事先说明:
由于每次都要导入库和处理中文乱码问题,我都是在最前面先写好,后面的代码就不在写了。要是copy到自己本地的话,就要把下面的代码也copy下。
# 准备工作
import pandas as pd
import numpy as np
from matplotlib import pyplot as plt
import matplotlib
matplotlib.rc("font",family="FangSong")First
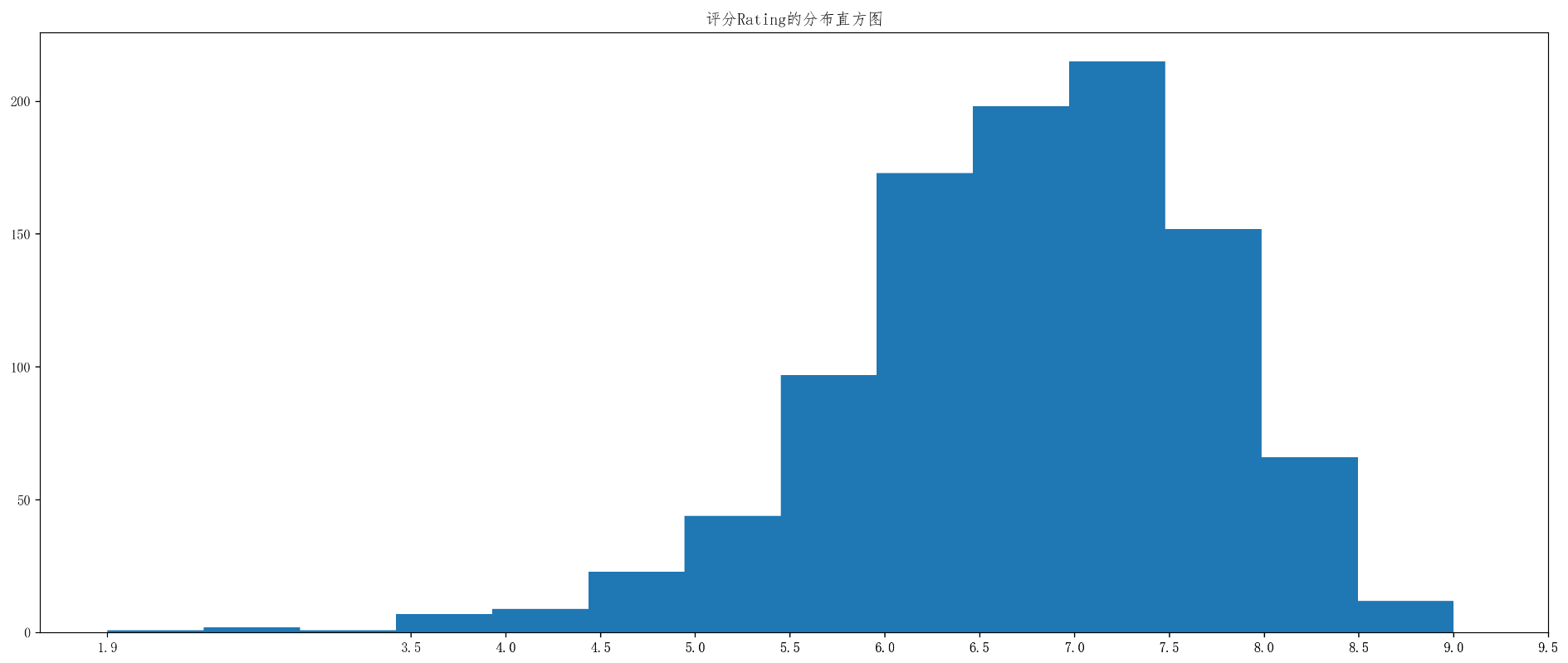
需求:给定最流行的1000部电影的相关的数据,统计Rating和runtime的分布情况
分析
- 毫无疑问,分布情况肯定是直方图
- 把所有数据中是
runtime和Rating的列选出来 - 求极差,设置组距
- 设置/绘制直方图
代码
# 统计最流行1000部电影的Rating和runtime分布情况
file_path = "./IMDB-Movie-Data.csv"
df = pd.read_csv(file_path)
# print(df.head(1))
# print(df.info())
#rating,runtime分布情况
#选择图形,直方图
#准备数据
runtime_data = df["Runtime (Minutes)"].values
# 计算极差
max_runtime = runtime_data.max()
min_runtime = runtime_data.min()
# 计算组数
# print(max_runtime-min_runtime)
num_runtime = int((max_runtime-min_runtime)//5)
#设置图形的大小
plt.figure(figsize=(20,8),dpi=200)
plt.hist(runtime_data,num_runtime)
_x = [min_runtime]
i = min_runtime
while i<=max_runtime+25:
i = i+5
_x.append(i)
plt.xticks(_x,rotation=45)
plt.title("时长runtime的分布直方图")
plt.show()# 准备数据
Ratint_data = df["Rating"].values
max_Rating = Ratint_data.max()
min_Rating = Ratint_data.min()
num_Rating = int((max_Rating-min_Rating)//0.5)
plt.figure(figsize=(20,8),dpi=200)
plt.hist(Ratint_data,num_Rating)
# 设置不等宽组距_
x=[1.9,3.5]
i=3.5
while i<max_Rating+0.5:
i+=0.5
_x.append(i)
plt.xticks(_x)
plt.title("评分Rating的分布直方图")
plt.show()效果

Second
需求:给定最流行的1000部电影的相关的数据,统计这些电影的类型
分析
- 毫无疑问,连续数据的分布用条形图
- 选出电影中类型的那一列数据
- 用相关方法把其变成列表
- 构造全零数组
- 遍历每个电影。如果有该类型,则赋值为1,否则不变
- 排序
- 绘制条形图
代码
# 统计最流行1000部电影的类型
# 准备数据
file_path="IMDB-Movie-Data.csv"
df=pd.read_csv(file_path)
# print(df["Genre"].head())
# 统计电影的类型
temp_list=df["Genre"].str.split(",").tolist()
# print(temp_list)
genre_list=list(set(i for j in temp_list for i in j))
# print(genre_list)
# 构造全零的数组
zeros_df=pd.DataFrame(np.zeros((df.shape[0],len(genre_list))),columns=genre_list)
# print(zeros_df.head())
# 给每个电影存在的类型赋值为1
for i in range(df.shape[0]):
zeros_df.loc[i,temp_list[i]]=1
# print(zeros_df.head())
# 统计每种类型的电影的和
genre_count=zeros_df.sum(axis=0)
# print(genre_count)
# 排序
genre_count=genre_count.sort_values()
# print(genre_count)
_x=genre_count.index
_y=genre_count.values
# print(_x,_y)
# 绘制条形图
plt.figure(figsize=(20,8),dpi=200)
plt.bar(range(len(_x)),_y)
plt.xticks(range(len(_x)),_x)
plt.xlabel("电影类型")
plt.ylabel("电影数量")
plt.title("最流行的1000部电影的分类")
plt.show()效果

思考学习
- 某一列是字符串类型,并且有多个值。我们可以通过此题学到一种解决办法(以后可以套用):
-
- 用字符串方法进行切割
- 转化成列表
- 两层循环取出类型
# 通过字符串的方法,进行切割
temp_list=df["Genre"].str.split(",").tolist()
# 套用两层循环,用set是去重
genre_list=list(set(i for j in temp_list for i in j))- 对于某一特征有多个属性,而我们要统计属性的数量。我们可以通过此题学到一种解决办法(以后可以套用):
-
- 构造全零数组(维度根据实际情况来,一般情况下,0轴是样本数量,1轴是属性数量,列标签也是属包含所有属性),
0表示没有这种属性 - 遍历每个样本的该特征的所有属性,如果有,则将该位置的值变为
1 - 统计,求和
- 构造全零数组(维度根据实际情况来,一般情况下,0轴是样本数量,1轴是属性数量,列标签也是属包含所有属性),
# 构造全零的数组
zeros_df=pd.DataFrame(np.zeros((df.shape[0],len(genre_list))),columns=genre_list)
# print(zeros_df.head())
# 给每个电影存在的类型赋值为1
for i in range(df.shape[0]):
zeros_df.loc[i,temp_list[i]]=1
# print(zeros_df.head())
# 统计每种类型的电影的和
genre_count=zeros_df.sum(axis=0)
# print(genre_count)Third
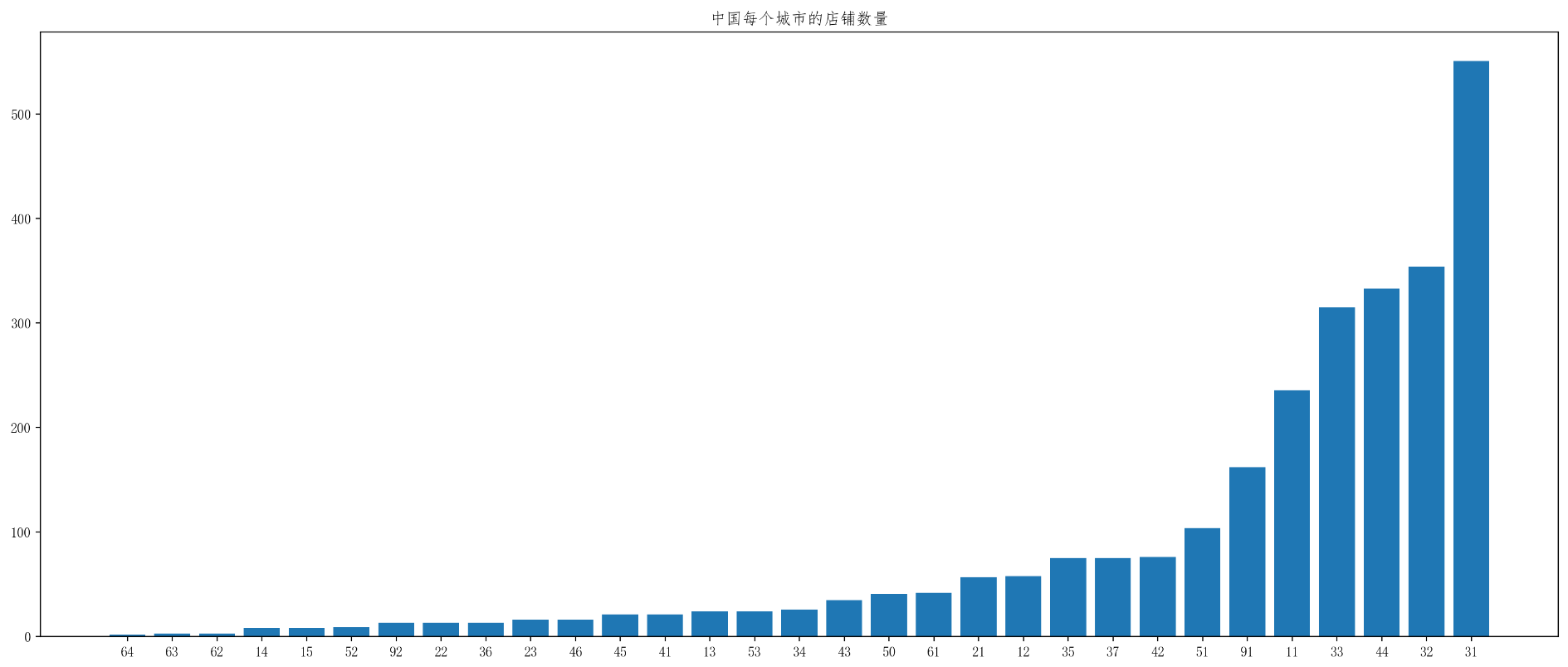
需求:给定Starbucks所有店铺的相关数据,求中美两国Starbucks的数量,绘制店铺总数前十的国家的图,绘制中国每个城市(省市)的店铺数量的图
分析
- 统计中美两国Starbucks的数量:
- 用
pandas自带的分组操作,按国家Country分类 - 用聚合
count方法 - 选出中美两国
- 绘制店铺总数前十的国家的图:
- 根据第一问的数据,进行排序
- 绘制图形
- 绘制图形呈现中国每个城市的店铺数量:
- 找出中国的数据
- 用
pandas自带的分组操作,按省市State/Province分类 - 用聚合
count方法 - 绘制图形
代码
# 统计中美两国Starbucks的数量
# 准备数据
file_path="starbucks_store_worldwide.csv"
df=pd.read_csv(file_path)
# print(df.head())
# 根据国家分组
country_data=df.groupby(by="Country")
# print(country_data)
# for country,values in country_data:
# print(country)
# print(values)
# 测试,看country_data统计出来的是什么数据
# t=country_data["Ownership Type"]
# t=country_data["Brand"]
# print(t)
# for i in t:
# print(i)
# 调用聚合方法,得到答案
# country_count=country_data["Ownership Type"].count().sort_values()
country_count=country_data["Brand"].count().sort_values()
# print(country_count)
print("美国Starbucks数量:"+str(country_count["US"]))
print("中国Starbucks数量:"+str(country_count["CN"]))# 绘制店铺总数前十的国家的图
country_max=country_count[-10:]
# print(country_max)
_x=country_max.index
_y=country_max.values
# print(_x)
# print(_y)
plt.figure(figsize=(20,8),dpi=200)
plt.bar(range(len(_x)),_y)
plt.xticks(range(len(_x)),_x)
plt.title("starbucks店铺总数前十的国家")
plt.show()# 绘制图形呈现中国每个城市的店铺数量
china_data=df[df["Country"]=="CN"]
# print(china_data)
china_province=china_data.groupby(by="State/Province")
# for province,values in china_province:
# if(int(province)==31):
# print(province)
# print(values)
china_province=china_province["Brand"].count().sort_values()
# print(china_province)
_x=china_province.index
_y=china_province.values
plt.figure(figsize=(20,8),dpi=200)
plt.bar(range(len(_x)),_y)
plt.xticks(range(len(_x)),_x)
plt.title("中国每个城市的店铺数量")
plt.show()效果
![]()

思考学习
- 学会使用
pandas自带的分组操作,注意操作之后得到的迭代器(应该是迭代器,毕竟不能直接看数据,但是支持遍历等操作) - 对于上一步得到的迭代器,使用聚合
count可以直接统计出各个组内的数据数量
Fourth
需求:给出全球排名前10000本书相关数据,统计不同年份的书籍数量,不同年份的书籍的平均评分情况
分析
相信经过前面三个案例的练习,这个案例应该可以轻松解决👀。所以,我就偷个懒,不写分析了😝
代码
# 不同年份书籍的数量
file_path="books.csv"
df=pd.read_csv(file_path)
year_data=df[pd.notnull(df["original_publication_year"])].groupby(by="original_publication_year").count()["id"]
# year_data=df.groupby(by="original_publication_year").count()["id"]
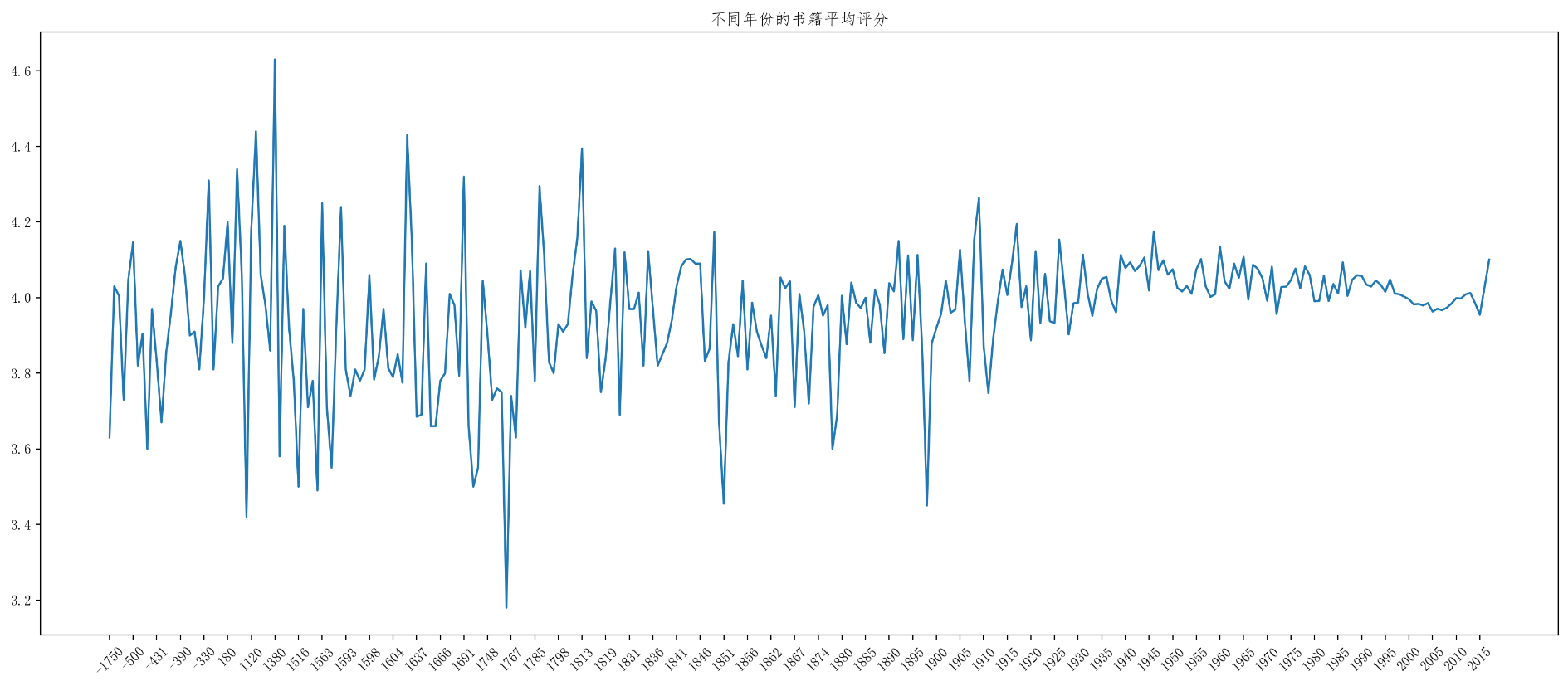
print(year_data)# 不同年份的书籍平均评分
rating_data=df[pd.notnull(df["original_publication_year"])]
rating_mean=rating_data["average_rating"].groupby(by=rating_data["original_publication_year"]).mean()
_x=rating_mean.index
_y=rating_mean.values
plt.figure(figsize=(20,8),dpi=200)
plt.plot(range(len(_x)),_y)
plt.xticks(list(range(len(_x)))[::5],_x[::5].astype(int),rotation=45)
plt.title("不同年份的书籍平均评分")
plt.show()效果