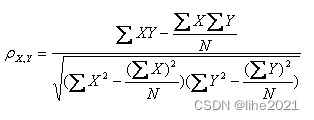模型拟合概念和欠拟合模型、过拟合调整策略
文章目录
- 模型拟合概念和欠拟合模型、过拟合调整策略
- 一、模型拟合度概念介绍
- 1.测试集的“不可知悖论”
- 2.模型拟合度概念与实验
- 二、过拟合、欠拟合问题解决方案
- 1. 欠拟合解决方案
- 2.过拟合解决方案
- 三、神经网络结果选择策略
- 1. 参数和超参数
- 2. 神经网络模型结构选择策略
- 3. 激活函数使用的单一性
- 参考
一、模型拟合度概念介绍
1.测试集的“不可知悖论”
通过此前介绍,已经知道深度学习模型主要是通过模型在测试集上的运行效果来判断模型好坏。测试集相当于是“高考”,而此前的模型训练都相当于是在练习,但怎么样的练习才能有效的提高高考成绩,这里就存在一个“悖论”,那就是练习是为了高考,而在高考前我们永远不知道练习是否有效,那高考对于练习的核心指导意义何在?在机器学习领域,严格意义上的测试集是不能参与建模的,此处不能参与建模,不仅是指在训练模型时不能带入测试集进行训练,更是指当模型训练完成之后、观察模型在测试集上的运行结果后,也不能据此再进行模型修改(比如增加神经网络层数),把数据带入模型训练是影响模型参数,而根据模型运行结果再进行模型结构调整,实际上是修改了模型超参数,不管是修改参数还是超参数,都是影响了模型建模过程,都相当于是带入进行了建模。是的,如果通过观察测试集结果再调整模型结构,也相当于是带入测试集数据进行训练,而严格意义上的测试集,是不能带入模型训练的。(这是一个有点绕的“悖论”…)
而泛化能力指的是在模型未知数据集(没带入进行训练的数据集)上的表现,虽然测试集只能测一次,但我们还是希望有机会能把模型带入未知数据集进行测试,此时我们就需要一类新的数据集——验证集。验证集在模型训练阶段不会带入模型进行训练,但当模型训练结束之后,会把模型带入验证集进行计算,通过观测验证集上模型运行结果,判断模型是否要进行调整,验证集也会模型训练,只不过验证集训练的不是模型参数,而是模型超参数,关于模型参数和超参数的概念后面还会再详细讨论,当然,也可以把验证集看成是应对高考的“模拟考试”,通过“模拟考试”的考试结果来调整复习策略,从而更好的应对“高考”。总的来说,测试集是严格不能带入训练的数据集,在实际建模过程中可以先把测试集切分出来,然后“假装这个数据集不存在”,在剩余的数据集中划分训练集和验证集,把训练集带入模型进行运算,再把验证集放在训练好的模型中进行运行,观测运行结果,再进行模型调整。
总的来说,在模型训练和观测模型运行结果的过程总共涉及三类数据集,分别是训练集、验证集和测试集。不过由于测试集定位特殊,在一些不需要太严谨的场景下,有时也会混用验证集和测试集的概念。在不区分验证集和测试集的情况下,当数据集切分完成后,对于一个模型来说,我们能够获得两套模型运行结果,一个是训练集上模型效果,一个是测试集上模型效果,而这组结果,就将是整个模型优化的基础数据。
2.模型拟合度概念与实验
在所有的模型优化问题中,最基础的也是最核心的问题,就是关于模型拟合程度的探讨与优化。根据此前的讨论,模型如果能很好的捕捉总体规律,就能够有较好的未知数据的预测效果。但限制模型捕捉总体规律的原因主要有两点:
- 其一,样本数据能否很好的反应总体规律
如果样本数据本身无法很好的反应总体规律,那建模的过程就算捕捉到了规律可能也无法适用于未知数据。
- 其二,样本数据能反应总体规律,但模型没有捕捉到
如果说要解决第一种情况需要在数据获取端多下功夫,那么如果数据能反应总体规律而模型效果不佳,则核心原因就在模型本身了。
此前介绍过,机器学习模型评估主要依据模型在测试集上的表现,如果测试集效果不好,则我们认为模型还有待提升,但导致模型在测试集上效果不好的原因其实也主要有两点,其一是模型没捕捉到训练集上数据的规律,其二则是模型过分捕捉训练集上的数据规律,导致模型捕获了大量训练集独有的、无法适用于总体的规律(局部规律),而测试集也是从总体中来,这些规律也不适用于测试集。前一种情况我们称模型为欠拟合,后一种情况我们称模型为过拟合。

根据最终的输出结果能够清楚的看到,1阶多项式拟合的时候蓝色拟合曲线即无法捕捉数据集的分布规律,离数据集背后客观规律也很远,而三阶多项式在这两方面表现良好,十阶多项式则在数据集分布规律捕捉上表现良好,单同样偏离红色曲线较远。此时一阶多项式实际上就是欠拟合,而十阶多项式则过分捕捉噪声数据的分布规律,而噪声之所以被称作噪声,是因为其分布本身毫无规律可言,或者其分布规律毫无价值(如此处噪声分布为均匀分布),因此就算十阶多项式在当前训练数据集上拟合度很高,但其捕捉到的无用规律无法推广到新的数据集上,因此该模型在测试数据集上执行过程将会有很大误差。即模型训练误差很小,但泛化误差很大。
不难发现,过拟合产生的根本原因,还是样本之间有“误差”,或者不同批次的数据规律不完全一致。
因此,我们有基本结论如下:
-
模型欠拟合:训练集上误差较大
-
模型过拟合:训练集上误差较小,但测试集上误差较大
而模型是否出现欠拟合或者过拟合,其实和模型复杂度有很大关系。我们通过上述模型不难看出,模型越复杂,越有能力捕捉训练集上的规律,因此如果模型欠拟合,我们可以通过提高模型复杂度来进一步捕捉规律,但同时也会面临模型过于复杂而导致过拟合的风险。
对于深度学习来说,模型复杂度和模型结构直接相关,隐藏层越多、每一层神经元越多、模型就越复杂,当然模型复杂度还和激活函数有关。模型拟合度优化是模型优化的核心,深度学习模型的一系列优化方法也基本是根据拟合度优化这一核心目标衍生出来的,接下来,我们就来看下如何通过调整模型结构来进行拟合度优化。
二、过拟合、欠拟合问题解决方案
1. 欠拟合解决方案
- 增加模型复杂度,通过增加模型参数来增加模型学习能力:
- 对于原本的算法,可以通过增加模型深度的方法增大模型的复杂度;
- 选择更加复杂的算法模型;
- 增加特征数量:增加更多强表达能力的特征;
- 调整模型参数或者超参
- 修改学习率、隐藏层数量等模型参数、优化算法中的训练参数,等超参增强训练过程中模型的学习能力;
- 降低正则化
- 若之前有增加正则化,则需要考虑是否存在正则化过大导致的学习能力下降
2.过拟合解决方案
- 增加训练数据
- 采用更强的正则化约束
- 减少特征数量
- 降低模型复杂度
- 使用Dropout层
- 使用早停提前结束训练
三、神经网络结果选择策略
1. 参数和超参数
在实际建模过程中,神经网络的模型结构是影响建模结果至关重要的因素。但对于一个数据集,构建几层神经网络、每一层设置多少个神经元,却不是一个存在唯一最优解的参数,虽然我们希望能够有个数学过程帮我们直接确定模型结构,但由于影响因素较多,很多时候模型在确定模型结构上,还是一个首先根据经验设置模型结构、然后再根据实际建模效果不断调整的过程。
关于参数和超参数的说明:
在机器学习中,参数其实分为两类,其一是参数,其二则是超参数,一个影响模型的变量是参数还是超参数,核心区别就在于这个变量的取值能否通过一个严谨的数学过程求出,如果可以,我们就称其为参数,如果不行,我们就称其为超参数。典型的,如简单线性回归中的自变量的权重,我们通过最小二乘法或者梯度下降算法,能够求得一组全域最优解,因此自变量的权重就是参数,类似的,复杂神经网络中的神经元连接权重也是参数。但除此以外,还有一类影响模型效果的变量却无法通过构建数学方程、然后采用优化算法算得最优解,典型的如训练集和测试集划分比例、神经网络的层数、每一层神经元个数等等,这些变量同样也会影响模型效果,但由于无法通过数学过程求得最优解,很多时候我们都是凭借经验设置数值,然后根据建模结果再进行手动调节,这类变量我们称其为超参数。
不难发现,在实际机器学习建模过程中超参数出现的场景并不比参数出现的场景少,甚至很多时候,超参数的边界也和我们如何看待一个模型息息相关,例如,如果我们把“选什么模型”也看成是一个最终影响建模效果的变量,那这个变量也是一个超参数。也就是说,超参数也就是由“人来决策”的部分场合,而这部分也就是体现算法工程师核心竞争力的环节。
当然,就像此前介绍的那样,参数通过优化算法计算出结果,而机器学习发展至今,也出现了很多辅助超参数调节的工具,比如网格搜索(grid search)、AutoML等,但哪怕是利用工具调整超参数,无数前辈在长期实践积累下来的建模经验仍然是弥足珍贵的,也是我们需要不断学习、不断理解,当然,更重要的是,所有技术人经验的积累是一个整体,因此也是需要我们参与分享的。
2. 神经网络模型结构选择策略
而一般来说在模型结构选择方面,根据经验,有如下基本结论:
- 层数选择方面
- 三层以内:模型效果会随着层数增加而增加;
- 三层至六层:随着层数的增加,模型的稳定性迭代的稳定性会受到影响,并且这种影响是随着层数增加“指数级”增加的,此时我们就需要采用一些优化方法对输入数据、激活函数、损失函数和迭代过程进行优化,一般来说在六层以内的神经网络在通用的优化算法配合下,是能够收敛至一个较好的结果的;
- 六层以上:在模型超过六层之后,优化方法在一定程度上仍然能够辅助模型训练,但此时保障模型正常训练的更为核心的影响因素,就变成了数据量本身和算力。神经网络模型要迭代收敛至一个稳定的结果,所需的epoch是随着神经网络层数增加而增加的,也就是说神经网络模型越复杂,收敛所需迭代的轮数就越多,此时所需的算力也就越多。而另一方面,伴随着模型复杂度增加,训练所需的数据量也会增加,如果是复杂模型应用于小量样本数据,则极有可能会出现“过拟合”的问题从而影响模型的泛化能力。当然,伴随着模型复杂度提升、所需训练数据增加,对模型优化所采用的优化算法也会更加复杂。也就是说,六层以内神经网络应对六层以上的神经网络模型,我们需要更多的算力支持、更多的数据量、以及更加复杂的优化手段支持。
- 每一层神经元个数选择方面:当然输入层的神经元个数就是特征个数,而输出层神经元个数,如果是回归类问题或者是逻辑回归解决二分类问题,输出层就只有一个神经元,而如果是多分类问题,输出层神经元个数就是类别总数。而隐藏层神经元个数,可以按照最多不超过输入特征的2-4倍进行设置,当然默认连接方式是全连接,每一个隐藏层可以设置相同数量的神经元。其实对于神经元个数设置来说,后期是有调整空间的,哪怕模型创建过程神经元数量有些“饱和”,我们后期我们可以通过丢弃法(优化方法的一种)对隐藏层神经元个数和连接方式进行修改。对于某些非结构化数据来说,隐藏层神经元个数也会根据数据情况来进行设置,如神经元数量和图像关键点数量匹配等。
3. 激活函数使用的单一性
同时,对于激活函数的交叉使用,需要知道,通常来说,是不会出现多种激活函数应用于一个神经网络中的情况的。主要原因并不是因为模型效果就一定会变差,而是如果几种激活函数效果类似,那么交叉使用几种激活函数其实效果和使用一种激活函数区别不大,而如果几种激活函数效果差异非常明显,那么这几种激活函数的堆加就会使得模型变得非常不可控。此前的实验让我们深刻体会优化算法的必要性,但目前工业界所掌握的、针对激活函数的优化算法都是针对某一种激活函数来使用的,激活函数的交叉使用会令这些优化算法失效。因此,尽管机器学习模型是“效果为王”,但在基础理论没有进一步突破之前,不推荐在一个神经网路中使用多种激活函数。
参考
菜菜子的深度学习









![带你学会深度学习之卷积神经网络[CNN] - 5](https://img-blog.csdnimg.cn/direct/ae10a01bc333454992befb6dd1e8f08d.png)