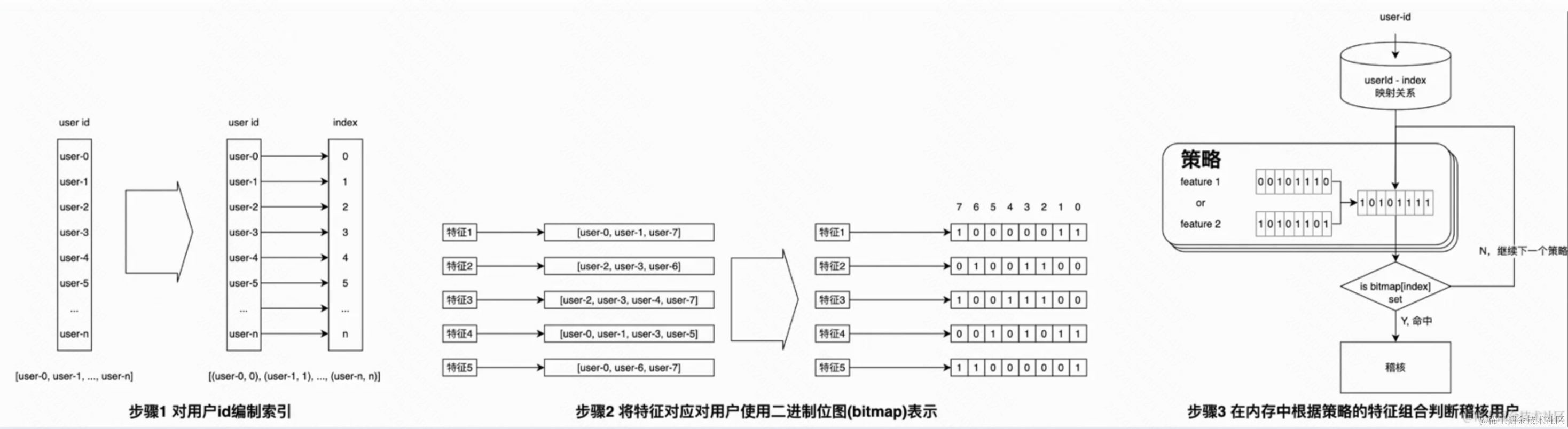
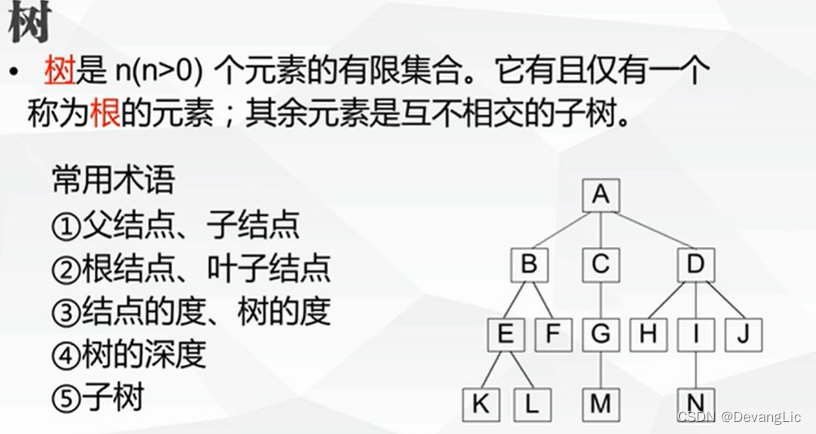
二叉树

参考 http://t.csdnimg.cn/ozVwT
数据库
SQL程序语言有四种类型,对数据库的基本操作都属于这四类,它们分别为;数据定义语言(DDL)、数据查询语言(DQL)、数据操纵语言(DML)、数据控制语言(DCL)
参考 https://zhuanlan.zhihu.com/p/391552199【CSDN跳转不方便,自行复制参考】
指数表示
https://blog.csdn.net/qwy1270005925/article/details/113009431

赋值奇观

给定定义语句 int a=3, b=2, c=1;,让我们逐个检查选项中的赋值体现式:
A. a=(b=4)=3;:这个表达式首先将 b 赋值为 4,然后尝试将 4 赋值给 a,但是由于赋值表达式 (b=4) 的结果是一个值,而不是一个可修改的变量,因此无法将 4 再次赋值给 a。这是一个语法错误,因此选项 A 是错误的。
B. a=b=c+1;:这个表达式首先计算 c+1,然后将结果赋值给 b,最后将 b 的值赋值给 a。这是一个合法的赋值表达式。
C. a=(b=4)+c;:这个表达式首先将 b 赋值为 4,然后将 4 加上 c 的值,最后将结果赋值给 a。这是一个合法的赋值表达式。
D. a=1+(b=c=4);:这个表达式首先将 c 赋值为 4,然后将 b 赋值为 4,最后将 1 加上 4 的值,结果再赋值给 a。这是一个合法的赋值表达式。
因此,错误的赋值体现式是选项 A. a=(b=4)=3;
if 后的条件式
可以为任意合法数值
if语句的基本形式是 if (expression) statement,其中 “expression” 是一个条件表达式,用于决定是否执行后面的语句。关于 “expression” 的论述,正确的是选项 D. 可以是任意合法的数值。
在C语言中,if语句中的 “expression” 可以是任何具有数值的表达式,而不仅仅限于逻辑值、整数值或正数。当 “expression” 的值为非零时,被视为真(true),执行后面的语句;当 “expression” 的值为零时,被视为假(false),不执行后面的语句。
因此,选项 D. 可以是任意合法的数值是正确的论述。
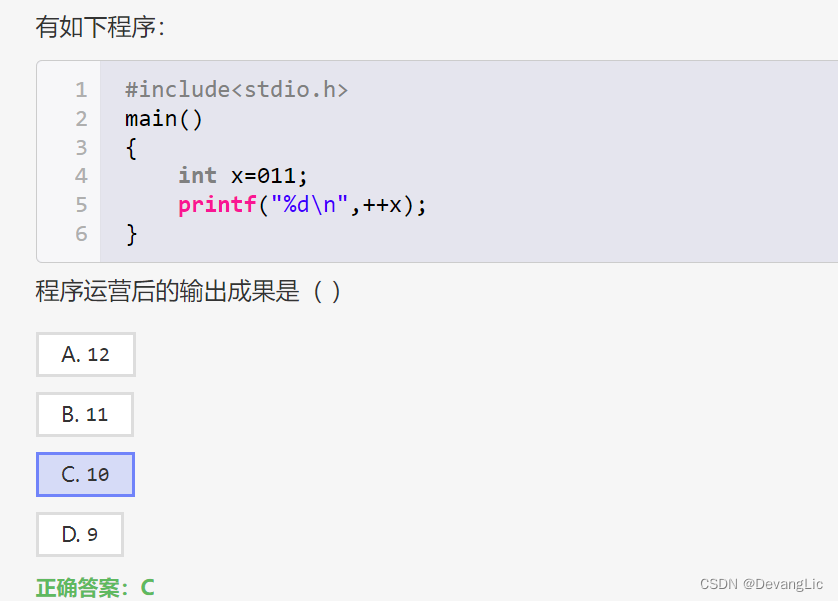
#进制奇观
在C语言中,以0开头的数字表示八进制数。因此,变量x被赋值为八进制的011,即十进制的9。然后使用++运算符对x进行自增操作,将x的值加1,变为10。最后通过printf函数输出x的值,所以程序的输出结果是10。
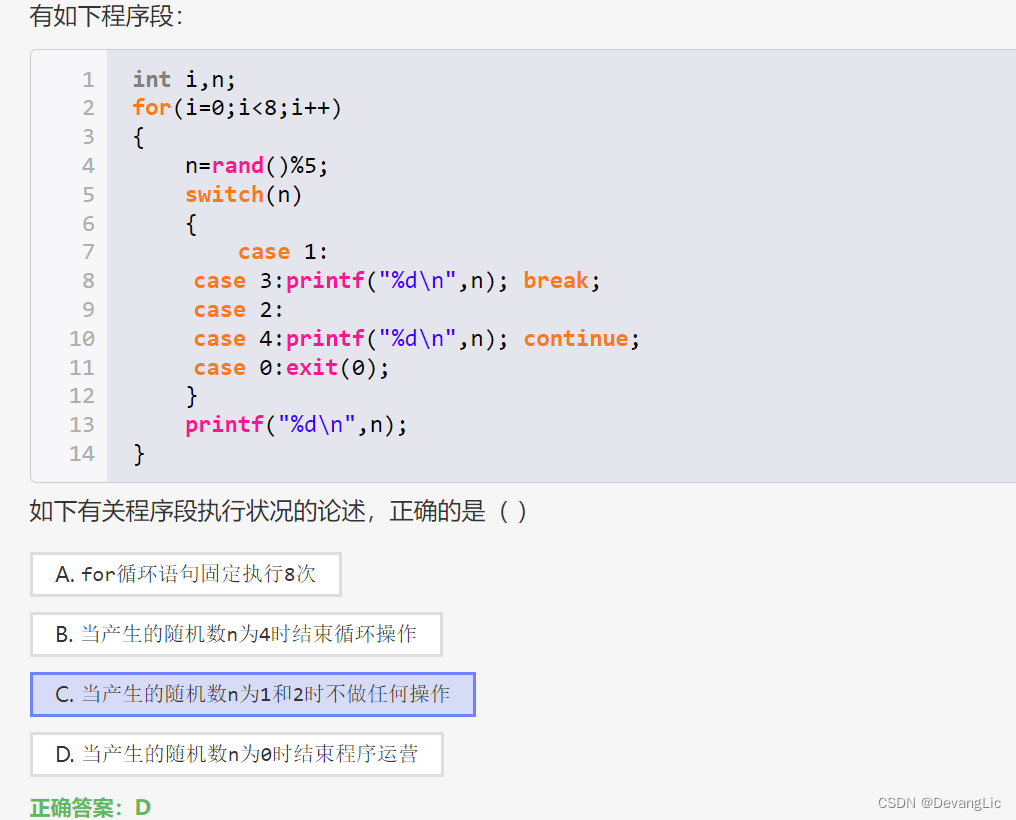
break switch
这段代码是一个C语言程序,它使用了一个for循环来迭代8次。在每次迭代中,它生成一个随机数n,范围是0到4(包括0和4)。然后根据n的值执行不同的操作:
- 如果n等于1或3,它会打印出n的值并跳出switch语句;
- 如果n等于2或4,它会打印出n的值并继续下一次迭代;
- 如果n等于0,它会立即退出程序。
在每次迭代的最后,无论n的值是多少,都会打印出n的值。因此,当程序结束时,会打印出8个数字,其中最后一个数字是0。
字符常量与字符串常量 不同
字符常量 ‘0’ 和 ‘9’ 而不是字符串常量 “0” 和 “9”。

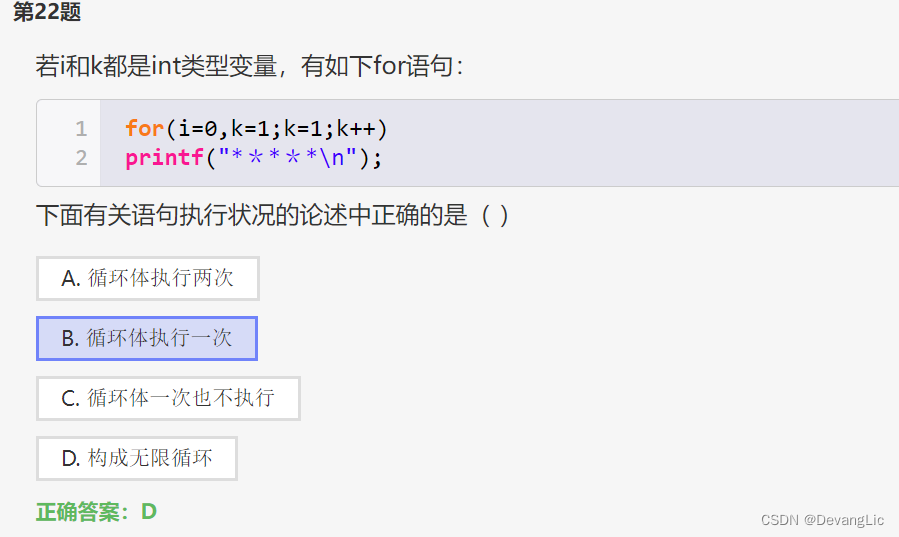
奇葩条件
在 C 语言中,赋值操作的结果是被赋值的变量的值。因此,这个循环条件实际上是一个永远为真的条件,因为 k=1 操作总是成功的,导致循环无限进行下去。
赋值
若有定义语句:char s[3][10],(*k)[3],*p;,则如下赋值语句正确的是( )
A. p=s;
B. p=k;
C. p=s[0];
D. k=s;
让我们逐个检查选项:
A.p=s;: 这个赋值语句是不正确的。因为s是一个二维字符数组,而p是一个指向字符的指针,类型不匹配。
B.p=k;: 这个赋值语句是不正确的。因为k是一个指向包含3个元素的一维字符数组的指针,而p是一个指向字符的指针,类型不匹配。
C.p=s[0];: 这个赋值语句是正确的。因为s[0]是一个字符数组,而p是一个指向字符的指针,可以将s[0]的地址赋给p。
D.k=s;: 这个赋值语句是不正确的。因为k是一个指向包含3个元素的一维字符数组的指针,而s是一个二维字符数组,类型不匹配。
因此,正确答案是 C.p=s[0];
static 我记性很好,别耍赖
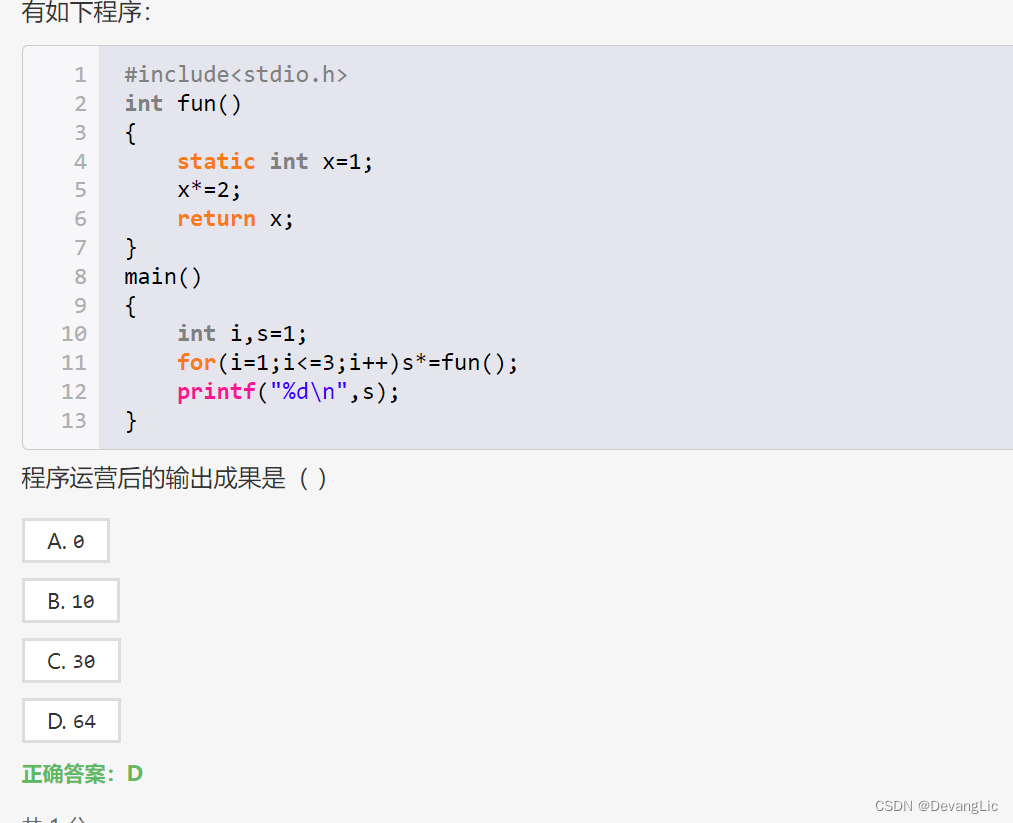
这段代码定义了一个静态局部变量
x和两个函数fun()和main()。fun()函数每次被调用时,将静态变量x的值乘以 2,并返回乘积结果。main()函数则通过循环调用fun()函数,并将返回值累乘到变量s中,最后输出s的值。
让我们逐行分析代码:
#include <stdlib.h>
这一行包含了标准库头文件 <stdlib.h>,虽然在这段代码中并未使用到该头文件,但是这是一个好的编程习惯,以确保程序中使用的函数能够正确地被声明。
int fun()
{
static int x = 1;
x *= 2;
return x;
}
这里定义了一个名为 fun() 的函数,它没有参数,并且返回一个整数值。函数内部有一个静态局部变量 x,它被初始化为 1。每次调用 fun() 函数时,x 的值都会乘以 2,然后返回乘积结果。
int main()
{
int i, s = 1;
for(i = 1; i <= 3; i++)
s *= fun();
printf("%d\n", s);
return 0;
}
在 main() 函数中,定义了两个整型变量 i 和 s,其中 s 初始化为 1。然后通过一个循环,调用 fun() 函数三次,并将返回值累乘到 s 中。最后,使用 printf() 函数输出 s 的值,并返回 0。
现在让我们来计算一下程序的输出:
第一次调用 fun() 函数时,x 的初始值是 1,返回值是 2。
第二次调用时,x 的值已经变成了 2,返回值是 4。
第三次调用时,x 的值已经变成了 4,返回值是 8。
因此,最终输出的结果是 2 * 4 * 8 = 64。
所以程序的输出是 64。
结构体结构体,有一点奇怪
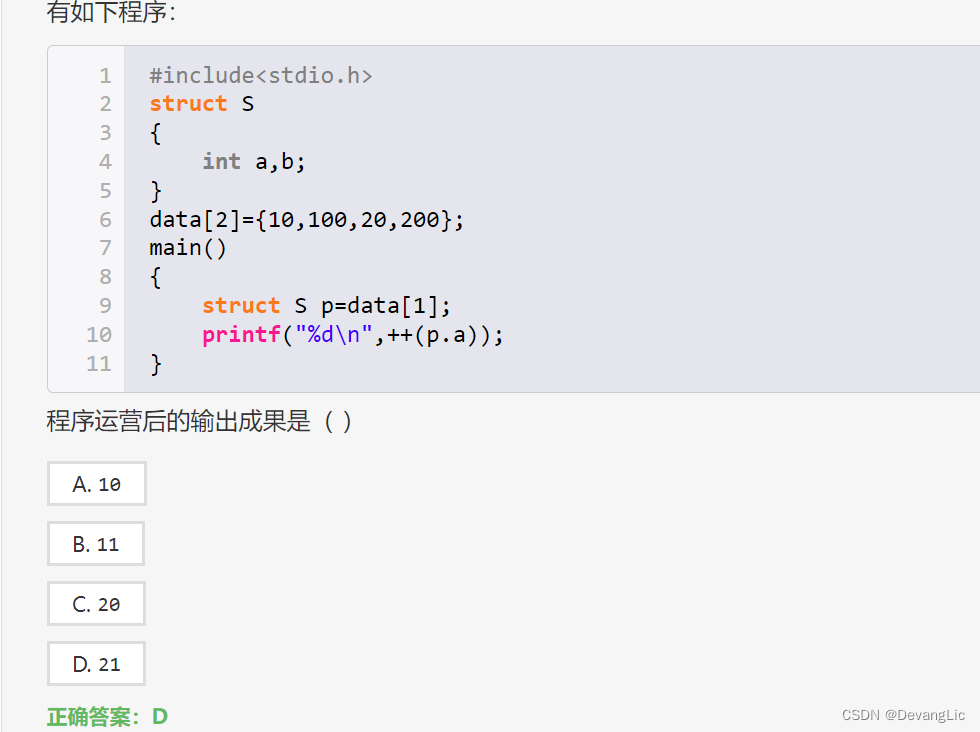
这段代码定义了一个结构体
S,包含两个成员变量a和b。然后创建了一个名为data的结构体数组,其中包含两个S类型的结构体实例,分别初始化为{10, 100}和{20, 200}。
接着在main()函数中,定义了一个名为p的S类型结构体变量,并将其初始化为data[1],即第二个结构体实例{20, 200}。
然后使用printf()函数输出p.a的值,但在输出之前对p.a进行了自增操作。需要注意的是,p是一个结构体变量,p.a是其中的成员变量,而对结构体成员变量进行自增操作是合法的。
因此,程序的输出是21。
文件操作

参考 https://www.cnblogs.com/spmt/p/10830600.html
打开方式 说明
r 以只读方式打开文件,只允许读取,不允许写入。该文件必须存在。
r+ 以读/写方式打开文件,允许读取和写入。该文件必须存在。
rb+ 以读/写方式打开一个二进制文件,允许读/写数据。
rt+ 以读/写方式打开一个文本文件,允许读和写。
w 以只写方式打开文件,若文件存在则长度清为0,即该文件内容消失,若不存在则创建该文件。
w+ 以读/写方式打开文件,若文件存在则文件长度清为零,即该文件内容会消失。若文件不存在则建立该文件。
a 以追加的方式打开只写文件。若文件不存在,则会建立该文件,如果文件存在,写入的数据会被加到文件尾,即文件原先的内容会被保留(EOF符保留)。
a+ 以追加方式打开可读/写的文件。若文件不存在,则会建立该文件,如果文件存在,则写入的数据会被加到文件尾后,即文件原先的内容会被保留(原来的EOF符 不保留)。
wb 以只写方式打开或新建一个二进制文件,只允许写数据。
wb+ 以读/写方式打开或建立一个二进制文件,允许读和写。
wt+ 以读/写方式打开或建立一个文本文件,允许读写。
at+ 以读/写方式打开一个文本文件,允许读或在文本末追加数据。
ab+ 以读/写方式打开一个二进制文件,允许读或在文件末追加数据。
自己补写程序注意变量类型