前言
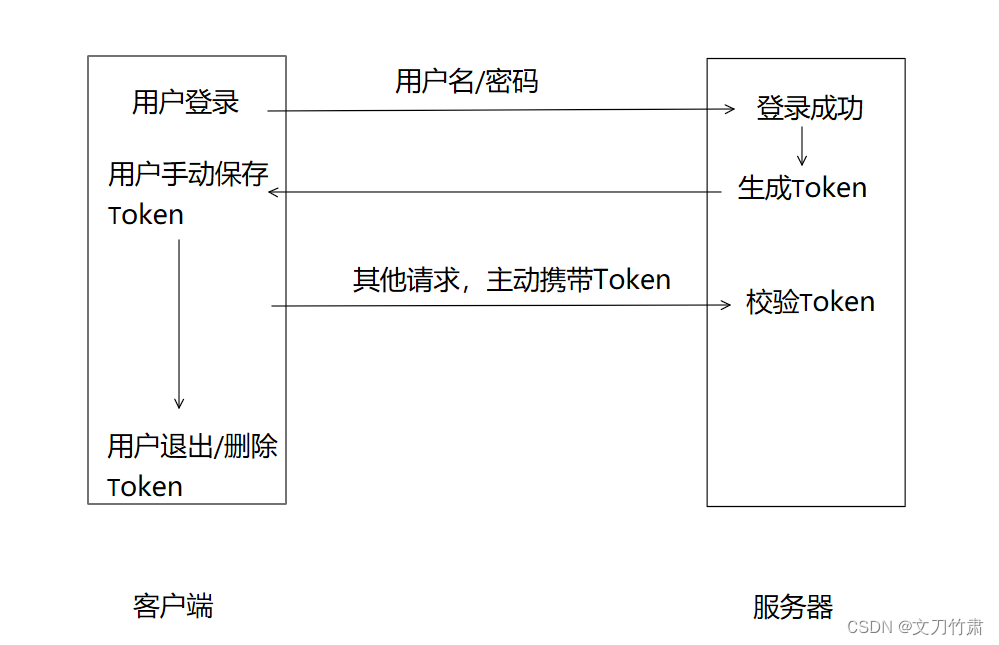
前些天,公司准备使用开源BI工具superset,但部署成功后,连接阿里数仓获取表时,一直报错,苦于日志不详细,从日志中并没有看出哪里的问题,然后就拉源码进行调试,终于找到抛出异常的位置,但是当我打印这个异常的时候并没有异常信息输出,这促使我重新看一遍python的异常与错误处理。
try语句
try:passexcept Exception as e:print(e)finally:print("Finally block")
![]()
位置
![]()
我们需要把更精确的except语句放到最前面,python的内置异常类之间是存在继承关系的,就拿我看superset源码中的例子
print(issubclass(NotImplementedError, RuntimeError)) # Trueprint(issubclass(RuntimeError, Exception)) # Trueprint(issubclass(Exception, BaseException)) # True
可以看到异常类的继承关系:BaseException -> Exception -> RuntimeError -> NotImplementedError,当然,这只是我举的一个例子。
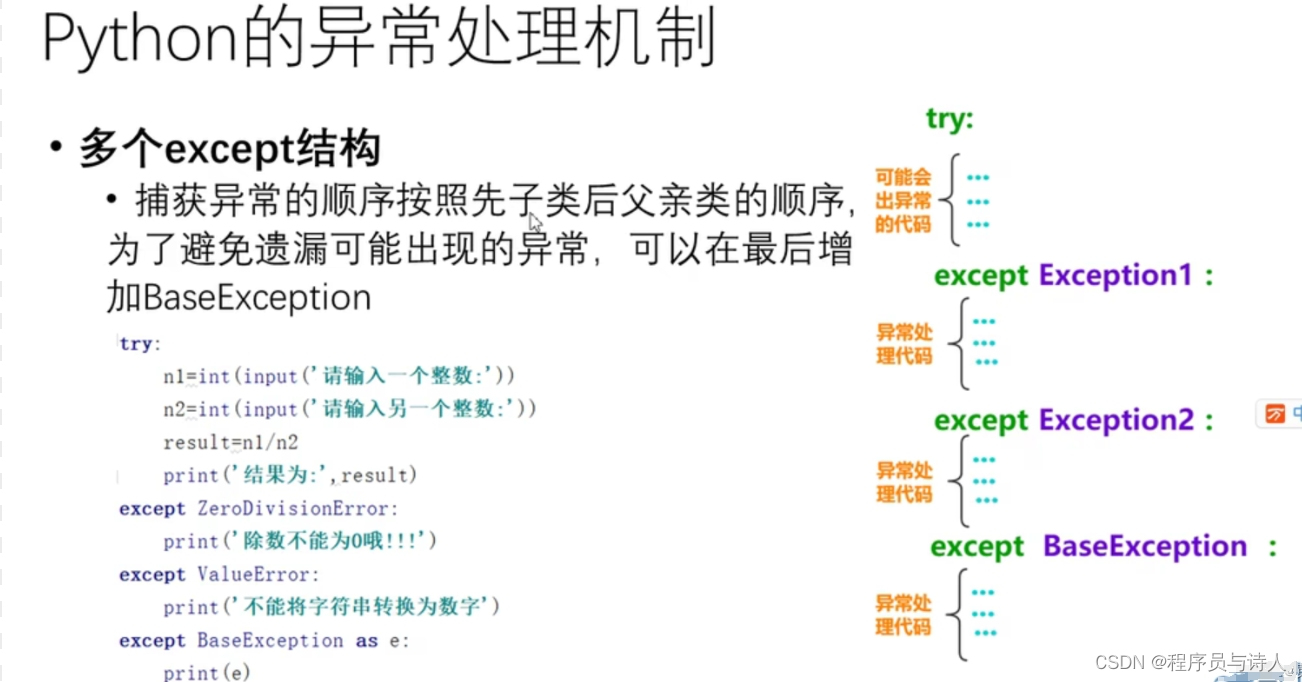
如果代码块中有多条except,异常匹配会按照从上到下的顺序进行。
如果把模糊不清的异常放在前面,就会导致下面的except不会触发,像下面这样
dic = {"name": "panda", "age": 18}try:print(dic['sex'])except Exception as e:print(f'exception: {e}')except KeyError:print('sex not in dic')
这段代码会输出exception: 'sex',KeyError下面的代码永远不会执行。
![]()
分支
![]()
啥时候需要分支呢?和条件语句的分支一样吗?
当我们需要程序没有异常时,才执行之后的逻辑,我们就需要分支了。
先看看,不使用else,我们是这样实现的
dic = {"name": "panda", "age": 18}successed = Falsetry:print(dic['sex'])successed = Trueexcept KeyError:print('sex not in dic')if successed:# 业务逻辑print('successed')
这里我们定义了一个额外变量,来控制真正的业务逻辑是否执行。如果使用try语句中的else分支,代码会变的很简单,像这样
dic = {"name": "panda", "age": 18}try:dic['name']except KeyError:print('sex not in dic')else:# 业务逻辑print('successed')
代码运行会输出successed,虽然和条件语句中的else是同一个词,但意义不同,这里的else表示try语句未抛出异常时,才执行else分支下的内容。
当然,需要注意的是,和finally语句不同,如果程序遇到return或break语句,中断异常捕获,即使没有任何异常,else中的逻辑也不会执行,像这样
def demo():try:a = 1return aexcept Exception as e:print(e)else:print('no error')finally:print('finally')demo()
这段代码,会输出finally,虽然代码没有异常,但是因为有return,导致else中的代码不会执行。
![]()
空raise语句
![]()
抛出异常,交给上层处理
def demo():try:a = 1/0except Exception as e:raisedemo()
空raise语句,会原封不动的重新抛出当前异常。这段代码执行结果为ZeroDivisionError: division by zero
![]()
建议抛出异常不要返回错误
![]()
之前写代码,我通常习惯将错误和结果一起返回,就是返回一个元组,包含返回结果和错误信息,然后通过错误信息来判断,进行后面的逻辑,像这样
MAX_LENGTH_OF_NAME = 12MAX_ITEMS_QUOTA = 10class Item:def __init__(self, name):self.name = namedef create_item(name):"""接收名称,创建 Item 对象:return: (对象,错误信息),成功时错误信息为 ''"""if len(name) > MAX_LENGTH_OF_NAME:return None, 'name of item is too long'return Item(name=name), ''def create_from_input():name = input()item, err_msg = create_item(name)if err_msg:print(f'create item failed: {err_msg}')else:print('item<{name}> created')create_from_input()
create_item()用来创建Item对象,函数内部进行长度判断逻辑,执行失败返回空字符串和错误信息组成的元组,在调用层create_from_input()来判断是否有错误信息,从而进行不同逻辑处理。刚开始感觉这样写还不错,后来代码量上来,都是这种写法,写的就懵了。
我们应该使用异常来进行错误处理,会优雅很多,像这样
# -*- coding: utf-8 -*-MAX_LENGTH_OF_NAME = 12MAX_ITEMS_QUOTA = 10def get_current_items():return []class Item:def __init__(self, name):self.name = nameclass CreateItemError(Exception):def __init__(self, *args, **kwargs):passdef create_item(name):"""创建一个新的 Item:raises: 当无法创建时抛出 CreateItemError"""if len(name) > MAX_LENGTH_OF_NAME:raise CreateItemError('name of item is too long')return Item(name=name)def create_from_input():name = input()try:item = create_item(name)except CreateItemError as e:print(f'create item failed: {e}')else:print(f'item<{name}> created')create_from_input()
这里我们自定义了异常错误类CreateItemError,这样create_item()函数只会返回Item类型或者抛出异常,清晰多了。
![]()
with
![]()
这并不陌生,我们通常操作一个文件时,会使用with来打开文件,像这样
with open('filename', 'r') as f:pass
但并不是所有对象都能配合with使用,需要满足上下文管理器协议的对象才可以。
要满足上下文管理器,需要实现__enter__和__exit__两个魔法方法,__enter__在进入管理器时被调用,__exit__在退出管理器时调用。
![]()
with使用案例
![]()
代替finally清理资源,先来看看使用finally是这样实现的
conn = MySQLDB(host, port, user, password, database)try:conn.execute_sql('select * from ...')except Exception as e:print(f'Unable to use connection: {e}')finally:conn.close()
这是我举的一个例子,MySQLDB是用来连接数据库的类,实现了execute_sql方法用来执行sql语句,最后关闭连接。
如果使用with会简洁很多,MySQLDB类中实现__enter__和__exit__两个魔法方法
class MySQLDB(SQLBase):"""MySQL DB table API"""def __init__(self, host: str, port: int, user: str, password: str, database: str, charset='utf8mb4'):"""Connect to the MySQL database:param host::param port::param user::param password::param database:"""self.connection = pymysql.connect(host=host,port=int(port),user=user,password=password,database=database,charset=charset,cursorclass=pymysql.cursors.DictCursor)def __enter__(self):return self.connectiondef __exit__(self, exc_type, exc_val, exc_tb):self.connection.close()return Falsedef execute_sql(self, sql: str) -> None:"""Execute SQLpass
接下来,我们就可以使用with了
with MySQLDB(host='127.0.0.1', port=3306, user='root', password='123456', database='test') as db:db.execute_sql("")
忽略异常,有时候出现异常,并不会影响业务逻辑,但异常会阻碍程序运行,此时就需要try/except来捕获,但如果需要忽略的异常比较多,就有很多try/except,不优雅,我们可以直接实现一个上下文管理器来统一忽略异常,像这样
class ignore_closed:def __enter__(self):passdef __exit__(self, exc_type, exc_value, traceback):if exc_type == NotImplementedError:return Truereturn False
在使用时,如果需要忽略NotImplementedError错误,就可以使用with,with ignore_closed():__exit__接收三个参数,with上下文内未抛出异常,解释器在执行__exit__方法时,exc_type、exc_value、traceback这三个参数的值都是None,如果有异常抛出,这三个参数就是异常的具体内容:
-
exc_type:异常的类型 -
exc_value:异常对象 -
traceback:错误的堆栈对象
此时,如果__exit__返回True,异常就不会继续抛出,如果返回False,那异常就正常抛出。
当然,标准库模块contextlib里面的suppress函数,提供了忽略异常功能,可以直接使用
contextmanager装饰器
上面的例子可以看到,定义一个上下文管理器还是比较麻烦的,需要实现两个魔法方法。为了简化,python提供的更简便的装饰器:@contextmanager,像这样
from contextlib import contextmanager@contextmanagerdef create_conn_obj():conn = MySQLDB(host='127.0.0.1', port=3306, user='root', password='123456', database='test')try:yield connfinally:conn.close()
yield前面的逻辑会进入管理器时执行,就像__enter__,yield后面的逻辑会在退出管理器时执行,就像__exit__想要在上下文管理器内处理异常,必须使用 try包裹yield语句。
@contextmanager可以把一个生成器函数转化成上下文管理器。
![]()
定位问题
![]()
看superset源码定位问题时,这样一段代码出现异常
try:views = set(inspector.get_view_names(schema))except Exception as ex:print(ex)raise cls.get_dbapi_mapped_exception(ex)
在这段代码中,当发生异常时,通过 print(ex) 语句打印异常信息是一个常见的做法。然而,并非所有类型的异常都包含可读的文本信息。
有些异常可能不会直接包含有用的信息,而是需要从其他属性中获取。因此,打印异常时可能看不到具体的错误信息。
为了更好地查看异常信息,可以尝试打印完整的异常堆栈信息,而不仅仅是异常对象本身。
可以修改代码如下:
try:views = set(inspector.get_view_names(schema))except Exception as ex:import tracebacktraceback.print_exc()raise cls.get_dbapi_mapped_exception(ex)
通过使用 traceback.print_exc() 函数,可以打印完整的异常堆栈信息,包括异常的类型、消息和堆栈轨迹,这样可以更全面地了解发生了什么异常以及其详细信息。学到了,果然很快就解决问题了
![]()
最后
![]()
公司的BI工具总算可以正常使用了,感受到了看源码、改源码的快乐。

END