文章目录
- 前言
- 一、认识线程
- 1.1线程概念
- 1.2为什么要有线程
- 1.3线程和进程的区别(经典面试题)
- 二、创建线程
- 2.1继承 Thread 类,重写run
- 2.2实现 Runnable 接口,重写run
- 2.3继承 Thread 类,重写run,匿名内部类
- 2.4实现 Runnable 接口,重写run,匿名内部类
- 2.5lambda表达式【推荐写法】
- 2.6sleep提前唤醒
- 三、Thread的几个常见属性
- 四、Thread类的基本使用
- 4.1启动线程
- start和run的区别?(经典面试题)
- 4.2终止线程
- 4.3等待线程
- 五、线程的状态
前言
在当今科技发展迅速的社会中,多线程编程已经成为一种必不可少的技能。随着计算机硬件的发展,多核处理器已经成为主流,而多线程编程可以充分利用这些处理器的性能,提高程序的运行效率。因此,掌握多线程编程已经成为程序员们必须具备的技能之一。
一、认识线程
1.1线程概念
⼀个线程就是⼀个 “执⾏流”. 每个线程之间都可以按照顺序执⾏⾃⼰的代码. 多个线程之间 “同时” 执⾏着多份代码.
1.2为什么要有线程
- 尽管多进程也能实现并发编程,但是线程比进程更轻量,线程的创建、调度、销毁都比进程更快。
- "并发编程"成为刚需,大部分现代电脑使用的操作系统都支持多核CPU,这样可以更好地利用CPU资源,提高系统性能,而并发编程能更充分利用多核CPU。
- 有些场景需要"等待IO",为了让等待IO的时间可以去做其他工作,也需要并发编程提高效率。
1.3线程和进程的区别(经典面试题)
1.进程包含线程。
2.线程是系统调度执行的基本单位:每个线程是一个独立的执行流,可以执行一些代码,并且单独的参与到CPU的调度中( 状态、上下文、优先级、记账信息…每个线程有自己的一份);进程是系统资源分配的基本单位:每个进程有自己的资源,进程中的线程共用这一份资源(主要是内存空间和文件描述符)([^1]: 文件描述符是一个用于标识已被进程打开的文件的整数。在Unix-like操作系统中,包括Linux和Mac OS等,文件描述符是对文件、管道、套接字等I/O资源的引用。每个进程都有一个文件描述符表,其中存储了该进程打开的文件的信息)。
3.进程和进程之间不会互相影响;同一个进程中的线程之间,可能会相互干扰,引起线程安全问题,例如同一个进程中的某个线程抛出异常,可能影响到其他线程,会把整个进程中的所有线程都异常终止。
4.线程并不是越多越好,适度就行,如果线程过多,调度开销可能非常明显。
二、创建线程
2.1继承 Thread 类,重写run
package thread;
//1.创建一个自己的类,继承这个Thread
//为什么这个Thread可以直接用不需要导包?因为java标准库中,有一个特殊的包java.long,默认导入的
//为什么类前面没有public?因为一个.java文件中只能有一个public类
//这个类如果没有public包级作用于,就是只能在当前包里被其他的类使用
class MyThread extends Thread {
@Override
public void run() {
// run 方法就是该线程的入口方法.
System.out.println("hello world");
}
}
public class ThreadDemo1 {
public static void main(String[] args) {
// 2. 根据刚才的类, 创建出示例. (线程实例, 才是真正的线程).
// MyThread t = new MyThread();
Thread t = new MyThread();
// 3. 调用 Thread 的 start 方法, 才会真正调用系统 api, 在系统内核中创建出线程.
t.start();
}
}
2.2实现 Runnable 接口,重写run
package Thread;
//实现Runnable接口,重写run
class MyThread3 implements Runnable{
//Runnable可以理解为“可执行的”,通过这个接口,可以抽象表示出一段可以被其他实体来执行的代码
@Override
public void run() {
while(true){
System.out.println("hello runnable");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
}
}
public class ThreadDemo3 {
public static void main(String[] args) throws InterruptedException {
/*Runnable runnable=new MyThread3();
Thread t=new MyThread(runnable);*/
//还是需要搭配Thread类才能真正在系统中创建出线程
//这种写法其实就是把线程和要执行的任务进行了解耦合了
Thread t=new Thread(new MyThread3());
t.start();
while(true){
System.out.println("hello main");
Thread.sleep(1000);
}
}
}
2.3继承 Thread 类,重写run,匿名内部类
package Thread;
//继承Tread重写run,但是要使用匿名内部类(在一个类里面定义一个类,匿名意味着没有名字,不能重复使用)
public class ThreadDemo4 {
public static void main(String[] args) throws InterruptedException {
Thread t=new Thread(){//写{}意思是要定义一个类,与此同时,这个行新的类
//继承自Tread,此处{}中可以定义子类的属性和方法,此处最主要的目的是重写run方法
//与此同时,这个代码还创建了子例的实例
//t指向的实例(对象)并非单纯的Thread,而是Thread的子类(因为他是匿名类,所以我们也不知道他叫啥)
@Override
public void run() {
System.out.println("hello thread");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
};
t.start();
while(true){
System.out.println("hello main");
Thread.sleep(1000);
}
}
}
2.4实现 Runnable 接口,重写run,匿名内部类
package Thread;
//实现Runnable,重写run,匿名内部类
public class TreadDemo5 {
public static void main(String[] args) throws InterruptedException {
Thread t=new Thread(new Runnable(){//实现Runnable,重写run,匿名内部类
@Override
public void run() {
while(true){
System.out.println("hello runnable");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
}
});//Thread构造方法的参数,填写Runnable的匿名内部类的实例
t.start();
while(true){
System.out.println("hello main");
Thread.sleep(1000);
}
}
}
2.5lambda表达式【推荐写法】
package Thread;
//常用并推荐的写法,使用lambda表达式(匿名函数/方法)
//这个写法相当于实现了Runnable重写run,lambda代替了Runnable的位置
public class ThreadDemo6 {
public static void main(String[] args) throws InterruptedException {
Thread t=new Thread(()->{ //这里的()是形参列表,这里能带参数,线程入口不需要参数
//()前面应该有一个函数名,此处作为匿名函数,就没有名字
while(true){
System.out.println("hello thread");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
});
t.start();
while(true){
System.out.println("hello main");
Thread.sleep(1000);
}
}
}
2.6sleep提前唤醒

我们在写代码的时候可以发现,sleep这行代码会报错,报错信息是受查异常。
那么什么是受查异常呢?
代码会受查异常是因为在编译时,编译器要求程序必须处理可能抛出的异常,否则会报编译错误。受查异常是指在代码中明确定义了可能发生的异常,并且在方法中必须使用try-catch或者throws关键字来处理这些异常,否则会导致编译错误。
这里的异常意味着sleep(1000)过程中,可能被提前唤醒,正常情况下会休眠满一秒才能醒过来继续往下执行,也会有特殊情况提前唤醒。
另外还有非受查异常,非受查异常是指在代码中没有明确定义,或者不受编译器检查的异常,通常是由程序逻辑错误或者环境问题导致的异常,例如空指针异常、数组越界异常等。在处理非受查异常时,可以选择捕获处理,也可以直接抛出给调用方处理。非受查异常不会导致编译错误,但是如果没有处理可能会导致程序运行时异常。
在处理sleep提前唤醒可能导致的问题时,需要谨慎设计程序逻辑,确保在提前唤醒时程序的状态和数据都是正确的。同时,需要保证程序在提前唤醒后能够正确地恢复执行。
三、Thread的几个常见属性
| 属性 | 获取方法 |
|---|---|
| ID | getId():jvm自动分配的身份标识,保证唯一性,不同线程不会重复 |
| 名称 | getName():名称是各种调试⼯具⽤到 |
| 状态 | getState():状态表⽰线程当前所处的⼀个情况 |
| 优先级 | getPriority():在java中设置优先级效果不是很明显(对内核调度器的调度过程产生了一些影响)由于系统的随机调度 |
| 是否后台线程 | isDaemon():也可以称为是否是"后台线程",关于后台线程,需要记住⼀点:JVM会在⼀个进程的所有⾮后台线程结束后,才会结束运⾏ |
| 是否存活 | isAlive():简单的理解,为 run ⽅法是否运⾏结束了 |
| 是否被中断 | isInterrupted() |
以下是一些代码示例:
package Thread;
//获取线程引用
class MyThread4 extends Thread{
//如果是继承Thread,直接使用this拿到线程实例
//如果是Runnable或者lambda的方式,就不可以,因为此时的this已经不再指向Thread对象了
//就只能使用Thread.currentThread()了
@Override
public void run() {
System.out.println(this.getId()+","+this.getName());
}
}
public class ThreadDemo13 {
public static void main(String[] args) throws InterruptedException {
MyThread4 t1=new MyThread4();
MyThread4 t2=new MyThread4();
t1.start();
t2.start();
Thread.sleep(1000);
System.out.println(t1.getId()+","+t1.getName());//与run方法里面执行结果是一样的
System.out.println(t2.getId()+","+t2.getName());
}
}
package Thread;
//获取线程引用
//Thread.currentThread()获取到当前线程的引用
public class ThreadDemo14 {
public static void main(String[] args) {
Thread t1=new Thread(()->{
Thread t=Thread.currentThread();
System.out.println(t.getName());
});
Thread t2=new Thread(()->{
Thread t=Thread.currentThread();
System.out.println(t.getName());
});
t1.start();
t2.start();
}
}
package Thread;
//前台线程的运行会阻止进程结束
//后台线程的运行不会阻止进程结束
public class ThreadDemo7 {
public static void main(String[] args) {
Thread t=new Thread(new Runnable(){
@Override
public void run() {
while(true){
System.out.println("hello thread");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
}
},"这是我的线程");
//在start之前设置线程setDaemon为true为后台线程,进程直接结束(如果之后设置来不及)
t.setDaemon(true);
t.start();
}
}
package Thread;
public class TreadDemo8 {
public static void main(String[] args) throws InterruptedException {
Thread t=new Thread(()->{
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
});
System.out.println("start之前:"+t.isAlive());
t.start();
System.out.println("start之后:"+t.isAlive());
Thread.sleep(2000);//如果把2000改成1000,此时由于多线程调度,isAlive就未知了
//2s之后线程t结束
System.out.println("t结束之后:"+t.isAlive());
}
}
//java代码中定义的线程对象实例,虽然表示一个线程,这个对象本身的生命周期和内核中的pcb生命周期是不完全一样的
//Thread t=new Thread(),此时t对象有了,但是内核pcb还没有,isAlive就是false
//t.start(),真正在内核中创建出这个pcb,此时isAlive就是true
//当线程run执行完了,此时内核中线程就结束了,内核pcb释放,但是此时变量t可能还存在,于是isAlive也是false
四、Thread类的基本使用
4.1启动线程
之前我们已经看到了如何通过覆写 run ⽅法创建⼀个线程对象,但线程对象被创建出来并不意味着线程就开始运⾏了。调⽤ start ⽅法, 才真的在操作系统的底层创建出⼀个线程.
start和run的区别?(经典面试题)
start和run都是线程的启动方法,但是它们之间有一些区别:
- start方法是启动一个新的线程,当调用start方法时,会为该线程分配一个新的栈空间,并且在线程启动后会自动调用run方法来执行线程的任务。而直接调用run方法是在当前线程中执行run方法的任务。
- 使用start方法来启动线程能够实现并发执行,因为每次调用start方法都会创建一个新的线程。而直接调用run方法则只是在当前线程中执行任务,无法实现并发执行。
总的来说,start方法用于启动一个新的线程来执行任务,实现并发执行,需要较多的系统资源开销。而run方法则可以在当前线程中执行任务,但无法实现并发执行,不需要额外的系统资源开销。
4.2终止线程
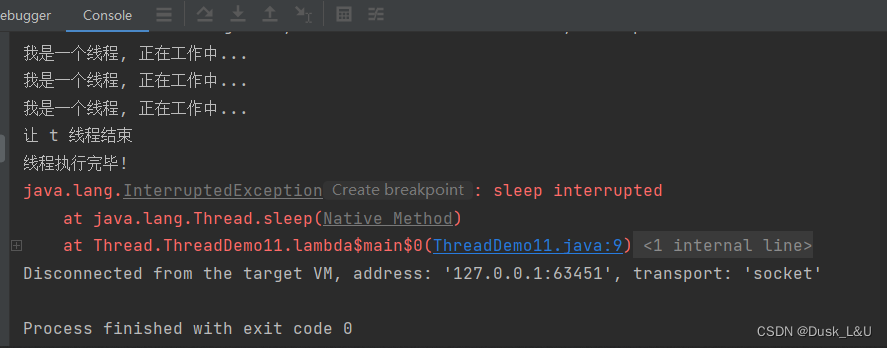
eg.下面这个例子在执行sleep的过程中,调用interrupt,大概率sleep休眠时间还没到就被提前唤醒,当我们去掉代码中的sleep时,能发现interrupt可以让线程顺利结束的,
public class ThreadDemo11 { public static void main(String[] args) throws InterruptedException { Thread t = new Thread(() -> { while (!Thread.currentThread().isInterrupted()) {//判定是否结束 System.out.println("我是一个线程, 正在工作中..."); try { Thread.sleep(1000); } catch (InterruptedException e) { e.printStackTrace(); } } System.out.println("线程执行完毕!"); }); t.start(); Thread.sleep(3000); // 使用一个 interrupt 方法, 来修改刚才标志位的值,设置让线程结束 System.out.println("让 t 线程结束"); t.interrupt(); } } ```
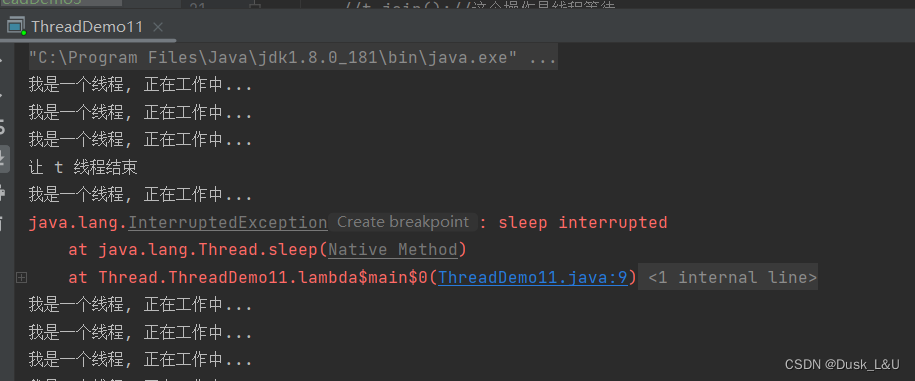
提前唤醒会出现两件事–
- 抛出InterruptedException异常,这个异常紧接着就会被catch获取到
- 清除Thread对象的isInterrupted标志位,意思是通过interrupt方法,已经把标志位设为true了,但是sleep提前唤醒操作,就把标志位又设回false了,此时循环还是会继续执行
那么怎么让线程结束呢? 在catch里面加上break就可以了~
线程顺利结束~
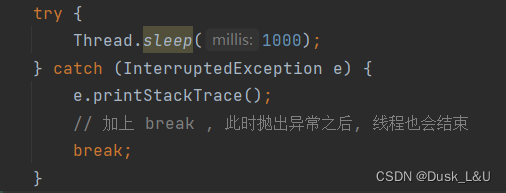
根据上诉,为什么sleep要清空标志位呢? 是为了给程序员更多的“可操作性空间”,可以在catch语句中写一些代码做一些处理——
1)让线程立刻结束(加上break)
2)让线程不结束,继续执行(不加break)
3)让线程执行一些逻辑后再结束(写一些其他代码再break)
另外,在实际开发中,catch里面应该写什么样的代码?(如果程序出现异常怎样处理更合理)
①尝试自动恢复,能自动恢复的尽量自动恢复,比如出现了一个网络通信相关的异常可以在catch尝试重连网络。
②记录日志(异常信息记录到文件中)。 ③发出警报,针对比较严重的问题,包括但不限于给程序员发邮件,发短信,打电话…
④也有少数的正常的业务逻辑,会依赖到catch,比如文件操作中的方法,就要通过catch来结束循环之类…[非常规用法]
4.3等待线程
join()方法让一个线程等待另一个线程结束。线程之间的执行顺序,是无序的调度过程,我们无法指定哪个线程何时结束,有的时候又希望能够控制线程之间结束的先后顺序,此时就可以用join,join这个方法会让等待线程阻塞,一直阻塞等待到被等待的线程执行完run方法。

执行join的时候,看t线程是否在运行
如果t运行中,main线程会阻塞(main线程暂时不参与cpu执行)
如果t运行结束,main线程从阻塞中恢复,并且继续往下执行
package Thread;
import javax.print.attribute.standard.PresentationDirection;
public class ThreadDemo12 {
// t 线程把计算的结果放到 result 中.
private static long result = 0;
public static void main(String[] args) throws InterruptedException {
Thread t = new Thread(() -> {
long tmp = 0;
for (long i = 1; i <= 50_0000_0000L; i++) {//实际上计算结果太大会溢出这里先忽略这个事情
tmp += i;
}
result += tmp;
});
Thread t2 = new Thread(() -> {
// try {
// // 如果把 join 加到末尾, 这个时候, 就还是 t 和 t2 并发执行, 没啥区别
// // 如果把 join 加到开头, 这个时候, 就是先执行 t, t2 先阻塞. 等到 t 执行完了之后, t2 继续执行. 又成了串行执行了.
// t.join();
// } catch (InterruptedException e) {
// e.printStackTrace();
// }
long tmp = 0;
for (long i = 50_0000_0001L; i <= 100_0000_0000L; i++) {
tmp += i;
}
result += tmp;
});
long beg = System.currentTimeMillis();
t.start();
t2.start();
// 主要就是不知道 t 线程要执行多久
// Thread.sleep(1000);
// 使用 join, 就会严格按照 t 线程执行结束来作为等待的条件.
// 什么时候 t 运行结束(计算完毕), 什么时候, join 就结束等待
// t 运行 1ms, join 就等待 1ms; t 运行 10s, join 就等待 10s
// 确保 join 之后得到的结果, 一定是靠谱的结果.
t.join();
t2.join();
long end = System.currentTimeMillis();
// 上面加上 join 之后, 结果就一定是 t 线程执行结束的结果了.
System.out.println("result = " + result);
System.out.println("time = " + (end - beg) + " ms");
}
}
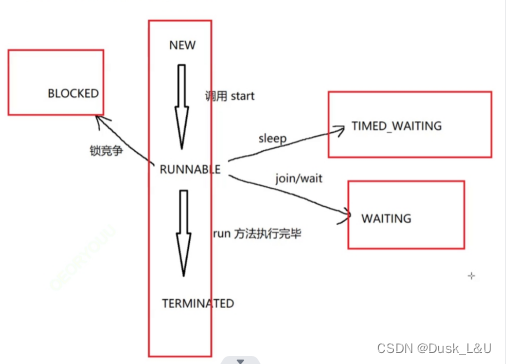
五、线程的状态
• NEW: Thread对象创建好了,但是还没有调用start方法在系统中创建线程。
• RUNNABLE: 就绪状态,表示这个线程正在cpu上执行,或者准备就绪随时可以去cpu执行。
• TIMED_WAITING: 指定时间的阻塞,在达到一定时间之后自动解除阻塞。
• WAITING: 不带时间的阻塞(死等),必须满足一定的条件才会解除阻塞。
• TERMINATED: Thread对象仍存在,但是系统内部的线程已经执行完毕了。
• BLOCKED: 由于锁竞争引起的阻塞。
![解决nginx报错nginx: [emerg] unknown log format main in 的方法](https://img-blog.csdnimg.cn/direct/4ad75087aad9426bb851295795af9126.png)