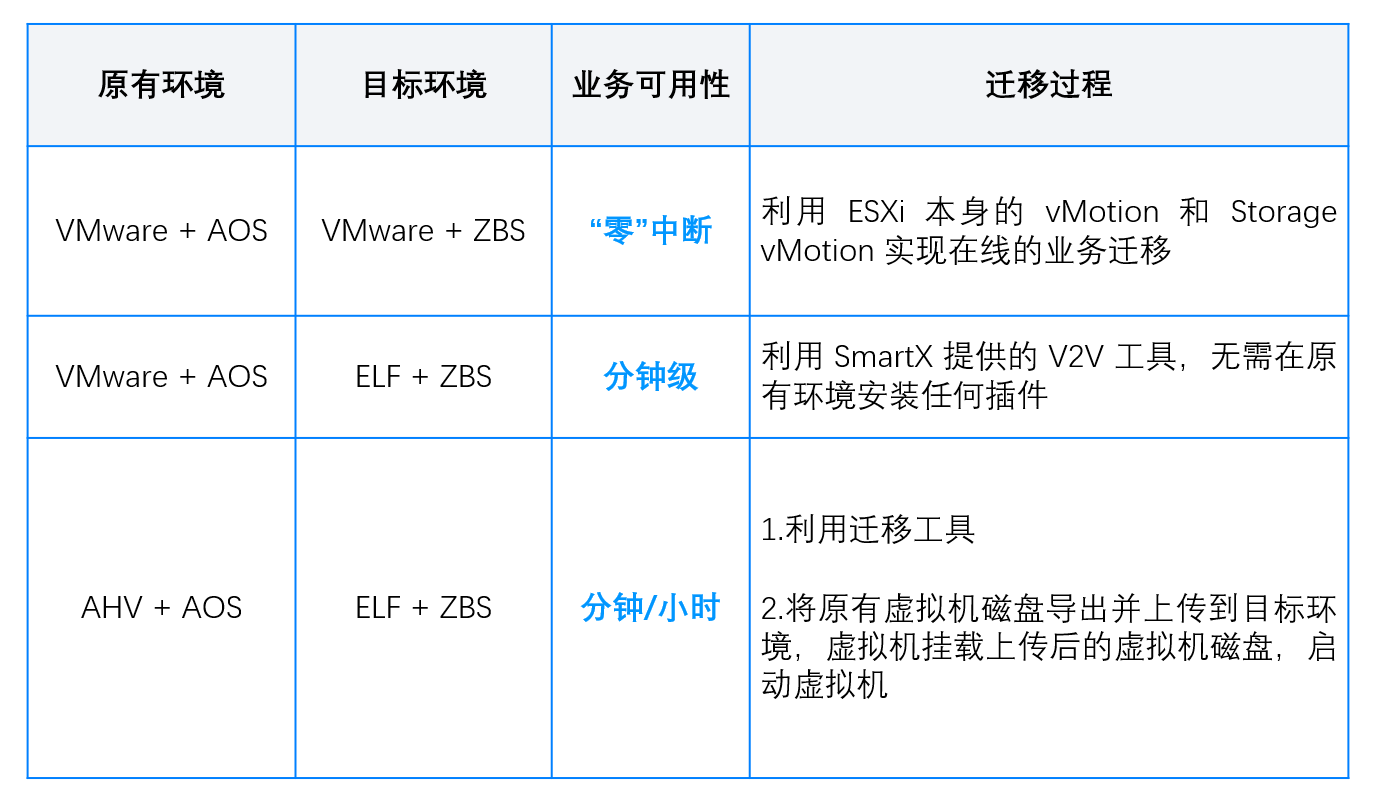
Enhancing Robustness in Retrieval-Augmented Language Models
检索增强型语言模型(RALMs)在大型语言模型的能力上取得了重大进步,特别是在利用外部知识源减少事实性幻觉方面。然而,检索到的信息的可靠性并不总是有保证的。检索到无关数据可能导致回答偏离正轨,甚至可能使模型忽略其固有的知识,即使它拥有足够的信息来回答查询。此外,标准的RALMs通常难以评估它们是否拥有足够的知识,包括内在知识和检索到的知识,以提供准确的答案。在知识缺乏的情况下,这些系统理想情况下应该以“未知”回应无法回答的问题。为了应对这些挑战,我们引入了CHAIN-OF-NOTING(CON),这是一种新颖的方法,旨在提高RALMs在面对噪声、无关文档和未知场景时的鲁棒性。CON的核心思想是为检索到的文档生成顺序阅读笔记,从而彻底评估它们与给定问题的相关性,并将这些信息整合以形成最终答案。我们使用ChatGPT为CON创建训练数据,随后在LLaMa-2 7B模型上进行了训练。我们在四个开放领域问答基准上的实验表明,装备了CON的RALMs显著优于标准的RALMs。特别是,CON在完全噪声检索文档的情况下,EM分数平均提高了+7.9,在实时问题超出预训练知识范围的情况下的拒绝率提高了+10.5。


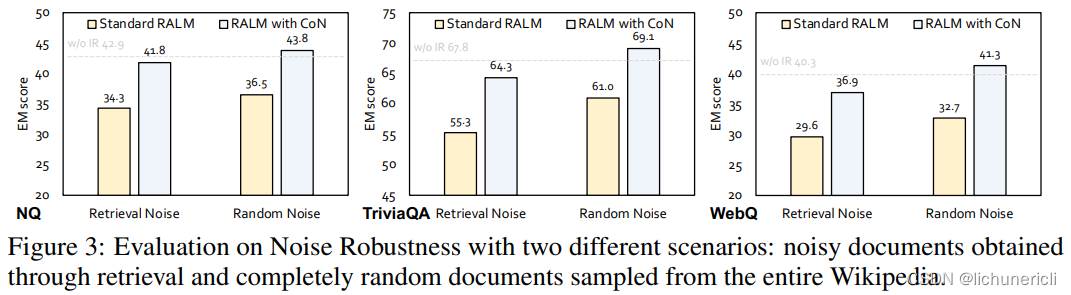
在这篇论文中,我们介绍了CHAIN-OF-NOTING(CON)框架,这是一种新颖的方法论,旨在增强RALMs的鲁棒性。CON的核心概念围绕着为每个检索到的文档生成顺序阅读笔记。这个过程允许深入评估文档与提出问题的相关性,并帮助合成这些信息以构建最终的答案。我们使用了ChatGPT来生成CON的初始训练数据,然后使用LLaMa-2 7B模型进一步优化这些数据。我们在各种开放领域问答基准上的测试表明,集成了CON的RALMs在性能上显著超过了传统的RALMs。