写在前面:
本次是根据前文讲解的爬虫、数据清洗、分析进行的一个纵隔讲解案例,也是对自己这段时间python爬虫、数据分析方向的一个总结。
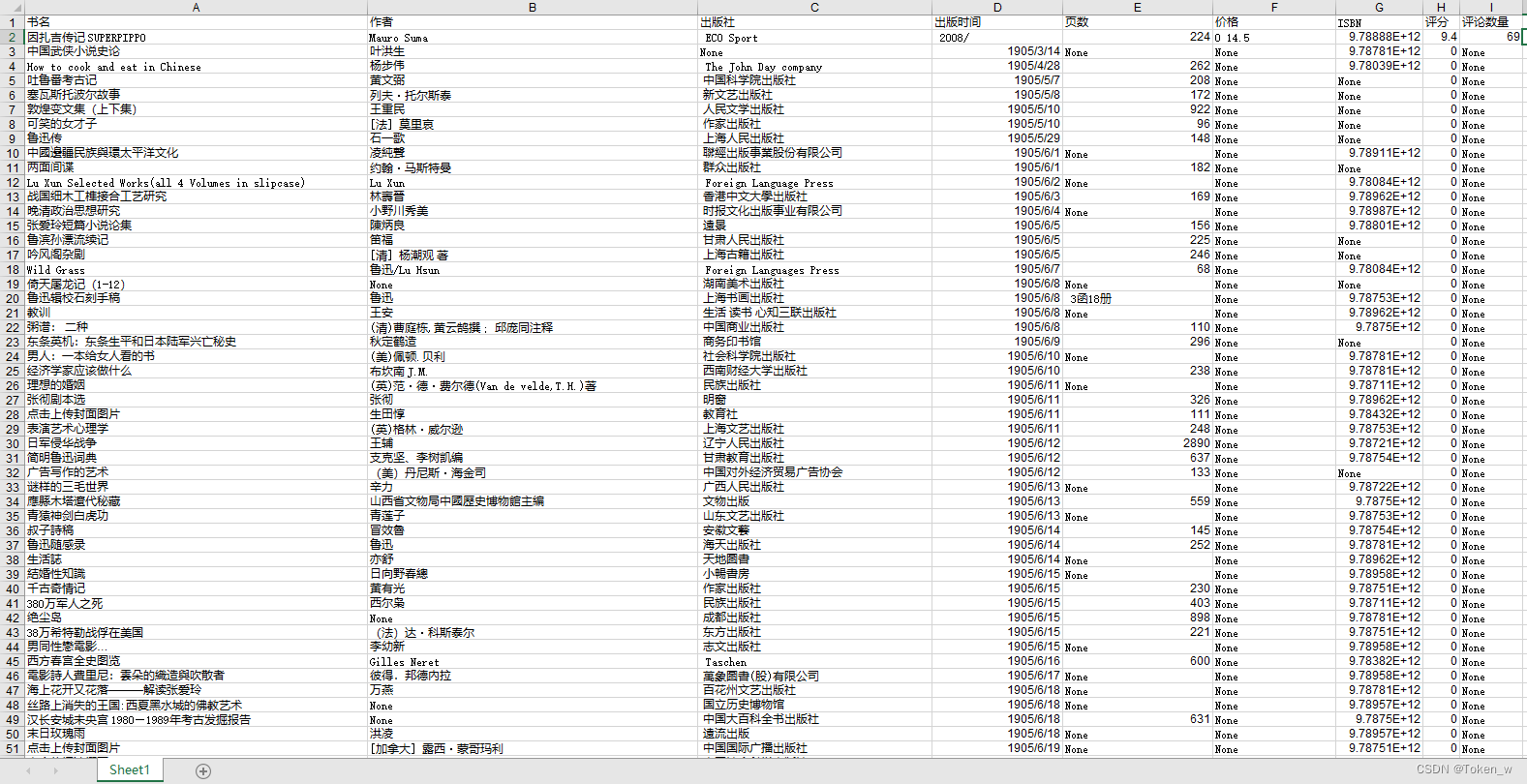
本例设计一个豆瓣读书数据⽂件,book.xlsx⽂件保存的是爬取豆瓣⽹站得到的图书数据,共 60671 条。下⾯进⾏探索性数据分析。
文章目录
- 一、清洗爬取的网站数据
- 1. 导入数据
- 2、清洗方法
- 3. 处理页数数据
- 4.处理价格数据
- 5.处理评论数量数据
- 二、分析爬取的网站数据
- 1.处理出版时间
- 2.分析图书数量与年份的关系
- 3.分析图书评分与年份的关系
- 4.分析图书价格分布情况
- 5.出版图书最多的top20出版社
- 6. 图书评分较高的出版社
- 7. 出书较多的作者
- 8.分析评论和评论数量的关系
- 9.分析评分与评论数量的关系2
一、清洗爬取的网站数据
1. 导入数据
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
plt.rc('font', **{'family':'SimHei'})
# 导⼊数据
df = pd.read_excel('books.xlsx')
# 删除第9列
df = df.drop('Unnamed: 9', axis=1)
2、清洗方法
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
plt.rc('font', **{'family':'SimHei'})
# 导⼊数据
df = pd.read_excel('books.xlsx')
# 删除第9列
df = df.drop('Unnamed: 9', axis=1)
# 对数据做清洗(缺失值与异常值)
df.describe()
df.info()
df.dtypes
"""
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 60671 entries, 0 to 60670
Data columns (total 9 columns):
书名 60671 non-null object
作者 60668 non-null object
出版社 60671 non-null object
出版时间 60671 non-null object
页数 60671 non-null object
价格 60656 non-null object
ISBN 60671 non-null object
评分 60671 non-null float64
评论数量 60671 non-null object
dtypes: float64(1), object(8)
memory usage: 2.3+ MB
"""
3. 处理页数数据
⽬前只要评分是数值型数据,我们还要将⻚数、价格、评论数量转换成数值型数据。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
plt.rc('font', **{'family':'SimHei'})
# 导⼊数据
df = pd.read_excel('books.xlsx')
# 删除第9列
df = df.drop('Unnamed: 9', axis=1)
# 对数据做清洗(缺失值与异常值)
df.describe()
df.info()
df.dtypes
print("---------------------------------")
# 前期分析
print( df['页数'].describe() )
'''
count 60671
unique 2109
top None
freq 4267
Name: 页数, dtype: object
'''
print( df['页数'].isnull().sum() ) # 返回:0 ,这样看不出来
print( len(df[df['页数']=='None']) ) # 返回:4267 , 看看有多少 None 值页数信息
print("---------------------------------")
# 转换
# 定义 convert_to_int ⽅法处理页数数据,如果为 None 则填充 0
import re
def convert2int(x):
if re.match('^\d+$',str(x)):
return x
else:
return 0
df['页数'] = df['页数'].apply(convert2int)
'''
# 或者⽤ lambda 表达式
df['页数'] = df['页数'].apply(lambda x: x if re.match('^\d+$', str(x)) else 0)
df['页数'] = df['页数'].astype(int)
'''
print( df['页数'].describe() )
'''
count 6.067100e+04
mean 6.883281e+06
std 1.695365e+09
min 0.000000e+00
25% 1.940000e+02
50% 2.640000e+02
75% 3.600000e+02
max 4.175936e+11
Name: 页数, dtype: float64
'''
print( df['页数'].isnull().sum() ) # 返回:0
print( len(df[df['页数']=='None']) ) # 返回:0
4.处理价格数据
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
plt.rc('font', **{'family':'SimHei'})
# 导⼊数据
df = pd.read_excel('books.xlsx')
# 删除第9列
df = df.drop('Unnamed: 9', axis=1)
# 对数据做清洗(缺失值与异常值)
df.describe()
df.info()
df.dtypes
print("---------------------------------")
# 处理价格数据
df['价格'] = df['价格'].apply(lambda x: x if re.match('^[\d\.]+$', str(x)) else 0)
df['价格'] = df['价格'].astype(float)
# 价格为 0 的图书数量
print( len(df[df['价格'] == 0]) ) # 3217
5.处理评论数量数据
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
plt.rc('font', **{'family':'SimHei'})
# 导⼊数据
df = pd.read_excel('books.xlsx')
# 删除第9列
df = df.drop('Unnamed: 9', axis=1)
# 对数据做清洗(缺失值与异常值)
df.describe()
df.info()
df.dtypes
print("---------------------------------")
# 处理评论数量数据
df['评论数量'] = df['评论数量'].apply(lambda x: x if re.match('^\d+$', str(x)) else 0)
df['评论数量'] = df['评论数量'].astype(int)
print( df.dtypes )
'''
书名 object
作者 object
出版社 object
出版时间 object
页数 int64
价格 float64
ISBN object
评分 float64
评论数量 int32
dtype: obje
'''
二、分析爬取的网站数据
1.处理出版时间
后⾯需要⽤到年份信息,这⾥先对年份信息进⾏加⼯:处理出版时间,只要年份。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
plt.rc('font', **{'family':'SimHei'})
# 导⼊数据
df = pd.read_excel('books.xlsx')
# 删除第9列
df = df.drop('Unnamed: 9', axis=1)
# 对数据做清洗(缺失值与异常值)
df.describe()
df.info()
df.dtypes
# 处理⻚数数据
# 定义 convert_to_int ⽅法处理页数数据,如果为 None 则填充 0
import re
def convert2int(x):
if re.match('^\d+$',str(x)):
return x
else:
return 0
df['页数'] = df['页数'].apply(convert2int)
# 处理价格数据
df['价格'] = df['价格'].apply(lambda x: x if re.match('^[\d\.]+$', str(x)) else 0)
df['价格'] = df['价格'].astype(float)
# 处理评论数量数据
df['评论数量'] = df['评论数量'].apply(lambda x: x if re.match('^\d+$', str(x)) else 0)
df['评论数量'] = df['评论数量'].astype(int)
print("---------------------------------")
# 处理出版时间,只要年份
def year(s):
y = re.findall('\d{4}',str(s))
if len(y)>0:
return y[0]
return ''
df['出版年份'] = df['出版时间'].apply(year)
# 看看还有多少没有年份信息的
print( len(df[df['出版年份'] == '']) ) # 返回: 1035
2.分析图书数量与年份的关系
# 与上面示例源代码相同,这里省略
print("---------------------------------")
print("---------------------------------")
# 按出版年份进⾏分组
grouped = df.groupby('出版年份')
data = grouped['ISBN'].count()
# 有两条数据⽐较奇怪,处理⼀下
df[df['出版年份'] == '1979']
df.loc[df.index[60632], ['书名', '出版时间', '出版年份']]
"""
书名 鲁迅作品中的绍兴⽅⾔注释
出版时间 1979/初版印
出版年份 1979
Name: 60632, dtype: object
"""
df.loc[df.index[60632], ['出版年份']] = '1979'
df[df['出版年份'] == '2002']
df.loc[df.index[4544], ['书名', '出版时间', '出版年份']]
"""
书名 俄罗斯插画作品集
出版时间 2002/2
出版年份 2002
Name: 4544, dtype: object
"""
df.loc[df.index[4544], ['出版年份']] = '2002'
# 然后按”出版年份“进⾏分组
grouped = df.groupby('出版年份')
data = grouped['ISBN'].count()
print( data )
print("---------------------------------")
# 判断前7条数据和后4条数据属于异常数据,所以删除前7后4的数据
data2 = data[7:-4]
# 准备画图,设置宽⼀点
plt.figure(figsize=(15, 5))
# 设置 x 周标签的倾斜⻆度
plt.xticks(rotation=60)
plt.xlabel('年份')
plt.ylabel('图书数量')
plt.plot(data2.index, data2.values)
plt.show()
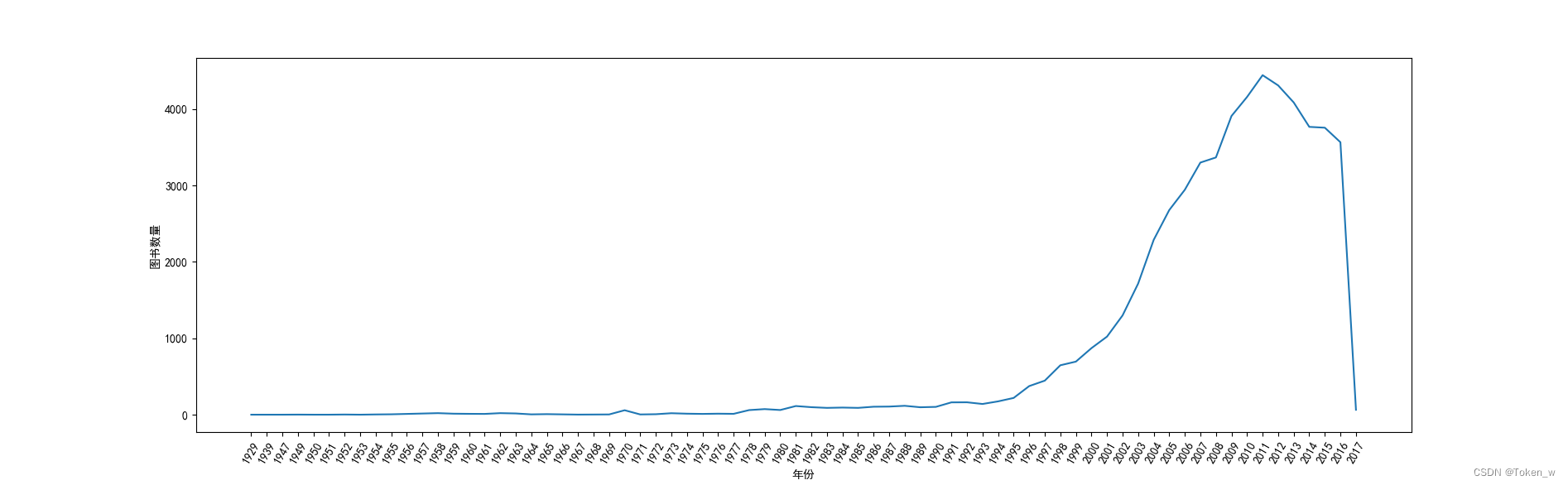
3.分析图书评分与年份的关系
# 与上面示例源代码相同,这里省略
print("---------------------------------")
print("---------------------------------")
# 按出版年份进⾏分组
grouped = df.groupby('出版年份')
data = grouped['ISBN'].count()
# 有两条数据⽐较奇怪,处理⼀下
df[df['出版年份'] == '1979']
df.loc[df.index[60632], ['书名', '出版时间', '出版年份']]
"""
书名 鲁迅作品中的绍兴⽅⾔注释
出版时间 1979/初版印
出版年份 1979
Name: 60632, dtype: object
"""
df.loc[df.index[60632], ['出版年份']] = '1979'
df[df['出版年份'] == '2002']
df.loc[df.index[4544], ['书名', '出版时间', '出版年份']]
"""
书名 俄罗斯插画作品集
出版时间 2002/2
出版年份 2002
Name: 4544, dtype: object
"""
df.loc[df.index[4544], ['出版年份']] = '2002'
# 然后按”出版年份“进⾏分组
grouped = df.groupby('出版年份')
data = grouped['ISBN'].count()
print( data )
print("---------------------------------")
data3 = grouped['评分'].mean()
data3 = data3[7:-4]
# 折线图反映年份和评分之间的关系
# 设置宽⼀点
plt.figure(figsize=(15, 5))
# 设置 x 周标签的倾斜⻆度
plt.xticks(rotation=60)
plt.xlabel('出版年份')
plt.ylabel('评分')
plt.plot(data3.index, data3.values)
# 还要画均值线
m = data3.values.mean()
plt.plot(data3.index, [m]*len(data3.index))
plt.show()
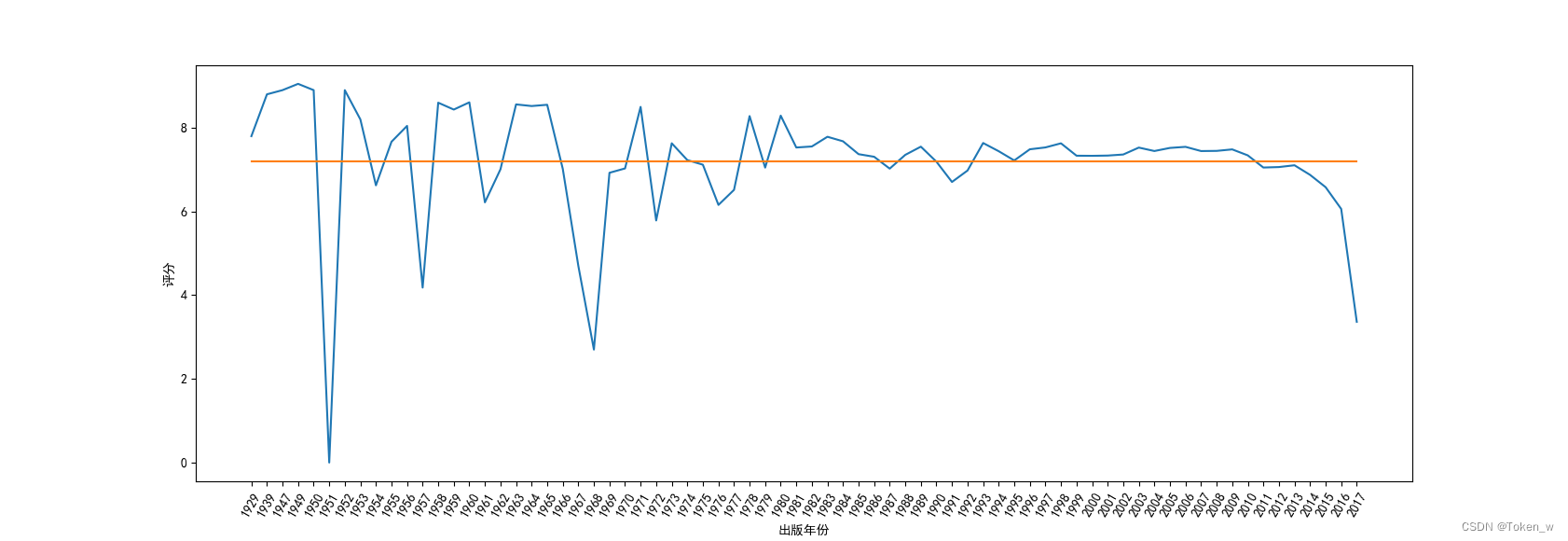
4.分析图书价格分布情况
# 与上面示例源代码相同,这里省略
print("---------------------------------")
print("---------------------------------")
df2 = df[df['价格'] > 0]
# 看看有多少价格⼤于0的
len(df2)
df2['价格'].describe()
# 直⽅图显⽰图书价格分布情况
plt.figure(figsize=(15, 5))
plt.hist(df2['价格'], bins=40, range=(0, 200), rwidth=0.8)
plt.show()
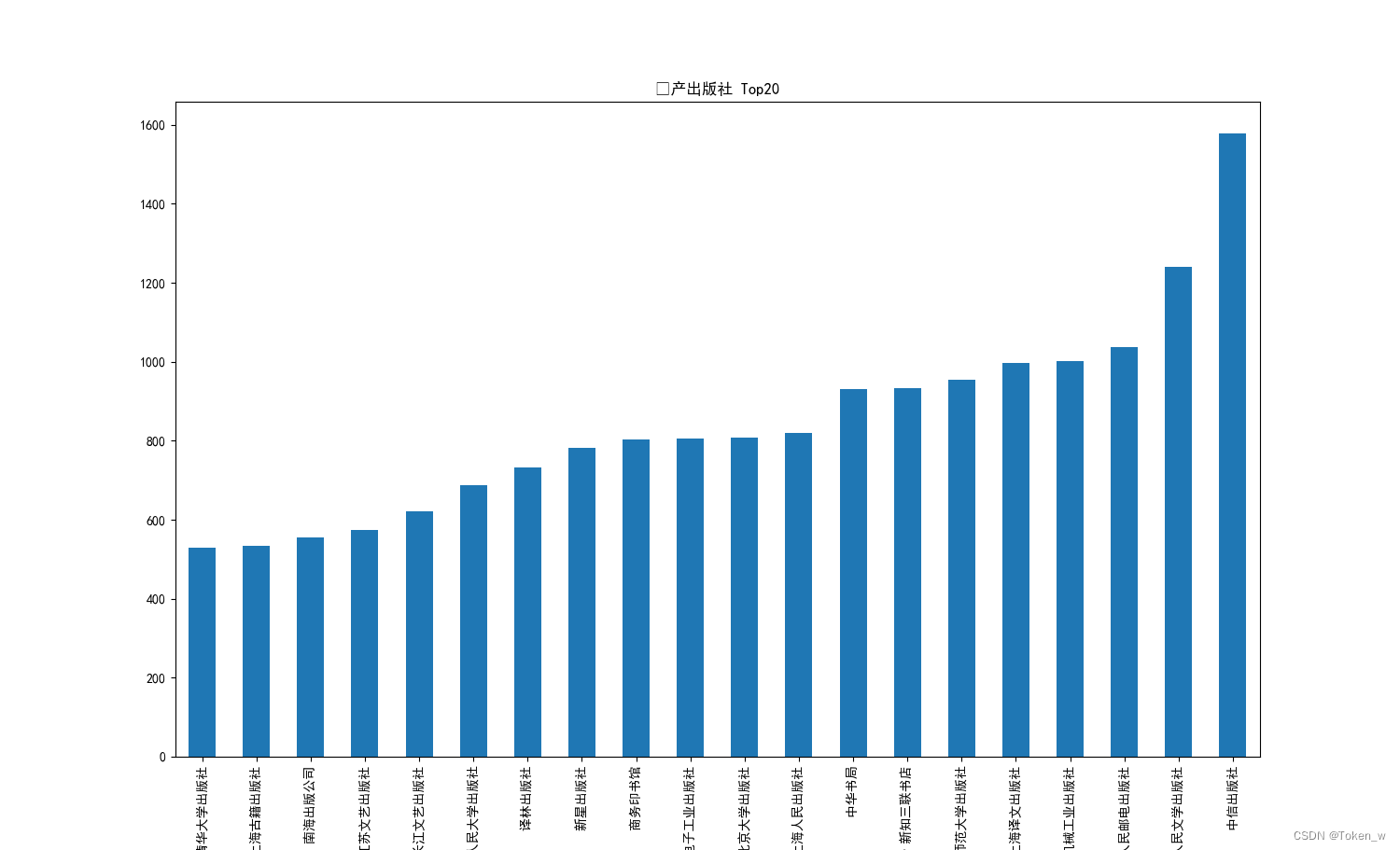
5.出版图书最多的top20出版社
# 与上面示例源代码相同,这里省略
print("---------------------------------")
print("---------------------------------")
# 出版书籍最多的20个出版社
data4 = df.groupby('出版社')['ISBN'].count()
plt.figure(figsize=(15, 5))
plt.title('⾼产出版社 Top20')
# 最多的是 None,要去掉,所以选择 -21:-1
data4.sort_values()[-21:-1].plot(kind='bar')
plt.show()
6. 图书评分较高的出版社
# 与上面示例源代码相同,这里省略
print("---------------------------------")
print("---------------------------------")
# 评分较⾼的出版社
plt.figure(figsize=(15, 5))
plt.title('好评出版社 Top20')
data5 = df.groupby('出版社')['评分'].mean()
data5.sort_values()[-20:].plot(kind='bar')
plt.show()
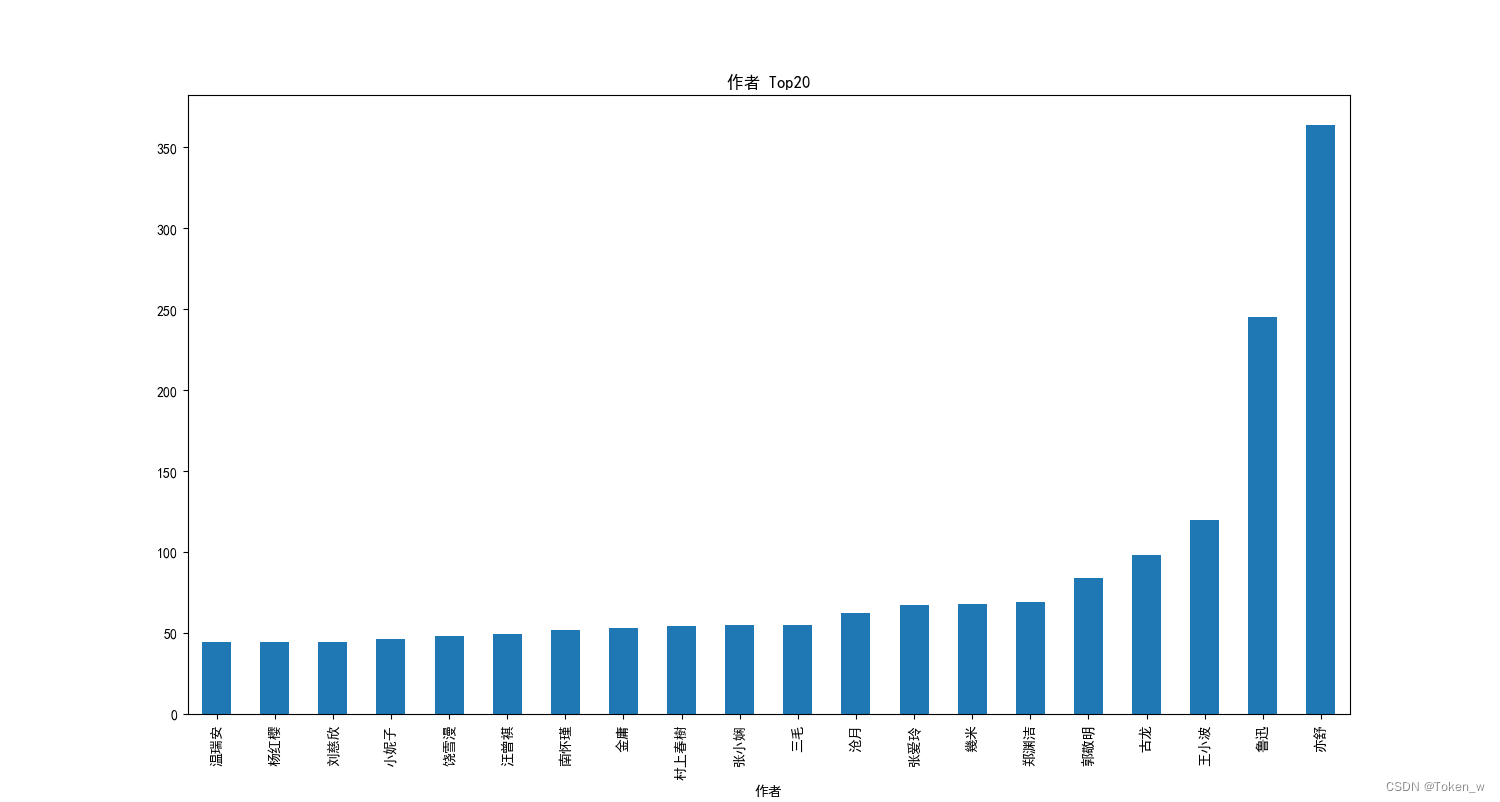
7. 出书较多的作者
# 与上面示例源代码相同,这里省略
print("---------------------------------")
print("---------------------------------")
# 出书较多的作者
plt.figure(figsize=(15, 5))
plt.title('作者 Top20')
data6 = df.groupby('作者')['ISBN'].count()
data6.sort_values()[-21:-1].plot(kind='bar')
plt.show()
8.分析评论和评论数量的关系
# 与上面示例源代码相同,这里省略
print("---------------------------------")
print("---------------------------------")
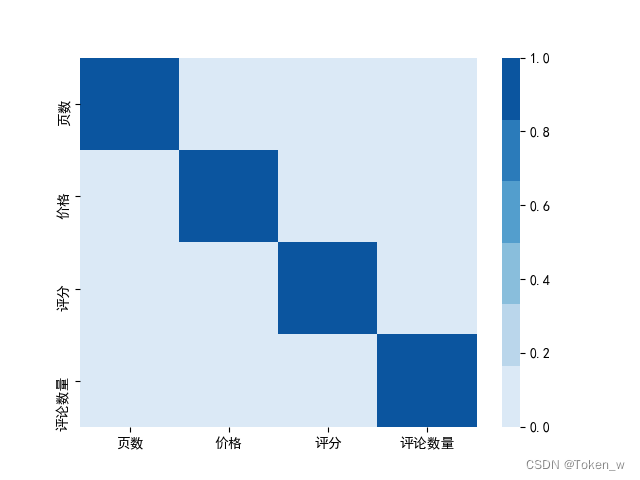
print( df.corr() )
'''
页数 价格 评分 评论数量
页数 1.000000 -0.000030 0.003157 -0.000658
价格 -0.000030 1.000000 0.001443 -0.001673
评分 0.003157 0.001443 1.000000 0.063536
评论数量 -0.000658 -0.001673 0.063536 1.000000
'''
9.分析评分与评论数量的关系2
# 与上面示例源代码相同,这里省略
print("---------------------------------")
print("---------------------------------")
# 评分⾼低与评论数量之间是否存在某种关系
# 当系统中安装多个Python版本时,可能存在无法导入问题,可以使用下面2行代码,指定要加载的seaborn文件所在的路径。
# 如果不存在加载问题,可以删除下面2行代码。
import sys
sys.path.append('C:\ProgramData\Anaconda3\Lib\site-packages')
# 加载seaborn
'''
Seaborn是在matplotlib的基础上进行了更高级的API封装,从而使得作图更加容易,
在大多数情况下使用seaborn能做出很具有吸引力的图,而使用matplotlib就能制作具有更多特色的图。
应该把Seaborn视为matplotlib的补充,而不是替代物。
同时它能高度兼容numpy与pandas数据结构以及scipy与statsmodels等统计模式。
'''
import seaborn as sns
# 计算相关性矩阵
corr = df.corr()
sns.heatmap(corr, cmap=sns.color_palette('Blues'))
plt.show()
写在最后:希望大家可以学到用到,多多支持!!!