相关文章
【论文精读】Transformer:Attention Is All You Need
文章目录
- 相关文章
- 一、文章概览
- (一)研究背景
- (二)核心思路
- (三)相关工作
- (三)文章结论
- 二、模型细节
- (一)组成模块
- (二)模型的大体流程
- (三)具体的模型的前向过程
- (四)transformer encoder的公式表达
- (五)消融实验
- 1、关于图像分类编码方式的消融实验
- 2、关于位置编码的消融实验
- 三、实验
- (一)模型的变体
- (二)分类精度结果对比
- (三)数据集的大小对ViT的影响
- (四)BiT、ViT、Hybrids模型集的比较
- (五)vit的内部表征
一、文章概览
AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE
一张图像相当于 16X16 个单词:大规模图像识别的transformer
(一)研究背景
- Transformer 架构已成为nlp任务事实上的标准(BERT、T5、GPT3),但是用transformer做cv较少
- 视觉领域的注意力要么与卷积网络结合使用,要么就是替换卷积网络的某些组件,但是整体结构不变
(二)核心思路
- 将图像分割为patch,将这些patch的线性嵌入序列作为 Transformer 的输入。这个时候图片就变成了图片块,图片块可以类比于nlp任务中的单词。
- 训练方式:有监督的训练
nlp中transformer采用的无监督方式
(三)相关工作
ViT和其它 self-attention in CV 的工作不同: ViT除了将图片转成 16 * 16 patches + 位置编码 之外,没有额外引入图像特有的归纳偏置,因此不需要对 vision 领域的了解,直接把图片理解成 a sequence of patches。
(三)文章结论
- 当在中型大小的数据集上,比如ImageNet进行训练时,如果不加比较强的约束,ViT模型和同等大小的残差网络相比会弱一些。这个结果是可以预计到的:Transformer 与CNN相比,会少一些inductive biases 归纳偏置。
inductive biases 归纳偏置:先验知识 or 提前的假设
- 卷积神经网络中常说的 inductive biases :
- locality:假设图片上相邻的区域会有相邻的特征
- translation equaivariance平移等变性: f ( g ( x ) ) = g ( f ( x ) ) f (g(x)) = g( f(x) ) f(g(x))=g(f(x)),也就是说 f f f 和 g g g 函数的顺序不影响结果。
- CNN 有 locality 和 translation equivariance 归纳偏置,因此CNN 有 很多先验信息,进而可以利用较少的数据去学好一个模型。
- Transformer 没有这些先验信息,只能 从图片数据里,自己学习对 视觉世界 的感知。
- 当以足够的规模进行预训练并转移到数据点较少的任务时,ViT能够取得优异的结果。当在公共 ImageNet-21k 数据集或内部 JFT-300M 数据集上进行预训练时,ViT 在多个图像识别基准上接近或击败了最先进的技术。特别是,最佳模型在 ImageNet 上达到 88.55% 的准确率,在 ImageNet-ReaL 上达到 90.72%,在 CIFAR-100 上达到 94.55%,在 19 个任务的 VTAB 套件上达到 77.63%。
二、模型细节
(一)组成模块
在模型设计上,ViT 尽可能使用了最原始的Transformer,大体由三个模块组成:
- Linear Projection of Flattened Patches(Embedding层)
- Transformer Encoder(图右侧有给出更加详细的结构)
- MLP Head(最终用于分类的层结构)

(二)模型的大体流程
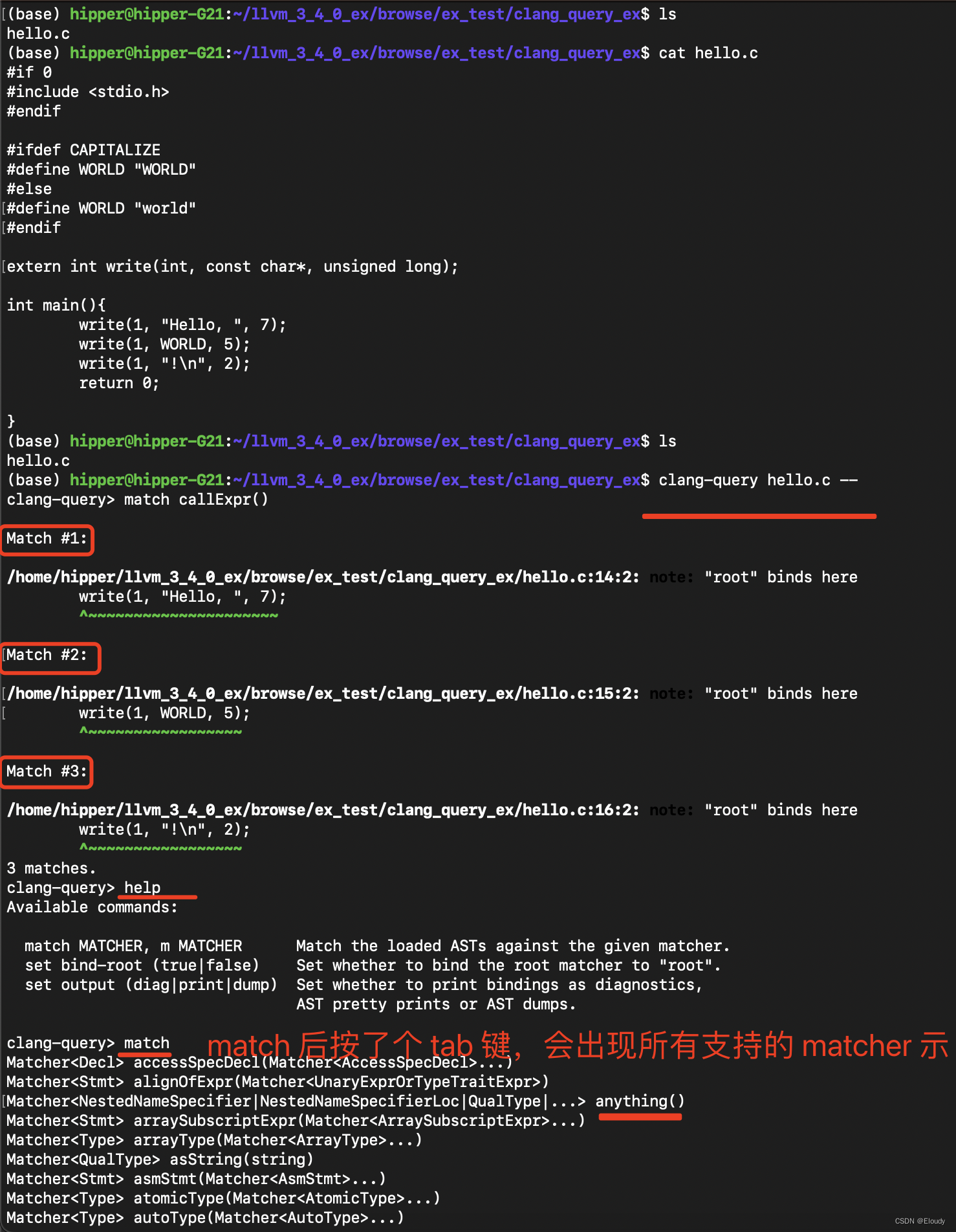
- 给定一张图片输入,先将图片划分成patch,然后将其转换为序列
- 每个patch会通过一个线性投射层得到一个特征
- 为了确保图片的位置信息得到保留,因此需要加上一个位置编码
- 将处理后的token输入transformer的encoder当中,将其中的class token经过一个mlp模块得到最终的分类
(三)具体的模型的前向过程
- 输入图像为224×224×3,将其切割成16*16的patches,就会得到196个图像块,每一个图像块的维度是16×16×3=768
此时图片就从原先的224x224x3转变成了196个维度为768的patch

- 将这些patch输入到线性投射层(一个维度为768x768的全连接层,第一个768依据图像的patch得到,是不变的,第二个768可以发生改变,如果transformer变得更大了,它也可以相应的变得更大),因此线性投射的输出为196x768的矩阵
此时有196个token,每个token向量的维度为768

- 此时可以将vision的问题转变成NLP的问题了,输入就是一系列1d的token,而不再是一张2d的图片了。在图片本身的token基础上,回家一个额外的cls token(维度为768),所以整体进入transformer的序列长度为197x768
图像的位置编码信息是直接加到token上去的,不是拼接,因此不会改变序列的维度,序列还是197x768
- 输入序列先经过一个layer norm,维度不变,依然是197x768;在多头注意力机制里,总共包括k、q、v三份,每一份都是197×768;再过一层layer norm,还是197×768;然后再过一层MLP,这里会把维度先对应地放大,一般是放大4倍,所以就是197×3072,然后再缩小投射回去,再变成197×768,就输出了。
多头自注意力中的维度其实并不是768,假设现在使用的是VIsion Transformer的base版本,即多头使用了12个头,那么最后的维度就变成了768/12=64,也就是说这里的k、q、v变成了197×64,但是有12个头,有12个对应的k、q、v做自注意力操作,最后再将12个头的输出直接拼接起来,这样64拼接出来之后又变成了768,所以多头自注意力出来的结果经过拼接还是197×768

综上就是一个Transformer block的前向传播的过程,进去之前是197×768,出来还是197×768,这个序列的长度和每个token对应的维度大小都是一样的,所以就可以在一个Transformer block上不停地往上叠加Transformer block,最后有L层Transformer block的模型就构成了Transformer encoder。
(四)transformer encoder的公式表达

- X p X_p Xp是图像块的patch,共有n个patch,即 X p 1 X_p^1 Xp1到 X p N X_p^N XpN
- E E E是线性投影的全连接层,通过线性投影得到了patch embedding
- 在patch embedding前边拼接一个class embedding,即 X c l a s s X_{class} Xclass,然后加上位置编码信息 E p o s E_{pos} Epos
- 每个transformer block中包含一个多头自注意力MSA和MLP,做这两个操作前需要经过layer norm,操作完成后进行一次残差连接
- 第 l l l个transformer block出来的结果即为 Z l Z_l Zl
- L L L层循环解释后将最后一层输出的第一个位置也就是class token对应的输出( Z L 0 Z_L^0 ZL0)作为整体图像的特征去完成分类任务。
(五)消融实验
1、关于图像分类编码方式的消融实验
在做图像分类的任务时,模型可以通过全局平均池化得到一个全局特征然后去做分类,也可以用一个class token去做。文章中所有的实验都是用class token去做的,主要的目的是跟原始的Transformer尽可能地保持一致,作者就是想证明,一个标准的Transformer照样可以做视觉。

- 绿线表示全局平均池化
- 蓝线表示class token
- 可以发现到最后绿线和蓝线的效果是差不多的,但是作者指出绿线和蓝线所使用的学习率(lr, Learning rate)是不一样的,如果直接将蓝线的学习率拿过来使用得到的效果可能如橙线所示,也就是说需要进行好好调参。
2、关于位置编码的消融实验
- 1d:NLP中常用的位置编码,也就是本文使用的位置编码(把一个图片打成九宫格,用的是1到9的数来表示图像块)
- 2d:使用11、12、13、21等来表示图像块,这样就跟视觉问题更加贴近,因为它有了整体的结构信息。具体的做法就是,原有的1d的位置编码的维度是d,现在因为横坐标、纵坐标都需要去表示,横坐标有D/2的维度,纵坐标也有D/2的维度,就是说分别有一个D/2的向量去表述横坐标和纵坐标,最后将这两个D/2的向量拼接到一起就又得到了一个长度为D的向量,把这个向量叫做2d的位置编码
- relative positional embedding(相对位置编码):在1d的位置编码中,两个patch之间的距离既可以用绝对的距离来表示,又可以用它们之间的相对距离来表示(文中所提到的offset),这样也可以认为是一种表示图像块之间位置信息的方式
 最后的结果显示三种表示方法的效果差不多。
最后的结果显示三种表示方法的效果差不多。
三、实验
(一)模型的变体
一共有三种模型,参数如下图所示。由于transformer的序列长度其实是跟patch size成反比的,因为patch size越小,切成的块就越多,patch size越大,切成的块就越少,所以当模型用了更小的patch size的时候计算起来就会更贵,因为序列长度增加了。

(二)分类精度结果对比
将几个ViT的变体和卷积神经网络(BiT和Noisy Student)进行对比,结果如下表所示。

(三)数据集的大小对ViT的影响
- 左侧的图像表示:在小数据集上进行预训练时,大型ViT模型的表现要比BiTResNets 差,但在较大数据集上进行预训练时,ViT更好。随着数据集的增长,较大的ViT变体会取代较小的ViT变体。
- 右侧的图像表示:ResNets在较小的预训练数据集上表现更好,但ViT在较大的预训练数据集上表现更好。

(四)BiT、ViT、Hybrids模型集的比较
在相同的计算开销下,ViT的性能一般优于ResNet。对于较小的模型尺寸,混合Transformer比纯Transformer有所改善,而对于较大的模型尺寸,纯Transformer比混合Transformer有所改善。
左图的average-5就是他在五个数据集(ImageNet real、pets、flowers、CIFAR-10、CIFAR-100)上做了evaluation,然后把这个数字平均了

(五)vit的内部表征
- vision transformer的第一层(linear projection layer,E)提取出的头28个主成分,其实vision transformer学到了跟卷积神经网络很像,都是这种看起来像gabor filter,有颜色和纹理,所以作者说这些成分是可以当作基函数的,也就是说,它们可以用来描述每一个图像块的底层的结构
- 学到的位置编码是可以表示一些距离信息的,同时它还学习到了一些行和列的规则,每一个图像块都是同行同列的相似性更高,也就意味着虽然它是一个1d的位置编码,但是它已经学到了2d图像的距离概念,这也可以解释为什么在换成2d的位置编码以后,并没有得到效果上的提升,是因为1d已经够用了
- 随着网络越来越深,所有注意力头的注意距离增加,网络学到的特征也会变得越来越高级,越来越具有语义信息;大概在网络的后半部分,模型的自注意力的距离已经非常远了,也就是说它已经学到了带有语义性的概念,而不是靠邻近的像素点去进行判断。

参考:
ViT论文逐段精读【论文精读】
《Vision Transformer (ViT)》论文精度,并解析ViT模型结构以及代码实现
ViT(Vision Transformer)全文精读