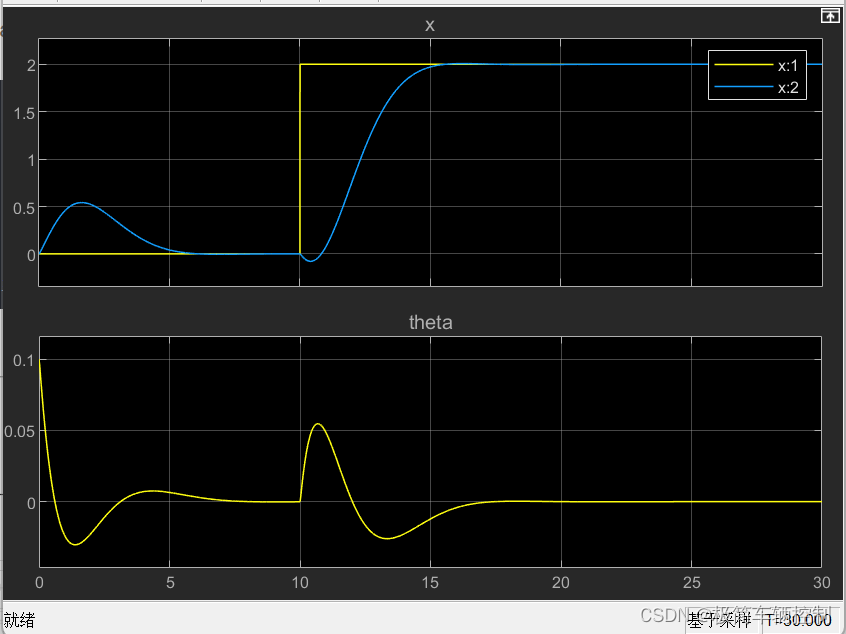
一、前言
在大多数传统的web系统中,使用Redis一般都是作为缓存使用,在大数据查询时作为缓解性能的一种解决方案。博主的的系统中使用Redis也主要使用到缓存的作用,还有做了注册中心,分布式事务。其他的强大的功能,没有运用上。下面看一张图,看看Redis高阶还能用到哪些常见的场景。
二、Redis高阶用法
- 消息队列:Redis的列表数据结构非常适合作为简单的消息队列。消息发布者可以使用LPUSH命令向队列中添加消息,而多个消息订阅者则可以通过阻塞线程使用BRPOP命令从队列中取出消息。需要注意的是,Redis官方并不提供可靠消费/发布的机制,因此需要自行实现故障转移、队列持久化、队列监控和流量控制等功能。
- Lua脚本:Redis支持使用Lua脚本在服务器端执行一系列命令。这有助于减少客户端与服务器之间的网络开销,并且可以实现复杂的原子操作。
- 事务:Redis支持事务,可以将一系列命令作为一个原子操作来执行。这通过MULTI、EXEC、DISCARD和WATCH等命令来实现,确保在事务执行期间,中间步骤不会被其他客户端打断。
- 分布式锁:Redis可以利用SET命令的NX(不覆盖)参数来实现分布式锁。获取锁的客户端可以执行临界区的代码,而其他客户端则需要等待锁的释放。
public String lock(String key, int timeOutSecond) {
for (; ; ) {
String stamp = String.valueOf(System.nanoTime());
boolean exist = redisTemplate.opsForValue().setIfAbsent(key, stamp, timeOutSecond, TimeUnit.SECONDS);
if (exist) {
return stamp;
}
}
}
public void unlock(String key, String stamp) {
redisTemplate.execute(script, Arrays.asList(key), stamp);
}- 排行榜:Redis的有序集合数据结构(zset)非常适合用来实现排行榜功能。例如,可以通过zadd命令添加分数和成员,然后使用zrevrange命令获取排名最高的成员。
- HyperLogLog:这是Redis用于基数统计的算法。当输入元素的数量或体积非常大时,HyperLogLog所需的计算空间总是固定的且很小。通过pfadd命令添加元素,然后使用pfcount命令获取基数统计结果。
- 过期键管理:Redis可以为键设置过期时间,过期后键会自动被删除。这对于缓存系统特别有用,可以避免长时间占用内存。
redis的数据结构丰富,一般不会在功能性上造成困扰。但随着请求量的增加,SLA要求的提高,我们势必会对Redis进行一些改造和定制性开发。
高可用挑战
redis提供了主从、哨兵、cluster等三种集群模式,其中cluster模式为目前大多数公司所采用的方式。
但是,redis的cluster模式,有不少的硬伤。redis cluster采用虚拟槽的概念,把所有的key映射到 0~16383个整数槽内,属于无中心化的架构。但它的维护成本较高,slave也不能够参与读取操作。
它的主要问题,在于一些批量操作的限制。由于key被hash到多台机器上,所以mget、hmset、sunion等操作就非常的不友好,经常发生性能问题。
redis的主从模式是最简单的模式,但无法做到自动failover,通常在主从切换后,还需要修改业务代码,这是不能忍受的。即使加上haproxy这样的负载均衡组件,复杂性也是非常高的。
哨兵模式在主从数量比较多的时候,能够显著的体现它的价值。一个哨兵集群,能够监控成百上千个集群,但是哨兵集群本身的维护是比较困难的。幸运的是,redis的文本协议非常简单,在netty中,甚至直接提供了redis的codec。自研一套哨兵系统,加强它的功能,是可行的。
冷热数据分离
redis的特点是,不管什么数据,都一股脑地搞到内存里做计算,这对于有时间序列概念,有冷热数据之分的业务,造成了非常大的成本考验。为什么大多数开发者喜欢把数据存放在MySQL中,而不是Redis中?除了事务性要求以外,很大原因是历史数据的问题。
通常,这种冷热数据的切换,是由中间件完成的。我们上面也谈到了,Redis是一个文本协议,非常简单。做一个中间件,或者做一个协议兼容的Redis模拟存储,是比较容易的。
比如我们Redis中,只保留最近一年的活跃用户。一个好几年不活跃的用户,突然间访问了系统,这时候我们获取数据的时候,就需要中间件进行转换,从容量更大,速度更慢的存储中查找。
这个时候,Redis的作用,更像是一个热库,更像是一个传统cache层做的事情,发生在业务已经上规模的时候。但是注意,直到此时,我们的业务层代码,一直都是操作的redis的api。它们使用这众多的函数指令,并不关心数据到底是真正存储在redis中,还是在ssdb中。
功能性需求
redis还能玩很多花样。举个例子,全文搜索。很多人都会首选es,但redis生态就提供了一个模块:RediSearch,可以做查询,可以做filter。
但我们通常还会有更多的需求,比如统计类、搜索类、运营效果分析等。这类需求与大数据相关,即使是传统的DB也不能胜任。这时候,我们当然要把redis中的数据,导入到其他平台进行计算啦。
如果你选择的是redis数据库,那么dba打交道的,就是rdb,而不是binlog。有很多的rdb解析工具(比如redis-rdb-tools),能够定期把rdb解析成记录,导入到hadoop等其他平台。
此时,rdb成为所有团队的中枢,成为基本的数据交换格式。导入到其他db后的业务,该怎么玩怎么玩,完全不会因为业务系统选用了redis就无法运转。