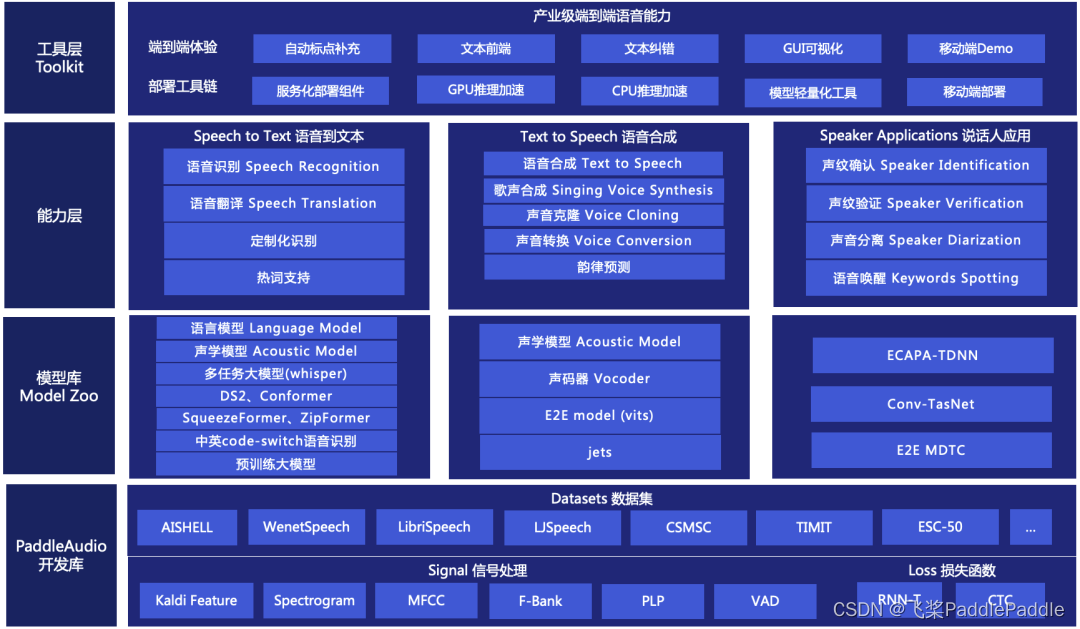
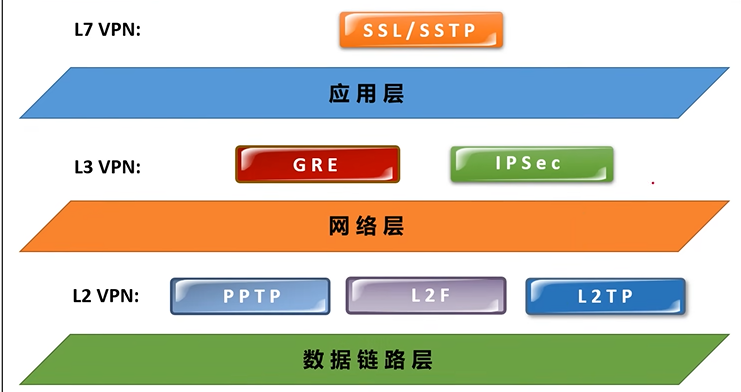
文章目录
- 1.摘要
- 2.图片的准备及预处理
- 3.打包并保存数据
- 4.搭建模型
- 5.训练模型
- 6.测试模型
- 7.总结
1.摘要
图像分类,也可以称作图像识别,顾名思义,就是辨别图像中的物体属于什么类别。核心是从给定的分类集合中给图像分配一个标签的任务。实际上,这意味着我们的任务是分析一个输入图像并返回一个将图像分类的标签,而卷积神经网络(Convolutional Neural Networks, CNN)是一类包含卷积计算且具有深度结构的前馈神经网络(Feedforward Neural Networks),非常适合做图片分类任务,是计算机视觉中应用最广泛的方法,通过指定卷积大小,窗口移动大小,一步步的移动来学习数据特征,每次学习计算卷积层后,计算一次最大的池化层,这样可防止过拟合,降低维度,经过反复传播训练,直到最优解。
为此,本篇将实现CNN进行图像分类的整个全流程,包括:1.图片的准备预处理;2.图片的数据集的打包;3.CNN模型的搭建;4.模型的训练;5.结果测试。希望对读者有所帮助。
2.图片的准备及预处理
首先,本文准备的数据集是皮肤病的病理图片,分为两类,包括:melanoma(黑素瘤),nevus(痣),共计510张图片。为方便大家进行学习,我将图片的链接放在此处,供大家使用。链接:https://pan.baidu.com/s/1EJBRQ52sVZMgjhVlgP8qMQ
提取码:duc4
在这里,由于数据集中的照片太大,本文使用笔记本进行训练,计算性能有限,我将RGB图片转换为灰度图,并将尺寸统一为500*500,减小数据量导入CNN模型,读者可根据自己电脑性能进行调节参数,提升识别准确率。
import numpy as np
import cv2
import os,glob,tqdm
from sklearn.preprocessing import OneHotEncoder
from sklearn.model_selection import train_test_split
# 搭建模型
import tensorflow as tf
from tensorflow.keras.layers import Dense,Conv2D,MaxPool2D,Flatten
from tensorflow.keras import optimizers,losses
import matplotlib.pyplot as plt
%matplotlib inline
查看数据集中的一张照片ISIC_0012258.jpg,及大小
img = cv2.imread('./picture_set/datasets1/melanoma/ISIC_0012258.jpg')
plt.imshow(cv2.cvtColor(img,cv2.COLOR_BGR2RGB))
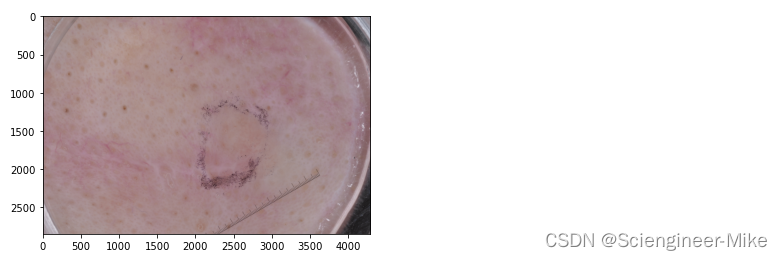
img.shape

定义一个函数,将数据集中的图片转换为灰度图,大小转化为5005001的大小。
# 准备两个列表,存放数据和标签
img_list,label_list = [],[]
labels = os.listdir("./picture_set/datasets1/")
# 遍及所有文件夹
for label in labels:
file_list = glob.glob('./picture_set/datasets1/%s/*.jpg'%label)
# 遍及每一张照片
for img_file in tqdm.tqdm(file_list,desc="处理%s"%label):
# 读取图片
img = cv2.imread(img_file)
# 转换为灰度图
img_gray = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
# 改变尺寸
img_resize = cv2.resize(img_gray,(500,500))
# 增加维度
img_resize_ = np.expand_dims(img_resize,axis=2)
img_list.append(img_resize_)
label_list.append(label)

np.array(img_list).shape,np.array(label_list).shape

3.打包并保存数据
第二章节我们已经对数据进行了预处理,这部分我将数据打包为npz格式的数据,方便后面建模导入模型方便。打包代码很简单,如下:
X = np.array(img_list)
y = np.array(label_list)
#存储为numpy文件
np.savez('img_data.npz',X,y)
打包完成后,将会在目录下有个img_data.npz文件。
4.搭建模型
首先对刚才的打包数据进行解析,并查看我们的数据集和标签。
# 读取npz文件
data = np.load('img_data.npz')
img_list = data["arr_0"]
label_list = data["arr_1"]
img_list.shape,label_list.shape
数据集的特征尺寸为(510,500,500,1),标签值为(500,)

可以看到模型的标签为两类(melanoma,nevus)
print("类别名称:",np.unique(label_list))
print("打印标签:",label_list)

接下来,我将对标签值进行独热编码,方便模型导入。代码如下:
OE = OneHotEncoder()
label = OE.fit_transform(np.expand_dims(label_list,1))
y = label.toarray()
y[:10]

我对所有的病理图片进行分割,以便更好的训练网络,通过sklearn库的train_test_split()将图片划分完训练集和测试集,到此数据集准备完成。
x_train,x_test,y_train,y_test = train_test_split(img_list,y,test_size=0.15,random_state=0,shuffle=True)
print(x_train.shape,y_train.shape,x_test.shape,y_test.shape)
数据集准备完成,接下来搭建CNN模型。
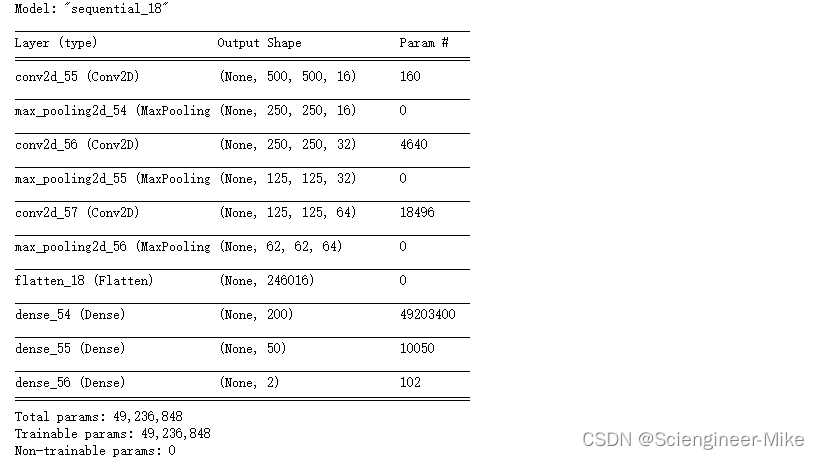
new_model = tf.keras.Sequential([
Conv2D(16,3,padding="same",input_shape=(500,500,1),activation="relu"),
MaxPool2D((2,2)),
Conv2D(32,3,padding="same",activation="relu"),
MaxPool2D((2,2)),
Conv2D(64,3,padding="same",activation="relu"),
MaxPool2D((2,2)),
Flatten(),
Dense(200,activation="relu"),
Dense(50,activation="relu"),
Dense(2,activation="softmax")
])
new_model.compile(optimizer=optimizers.Adam(learning_rate=0.0001),loss=losses.categorical_crossentropy,metrics=["accuracy"])
new_model.summary()
5.训练模型
history = new_model.fit(x_train,y_train,validation_data=(x_test,y_test),batch_size=30,epochs=10)

笔记本性能有限,感兴趣的可以自己增大训练epoch,调整模型参数等等。接下来,可视化模型准确度和损失。代码如下:
plt.plot(history.history["loss"],label="train_set")
plt.plot(history.history["val_loss"],label="test_set")
plt.title('model loss')
plt.xlabel("epoch")
plt.ylabel("loss")
plt.legend()
plt.show()

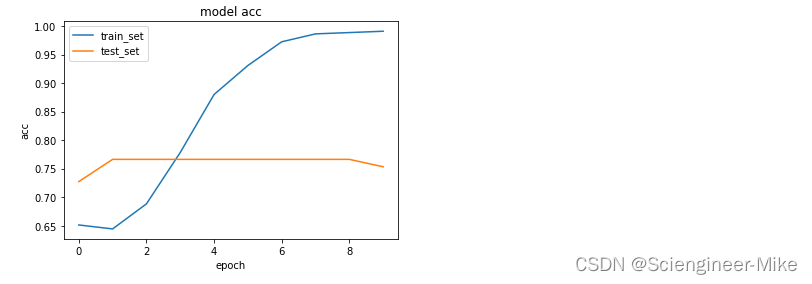
plt.plot(history.history["acc"],label="train_set")
plt.plot(history.history["val_acc"],label="test_set")
plt.title('model acc')
plt.xlabel("epoch")
plt.ylabel("acc")
plt.legend()
plt.show()
完成训练后,我们将模型进行保存,方便后续进行部署使用。
new_model.save("mp.h5")
6.测试模型
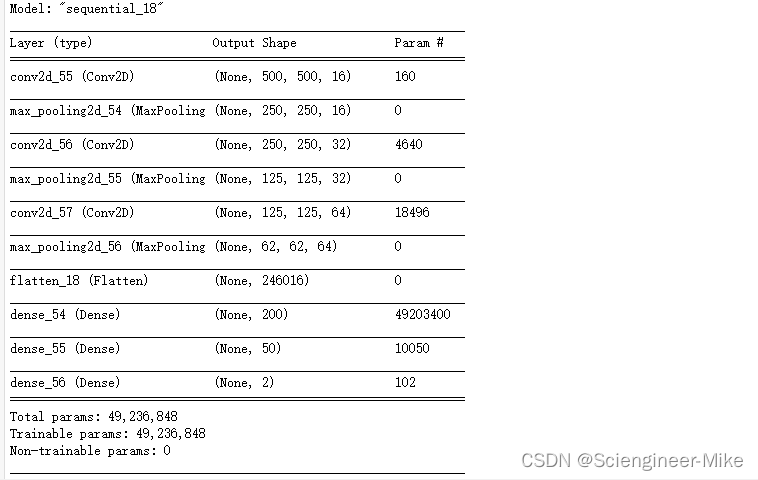
加载模型并查看模型结构
model = tf.keras.models.load_model("mp.h5")
model.summary()
导入成功之后,将测试图片导入,我提取了数据集中的一张图片进行测试,标签为melanoma
# 提取中数据集中的一张图片进行测试---标签为melanoma
img_test = cv2.imread('./picture_set/datasets1/melanoma/ISIC_0012258.jpg')
img_test_gray = cv2.cvtColor(img_test,cv2.COLOR_BGR2GRAY)
img_test_resize = cv2.resize(img_test_gray,(500,500))
img_test_resize_ = np.expand_dims(img_test_resize,axis=2)
img_input = np.expand_dims(img_test_resize_,axis=0)
pred = model.predict(img_input)
pred
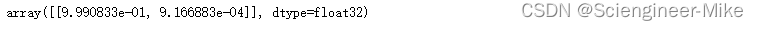
print("照片melanoma预测的标签为:",labels[np.argmax(pred)])

7.总结
到这里,我们完成了整个图片识别的全流程,从数据准备到CNN建模,从训练模型到模型预测,通过皮肤病数据集,为大家完整的展示了深度学习在图片分类中的完整流程,希望对大家工作学习中有所帮助。





![sqlserver连接时报错 [IM002] [Microsoft][ODBC 驱动程序管理器] 未发现数据源名称并且未指定默认驱动程序](https://img-blog.csdnimg.cn/b7531b45aed64f3db1bc0ba11f1ac354.png)