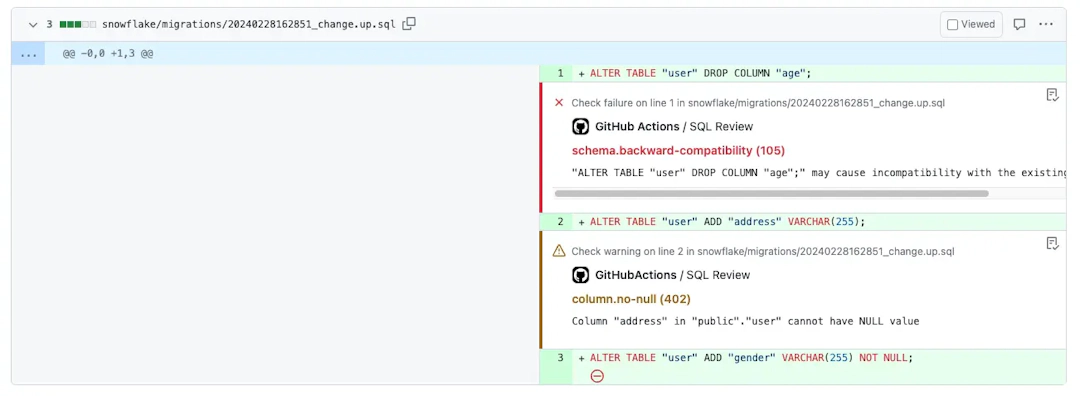
利用Python进行数据分析:Pandas与Jupyter Notebook的完美结合
在数据科学和分析领域,Python语言因其强大的数据处理库而备受青睐。其中,Pandas是Python中最常用的数据分析库之一,而Jupyter Notebook则是一个流行的交互式计算环境,可让用户在浏览器中创建和共享文档,其中包含实时代码、可视化和解释性文本。本文将介绍如何结合Pandas和Jupyter Notebook进行数据分析,并提供一些示例来演示它们的强大功能。
安装和设置
首先,确保你已经安装了Python和Jupyter Notebook。你可以使用pip来安装它们:
pip install pandas jupyter
安装完成后,你可以在命令行中输入以下命令启动Jupyter Notebook:
jupyter notebook
使用Pandas进行数据分析
Pandas提供了一个称为DataFrame的数据结构,它类似于电子表格或数据库表格。DataFrame使得数据加载、清洗、转换和分析变得更加简单。以下是一个使用Pandas加载数据、进行基本数据分析的示例:
import pandas as pd
# 从CSV文件加载数据
data = pd.read_csv('data.csv')
# 显示数据的前几行
print("数据的前几行:")
print(data.head())
# 统计数据的基本信息
print("\n数据的基本统计信息:")
print(data.describe())
# 统计数据中不同类别的数量
print("\n不同类别的数量:")
print(data['category'].value_counts())
结合Jupyter Notebook进行交互式分析
Jupyter Notebook允许你在笔记本中编写Python代码并立即查看结果。你可以将代码和文本混合在一起,以便记录分析过程并分享你的工作。下面是如何在Jupyter Notebook中使用Pandas进行交互式数据分析的示例:
# 在Jupyter Notebook中使用Pandas
import pandas as pd
# 从CSV文件加载数据
data = pd.read_csv('data.csv')
# 显示数据的前几行
data.head()
这段代码将在Jupyter Notebook中显示数据的前几行,让你可以立即查看数据的结构和内容。
数据可视化
除了数据分析,Pandas和Jupyter Notebook还可以与其他库一起使用,如Matplotlib和Seaborn,用于创建数据可视化。以下是一个简单的示例,演示如何使用这些库创建直方图:
import matplotlib.pyplot as plt
# 设置绘图风格
plt.style.use('ggplot')
# 创建直方图
data['value'].plot(kind='hist', bins=20, alpha=0.7)
plt.title('Value Distribution')
plt.xlabel('Value')
plt.ylabel('Frequency')
plt.show()
数据清洗与处理
在实际的数据分析过程中,数据往往会存在缺失值、异常值等问题,需要进行清洗和处理。Pandas提供了丰富的功能来处理这些问题。下面是一个示例,展示如何处理数据中的缺失值:
# 检查缺失值
missing_values = data.isnull().sum()
print("缺失值统计:")
print(missing_values)
# 删除包含缺失值的行
data_cleaned = data.dropna()
# 填充缺失值
data_filled = data.fillna(method='ffill') # 使用前一个值填充缺失值
# 替换缺失值
data_replaced = data.replace({'category': {None: 'Unknown'}})
# 输出处理后的数据
print("\n处理后的数据:")
print(data_cleaned.head())
高级数据分析
除了基本的数据分析和处理,Pandas还支持高级数据操作,如分组、合并和透视表。下面是一个示例,展示如何使用Pandas进行数据分组和聚合:
# 按类别分组并计算平均值
grouped_data = data.groupby('category').mean()
# 显示分组后的数据
print("\n按类别分组后的平均值:")
print(grouped_data)
将分析结果导出
最后,一旦完成数据分析,你可能希望将结果导出到文件中,以便与他人分享或用于进一步处理。Pandas支持将数据导出到各种格式,如CSV、Excel等。下面是一个示例:
# 导出数据到CSV文件
data_cleaned.to_csv('cleaned_data.csv', index=False)
print("已导出清洗后的数据到 cleaned_data.csv 文件")
完整案例:分析销售数据
假设我们有一份包含产品销售信息的CSV文件,其中包括日期、产品类别、销售额等字段。我们将使用Pandas和Jupyter Notebook来加载、清洗、分析这些数据,并进行可视化展示。
import pandas as pd
import matplotlib.pyplot as plt
# 加载数据
sales_data = pd.read_csv('sales_data.csv')
# 显示数据的前几行
print("数据的前几行:")
print(sales_data.head())
# 检查缺失值
missing_values = sales_data.isnull().sum()
print("\n缺失值统计:")
print(missing_values)
# 处理缺失值
sales_data_cleaned = sales_data.dropna()
# 按产品类别分组并计算总销售额
category_sales = sales_data_cleaned.groupby('Category')['Sales'].sum()
# 创建柱状图
category_sales.plot(kind='bar', color='skyblue')
plt.title('Total Sales by Category')
plt.xlabel('Category')
plt.ylabel('Total Sales')
plt.xticks(rotation=45)
plt.show()
# 导出处理后的数据
sales_data_cleaned.to_csv('cleaned_sales_data.csv', index=False)
print("\n已导出清洗后的数据到 cleaned_sales_data.csv 文件")
这个案例首先加载了销售数据,然后清洗了其中的缺失值。接着,对清洗后的数据按产品类别进行分组,并计算了每个类别的总销售额。最后,使用Matplotlib创建了一个柱状图展示了不同产品类别的总销售额,并将处理后的数据导出到了一个新的CSV文件中。
通过这个完整的案例,我们展示了如何使用Pandas和Jupyter Notebook进行数据分析,从数据加载到可视化展示再到结果导出的全过程。这种结合为数据分析工作提供了极大的便利和效率。
进一步分析和可视化
在实际数据分析中,我们可能需要更深入地探索数据,进行更多的分析和可视化。以下是一些进一步的分析和可视化示例:
分析销售额趋势
我们可以分析销售数据的时间趋势,了解销售额随时间的变化情况。
# 将日期列转换为日期时间类型
sales_data_cleaned['Order Date'] = pd.to_datetime(sales_data_cleaned['Order Date'])
# 提取年份和月份信息
sales_data_cleaned['Year'] = sales_data_cleaned['Order Date'].dt.year
sales_data_cleaned['Month'] = sales_data_cleaned['Order Date'].dt.month
# 按年份和月份分组计算每月总销售额
monthly_sales = sales_data_cleaned.groupby(['Year', 'Month'])['Sales'].sum()
# 创建折线图显示销售额随时间的变化
monthly_sales.plot(kind='line', marker='o', color='orange', figsize=(10, 6))
plt.title('Monthly Sales Trend')
plt.xlabel('Year-Month')
plt.ylabel('Total Sales')
plt.grid(True)
plt.xticks(rotation=45)
plt.show()
分析产品销售排名
我们可以分析各个产品的销售情况,找出销售额最高的产品。
# 按产品名称分组并计算总销售额
product_sales = sales_data_cleaned.groupby('Product')['Sales'].sum()
# 按销售额降序排序
product_sales_sorted = product_sales.sort_values(ascending=False)
# 取销售额最高的前10个产品
top_10_products = product_sales_sorted.head(10)
# 创建水平条形图显示销售额最高的前10个产品
top_10_products.plot(kind='barh', color='green', figsize=(10, 6))
plt.title('Top 10 Products by Sales')
plt.xlabel('Total Sales')
plt.ylabel('Product')
plt.show()
分析销售额的区域分布
我们可以分析销售额在不同地区的分布情况。
# 按地区分组并计算总销售额
region_sales = sales_data_cleaned.groupby('Region')['Sales'].sum()
# 创建饼图显示销售额在不同地区的分布情况
region_sales.plot(kind='pie', autopct='%1.1f%%', figsize=(8, 8))
plt.title('Sales Distribution by Region')
plt.ylabel('')
plt.show()
通过以上示例,我们展示了更多的数据分析和可视化技巧,使得我们可以更全面地理解数据,从而做出更深入的决策和洞察。Pandas和Jupyter Notebook的结合为数据分析提供了极大的灵活性和便利性,使得数据科学家可以更轻松地探索数据、发现规律并做出有效的分析。
进一步优化和探索
除了以上的分析和可视化外,我们还可以进一步优化代码,探索更多的数据分析技巧,使得我们的分析更加全面和深入。
分析销售额的季节性变化
我们可以进一步分析销售数据的季节性变化,了解销售额在不同季节或月份的表现。
# 提取季节信息
sales_data_cleaned['Quarter'] = sales_data_cleaned['Order Date'].dt.quarter
# 按季度分组并计算总销售额
quarterly_sales = sales_data_cleaned.groupby('Quarter')['Sales'].sum()
# 创建柱状图显示季度销售额
quarterly_sales.plot(kind='bar', color='purple', figsize=(8, 6))
plt.title('Quarterly Sales')
plt.xlabel('Quarter')
plt.ylabel('Total Sales')
plt.xticks(rotation=0)
plt.show()
探索销售额和利润的关系
我们可以分析销售额和利润之间的关系,找出销售额高但利润低的产品或地区。
# 计算利润(利润 = 销售额 - 成本)
sales_data_cleaned['Profit'] = sales_data_cleaned['Sales'] - sales_data_cleaned['Cost']
# 按产品名称分组并计算平均利润
product_profit = sales_data_cleaned.groupby('Product')['Profit'].mean()
# 按利润降序排序
product_profit_sorted = product_profit.sort_values(ascending=False)
# 取利润最高的前10个产品
top_10_profitable_products = product_profit_sorted.head(10)
# 创建水平条形图显示利润最高的前10个产品
top_10_profitable_products.plot(kind='barh', color='blue', figsize=(10, 6))
plt.title('Top 10 Profitable Products')
plt.xlabel('Average Profit')
plt.ylabel('Product')
plt.show()
分析销售额和促销活动的关系
我们可以探索销售额和促销活动之间的关系,了解是否有促销活动会提升销售额。
# 根据促销活动标志分组并计算总销售额
promotion_sales = sales_data_cleaned.groupby('Promotion')['Sales'].sum()
# 创建饼图显示促销活动对销售额的影响
promotion_sales.plot(kind='pie', autopct='%1.1f%%', figsize=(8, 8))
plt.title('Sales Distribution by Promotion')
plt.ylabel('')
plt.show()
通过以上优化和探索,我们能够更深入地了解销售数据,发现更多的规律和洞察,从而为业务决策提供更有力的支持。同时,我们也展示了Python在数据分析领域的强大能力,以及Pandas和Jupyter Notebook的灵活性和便利性,使得数据分析工作更加高效和有趣。
总结
本文介绍了如何利用Python中的Pandas和Jupyter Notebook进行数据分析,并提供了多个示例来展示它们的强大功能。我们从数据加载、清洗、分析到可视化和探索性分析,全方位地演示了如何利用这两个工具进行数据科学工作。
首先,我们学习了如何使用Pandas加载数据,并进行基本的数据清洗和处理,包括处理缺失值、分组计算、数据转换等。随后,我们展示了如何在Jupyter Notebook中结合Pandas进行交互式分析,以及如何利用Matplotlib和Seaborn等库进行数据可视化。
然后,我们进行了更深入的分析,包括分析销售额趋势、产品销售排名、销售额的区域分布等。通过这些分析,我们能够更全面地了解数据,并发现其中的规律和趋势。
最后,我们进行了进一步的优化和探索,包括分析销售额的季节性变化、销售额和利润的关系、销售额和促销活动的关系等。这些分析能够为业务决策提供更深入的洞察和支持。
综上所述,Pandas和Jupyter Notebook的结合为数据科学工作提供了强大的工具和平台,使得数据分析工作更加高效、灵活和有趣。通过不断学习和探索,我们能够发现数据中的价值,为业务发展和决策提供更好的支持。

![[音视频学习笔记]七、自制音视频播放器Part2 - VS + Qt +FFmpeg 写一个简单的视频播放器](https://img-blog.csdnimg.cn/direct/2afff4465b2d45218068d2b4685630f9.png)