓包工具 (比如:WireShark ) 发现网络协议是加密的, 看不到有效的信息,那么这个抓包的办法就不行了。这个时候就可以考虑用 Frida 进行 API 跟踪的方式来达到你的目的。
- 假如你开发了一个桌面应用并且已经部署到用户那里,现在用户反馈过来一个问题,但是你发现你打的日志信息又不足以定位问题, 那你只能说再加一些日志,然后再给用户单独发一个版本来定位问题,这个是传统的问题定位方式。但是如果考虑用 Frida 的话,那问题定位就简单多了,使用 Frida 挂钩(hook)住函数,打印函数调用堆栈,传入参数,以及返回值,就可以轻松定位问题。
- 你还可以使用 Frida 给 WireShark 快速的做一个经过加密的协议嗅探器,更进一步,为了满足你的实验需求,你甚至可以主动发起函数调用来模拟不同的网络状态。
- 如果你有一个内部App需要做黑盒测试,如果你用Frida的话,你就可以用完全不侵染原有业务逻辑的基础上进行测试,尤其在进行逻辑异常流程测试的时候,效果很好。
为什么 Frida 使用 Python 提供API,又用JavaScript来调试程序逻辑
- Frida 核心是用 C 语言编写,并将 QuickJS 注入到目标进程中,之后通过一个专门的双向信息通道,目标进程就可以和这个注入进来的 JavaScript 引擎进行通信, 这样通过JavaScript代码就可以在目标进程中做很多事情,比如:完全访问内存、函数Hook,甚至调用目标进程中的原生函数都可以。JavaScript 引擎对比 ( V8、JSCore、Hermes、QuickJS,hybrid ):https://cloud.tencent.com/developer/article/1801742
- 通过 Python 和 JS 代码, 你可以快速的开发出无风险的 Frida 脚本,因为如果你的JS代码里面错误或者异常的话,Frida 都会给你捕获到,不会让目标进程 Crash 的,所以叫无风险。
- 如果不想使用 Python 进行开发, 也可以直接用C进行开发, 并且 Frida 还提供了 Node.js、Python、Swift、。net、Qml、Go 等语言的接口封装。
Frida 安装
准备环境
- Python:建议使用最新的 3.x 版本
- Windows,MacOS,或者 GNU/Linux
最好的安装方式是通过 pypi 安装,安装 frida-tools 时会先自动安装 Frida。
直接安装:pip install frida-tools
使用豆瓣源:pip install -i https://pypi.doubanio.com/simple/ frida-tools
还可以从 Frida 的 GitHub 发布页面获取其他二进制文件。GitHub releases
测试是否安装成功
- 启动一个可以被注入的进程,示例:输入 cat 后直接按 enter,让程序一直处于等待输入状态。如果用 Windows 测试,可以启动记事本程序 notepad.exe 来代替。
- 创建 example.py 文件,
import frida
def on_message(message, data):
print("[on_message] message:", message, "data:", data)
session = frida.attach("cat")
script = session.create_script("""
rpc.exports.enumerateModules = () => {
return Process.enumerateModules();
};
""")
script.on("message", on_message)
script.load()
print([m["name"] for m in script.exports.enumerate_modules()])- 如果是 GNU/Linux 系统,执行命令:sudo sysctl kernel.yama.ptrace_scope=0 从而允许非父子进程之间的 ptrace 操作
- 执行 python example.py ,如下效果:
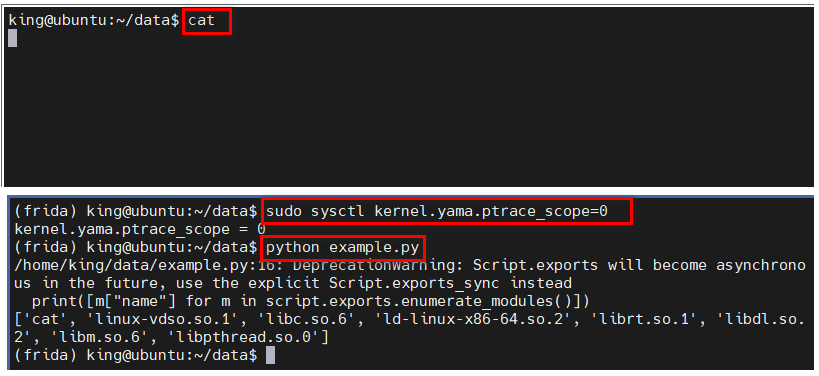
执行成功的话,脚本输出结果是这样的:['cat', …, 'ld-2.15.so']
Frida 快速入门
这里先给出一个例子
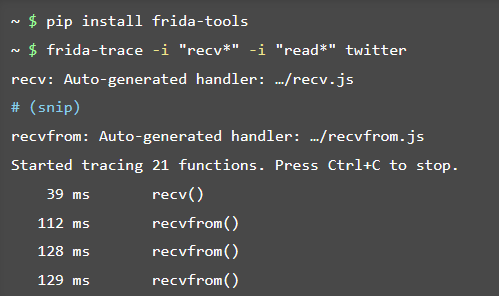
这个示例中,Frida 把自己注入到 Twitter,然后枚举进程中已经加载的模块,并 挂钩(hook) 名称以 recv 或 read 开头的所有函数。同时 Frida 框架会自动生成 Hook 回调处理脚本。你可以随意修改脚本以满足你的需求,修改保存之后,Frida 会自动重新加载修改之后对脚本。如上图,Frida 生成的默认脚本只是打印了函数名。下面看下框架生成的默认脚本 recvfrom.js
/*
* Auto-generated by Frida. Please modify to match the
* signature of recvfrom.
*
* This stub is somewhat dumb. Future verions of Frida
* could auto-generate based on OS API references, manpages,
* etc. (Pull-requests appreciated!)
*
* For full API reference, see:
* https://frida.re/docs/javascript-api/
*/
{
/**
* Called synchronously when about to call recvfrom.
*
* @this {object} - Object allowing you to store state for
* use in onLeave.
* @param {function} log - Call this function with a string
* to be presented to the user.
* @param {array} args - Function arguments represented as
* an array of NativePointer objects.
* For example use args[0].readUtf8String() if the first
* argument is a pointer to a C string encoded as UTF-8.
* It is also possible to modify arguments by assigning a
* NativePointer object to an element of this array.
* @param {object} state - Object allowing you to keep
* state across function calls.
* Only one JavaScript function will execute at a time, so
* do not worry about race-conditions. However, do not use
* this to store function arguments across onEnter/onLeave,
* but instead use "this" which is an object for keeping
* state local to an invocation.
*/
onEnter(log, args, state) {
log("recvfrom()");
},
/**
* Called synchronously when about to return from recvfrom.
*
* See onEnter for details.
*
* @this {object} - Object allowing you to access state
* stored in onEnter.
* @param {function} log - Call this function with a string
* to be presented to the user.
* @param {NativePointer} retval - Return value represented
* as a NativePointer object.
* @param {object} state - Object allowing you to keep
* state across function calls.
*/
onLeave(log, retval, state) {
}
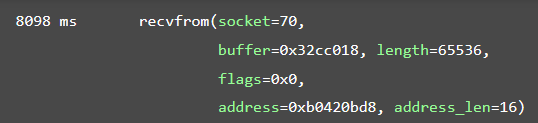
}现在,把 log() 这行用下面的代码代替:
log("recvfrom(socket=" + args[0].toInt32()
+ ", buffer=" + args[1]
+ ", length=" + args[2].toInt32()
+ ", flags=" + args[3]
+ ", address=" + args[4]
+ ", address_len=" + args[5].readPointer().toInt32()
+ ")");保存文件(Frida会自动加载修改之后的文件),然后操作 Twitter 触发下网络访问,输出大致如下:
Frida 最强大的是可以基于Frida API开发出各种场景下的实用工具,就像 Frida-trace 一样。
Frida 使用的3种模式
Frida 的动态代码执行功能,主要是在它的核心引擎 Gum 中用C语言来实现的。一般在使用 Frida开发时使用脚本语言就可以,因为脚本语言可以快速开发、修改、执行、验证,从而大大缩短开发周期。比如说 GumJS。只需要很少的几行C代码,你就可以在Python程序运行时运行一段JavaScript,通过 JavaScript 来完全访问 Gum 的 api,从而允许你 hook 函数,枚举加载的库、导入和导出的函数,读写内存,扫描内存进行查找,等等。
注入模式 (attach)
- 大多数时候,都是附加到正在运行的程序,或者在程序执行时进行拦截劫持,然后在其中运行插装逻辑 (就是在目标进程中运行我们的代码逻辑)。这是使用 Frida 最常见的一种方式,所以大部分文档都关注于此。这个功能是由 frida-core 提供的。注入模式的大致实现思路是这样的,带有GumJS的Frida核心引擎被打包成一个动态连接库,然后把这个动态连接库注入到目标进程中,同时提供了一个双向通信通道,这样你的控制端就可以和注入的模块进行通信了,在不需要的时候,还可以在目标进程中把这个注入的模块给卸载掉。Frida 还提供了枚举已经安装的 App列表,运行的进程列表,已经连接的设备列表,这里所说的设备列表通常就是 frida-server 所在的设备,通常是运行 frida-server 的 iOS 和 Android 设备。frida-server 是一个守护进程,通过 TCP 和 Frida 核心引擎通信,默认的监听端口是 27042
嵌入模式 (gadget)
- 在实际使用的过程中,会发现在没有 root 过的 iOS、Android 设备上你是没有办法对进程进行注入的,也就是说第一种注入模式失效了,这个时候嵌入模式就派上用场了。Frida 提供了一个动态连接库组件 frida-gadget, 可以把这个动态库集成到你的程序里面来使用 Frida 的动态执行功能。一旦你集成了gadget,你就可以使用现有的基于 Frida 的工具(如 frida-trace)远程与它进行交互。同时也支持从文件自动加载Js文件执行JS逻辑。
预加载模式 (spawn)
- "预加载(Preloaded)模式" 就是指预先加载到目标应用或进程中的特定代码或库。它允许开发者在应用程序启动前就注入代码,这样就可以从一开始就监视和修改程序的行为。这是一种在执行任何操作之前拦截和改变程序行为的有效方法。注入模式是在入口点跑过之后,才能执行JS逻辑,这个是最大的区别
- 使用场景:在程序运行之前先 hook,再启动。过掉 frida 检测、代理检测、root检测 等。
- 官网文档:https://frida.re/docs/modes/
Gadget
Gadget (工具,组件、部件)。程序源码经过编译后,变成 obj 文件,obj 文件再链接各种静态库、动态库,才能编译成最终的可执行程序,Gadget 就是 Frida 的一个共享库,可以把这个库直接链接到自己编写的程序中,从而实现和 frida 进行交互。
Frida 的 Gadget 是一个共享库,它是由程序加载,在 Injected 模式无法使用时可以使用这个。
Gadget 有多种使用方式,例如:
- 修改程序的源代码
- 修补它,或者修补使用的任意一个库。就像这个:insert_dylib
- 使用动态链接器功能,如 LD_PRELOAD 或 DYLD_INSERT_LIBRARIES
一旦动态链接器执行其构造函数,Gadget (小工具) 就会启动。它支持四种不同的交互
- Listen 监听
- Connect 连接
- Script 脚本
- ScriptDirectory 脚本目录
其中 Listen 交互是默认的。可以通过添加配置文件来覆盖它。该文件的命名应该与Gadget二进制文件完全相同,但要使用.config作为文件扩展名。举个例子,如果你把二进制文件命名为FridaGadget。您可以将配置文件命名为 FridaGadget.config。
注意:您可以随心所欲地命名 Gadget 二进制文件,这对于躲避反 Frida 检测方案很有用,这些方案会查找名称中带有 "Frida" 的加载库。
Gadget 不是关注的重点,更多可以查看 Gadget 官网文档:https://frida.re/docs/gadget/
Stalker (跟踪)
Stalker 是 Frida 的代码跟踪引擎。它允许跟踪线程,捕获每个函数、每个块,甚至执行的每一条指令。Stalker 目前支持运行 Android 或 iOS 的手机和平板电脑上常见的 AArch64 架构,以及台式机和笔记本电脑上常见的 Intel 64 和 IA-32 架构。
官网文档:https://frida.re/docs/stalker/
官网文档详解介绍了 Stalker 如何工作的,并剖析了 Stalker 的 ARM64 实现。
Frida 操作 C/C++ 程序
展示C/C++函数在被调用时,使用 Frida 进行拦截,然后修改函数参数,以及对目标进程中的函数进行自定义调用。
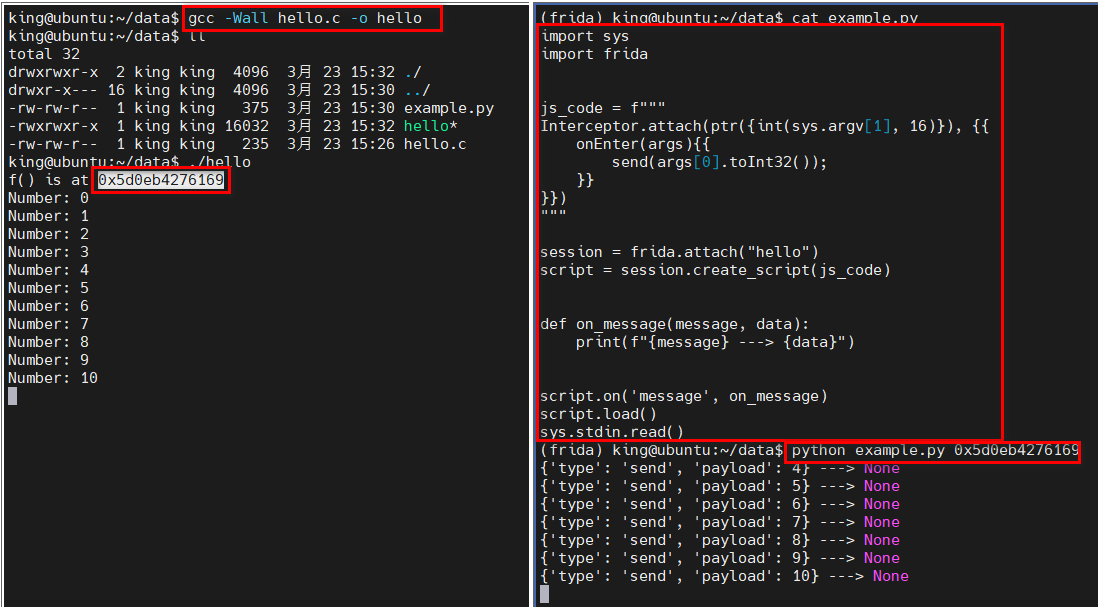
示例:创建一个文件 hello.c
#include <stdio.h>
#include <unistd.h>
void f(int n) {
printf("Number: %d\n", n);
}
int main(int argc, char *argv[]) {
int i = 0;
printf("f() is at %p\n", f);
while (1) {
f(i++);
sleep(1);
}
}编译方式:gcc -Wall hello.c -o hello
启动程序 ( 0x400544 在以下示例中): f()
f() is at 0x400544
Number: 0
Number: 1
Number: 2
…
hook 函数
对目标进程的函数 f() 进行了Hook,并把拦截到的函数的参数打印出来,创建 hook.py
import sys
import frida
js_code = f"""
Interceptor.attach(ptr({int(sys.argv[1], 16)}), {{
onEnter(args){{
send(args[0].toInt32());
}}
}})
"""
session = frida.attach("hello")
script = session.create_script(js_code)
def on_message(message, data):
print(f"{message} ---> {data}")
script.on('message', on_message)
script.load()
sys.stdin.read()运行脚本:python hook.py 0x400544,正常情况,每隔1秒钟应该能看到一行输出。运行效果:
- ctrl+c 强行中断当前程序的执行。
- ctrl+z 将任务中断,但是此任务并没有结束,他仍然在进程中,只是放到后台并维持挂起的状态。如需其在后台继续运行,需用“bg 进程号”使其继续运行;再用"fg 进程号"可将后台进程前台化。
- ctrl+\ 表示退出。
- ctrl+d 表示结束当前输入(即用户不再给当前程序发出指令),那么Linux通常将结束当前程序。
在 linux 中 ctrl+c、ctrl+d、ctrl+z 意义
- ctrl-c 发送 SIGINT 信号给前台进程组中的所有进程。常用于终止正在运行的程序。
- ctrl-z 发送 SIGTSTP 信号给前台进程组中的所有进程,常用于挂起一个进程。
- ctrl-d 不是发送信号,而是表示一个特殊的二进制值,表示 EOF。
- ctrl-\ 发送 SIGQUIT 信号给前台进程组中的所有进程,终止前台进程并生成 core 文件。
hook 修改 函数参数
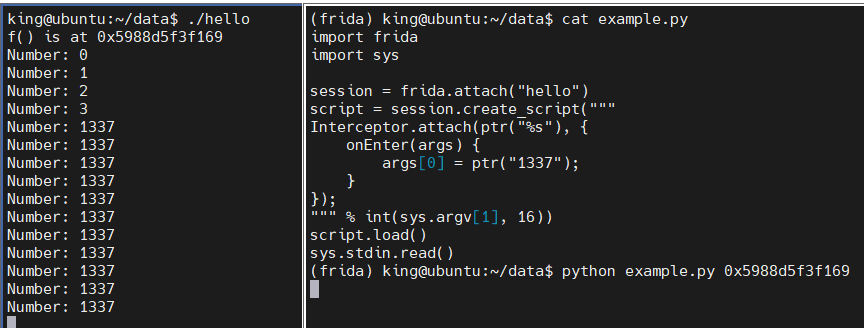
还是利用上面的程序,但是这次要修改函数调用的参数,创建文件 modify.py,大致内容如下
import frida
import sys
session = frida.attach("hello")
script = session.create_script("""
Interceptor.attach(ptr("%s"), {
onEnter(args) {
args[0] = ptr("1337");
}
});
""" % int(sys.argv[1], 16))
script.load()
sys.stdin.read()执行脚:python modify.py 0x400544,可以看到一直输出 1337,直到按 Ctrl+D 停止程序
hook 创建函数指针,并调用函数
可以使用 Frida 在目标进程空间内进行函数调用,创建文件 call.py,大致内容如下:
import frida
import sys
session = frida.attach("hello")
script = session.create_script("""
const f = new NativeFunction(ptr("%s"), 'void', ['int']);
f(1911);
f(1911);
f(1911);
""" % int(sys.argv[1], 16))
script.load()运行脚本:python call.py 0x400544 ,注意观察输出结果,然后结合测试程序的逻辑,输出结果可以看出函数调用成功了:
注入 字符串 并调用函数
用 Frida 你可以在目标进程中注入整形、字符串、甚至是任何你需要的类型。为了实验需要,创建如下文件 hi.c,内容如下:
#include <stdio.h>
#include <unistd.h>
int f(const char *s) {
printf("String: %s\n", s);
return 0;
}
int main(int argc, char *argv[]) {
const char *s = "Testing!";
printf("f() is at %p\n", f);
printf("s is at %p\n", s);
while (1) {
f(s);
sleep(1);
}
}和上面的实验相似,接着创建一个脚本文件 stringhook.py ,使用 Frida 把字符串注入内存,然后调用函数 f(),大致内容如下:
import frida
import sys
session = frida.attach("hi")
script = session.create_script("""
const st = Memory.allocUtf8String("TESTMEPLZ!");
const f = new NativeFunction(ptr("%s"), 'int', ['pointer']);
// In NativeFunction param 2 is the return value type,
// and param 3 is an array of input types
f(st);
""" % int(sys.argv[1], 16))
def on_message(message, data):
print(message)
script.on('message', on_message)
script.load()注意观察程序 hi 的输出结果,应该能看到大致如下的输出结果:
...
String: Testing!
String: Testing!
String: TESTMEPLZ!
String: Testing!
String: Testing!
...
使用 Memory 对象中的方法,比如 Memory.alloc() 和 Memory.protect() 很容就能操作目标进程的内存,可以创建 Python 的 ctypes 和其他内存结构比如 structs,然后以字节数组的方式传递给目标函数。
注入指定格式的内存对象
例子:sockaddr_in结构。有过网络编程经验的人应该都熟悉这个最常见的C结构。下面给出一个示例程序,程序中创建了一个socket,然后通过5000端口连接上服务器,然后通过这条连接发送了一个字符串 "Hello there!",代码如下:
#include <arpa/inet.h>
#include <errno.h>
#include <netdb.h>
#include <netinet/in.h>
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <sys/socket.h>
#include <sys/types.h>
#include <unistd.h>
int main(int argc, char *argv[]) {
int sock_fd, i, n;
struct sockaddr_in serv_addr;
unsigned char *b;
const char *message;
char recv_buf[1024];
if (argc != 2) {
fprintf(stderr, "Usage: %s <ip of server>\n", argv[0]);
return 1;
}
printf("connect() is at: %p\n", connect);
if ((sock_fd = socket(AF_INET, SOCK_STREAM, 0)) < 0) {
perror("Unable to create socket");
return 1;
}
bzero(&serv_addr, sizeof(serv_addr));
serv_addr.sin_family = AF_INET;
serv_addr.sin_port = htons(5000);
if (inet_pton(AF_INET, argv[1], &serv_addr.sin_addr) <= 0) {
fprintf(stderr, "Unable to parse IP address\n");
return 1;
}
printf("\nHere's the serv_addr buffer:\n");
b = (unsigned char *) &serv_addr;
for (i = 0; i != sizeof(serv_addr); i++)
printf("%s%02x", (i != 0) ? " " : "", b[i]);
printf("\n\nPress ENTER key to Continue\n");
while (getchar() == EOF && ferror(stdin) && errno == EINTR);
if (connect(sock_fd, (struct sockaddr *) &serv_addr, sizeof(serv_addr)) < 0) {
perror("Unable to connect");
return 1;
}
message = "Hello there!";
if (send(sock_fd, message, strlen(message), 0) < 0) {
perror("Unable to send");
return 1;
}
while (1) {
n = recv(sock_fd, recv_buf, sizeof(recv_buf) - 1, 0);
if (n == -1 && errno == EINTR)
continue;
else if (n <= 0)
break;
recv_buf[n] = 0;
fputs(recv_buf, stdout);
}
if (n < 0) {
perror("Unable to read");
}
return 0;
}这基本上是一个比较标准的网络程序,使用第一个参数作为目标IP地址进行连接。打开一个命令,执行 nc -l 5000 这条命令,然后再打开另外一个命令行,执行如下命令:./client 127.0.0.1,这个时候你应该就能看到执行nc命令的那个窗口开始显示消息了,你也可以在nc窗口里面发送字符串到client程序去。
现在玩点好玩的,根据前面的描述,可以往目标进程中注入字符串以及内存指针,现在用同样的方式来操作 sockaddr_in ,运行程序,如下输出:
$ ./client 127.0.0.1
connect() is at: 0x400780Here's the serv_addr buffer:
02 00 13 88 7f 00 00 01 30 30 30 30 30 30 30 30
Press ENTER key to Continue
如果你还不熟悉 sockaddr_in 这个结构,可以到网上去查找相关的资料,相关资料还是很多的。这里我们重点关注 0x1388,也就是10进制的5000,这个就是我们的端口号,如果我们把这个数据改成 0x1389,我们就能把客户端的连接重定向到另外一个端口去了,如果我们把接下来的4字节数据也修改的话,那就能把客户端重定向到另外一个IP去了!
下面看这个脚本,这个脚本注入了一个指定格式的内存结构,然后劫持了libc.so中的 connect() 函数,在劫持的函数中用我们构造的结构体,替换 connect() 函数的第一个参数。创建文件 struct_mod.py,内容如下:
import frida
import sys
session = frida.attach("client")
script = session.create_script("""
// 首先,开辟一块内存用来存放我们的结构体
send('Allocating memory and writing bytes...');
const st = Memory.alloc(16);
// 现在,把结构体的内容填充到开辟的内存中。注意:填充的是二进制数据。
st.writeByteArray([0x02, 0x00, 0x13, 0x89, 0x7F, 0x00, 0x00, 0x01, 0x30, 0x30, 0x30, 0x30, 0x30, 0x30, 0x30, 0x30]);
// Module.getExportByName()可以在不知道源模块的情况下找到函数,但它很慢,
// 特别是在大型二进制文件中
Interceptor.attach(Module.getExportByName(null, 'connect'), {
onEnter(args) {
send('Injecting malicious byte array:');
args[1] = st;
}
//, onLeave(retval) {
// retval.replace(0); // 使用它来操作返回值
//}
});
""")
# Here's some message handling..
# [ It's a little bit more meaningful to read as output :-D
# Errors get [!] and messages get [i] prefixes. ]
def on_message(message, data):
if message['type'] == 'error':
print("[!] " + message['stack'])
elif message['type'] == 'send':
print("[i] " + message['payload'])
else:
print(message)
script.on('message', on_message)
script.load()
sys.stdin.read()使用 Module.findExportByName() 在目标进程中的指定模块中查找指定的导出函数。现在使用命令 ./client 127.0.0.1 把程序执行起来,然后在另外一个命令行中执行 nc -l 5001,在第三个命令行中执行 ./struct_mod.py,一旦我们的脚本执行起来,在 client 的那个命令行窗口里面和 nc 命令行窗口里面就能看到字符串消息了。通过这个实验,成功的劫持了网络应用程序,并且通过Frida修改了程序的原始行为,达到了不可告人的目的。这个实验证明 Frida 的强大,那就是:
- 无代码修改
- 不需要复杂的逆向
- 不需要花大量的时间去反汇编(感觉跟第2点相同)
最佳 实践
String allocation (UTF-8/UTF-16/ANSI)
字符串分配(UTF-8/UTF-16/ANSI)。可能会认为 "分配 / 替换 字符串" 就像这样简单:
onEnter(args) {
args[0].writeUtf8String('mystring');
}但是,这样做不太对,可能会报错,因为指向的字符串可能:
- 函数参数可能驻留在 "只读数据" 部分,该部分以只读方式映射到进程的地址空间;
- 函数参数重新赋值后,数据可能比原来的数据更长,因此 writeUtf8String() 会导致缓冲区溢出,并可能损坏不相关的内存。
即使你可以通过使用 Memory.protect() 解决前一个问题,但是有个更好的解决方案:分配一个新字符串并替换参数。然而,有一个陷阱:Memory.allocUtf8String()返回的值必须保持活动状态--一旦 JavaScript 值被垃圾收集,它就会被释放。这意味着它需要至少在函数调用的持续时间内保持活动状态,确切的语义取决于API是如何设计的。考虑到这一点,一个可靠的方法是:
onEnter(args) {
const buf = Memory.allocUtf8String('mystring');
this.buf = buf;
args[0] = buf;
}它的工作方式是,它绑定到一个对象,这个对象是每个线程和每个调用的,你在那里存储的任何东西都可以在 onLeave 中使用,这甚至可以在递归的情况下工作。这样,你就可以在 onEnter 中读取参数,并在 onLeave 中访问它们。这也是在函数调用期间保持内存分配活动的推荐方法。
如果函数保留指针并在函数调用完成后使用它,一个解决方案是这样做:
const myStringBuf = Memory.allocUtf8String('mystring');
Interceptor.attach(f, {
onEnter(args) {
args[0] = myStringBuf;
}
});Reusing arguments
在 onEnter 中使用参数时,通常是通过索引访问每个参数。但是当一个参数被多次访问时会发生什么呢?以下面的代码为例:
Interceptor.attach(f, {
onEnter(args) {
if (!args[0].readUtf8String(4).includes('MZ')) {
console.log(hexdump(args[0]));
}
}
});在上面的例子中,第一个参数从args数组中获得了两次,这就需要为两次查询frida-gum的信息付出代价。为了避免在多次需要相同参数时浪费宝贵的CPU周期,最好使用局部变量存储此信息:
Interceptor.attach(f, {
onEnter(args) {
const firstArg = args[0];
if (!firstArg.readUtf8String(4).includes('MZ')) {
console.log(hexdump(firstArg));
}
}
});"发送、接受" 消息
"被注入的目标进程、Python主控端" 相互发送和接收消息
被注入的目标进程:接收、发送
recv([type, ]callback):收到 Python主控端(就是基于Frida的应用程序) 发过来的消息时调用callback。type是可选的,可以指定仅接收指定type字段的消息。revc 每次只能接收一条消息。send(message[, data]):将JavaScript对象message发送到 Python主控端(就是基于Frida的应用程序)(message必须可序列化为JSON)。如果还有一些原始的二进制数据,你想一起发送,例如:你使用NativePointer#readByteArray转储了一些内存,那么你可以通过可选的data参数来传递它。这要求它是一个ArrayBuffer或一个0到255之间的整数数组。总结:消息是在第一个参数中传递,如果二进制数据与它一起传递,则第二个参数是ArrayBuffer,否则为 null。
Python主控端(就是基于Frida的应用程序)
- 接收:
def on_message(message, data):
print(message)
script.on('message', on_message) - 发送:
script.on('message', on_message)
script.load()
script.post({"type": "poke"})
创建文件 hello.c
#include <stdio.h>
#include <unistd.h>
void f(int n) {
printf("Number: %d\n", n);
}
int main(int argc,
char *argv[]) {
int i = 0;
printf("f() is at %p\n", f);
while (1) {
f(i++);
sleep(1);
}
}编译:gcc -Wall hello.c -o hello ,然后启动程序,记录下函数 f() 的地址
f() is at 0x400544
Number: 0
Number: 1
Number: 2
…
在目标进程中发送消息
从目标进程中给Python主控端发回了一条消息,理论上你可以发送任何可以序列化成JSON的任何JavaScript值。创建文件 send.py,大致内容如下:
import frida
import sys
session = frida.attach("hello")
script = session.create_script("send(1337);")
def on_message(message, data):
print(message)
script.on('message', on_message)
script.load()
sys.stdin.read()- 执行脚本:python send.py
- 输入结果:{'type': 'send', 'payload': 1337}
- 从上面的结果可以知道,send(1337) 这段JavaScript代码已经在 hello 这个进程中执行了,可以使用 Ctrl + D 来终止脚本执行。
处理JavaScript运行时错误
- 如果 JavaScript 脚本抛出了异常,这个异常就会被从目标进程发送到 Python 主控端。比如把 send(1337) 改成 send(a) (未定义变量a),Python主控端就会收到下面的错误信息:
- {u'type': u'error', u'description': u'ReferenceError: a is not defined', u'lineNumber': 1}
- 请注意 错误信息的字段变成了 error 而不是上面的 send
在目标进程中接收消息
- 也可以从Python主控端往目标进程中的JavaScript代码发消息,示例:pingpong.py
import frida
import sys
session = frida.attach("hello")
script = session.create_script("""
recv('poke', function onMessage(pokeMessage) { send('pokeBack'); });
""")
def on_message(message, data):
print(message)
script.on('message', on_message)
script.load()
script.post({"type": "poke"})
sys.stdin.read()- 执行:python pingpong.py
- 输出结果:{'type': 'send', 'payload': 'pokeBack'}
在目标进程中以阻塞方式接收
- 在目标进程中的 JavaScript 代码可以用阻塞的方式接收来自主控端的消息,示例:rpc.py
import frida
import sys
session = frida.attach("hello")
script = session.create_script("""
Interceptor.attach(ptr("%s"), {
onEnter(args) {
send(args[0].toString());
const op = recv('input', value => {
args[0] = ptr(value.payload);
});
op.wait();
}
});
""" % int(sys.argv[1], 16))
def on_message(message, data):
print(message)
val = int(message['payload'], 16)
script.post({'type': 'input', 'payload': str(val * 2)})
script.on('message', on_message)
script.load()
sys.stdin.read()先执行 hello 程序,然后记录下打印出来的函数地址(比如:0x400544)再执行:python rpc.py 0x400544 ,然后观察 hello 程序输出,输出结果一直是输入数据的2倍,按 Ctrl+D 结束。
将数据写入文件
如果你想将一些数据写入一个文件,你应该从注入的脚本中 send() 它,并在基于Frida的应用程序中接收它,然后将它写入一个文件。提示: send() 的数据应该是JSON可序列化的。
agent.js:
```
const data = { foo: 'bar' };
send(data);
```
app.py:
```
import frida
def on_message(message, data):
print(message['payload'])
```控制台 打印
console.log(line) , console.warn(line) , console.error(line) :将 line 写入基于Frida的应用程序的控制台。如果 ArrayBuffer对象作为参数,将会使用hexdump()函数输出结果。
Hexdump
hexdump(target[, options]): 把一个 ArrayBuffer 或者 NativePointer 的target变量,附加一些 options 属性,按照指定格式进行输出,比如:
const libc = Module.findBaseAddress('libc.so');
console.log(hexdump(libc, {
offset: 0,
length: 64,
header: true,
ansi: true
}));rpc.exports
rpc.exports :可以替换或插入的空对象,以便向您的应用程序暴露一个RPC风格的API。键指定方法名称,值是您导出的函数。这个函数可以返回一个简单的值以便立即返回给调用者,或者返回一个Promise以便异步返回。示例:
rpc.exports = {
add(a, b) {
return a + b;
},
sub(a, b) {
return new Promise(resolve => {
setTimeout(() => {
resolve(a - b);
}, 100);
});
}
};在 Node.js 程序中,这个 API 可以这样使用:
const frida = require('frida');
const fs = require('fs');
const path = require('path');
const util = require('util');
const readFile = util.promisify(fs.readFile);
let session, script;
async function run() {
const source = await readFile(path.join(__dirname, '_agent.js'), 'utf8');
session = await frida.attach('iTunes');
script = await session.createScript(source);
script.message.connect(onMessage);
await script.load();
console.log(await script.exports.add(2, 3));
console.log(await script.exports.sub(5, 3));
}
run().catch(onError);
function onError(error) {
console.error(error.stack);
}
function onMessage(message, data) {
if (message.type === 'send') {
console.log(message.payload);
} else if (message.type === 'error') {
console.error(message.stack);
}
}Python 版本
import codecs
import frida
def on_message(message, data):
if message['type'] == 'send':
print(message['payload'])
elif message['type'] == 'error':
print(message['stack'])
session = frida.attach('iTunes')
with codecs.open('./agent.js', 'r', 'utf-8') as f:
source = f.read()
script = session.create_script(source)
script.on('message', on_message)
script.load()
print(script.exports.add(2, 3))
print(script.exports.sub(5, 3))
session.detach()使用 script.on('message', on_message) 来监视来自注入进程(JavaScript端)的任何消息。还可以在 script 和 session 上查看其他通知。如果您希望在目标进程退出时得到通知,使用 session.on('detached', your_function) 。
Timing events (定时事件)
setTimeout(func, delay[, ...parameters]):在delay毫秒后调用func,可选地传递一个或多个parameters。返回一个id,可以传递给clearTimeout来取消它。clearTimeout(id):调用setTimeout返回的取消ID。setInterval(func, delay[, ...parameters]):每隔delay毫秒调用func,可选地传递一个或多个parameters。返回一个id,可以传递给clearInterval来取消它。clearInterval(id):调用setInterval返回的取消ID。setImmediate(func[, ...parameters]):安排func尽快在Frida的JavaScript线程上被调用,可选地传递一个或多个parameters。返回一个id,可以传递给clearImmediate取消它。clearImmediate(id):调用setImmediate返回的取消ID。
Garbage collection (垃圾收集)
gc():强制垃圾收集。用于测试,特别是涉及Script.bindWeak()的逻辑。
Worker
具有自己的JavaScript堆、锁等的工作脚本。
new Worker(url[, options]):创建一个新的 worker,在指定的url处执行脚本。URL通常是通过让模块导出其import.meta.url并从创建worker的模块导入来检索的。如果指定,options是一个对象,它可能包含一个或多个以下键:onMessage:当worker使用send()发出消息时调用的函数。回调签名与recv()相同。terminate():终止worker。post(message[, data]):给工人发消息。签名与send()相同。使用recv()在worker内部接收它。exports:用于调用由worker定义的rpc.exports的魔术代理对象。每个函数都返回一个Promise,你可以在一个P2P函数中等待它。
iOS 上使用 Frida
在 iOS 设备上,Frida 支持两种使用模式。
- 已越狱机器。在越狱的环境下,用户权限比较大,可以很容易调用系统服务和基础组件。
- 未越狱机器
已越狱机器
启动 Cydia 然后通过 Manage -> Sources -> Edit -> Add 这个操作步骤把 https://build.frida.re 这个代码仓库加入进去。然后你就可以在 Cydia 里面找到 Frida 的安装包了,然后你就可以把你的iOS设备插入电脑,并可以开始使用 Frida 了。
在主控端电脑上(Windows、macOS)执行如下命令,确保Frida可以正常工作:frida-ps -U
如果你还没有把你的iOS设备插入到电脑里面(或者插到电脑但是没有被正常识别),那应该会像下面这样提示:Waiting for USB device to appear...
如果iOS设备已经正常连接了,那应该会看到设备上的进程列表了,大致如下:
PID NAME
488 Clock
116 Facebook
312 IRCCloud
1711 LinkedIn
…
如果到了这一步没有问题,那就可以继续往下走。
跟踪Twitter中的加密函数
在设备上启动Twitter,然后让它持续的保持在前台,并确保你的机器不会进入睡眠状态。现在在你的主控端的机器上执行如下命令:
frida-trace -U -i "CCCryptorCreate*" Twitter
Uploading data...
CCCryptorCreate: Auto-generated handler …/CCCryptorCreate.js
CCCryptorCreateFromData: Auto-generated handler …/CCCryptorCreateFromData.js
CCCryptorCreateWithMode: Auto-generated handler …/CCCryptorCreateWithMode.js
CCCryptorCreateFromDataWithMode: Auto-generated handler …/CCCryptorCreateFromDataWithMode.js
Started tracing 4 functions. Press Ctrl+C to stop.
目前, 很多App的加密、解密、哈希算法基本上都是使用 CCryptorCreate 和相关的一组加密函数。现在,开始尝试在App里面触发一些网络操作,然后看到一些输出:
3979 ms CCCryptorCreate()
3982 ms CCCryptorCreateWithMode()
3983 ms CCCryptorCreate()
3983 ms CCCryptorCreateWithMode()
现在可以阅读 man CCryptorCreate 并编辑上述JavaScript文件,开始深入研究iOS应用程序。
没有越狱的iOS设备
Frida 能够检测可调试的应用程序,并将从 Frida 12.7.12 开始自动注入 Gadget。
只需注意以下几个要求:
- 理想情况下 iOS 设备应运行 iOS 13 或更高版本。对旧版本的支持被认为是实验性的。
- 必须挂载开发人员磁盘映像。Xcode 会在发现 iOS USB 设备后立即自动挂载它,但您也可以使用 ideviceimagemounter 手动挂载。
- 为了让一个 App 能使用 Frida,必须想办法让它加载一个 .dylib,就是一个 Gadget 模块。可以下载放在 ~/.cache/frida/gadget-ios.dylib
虽然 frida、frida-trace 等 CLI 工具绝对非常有用,但有时您可能想利用强大的 Frida API 构建自己的工具。为此,建议阅读有关函数和消息的章节,并且您看到的 frida.attach() 任何地方都可以将其替换为 frida.get_usb_device().attach()
使用示例 参考
- 通过REPL将脚本注入USB设备上的进程:frida -U -n Twitter -l demo1.js
- 列出USB设备上所有正在运行的进程名称和PID:frida-ps -U
- 列出USB设备上所有已安装的应用程序:frida-ps -Uai
- 列出USB设备上所有正在运行的应用程序:frida-ps -Ua
- 列出所有连接的设备:frida-ls-devices
- 跟踪 native(本地、原生) APIs:frida-trace -U Twitter -i "*URL*"
- 跟踪Objective-C APIs:frida-trace -U Twitter -m "-[NSURL* *HTTP*]"
- 回溯一个Objective-C方法调用:log('\tBacktrace:\n\t' + Thread.backtrace(this.context, Backtracer.ACCURATE).map(DebugSymbol.fromAddress) .join('\n\t'));
- 将数据写入文件:如果你想将一些数据写入一个文件,你应该从注入的脚本中
send()它,并在基于Frida的应用程序中接收它,然后将它写入一个文件。提示:send()的数据应该是JSON可序列化的。 - 调用本机函数:const address = Module.getExportByName('libsqlite3.dylib', 'sqlite3_sql'); const sql = new NativeFunction(address, 'char', ['pointer']); sql(statement);
数据结构:console.log('Type of args[2] -> ' + new ObjC.Object(args[2]).$className) 如果事情看起来不像预期的那样工作,那么您可能正在与错误的数据类型进行交互-运行以下命令以确定您正在处理的对象的实际类型!
- 将 NSData 转换为字符串。提示:如果字符串数据以null结尾,则不需要第2个参数(字节数)
const data = new ObjC.Object(args[2]);
data.bytes().readUtf8String(data.length()); - 将NSData转换为二进制数据
const data = new ObjC.Object(args[2]);
data.bytes().readByteArray(data.length()); - 迭代 NSArray
const array = new ObjC.Object(args[2]);
/*
* Be sure to use valueOf() as NSUInteger is a Number in
* 32-bit processes, and UInt64 in 64-bit processes. This
* coerces it into a Number in the latter case.
*/
const count = array.count().valueOf();
for (let i = 0; i !== count; i++) {
const element = array.objectAtIndex_(i);
} - 迭代 NSDictionary
const dict = new ObjC.Object(args[2]);
const enumerator = dict.keyEnumerator();
let key;
while ((key = enumerator.nextObject()) !== null) {
const value = dict.objectForKey_(key);
} - 解压 NSKeyedArchiver
const parsedValue = ObjC.classes.NSKeyedUnarchiver.unarchiveObjectWithData_(value); - 阅读结构。如果args[0]是一个指向结构体的指针,假设你想读取偏移量为4的uint 32,你可以如下所示:args[0].add(4).readU32();
- 在 iOS 7上关闭警报框
const UIAlertView = ObjC.classes.UIAlertView; /* iOS 7 */
const view = UIAlertView.alloc().initWithTitle_message_delegate_cancelButtonTitle_otherButtonTitles_(
'Frida', 'Hello from Frida', NULL, 'OK', NULL);
view.show();
view.release();
在iOS上设置警告框>= 8
// Defining a Block that will be passed as handler parameter to +[UIAlertAction actionWithTitle:style:handler:]
const handler = new ObjC.Block({
retType: 'void',
argTypes: ['object'],
implementation() {
}
});
// Import ObjC classes
const UIAlertController = ObjC.classes.UIAlertController;
const UIAlertAction = ObjC.classes.UIAlertAction;
const UIApplication = ObjC.classes.UIApplication;
// Using Grand Central Dispatch to pass messages (invoke methods) in application's main thread
ObjC.schedule(ObjC.mainQueue, () => {
// Using integer numerals for preferredStyle which is of type enum UIAlertControllerStyle
const alert = UIAlertController.alertControllerWithTitle_message_preferredStyle_('Frida', 'Hello from Frida', 1);
// Again using integer numeral for style parameter that is enum
const defaultAction = UIAlertAction.actionWithTitle_style_handler_('OK', 0, handler);
alert.addAction_(defaultAction);
// Instead of using `ObjC.choose()` and looking for UIViewController instances
// on the heap, we have direct access through UIApplication:
UIApplication.sharedApplication().keyWindow().rootViewController().presentViewController_animated_completion_(alert, true, NULL);
});打印 NSURL参数。示例:拦截对[UIApplication openURL:]的调用并显示传递的NSURL。
// Get a reference to the openURL selector
const openURL = ObjC.classes.UIApplication['- openURL:'];
// Intercept the method
Interceptor.attach(openURL.implementation, {
onEnter(args) {
// As this is an Objective-C method, the arguments are as follows:
// 0. 'self'
// 1. The selector (openURL:)
// 2. The first argument to the openURL method
const myNSURL = new ObjC.Object(args[2]);
// Convert it to a JS string
const myJSURL = myNSURL.absoluteString().toString();
// Log it
console.log('Launching URL: ' + myJSURL);
}
});Android 上使用 Frida
使用模拟器:在模拟器中进行测试,就要把 frida-trace -U -f re.frida.Gadget -i "open*" 命令中的 -U 替换成 -R,这样一来底层的内部调用也从 getusbdevice() 变成 getremotedevice()。
root、上传 frida-server 并执行
演示如何在Android设备上进行函数跟踪。首先需要 root 你的安卓设备。从技术上讲,使用Frida而不root设备也是可能的,例如通过重新打包应用程序以包含 frida-gadget,或使用调试器来完成相同的操作。但是使用 root 后的设备操作起来更简单快捷。如果没有 root 的设备,也可以使用模拟器。除了一台root设备之外,还需要安装Android SDK工具,因为要用到它的 adb 工具。
首先,下载最新的 Android 设备上的 frida-server (下载地址:https://github.com/frida/frida/releases)然后把这个文件在手机上运行起来:
$ adb root
$ adb push frida-server /data/local/tmp/
$ adb shell "chmod 755 /data/local/tmp/frida-server"
$ adb shell "/data/local/tmp/frida-server &"
某些应用程序会检测 frida-server 位置。将 frida-server 二进制文件重命名为随机名称,或将其移动到另一个位置(如 /dev)可能会解决问题。以 root 身份启动 frida-server,即如果您在 root 设备上执行此操作,则可能需要 su 并从该 shell 运行它。
确保 adb 可以看到您的设备:adb devices -l ,一切环境准备完毕,测试 Frida 是否正常,执行如下命令:frida-ps -U ,这条命令应该会显示一个进程列表:
PID NAME
1590 com.facebook.katana
13194 com.facebook.katana:providers
12326 com.facebook.orca
13282 com.twitter.android
…
如果上面都操作正常,继续往下走。。。
跟踪 Chrome 的 Open() 函数
现在在Android机器上启动 Chrome 浏览器,然后在你的主控端电脑上运行如下命令:
$ frida-trace -U -i open -N com.android.chrome
Uploading data...
open: Auto-generated handler …/linker/open.js
open: Auto-generated handler …/libc.so/open.js
Started tracing 2 functions. Press Ctrl+C to stop.
在Chrome 浏览器里面任意操作,可以看到主控端的命令行关于 open() 的输出:
1392 ms open()
1403 ms open()
1420 ms open()
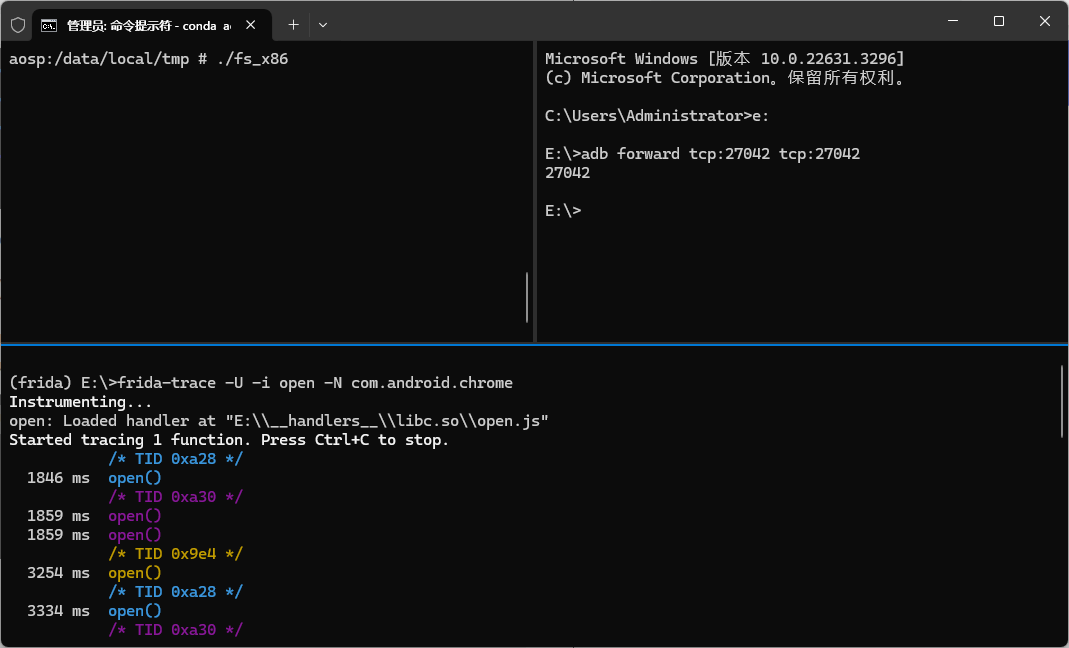
现在可以在阅读 man open 编辑上述 JavaScript 文件,并开始深入地研究 Android 应用程序。
hook java层函数
虽然 frida、frida-trace 等 CLI 工具非常有用,但不能满足所有需求,这时就可以利用Frida强大的 API 构建自己的工具。可以参考前面的 "Frida 操作 C/C++ 程序,发送、接收 消息",并且可以看到使用
frida.attach()的地方都可以替换为frida.get_usb_device().attach()
示例:为 Android CTF 构建工具
建议使用 Android x86模拟器。此工具基于 SECCON Quals CTF 2015 APK 1 示例。
下载:https://github.com/ctfs/write-ups-2015/tree/master/seccon-quals-ctf-2015/binary/reverse-engineering-android-apk-1
将代码保存为ctf.py并以 python ctf.py 运行。
import frida, sys
def on_message(message, data):
if message['type'] == 'send':
print("[*] {0}".format(message['payload']))
else:
print(message)
jscode = """
Java.perform(() => {
// Function to hook is defined here
const MainActivity = Java.use('com.example.seccon2015.rock_paper_scissors.MainActivity');
// Whenever button is clicked
const onClick = MainActivity.onClick;
onClick.implementation = function (v) {
// Show a message to know that the function got called
send('onClick');
// Call the original onClick handler
onClick.call(this, v);
// Set our values after running the original onClick handler
this.m.value = 0;
this.n.value = 1;
this.cnt.value = 999;
// Log to the console that it's done, and we should have the flag!
console.log('Done:' + JSON.stringify(this.cnt));
};
});
"""
process = frida.get_usb_device().attach('com.example.seccon2015.rock_paper_scissors')
script = process.create_script(jscode)
script.on('message', on_message)
print('[*] Running CTF')
script.load()
sys.stdin.read()注意:设置字段的值使用 this.m.value = 0 而不是 this.m = 0 。如果这个类中还有一个名为 m 的方法,我们需要使用 this._m.value = 0 来设置字段 m 的值。一般来说,当查看对象的属性时,需要使用 .value 来访问这些字段引用的值。
Java 桥 可以做什么
- Java.perform(fn):相当于是 frida 的 main 函数,所有的脚本必须放在这个里面。作用就是确保当前线程被附加到 VM 上,并且调用 fn 函数。此函数在内部调用 VM::AttachCurrentThread,然后执行 fn 回调函数中的 Javascript 脚本来操作Java运行时,最后使用 VM::DetachCurrentThread 释放资源。
- Java.available:确认当前进程的 java 虚拟机是否已经启动,虚拟机包括Dalbik或者ART等。如果Java虚拟机没有启动,就不要使用 java 的任何属性或者方法。否则报错。
- Java.use(className):通过类名获得 Java 类,返回一个 "包裹好的Javascript对象"。通过该对象,可访问类成员,通过调用
$new()构造函数并实例化对象。调用 $dispose()销毁对象 - Java.choose(className, callback):在内存中扫描 Java 堆,枚举 Java 对象(className)实例。比如可以使用
java.lang.String扫描内存中的字符串。callbacks 提供两个参数:onMatch(instance)和onComplete,分别是找到匹配对象和扫描完成调用。 - Java.scheduleOnMainThread(fn):在 VM 主线程 (UI线程) 上执行回调函数。Android 中操作UI元素需要在主线程中执行代码,
scheduleOnMainThread就是用来在主线程中执行函数。Java.perform(function(){ var Toast = Java.use("android.widget.Toast"); // 获取 context var currentApplication = Java.use("android.app.ActivityThread").currentApplication(); var context = currentApplication.getApplicationContext(); // 在主线程中运行回调 Java.scheduleOnMainThread(function(){ Toast.makeText(context, "Hello frida!", Toast.LENGTH_LONG.value).show(); }); }); - Java.enumerateLoadedClasses(callbacks):列出当前已经加载的类,用回调函数处理
- Java.enumerateLoadedClassesSync():获得所有加载类的数组
- enumerateLoadedClasses(callbacks):枚举当前已加载的类。
callbacks参数是一个对象,需要提供两个回调函数——onMatch(className)和onComplete。每次找到一个类就会调用一次onMatch,全部找完之后,调用onComplete。 - Java.cast(handle, klass):用来获取指定内存地址的类的实例的对象。这个对象有类属性,可以得到所属类的对象。还有$className属性过去类名的字符串。一个对象可能有很多实例
java 接口的 api 中
- perform 是必须用,相当于 frida 的 main 函数。
- use 最常用,用来获取类的对象,获取对象后就可以对方法进行hook、替换等操作,相当于修改源码。
- choose 和 cast 是针对运行时对象的实例,相当于动态调试过程中获取信息。
Frida 中 Java Bridge 示例:
Java.perform(() => {
// Create an instance of java.lang.String and initialize it with a string
const JavaString = Java.use('java.lang.String');
const exampleString1 = JavaString.$new('Hello World, this is an example string in Java.');
console.log('[+] exampleString1: ' + exampleString1);
console.log('[+] exampleString1.length(): ' + exampleString1.length());
// Create an instance of java.nio.charset.Charset, and initialize the default character set
const Charset = Java.use('java.nio.charset.Charset');
const charset = Charset.defaultCharset();
// Create a byte array of a Javascript string
const charArray = 'This is a Javascript string converted to a byte array.'.split('').map(function(c) {
return c.charCodeAt(0);
});
// Create an instance of java.lang.String and initialize it through an overloaded $new,
// with a byte array and a instance of java.nio.charset.Charset
const exampleString2 = JavaString.$new.overload('[B', 'java.nio.charset.Charset').call(JavaString, charArray, charset)
console.log('[+] exampleString2: ' + exampleString2);
console.log('[+] exampleString2.length(): ' + exampleString2.length());
// Intercept the initialization of java.lang.Stringbuilder's overloaded constructor,
// and write the partial argument to the console
const StringBuilder = Java.use('java.lang.StringBuilder');
// We need to replace .$init() instead of .$new(), since .$new() = .alloc() + .init()
const ctor = StringBuilder.$init.overload('java.lang.String');
ctor.implementation = function (arg) {
let partial = '';
const result = ctor.call(this, arg);
if (arg !== null) {
partial = arg.toString().replace('\n', '').slice(0, 10);
}
// console.log('new StringBuilder(java.lang.String); => ' + result);
console.log('new StringBuilder("' + partial + '");');
return result;
};
console.log('[+] new StringBuilder(java.lang.String) hooked');
// Intercept the toString() method of java.lang.StringBuilder and write its partial contents to the console.
const toString = StringBuilder.toString;
toString.implementation = function () {
const result = toString.call(this);
let partial = '';
if (result !== null) {
partial = result.toString().replace('\n', '').slice(0, 10);
}
console.log('StringBuilder.toString(); => ' + partial);
return result;
};
console.log('[+] StringBuilder.toString() hooked');
});stacktrace 用法示例
Java.perform(() => {
const Cipher = Java.use('javax.crypto.Cipher');
const Exception = Java.use('java.lang.Exception');
const Log = Java.use('android.util.Log');
const init = Cipher.init.overload('int', 'java.security.Key');
init.implementation = function (opmode, key) {
const result = init.call(this, opmode, key);
console.log('Cipher.init() opmode:', opmode, 'key:', key);
console.log(stackTraceHere());
return result;
};
function stackTraceHere() {
return Log.getStackTraceString(Exception.$new());
}
});连接到 Node.js 进程的 V8 VM 以注入任意JS
const uv_default_loop = new NativeFunction(Module.getExportByName(null, 'uv_default_loop'), 'pointer', []);
const uv_async_init = new NativeFunction(Module.getExportByName(null, 'uv_async_init'), 'int', ['pointer', 'pointer', 'pointer']);
const uv_async_send = new NativeFunction(Module.getExportByName(null, 'uv_async_send'), 'int', ['pointer']);
const uv_close = new NativeFunction(Module.getExportByName(null, 'uv_close'), 'void', ['pointer', 'pointer']);
const uv_unref = new NativeFunction(Module.getExportByName(null, 'uv_unref'), 'void', ['pointer']);
const v8_Isolate_GetCurrent = new NativeFunction(Module.getExportByName(null, '_ZN2v87Isolate10GetCurrentEv'), 'pointer', []);
const v8_Isolate_GetCurrentContext = new NativeFunction(Module.getExportByName(null, '_ZN2v87Isolate17GetCurrentContextEv'), 'pointer', ['pointer']);
const v8_HandleScope_init = new NativeFunction(Module.getExportByName(null, '_ZN2v811HandleScopeC1EPNS_7IsolateE'), 'void', ['pointer', 'pointer']);
const v8_HandleScope_finalize = new NativeFunction(Module.getExportByName(null, '_ZN2v811HandleScopeD1Ev'), 'void', ['pointer']);
const v8_String_NewFromUtf8 = new NativeFunction(Module.getExportByName(null, '_ZN2v86String11NewFromUtf8EPNS_7IsolateEPKcNS_13NewStringTypeEi'), 'pointer', ['pointer', 'pointer', 'int', 'int']);
const v8_Script_Compile = new NativeFunction(Module.getExportByName(null, '_ZN2v86Script7CompileENS_5LocalINS_7ContextEEENS1_INS_6StringEEEPNS_12ScriptOriginE'), 'pointer', ['pointer', 'pointer', 'pointer']);
const v8_Script_Run = new NativeFunction(Module.getExportByName(null, '_ZN2v86Script3RunENS_5LocalINS_7ContextEEE'), 'pointer', ['pointer', 'pointer']);
const NewStringType = {
kNormal: 0,
kInternalized: 1
};
const pending = [];
const processPending = new NativeCallback(function () {
const isolate = v8_Isolate_GetCurrent();
const scope = Memory.alloc(24);
v8_HandleScope_init(scope, isolate);
const context = v8_Isolate_GetCurrentContext(isolate);
while (pending.length > 0) {
const item = pending.shift();
const source = v8_String_NewFromUtf8(isolate, Memory.allocUtf8String(item), NewStringType.kNormal, -1);
const script = v8_Script_Compile(context, source, NULL);
const result = v8_Script_Run(script, context);
}
v8_HandleScope_finalize(scope);
}, 'void', ['pointer']);
const onClose = new NativeCallback(function () {
Script.unpin();
}, 'void', ['pointer']);
const handle = Memory.alloc(128);
uv_async_init(uv_default_loop(), handle, processPending);
uv_unref(handle);
Script.bindWeak(handle, () => {
Script.pin();
uv_close(handle, onClose);
});
function run(source) {
pending.push(source);
uv_async_send(handle);
}
run('console.log("Hello from Frida");');在 Perl 5 进程中跟踪函数调用
const pointerSize = Process.pointerSize;
const SV_OFFSET_FLAGS = pointerSize + 4;
const PVGV_OFFSET_NAMEHEK = 4 * pointerSize;
const SVt_PVGV = 9;
Interceptor.attach(Module.getExportByName(null, 'Perl_pp_entersub'), {
onEnter(args) {
const interpreter = args[0];
const stack = interpreter.readPointer();
const sub = stack.readPointer();
const flags = sub.add(SV_OFFSET_FLAGS).readU32();
const type = flags & 0xff;
if (type === SVt_PVGV) {
/*
* Note: this console.log() is not ideal performance-wise,
* a proper implementation would buffer and submit events
* periodically with send().
*/
console.log(GvNAME(sub) + '()');
} else {
// XXX: Do we need to handle other types?
}
}
});
function GvNAME(sv) {
const body = sv.readPointer();
const nameHek = body.add(PVGV_OFFSET_NAMEHEK).readPointer();
return nameHek.add(8).readUtf8String();
}Windows 上使用 Frida
演示如何使用Frida监视一个名为 fledge.exe(BB模拟器)的进程正在执行的jvm.dll。
将下面代码保存为 bb.py,运行BB模拟器(fledge.exe),然后运行 python.exe bb.py fledge.exe 以监视 jvm.dll 的 AES 使用情况。
import frida
import sys
def on_message(message, data):
print("[%s] => %s" % (message, data))
def main(target_process):
session = frida.attach(target_process)
script = session.create_script("""
// Find base address of current imported jvm.dll by main process fledge.exe
const baseAddr = Module.findBaseAddress('Jvm.dll');
console.log('Jvm.dll baseAddr: ' + baseAddr);
const setAesDecrypt0 = resolveAddress('0x1FF44870'); // Here we use the function address as seen in our disassembler
Interceptor.attach(setAesDecrypt0, { // Intercept calls to our SetAesDecrypt function
// When function is called, print out its parameters
onEnter(args) {
console.log('');
console.log('[+] Called SetAesDeCrypt0' + setAesDecrypt0);
console.log('[+] Ctx: ' + args[0]);
console.log('[+] Input: ' + args[1]); // Plaintext
console.log('[+] Output: ' + args[2]); // This pointer will store the de/encrypted data
console.log('[+] Len: ' + args[3]); // Length of data to en/decrypt
dumpAddr('Input', args[1], args[3].toInt32());
this.outptr = args[2]; // Store arg2 and arg3 in order to see when we leave the function
this.outsize = args[3].toInt32();
},
// When function is finished
onLeave(retval) {
dumpAddr('Output', this.outptr, this.outsize); // Print out data array, which will contain de/encrypted data as output
console.log('[+] Returned from setAesDecrypt0: ' + retval);
}
});
function dumpAddr(info, addr, size) {
if (addr.isNull())
return;
console.log('Data dump ' + info + ' :');
const buf = addr.readByteArray(size);
// If you want color magic, set ansi to true
console.log(hexdump(buf, { offset: 0, length: size, header: true, ansi: false }));
}
function resolveAddress(addr) {
const idaBase = ptr('0x1FEE0000'); // Enter the base address of jvm.dll as seen in your favorite disassembler (here IDA)
const offset = ptr(addr).sub(idaBase); // Calculate offset in memory from base address in IDA database
const result = baseAddr.add(offset); // Add current memory base address to offset of function to monitor
console.log('[+] New addr=' + result); // Write location of function in memory to console
return result;
}
""")
script.on('message', on_message)
script.load()
print("[!] Ctrl+D on UNIX, Ctrl+Z on Windows/cmd.exe to detach from instrumented program.\n\n")
sys.stdin.read()
session.detach()
if __name__ == '__main__':
if len(sys.argv) != 2:
print("Usage: %s <process name or PID>" % __file__)
sys.exit(1)
try:
target_process = int(sys.argv[1])
except ValueError:
target_process = sys.argv[1]
main(target_process)MacOS 上使用 Frida
要在 macOS 上设置 Frida,你需要授权Frida使用 task_for_pid 访问目标进程。如果你使用GUI运行Frida工具(例如,从Terminal.app),则会通过 taskgate 提示你授权该过程。你可能还需要禁用系统完整性保护。
Objective-C 基础知识
import frida
import sys
def on_message(message, data):
print("[{}] => {}".format(message, data))
def main(target_process):
session = frida.attach(target_process)
script = session.create_script("""
const appWillFinishLaunching = ObjC.classes.NSApplicationDelegate['- applicationWillFinishLaunching:'];
Interceptor.attach(appWillFinishLaunching.implementation, {
onEnter(args) {
// As this is an Objective-C method, the arguments are as follows:
// 0. 'self'
// 1. The selector (applicationWillFinishLaunching:)
// 2. The first argument to this method
const notification = new ObjC.Object(args[2]);
// Convert it to a JS string and log it
const notificationStr = notification.absoluteString().toString();
console.log('Will finish launching with notification: ' + notificationStr);
}
});
""")
script.on("message", on_message)
script.load()
print("[!] Ctrl+D or Ctrl+Z to detach from instrumented program.\n\n")
sys.stdin.read()
session.detach()
if __name__ == "__main__":
main("Safari")Linux 上使用 Frida
略。。。
Frida CLI
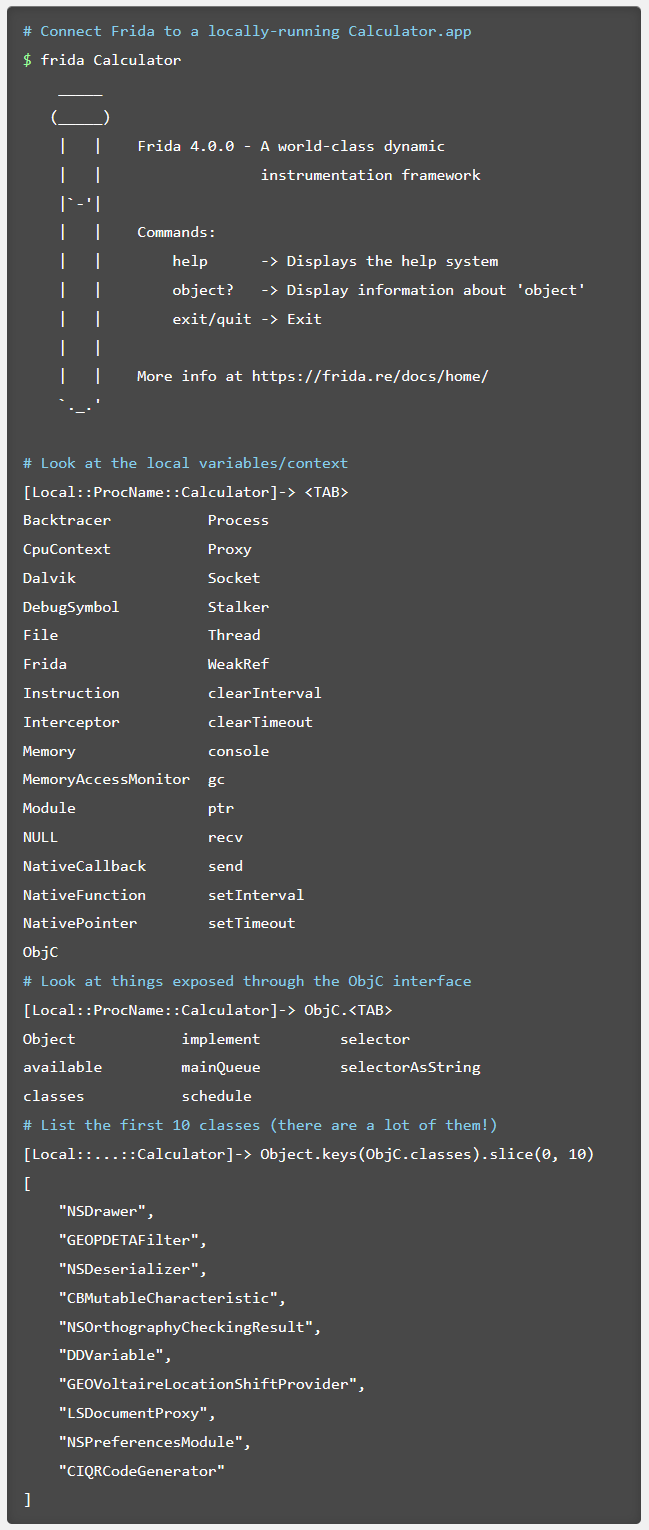
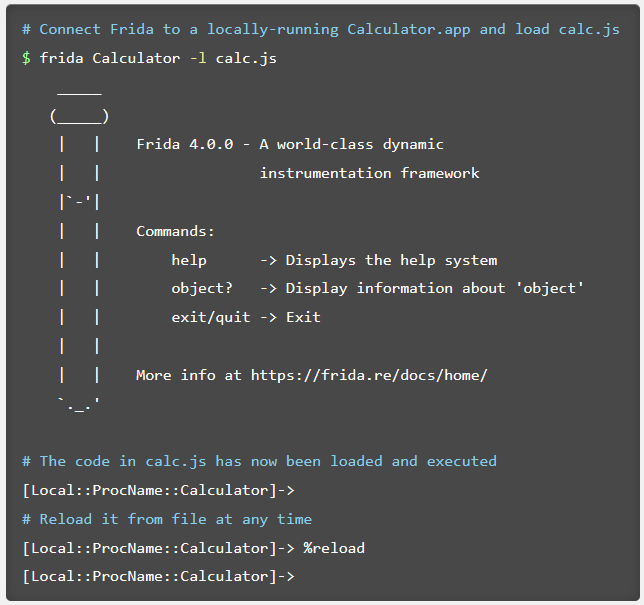
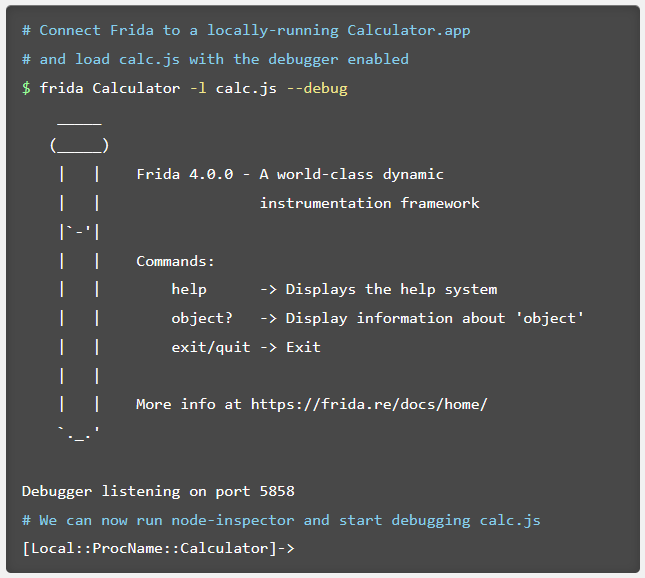
Frida CLI 是一个 REPL ( "读取-求值-输出" 循环,英语:Read-Eval-Print Loop,简称REPL ) 接口,旨在模仿 IPython(或Cycript)的许多优秀功能,试图实现快速原型设计和轻松调试。
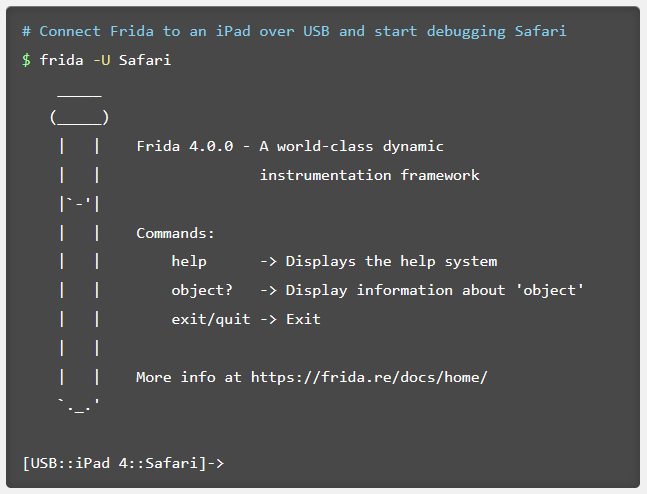
示例 会话
加载 脚本
以 调试模式 启动
frida-ps
命令行工具,用于列出进程,在与远程系统交互时非常有用。
# Connect Frida to an iPad over USB and list running processes
$ frida-ps -U
# List running applications
$ frida-ps -Ua
# List installed applications
$ frida-ps -Uai
# Connect Frida to the specific device
$ frida-ps -D 0216027d1d6d3a03frida-ls-devices
用于列出连接的设备,在与多个设备交互时非常有用。
frida-trace
frida-trace 是一个动态 跟踪 函数调用 的工具。
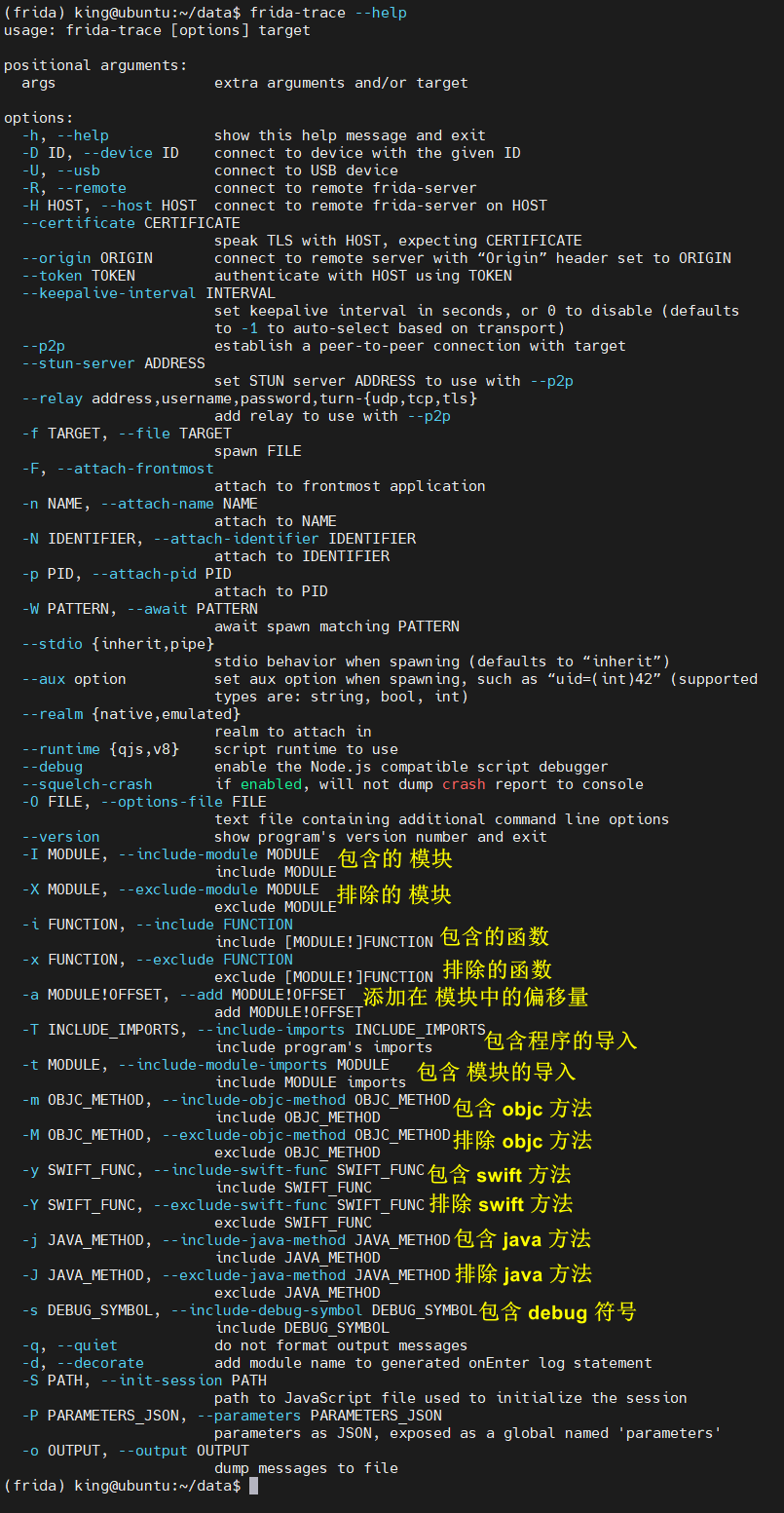
- -U,-usb:连接到USB设备。此选项告知frida-trace对通过主机的USB连接连接的远程设备执行跟踪。
- -O:通过文本文件传递命令行选项。使用此选项,您可以通过一个或多个文本文件传递任意数量的命令行选项。文本文件中的选项可以在一行或多行上,每行包含任意数量的选项,包括其他
-O命令选项。此功能对于处理大量命令行选项非常有用,并解决了命令行超过操作系统最大命令行长度时的问题。 - -I,-X:包含/排除模块。这些选项允许您在一个选项中包含或排除特定模块中的所有函数(例如,*.so,*.dll)在一个单一的选项中。该选项需要一个文件名glob来匹配一个或多个模块。任何与glob模式匹配的模块都将被完整地包含或排除。
frida-trace将为-I选项匹配的每个函数生成一个JavaScript处理程序文件。-
-a:包含函数(基于偏移)
-
-P:使用全局可访问的JSON对象初始化frida-trace会话
-
-S:使用JavaScript代码初始化frida-trace会话
-
-d,-decorate:将模块名称添加到日志跟踪
示例:frida-trace -p 9753 --decorate -O additional-options.txt
其中 additional-options.txt 是
-i "gdi32full.dll!ExtTextOutW"
-S core.js -S ms-windows.js
-O module-offset-options.txt而 module-offset-options.txt 是:
-a "gdi32full.dll!0x3918DC" -a "gdi32full.dll!0xBE7458"
-a "gdi32full.dll!0xBF9904"
示例:
# Trace recv* and send* APIs in Safari, insert library names
# in logging
$ frida-trace --decorate -i "recv*" -i "send*" Safari
# Trace ObjC method calls in Safari
$ frida-trace -m "-[NSView drawRect:]" Safari
# Launch SnapChat on your iPhone and trace crypto API calls
$ frida-trace \
-U \
-f com.toyopagroup.picaboo \
-I "libcommonCrypto*"
# Launch YouTube on your Android device and trace Java methods
# with “certificate” in their signature (s), ignoring case (i)
# and only searching in user-defined classes (u)
$ frida-trace \
-U \
-f com.google.android.youtube \
--runtime=v8 \
-j '*!*certificate*/isu'
# Trace all JNI functions in Samsung FaceService app on Android
$ frida-trace -U -i "Java_*" com.samsung.faceservice
# Trace a Windows process's calls to "mem*" functions in msvcrt.dll
$ frida-trace -p 1372 -i "msvcrt.dll!*mem*"
# Trace all functions matching "*open*" in the process except
# in msvcrt.dll
$ frida-trace -p 1372 -i "*open*" -x "msvcrt.dll!*open*"
# Trace an unexported function in libjpeg.so
$ frida-trace -p 1372 -a "libjpeg.so!0x4793c"frida-discover
用于发现程序中的内部函数的工具,然后可以使用 frida-trace 进行跟踪。
frida-kill
用于杀死进程的命令行工具。可以从frida-ps工具获取PID。
frida-kill -D <DEVICE-ID> <PID>
gum-graft
gum-graft工具用于提前修补二进制文件,以允许Interceptor在禁止修改运行时代码的环境中对其进行检测。目前,这只适用于采用严格代码签名策略的苹果移动操作系统,即在没有附加调试器的情况下运行应用程序的监禁系统。在这种情况下,覆盖Gadget code_signing选项并将其设置为required。下载: https://github.com/frida/frida/releases
2、JavaScript API
强烈建议使用 TypeScript 进行开发。TypeScript 是由微软开发的自由和开源的编程语言,它是 JavaScript 的一个超集,扩展了 JavaScript 的语法。TypeScript 建立在 JavaScript 之上。TypeScript 编译器会将 TypeScript 代码编译为纯 JavaScript 代码,然后就可以部署到任何 JavaScript 环境中。TypeScript 文件的扩展是 .ts ,而不是 JavaScript 文件的 .js 扩展名。TypeScript 使用 JavaScript 语法,并添加了额外的语法来支持类型。如果编写的 JavaScript 程序没有任何语法错误,那么,它也是一个 TypeScript 程序。这意味着所有的 JavaScript 程序都是 TypeScript 程序。
TypeScript 和 JavaScript 区别
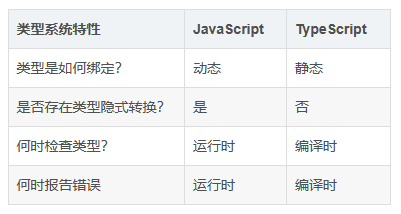
类型绑定
- JavaScript:
JavaScript动态绑定类型,只有运行程序才能知道类型,在程序运行之前JavaScript对类型一无所知- TypeScript:
TypeScript是在程序运行前(也就是编译时)就会知道当前是什么类型。当然如果该变量没有定义类型,那么TypeScript会自动类型推导出来。
- JavaScript:比如在
JavaScript中1 + true这样一个代码片段,JavaScript存在隐式转换,这时true会变成number类型number(true)和1相加。- TypeScript:在
TypeScript中,1+true这样的代码会在TypeScript中报错,提示number类型不能和boolean类型进行运算。
- JavaScript:在
JavaScript中只有在程序运行时才能检查类型。类型也会存在隐式转换,很坑。- TypeScript:在
TypeScript中,在编译时就会检查类型,如果和预期的类型不符合直接会在编辑器里报错、爆红
- JavaScript:在
JavaScript只有在程序执行时才能抛出异常,JavaScript存在隐式转换,等我们程序执行时才能真正的知道代码类型是否是预期的类型,代码是不是有效。- TypeScript:在
TypeScript中,当你在编辑器写代码时,如有错误则会直接抛出异常,极大得提高了效率,也是方便。
运行时 信息
- Frida
- Script
- Frida.version:包含当前Frida版本的属性,字符串。
- Frida.heapSize :动态属性,包含当前 Frida 私有堆的大小,被所有脚本和Frida自己的运行时共享。这对于检测使用了多少宿主进程的内存非常有用。
- Script.runtime :正在使用运行时的字符串属性。 QJS 或 V8
- Script.pin() :暂时阻止当前脚本被卸载。但是在后面必须有一个匹配的 unpin(),通常需要在另一个线程上调度清理时在bindWeak() 的回调中使用。
- Script.unpin():反转前一个pin(),以便可以卸载当前脚本。
- Script.bindWeak(value, fn) :监视 value ,并在 value 被垃圾收集或脚本即将卸载时立即调用 fn 。返回一个ID,可以将其传递给 Script.unbindWeak() 进行显式清理。
- Script.unbindWeak(id) :停止监视传递给 Script.bindWeak(value, fn) 的值,并立即调用 fn 。
- Script.setGlobalAccessHandler(handler | null) :安装或卸载一个处理程序,用于解决访问不存在的全局变量的情况。这对于实现一个REPL很有用。
handler 是一个包含两个属性的对象
enumerate() :查询存在哪些额外的全局变量。必须返回字符串数组。
get(property) :获取给定属性的值。
Process、Thread、Module、Memory
- Thread
- Process
- Module
- ModuleMap
- Memory
- MemoryAccessMonitor
- CModule
- ApiResolver
- DebugSymbol
- Kernel
Process 进程
表示当前被附加的进程,而不是所有进程。
- Process.id :数字类型的属性,返回 pid
- Process.arch :字符串类型属性,返回 ia32 、 x64 、 arm 或 arm64
- Process.platform :字符串类型属性,返回 windows 、 darwin 、 linux 或 qnx
- Process.pageSize :属性,虚拟内存页面大小(以字节为单位)
- Process.pointerSize :属性,指针大小(以字节为单位)
- Process.codeSigningPolicy:字符串类型的属性,optional或required,后者意味着Frida将避免修改内存中的现有代码,并且不会尝试运行无符号代码。目前,除非您使用Gadget并将其配置为假设需要代码签名,否则此属性将始终设置为可选。此属性允许您确定拦截器API是否禁用,以及修改代码或运行无符号代码是否安全。
- Process.mainModule :包含一个 Module 的属性,表示进程的主要可执行文件
- Process.getCurrentDir() :返回一个字符串,指定当前工作目录的文件系统路径
- Process.getHomeDir() :返回一个字符串,指定当前用户主目录的文件系统路径
- Process.getTmpDir() :返回一个字符串,指定用于临时文件的目录的文件系统路径
- Process.isDebuggerAttached() :返回一个布尔值,指示当前是否连接了调试器
- Process.getCurrentThreadId() :获取此线程的操作系统特定的ID作为一个数字
- Process.enumerateThreads() :枚举所有线程,返回包含以下属性的对象数组:
id :操作系统特定ID
state :指定 running 、 stopped 、 waiting 、 uninterruptible 或 halted 的字符串
context: :对于ia32/x64/arm,使用pc和sp为NativePointer对象,分别指定EIP/RIP/ pc和ESP/RSP/ sp。其他特定于处理器的键也可用,例如eax、rax、r0、x0等。- Process.findModuleByAddress(address),
Process.getModuleByAddress(address),
Process.findModuleByName(name),
Process.getModuleByName(name):查找与指定的地址或名称匹配的模块,返回值是一个地址或名称。如果找不到这样的模块,find-prefixed函数返回null,而get-prefixed函数抛出异常。- Process.enumerateModules() :枚举当前被附加的进程的所有模块(也就是动态链接库或可执行文件)的信息。然后返回 Module对象数组。它只和当前注入的进程相关,而不是所有进程。通过这个函数可以获取载入内存的模块的列表,包括模块的名称、基址、大小等信息。
- Process.findRangeByAddress(address) , getRangeByAddress(address) :查找包含地址范围的详细信息。返回一个对象。如果找不到这样的范围,findRangeByAddress()返回null,而getRangeByAddress()抛出异常。有关包含哪些字段的详细信息,请参见 Process.enumerateRanges() 。
- Process.enumerateRanges(protection|specifier) :枚举满足给定保护的内存范围,该保护以字符串形式表示:rwx,其中rw-表示“至少可读写”。返回一个包含以下属性的对象数组:
base :基址作为 NativePointer
size :大小(字节)
protection :保护字符串
file :(可用时)文件映射详细信息作为对象,包含:
path :完整的文件系统路径作为字符串
offset :磁盘上映射文件的偏移量,以字节为单位
size :磁盘上映射文件的大小,以字节为单位- Process.enumerateMallocRanges() :就像 enumerateRanges() 一样,但是用于系统单个内存分配的堆。
- Process.setExceptionHandler(callback) :安装一个进程范围的异常处理回调,让它有机会在宿主进程本身之前处理本机异常。
Thread 线程
- Thread.backtrace([context, backtracer]) :返回当前线程的调用堆栈。这通常在调试或分析应用程序行为时非常有用,可以让你知道在特定时刻哪些函数被调用,以及它们的调用顺序。这个追踪包含了一系列的栈帧,每个栈帧代表着调用栈中的一个函数调用。总结:为当前线程生成一个 backtracer (回溯),返回值是一个 NativePointer 对象数组。
如果你从Interceptor的 onEnter 或 onLeave 回调函数中调用它,你应该为可选的 context 参数提供 this.context ,因为它会给你一个更准确的回溯给予。省略 context 意味着回溯将从当前堆栈位置生成,由于JavaScript VM的堆栈帧,这可能不会给予很好的回溯。可选的 backtracer 参数指定要使用的回溯器的类型,并且必须是 Backtracer.FUZZY 或 Backtracer.ACCURATE ,如果没有指定,后者是默认值。准确的回溯程序依赖于调试器友好的二进制文件或调试信息的存在来做好工作,而模糊回溯程序对堆栈执行取证以猜测返回地址,这意味着你会得到误报,但它可以在任何二进制文件上工作。生成的回溯当前限制为16帧,并且在不重新编译Frida的情况下不可调整。const f = Module.getExportByName('libcommonCrypto.dylib', 'CCCryptorCreate'); Interceptor.attach(f, { onEnter(args) { console.log('CCCryptorCreate called from:\n' + Thread.backtrace(this.context, Backtracer.ACCURATE) .map(DebugSymbol.fromAddress).join('\n') + '\n'); } });
- Thread.sleep(delay) :将当前线程挂起 delay 秒后再恢复执行。
Module 模块
由 Module.load(path) 和 Process.enumerateModules() 等返回的对象。在 Frida 中,Module是指进程加载到进程地址空间中的模块。一个模块通常代表一个动态链接库(如 DLL 文件在 Windows 上,或 SO 文件在 Linux 和 Android 上),或者可执行文件本身。Module 提供了对这些模块的各种操作和信息,包括:
- 模块的名称。
- 模块的基地址,即模块在进程内存空间中的起始地址。
- 导出表,列出模块导出的函数和变量。
- 寻找特定符号的地址,例如函数或全局变量。
- 枚举模块中的所有符号。
- 等等。
通过使用 Frida 的 Module 相关功能,可以在运行时探查和操作应用程序的模块,这对于逆向工程和动态分析特别有用。
name :规范模块名称作为字符串
base :基址。是NativePointer类型
size :大小(字节)
path :完整的文件系统路径作为字符串
- enumerateImports() :枚举 模块的 导入表,返回包含以下属性的对象数组:
type :字符串,function 或 variable
name :字符串,导入名
module :字符串,模块名
address :NativePointer,绝对地址
slot :NativePointer,导入名在内存的存储位置 - enumerateExports() :枚举 模块的 导出表,返回包含以下属性的对象数组:
type :字符串,function 或 variable
name :字符串,导入名
address :NativePointer,绝对地址 - enumerateSymbols() :枚举模块的符号,返回包含以下属性的对象数组:
isGlobal :boolean,指定符号是否全局可见
type :字符串,类型
name :字符串,符号名
address :NativePointer,绝对地址
size :如果存在,指定符号大小(以字节为单位)的数字 - enumerateRanges(protection) :类似 Process.enumerateRanges,但是它的作用域是模块。
- enumerateSections() :枚举模块的Sections,返回包含以下属性的对象数组:
id :字符串,使用包含"节索引、段名称、节名称"作为id
name :字符串,节名
address :NativePointer,绝对地址
size :大小(字节) - enumerateDependencies() :枚举模块的依赖项,返回包含以下属性的对象数组:
name :字符串,模块名
type :字符串,取值为:regular、weak、reexport、upward - findExportByName(exportName), getExportByName(exportName):返回名为 exportName 的导出函数的绝对地址。如果找不到这样的导出函数,find-prefixed 函数将返回null,而 get-prefixed 函数将抛出异常。
- Module.load(path) :从文件系统路径加载指定的模块,并返回 Module 对象。如果无法加载指定的模块,则引发异常。
- Module.ensureInitialized(name) :确保指定模块的初始化已经运行。这在早期插装过程中很重要,即在进程生命周期的早期运行代码,以便能够安全地与API交互。
- Module.findBaseAddress(name), Module.getBaseAddress(name):返回 name 模块的基址。如果找不到这样的模块,find-prefixed函数将返回null,而get-prefixed函数将抛出异常。
- Module.findExportByName(moduleName|null, exportName), Module.getExportByName(moduleName|null, exportName):返回 moduleName 中名为 exportName 的导出函数的绝对地址。如果模块未知,可以传递 null 搜索所有模块,但是会导致搜索效率变慢。如果找不到这样的模块或导出,find-prefixed 函数将返回 null,而 get-prefixed 函数将抛出异常。
- new ModuleMap([filter]) :创建一个新的模块映射,这个映射为确定给定内存地址属于哪个模块(如果有的话)而优化。在创建时,它会捕获当前加载的模块的快照,这个快照可以通过调用 update() 来刷新。filter 参数是可选的,它允许你传递一个用于过滤模块列表的函数。如果你只关心应用程序本身所拥有的模块,这会很有用,并且允许你快速检查一个地址是否属于其模块之一。过滤函数接收一个 Module 对象,并且对于应该保留在映射中的每个模块都必须返回 true。每次更新映射时,都会为每个加载的模块调用这个函数。
- has(address) :检查 address 是否属于所包含的任何模块,返回 boolean
- find(address) , get(address) :返回一个Module,包含 address 所属模块的详细信息。如果找不到这样的模块, find() 返回 null ,而 get() 抛出异常。
- findName(address) 、 getName(address) 、 findPath(address) 、 getPath(address) :就像 find() 和 get() 一样,但只返回 name 或 path 字段,当你不需要其他细节时,开销更少。
- update() :更新 映射(map)。应该在加载或卸载模块后调用此函数,以避免对过时数据进行操作。
- values() :返回一个数组,其中包含当前在map中的Module对象。返回的数组是一个深度副本,在调用 update() 后不会发生变化。
Memory 内存
- Memory.scan(address, size, pattern, callbacks) :在指定内存范围内扫描搜索特定模式的数据。这对于在应用程序的内存空间中查找特定的字符串、函数签名、加密密钥等非常有用。 address 表示开始地址,大小为 size 的内存范围内出现是否有匹配的 pattern 。
pattern 匹配条件
callbacks 回调对象,具有以下属性
onMatch(address, size) 当匹配到时调用,把匹配到的address作为NativePointer
onError(reason) 扫描时出现内存访问错误时调用
onComplete() 指定内存范围扫描完成时调用 - Memory.scanSync(address, size, pattern) : scan() 的同步版本,返回包含以下属性的对象数组:
address :绝对地址为 NativePointer
size :大小(以字节为单位)
// 查找程序自身的模块, 这里定位到 0:
const m = Process.enumerateModules()[0];
// 或者通过 name 导入模块
//const m = Module.load('win32u.dll');
// 打印模块的属性
console.log(JSON.stringify(m));
// 从模块的 base address 开始进行 dump
console.log(hexdump(m.base));
// 匹配的 pattern :
const pattern = '00 00 00 00 ?? 13 37 ?? 42';
Memory.scan(m.base, m.size, pattern, {
onMatch(address, size) {
console.log('Memory.scan() found match at', address, 'with size', size);
// Optionally stop scanning early:
return 'stop';
},
onComplete() {
console.log('Memory.scan() complete');
}
});
const results = Memory.scanSync(m.base, m.size, pattern);
console.log('Memory.scanSync() result:\n' + JSON.stringify(results));- Memory.alloc(size[, options]) :在堆上分配 size 大小字节数内存空间。或者,如果
size是Process.pageSize的倍数,则由操作系统管理的一个或多个原始内存页。使用页面粒度时,如果需要在给定地址附近分配内存,也可以指定options对象{ near: address, maxDistance: distanceInBytes },方法是指定 。返回的值为 aNativePointer,当所有 JavaScript 句柄都消失时,将释放底层内存。这意味着,当 JavaScript 运行时外部的代码使用指针时,您需要保留对指针的引用。 - Memory.copy(dst, src, n) :就像 memcpy() 一样。不返回任何内容。
DST: NativePointer 指定目标基址。
src: NativePointer 指定源基址。
n:要复制的大小(以字节为单位)。 - Memory.dup(address, size):当 Memory.alloc() 后立刻执行 Memory.copy() 时,可以简写为 Memory.dup。返回一个包含新分配内存的基地址的 NativePointer。有关内存分配生命周期的详细信息,请参阅 Memory.copy()。
- Memory.protect(address, size, protection) :更新内存区域上的保护,其中 protection 是格式相同的 Process.enumerateRanges() 字符串。返回一个布尔值,指示操作是否成功完成。
示例:Memory.protect(ptr('0x1234'), 4096, 'rw-'); - Memory.patchCode(address, size, apply) :安全的修改开始地址是 address 大小为 size 的内存空间。address 是一个 NativePointer。提供的 JavaScript 函数 apply 将使用一个可写指针调用,您必须在返回之前将所需的修改写入其中。不要假设这与地址相同,因为一些系统要求修改必须先写入临时位置,然后再映射到原始内存页面上(例如,在 iOS 上,直接修改内存中的代码可能导致进程失去其 CS_VALID 状态)。
const getLivesLeft = Module.getExportByName('game-engine.so', 'get_lives_left');
const maxPatchSize = 64; // Do not write out of bounds, may be a temporary buffer!
Memory.patchCode(getLivesLeft, maxPatchSize, code => {
const cw = new X86Writer(code, { pc: getLivesLeft });
cw.putMovRegU32('eax', 9000);
cw.putRet();
cw.flush();
});- Memory.allocUtf8String(str) 、 Memory.allocUtf16String(str) 、 Memory.allocAnsiString(str) : 在堆上分配、编码和写出 str 为 UTF-8/UTF-16/ANSI 字符串。返回的对象是 NativePointer 。有关其生命周期的详细信息,请参阅 Memory.alloc() 。
MemoryAccessMonitor
- MemoryAccessMonitor.enable(ranges, callbacks) :监视一个或多个内存范围的访问,并在首次访问每个包含的内存页时通知。 ranges 是单个范围对象或此类对象的数组,每个对象包含:
base :基址作为 NativePointer
size :大小(以字节为单位)
callbacks 一个回调对象 - MemoryAccessMonitor.disable() :停止监视
CModule
new CModule(code[, symbols, options]):从提供的code创建一个新的 C 模块,可以是包含要编译的 C 源代码的字符串,也可以是包含预编译共享库的 ArrayBuffer。C 模块被映射到内存中,并完全可供 JavaScript 访问。全局函数会自动导出为 NativePointer 属性,其命名方式与 C 源代码中的名称完全相同。这意味着您可以将它们传递给 Interceptor 和 Stalker,或者使用 NativePointer 调用它们。除了访问 Gum、GLib 和标准 C API 的精选子集外,映射的代码还可以通过symbols公开的代码与 JavaScript 进行通信。这是可选的第二个参数,该对象指定其他符号名称及其 NativePointer 值,每个值都将在创建时插入。例如,这可能是使用 Memory.alloc() 和/或 NativeCallback 值分配的一个或多个内存块,用于接收来自 C 模块的回调。若要执行初始化和清理,可以使用以下名称和签名定义函数:void init (void)、void finalize (void)。注意,所有数据都是只读的,因此应将可写全局变量声明为 extern,使用 Memory.alloc() 等方式进行分配,并通过构造函数的第二个参数作为符号传入。可选的第三个参数options,是一个对象,可用于指定要使用的工具链,例如:{ toolchain: 'external' }dispose():从内存中取消模块映射。builtins:一个对象,指定从 C 源代码构造 CModule 时存在的内置项。这通常由基架工具使用,
const cm = new CModule(`
#include <stdio.h>
void hello(void) {
printf("Hello World from CModule\\n");
}
`);
console.log(JSON.stringify(cm));
const hello = new NativeFunction(cm.hello, 'void', []);
hello();执行命令:frida -p 0 -l example.js
对于原型设计,建议使用 Frida REPL 的内置 CModule 支持:frida -p 0 -C example.c ,可以添加 -l example.js 加载一些 JavaScript 。JavaScript 代码可以使用命名 cm 的全局变量来访问 CModule 对象,但只能在调用之后 rpc.exports.init() ,因此请根据那里的 CModule 执行任何初始化。您也可以通过赋值给名为 cs 的全局对象来注入符号,但这必须在调用之前 rpc.exports.init() 完成。
ApiResolver
new ApiResolver(type):创建一个给定type的新解析器,允许按名称快速查找 API,并允许使用 glob。确切地说,哪些解析器可用取决于当前平台和当前进程中加载的运行时。解析程序将加载创建时所需的最小数据量,并根据接收的查询延迟加载其余数据。目前可用的解释器包括:
module :解析模块导出、导入和部分。
swift :解析 Swift 函数。在加载了Swift的进程中可用。使用 Swift.available 检查Swift是否可用,或将 new ApiResolver('swift') 调用包装在 try-catch。
objc :解析 Objective-C 方法。在加载了Objective-C的进程中,在 macOS 和 iOS 上可用。使用 ObjC.available 检查ObjC是否可用,或将 new ApiResolver('objc') 调用包装在 try-catch。- enumerateMatches(query) :执行特定 query 于解析程序的字符串(可选后缀为 /i 以执行不区分大小写的匹配),返回包含以下属性的对象数组:
name :找到的 API 的名称
address :地址为 NativePointer
size :如果存在,则指定大小(以字节为单位)的数字
const resolver = new ApiResolver('module');
const matches = resolver.enumerateMatches('exports:*!open*');
const first = matches[0];
/*
* Where `first` is an object similar to:
*
* {
* name: '/usr/lib/libSystem.B.dylib!opendir$INODE64',
* address: ptr('0x7fff870135c9')
* }
*/
const resolver = new ApiResolver('module');
const matches = resolver.enumerateMatches('sections:*!*text*');
const first = matches[0];
/*
* Where `first` is an object similar to:
*
* {
* name: '/usr/lib/libSystem.B.dylib!0.__TEXT.__text',
* address: ptr('0x191c1e504'),
* size: 1528
* }
*/
const resolver = new ApiResolver('swift');
const matches = resolver.enumerateMatches('functions:*CoreDevice!*RemoteDevice*');
const first = matches[0];
/*
* Where `first` is an object similar to:
*
* {
* name: '/Library/Developer/PrivateFrameworks/CoreDevice.framework/Versions/A/CoreDevice!dispatch thunk of CoreDevice.RemoteDevice.addDeviceInfoChanged(on: __C.OS_dispatch_queue?, handler: (Foundation.UUID, CoreDeviceProtocols.DeviceInfo) -> ()) -> CoreDevice.Invalidatable',
* address: ptr('0x1078c3570')
* }
*/
const resolver = new ApiResolver('objc');
const matches = resolver.enumerateMatches('-[NSURL* *HTTP*]');
const first = matches[0];
/*
* Where `first` is an object similar to:
*
* {
* name: '-[NSURLRequest valueForHTTPHeaderField:]',
* address: ptr('0x7fff94183e22')
* }
*/DebugSymbol
调试符号。
- DebugSymbol.fromAddress(address)、DebugSymbol.fromName(name):查找 name / address 的调试信息, 返回包含以下内容的对象:
address :此符号所针对的地址,作为 NativePointer
name :符号的名称,以字符串形式表示,如果未知,则为 null。
moduleName :拥有此符号的模块名称,为字符串,如果未知,则为 null。
fileName :拥有此符号的文件名,为字符串,如果未知,则为 null。
lineNumber :行号 中 fileName ,为数字,如果未知,则为 null。
组合使用 toString() 和 Thread.backtrace() 非常有用:
const f = Module.getExportByName('libcommonCrypto.dylib', 'CCCryptorCreate');
Interceptor.attach(f, {
onEnter(args) {
console.log('CCCryptorCreate called from:\n' +
Thread.backtrace(this.context, Backtracer.ACCURATE)
.map(DebugSymbol.fromAddress).join('\n') + '\n');
}
});DebugSymbol.getFunctionByName(name):解析函数名称并将其地址返回为NativePointer.如果找到多个函数,则返回第一个函数。如果无法解析名称,则引发异常。DebugSymbol.findFunctionsNamed(name):解析函数名称并将其地址作为NativePointer对象数组返回。DebugSymbol.findFunctionsMatching(glob):解析匹配glob的函数名称,并将其地址作为NativePointer对象数组返回。DebugSymbol.load(path):加载特定模块的调试符号。
Kernel
Kernel.available:指定内核 API 是否可用。如果不可用则不要调用Kernel属性或方法。Kernel.base:内核的基址,作为 UInt64。Kernel.pageSize:内核页面的大小(以字节为单位),以数字表示。Kernel.enumerateModules():枚举当前加载的内核模块,返回包含以下属性的对象数组:
name :字符串形式的规范模块名称
base :基址作为 NativePointer
size :大小(以字节为单位)Kernel.enumerateRanges(protection|specifier): 枚举内核内存范围,protection格式为以下形式的字符串:rwx,其中rw-表示“必须至少是可读和可写的”。或者,可以为specifier对象提供一个protection键,其值如上所述,true如果您希望合并具有相同保护的相邻范围,则可以将coalesce键设置为(默认值为false;即保持范围分开)。返回包含以下属性的对象数组:
base :基址作为 NativePointer
size :大小(以字节为单位)
protection :保护字符串Kernel.enumerateModuleRanges(name, protection):类似Kernel.enumerateRanges,只是它的范围限定为指定的模块name——这可能是null针对内核本身的模块。每个范围还有一个name字段,其中包含字符串形式的唯一标识符。Kernel.alloc(size):分配size大小字节数的内核内存,四舍五入为内核页面大小的倍数。返回的值是UInt64指定分配的基址。Kernel.protect(address, size, protection):更新内核内存区域上的保护,其中protection是与Kernel.enumerateRanges()格式相同的字符串。示例:Kernel.protect(UInt64('0x1234'), 4096, 'rw-');Kernel.readByteArray(address, length):就像NativePointer#readByteArray一样,但从内核内存中读取。Kernel.writeByteArray(address, bytes):就像NativePointer#writeByteArray一样,但写入内核内存。Kernel.scan(address, size, pattern, callbacks):就像Memory.scan一样,但扫描内核内存。Kernel.scanSync(address, size, pattern):scan()的同步版本,返回数组中的匹配项。
数据类型、函数、回调
- Int64
- UInt64
- NativePointer
- ArrayBuffer
- NativeFunction
- NativeCallback
- SystemFunction
int64(v): 等价于 new Int64(v)
uint64(v): 等价于 new UInt64(v)
ptr(s): 等价于 new NativePointer(s)
NULL: 等价于 ptr("0")
Int64
new Int64(v):从v创建一个新的 Int64,v是数字或字符串,其中包含十进制值,如果前缀为“0x”,则为十六进制。为了简洁起见,可以使用简写int64(v)add(rhs),sub(rhs),and(rhs),or(rhs),xor(rhs):用这个Int64 "加 / 减 / 与 / 或 / xor"rhs创建一个新的 Int64,rhs 可以是一个数字,也可以是另一个 Int64shr(n),shl(n): 创建一个新的 Int64,将这个 Int64 向右/向左 移动 n 位compare(rhs):返回一个整数比较结果,就像 String#localeCompare() 一样toNumber():将此 Int64 转换为一个数字toString([radix = 10]):转换为可选基数的字符串(默认为 10)
UInt64
new UInt64(v):从v创建一个新的 UInt64,v 是一个数字或字符串,其中包含十进制值,如果前缀为“0x”,则为十六进制。为了简洁起见,可以简写为uint64(v)add(rhs)、sub(rhs)、and(rhs)、or(rhs)、xor(rhs):compare(rhs):返回一个整数比较结果,就像 String#localeCompare() 一样toNumber():将此 UInt64 转换为一个数字toString([radix = 10]):转换为可选基数的字符串(默认为 10)
NativePointer (指针)
new NativePointer(s):从包含十进制或十六进制内存地址(如果前缀为“0x”)的字符串s创建新的 NativePointer。为了简洁起见,可以使用简写ptr(s)isNull():返回一个布尔值,检查指针是否为 NULLadd(rhs)、sub(rhs)、and(rhs)、or(rhs)、xor(rhs):shr(n),shl(n): 创建一个新的 NativePointer,这个 NativePointer 向右/向左 移动 n 位not():创建一个新的 NativePointer,并将此 NativePointer 的位反转sign([key, data]):通过获取此 NativePointer 的位并添加指针身份验证位,创建签名指针来创建新的 NativePointer。如果当前进程不支持指针身份验证,则此操作将返回此 NativePointer 而不是新值。data参数还可以指定为 NativePointer/类似数字的值,以提供用于签名的额外数据,默认为0。
(可选) key 可以指定为字符串。支持的值为:
ia:IA 密钥,用于对代码指针进行签名。这是默认设置。
ib:IB 密钥,用于对代码指针进行签名。
da:DA 键,用于对数据指针进行签名。
db:DB 键,用于对数据指针进行签名。strip([key]):通过获取此 NativePointer 的位并删除其指针身份验证位,创建原始指针来创建新的 NativePointer。如果当前进程不支持指针身份验证,则此操作将返回此 NativePointer 而不是新值。可选)key可以传递以指定用于对被剥离的指针进行签名的密钥。默认值为ia。(有关支持的值,请参阅sign()。blend(smallInteger):通过获取此 NativePointer 的位并将它们与常量混合来创建一个新的 NativePointer,该常量又可以sign()传递给data.equals(rhs):返回一个布尔值,指示是否rhs等于此值;即它具有相同的指针值compare(rhs):返回一个整数比较结果,就像 String#localeCompare() 一样toInt32():将此 NativePointer 转换为有符号的 32 位整数toString([radix = 16]):转换为可选基数的字符串(默认为 16)toMatchPattern():返回一个字符串,其中包含此指针的原始值的匹配模式readPointer():从此内存位置读取一个NativePointer。如果地址不可读,则会引发 JavaScript 异常。writePointer(ptr):写ptr到此内存位置。如果地址不可写,则会引发 JavaScript 异常。readS8(),readU8(),readS16(),readU16(),readS32(),readU32(),readShort(),readUShort(),readInt(),readUInt(),readFloat(),readDouble():从该内存位置读取一个有符号或无符号的8/16/32等整数或浮点/双精度值,并将其作为数字返回。如果地址不可读,则会引发 JavaScript 异常。writeS8(value),writeU8(value),writeS16(value),writeU16(value),writeS32(value),writeU32(value),writeShort(value),writeUShort(value),writeInt(value),writeUInt(value),writeFloat(value),writeDouble(value):向该内存位置写入一个有符号或无符号的8/16/32等整数或浮点/双精度值。如果地址不可读,则会引发 JavaScript 异常。readS64(),readU64(),readLong(),readULong():从此内存位置读取有符号或无符号的64 位值,并将其作为 Int64/UInt64 值返回。如果地址不可读,则会引发 JavaScript 异常。writeS64(value),writeU64(value),writeLong(value),writeULong(value): 将 Int64/ UInt64 写value入此内存位置。如果地址不可写,则会引发 JavaScript 异常。readByteArray(length):从此内存位置读取length字节,并将其作为 ArrayBuffer 返回。通过将此缓冲区作为第二个参数传递给send(),可以有效地将其传输到基于 Frida 的应用程序。如果写入地址的任何字节不可写,则会引发 JavaScript 异常。writeByteArray(bytes):写bytes入此内存位置,其中bytes是 ArrayBuffer(通常从readByteArray()返回)或介于 0 和 255 之间的整数数组。例如:[ 0x13, 0x37, 0x42 ].如果写入地址的任何字节不可写,则会引发 JavaScript 异常。readCString([size = -1]),readUtf8String([size = -1]),readUtf16String([length = -1]),readAnsiString([size = -1]):以 ASCII、UTF-8、UTF-16 或 ANSI 字符串的形式读取此内存位置的字节。如果您知道字符串的大小(以字节为单位),请提供可选size参数,如果字符串以 NUL 结尾,请省略该参数或指定 -1。同样,如果您知道字符串的长度(以字符为单位),则可以提供可选length参数。如果从地址读取的任何size/length字节不可读,则会引发 JavaScript 异常。注意:readAnsiString()仅在 Windows 上可用writeUtf8String(str),writeUtf16String(str),writeAnsiString(str): 对 JavaScript 字符串进行编码并将其写入此内存位置(使用 NUL-terminator)。如果写入地址的任何字节不可写,则会引发 JavaScript 异常。注意:writeAnsiString()仅在 Windows 上可用
ArrayBuffer
数组缓冲区。在Frida中,ArrayBuffer的wrap和unwrap方法用于在JavaScript和本机代码之间进行ArrayBuffer对象和内存指针之间的转换。通过使用wrap和unwrap方法,可以在JavaScript和本机代码之间轻松地进行ArrayBuffer对象和本机指针之间的转换,从而实现二进制数据的高效传递。
wrap(address, size):在内存中创建 ArrayBuffer。用于将本机指针转换为ArrayBuffer对象。它接受一个指向内存块的本机指针,并返回一个ArrayBuffer对象,该对象将该内存块包装在其内部。这个方法通常用于从本机函数中获取二进制数据,然后在JavaScript端使用。其中address是一个NativePointer本机指针,指向要包装的内存块。size要包装的内存块的大小(以字节为单位)。与NativePointer读/写 API 不同,不会对访问执行验证,这意味着错误的指针会使进程崩溃。unwrap():用于将ArrayBuffer对象转换为本机指针,并返回指向其内部存储的本机指针。这个方法通常用于将JavaScript端创建的ArrayBuffer对象传递给本机函数使用。调用方有责任在后备存储仍在使用时保持缓冲区处于活动状态。
NativeFunction (函数指针)
翻译成 "函数指针" 不太准确。根据一个 NativePointer (指针) 来创建一个函数,
new NativeFunction(address, returnType, argTypes[, abi]):根据address(NativePointer) 创建一个新的 NativeFunction 函数
returnType 指定返回类型
argTypes 数组 指定参数类型。也可以选择abi指定(如果不是系统默认值)。
对于可变参数函数,argTypes在固定参数和可变参数之间添加一个'...'。
"按值" 传递的 "结构体和类"
- 对于通过值传递的结构体或类,提供一个数组来代替字符串,该数组包含一个接一个的结构体的字段类型。您可以根据需要将它们嵌套在结构中以表示结构。请注意,返回的对象也是
NativePointer,因此可以传递给Interceptor#attach。这必须与struct/class完全匹配,所以如果你有一个包含三个int的struct,你必须传递['int', 'int', 'int']。对于具有虚方法的类,第一个字段将是指向vtable的指针。对于涉及返回值大于Process.pointerSize的C++场景,典型的ABI可能期望必须作为第一个参数传入预分配空间的NativePointer。(This例如,WebKit中的场景很常见。)
支持的 types
- void
- pointer
- int
- uint
- long
- ulong
- char
- uchar
- size_t
- ssize_t
- float
- double
- int8
- uint8
- int16
- uint16
- int32
- uint32
- int64
- uint64
- bool
支持的 abis
- default
- Windows 32-bit:
- sysv
- stdcall
- thiscall
- fastcall
- mscdecl
- Windows 64-bit:
- win64
- UNIX x86:
- sysv
- unix64
- UNIX ARM:
- sysv
- vfp
new NativeFunction(address, returnType, argTypes[, options]) :就像前面的构造函数一样,但其中第四个参数 options 是一个对象,它可能包含一个或多个以下键:
- abi :与上面的枚举相同。
- scheduling :将行为调度为字符串。支持的值为:
cooperative:允许其他线程在调用本机函数时执行JavaScript代码,即在调用之前释放锁,然后重新获取锁。这是默认行为。
exclusive:不允许其他线程在调用本机函数时执行JavaScript代码,即保持JavaScript锁。这会更快,但可能会导致死锁。 - exceptions :异常行为作为字符串。支持的值为:
steal:如果被调用的函数生成了一个原生异常,例如通过解引用一个无效的指针,Frida将展开堆栈并窃取异常,将其转换为可以处理的JavaScript异常。这可能会使应用程序处于未定义状态,但对于避免在实验时崩溃进程非常有用。这是默认行为。
propagate:让应用程序处理函数调用期间发生的任何本地异常。(Or,通过 Process.setExceptionHandler() 安装的处理程序。) - traps :要启用的代码陷阱,作为字符串。支持的值为:
default:如果函数调用触发了任何钩子,则会调用Interceptor.attach()回调。
all:除了拦截器回调之外,跟踪器也可以在每次函数调用期间临时重新激活。这对于例如在引导模糊器时测量代码覆盖率,在调试器中实现“单步执行”等非常有用。请注意,当使用Java和ObjC API时,这也是可能的,因为方法包装器还提供了 clone(options) API来创建具有自定义NativeFunction选项的新方法包装器。
NativeCallback
new NativeCallback(func, returnType, argTypes[, abi]):创建一个由JavaScript函数func实现的新NativeCallback,其中returnType指定返回类型,argTypes数组指定参数类型。如果不是系统默认值,也可以指定abi。有关支持的类型和abis的详细信息,请参阅NativeFunction。请注意,返回的对象也是NativePointer,因此可以传递给Interceptor#replace。当通过Interceptor.replace()使用结果回调时,将使用绑定到具有一些有用属性的对象的this调用func,就像Interceptor.attach()中的对象一样。
SystemFunction
new SystemFunction(address, returnType, argTypes[, abi]):就像NativeFunction一样,但也提供了线程最后一次错误状态的快照。返回值是一个对象,将实际返回值包装为value,并带有一个额外的特定于平台的字段,名为errno(UNIX)或lastError(Windows)。new SystemFunction(address, returnType, argTypes[, options]):与上面相同,但接受一个类似于NativeFunction对应构造函数的options对象。
网络
- Socket
- SocketListener
- SocketConnection
Socket
Socket.listen([options]):打开一个TCP或UNIX侦听套接字。返回一个Promise,它接收一个SocketObject。使用随机选择的TCP 端口。同时在 IPv4、IPv6 上监听,绑定所有接口。
可选的 options 参数是一个可能包含以下键的对象:
family :地址族字符串。支持的值为:unix、IPv4、IPv6
host :IP地址。默认所有接口。
port :数字类型的端口。默认任何可用的端口。
type :(UNIX family)UNIX套接字类型:anonymous、path、abstract、abstract-padded
path :(UNIX系列)UNIX套接字路径。
backlog :将backlog作为一个数字。默认为 10Socket.connect(options):连接到TCP或UNIX服务器。返回一个接收SocketConnection的Promise。options 参数是一个对象,它应该包含以下一些键:
family :地址族字符串。支持的值为:unix、IPv4、IPv6
host :IP地址。默认所有接口。
port :数字类型的端口。默认任何可用的端口。
type :(UNIX family)UNIX套接字类型:anonymous、path、abstract、abstract-padded
path :(UNIX系列)UNIX套接字路径。- Socket.type(handle) :检查OS套接字 handle ,并将其类型作为字符串返回,如果无效或未知,则返回 tcp 、 udp 、 tcp6 、 udp6 、 unix:stream 、 unix:dgram 或 null
- Socket.localAddress(handle) 、 Socket.peerAddress(handle) :检查OS套接字 handle 并返回其本地或对等地址,如果无效或未知,则返回 null 。返回的对象具有以下字段:
ip :IP地址
port :端口。
path :UNIX路径。
SocketListener
所有方法都是完全异步的,并返回Promise对象。
path:正在侦听的(UNIX系列)路径。port:(IP系列)正在侦听的IP端口。close():关闭监听器,释放监听器相关资源,监听器关闭后,其他操作将失败。允许多次关闭侦听器,并且不会导致错误。accept():等待下一个客户端连接。返回的Promise接收一个SocketConnection。
SocketConnection
继承自IOStream。所有方法都是完全异步的,并返回Promise对象。
setNoDelay(noDelay): 如果noDelay是true,则禁用Nagle算法,否则启用它。Nagle算法默认启用,因此只有在您希望优化低延迟而不是高吞吐量时才需要调用此方法。
文件 和 流
- File
- IOStream
- InputStream
- OutputStream
- UnixInputStream
- UnixOutputStream
- Win32InputStream
- Win32OutputStream
File
File.readAllBytes(path):从path指定的文件中同步读取所有字节,并将其作为ArrayBuffer返回。File.readAllText(path):从path指定的文件中同步读取所有文本,并将其作为字符串返回。该文件必须是UTF-8编码的,如果不是这种情况,将引发异常。File.writeAllBytes(path, data):将data同步写入到path指定的文件中,其中data为ArrayBuffer。File.writeAllText(path, text):将text同步写入path指定的文件,其中text为字符串。该文件将采用UTF-8编码。new File(filePath, mode):在filePath处打开或创建文件,并使用mode字符串指定应如何打开该文件。例如"wb"打开文件,以二进制模式写入(这与C标准库中的fopen()格式相同)。tell():返回文件指针在文件中的当前位置。seek(offset[, whence]):将文件指针移动到新位置。offset是要移动到的位置,whence是偏移量的起始点(File.SEEK_SET表示文件的开头,File.SEEK_CUR表示当前文件位置,File.SEEK_END表示文件的结尾)。readBytes([size]):从当前文件指针位置开始读取并返回size字节作为ArrayBuffer。如果未指定size,则从当前位置读取到文件的末尾。readBytes([size]):从当前文件指针位置开始读取并返回size字节作为ArrayBuffer。如果未指定size,则从当前位置读取到文件的末尾。readLine():读取并返回下一行字符串。从当前文件指针位置开始阅读。返回的行不包含换行符。write(data):同步写入data到文件中,其中data是字符串或缓冲区,由NativePointer#readByteArray返回flush():将所有缓冲数据刷新到底层文件。close():关闭文件。您应该在处理完文件后调用此函数,除非您对在对象被垃圾收集或脚本被卸载时发生此操作没有意见。
IOStream
所有方法都是完全异步的,并返回Promise对象。
input:要读取的InputStream。output:要写入的OutputStream。close():关闭流,释放与之相关的资源。这也将关闭各个输入和输出流。一旦流被关闭,所有其他操作都将失败。允许多次关闭流,并且不会导致错误。
InputStream
所有方法都是完全异步的,并返回Promise对象。
close():关闭流,释放流相关资源。流关闭后,其他操作将失败。允许多次关闭流,并且不会导致错误。read(size):从流中读取最多size个字节。返回的Promise接收一个长度为size字节的ArrayBuffer。流的结束通过空缓冲区发出信号。readAll(size):保持从流中阅读,直到正好消耗了size字节。返回的Promise接收一个长度正好为size字节的ArrayBuffer。过早的错误或流的结尾会导致Promise被错误拒绝,其中Error对象有一个包含不完整数据的partialData属性。
OutputStream
所有方法都是完全异步的,并返回Promise对象。
close():关闭流,释放流相关资源。流关闭后,其他操作将失败。允许多次关闭流,并且不会导致错误。write(data):尝试将data写入流。data的值可以是ArrayBuffer或0到255之间的整数数组。返回的Promise接收一个Number,指定有多少字节的data被写入流。writeAll(data):继续写入流,直到所有data都被写入。data的值可以是ArrayBuffer或0到255之间的整数数组。过早错误或流结束导致错误,其中Error对象具有partialSize属性,该属性指定在错误发生之前有多少个data字节写入流。writeMemoryRegion(address, size):尝试将size字节写入流中,从address中阅读它们,这是NativePointer。返回的Promise接收一个Number,指定有多少字节的data被写入流。
UnixInputStream、UnixOutputStream
(Only在类UNIX操作系统上可用。)
new UnixInputStream(fd[, options]):从指定的文件描述符fd创建新的InputStream。您还可以提供一个options对象,并将autoClose设置为true,以便在通过close()或将来的垃圾收集释放流时使流关闭底层文件描述符。new UnixOutputStream(fd[, options]):从指定的文件描述符fd创建新的OutputStream。您还可以提供一个options对象,并将autoClose设置为true,以便在通过close()或将来的垃圾收集释放流时使流关闭底层文件描述符。
Win32InputStream、Win32OutputStream
(Only在Windows上可用)。
new Win32InputStream(handle[, options]):从指定的handle创建一个新的InputStream,这是一个Windows HANDLE值。您还可以提供一个options对象,并将autoClose设置为true,以使流在释放时关闭底层句柄,无论是通过close()还是将来的垃圾收集。new Win32OutputStream(handle[, options]):从指定的handle创建一个新的OutputStream,这是一个Windows HANDLE值。您还可以提供一个options对象,并将autoClose设置为true,以使流在释放时关闭底层句柄,无论是通过close()还是将来的垃圾收集。
数据库
- SqliteDatabase
- SqliteStatement
SqliteDatabase
SqliteDatabase.open(path[, options]):打开由path指定的SQLite v3数据库,一个包含数据库文件系统路径的字符串。默认情况下,数据库将以读写方式打开,但您可以通过提供一个名为flags的属性的options对象来自定义此行为,指定包含以下一个或多个值的字符串数组:readonly,readwrite,create。返回的SqliteDatabase对象将允许您对数据库执行查询。SqliteDatabase.openInline(encodedContents):就像open()一样,但数据库的内容是以包含其数据的字符串形式提供的,Base64编码。我们建议在对数据库进行Base64编码之前对其进行gzip压缩,但这是可选的,可以通过查找gzip魔术标记来检测。数据库是以读写方式打开的,但100%在内存中,从不接触文件系统。这对于需要捆绑预计算数据的缓存的代理很有用,例如用于指导动态分析的静态分析数据。close():关闭数据库。您应该在处理完数据库后调用此函数,除非您对在对象被垃圾收集或脚本被卸载时发生此操作没有意见。exec(sql):执行原始SQL查询,其中sql是包含查询的文本表示的字符串。查询的结果被忽略,因此这应该只用于设置数据库的查询,例如表创建。prepare(sql):将提供的SQL编译为SqliteStatement对象,其中sql是包含查询的文本表示的字符串。示例:const db = SqliteDatabase.open('/path/to/people.db'); const smt = db.prepare('SELECT name, bio FROM people WHERE age = ?'); console.log('People whose age is 42:'); smt.bindInteger(1, 42); let row; while ((row = smt.step()) !== null) { const [name, bio] = row; console.log('Name:', name); console.log('Bio:', bio); } smt.reset();dump():将数据库转储到一个编码为Base64的gzip压缩blob,其中结果作为字符串返回。这对于在代理代码中内联缓存很有用,通过调用SqliteDatabase.openInline()加载。
SqliteStatement
bindInteger(index, value):将整数value绑定到indexbindFloat(index, value):将浮点数value绑定到indexbindText(index, value):将文本value绑定到indexbindBlob(index, bytes):将blobbytes绑定到index,其中bytes是ArrayBuffer、字节值数组或字符串bindNull(index):将空值绑定到indexstep():开始一个新的查询并获得第一个结果,或者移动到下一个结果。返回一个数组,其中包含按查询指定的顺序排列的值,或者当到达最后一个结果时返回null。如果您打算再次使用此对象,则应在此时调用reset()。reset():重置内部状态以允许后续查询
常用功能
- Interceptor
- Stalker
- ObjC
- Java
Interceptor (拦截器)
Interceptor.attach(target, callbacks[, data]):当对target函数进行调用时进行拦截。target是一个NativePointer,指定你想要拦截的函数地址。请注意,在32位ARM上,对于ARM功能,此地址的最低有效位必须设置为0,对于Thumb功能,此地址的最低有效位必须设置为1。如果是从Frida API(例如Module.getExportByName())获取地址,Frida会为您处理此详细信息。
callbacks 参数是一个包含以下一个或多个的对象:
onEnter(args) :回调函数,参数args是一个数组。执行被拦截函数的参数列表
onLeave(retval) :回调函数,参数retval是被拦截函数的返回值。你可以调用 retval.replace(1337) 将返回值替换为整数 1337 ,或调用 retval.replace(ptr("0x1234")) 将返回值替换为指针。请注意,这个对象在onLeave调用中被回收,所以不要在回调之外存储和使用它。如果需要存储包含的值,请进行深度复制,例如:ptr(retval.toString())Interceptor.detachAll():分离所有先前附加的回调。Interceptor.replace(target, replacement[, data]):将target的函数替换为replacement的实现。如果你想完全或部分替换现有函数的实现,通常会使用这个方法。使用NativeCallback在JavaScript中实现replacement。如果被替换的函数使用很频繁,你可以使用CModule在C中实现replacement。然后,您还可以指定第三个可选参数data,这是一个可通过gum_invocation_context_get_listener_function_data()访问的NativePointer。使用gum_interceptor_get_current_invocation()获取GumInvocationContext *。请注意,在调用Interceptor#revert之前,replacement将保持活动状态。如果你想链接到原始的实现,你可以通过你的实现中的NativeFunction同步调用target,这将绕过并直接进入原始的实现。Interceptor.revert(target):将target中的函数还原为之前的实现。Interceptor.flush():确保所有待定的更改已经提交到内存中。这应该只在少数必要的情况下这样做,例如,如果您刚刚使用attach()附加到或使用replace()替换了一个您即将使用NativeFunction调用的函数。待处理的更改会在当前线程即将离开JavaScript运行时或调用send()时自动刷新。这包括建立在send()之上的任何API,比如从RPC方法返回时,以及调用console API上的任何方法。Interceptor.breakpointKind:指定用于非内联钩子的断点类型的字符串。仅在Barebone后端可用。默认是软件断点。将其设置为“hard”以使用硬件断点。
如果被挂钩的函数非常频繁地被调用,那么 onEnter 和 onLeave 可能是指向使用CModule编译的本地C函数的NativePointer值。它们的签名是:
- void onEnter (GumInvocationContext * ic)
- void onLeave (GumInvocationContext * ic)
在这种情况下,第三可选参数 data 可以是可通过gum_invocation_context_get_listener_function_data() 访问的 NativePointer 。
您也可以通过传递函数而不是 callbacks 对象来拦截任意指令。这个函数与 onEnter 有相同的签名,但是传递给它的 args 参数只会在被拦截的指令位于函数的开始处或者位于寄存器/堆栈尚未偏离该点的点处时给你给予合理的值。
就像上面一样,这个函数也可以通过指定 NativePointer 而不是函数来实现。
返回一个侦听器对象,您可以在其上调用 detach() 。
请注意,这些函数将通过绑定到每次调用(线程本地)对象的 this 来调用,您可以在其中存储任意数据,如果您想在 onEnter 中读取参数并在 onLeave 中对其进行操作,这很有用。示例:
Interceptor.attach(Module.getExportByName('libc.so', 'read'), {
onEnter(args) {
this.fileDescriptor = args[0].toInt32();
},
onLeave(retval) {
if (retval.toInt32() > 0) {
/* do something with this.fileDescriptor */
}
}
});此外,该对象还包含一些有用的属性:
returnAddress:返回地址作为NativePointercontext: 带有键pc和sp的对象,它们是NativePointer对象,分别指定ia32/x64/arm的EIP/RIP/PC和ESP/RSP/SP。还有其他特定于处理器的键可用,例如eax、rax、r0、x0等。您也可以通过赋值给这些键来更新寄存器的值。errno:(UNIX)当前errno值(您可以替换它)lastError:(Windows)当前操作系统错误值(您可以替换它)threadId:OS线程IDdepth:相对于其他调用的调用深度
示例:
Interceptor.attach(Module.getExportByName(null, 'read'), {
onEnter(args) {
console.log('Context information:');
console.log('Context : ' + JSON.stringify(this.context));
console.log('Return : ' + this.returnAddress);
console.log('ThreadId : ' + this.threadId);
console.log('Depth : ' + this.depth);
console.log('Errornr : ' + this.err);
// Save arguments for processing in onLeave.
this.fd = args[0].toInt32();
this.buf = args[1];
this.count = args[2].toInt32();
},
onLeave(result) {
console.log('----------')
// Show argument 1 (buf), saved during onEnter.
const numBytes = result.toInt32();
if (numBytes > 0) {
console.log(hexdump(this.buf, { length: numBytes, ansi: true }));
}
console.log('Result : ' + numBytes);
}
})性能考虑
- 提供的回调对性能有很大的影响。如果你只需要检查参数,但不关心返回值,或者相反,请确保省略不需要的回调;即避免将逻辑放在onEnter中,并将onLeave作为空回调留在那里。
- 在iPhone 5S上,仅提供onEnter时的基本开销可能是6微秒,而同时提供onEnter和onLeave时可能是11微秒。
- 还要小心拦截每秒调用无数次的函数调用;虽然send()是异步的,但发送单个消息的总开销并没有针对高频率进行优化,因此这意味着Frida让您根据是否需要低延迟或高吞吐量来将多个值批处理到单个send()调用中。
- 然而,当你钩住频繁使用的函数时,你可以使用拦截器和CModule来实现C中的回调。
示例:Interceptor.replace(target, replacement[, data])
const openPtr = Module.getExportByName('libc.so', 'open');
const open = new NativeFunction(openPtr, 'int', ['pointer', 'int']);
Interceptor.replace(openPtr, new NativeCallback((pathPtr, flags) => {
const path = pathPtr.readUtf8String();
log('Opening "' + path + '"');
const fd = open(pathPtr, flags);
log('Got fd: ' + fd);
return fd;
}, 'int', ['pointer', 'int']));Stalker (跟踪狂)
- Stalker.exclude(range) 将指定的内存范围标记为排除,这是一个具有基址和大小属性的对象,就像 Process.getModuleByName() 返回的对象中的属性。这意味着Stalker在遇到这样一个范围内的指令调用时不会跟踪执行。因此,您将能够观察/修改传入的参数和返回的值,但不会看到其间发生的指令。
Stalker.follow([threadId, options]):开始跟踪threadId(或者当前线程,如果省略),可选地使用options来启用事件。Stalker.unfollow([threadId]):停止跟踪threadId(或者当前线程,如果省略)。Stalker.flush():清除所有缓冲事件。当你不想等到下一个Stalker.queueDrainIntervaltick时很有用。Stalker.garbageCollect():在Stalker#unfollow之后的安全点释放累积的内存。这是为了避免竞争条件,即刚刚被取消跟踪的线程正在执行其最后一条指令。Stalker.invalidate(address):使当前线程的已转换代码对于给定的基本块无效。在提供转换回调并希望动态调整给定基本块的插装时很有用。这比取消并重新跟踪线程要有效得多,取消并重新跟踪线程将丢弃所有缓存的转换,并要求从头开始编译所有遇到的基本块。Stalker.invalidate(threadId, address):使特定线程的已转换代码对于给定的基本块无效。在提供转换回调并希望动态调整给定基本块的插装时很有用。这比取消并重新跟踪线程要有效得多,取消并重新跟踪线程将丢弃所有缓存的转换,并要求从头开始编译所有遇到的基本块。Stalker.addCallProbe(address, callback[, data]):调用address时同步调用callback(签名见Interceptor#attach#onEnter)。返回一个id,稍后可以传递给Stalker#removeCallProbe。也可以使用CModule在C中实现callback,通过指定NativePointer而不是函数。签名:void onCall (GumCallSite * site, gpointer user_data)在这种情况下,第三个可选参数data可以是NativePointer,其值作为user_data传递给回调。Stalker.removeCallProbe:删除Stalker#addCallProbe添加的调用探测。Stalker.trustThreshold:一个整数,指定一段代码需要执行多少次才能被认为是可信的。指定-1表示不信任(慢),指定0表示从一开始就信任代码,指定N表示在代码执行N次后信任代码。默认值为1。Stalker.queueCapacity:指定事件队列容量(以事件数量表示)的整数。共16384个事件。Stalker.queueDrainInterval:一个整数,以毫秒为单位指定每次事件队列耗尽之间的时间。250毫秒,这意味着事件队列每秒被清空四次。您也可以将此属性设置为零以禁用定期排出,并在希望排出队列时调用Stalker.flush()。
示例:
const mainThread = Process.enumerateThreads()[0];
Stalker.follow(mainThread.id, {
events: {
call: true, // CALL instructions: yes please
// Other events:
ret: false, // RET instructions
exec: false, // all instructions: not recommended as it's
// a lot of data
block: false, // block executed: coarse execution trace
compile: false // block compiled: useful for coverage
},
//
// Only specify one of the two following callbacks.
// (See note below.)
//
//
// onReceive: Called with `events` containing a binary blob
// comprised of one or more GumEvent structs.
// See `gumevent.h` for details about the
// format. Use `Stalker.parse()` to examine the
// data.
//
//onReceive(events) {
//},
//
//
// onCallSummary: Called with `summary` being a key-value
// mapping of call target to number of
// calls, in the current time window. You
// would typically implement this instead of
// `onReceive()` for efficiency, i.e. when
// you only want to know which targets were
// called and how many times, but don't care
// about the order that the calls happened
// in.
//
onCallSummary(summary) {
},
//
// Advanced users: This is how you can plug in your own
// StalkerTransformer, where the provided
// function is called synchronously
// whenever Stalker wants to recompile
// a basic block of the code that's about
// to be executed by the stalked thread.
//
//transform(iterator) {
// let instruction = iterator.next();
//
// const startAddress = instruction.address;
// const isAppCode = startAddress.compare(appStart) >= 0 &&
// startAddress.compare(appEnd) === -1;
//
// /*
// * Need to be careful on ARM/ARM64 as we may disturb instruction sequences
// * that deal with exclusive stores.
// */
// const canEmitNoisyCode = iterator.memoryAccess === 'open';
//
// do {
// if (isAppCode && canEmitNoisyCode && instruction.mnemonic === 'ret') {
// iterator.putCmpRegI32('eax', 60);
// iterator.putJccShortLabel('jb', 'nope', 'no-hint');
//
// iterator.putCmpRegI32('eax', 90);
// iterator.putJccShortLabel('ja', 'nope', 'no-hint');
//
// iterator.putCallout(onMatch);
//
// iterator.putLabel('nope');
// }
//
// iterator.keep();
// } while ((instruction = iterator.next()) !== null);
//},
//
// The default implementation is just:
//
// while (iterator.next() !== null)
// iterator.keep();
//
// The example above shows how you can insert your own code
// just before every `ret` instruction across any code
// executed by the stalked thread inside the app's own
// memory range. It inserts code that checks if the `eax`
// register contains a value between 60 and 90, and inserts
// a synchronous callout back into JavaScript whenever that
// is the case. The callback receives a single argument
// that gives it access to the CPU registers, and it is
// also able to modify them.
//
// function onMatch (context) {
// console.log('Match! pc=' + context.pc +
// ' rax=' + context.rax.toInt32());
// }
//
// Note that not calling keep() will result in the
// instruction getting dropped, which makes it possible
// for your transform to fully replace certain instructions
// when this is desirable.
//
//
// Want better performance? Write the callbacks in C:
//
// /*
// * const cm = new CModule(\`
// *
// * #include <gum/gumstalker.h>
// *
// * static void on_ret (GumCpuContext * cpu_context,
// * gpointer user_data);
// *
// * void
// * transform (GumStalkerIterator * iterator,
// * GumStalkerOutput * output,
// * gpointer user_data)
// * {
// * cs_insn * insn;
// *
// * while (gum_stalker_iterator_next (iterator, &insn))
// * {
// * if (insn->id == X86_INS_RET)
// * {
// * gum_x86_writer_put_nop (output->writer.x86);
// * gum_stalker_iterator_put_callout (iterator,
// * on_ret, NULL, NULL);
// * }
// *
// * gum_stalker_iterator_keep (iterator);
// * }
// * }
// *
// * static void
// * on_ret (GumCpuContext * cpu_context,
// * gpointer user_data)
// * {
// * printf ("on_ret!\n");
// * }
// *
// * void
// * process (const GumEvent * event,
// * GumCpuContext * cpu_context,
// * gpointer user_data)
// * {
// * switch (event->type)
// * {
// * case GUM_CALL:
// * break;
// * case GUM_RET:
// * break;
// * case GUM_EXEC:
// * break;
// * case GUM_BLOCK:
// * break;
// * case GUM_COMPILE:
// * break;
// * default:
// * break;
// * }
// * }
// * `);
// */
//
//transform: cm.transform,
//onEvent: cm.process,
//data: ptr(1337) /* user_data */
//
// You may also use a hybrid approach and only write
// some of the callouts in C.
//
});性能考虑
- 提供的回调对性能有很大的影响。如果你只需要定期的调用摘要,但不关心原始事件,或者相反,请确保省略不需要的回调;也就是说,避免将逻辑放在onCallSummary中,并将onReceive作为空回调留在那里。
- 还要注意,Stalker可以与CModule结合使用,这意味着回调可以用C实现。
示例:Stalker.parse(events[, options])
onReceive(events) {
console.log(Stalker.parse(events, {
annotate: true, // to display the type of event
stringify: true
// to format pointer values as strings instead of `NativePointer`
// values, i.e. less overhead if you're just going to `send()` the
// thing not actually parse the data agent-side
}));
},ObjC
ObjC.available:一个布尔值,指定当前进程是否加载了一个Objective-C运行时。ObjC.api:一个对象,将函数名映射到NativeFunction实例,用于直接访问大部分的Objective-C runtime APIObjC.classes:一个对象,映射所有类到ObjC.Object,JavaScript 会绑定当前注册的所有类。您可以通过使用点表示法和用下划线替换冒号来与对象交互,即:[NSString stringWithString:@"Hello World"]变成了const { NSString } = ObjC.classes; NSString.stringWithString_("Hello World");。注意方法名后面的下划线。有关更多详细信息,请参阅iOS示例部分。ObjC.protocols:将协议名称映射到ObjC.Protocol。JavaScript 会绑定当前注册的每个协议。ObjC.mainQueue:主线程的GCD队列ObjC.schedule(queue, work):在queue指定的GCD队列上调度JavaScript函数work。在调用work之前创建NSAutoreleasePool,并在返回时清理。
const { NSSound } = ObjC.classes; /* macOS */
ObjC.schedule(ObjC.mainQueue, () => {
const sound = NSSound.alloc().initWithContentsOfFile_byReference_("/Users/oleavr/.Trash/test.mp3", true);
sound.play();
});new ObjC.Object(handle[, protocol]):在handle(一个NativePointer)的现有对象的情况下创建一个JavaScript绑定。如果你想把handle当作一个只实现某个协议的对象,你也可以指定protocol参数。
Interceptor.attach(myFunction.implementation, {
onEnter(args) {
// ObjC: args[0] = self, args[1] = selector, args[2-n] = arguments
const myString = new ObjC.Object(args[2]);
console.log("String argument: " + myString.toString());
}
});此对象具有一些特殊属性:
$kind:指定instance、class或meta-class的字符串$super:一个ObjC.Object实例,用于链接到超类方法实现$superClass:作为ObjC.Object实例的超类$class:此对象的类作为ObjC.Object实例$className:包含此对象的类名的字符串$protocols:对象将协议名称映射到该对象符合的每个协议的ObjC.Protocol实例$methods:数组,包含此对象的类和父类公开的本机方法名称$ownMethods:数组包含此对象的类公开的本机方法名称,不包括父类$ivars:对象将每个实例变量名映射到其当前值,允许您通过访问和赋值来读取和写入每个实例变量- 还有一个
equals(other)方法用于检查两个实例是否引用同一个底层对象。 - 请注意,所有方法包装器都提供了一个
clone(options)API来创建一个带有自定义NativeFunction选项的新方法包装器。
new ObjC.Protocol(handle) :在 handle (一个NativePointer)的现有协议下创建一个JavaScript绑定。
new ObjC.Block(target[, options]): 创建一个JavaScript绑定,给定 target 处的现有块(一个NativePointer),或者,要定义一个新块, target 应该是一个对象,指定类型签名和每当调用该块时要调用的JavaScript函数。函数是用 implementation 键指定的,签名是通过 types 键或通过 retType 和 argTypes 键指定的。详情参见 ObjC.registerClass() 。请注意,如果现有块缺少签名元数据,您可以调用 declare(signature) ,其中 signature 是具有 types 键或 retType 和 argTypes 键的对象,如上所述。你也可以提供一个带有与NativeFunction支持的相同选项的 options 对象,例如,在调用块时传递 traps: 'all' 以便执行 Stalker.follow() 。最常见的用例是挂接一个现有的块,对于一个需要两个参数的块,它看起来像这样:
const pendingBlocks = new Set();
Interceptor.attach(..., {
onEnter(args) {
const block = new ObjC.Block(args[4]);
pendingBlocks.add(block); // Keep it alive
const appCallback = block.implementation;
block.implementation = (error, value) => {
// Do your logging here
const result = appCallback(error, value);
pendingBlocks.delete(block);
return result;
};
}
});ObjC.implement(method, fn) :创建一个兼容 method 签名的JavaScript实现,其中JavaScript函数 fn 作为实现。返回一个可以分配给ObjC方法的 implementation 属性的 NativeCallback 。
const NSSound = ObjC.classes.NSSound; /* macOS */
const oldImpl = NSSound.play.implementation;
NSSound.play.implementation = ObjC.implement(NSSound.play, (handle, selector) => {
return oldImpl(handle, selector);
});
const NSView = ObjC.classes.NSView; /* macOS */
const drawRect = NSView['- drawRect:'];
const oldImpl = drawRect.implementation;
drawRect.implementation = ObjC.implement(drawRect, (handle, selector) => {
oldImpl(handle, selector);
});由于 implementation 属性是 NativeFunction ,因此也是 NativePointer ,您也可以使用 Interceptor 来挂钩函数:
const { NSSound } = ObjC.classes; /* macOS */
Interceptor.attach(NSSound.play.implementation, {
onEnter() {
send("[NSSound play]");
}
});ObjC.registerProxy(properties) :创建一个新的类,作为目标对象的代理,其中 properties 是一个对象,指定:
protocols:(可选)该类所遵循的协议数组。methods:(可选)指定要实现的方法的对象。events:(可选)指定用于获取事件通知的回调的对象:
dealloc() :在对象被释放后立即调用。这是您可以清理任何关联状态的地方。
forward(name) :使用 name 调用,指定我们将要转发调用的方法名称。这可能是您从一个临时回调开始的地方,它只是记录名称,以帮助您决定覆盖哪些方法。
const MyConnectionDelegateProxy = ObjC.registerProxy({
protocols: [ObjC.protocols.NSURLConnectionDataDelegate],
methods: {
'- connection:didReceiveResponse:': function (conn, resp) {
/* fancy logging code here */
/* this.data.foo === 1234 */
this.data.target
.connection_didReceiveResponse_(conn, resp);
},
'- connection:didReceiveData:': function (conn, data) {
/* other logging code here */
this.data.target
.connection_didReceiveData_(conn, data);
}
},
events: {
forward(name) {
console.log('*** forwarding: ' + name);
}
}
});
const method = ObjC.classes.NSURLConnection[
'- initWithRequest:delegate:startImmediately:'];
Interceptor.attach(method.implementation, {
onEnter(args) {
args[3] = new MyConnectionDelegateProxy(args[3], {
foo: 1234
});
}
});ObjC.registerClass(properties) :创建一个新的Java-C类,其中 properties 是一个对象,指定:
name:(可选)指定类名称的字符串;如果您不关心全局可见的名称,并且希望运行库自动为您生成一个名称,则省略此选项。super:(可选)Super-class,或null创建一个新的根类;省略从NSObject继承。protocols:(可选)该类所遵循的协议数组。methods:(可选)指定要实现的方法的对象。
const MyConnectionDelegateProxy = ObjC.registerClass({
name: 'MyConnectionDelegateProxy',
super: ObjC.classes.NSObject,
protocols: [ObjC.protocols.NSURLConnectionDataDelegate],
methods: {
'- init': function () {
const self = this.super.init();
if (self !== null) {
ObjC.bind(self, {
foo: 1234
});
}
return self;
},
'- dealloc': function () {
ObjC.unbind(this.self);
this.super.dealloc();
},
'- connection:didReceiveResponse:': function (conn, resp) {
/* this.data.foo === 1234 */
},
/*
* But those previous methods are declared assuming that
* either the super-class or a protocol we conform to has
* the same method so we can grab its type information.
* However, if that's not the case, you would write it
* like this:
*/
'- connection:didReceiveResponse:': {
retType: 'void',
argTypes: ['object', 'object'],
implementation(conn, resp) {
}
},
/* Or grab it from an existing class: */
'- connection:didReceiveResponse:': {
types: ObjC.classes
.Foo['- connection:didReceiveResponse:'].types,
implementation(conn, resp) {
}
},
/* Or from an existing protocol: */
'- connection:didReceiveResponse:': {
types: ObjC.protocols.NSURLConnectionDataDelegate
.methods['- connection:didReceiveResponse:'].types,
implementation(conn, resp) {
}
},
/* Or write the signature by hand if you really want to: */
'- connection:didReceiveResponse:': {
types: 'v32@0:8@16@24',
implementation(conn, resp) {
}
}
}
});
const proxy = MyConnectionDelegateProxy.alloc().init();
/* use `proxy`, and later: */
proxy.release();ObjC.registerProtocol(properties) :创建一个新的C2C协议,其中 properties 是一个对象,指定:
name: (可选)指定协议名称的字符串;如果您不关心全局可见的名称,并且希望运行时自动为您生成一个名称,请省略此字符串。protocols:(可选)此协议包含的协议数组。methods:(可选)指定要声明的方法的对象。
const MyDataDelegate = ObjC.registerProtocol({
name: 'MyDataDelegate',
protocols: [ObjC.protocols.NSURLConnectionDataDelegate],
methods: {
/* You must specify the signature: */
'- connection:didStuff:': {
retType: 'void',
argTypes: ['object', 'object']
},
/* Or grab it from a method of an existing class: */
'- connection:didStuff:': {
types: ObjC.classes
.Foo['- connection:didReceiveResponse:'].types
},
/* Or from an existing protocol method: */
'- connection:didStuff:': {
types: ObjC.protocols.NSURLConnectionDataDelegate
.methods['- connection:didReceiveResponse:'].types
},
/* Or write the signature by hand if you really want to: */
'- connection:didStuff:': {
types: 'v32@0:8@16@24'
},
/* You can also make a method optional (default is required): */
'- connection:didStuff:': {
retType: 'void',
argTypes: ['object', 'object'],
optional: true
}
}
});
ObjC.bind(obj, data) :将一些JavaScript数据绑定到一个Objective-C 实例;有关示例,请参阅 ObjC.registerClass() 。
ObjC.unbind(obj) :解除绑定一个Objective-C实例中之前关联的JavaScript数据,示例见 ObjC.registerClass() 。
ObjC.getBoundData(obj) :从一个Objective-C对象中查找以前绑定的数据。
ObjC.enumerateLoadedClasses([options, ]callbacks) :枚举当前加载的类,其中 callbacks 是指定以下内容的对象:
onMatch(name, owner):为每个加载的类调用,类的name作为字符串,owner指定加载类的模块的路径。要获取给定类的JavaScript包装器,请执行以下操作:ObjC.classes[name]。onComplete():当所有类都被枚举时调用。
示例:
ObjC.enumerateLoadedClasses({
onMatch(name, owner) {
console.log('onMatch:', name, owner);
},
onComplete() {
}
});可选的 options 参数是一个对象,您可以在其中指定 ownedBy 属性以将枚举限制为给定 ModuleMap 中的模块。示例:
const appModules = new ModuleMap(isAppModule);
ObjC.enumerateLoadedClasses({ ownedBy: appModules }, {
onMatch(name, owner) {
console.log('onMatch:', name, owner);
},
onComplete() {
}
});
function isAppModule(m) {
return !/^\/(usr\/lib|System|Developer)\//.test(m.path);
}ObjC.enumerateLoadedClassesSync([options]) : enumerateLoadedClasses() 的同步版本,返回一个对象映射所有者模块到类名数组。
const appModules = new ModuleMap(isAppModule);
const appClasses = ObjC.enumerateLoadedClassesSync({ ownedBy: appModules });
console.log('appClasses:', JSON.stringify(appClasses));
function isAppModule(m) {
return !/^\/(usr\/lib|System|Developer)\//.test(m.path);
}ObjC.choose(specifier, callbacks) :通过扫描堆枚举与 specifier 匹配的类的活动实例。 specifier 要么是一个类选择器,要么是一个指定类选择器和所需选项的对象。类选择器是类的ObjC.Object,例如ObjC.classes.UIButton。当传递一个对象作为指定符时,你应该为类选择器提供 class 字段,为 subclasses 字段提供一个布尔值,指示你是否也对匹配给定类选择器的子类感兴趣。默认值是还包括子类。 callbacks 参数是一个对象,指定:
onMatch(instance):对于每个使用现成的instance找到的活动实例,调用一次,就像您知道这个特定的EASP-C实例位于0x 1234时调用new ObjC.Object(ptr("0x1234"))一样。此函数可能返回字符串stop以提前取消枚举。onComplete():在枚举所有实例时调用
ObjC.chooseSync(specifier) : choose() 的同步版本,返回数组中的实例。
ObjC.selector(name) :将JavaScript字符串 name 转换为选择器
ObjC.selectorAsString(sel) :将选择器 sel 转换为JavaScript字符串
Java
Java.available:布尔值,指定当前进程是否加载了Java VM,即Dalvik或ART。若果没有加在,就不要调用任何其他Java属性或方法。Java.androidVersion:一个字符串,指定运行的Android版本。-
Java.enumerateLoadedClassesSync():enumerateLoadedClasses()的同步版本,返回数组中的类名。 -
Java.enumerateLoadedClasses(callbacks):枚举当前加载的类,该函数接受一个名为callbacks的参数,它是一个对象。这个对象有两个属性:onMatch和onComplete。 - onMatch(name, handle) :为每个加载的类调用 name ,它可能被传递到 use() 以获得JavaScript包装器。你也可以 Java.cast() 到 handle 到 java.lang.Class 。
onComplete() :当所有类都被枚举时调用。
onMatch: 当一个类被枚举到时,这个回调函数被调用。它接受一个参数,即当前被枚举到的类的名称。可以在这个函数里处理或记录类名。
onComplete: 当所有的类都被枚举完毕后,这个回调函数被调用。它不接受任何参数,通常用于执行清理工作或者告知枚举操作已完成。
用法:你需要编写两个回调函数,一个是每当发现一个类时应该执行的操作(onMatch),另一个是当所有类都已经被找到后执行的操作(onComplete)。以下是一个简单的使用例子:
Java.enumerateLoadedClasses({
onMatch: function(className) {
// 对于每一个找到的类,可以在这里处理,例如打印类名
console.log(className);
},
onComplete: function() {
// 当所有类都枚举完成后,在这里执行一些结束操作
console.log('Enumeration complete');
}
});Java.enumerateClassLoadersSync() : enumerateClassLoaders() 的同步版本,返回数组中的类加载器。Java.enumerateClassLoaders(callbacks) :枚举Java VM中存在的类加载器,其中 callbacks 是指定以下内容的对象:
onMatch(loader):为每个带有loader的类加载器调用,为特定的java.lang.ClassLoader包装。onComplete():当所有类装入器都被枚举时调用。
您可以将这样的加载器传递给 Java.ClassFactory.get() ,以便能够在指定的类加载器上加载 .use() 个类。
Java.enumerateMethods(query) :枚举与 query 匹配的方法,指定为 "class!method" ,允许使用globs。也可以后缀 / 和一个或多个修饰符:
i:不区分大小写的匹配。s:包含方法签名,例如"putInt"变成"putInt(java.lang.String, int): void"。u:仅用户定义类,忽略系统类。
Java.perform(() => {
const groups = Java.enumerateMethods('*youtube*!on*')
console.log(JSON.stringify(groups, null, 2));
});Java.scheduleOnMainThread(fn) :在VM的主线程上运行 fn 。
Java.perform(fn) :确保当前线程连接到VM并调用 fn 。(This在Java的回调中是不必要的。如果应用的类加载器还不可用,将推迟调用 fn 。如果不需要访问应用程序的类,请使用 Java.performNow() 。
Java.perform(() => {
const Activity = Java.use('android.app.Activity');
Activity.onResume.implementation = function () {
send('onResume() got called! Let\'s call the original implementation');
this.onResume();
};
});Java.performNow(fn) :确保当前线程连接到VM并调用 fn 。This在Java的回调中是不必要的。
Java.use(className) :动态获取 className 的JavaScript包装器,您可以通过调用 $new() 来实例化对象以调用构造函数。对一个实例调用 $dispose() 来显式地清理它(或者等待JavaScript对象被垃圾回收,或者脚本被卸载)。静态和非静态方法都是可用的,你甚至可以替换一个方法实现并抛出一个异常:
Java.perform(() => {
const Activity = Java.use('android.app.Activity');
const Exception = Java.use('java.lang.Exception');
Activity.onResume.implementation = function () {
throw Exception.$new('Oh noes!');
};
});默认情况下使用应用的类加载器,但您可以通过为 Java.classFactory.loader 分配不同的加载器实例来对此进行自定义。
请注意,所有方法包装器都提供了一个 clone(options) API来创建一个带有自定义NativeFunction选项的新方法包装器。
Java.openClassFile(filePath) :打开 filePath 的.dex文件,返回一个对象,方法如下:
load():将包含的类加载到VM中。getClassNames():获取可用类名数组。
Java.choose(className, callbacks) :通过扫描Java堆来枚举 className 类的活动实例,其中 callbacks 是指定以下内容的对象:
onMatch(instance):对每个使用现成的instance找到的活动实例进行调用,就像您使用此特定实例的原始句柄调用Java.cast()一样。此函数可能返回字符串stop以提前取消枚举。onComplete():在枚举所有实例时调用
Java.retain(obj) :复制JavaScript包装器 obj 以备后用,外部替换方法。
Java.perform(() => {
const Activity = Java.use('android.app.Activity');
let lastActivity = null;
Activity.onResume.implementation = function () {
lastActivity = Java.retain(this);
this.onResume();
};
});Java.cast(handle, klass) :根据从 Java.use() 返回的给定类 klass 的 handle 处的现有实例,创建一个JavaScript包装器。这样的包装器也有一个 class 属性用于获取其类的包装器,还有一个 $className 属性用于获取其类名的字符串表示。
const Activity = Java.use('android.app.Activity');
const activity = Java.cast(ptr('0x1234'), Activity);Java.array(type, elements) :从JavaScript数组 elements 创建一个Java数组,其中包含指定的 type 元素。生成的Java数组的行为类似于JS数组,但可以通过引用传递给Java API,以便允许它们修改其内容。
const values = Java.array('int', [ 1003, 1005, 1007 ]);
const JString = Java.use('java.lang.String');
const str = JString.$new(Java.array('byte', [ 0x48, 0x65, 0x69 ]));Java.isMainThread() :判断调用者是否在主线程上运行。
Java.registerClass(spec) :创建一个新的Java类并返回一个包装器,其中 spec 是一个对象,包含:
name:指定类名称的字符串。superClass:(可选)超类。继承自java.lang.Object。implements:(可选)该类实现的接口数组。fields:(可选)指定要公开的每个字段的名称和类型的对象。methods:(可选)指定要实现的方法的对象。
const SomeBaseClass = Java.use('com.example.SomeBaseClass');
const X509TrustManager = Java.use('javax.net.ssl.X509TrustManager');
const MyTrustManager = Java.registerClass({
name: 'com.example.MyTrustManager',
implements: [X509TrustManager],
methods: {
checkClientTrusted(chain, authType) {
},
checkServerTrusted(chain, authType) {
},
getAcceptedIssuers() {
return [];
},
}
});
const MyWeirdTrustManager = Java.registerClass({
name: 'com.example.MyWeirdTrustManager',
superClass: SomeBaseClass,
implements: [X509TrustManager],
fields: {
description: 'java.lang.String',
limit: 'int',
},
methods: {
$init() {
console.log('Constructor called');
},
checkClientTrusted(chain, authType) {
console.log('checkClientTrusted');
},
checkServerTrusted: [{
returnType: 'void',
argumentTypes: ['[Ljava.security.cert.X509Certificate;', 'java.lang.String'],
implementation(chain, authType) {
console.log('checkServerTrusted A');
}
}, {
returnType: 'java.util.List',
argumentTypes: ['[Ljava.security.cert.X509Certificate;', 'java.lang.String', 'java.lang.String'],
implementation(chain, authType, host) {
console.log('checkServerTrusted B');
return null;
}
}],
getAcceptedIssuers() {
console.log('getAcceptedIssuers');
return [];
},
}
});Java.deoptimizeEverything() :强制VM使用其解释器执行所有操作。在某些情况下,防止优化绕过方法钩子是必要的,并允许ART的Instrumentation API用于跟踪运行时。
Java.deoptimizeBootImage() :类似于Java.deoptimizeEverything(),但只对靴子镜像代码进行反优化。与 dalvik.vm.dex2oat-flags --inline-max-code-units=0 一起使用,以获得最佳效果。
Java.vm :使用以下方法创建对象:
perform(fn):确保当前线程连接到VM并调用fn。(This在Java的回调中是不必要的。getEnv():获取当前线程的JNIEnv的包装器。如果当前线程未附加到VM,则引发异常。tryGetEnv():尝试获取当前线程的JNIEnv的包装器。如果当前线程未连接到VM,则返回null。
Java.classFactory :用于实现例如 Java.use() 的默认类工厂。使用应用程序的主类加载器。
Java.ClassFactory :类,具有以下属性:
get(classLoader):获取给定类装入器的类工厂实例。在后台使用的默认类工厂只与应用程序的主类加载器交互。其他类装入器可以通过Java.enumerateClassLoaders()发现,并通过此API进行交互。loader:只读属性,为当前使用的类加载器提供包装。对于默认的类工厂,这是通过第一次调用Java.perform()来更新的。cacheDir:包含当前正在使用的缓存目录的路径的字符串。对于默认的类工厂,这是通过第一次调用Java.perform()来更新的。tempFileNaming:指定用于临时文件的命名约定的对象。默认为{ prefix: 'frida', suffix: 'dat' }。use(className):类似于Java.use(),但用于特定的类加载器。openClassFile(filePath):类似于Java.openClassFile(),但用于特定的类加载器。retain(obj):类似于Java.retain(),但用于特定的类加载器。cast(handle, klass):类似于Java.cast(),但用于特定的类加载器。array(type, elements):类似于Java.array(),但用于特定的类加载器。registerClass(spec):类似于Java.registerClass(),但用于特定的类加载器。
CPU 指令
- Instruction
- X86Writer
- X86Relocator
- x86 enum types
- ArmWriter
- ArmRelocator
- ThumbWriter
- ThumbRelocator
- ARM enum types
- Arm64Writer
- Arm64Relocator
- AArch64 enum types
- MipsWriter
- MipsRelocator
- MIPS enum types
Instruction (指令)
Instruction.parse(target) :解析内存中 target 地址处的指令,由 NativePointer 表示。请注意,在32位ARM上,对于ARM功能,此地址的最低有效位必须设置为0,对于Thumb功能,此地址的最低有效位必须设置为1。如果您从Frida API(例如 Module.getExportByName() )获取地址,Frida会为您处理此详细信息。返回的对象具有以下字段:
address:此指令的地址(EIP),作为NativePointernext:指向下一条指令的指针,所以你可以parse()它size:此指令的大小mnemonic:指令助记符的字符串表示opStr:指令操作数的字符串表示operands: 描述每个操作数的对象数组,每个操作数至少指定type和value,但也可能根据体系结构指定其他属性regsRead:此指令隐式读取的寄存器名称数组regsWritten:此指令隐式写入的寄存器名称数组groups:该指令所属的组名数组toString():转换为人类可读的字符串
有关 operands 和 groups 的详细信息,请参阅您的架构的 Capstone文档。
X86Writer
new X86Writer(codeAddress[, { pc: ptr('0x1234') }]):创建一个新的代码编写器,用于生成直接写入codeAddress内存的x86机器码,指定为NativePointer。第二个参数是一个可选的选项对象,可以在其中指定初始程序计数器,这在生成临时缓冲区的代码时很有用。在iOS上使用Memory.patchCode()时,这是必不可少的,它可能会为您提供一个临时位置,稍后会映射到目标内存位置的内存中。reset(codeAddress[, { pc: ptr('0x1234') }]):回收实例dispose():急切地清理内存flush():解析标签引用并将挂起数据写入内存。一旦你完成了代码的生成,你就应该调用这个函数。通常也希望在不相关的代码段之间这样做,例如,当一次生成多个函数时。base:输出的第一个字节的内存位置,作为NativePointercode:输出的下一个字节的内存位置,作为NativePointerpc:输出的下一个字节的程序计数器,作为NativePointeroffset:当前偏移量作为JavaScript NumberputLabel(id):在当前位置放置一个标签,其中id是一个字符串,可能在过去和未来的put*Label()调用中被引用putCallAddressWithArguments(func, args): 放置调用具有指定args的C函数所需的代码,指定为JavaScript数组,其中每个元素是指定寄存器的字符串,或者是指定立即值的Number或NativePointer。putCallAddressWithAlignedArguments(func, args):与上面一样,但也确保参数列表在16字节边界上对齐putCallRegWithArguments(reg, args): 放置调用具有指定args的C函数所需的代码,指定为JavaScript数组,其中每个元素是指定寄存器的字符串,或者是指定立即值的Number或NativePointer。putCallRegWithAlignedArguments(reg, args):与上面一样,但也确保参数列表在16字节边界上对齐putCallRegOffsetPtrWithArguments(reg, offset, args): 放置调用具有指定args的C函数所需的代码,指定为JavaScript数组,其中每个元素是指定寄存器的字符串,或者是指定立即值的Number或NativePointer。putCallAddress(address):放置CALL指令putCallReg(reg):放置CALL指令putCallRegOffsetPtr(reg, offset):放置CALL指令putCallIndirect(addr):放置CALL指令putCallIndirectLabel(labelId):放置引用labelId的CALL指令,由过去或未来putLabel()定义putCallNearLabel(labelId):放置引用labelId的CALL指令,由过去或未来putLabel()定义putLeave():放入LEAVE指令putRet():放置RET指令putRetImm(immValue):放置RET指令putJmpAddress(address):放置JMP指令putJmpShortLabel(labelId):放置一条引用labelId的JMP指令,由过去或未来的putLabel()定义putJmpNearLabel(labelId):放置一条引用labelId的JMP指令,由过去或未来的putLabel()定义putJmpReg(reg):放置JMP指令putJmpRegPtr(reg):放置JMP指令putJmpRegOffsetPtr(reg, offset):放置JMP指令putJmpNearPtr(address):放置JMP指令putJccShort(instructionId, target, hint):放入JCC指令- putJccNear(instructionId, target, hint):放入JCC指令
- putJccShortLabel(instructionId, labelId, hint):放置引用labelId的JCC指令,由过去或未来的
- putLabel()定义
- putJccNearLabel(instructionId, labelId, hint):放置引用labelId的JCC指令,由过去或未来的
- putLabel()定义
- putAddRegImm(reg, immValue):放入ADD指令
- putAddRegReg(dstReg, srcReg):放入ADD指令
- putAddRegNearPtr(dstReg, srcAddress) :放入ADD指令
putSubRegImm(reg, immValue) :放入一个命令
putSubRegReg(dstReg, srcReg) :放入一个命令
putSubRegNearPtr(dstReg, srcAddress) :放入一个命令
putIncReg(reg) :放入INC指令
putDecReg(reg) :放入DEC指令
putIncRegPtr(target, reg) :放入INC指令
putDecRegPtr(target, reg) :放入DEC指令
putLockXaddRegPtrReg(dstReg, srcReg) :放置一条XADD指令
putLockCmpxchgRegPtrReg(dstReg, srcReg) :放入一条CMPXCHG指令
putLockIncImm32Ptr(target) :放入一个CININC IMM32指令
putLockDecImm32Ptr(target) :放置一条ADDEC IMM32指令
putAndRegReg(dstReg, srcReg) :放入AND指令
putAndRegU32(reg, immValue) :放入AND指令
putShlRegU8(reg, immValue) :放入SHL指令
putShrRegU8(reg, immValue) :放入SHR指令
putXorRegReg(dstReg, srcReg) :放入XOR指令
putMovRegReg(dstReg, srcReg) :输入MOV指令
putMovRegU32(dstReg, immValue) :输入MOV指令
putMovRegU64(dstReg, immValue) :输入MOV指令
putMovRegAddress(dstReg, address) :输入MOV指令
putMovRegPtrU32(dstReg, immValue) :输入MOV指令
putMovRegOffsetPtrU32(dstReg, dstOffset, immValue) :输入MOV指令
putMovRegPtrReg(dstReg, srcReg) :输入MOV指令
putMovRegOffsetPtrReg(dstReg, dstOffset, srcReg) :输入MOV指令
putMovRegRegPtr(dstReg, srcReg) :输入MOV指令
putMovRegRegOffsetPtr(dstReg, srcReg, srcOffset) :输入MOV指令
putMovRegBaseIndexScaleOffsetPtr(dstReg, baseReg, indexReg, scale, offset) :输入MOV
putMovRegNearPtr(dstReg, srcAddress) :输入MOV指令
putMovNearPtrReg(dstAddress, srcReg) :输入MOV指令
putMovFsU32PtrReg(fsOffset, srcReg) :放入MOV FS指令
putMovRegFsU32Ptr(dstReg, fsOffset) :放入MOV FS指令
putMovFsRegPtrReg(fsOffset, srcReg) :放入MOV FS指令
putMovRegFsRegPtr(dstReg, fsOffset) :放入MOV FS指令
putMovGsU32PtrReg(fsOffset, srcReg) :放入MOV GS指令
putMovRegGsU32Ptr(dstReg, fsOffset) :放入MOV GS指令
putMovGsRegPtrReg(gsOffset, srcReg) :放入MOV GS指令
putMovRegGsRegPtr(dstReg, gsOffset) :放入MOV GS指令
putMovqXmm0EspOffsetPtr(offset) :放置MOVQ XMM0 ESP指令
putMovqEaxOffsetPtrXmm0(offset) :放入MOVQ EAX XMM0指令
putMovdquXmm0EspOffsetPtr(offset) :放入MOVDQU XMM0 ESP指令
putMovdquEaxOffsetPtrXmm0(offset) :放入MOVDQU EAX XMM0指令
putLeaRegRegOffset(dstReg, srcReg, srcOffset) :放入LEA 指令
putXchgRegRegPtr(leftReg, rightReg) :放入XCHG指令
putPushU32(immValue) :放入PUSH指令
putPushNearPtr(address) :放入PUSH指令
putPushReg(reg) :放入PUSH指令
putPopReg(reg) :放入POP指令
putPushImmPtr(immPtr) :放入PUSH指令
putPushax() :放置PUSHAX指令 -
putPopax(): put a POPAX instruction -
putPushfx(): put a PUSHFX instruction -
putPopfx(): put a POPFX instruction -
putSahf(): put a SAHF instruction -
putLahf(): put a LAHF instruction -
putTestRegReg(regA, regB): put a TEST instruction -
putTestRegU32(reg, immValue): put a TEST instruction -
putCmpRegI32(reg, immValue): put a CMP instruction -
putCmpRegOffsetPtrReg(regA, offset, regB): put a CMP instruction -
putCmpImmPtrImmU32(immPtr, immValue): put a CMP instruction -
putCmpRegReg(regA, regB): put a CMP instruction -
putClc(): put a CLC instruction -
putStc(): put a STC instruction -
putCld(): put a CLD instruction -
putStd(): put a STD instruction -
putCpuid(): put a CPUID instruction -
putLfence(): put an LFENCE instruction -
putRdtsc(): put an RDTSC instruction -
putPause(): put a PAUSE instruction -
putNop(): put a NOP instruction -
putBreakpoint(): put an OS/architecture-specific breakpoint instruction -
putPadding(n): putnguard instruction -
putNopPadding(n): putnNOP instructions -
putFxsaveRegPtr(reg): put a FXSAVE instruction -
putFxrstorRegPtr(reg): put a FXRSTOR instruction -
putU8(value): put a uint8 -
putS8(value): put an int8 -
putBytes(data): put raw data from the provided ArrayBuffer
X86Relocator
new X86Relocator(inputCode, output): 创建新的代码重定位器,用于将x86指令从一个存储器位置复制到另一个存储器位置,注意相应地调整位置相关指令。源地址由NativePointer的inputCode指定。目标地址由output给出,一个X86 Writer指向所需的目标内存地址。reset(inputCode, output):回收实例dispose():急切地清理内存input:到目前为止读取的最新指令。从null开始,每次调用都会更改为readOne()。eob:布尔值,表示是否到达块结束,即我们到达了任何类型的分支,如CALL,JMP,BL,RET。eoi:一个布尔值,表示是否已经到达输入结束,例如,我们已经到达JMP/B/RET,一个指令之后可能有也可能没有有效代码。readOne():将下一条指令读入重定位器的内部缓冲区,并返回到目前为止读取的字节数,包括以前的调用。您可以继续调用此方法来保持缓冲,或者立即调用writeOne()或skipOne()。或者,您可以缓冲到所需的点,然后调用writeAll()。当到达输入结束时返回零,这意味着eoi属性现在是true。peekNextWriteInsn():查看要写入或跳过的下一条指令peekNextWriteSource():查看下一条要写入或跳过的指令的地址skipOne():跳过下一个要写的指令skipOneNoLabel():跳过接下来要写的指令,但没有标签供内部使用。这打破了将分支重新定位到重新定位的范围内的位置,并且是对所有分支都被重写的用例的优化(例如Frida的Stalker)。writeOne():写入下一条缓冲指令writeOneNoLabel():写入下一条缓冲指令,但不带标签供内部使用。这打破了将分支重新定位到重新定位的范围内的位置,并且是对所有分支都被重写的用例的优化(例如Frida的Stalker)。writeAll():写入所有缓冲指令
x86 enum types
- Register:
xaxxcxxdxxbxxspxbpxsixdieaxecxedxebxespebpesiediraxrcxrdxrbxrsprbprsirdir8r9r10r11r12r13r14r15r8dr9dr10dr11dr12dr13dr14dr15dxipeiprip - InstructionId:
jojnojbjaejejnejbejajsjnsjpjnpjljgejlejgjcxzjecxzjrcxz - BranchHint:
no-hintlikelyunlikely - PointerTarget:
bytedwordqword
ArmWriter
-
new ArmWriter(codeAddress[, { pc: ptr('0x1234') }]): create a new code writer for generating ARM machine code written directly to memory atcodeAddress, specified as a NativePointer. The second argument is an optional options object where the initial program counter may be specified, which is useful when generating code to a scratch buffer. This is essential when using Memory.patchCode() on iOS, which may provide you with a temporary location that later gets mapped into memory at the intended memory location. -
reset(codeAddress[, { pc: ptr('0x1234') }]): recycle instance -
dispose(): eagerly clean up memory -
flush(): resolve label references and write pending data to memory. You should always call this once you’ve finished generating code. It is usually also desirable to do this between pieces of unrelated code, e.g. when generating multiple functions in one go. -
base: memory location of the first byte of output, as a NativePointer -
code: memory location of the next byte of output, as a NativePointer -
pc: program counter at the next byte of output, as a NativePointer -
offset: current offset as a JavaScript Number -
skip(nBytes): skipnBytes -
putLabel(id): put a label at the current position, whereidis a string that may be referenced in past and futureput*Label()calls -
putCallAddressWithArguments(func, args): put code needed for calling a C function with the specifiedargs, specified as a JavaScript array where each element is either a string specifying the register, or a Number or NativePointer specifying the immediate value. -
putCallReg(reg): put a CALL instruction -
putCallRegWithArguments(reg, args): put code needed for calling a C function with the specifiedargs, specified as a JavaScript array where each element is either a string specifying the register, or a Number or NativePointer specifying the immediate value. -
putBranchAddress(address): put code needed for branching/jumping to the given address -
canBranchDirectlyBetween(from, to): determine whether a direct branch is possible between the two given memory locations -
putBImm(target): put a B instruction -
putBCondImm(cc, target): put a B COND instruction -
putBLabel(labelId): put a B instruction referencinglabelId, defined by a past or future putLabel() -
putBCondLabel(cc, labelId): put a B COND instruction referencinglabelId, defined by a past or future putLabel() -
putBlImm(target): put a BL instruction -
putBlxImm(target): put a BLX instruction -
putBlLabel(labelId): put a BL instruction referencinglabelId, defined by a past or future putLabel() -
putBxReg(reg): put a BX instruction -
putBlReg(reg): put a BL instruction -
putBlxReg(reg): put a BLX instruction -
putRet(): put a RET instruction -
putVpushRange(firstReg, lastReg): put a VPUSH RANGE instruction -
putVpopRange(firstReg, lastReg): put a VPOP RANGE instruction -
putLdrRegAddress(reg, address): put an LDR instruction -
putLdrRegU32(reg, val): put an LDR instruction -
putLdrRegReg(dstReg, srcReg): put an LDR instruction -
putLdrRegRegOffset(dstReg, srcReg, srcOffset): put an LDR instruction -
putLdrCondRegRegOffset(cc, dstReg, srcReg, srcOffset): put an LDR COND instruction -
putLdmiaRegMask(reg, mask): put an LDMIA MASK instruction -
putLdmiaRegMaskWb(reg, mask): put an LDMIA MASK WB instruction -
putStrRegReg(srcReg, dstReg): put a STR instruction -
putStrRegRegOffset(srcReg, dstReg, dstOffset): put a STR instruction -
putStrCondRegRegOffset(cc, srcReg, dstReg, dstOffset): put a STR COND instruction -
putMovRegReg(dstReg, srcReg): put a MOV instruction -
putMovRegRegShift(dstReg, srcReg, shift, shiftValue): put a MOV SHIFT instruction -
putMovRegCpsr(reg): put a MOV CPSR instruction -
putMovCpsrReg(reg): put a MOV CPSR instruction -
putAddRegU16(dstReg, val): put an ADD U16 instruction -
putAddRegU32(dstReg, val): put an ADD instruction -
putAddRegRegImm(dstReg, srcReg, immVal): put an ADD instruction -
putAddRegRegReg(dstReg, srcReg1, srcReg2): put an ADD instruction -
putAddRegRegRegShift(dstReg, srcReg1, srcReg2, shift, shiftValue): put an ADD SHIFT instruction -
putSubRegU16(dstReg, val): put a SUB U16 instruction -
putSubRegU32(dstReg, val): put a SUB instruction -
putSubRegRegImm(dstReg, srcReg, immVal): put a SUB instruction -
putSubRegRegReg(dstReg, srcReg1, srcReg2): put a SUB instruction -
putRsbRegRegImm(dstReg, srcReg, immVal): put a RSB instruction -
putAndsRegRegImm(dstReg, srcReg, immVal): put an ANDS instruction -
putCmpRegImm(dstReg, immVal): put a CMP instruction -
putNop(): put a NOP instruction -
putBreakpoint(): put an OS/architecture-specific breakpoint instruction -
putBrkImm(imm): put a BRK instruction -
putInstruction(insn): put a raw instruction as a JavaScript Number -
putBytes(data): put raw data from the provided ArrayBuffer
ArmRelocator
-
new ArmRelocator(inputCode, output): create a new code relocator for copying ARM instructions from one memory location to another, taking care to adjust position-dependent instructions accordingly. The source address is specified byinputCode, a NativePointer. The destination is given byoutput, an ArmWriter pointed at the desired target memory address. -
reset(inputCode, output): recycle instance -
dispose(): eagerly clean up memory -
input: latest Instruction read so far. Starts outnulland changes on every call to readOne(). -
eob: boolean indicating whether end-of-block has been reached, i.e. we’ve reached a branch of any kind, like CALL, JMP, BL, RET. -
eoi: boolean indicating whether end-of-input has been reached, e.g. we’ve reached JMP/B/RET, an instruction after which there may or may not be valid code. -
readOne(): read the next instruction into the relocator’s internal buffer and return the number of bytes read so far, including previous calls. You may keep calling this method to keep buffering, or immediately call either writeOne() or skipOne(). Or, you can buffer up until the desired point and then call writeAll(). Returns zero when end-of-input is reached, which means theeoiproperty is nowtrue. -
peekNextWriteInsn(): peek at the next Instruction to be written or skipped -
peekNextWriteSource(): peek at the address of the next instruction to be written or skipped -
skipOne(): skip the instruction that would have been written next -
writeOne(): write the next buffered instruction -
writeAll(): write all buffered instructions
ThumbWriter
-
new ThumbWriter(codeAddress[, { pc: ptr('0x1234') }]): create a new code writer for generating ARM machine code written directly to memory atcodeAddress, specified as a NativePointer. The second argument is an optional options object where the initial program counter may be specified, which is useful when generating code to a scratch buffer. This is essential when using Memory.patchCode() on iOS, which may provide you with a temporary location that later gets mapped into memory at the intended memory location. -
reset(codeAddress[, { pc: ptr('0x1234') }]): recycle instance -
dispose(): eagerly clean up memory -
flush(): resolve label references and write pending data to memory. You should always call this once you’ve finished generating code. It is usually also desirable to do this between pieces of unrelated code, e.g. when generating multiple functions in one go. -
base: memory location of the first byte of output, as a NativePointer -
code: memory location of the next byte of output, as a NativePointer -
pc: program counter at the next byte of output, as a NativePointer -
offset: current offset as a JavaScript Number -
skip(nBytes): skipnBytes -
putLabel(id): put a label at the current position, whereidis a string that may be referenced in past and futureput*Label()calls -
commitLabel(id): commit the first pending reference to the given label, returningtrueon success. Returnsfalseif the given label hasn’t been defined yet, or there are no more pending references to it. -
putCallAddressWithArguments(func, args): put code needed for calling a C function with the specifiedargs, specified as a JavaScript array where each element is either a string specifying the register, or a Number or NativePointer specifying the immediate value. -
putCallRegWithArguments(reg, args): put code needed for calling a C function with the specifiedargs, specified as a JavaScript array where each element is either a string specifying the register, or a Number or NativePointer specifying the immediate value. -
putBranchAddress(address): put code needed for branching/jumping to the given address -
canBranchDirectlyBetween(from, to): determine whether a direct branch is possible between the two given memory locations -
putBImm(target): put a B instruction -
putBLabel(labelId): put a B instruction referencinglabelId, defined by a past or future putLabel() -
putBLabelWide(labelId): put a B WIDE instruction -
putBxReg(reg): put a BX instruction -
putBlImm(target): put a BL instruction -
putBlLabel(labelId): put a BL instruction referencinglabelId, defined by a past or future putLabel() -
putBlxImm(target): put a BLX instruction -
putBlxReg(reg): put a BLX instruction -
putCmpRegImm(reg, immValue): put a CMP instruction -
putBeqLabel(labelId): put a BEQ instruction referencinglabelId, defined by a past or future putLabel() -
putBneLabel(labelId): put a BNE instruction referencinglabelId, defined by a past or future putLabel() -
putBCondLabel(cc, labelId): put a B COND instruction referencinglabelId, defined by a past or future putLabel() -
putBCondLabelWide(cc, labelId): put a B COND WIDE instruction -
putCbzRegLabel(reg, labelId): put a CBZ instruction referencinglabelId, defined by a past or future putLabel() -
putCbnzRegLabel(reg, labelId): put a CBNZ instruction referencinglabelId, defined by a past or future putLabel() -
putPushRegs(regs): put a PUSH instruction with the specified registers, specified as a JavaScript array where each element is a string specifying the register name. -
putPopRegs(regs): put a POP instruction with the specified registers, specified as a JavaScript array where each element is a string specifying the register name. -
putVpushRange(firstReg, lastReg): put a VPUSH RANGE instruction -
putVpopRange(firstReg, lastReg): put a VPOP RANGE instruction -
putLdrRegAddress(reg, address): put an LDR instruction -
putLdrRegU32(reg, val): put an LDR instruction -
putLdrRegReg(dstReg, srcReg): put an LDR instruction -
putLdrRegRegOffset(dstReg, srcReg, srcOffset): put an LDR instruction -
putLdrbRegReg(dstReg, srcReg): put an LDRB instruction -
putVldrRegRegOffset(dstReg, srcReg, srcOffset): put a VLDR instruction -
putLdmiaRegMask(reg, mask): put an LDMIA MASK instruction -
putStrRegReg(srcReg, dstReg): put a STR instruction -
putStrRegRegOffset(srcReg, dstReg, dstOffset): put a STR instruction -
putMovRegReg(dstReg, srcReg): put a MOV instruction -
putMovRegU8(dstReg, immValue): put a MOV instruction -
putMovRegCpsr(reg): put a MOV CPSR instruction -
putMovCpsrReg(reg): put a MOV CPSR instruction -
putAddRegImm(dstReg, immValue): put an ADD instruction -
putAddRegReg(dstReg, srcReg): put an ADD instruction -
putAddRegRegReg(dstReg, leftReg, rightReg): put an ADD instruction -
putAddRegRegImm(dstReg, leftReg, rightValue): put an ADD instruction -
putSubRegImm(dstReg, immValue): put a SUB instruction -
putSubRegReg(dstReg, srcReg): put a SUB instruction -
putSubRegRegReg(dstReg, leftReg, rightReg): put a SUB instruction -
putSubRegRegImm(dstReg, leftReg, rightValue): put a SUB instruction -
putAndRegRegImm(dstReg, leftReg, rightValue): put an AND instruction -
putOrRegRegImm(dstReg, leftReg, rightValue): put an OR instruction -
putLslRegRegImm(dstReg, leftReg, rightValue): put a LSL instruction -
putLslsRegRegImm(dstReg, leftReg, rightValue): put a LSLS instruction -
putLsrsRegRegImm(dstReg, leftReg, rightValue): put a LSRS instruction -
putMrsRegReg(dstReg, srcReg): put a MRS instruction -
putMsrRegReg(dstReg, srcReg): put a MSR instruction -
putNop(): put a NOP instruction -
putBkptImm(imm): put a BKPT instruction -
putBreakpoint(): put an OS/architecture-specific breakpoint instruction -
putInstruction(insn): put a raw instruction as a JavaScript Number -
putInstructionWide(upper, lower): put a raw Thumb-2 instruction from two JavaScript Number values -
putBytes(data): put raw data from the provided ArrayBuffer
ThumbRelocator
-
new ThumbRelocator(inputCode, output): create a new code relocator for copying ARM instructions from one memory location to another, taking care to adjust position-dependent instructions accordingly. The source address is specified byinputCode, a NativePointer. The destination is given byoutput, a ThumbWriter pointed at the desired target memory address. -
reset(inputCode, output): recycle instance -
dispose(): eagerly clean up memory -
input: latest Instruction read so far. Starts outnulland changes on every call to readOne(). -
eob: boolean indicating whether end-of-block has been reached, i.e. we’ve reached a branch of any kind, like CALL, JMP, BL, RET. -
eoi: boolean indicating whether end-of-input has been reached, e.g. we’ve reached JMP/B/RET, an instruction after which there may or may not be valid code. -
readOne(): read the next instruction into the relocator’s internal buffer and return the number of bytes read so far, including previous calls. You may keep calling this method to keep buffering, or immediately call either writeOne() or skipOne(). Or, you can buffer up until the desired point and then call writeAll(). Returns zero when end-of-input is reached, which means theeoiproperty is nowtrue. -
peekNextWriteInsn(): peek at the next Instruction to be written or skipped -
peekNextWriteSource(): peek at the address of the next instruction to be written or skipped -
skipOne(): skip the instruction that would have been written next -
writeOne(): write the next buffered instruction -
copyOne(): copy out the next buffered instruction without advancing the output cursor, allowing the same instruction to be written out multiple times -
writeAll(): write all buffered instructions
ARM enum types
- Register:
r0r1r2r3r4r5r6r7r8r9r10r11r12r13r14r15splrsbslfpippcs0s1s2s3s4s5s6s7s8s9s10s11s12s13s14s15s16s17s18s19s20s21s22s23s24s25s26s27s28s29s30s31d0d1d2d3d4d5d6d7d8d9d10d11d12d13d14d15d16d17d18d19d20d21d22d23d24d25d26d27d28d29d30d31q0q1q2q3q4q5q6q7q8q9q10q11q12q13q14q15 - SystemRegister:
apsr-nzcvq - ConditionCode:
eqnehslomiplvsvchilsgeltgtleal - Shifter:
asrlsllsrrorrrxasr-reglsl-reglsr-regror-regrrx-reg
Arm64Writer
-
new Arm64Writer(codeAddress[, { pc: ptr('0x1234') }]): create a new code writer for generating AArch64 machine code written directly to memory atcodeAddress, specified as a NativePointer. The second argument is an optional options object where the initial program counter may be specified, which is useful when generating code to a scratch buffer. This is essential when using Memory.patchCode() on iOS, which may provide you with a temporary location that later gets mapped into memory at the intended memory location. -
reset(codeAddress[, { pc: ptr('0x1234') }]): recycle instance -
dispose(): eagerly clean up memory -
flush(): resolve label references and write pending data to memory. You should always call this once you’ve finished generating code. It is usually also desirable to do this between pieces of unrelated code, e.g. when generating multiple functions in one go. -
base: memory location of the first byte of output, as a NativePointer -
code: memory location of the next byte of output, as a NativePointer -
pc: program counter at the next byte of output, as a NativePointer -
offset: current offset as a JavaScript Number -
skip(nBytes): skipnBytes -
putLabel(id): put a label at the current position, whereidis a string that may be referenced in past and futureput*Label()calls -
putCallAddressWithArguments(func, args): put code needed for calling a C function with the specifiedargs, specified as a JavaScript array where each element is either a string specifying the register, or a Number or NativePointer specifying the immediate value. -
putCallRegWithArguments(reg, args): put code needed for calling a C function with the specifiedargs, specified as a JavaScript array where each element is either a string specifying the register, or a Number or NativePointer specifying the immediate value. -
putBranchAddress(address): put code needed for branching/jumping to the given address -
canBranchDirectlyBetween(from, to): determine whether a direct branch is possible between the two given memory locations -
putBImm(address): put a B instruction -
putBLabel(labelId): put a B instruction referencinglabelId, defined by a past or future putLabel() -
putBCondLabel(cc, labelId): put a B COND instruction referencinglabelId, defined by a past or future putLabel() -
putBlImm(address): put a BL instruction -
putBlLabel(labelId): put a BL instruction referencinglabelId, defined by a past or future putLabel() -
putBrReg(reg): put a BR instruction -
putBrRegNoAuth(reg): put a BR instruction expecting a raw pointer without any authentication bits -
putBlrReg(reg): put a BLR instruction -
putBlrRegNoAuth(reg): put a BLR instruction expecting a raw pointer without any authentication bits -
putRet(): put a RET instruction -
putRetReg(reg): put a RET instruction -
putCbzRegImm(reg, target): put a CBZ instruction -
putCbnzRegImm(reg, target): put a CBNZ instruction -
putCbzRegLabel(reg, labelId): put a CBZ instruction referencinglabelId, defined by a past or future putLabel() -
putCbnzRegLabel(reg, labelId): put a CBNZ instruction referencinglabelId, defined by a past or future putLabel() -
putTbzRegImmImm(reg, bit, target): put a TBZ instruction -
putTbnzRegImmImm(reg, bit, target): put a TBNZ instruction -
putTbzRegImmLabel(reg, bit, labelId): put a TBZ instruction referencinglabelId, defined by a past or future putLabel() -
putTbnzRegImmLabel(reg, bit, labelId): put a TBNZ instruction referencinglabelId, defined by a past or future putLabel() -
putPushRegReg(regA, regB): put a PUSH instruction -
putPopRegReg(regA, regB): put a POP instruction -
putPushAllXRegisters(): put code needed for pushing all X registers on the stack -
putPopAllXRegisters(): put code needed for popping all X registers off the stack -
putPushAllQRegisters(): put code needed for pushing all Q registers on the stack -
putPopAllQRegisters(): put code needed for popping all Q registers off the stack -
putLdrRegAddress(reg, address): put an LDR instruction -
putLdrRegU32(reg, val): put an LDR instruction -
putLdrRegU64(reg, val): put an LDR instruction -
putLdrRegU32Ptr(reg, srcAddress): put an LDR instruction -
putLdrRegU64Ptr(reg, srcAddress): put an LDR instruction -
putLdrRegRef(reg): put an LDR instruction with a dangling data reference, returning an opaque ref value that should be passed to putLdrRegValue() at the desired location -
putLdrRegValue(ref, value): put the value and update the LDR instruction from a previous putLdrRegRef() -
putLdrRegReg(dstReg, srcReg): put an LDR instruction -
putLdrRegRegOffset(dstReg, srcReg, srcOffset): put an LDR instruction -
putLdrRegRegOffsetMode(dstReg, srcReg, srcOffset, mode): put an LDR MODE instruction -
putLdrswRegRegOffset(dstReg, srcReg, srcOffset): put an LDRSW instruction -
putAdrpRegAddress(reg, address): put an ADRP instruction -
putStrRegReg(srcReg, dstReg): put a STR instruction -
putStrRegRegOffset(srcReg, dstReg, dstOffset): put a STR instruction -
putStrRegRegOffsetMode(srcReg, dstReg, dstOffset, mode): put a STR MODE instruction -
putLdpRegRegRegOffset(regA, regB, regSrc, srcOffset, mode): put an LDP instruction -
putStpRegRegRegOffset(regA, regB, regDst, dstOffset, mode): put a STP instruction -
putMovRegReg(dstReg, srcReg): put a MOV instruction -
putMovRegNzcv(reg): put a MOV NZCV instruction -
putMovNzcvReg(reg): put a MOV NZCV instruction -
putUxtwRegReg(dstReg, srcReg): put an UXTW instruction -
putAddRegRegImm(dstReg, leftReg, rightValue): put an ADD instruction -
putAddRegRegReg(dstReg, leftReg, rightReg): put an ADD instruction -
putSubRegRegImm(dstReg, leftReg, rightValue): put a SUB instruction -
putSubRegRegReg(dstReg, leftReg, rightReg): put a SUB instruction -
putAndRegRegImm(dstReg, leftReg, rightValue): put an AND instruction -
putEorRegRegReg(dstReg, leftReg, rightReg): put an EOR instruction -
putUbfm(dstReg, srcReg, imms, immr): put an UBFM instruction -
putLslRegImm(dstReg, srcReg, shift): put a LSL instruction -
putLsrRegImm(dstReg, srcReg, shift): put a LSR instruction -
putTstRegImm(reg, immValue): put a TST instruction -
putCmpRegReg(regA, regB): put a CMP instruction -
putXpaciReg(reg): put an XPACI instruction -
putNop(): put a NOP instruction -
putBrkImm(imm): put a BRK instruction -
putMrs(dstReg, systemReg): put a MRS instruction -
putInstruction(insn): put a raw instruction as a JavaScript Number -
putBytes(data): put raw data from the provided ArrayBuffer -
sign(value): sign the given pointer value
Arm64Relocator
-
new Arm64Relocator(inputCode, output): create a new code relocator for copying AArch64 instructions from one memory location to another, taking care to adjust position-dependent instructions accordingly. The source address is specified byinputCode, a NativePointer. The destination is given byoutput, an Arm64Writer pointed at the desired target memory address. -
reset(inputCode, output): recycle instance -
dispose(): eagerly clean up memory -
input: latest Instruction read so far. Starts outnulland changes on every call to readOne(). -
eob: boolean indicating whether end-of-block has been reached, i.e. we’ve reached a branch of any kind, like CALL, JMP, BL, RET. -
eoi: boolean indicating whether end-of-input has been reached, e.g. we’ve reached JMP/B/RET, an instruction after which there may or may not be valid code. -
readOne(): read the next instruction into the relocator’s internal buffer and return the number of bytes read so far, including previous calls. You may keep calling this method to keep buffering, or immediately call either writeOne() or skipOne(). Or, you can buffer up until the desired point and then call writeAll(). Returns zero when end-of-input is reached, which means theeoiproperty is nowtrue. -
peekNextWriteInsn(): peek at the next Instruction to be written or skipped -
peekNextWriteSource(): peek at the address of the next instruction to be written or skipped -
skipOne(): skip the instruction that would have been written next -
writeOne(): write the next buffered instruction -
writeAll(): write all buffered instructions
AArch64 enum types
- Register:
x0x1x2x3x4x5x6x7x8x9x10x11x12x13x14x15x16x17x18x19x20x21x22x23x24x25x26x27x28x29x30w0w1w2w3w4w5w6w7w8w9w10w11w12w13w14w15w16w17w18w19w20w21w22w23w24w25w26w27w28w29w30splrfpwspwzrxzrnzcvip0ip1s0s1s2s3s4s5s6s7s8s9s10s11s12s13s14s15s16s17s18s19s20s21s22s23s24s25s26s27s28s29s30s31d0d1d2d3d4d5d6d7d8d9d10d11d12d13d14d15d16d17d18d19d20d21d22d23d24d25d26d27d28d29d30d31q0q1q2q3q4q5q6q7q8q9q10q11q12q13q14q15q16q17q18q19q20q21q22q23q24q25q26q27q28q29q30q31 - ConditionCode:
eqnehslomiplvsvchilsgeltgtlealnv - IndexMode:
post-adjustsigned-offsetpre-adjust
MipsWriter
-
new MipsWriter(codeAddress[, { pc: ptr('0x1234') }]): create a new code writer for generating MIPS machine code written directly to memory atcodeAddress, specified as a NativePointer. The second argument is an optional options object where the initial program counter may be specified, which is useful when generating code to a scratch buffer. This is essential when using Memory.patchCode() on iOS, which may provide you with a temporary location that later gets mapped into memory at the intended memory location. -
reset(codeAddress[, { pc: ptr('0x1234') }]): recycle instance -
dispose(): eagerly clean up memory -
flush(): resolve label references and write pending data to memory. You should always call this once you’ve finished generating code. It is usually also desirable to do this between pieces of unrelated code, e.g. when generating multiple functions in one go. -
base: memory location of the first byte of output, as a NativePointer -
code: memory location of the next byte of output, as a NativePointer -
pc: program counter at the next byte of output, as a NativePointer -
offset: current offset as a JavaScript Number -
skip(nBytes): skipnBytes -
putLabel(id): put a label at the current position, whereidis a string that may be referenced in past and futureput*Label()calls -
putCallAddressWithArguments(func, args): put code needed for calling a C function with the specifiedargs, specified as a JavaScript array where each element is either a string specifying the register, or a Number or NativePointer specifying the immediate value. -
putCallRegWithArguments(reg, args): put code needed for calling a C function with the specifiedargs, specified as a JavaScript array where each element is either a string specifying the register, or a Number or NativePointer specifying the immediate value. -
putJAddress(address): put a J instruction -
putJAddressWithoutNop(address): put a J WITHOUT NOP instruction -
putJLabel(labelId): put a J instruction referencinglabelId, defined by a past or future putLabel() -
putJrReg(reg): put a JR instruction -
putJalAddress(address): put a JAL instruction -
putJalrReg(reg): put a JALR instruction -
putBOffset(offset): put a B instruction -
putBeqRegRegLabel(rightReg, leftReg, labelId): put a BEQ instruction referencinglabelId, defined by a past or future putLabel() -
putRet(): put a RET instruction -
putLaRegAddress(reg, address): put a LA instruction -
putLuiRegImm(reg, imm): put a LUI instruction -
putDsllRegReg(dstReg, srcReg, amount): put a DSLL instruction -
putOriRegRegImm(rt, rs, imm): put an ORI instruction -
putLdRegRegOffset(dstReg, srcReg, srcOffset): put an LD instruction -
putLwRegRegOffset(dstReg, srcReg, srcOffset): put a LW instruction -
putSwRegRegOffset(srcReg, dstReg, dstOffset): put a SW instruction -
putMoveRegReg(dstReg, srcReg): put a MOVE instruction -
putAdduRegRegReg(dstReg, leftReg, rightReg): put an ADDU instruction -
putAddiRegRegImm(dstReg, leftReg, imm): put an ADDI instruction -
putAddiRegImm(dstReg, imm): put an ADDI instruction -
putSubRegRegImm(dstReg, leftReg, imm): put a SUB instruction -
putPushReg(reg): put a PUSH instruction -
putPopReg(reg): put a POP instruction -
putMfhiReg(reg): put a MFHI instruction -
putMfloReg(reg): put a MFLO instruction -
putMthiReg(reg): put a MTHI instruction -
putMtloReg(reg): put a MTLO instruction -
putNop(): put a NOP instruction -
putBreak(): put a BREAK instruction -
putPrologueTrampoline(reg, address): put a minimal sized trampoline for vectoring to the given address -
putInstruction(insn): put a raw instruction as a JavaScript Number -
putBytes(data): put raw data from the provided ArrayBuffer
MipsRelocator
-
new MipsRelocator(inputCode, output): create a new code relocator for copying MIPS instructions from one memory location to another, taking care to adjust position-dependent instructions accordingly. The source address is specified byinputCode, a NativePointer. The destination is given byoutput, a MipsWriter pointed at the desired target memory address. -
reset(inputCode, output): recycle instance -
dispose(): eagerly clean up memory -
input: latest Instruction read so far. Starts outnulland changes on every call to readOne(). -
eob: boolean indicating whether end-of-block has been reached, i.e. we’ve reached a branch of any kind, like CALL, JMP, BL, RET. -
eoi: boolean indicating whether end-of-input has been reached, e.g. we’ve reached JMP/B/RET, an instruction after which there may or may not be valid code. -
readOne(): read the next instruction into the relocator’s internal buffer and return the number of bytes read so far, including previous calls. You may keep calling this method to keep buffering, or immediately call either writeOne() or skipOne(). Or, you can buffer up until the desired point and then call writeAll(). Returns zero when end-of-input is reached, which means theeoiproperty is nowtrue. -
peekNextWriteInsn(): peek at the next Instruction to be written or skipped -
peekNextWriteSource(): peek at the address of the next instruction to be written or skipped -
skipOne(): skip the instruction that would have been written next -
writeOne(): write the next buffered instruction -
writeAll(): write all buffered instructions
MIPS enum types
- Register:
v0v1a0a1a2a3t0t1t2t3t4t5t6t7s0s1s2s3s4s5s6s7t8t9k0k1gpspfps8rahilozeroat012345678910111213141516171819202122232425262728293031
3、其他语言 API
C API
JavaScript API 提供的 (例如:用于注入、函数操作、内存读取等) 功能,C语言都支持。
Frida 被分解成几个模块,这些都可以单独编译,也可以在发布页面上找到。devkit 下载页面附带了如何使用每个模块的示例。使用devkits是学习如何使用每个模块的最佳方法。
core 核心
frida-core包含主注入代码。从frida-core,你可以注入到一个进程中,创建一个运行QuickJS的线程,并运行你的JavaScript。
gum
frida-gum允许你使用C来增加和替换函数。devkit中的示例向您展示了如何仅从C扩展
open和close。 frida-gum
gumjs
frida-gumjs 包含 JavaScript 绑定。
gadget
类似于 frida-agent,除了 DYLD_BLOG_LIBRARIES,与应用程序捆绑等之外,它可以在远程模式下运行,在这种模式下就像 frida-server 一样。
Swift API
请参阅C或JS API页面以获取类似的文档。
Go API
从Go使用Frida的API变得很容易。有关完整文档,请访问 pkg.go.dev.
示例:
package main
import (
"fmt"
"github.com/frida/frida-go/frida"
)
func main() {
manager := frida.NewDeviceManager()
devices, err := manager.EnumerateDevices()
if err != nil {
panic(err)
}
fmt.Printf("[*] Frida version: %s\n", frida.Version())
fmt.Println("[*] Devices: ")
for _, device := range devices {
fmt.Printf("[*] %s => %s\n", device.Name(), device.ID())
}
}


![[ Linux ] git工具的基本使用(仓库的构建,提交)](https://img-blog.csdnimg.cn/direct/de62670ec55642ab9df947e560494b08.png)