作者:林清山(隆基)
前言:
从初代开源消息队列崛起,到 PC 互联网、移动互联网爆发式发展,再到如今 IoT、云计算、云原生引领了新的技术趋势,消息中间件的发展已经走过了 30 多个年头。
目前,消息中间件在国内许多行业的关键应用中扮演着至关重要的角色。随着数字化转型的深入,客户在使用消息技术的过程中往往同时涉及交叉场景,比如同时进行物联网消息、微服务消息的处理,同时进行应用集成、数据集成、实时分析等,企业需要为此维护多套消息系统,付出更多的资源成本和学习成本。
在这样的背景下,2022 年,RocketMQ 5.0 正式发布,相对于 RocketMQ 4.0,架构走向云原生化,并且覆盖了更多的业务场景。
背景
什么是流存储呢?前面我们在 《从互联网到云时代,Apache RocketMQ 是如何演进的?》 里提到 RocketMQ 5.0 具备“消息、事件、流”一体能力。这里的“流”指的就是流处理,而流存储是流处理的基石,流存储也是 RocketMQ 从应用架构集成走向数据架构集成的基础, 为大数据架构的数据组件提供异步解耦的能力。
本文第一部分,我们将从使用的角度出发,详细展示一下流存储的场景,看看它和业务消息的场景有哪些区别?第二部分,我们会讲 RocketMQ 5.0 面向流存储的场景,提供了哪些特性?第三部分,我们再结合两个数据集成的案例,来帮助大家了解流存储的用法。
什么是流场景
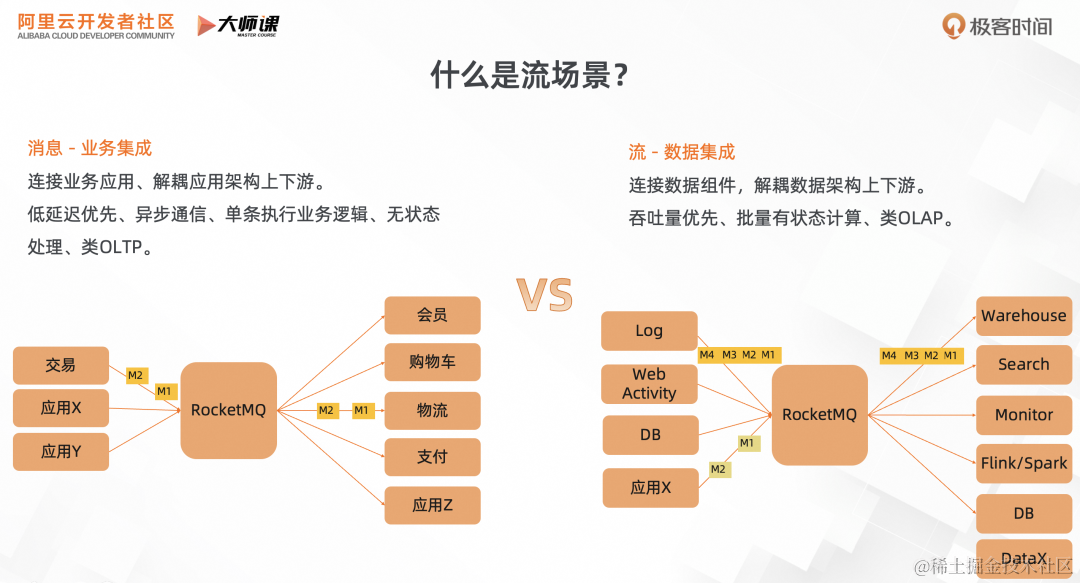
先看第一部分,什么是流场景?我们通过下面这个对比图来看,消息和流的区别。
前面我们讲的消息基础(《RocketMQ 5.0 架构解析:如何基于云原生架构支撑多元化场景》、《RocketMQ 在业务消息场景的优势详解》)、消息进阶(《Apache RocketMQ 5.0 消息进阶:如何支撑复杂的业务消息场景?》)都侧重于讲消息的业务集成。这里 RocketMQ 的主要作用是连接业务应用,解耦业务架构的上下游系统,比如交易系统的解耦。这类场景,更多的是在线业务,由用户触发某个业务流程,比如购买。为了保障用户体验,消息系统要优先保障低延迟。这个场景里和同步通信 RPC 对应,消息系统承担都是异步通信职责。在消息消费层面,更多的是基于消息数据执行对应的业务逻辑,触发下一个业务流程。每条消息的处理都是不相关的,无状态的。侧重于业务数字化场景,可类比于数据库的 OLTP,单次操作数据量少,用于在线交易。
再来看流场景,它主要是侧重于数据集成,连接各种数据组件,进行数据分发,解耦数据架构的上下游系统。 比如日志解决方案,采集日志数据,进行 ETL 将日志数据分发到搜索引擎、流计算、数据仓库等。除了日志之外,数据库 Binlog 分发、页面点击流也是常见的数据源。在这种场景里里面,由于是离线业务,它对低延迟的需求较弱,更加侧重于大批量吞吐型负载。另外在消息消费阶段,不再是单条消息处理,更多的是批量转储,或者批量进行流计算。侧重于数字业务化场景,可类比于数据库的 OLAP,单次操作数据量大,用于离线分析场景。
流存储特性
1. 流存储基础
第二部分我们看看,在流的场景下,对于 RocketMQ 的用法有何不同?
最大的区别就是它对于消息数据的访问模式:
- 由于用在数据集成场景,对于大规模的数据集成,不可避免的要涉及到数据的分片,基于数据分片来连接上下游数据系统。为了提升数据集成的质量,需要 Topic 的分区数不变,这样才能保证同一个分区的数据不会错乱。在消息的读写方式上,不再是指定 Topic 读写,而是指定 Topic 分片,也就是队列,进行读写操作。
- 作为流存储系统,下游的消费通常会是一些流计算引擎,用于有状态计算。为了支撑流计算引擎的容错处理,它需要支持 checkpoint 机制,类似于为流计算引擎提供 redolog,能够按照队列位点重放消息,重新恢复流计算的状态。它也会要求分片内有序,同一个 key 的数据会 hash 到同一个分片,用于实现 keyby 的操作。
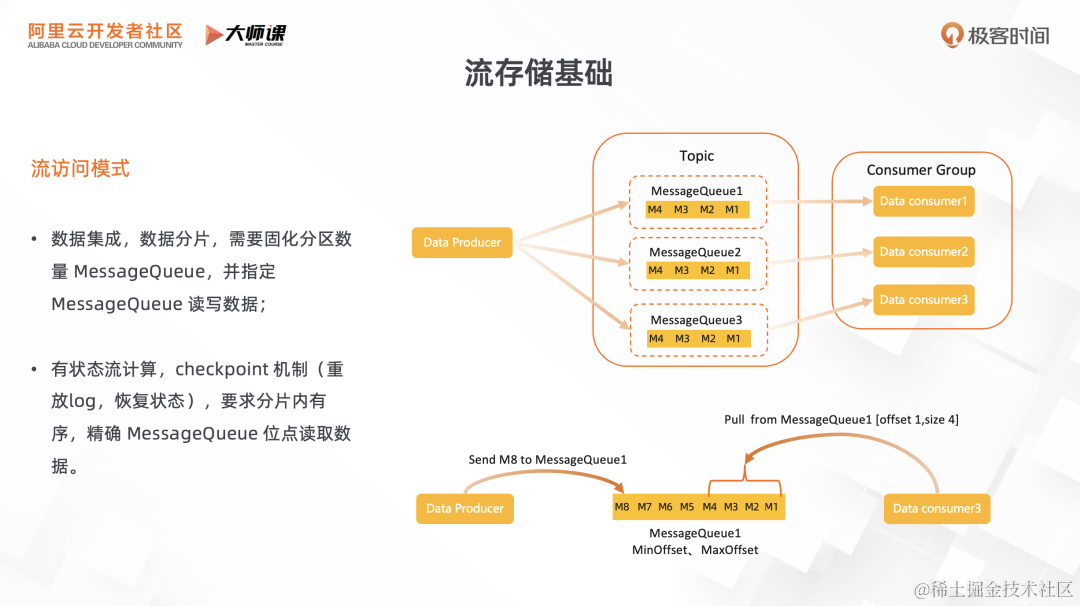
这就是流存储访问模式跟消息访问模式的区别。在消息场景里,用户只需要关注到 topic 资源,无需了解队列、位点等概念。
2. 流存储弹性
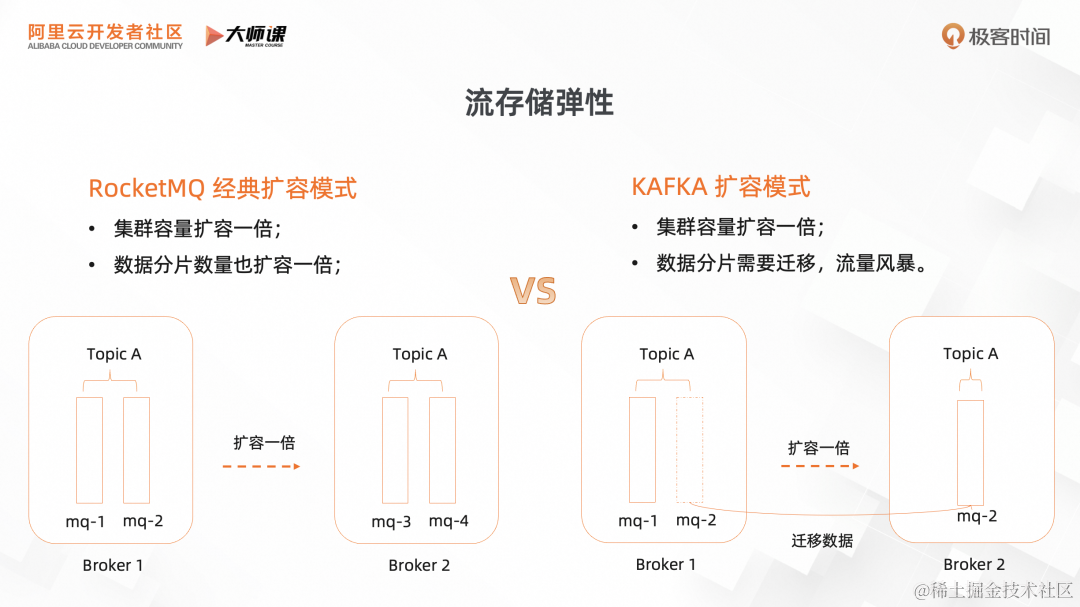
2.1 RocketMQ 经典扩容模式
刚才我们从用户维度了解了流存储的使用方式,现在我们再从运维角度来看流存储如何弹性?
我们先回顾一下现在业界的弹性方式。左下图是 RocketMQ 的经典扩容模式,比如说要将 Topic A 的容量扩容一倍,一般做法是新增一台机器,然后创建 Topic A,新增同等数量的队列。这样的话,分片数量也会扩容一倍,无法满足流存储固定分区的场景。
右下图则是 Kafka 的扩容模式,要将 Topic A 的容量扩容一倍时,需要添加一个新节点,并将原来旧节点的分区 mq-2 迁移到新节点。它虽然可以保证数分区数量不变,但是要对分区数据做迁移。当分区数特别多且数据量大,讲对集群产生流量风暴,严重影响稳定性,而且整个扩容时间不可控。
现有的流存储弹性机制都有所不足。
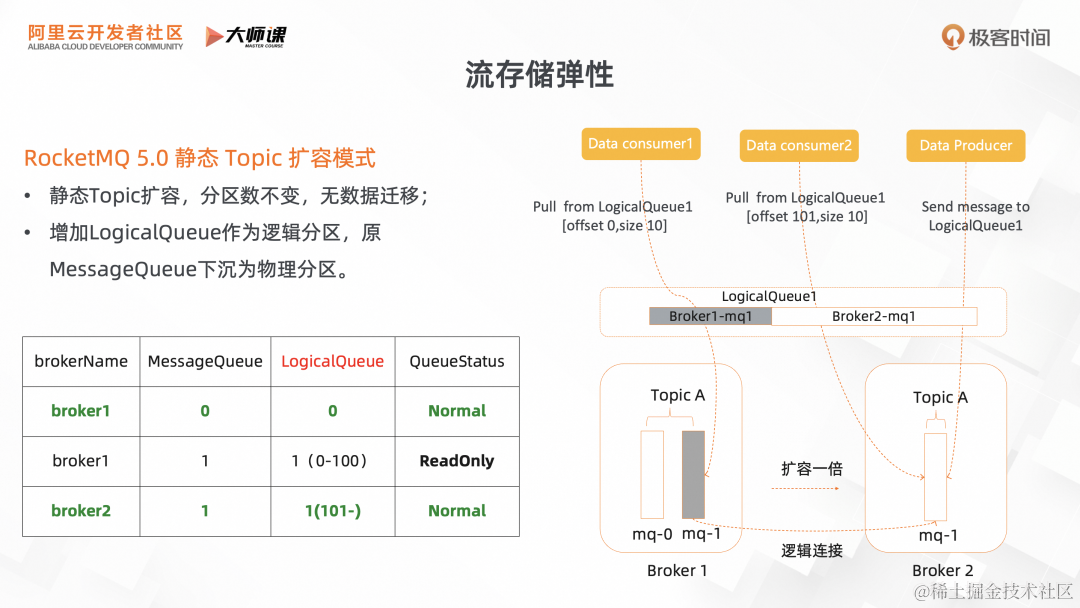
2.2 RocketMQ 5.0 静态 Topic 扩容模式
为了解决经典流存储的扩容难题,RocketMQ 5.0 提供了一种新的模式,引入静态 topic 。在静态 topic 的扩容模式,可以做到分区数不变,且扩容过程无数据迁移,可以实现秒级的扩容。
它的实现关键点是引入逻辑队列的概念。就是对于用户来说,它的访问的对象是不再是原来绑定到某个 Broker 的物理队列,而是 Topic 全局的逻辑队列,每个逻辑队列会对应一个或者多个物理队列。
我们基于实际的案例,来理解逻辑队列的实现原理。图为 Topic A 进行流量扩容一倍的操作,最初逻辑队列 1 绑定的物理队列是 Broker1 的 mq1。在扩容完成后,Broker1-mq1 变成只读状态,逻辑队列 1 的最新读写操作都在 Broker2-mq1,生产者最新的消息都会发往 Broker2-mq1。消费者如果读最新数据,则直接从 Broke2-mq1 的物理队列里面去读取;如果它读的是老数据的话,读请求讲转发到旧物理队列 Broker1-mq1。这样就完成了整个静态 topic 的扩容流程。既保证的分区数不变,又实现了没有数据迁移,降低了大量的数据复制,提升了系统的稳定性。
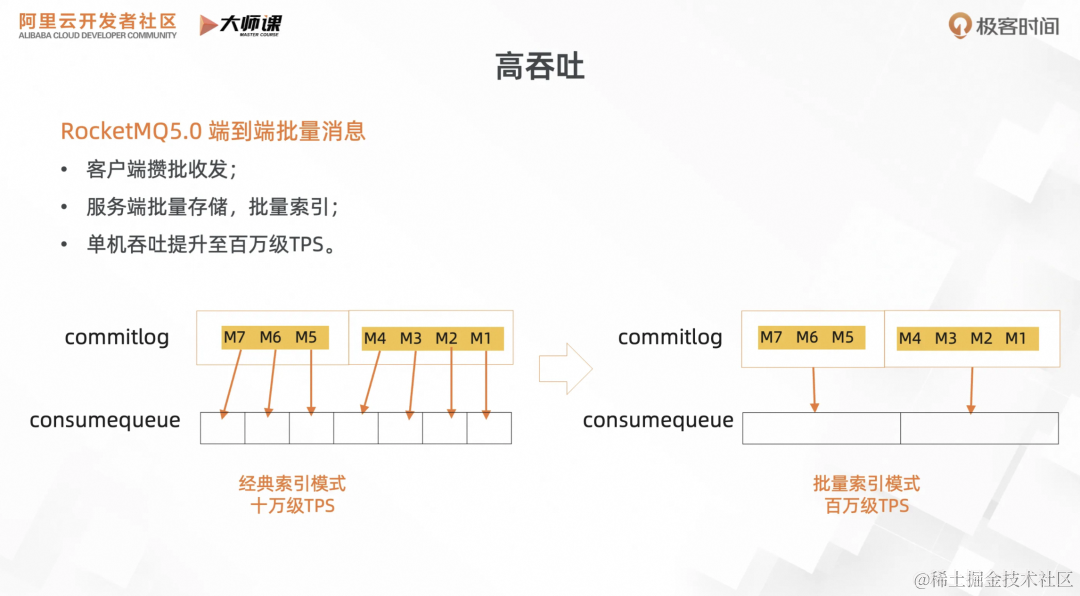
3. 高吞吐
在流场景里面,还有一个很重要的变化,就是数据类型的变化。
做个简单对比,业务集成场景,消息的数据承载的是业务事件,比如说订单操作、物流操作,特点就是数据规模较小,但是每一条数据的价值都特别高,访问模式是偏向于在线的,单条事务的短平快访问模式。
而在流场景里面,更多的是一些非交易型的数据。比如用户日志,系统的监控、IoT 的一些传感器数据、网站的点击流等等。特点是数据规模有数量级的提升,但单条数据的价值比较低的,访问模式偏向于离线批量传输。所以在流的场景里面,RocketMQ 存储要面向高吞吐做更多的优化。

在 RocketMQ 5.0 里面,我们引入了端到端的批量消息。如何理解端到端呢?就是从客户端开始,在发送阶段,消息在客户端攒批到一定数量,直接一个 RPC 请求里面直接发到 Broker 端。Broker 存储阶段,直接把整批消息存储,用批量索引的技术,一批消息只会构建一个索引,大幅度提升索引构建速度。在消费阶段,也是按照整批数据读取到消费端,先进行解包操作,最后执行消费逻辑。这样整个 Broker 的消息 TPS 可以从原来的十万级提升至百万级。
4. 流的状态
流存储通常会对接流计算引擎,比如 Flink、Spark 等。流计算引擎涉及的一些有状态计算,如数据聚合类的,求平均、求总和、keyby、时间窗口等算子都需要维护计算状态。
所以在 RocketMQ 5.0 里面,我们新增了 CompactTopic 的类型,是一种以流为核心的类 KV 服务,在不引入外部 KV 系统的情况下维护流的状态。它还适用于一些特殊场景,可作为最新值队列,比如用于股票价格流场景,股票交易,用户只关注每只股票的最新价格。
我们通过下图来了解一下 CompactTopic 的实现,在 CompactTopic 里面,每条消息就是一对 KV。如果用常规的 Topic,那么同一个 Key 的持续更新会占用大量的空间,影响读的效率。在生命周期管理上,也会因为磁盘占用过高,按照 FIFO 的方式,旧数据被整批删除。而对于 CompactTopic 来说,Broker 会定期对同一个 Key 的消息进行合并,节约存储空间,用户对 Topic 的流式访问,也只会读到每个 Key 的最新值。
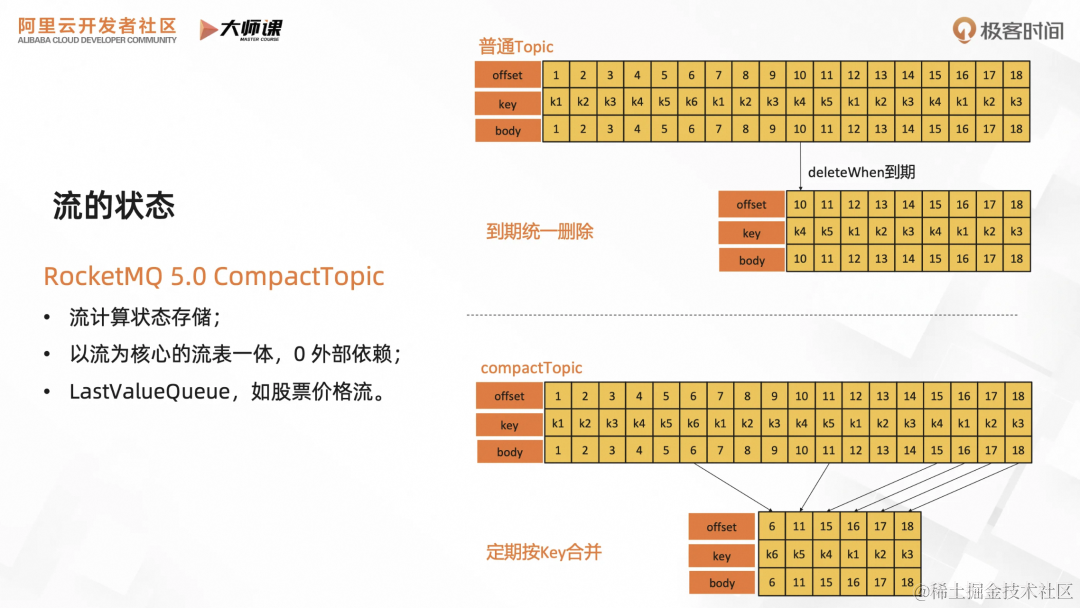
我们来结合这个例子,能对 CompactTopic 有更加形象的理解。消息生产没啥区别,需要为消息添加 Key。区别主要体现在消费的方式上,首先我们要用 PullConsumer,这是一个用于流场景的的消费者 SDK。然后我们要获取 Compact topic 的队列,进行队列分片。然后每一个消费者实例都会分配到固定的队列,承载这个分区的流状态的恢复。在这里的话,用 HashMap 进行模拟,重放整个队列,重新构建 KV。

5. 流数据 Schema
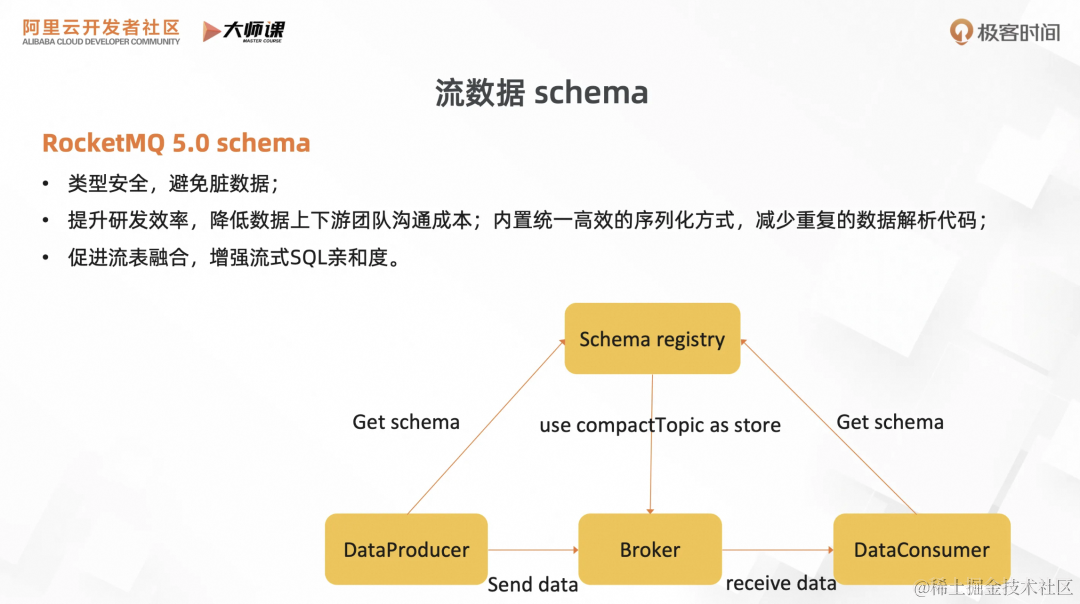
随着 RocketMQ 的数据生态的繁荣,数据集成涉及的上下游组件越来越多,提升数据治理能力也变得迫在眉睫。因此我们在 RocketMQ 5.0 引入 Schema 的概念,为消息增加结构化的描述。
它带来了几个好处:第一个是可以提高类型的安全,避免消息结构变化导致上下游数据集成不兼容,集成失败。第二个是可以提升数据集成的研发效率,上下游通过 Schema 注册中心获取消息结构,节约沟通成本,内置高效序列化机制,无需编写重复的序列化代码。同时在流表融合的大背景下面,消息 Schema 能和数据库的表结构的概念完成映射,提升流式 SQL 亲和度。
下图是就是消息 Schema 的架构。首先会有一个 Schema 注册中心的组件,维护 Schema 的数据,数据存储基于 CompactTopic。在消息收发的过程中,客户端都会先去获取 Schema 的格式,进行格式的校验,用内置的序列工具进行序列化,从而完成整个消息收发的链路。
我们再来看 Schema 的代码示例。左边是生产者、右边是消费者,代码结构和常规的方式接近。唯一的区别是,发送的对象是业务领域对象,无需自行转成 byte 数组。对于消费者也一样,消费者直接获取业务对象执行业务逻辑,减少了序列化、反序列化等繁杂的工作,提高了研发的效率。

典型案例
最后我们再来看几个 RocketMQ 流存储的例子。
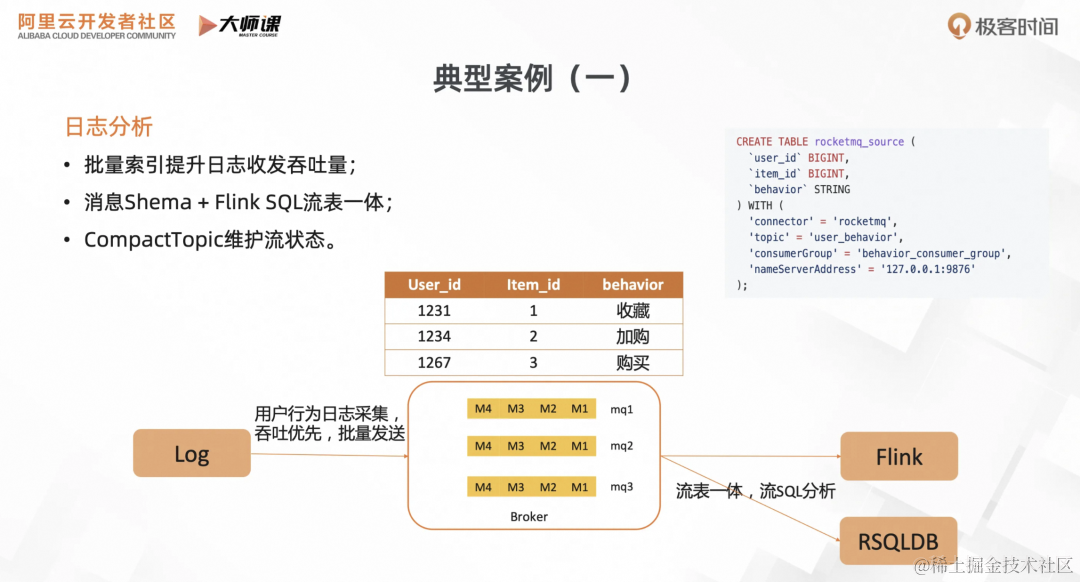
案例 1 :日志的采集和流 SQL 分析
首先,我们通过批量的索引,提升日志采集的吞吐量,降低机器成本。我们为日志消息引入 Schema,如这是用户在电商平台的行为操作,如商品进行收藏、加购、购买等操作,使得消息数据就像流动的表。在流存储下游对接 FlinkSQL 或者 RSQLDB,完成流式 SQL 分析。
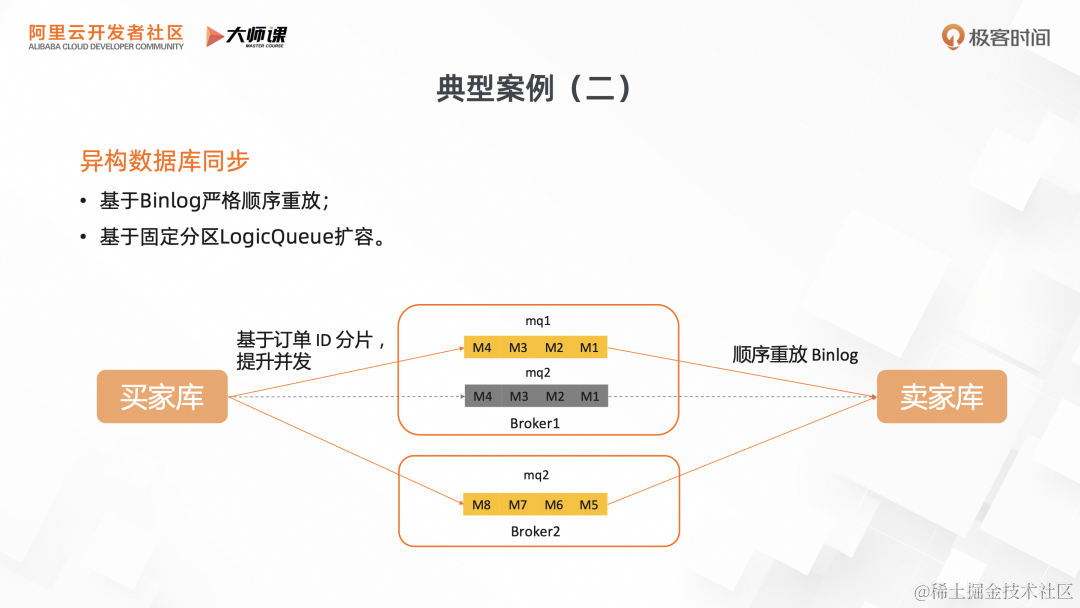
案例 2 :异构数据库的同步
如下图,我们有两个数据库,一个是按照买家 ID 的维度进行分库分表的,另外一个是按照卖家 ID 的维度进行分库分表,我们需要实时同步两个数据库的订单状态。基于 RocketMQ 的的流存储的能力,上游按照订单的 ID 去对 Binlog 进行分片,确保同一个记录的 Binlog 数据能分发到同一个队列。在消费阶段按照顺序重放队列里的 Binlog 数据,把数据同步到卖家库。当流量不足时, RocketMQ 对静态 Topic 进行扩容,分区数不变,保障了数据同步的正确性。
总结
这篇文章,我们了解了流存储用于数据集成的场景,它可以作为大数据架构的数据枢纽,连接数据的上下游组件。而 RocketMQ 的流存储的特性,既包含功能层面,提供流式的访问接口、状态存储、数据治理的能力,也包括了流的弹性、流的高吞吐能力。最后,我们也展示了两个数据集成的案例,包括日志的分析以及异构数据库的同步。
我们将持续为您带来深度剖析 RocketMQ 5.0 的系列文章,欢迎点击此处进入官网了解更多详情,也欢迎填写表单进行咨询:https://survey.aliyun.com/apps/zhiliao/bzT3AfPaq