在今天的文章中,我们将很快地通过 Docker 来快速地设置 Elasticsearch 及 Kibana,并设置 Elasticsearch 为向量搜索。
拉取 Docker 镜像
docker pull docker.elastic.co/elasticsearch/elasticsearch:8.12.2
docker pull docker.elastic.co/kibana/kibana:8.12.2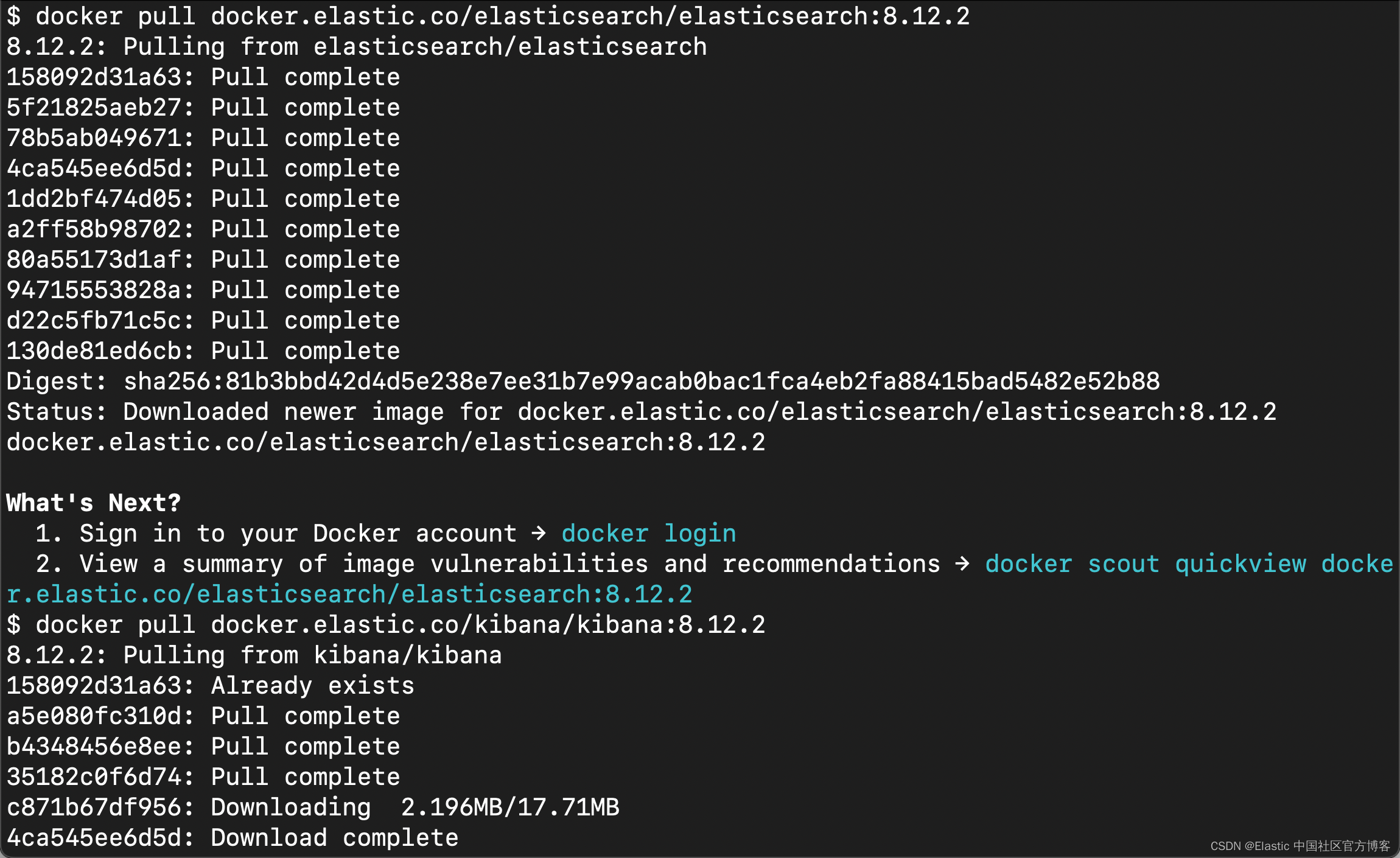
启动 Elasticsearch 及 Kibana 容器
docker network create elastic
docker run -d --name elasticsearch --net elastic -p 9200:9200 -p 9300:9300 -m 1GB -e "discovery.type=single-node" -e "ELASTIC_PASSWORD=password" docker.elastic.co/elasticsearch/elasticsearch:8.12.2
docker run -d --name kibana --net elastic -p 5601:5601 docker.elastic.co/kibana/kibana:8.12.2$ docker run -d --name elasticsearch --net elastic -p 9200:9200 -p 9300:9300 -m 1GB -e "discovery.type=single-node" -e "ELASTIC_PASSWORD=password" docker.elastic.co/elasticsearch/elasticsearch:8.12.2
39dc9085f239edb3c963de4fb122f0ec02f78a6311abd8297cf046c025cd2618$ docker run -d --name kibana --net elastic -p 5601:5601 docker.elastic.co/kibana/kibana:8.12.2
2766a300b3fd165f793f5f47b55748b2e9d4b016ea78b5c23565442e2c4cdfb5在上面,我们指定了 elasic 超级用户的密码为 password。这在下面将要使用到。
验证容器是否已启动并正在运行:
$ docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
2766a300b3fd docker.elastic.co/kibana/kibana:8.12.2 "/bin/tini -- /usr/l…" About a minute ago Up About a minute 0.0.0.0:5601->5601/tcp kibana
39dc9085f239 docker.elastic.co/elasticsearch/elasticsearch:8.12.2 "/bin/tini -- /usr/l…" 3 minutes ago Up 3 minutes 0.0.0.0:9200->9200/tcp, 0.0.0.0:9300->9300/tcp elasticsearch从上面我们可以看到 Elasticsarch 及 Kibana 已经完全运行起来了。我们可以在浏览器中进行验证:
docker exec -it elasticsearch /bin/bash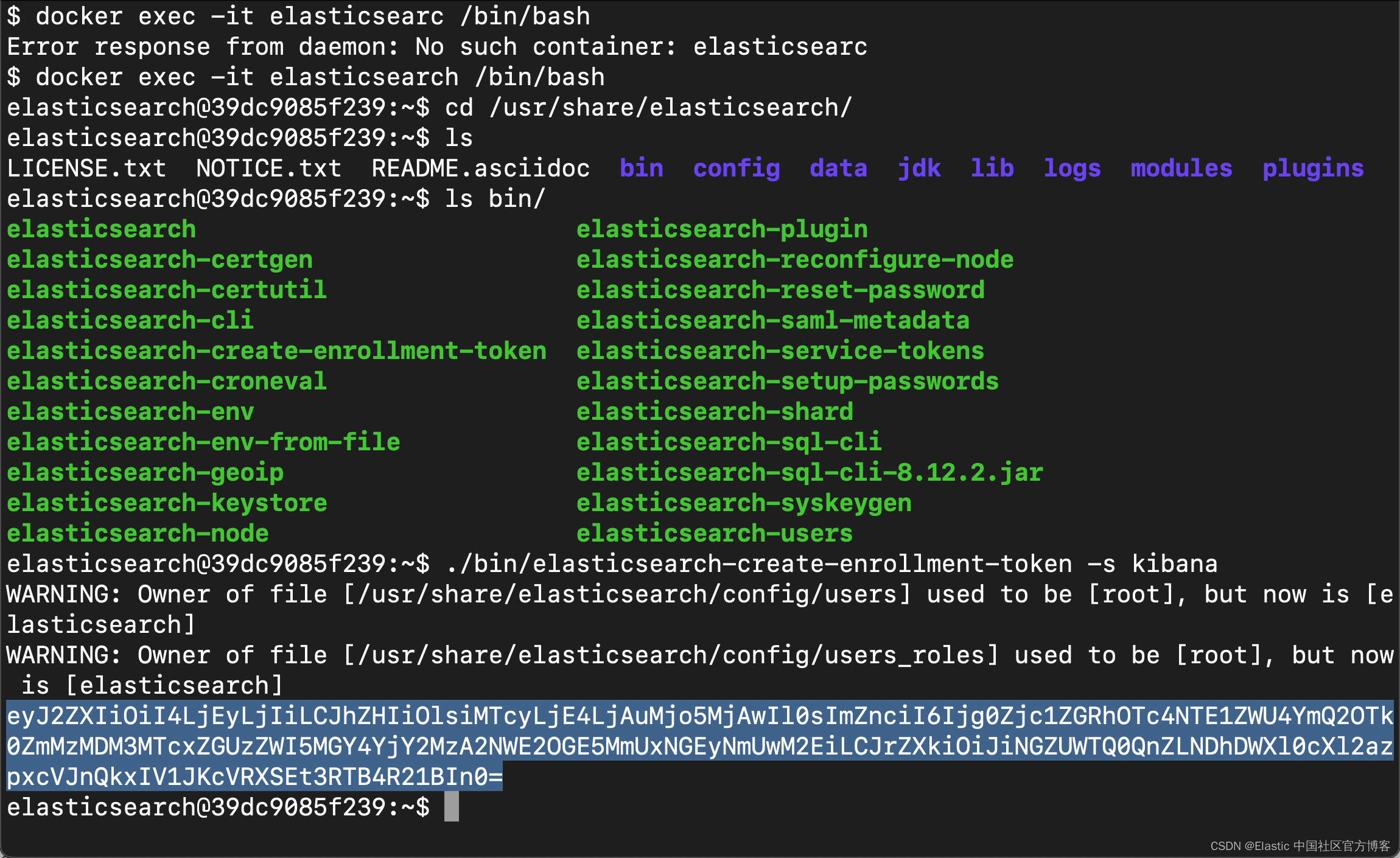
docker logs -f kibana$ docker logs -f kibana
Kibana is currently running with legacy OpenSSL providers enabled! For details and instructions on how to disable see https://www.elastic.co/guide/en/kibana/8.12/production.html#openssl-legacy-provider
{"log.level":"info","@timestamp":"2024-03-22T01:28:37.598Z","log.logger":"elastic-apm-node","ecs.version":"8.10.0","agentVersion":"4.2.0","env":{"pid":7,"proctitle":"/usr/share/kibana/bin/../node/bin/node","os":"linux 6.4.16-linuxkit","arch":"arm64","host":"2766a300b3fd","timezone":"UTC+00","runtime":"Node.js v18.18.2"},"config":{"active":{"source":"start","value":true},"breakdownMetrics":{"source":"start","value":false},"captureBody":{"source":"start","value":"off","commonName":"capture_body"},"captureHeaders":{"source":"start","value":false},"centralConfig":{"source":"start","value":false},"contextPropagationOnly":{"source":"start","value":true},"environment":{"source":"start","value":"production"},"globalLabels":{"source":"start","value":[["git_rev","f5bd489c5ff9c676c4f861c42da6ea99ae350832"]],"sourceValue":{"git_rev":"f5bd489c5ff9c676c4f861c42da6ea99ae350832"}},"logLevel":{"source":"default","value":"info","commonName":"log_level"},"metricsInterval":{"source":"start","value":120,"sourceValue":"120s"},"serverUrl":{"source":"start","value":"https://kibana-cloud-apm.apm.us-east-1.aws.found.io/","commonName":"server_url"},"transactionSampleRate":{"source":"start","value":0.1,"commonName":"transaction_sample_rate"},"captureSpanStackTraces":{"source":"start","sourceValue":false},"secretToken":{"source":"start","value":"[REDACTED]","commonName":"secret_token"},"serviceName":{"source":"start","value":"kibana","commonName":"service_name"},"serviceVersion":{"source":"start","value":"8.12.2","commonName":"service_version"}},"activationMethod":"require","message":"Elastic APM Node.js Agent v4.2.0"}
[2024-03-22T01:28:38.276+00:00][INFO ][root] Kibana is starting
[2024-03-22T01:28:38.320+00:00][INFO ][node] Kibana process configured with roles: [background_tasks, ui]
[2024-03-22T01:28:42.183+00:00][INFO ][plugins-service] Plugin "cloudChat" is disabled.
[2024-03-22T01:28:42.192+00:00][INFO ][plugins-service] Plugin "cloudExperiments" is disabled.
[2024-03-22T01:28:42.193+00:00][INFO ][plugins-service] Plugin "cloudFullStory" is disabled.
[2024-03-22T01:28:42.501+00:00][INFO ][plugins-service] Plugin "profilingDataAccess" is disabled.
[2024-03-22T01:28:42.501+00:00][INFO ][plugins-service] Plugin "profiling" is disabled.
[2024-03-22T01:28:42.587+00:00][INFO ][plugins-service] Plugin "securitySolutionServerless" is disabled.
[2024-03-22T01:28:42.587+00:00][INFO ][plugins-service] Plugin "serverless" is disabled.
[2024-03-22T01:28:42.587+00:00][INFO ][plugins-service] Plugin "serverlessObservability" is disabled.
[2024-03-22T01:28:42.587+00:00][INFO ][plugins-service] Plugin "serverlessSearch" is disabled.
[2024-03-22T01:28:42.929+00:00][INFO ][http.server.Preboot] http server running at http://0.0.0.0:5601
[2024-03-22T01:28:42.996+00:00][INFO ][plugins-system.preboot] Setting up [1] plugins: [interactiveSetup]
[2024-03-22T01:28:43.004+00:00][INFO ][preboot] "interactiveSetup" plugin is holding setup: Validating Elasticsearch connection configuration…
[2024-03-22T01:28:43.019+00:00][INFO ][root] Holding setup until preboot stage is completed.
i Kibana has not been configured.
Go to http://0.0.0.0:5601/?code=897018 to get started.
Your verification code is: 897 018 我们把上面的 enrollment token 及 verification code 填入下面的方框里:
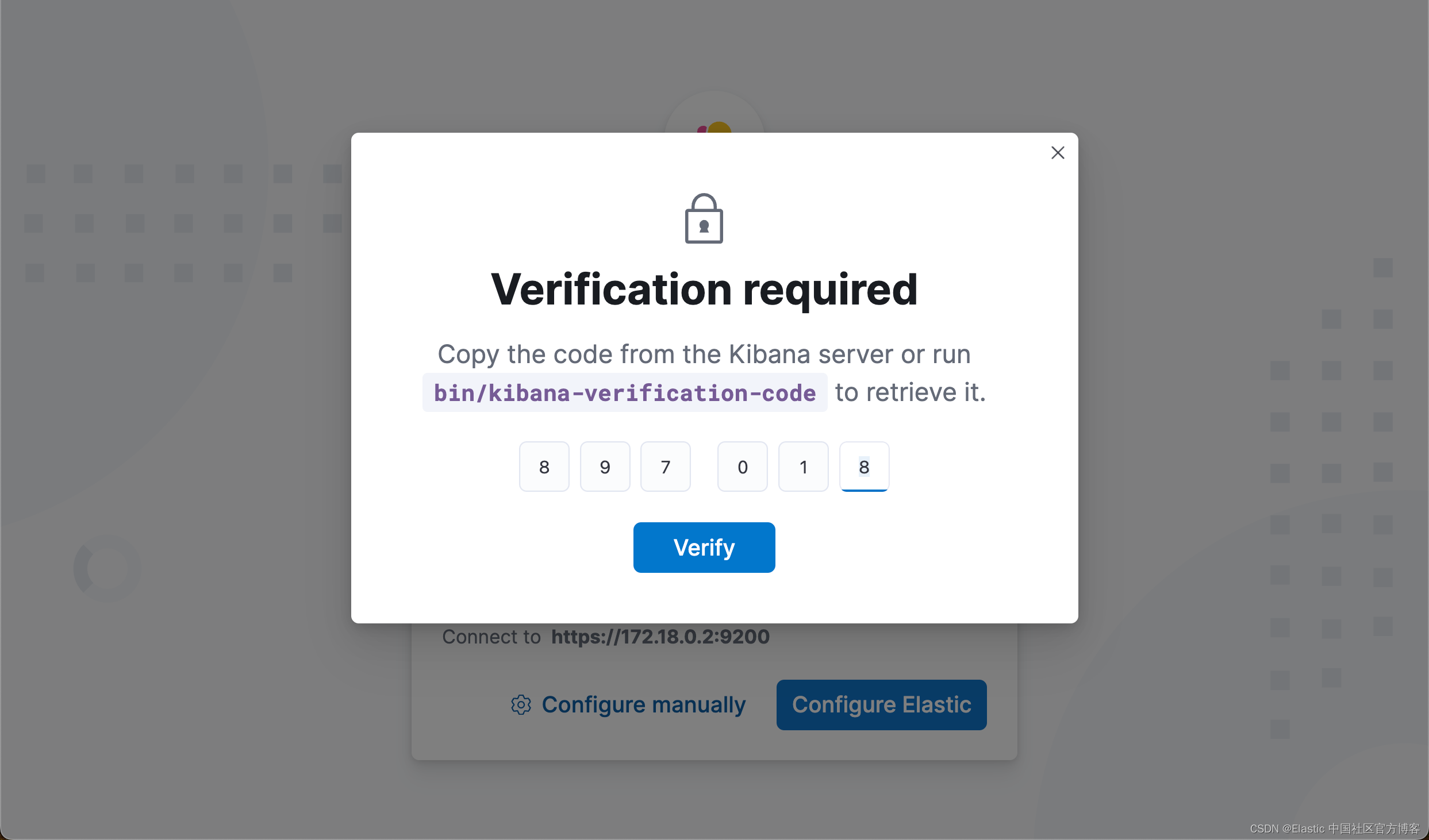
注意:由于一些原因,在上面显示的地址不是 localhost,而是电脑上的另外一个地址,比如 172.18.0.2:9200。这个并不影响我们的配置。
这样我们就成功地登录了。
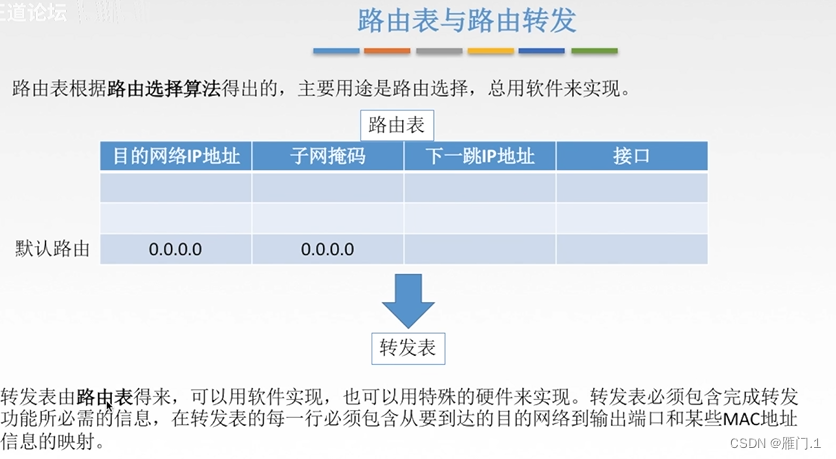
创建索引
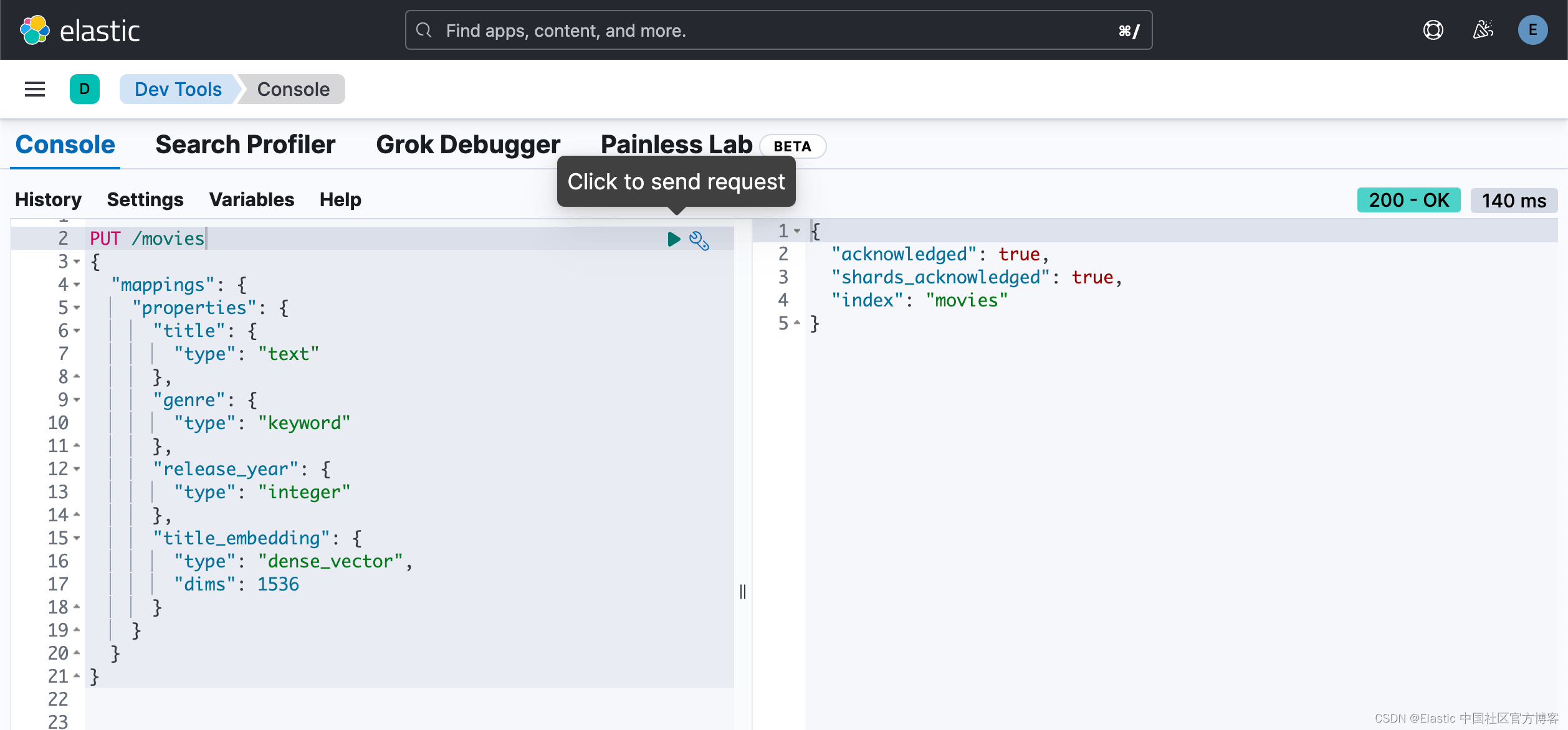
现在,让我们创建 “movies” 索引。 我们将使用 text-embedding-3-small 模型来生成 title 字段的向量嵌入并将其存储为 title_embedding。 该模型生成长度为 1536 的嵌入。因此我们需要将 title_embedding 字段映射指定为具有 1536 维的密集向量。
PUT /movies
{
"mappings": {
"properties": {
"title": {
"type": "text"
},
"genre": {
"type": "keyword"
},
"release_year": {
"type": "integer"
},
"title_embedding": {
"type": "dense_vector",
"dims": 1536
}
}
}
}
让我们使用 Elasticsearch Python 客户端插入一些文档。
Python 客户端需要 `ssl_assert_fingerprint` 才能连接到 Elasticsearch。 让我们使用以下命令来获取它:
openssl s_client -connect localhost:9200 -servername localhost -showcerts </dev/null 2>/dev/null | openssl x509 -fingerprint -sha256 -noout -in /dev/stdin$ openssl s_client -connect localhost:9200 -servername localhost -showcerts </dev/null 2>/dev/null | openssl x509 -fingerprint -sha256 -noout -in /dev/stdin
sha256 Fingerprint=20:67:39:6C:33:C0:D6:AC:E2:E3:A5:2E:56:6C:57:4F:91:DC:41:4D:99:9B:7F:0F:1C:20:AD:E2:20:FE:1E:1B写入文档到 Elasticsearch
现在我们可以在电影索引中插入一些文档。
我们现在 terminal 中打入如下的命令:
export OPENAI_API_KEY="YourOpenAiKey"在上面,请填入自己申请的 OpenAI key。
请按照下面的命令来安装所需要的包:
pip3 install elasticsearch python-dotenv我们创建如下的 python 应用:
write_index.py
from elasticsearch import Elasticsearch
from openai import OpenAI
import os
OPENAI_API_KEY= os.getenv("OPENAI_API_KEY")
es = Elasticsearch(
"https://localhost:9200",
ssl_assert_fingerprint='20:67:39:6C:33:C0:D6:AC:E2:E3:A5:2E:56:6C:57:4F:91:DC:41:4D:99:9B:7F:0F:1C:20:AD:E2:20:FE:1E:1B',
basic_auth=("elastic", "password")
)
openai = OpenAI(api_key=OPENAI_API_KEY)
movies = [
{"title": "Inception", "genre": "Sci-Fi", "release_year": 2010},
{"title": "The Shawshank Redemption", "genre": "Drama", "release_year": 1994},
{"title": "The Godfather", "genre": "Crime", "release_year": 1972},
{"title": "Pulp Fiction", "genre": "Crime", "release_year": 1994},
{"title": "Forrest Gump", "genre": "Drama", "release_year": 1994}
]
# Indexing movies
for movie in movies:
movie['title_embedding'] = openai.embeddings.create(
input=[movie['title']], model='text-embedding-3-small'
).data[0].embedding
es.index(index="movies", document=movie)我们使用如下的命令来运行脚本:
python3 write_index.py我们可以在 Kibana 中进行查看:
GET movies/_search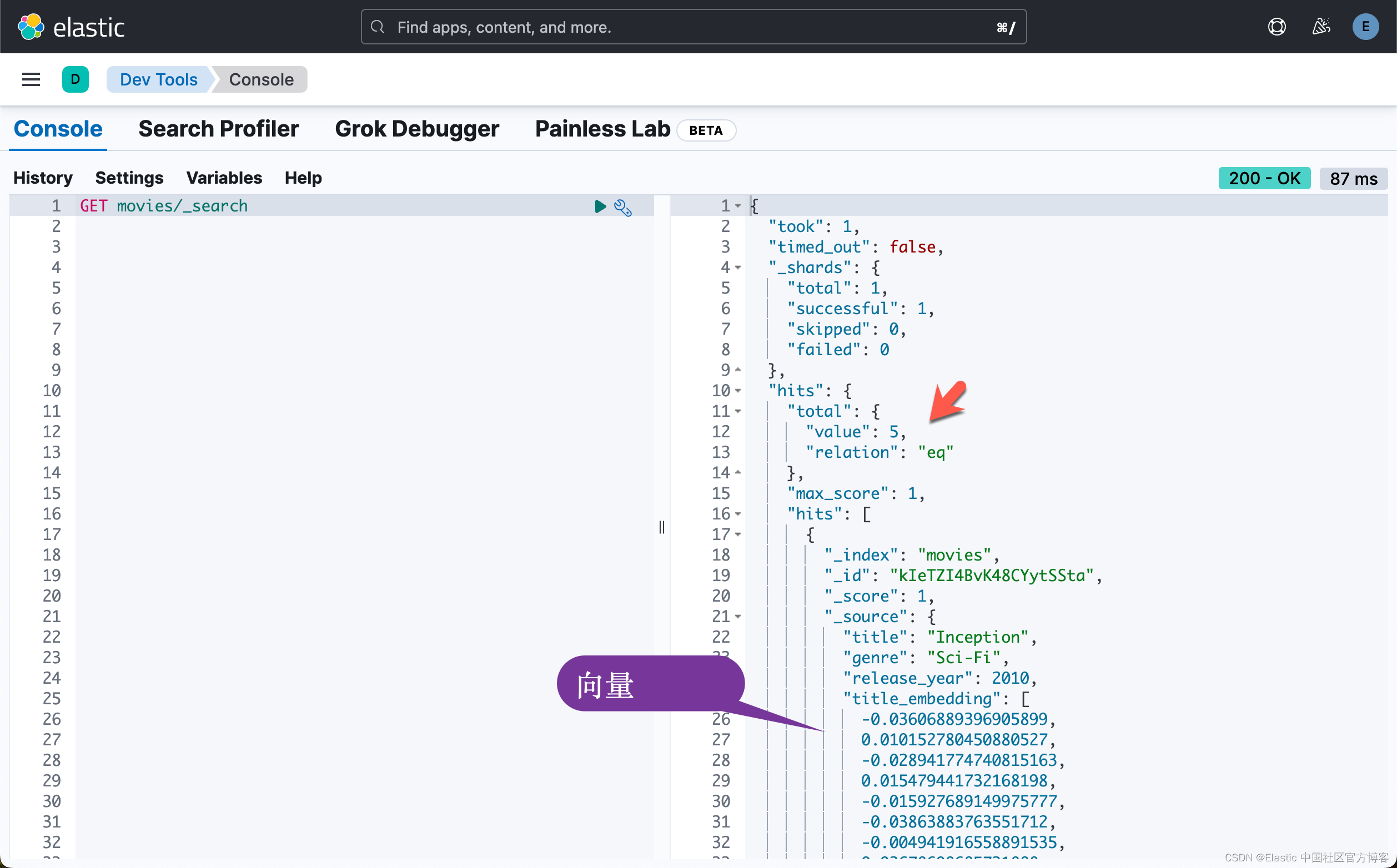
搜索索引
比方说,我们想要搜索与片名《godfather》紧密匹配的电影。 我们可以使用K最近邻(KNN)算法来搜索相关文档。 我们会将搜索限制为仅显示 1 个最接近的匹配结果。
首先我们需要获得单词 Godfather 的向量表示:
vector_value = openai_client.embeddings.create(
input=["Godfather"], model='text-embedding-3-small'
).data[0].embedding现在我们可以搜索电影索引来获取与片名《Godfather》紧密匹配的电影。 在我们的例子中,它应该与标题为《Godfather》的电影文档匹配。
query_string = {
"field": "title_embedding",
"query_vector": vector_value,
"k": 1,
"num_candidates": 100
}
results = es_client.search(index="movies", knn=query_string, source_includes=["title", "genre", "release_year"])
print(results['hits']['hits'])完整的 Python 应用如下:
search_index.py
from elasticsearch import Elasticsearch
from openai import OpenAI
import os
OPENAI_API_KEY= os.getenv("OPENAI_API_KEY")
es = Elasticsearch(
"https://localhost:9200",
ssl_assert_fingerprint='20:67:39:6C:33:C0:D6:AC:E2:E3:A5:2E:56:6C:57:4F:91:DC:41:4D:99:9B:7F:0F:1C:20:AD:E2:20:FE:1E:1B',
basic_auth=("elastic", "password")
)
openai = OpenAI(api_key=OPENAI_API_KEY)
vector_value = openai.embeddings.create(
input=["Godfather"], model='text-embedding-3-small'
).data[0].embedding
query_string = {
"field": "title_embedding",
"query_vector": vector_value,
"k": 1,
"num_candidates": 100
}
results = es.search(index="movies", knn=query_string, source_includes=["title", "genre", "release_year"])
print(results['hits']['hits'])运行上面的代码:
$ python3 search_index.py
[{'_index': 'movies', '_id': 'koeTZI4BvK48CYytTCuI', '_score': 0.8956262, '_source': {'title': 'The Godfather', 'genre': 'Crime', 'release_year': 1972}}]很显然,它找到了 Godfather 这个文档。
很多开发者可能想问,我们是不是也可以使用中文来进行搜索呢?
我们尝试如下的代码:
search_index.py
from elasticsearch import Elasticsearch
from openai import OpenAI
import os
OPENAI_API_KEY= os.getenv("OPENAI_API_KEY")
es = Elasticsearch(
"https://localhost:9200",
ssl_assert_fingerprint='20:67:39:6C:33:C0:D6:AC:E2:E3:A5:2E:56:6C:57:4F:91:DC:41:4D:99:9B:7F:0F:1C:20:AD:E2:20:FE:1E:1B',
basic_auth=("elastic", "password")
)
openai = OpenAI(api_key=OPENAI_API_KEY)
vector_value = openai.embeddings.create(
input=["教父"], model='text-embedding-3-small'
).data[0].embedding
query_string = {
"field": "title_embedding",
"query_vector": vector_value,
"k": 1,
"num_candidates": 100
}
results = es.search(index="movies", knn=query_string, source_includes=["title", "genre", "release_year"])
print(results['hits']['hits'])在上面的代码中,我们使用 “教父” 而不是 Godfather。运行上面的代码,它显示:
$ python3 search_index.py
[{'_index': 'movies', '_id': 'koeTZI4BvK48CYytTCuI', '_score': 0.6547822, '_source': {'title': 'The Godfather', 'genre': 'Crime', 'release_year': 1972}}]很显然,它也同样找到 Godfather 这个电影。它说明这个大语言模型支持多语言的搜索。