写这篇文章的目的是为了总结我之前看的标定,相机模型以及单目测距的内容,如果有错误,还请不吝赐教。
参考链接:
相机模型、相机标定及基于yolov5的单目测距实现
深度学习目标检测目标追踪单目测距
单目测距+代码部署(目标检测+车辆/行人等测距)
单镜头视觉系统检测车辆的测距方法
相机模型与视觉测距不完全指南
单目测距(yolo目标检测+标定+测距代码)
老规矩先上参考链接!感谢大佬们的无私奉献!!
代码链接
对代码的部分说明:
1.能跑通最新版本的yolov5就肯定能跑通我的这份代码,就是参考最新代码修改的。
2.权重和数据我就直接放仓库里了,clone下来直接跑,在inference/output里看结果。
3.觉得有用欢迎fork and star!
文章目录
- 1 前言
- 2 相机模型及单目测距原理
- 3 相机内参和外参的标定
- 4 基于yolov5的单目测距实现及关键代码
1 前言
在摄像头成像过程中,物体反射的光线通过摄像头的凸透镜打在成像器件上,形成一张图片。这是一个三维物体转换为二维图像的过程。在这个过程中,丢失了物体的深度信息,所以单目摄像头很难测距。但是,我们可以通过一个强假设,来简单计算物体的距离,即假设物体是处于地面上。具体意思下面再详细说。
2 相机模型及单目测距原理
相机模型可以简单看成一个凸透镜成像的模型。下图中,XcYcZc是相机坐标系,其原点为光心O,是相机凸透镜的中心点。x-o1-y坐标系是图像坐标系。
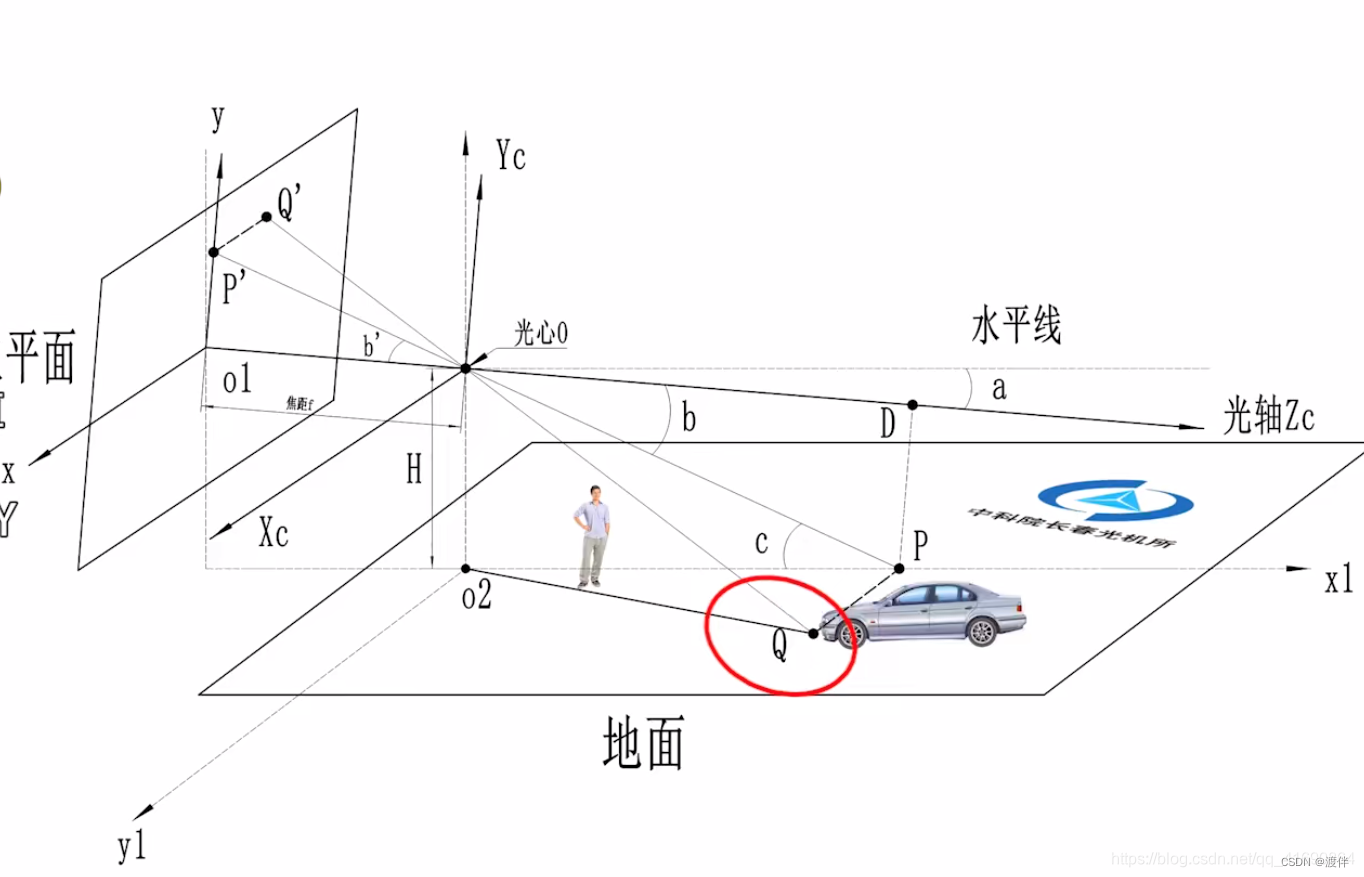
图片从b站up主(uid:109364003)的视频中截图的
图中有一个车辆,且车辆在地面上,其接地点Q必定在地面上。那么Q点的深度便可以求解出来。具体求解步骤懒得打公式了,就截图了。在单目测距过程中,实际物体上的Q点在成像的图片上对应Q’点,Q’点距离o1点沿y轴的距离为o1p’。这个距离o1p’除以y轴像素焦距fy (单位为pixel) ,再求arctan即可得到角度b’。然后按图中步骤很容易理解了。

在按图中步骤求解深度OD时,如果相机高度H、相机光轴与水平线的夹角a没有准确测量的话,会对测距精准度造成较大影响。所以用于自动驾驶时,随着车身抖动,测距精度会很低。如果路面不是水平的,而是具有曲率的,那该方法也将失效。
3 相机内参和外参的标定
这部分优秀文献特别多,等我闲的时候再来加。
4 基于yolov5的单目测距实现及关键代码
estimate_distance.py为主程序。该程序中有一个DistanceEstimation类,该类的主要成员函数有camera_parameters(), object_point_world_position(), distance(), Detect(). 在Detect函数中调用yolov5检测得到目标框后,便可以提取目标框的底边的中点作为2中所述的测距所需的Q’点。然后按照2中所述原理,便可以求得到Q点的Xw和Yw坐标。取Xw和Yw的坐标的平方和,再开根号便得到了目标的直线距离。

![[Qt学习笔记]Qt使用MFC编译生成dll库在无编程环境电脑出现无法加载dll的问题](https://img-blog.csdnimg.cn/img_convert/789387462e54e316f39d565108b99551.webp?x-oss-process=image/format,png)