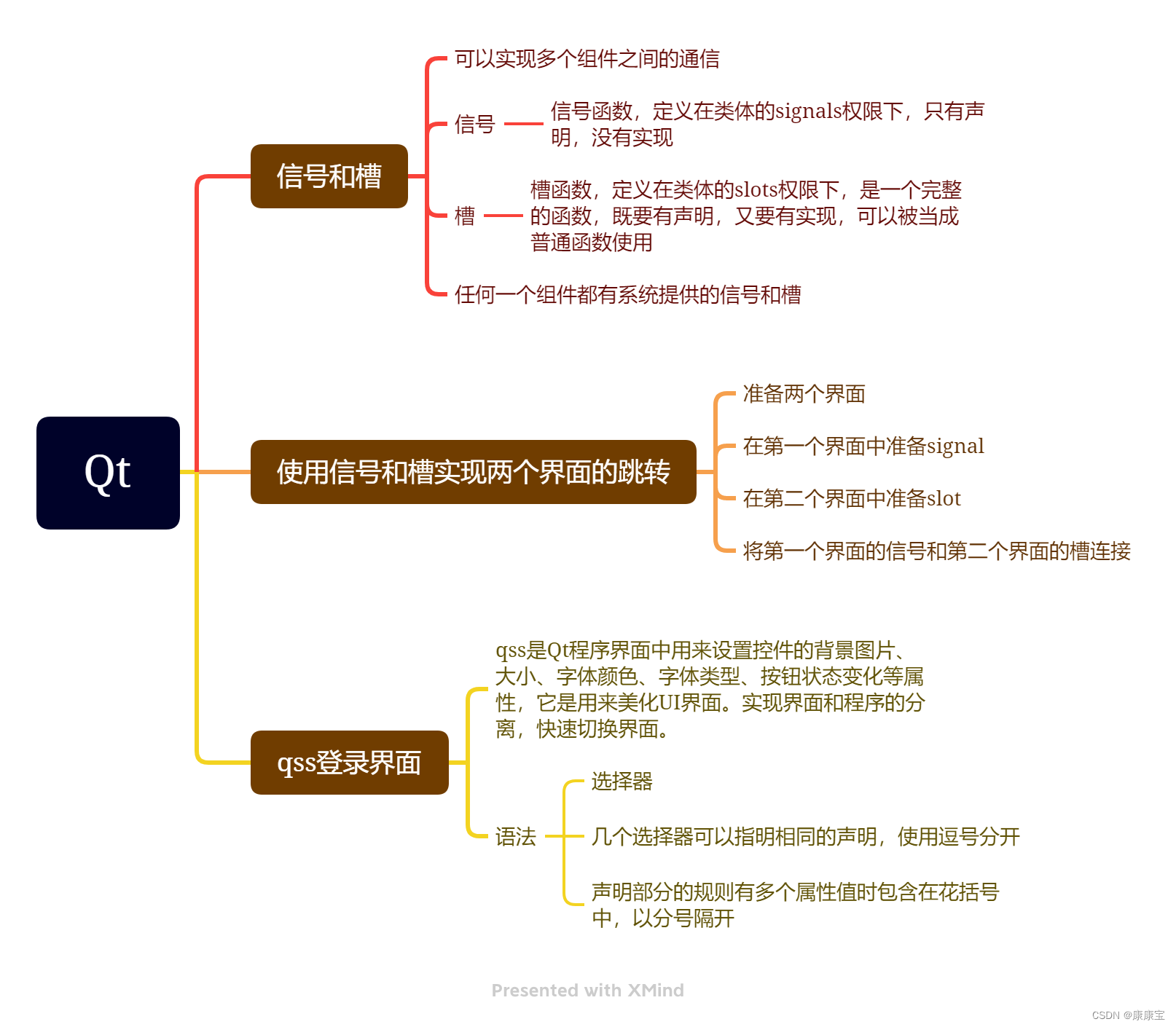
一、 基于用户的协同过滤算法直观感受
假设你在一家大型书店,店主不仅知道你过去的购买记录,还了解其他所有顾客的购买行为。当你要寻找下一本喜欢的书籍时,店主不是根据书籍本身的属性来推荐(比如作者、类型),而是参考了那些与你有着相似购书品味的“好友”。
如果你和另一位用户都喜欢科幻小说A、B和C,并且他还喜欢D,而你还没有读过D,那么基于你们相似的阅读口味,系统就可能推荐科幻小说D给你。
在这里例子中,书店的店主会收集用户的行为数据(例如你的购买行为),协同过滤算法会比较每位用户与其他用户之间的喜好相似度。例如,通过计算两用户对共同看过电影的评级差异程度来量化他们的相似偏好。
一旦找到与你喜好最接近的“邻居”用户又叫做“好友”,系统就会查看这些“邻居”的评价记录中哪些是你还没接触过的,并且他们给予高分的项目,把这些项目推荐给你。
二、 基于用户的协同过滤算法定义
基于用户的协同过滤(User-based Collaborative Filtering, UBCF)是一种推荐系统算法,它可以被形象地比喻成一种“好友建议模式”。这里的“好友”不一定是你真的好朋友,而是指算法计算出你和他具有高度相似性。
图书推荐场景
让我们用一个图书推荐的场景来详细介绍UBCF,有三个用户分别是Alice、Bob和Carol,还有五本小说A,B,C,D,E。如果用户购买了,就标记为1,如果未购买就标记为0。
| 用户 | 小说A | 小说B | 小说C | 小说D | 小说E | 推荐 |
|---|---|---|---|---|---|---|
| Alice | 1 | 1 | 1 | 0 | 0 | 小说D |
| Bob | 1 | 0 | 1 | 1 | 0 | |
| Carol | 1 | 1 | 1 | 1 | 1 |
三、基于用户的协同过滤算法的步骤
(1)收集用户行为数据
创建一个用户-物品评分矩阵,这里虽然没有具体评分数值,但可以将购买行为视为高分1,没有购买视为低分0,就是上面这个表格。
(2)计算用户相似度
这里用余弦相似度为例来计算书籍购买记录中顾客Alice和顾客Carol之间的相似度。余弦值越接近1,表示两个顾客的购买行为越相似。他们两个的购买记录向量在表中可以查到
- 顾客Alice的购买记录向量:Alice = [1, 1, 1, 0, 0]
- 顾客Carol的购买记录向量:Carol = [1, 1, 1, 1, 1]
余弦相似度公式:
计算点积 (A · C),也就是分子部分,对应相乘相加:
计算向量A和向量C的欧几里得范数(向量长度):
带入公式得到:
(3)选择相似用户【检索】
同理,可以把其他用户与Alice的相似度全部计算出来。本例中我们只需要再计算Bob和Alice的余弦相似度就好,让我们再一步步计算一下:
- 第一步、计算Alice和Bob购书记录向量的点积 (A · B)
- 第二步、计算向量A和向量B的欧几里得范数(向量长度)
- 第三步、带入余弦相似度的计算公式
| 用户 | 与Alice的相似度 |
| Carol | 0.7746 |
| Bob | 0.6667 |
(4)生成推荐列表【排序】
对于目标用户Alice,检索其最相似用户的购买记录,找出他们购买了而目标用户未购买的物品。本例中最相似的用户是Carol,它有两本书D和E是Alice没看过的。给定一个阈值或者按照相似用户对该书的喜爱程度加权排序,确定推荐顺序。这里关于加权排序不展开说了,只需要知道小说D被更多的人喜欢,所以排在前面。
| 推荐物品 |
| 小说D |
| 小说E |
由于Alice没有购买D和E,而Carol购买了全部且与Alice有较多的交集,因此推荐的排序就是小说D和E
(5)进行推荐
将最终推荐列表展示给目标用户Alice,如果只推荐1本书的话,就告知Alice系统推荐他尝试购买小说D。
三、基于用户的协同过滤算法有什么缺点?
-
数据稀疏性问题:在实际的用户-物品交互数据集中,往往大部分用户只对一小部分物品有过行为(如评分、购买等),这导致用户间的相似度计算基础不足,数据稀疏性会降低推荐的准确性。
-
冷启动问题:对于新加入系统的用户,由于没有足够的历史行为数据,算法无法为其找到足够相似的用户来进行有效推荐。同样,对于系统中新添加的物品,也难以快速获得推荐。
-
可扩展性受限:随着用户数量的增长,计算用户之间的相似度矩阵变得越来越耗时,内存占用也会大幅度增加。当用户基数庞大时,实时更新和计算用户相似度矩阵成为一项挑战。
-
流行度偏见和同质化问题:倾向于推荐那些已经被很多用户评分或购买的流行物品,而那些较少人知道的物品很难被推荐。用户容易被推荐总是相似的物品,从而降低了推荐多样性,可能会导致用户感到厌倦或失去探索新内容的机会。






![[项目前置]websocket协议](https://img-blog.csdnimg.cn/direct/b6454981b5204de8995e57954ac9b1a3.png)