| java数据结构与算法刷题目录(剑指Offer、LeetCode、ACM)-----主目录-----持续更新(进不去说明我没写完):https://blog.csdn.net/grd_java/article/details/123063846 |
|---|
文章目录
- 1. hash统计出现次数后排序
- 2. 桶排序
1. hash统计出现次数后排序
| 解题思路:时间复杂度O( ) ,空间复杂度 O ( ),空间复杂度O( ),空间复杂度O() |
|---|
- 通过hash表统计每个字符的出现次数,时间复杂度O( n n n)
- 对hash表按照出现次数降序排序,时间复杂度O( k ∗ l o g 2 k k*log_2{k} k∗log2k)是快速排序的时间复杂度。其中k是hash大小,也就是字符串中不重复的字母个数
如果使用数组作为hash表,不使用HashMap的话,则不需要排序
- 然后依次将最大出现次数的字符,拼接起来,输出。正好是按照排序好的hash表进行输出。O( k k k)
使用数组作为hash表,虽然不需要排序,但是每次都得遍历整个hash表找到出现次数最多的字符。因此时间复杂度O( n ∗ k n*k n∗k)其中n是字符串大小,k是hash表大小。我们需要找到n个字符拼接为结果字符串,每次都需要完整遍历hash表(长度为k)找到出现次数最多的
因此时间复杂度为
- 直接使用HashMap,时间复杂度O( n + k ∗ l o g 2 k n+k*log_2{k} n+k∗log2k),空间复杂度O( n + k n+k n+k).另外快速排序也需要额外栈空间O( l o g 2 k log_2{k} log2k)
- 使用数组作为hash表,时间复杂度O( n + n ∗ k n+n*k n+n∗k),空间复杂度O(n+k).
使用数组作为hash表所需大小:
字符串包含大小写字母和数字,ASCII码如下:A = 65,Z = 90. a = 97,z = 122,0 = 48,9 = 57
因此hash表大小为123即可(下标从0到122)。并且从48开始,前面47的下标是没有用的
| 代码:选用数组作为hash,因为这样更难,做题情况下,比使用HashMap效率高很多(工作场景下没什么区别)。但是工作场景中,要使用HashMap。 |
|---|
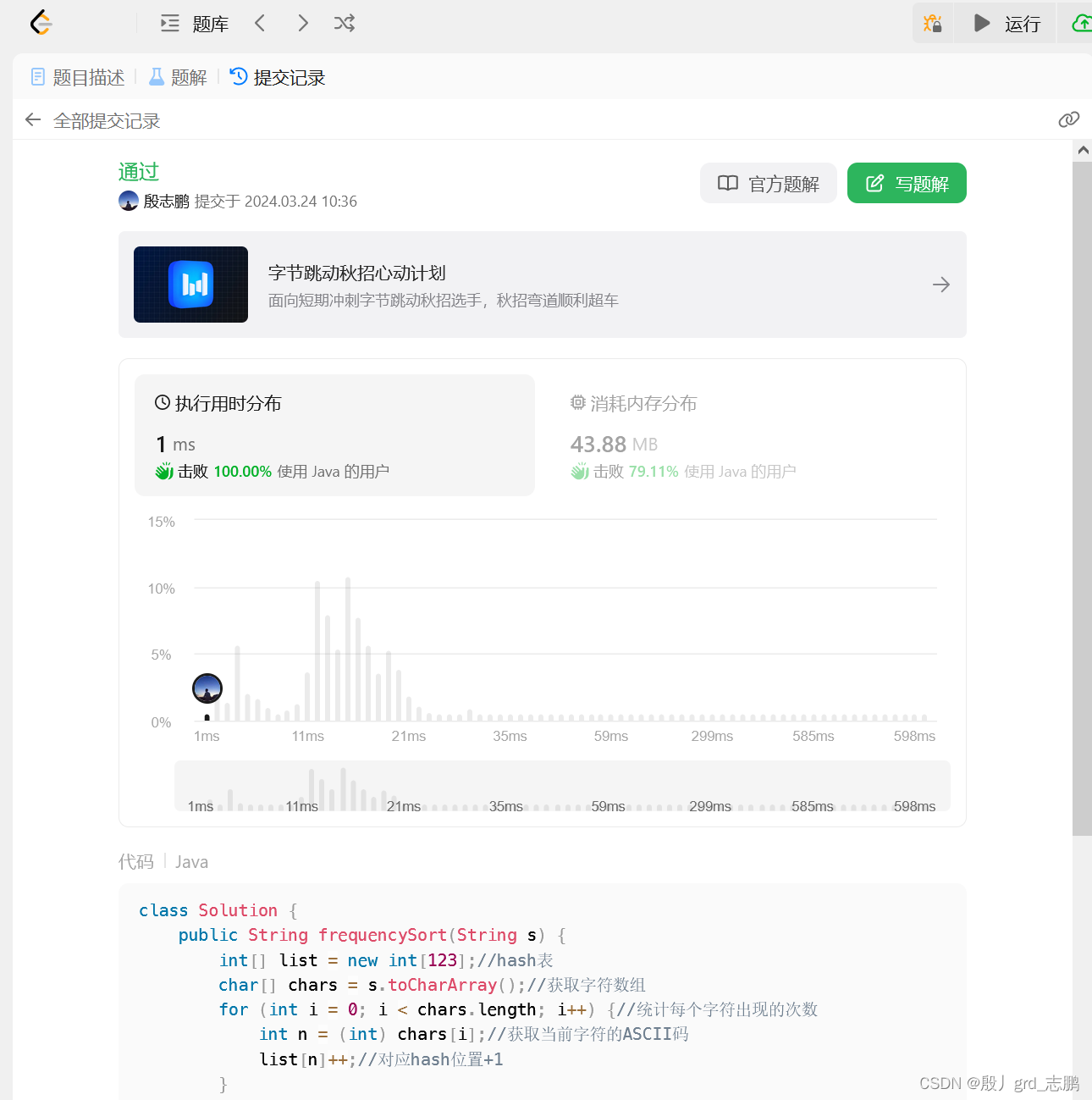
class Solution {
public String frequencySort(String s) {
int[] list = new int[123];//hash表
char[] chars = s.toCharArray();//获取字符数组
for (int i = 0; i < chars.length; i++) {//统计每个字符出现的次数
int n = (int) chars[i];//获取当前字符的ASCII码
list[n]++;//对应hash位置+1
}
int index = 0;//结果字符数组的下标
while (index < chars.length) {
int max = 0;//保存最大值
char target = ' ';//保存出现次数最多的字符
for (int i = 48; i < list.length; i++) {//遍历hash表
if (list[i] > max) {//如果当前字符出现次数更多
max = list[i];//保存这个次数
target = (char) i ;//让target指向这个字符
}
}
for (int j = 0; j < max; j++) {//将其拼接到字符数组中
chars[index++] = target;
}
list[target] = 0;//hash表中已经输出的字符归0
}
return String.valueOf(chars);
}
}
2. 桶排序
| 解题思路:时间复杂度O( n + k n+k n+k),空间复杂度O( n + k n+k n+k) |
|---|
- 先通过hash表统计每个字符的出现次数,时间复杂度O( n n n)
- 然后按照出现次数,将字符放入对应桶中。时间复杂度O( k k k)
桶保存的是对应出现次数的字符。例如1号桶保存出现1次的字符,2号桶保存出现次数为2的字符
- 然后从后往前遍历桶(出现次数高的先拼接到字符串)。时间复杂度O( k k k)
记住,当前是几号桶,取出的字符就出现几次。因此我们拼接字符串时,要将取出的字符每个都拼接对应桶的次数
| 代码:因为使用了StringBuilder,做题场景下的效率反而比方法1慢,但是实际工作场景中,肯定是这个方法的时间复杂度更优 |
|---|
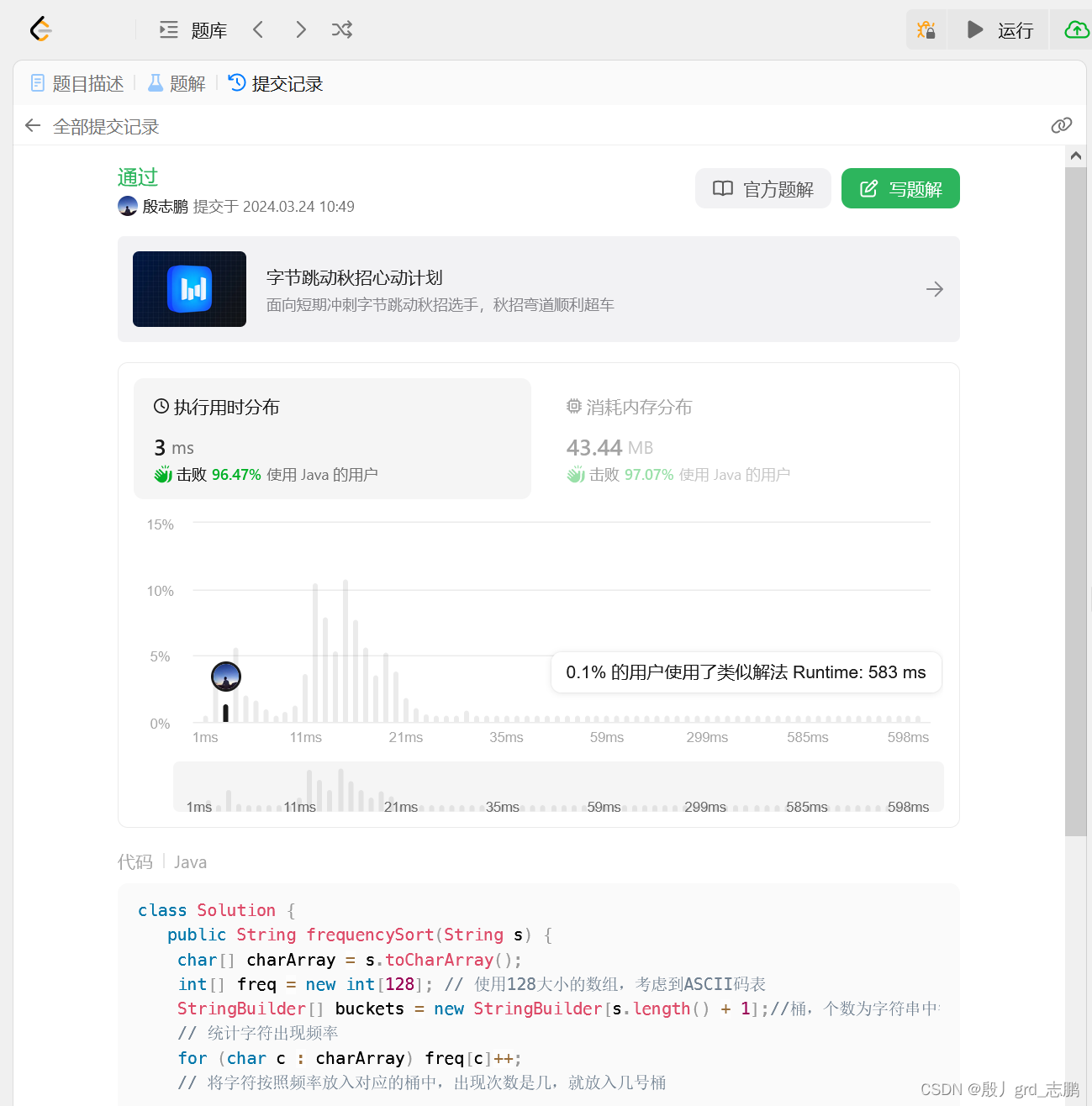
class Solution {
public String frequencySort(String s) {
char[] charArray = s.toCharArray();
int[] freq = new int[128]; // 使用128大小的数组,考虑到ASCII码表
StringBuilder[] buckets = new StringBuilder[s.length() + 1];//桶,个数为字符串中字符个数+1
// 统计字符出现频率
for (char c : charArray) freq[c]++;
// 将字符按照频率放入对应的桶中,出现次数是几,就放入几号桶
for (int i = 48; i < 128; i++) {
if (freq[i] > 0) {//如果当前字符出现次数>0
//放入对应出现次数的桶中,例如当前字符出现3次,就放入3号桶
if (buckets[freq[i]] == null) buckets[freq[i]] = new StringBuilder();//如果当前桶为空,先创建桶
buckets[freq[i]].append((char)i);//然后将字符添加到桶中
}
}
// 构建结果字符串
StringBuilder result = new StringBuilder();
for (int i = buckets.length-1; i > 0; i--) {//从后往前遍历桶
if (buckets[i] != null) {//先查看,统计出现次数最高字符的桶
for (char c : buckets[i].toString().toCharArray()) {//依次取出桶中字符
for (int j = 0; j < i; j++) {//当前是i号桶,这个字符需要添加i次,因为i是它的出现次数
result.append(c);
}
}
}
}
return result.toString();
}
}




![[iOS]GCD(一)](https://img-blog.csdnimg.cn/direct/06108a8e4d07487a8ae5822647f1b3bb.png)