爬虫实战-Python爬取百度当天热搜内容
- 学习建议
- 学习目标
- 预期内容
- 目标分解
- 热搜地址
- 热搜标题
- 热搜简介
- 热搜指数
- 小总结
- 代码实现
- 总结
学习建议
- 本文仅用于学习使用,不做他用;
- 本文仅获取页面的内容,作为学习和对Python知识的了解,不会对页面或原始数据造成压力;
- 请规范文明使用本文内容,请仅作为个人学习参考使用。
- 本文主要学习了Python爬虫的基础,及常用的几个模块或库的使用,比如BeautifulSoup、request等。
学习目标
- 获取百度当天的热搜内容,并打印出来;
- 内容需要包含热搜的标题、热搜简介、以及热搜的指数。
预期内容
- 输入网址打开百度首页;
- 进入首页后,点击【百度热搜】,如图:

- 进入热搜首页后,点击【热搜】,即当前页面就是我们需要的数据:
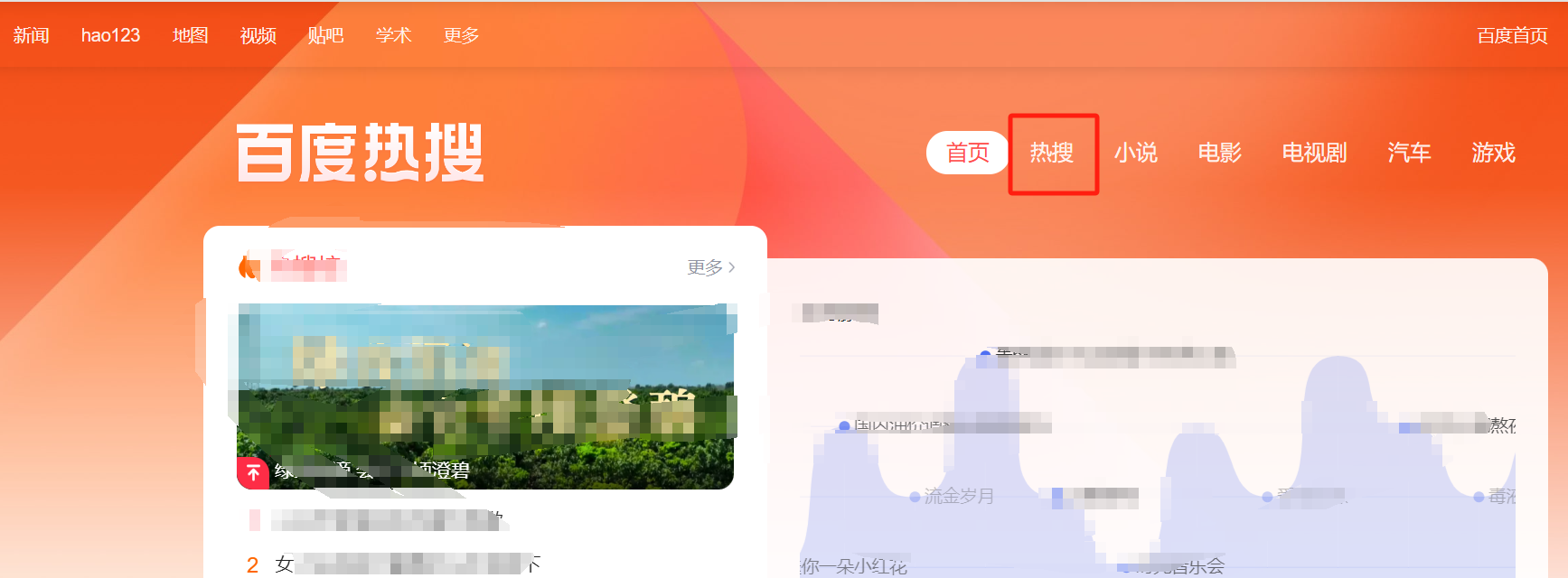
- 从下图可以看出,一条热搜的内容包含了热搜标题、该热搜的简介,以及热搜的指数,那么这三项内容就是我们最终要的内容:

目标分解
热搜地址
- 进入到热搜主界面后,我们查看当前页面的URL,后续需要用到:
https://top.baidu.com/board?tab=realtime

热搜标题
- 进入到热搜主页后,我们打开浏览器的F12调试模式;
- 然后查看这条热搜标题对应的界面的源码;

- 通过查看我们看出前两个热搜标题的源码为:
绿我涓滴 会它千顷澄碧英媒称有人目击凯特现身
- 从以上可以看出,有一个共同属性是class,剩下的就是标题内容不一样;
- 通过分析我们用正则表达式来统一识别所有的热搜标题:
(.\*?)
热搜简介
- 使用以上同样的方法,我们可以看到前两条热搜的简介如下:
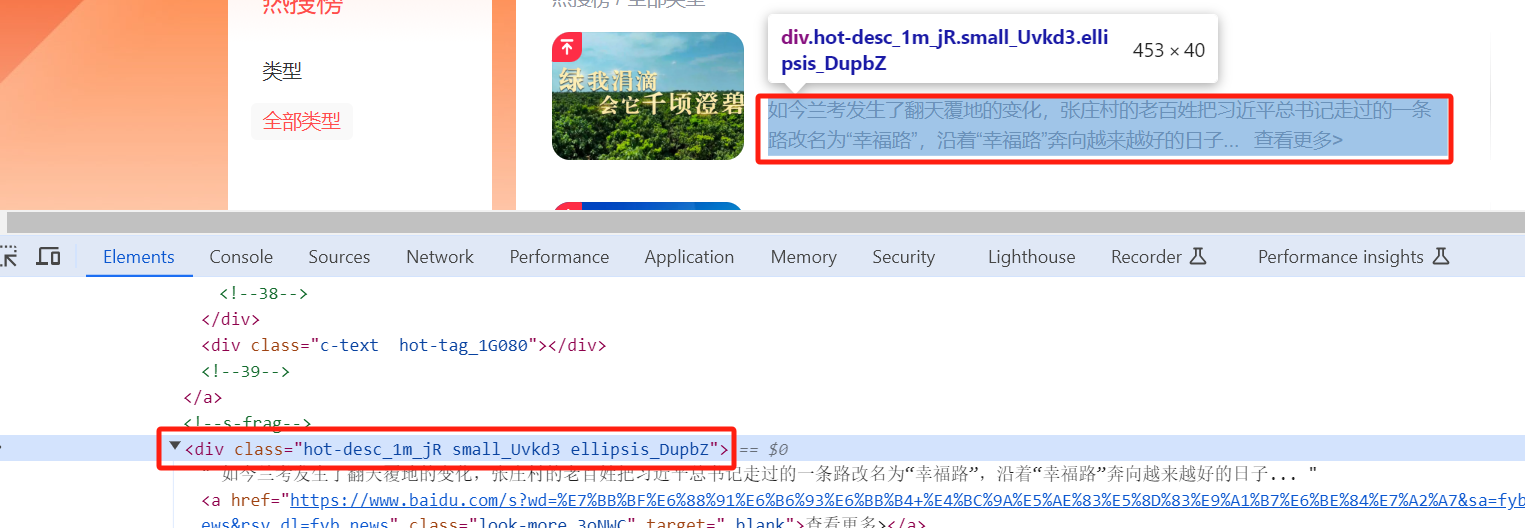
如今兰考发生了翻天覆地的变化,张庄村的老百姓把xx走过的一条路改名为“幸福路”,沿着“幸福路”奔向越来越好的日子...
- 同样可以使用正则表达式表示下:
(.\*)
热搜指数
- 使用同样方法我们获取到热搜指数的正则表达式为:
div class=“hot-index_1Bl1a”>(.*?)
小总结
- 通过以上分析,我们就得到了我们需要重点几个变量:
URL:url = https://top.baidu.com/board?tab=realtime
热搜标题: title = re.compile(r’(.*?)‘)
热搜简介:introduction = re.compile(r’(.*)<a’)
#热搜指数:index = re.compile(r’(.*?)')
代码实现
根据以上分析,我们整理下思路:
- 我们创建一个类TestHotsearch()来组织需要进行的操作;
- 在类初始化中,把URL、热搜标题、热搜简介、热搜指数四个变量初始化;
- 创建方法test_html_content()获取热搜页面的html内容;
- 创建方法test_get_content()获取需要的重点信息;
- 类实例化后调用对应的方法。
详细代码如下:
from bs4 import BeautifulSoup
import re
import urllib.request, urllib.error
class TestHotsearch():
def __init__(self):
# 热搜URL
self.url = 'https://top.baidu.com/board?tab=realtime'
# 热搜标题
self.title = re.compile(r'<div class="c-single-text-ellipsis">(.*?)</div>')
# 热搜简介
self.introduction = re.compile(r'<div class="hot-desc_1m_jR small_Uvkd3 ellipsis_DupbZ">(.*)<a')
# 热搜指数
self.index = re.compile(r'<div class="hot-index_1Bl1a">(.*?)</div>')
# 所有热搜条目
self.all_content = "category-wrap_iQLoo horizontal_1eKyQ"
def test_html_content(self):
"""
获取热搜页面的html内容
:return:
"""
header = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36"
}
request = urllib.request.Request(self.url, headers = header)
html_content = ""
try:
response = urllib.request.urlopen(request)
html_content = response.read().decode("utf-8")
except urllib.error.URLError as e:
if hasattr(e, "code"):
print(e.code)
if hasattr(e, "reason"):
print(e.reason)
return html_content.encode('gbk', 'ignore').decode('gbk')
def test_get_content(self):
"""
获取需要的重点信息
:return:
"""
# 获取html内容
html = self.test_html_content()
# 定义一个空列表保存要获取的信息
data_info = []
content = BeautifulSoup(html, "html.parser")
for name in content.find_all('div', class_=self.all_content):
data = []
name_str = str(name)
title = re.findall(self.title, name_str)
data.append(title)
introduction = re.findall(self.introduction, name_str)
data.append(introduction)
index = re.findall(self.index, name_str)
data.append(index)
data_info.append(data)
return data_info
if __name__ == "__main__":
hot_search = TestHotsearch()
get_content = hot_search.test_get_content()
print(f"获取到信息如下:{get_content}")
- 部分输出内容如下:
获取到信息如下:[[[’ 心系这门“关键课程” ‘], [], [’ 4932922 ‘]], [[’ 三只羊就梅菜扣肉事件致歉 ‘], [], [’ 4991528 ‘]], [[’ 女子山顶徒手攀爬石头手滑摔下 ‘], [], [’ 4816630 ‘]], [[’ 春分将至农事忙 ‘], [], [’ 4790902 ']],…
总结
Python主要是简单的爬虫实战,步骤清晰,容易理解和入门。建议最好用自己本地环境测试,仅供学习参考,请勿做其他用途。重点是学习Python正则表达式的应用,python的BeautifulSoup、request模块的使用等。