第二十章:并发执行器
抨击线程的人通常是系统程序员,他们心中有着典型应用程序员终其一生都不会遇到的用例。[…] 在 99%的用例中,应用程序员可能会遇到的情况是,生成一堆独立线程并将结果收集到队列中的简单模式就是他们需要了解的一切。
米歇尔·西莫纳托,Python 深思者¹
本章重点介绍了封装“生成一堆独立线程并将结果收集到队列中”模式的concurrent.futures.Executor类,这是米歇尔·西莫纳托描述的。并发执行器使得这种模式几乎可以轻松使用,不仅适用于线程,还适用于进程——对于计算密集型任务非常有用。
在这里,我还介绍了futures的概念——代表操作异步执行的对象,类似于 JavaScript 的 promises。这个基本概念不仅是concurrent.futures的基础,也是asyncio包的基础,是第二十一章的主题。
本章亮点
我将本章从“使用 Futures 进行并发”改名为“并发执行器”,因为执行器是这里涵盖的最重要的高级特性。Futures 是低级对象,在“Futures 在哪里?”中重点介绍,但在本章的其他部分基本上是不可见的。
所有 HTTP 客户端示例现在都使用新的HTTPX库,提供同步和异步 API。
在“带有进度显示和错误处理的下载”实验的设置现在更简单了,这要归功于 Python 3.7 中添加到http.server包中的多线程服务器。以前,标准库只有单线程的BaseHttpServer,不适合用于并发客户端的实验,因此我不得不在本书第一版中使用外部工具。
“使用 concurrent.futures 启动进程”现在演示了执行器如何简化我们在“多核素数检查器的代码”中看到的代码。
最后,我将大部分理论内容移至新的第十九章,“Python 中的并发模型”。
并发网络下载
并发对于高效的网络 I/O 至关重要:应用程序不应该闲置等待远程机器,而应该在收到响应之前做其他事情。²
为了用代码演示,我编写了三个简单的程序来从网络上下载 20 个国家的国旗图片。第一个flags.py按顺序运行:只有在上一个图片下载并保存在本地后才请求下一个图片。另外两个脚本进行并发下载:它们几乎同时请求多个图片,并在图片到达时保存。flags_threadpool.py脚本使用concurrent.futures包,而flags_asyncio.py使用asyncio。
示例 20-1 展示了运行三个脚本三次的结果。我还在 YouTube 上发布了一个73 秒的视频,这样你就可以看到它们运行时 macOS Finder 窗口显示保存的标志。这些脚本正在从fluentpython.com下载图片,该网站位于 CDN 后面,因此在第一次运行时可能会看到较慢的结果。示例 20-1 中的结果是在多次运行后获得的,因此 CDN 缓存已经热了。
示例 20-1 三个脚本 flags.py、flags_threadpool.py 和 flags_asyncio.py 的典型运行结果
$ python3 flags.py
BD BR CD CN DE EG ET FR ID IN IR JP MX NG PH PK RU TR US VN # ① 20 flags downloaded in 7.26s # ② $ python3 flags.py
BD BR CD CN DE EG ET FR ID IN IR JP MX NG PH PK RU TR US VN
20 flags downloaded in 7.20s
$ python3 flags.py
BD BR CD CN DE EG ET FR ID IN IR JP MX NG PH PK RU TR US VN
20 flags downloaded in 7.09s
$ python3 flags_threadpool.py
DE BD CN JP ID EG NG BR RU CD IR MX US PH FR PK VN IN ET TR
20 flags downloaded in 1.37s # ③ $ python3 flags_threadpool.py
EG BR FR IN BD JP DE RU PK PH CD MX ID US NG TR CN VN ET IR
20 flags downloaded in 1.60s
$ python3 flags_threadpool.py
BD DE EG CN ID RU IN VN ET MX FR CD NG US JP TR PK BR IR PH
20 flags downloaded in 1.22s
$ python3 flags_asyncio.py # ④ BD BR IN ID TR DE CN US IR PK PH FR RU NG VN ET MX EG JP CD
20 flags downloaded in 1.36s
$ python3 flags_asyncio.py
RU CN BR IN FR BD TR EG VN IR PH CD ET ID NG DE JP PK MX US
20 flags downloaded in 1.27s
$ python3 flags_asyncio.py
RU IN ID DE BR VN PK MX US IR ET EG NG BD FR CN JP PH CD TR # ⑤ 20 flags downloaded in 1.42s
①
每次运行的输出以下载的国旗国家代码开头,并以显示经过的时间的消息结束。
②
flags.py下载 20 张图像平均用时 7.18 秒。
③
flags_threadpool.py的平均时间为 1.40 秒。
④
对于flags_asyncio.py,平均时间为 1.35 秒。
⑤
注意国家代码的顺序:使用并发脚本下载时,每次下载的顺序都不同。
并发脚本之间的性能差异不大,但它们都比顺序脚本快五倍以上——这仅针对下载几千字节的 20 个文件的小任务。如果将任务扩展到数百个下载,那么并发脚本可以比顺序代码快 20 倍或更多。
警告
在针对公共网络服务器测试并发 HTTP 客户端时,您可能会无意中发动拒绝服务(DoS)攻击,或被怀疑这样做。在示例 20-1 的情况下,这样做是可以的,因为这些脚本是硬编码为仅发出 20 个请求。我们将在本章后面使用 Python 的http.server包来运行测试。
现在让我们研究示例 20-1 中测试的两个脚本的实现:flags.py和flags_threadpool.py。第三个脚本flags_asyncio.py将在第二十一章中介绍,但我想一起展示这三个脚本以阐明两点:
-
无论您使用哪种并发构造——线程还是协程——如果正确编码,您将看到网络 I/O 操作的吞吐量大大提高。
-
对于可以控制发出多少请求的 HTTP 客户端,线程和协程之间的性能差异不大。³
进入代码部分。
一个顺序下载脚本
示例 20-2 包含flags.py的实现,这是我们在示例 20-1 中运行的第一个脚本。它并不是很有趣,但我们将重用大部分代码和设置来实现并发脚本,因此它值得一提。
注意
为了清晰起见,在示例 20-2 中没有错误处理。我们稍后会处理异常,但这里我想专注于代码的基本结构,以便更容易将此脚本与并发脚本进行对比。
示例 20-2. flags.py:顺序下载脚本;一些函数将被其他脚本重用
import time
from pathlib import Path
from typing import Callable
import httpx # ①
POP20_CC = ('CN IN US ID BR PK NG BD RU JP '
'MX PH VN ET EG DE IR TR CD FR').split() # ②
BASE_URL = 'https://www.fluentpython.com/data/flags' # ③
DEST_DIR = Path('downloaded') # ④
def save_flag(img: bytes, filename: str) -> None: # ⑤
(DEST_DIR / filename).write_bytes(img)
def get_flag(cc: str) -> bytes: # ⑥
url = f'{BASE_URL}/{cc}/{cc}.gif'.lower()
resp = httpx.get(url, timeout=6.1, # ⑦
follow_redirects=True) # ⑧
resp.raise_for_status() # ⑨
return resp.content
def download_many(cc_list: list[str]) -> int: # ⑩
for cc in sorted(cc_list): ⑪
image = get_flag(cc)
save_flag(image, f'{cc}.gif')
print(cc, end=' ', flush=True) ⑫
return len(cc_list)
def main(downloader: Callable[[list[str]], int]) -> None: ⑬
DEST_DIR.mkdir(exist_ok=True) ⑭
t0 = time.perf_counter() ⑮
count = downloader(POP20_CC)
elapsed = time.perf_counter() - t0
print(f'\n{count} downloads in {elapsed:.2f}s')
if __name__ == '__main__':
main(download_many) ⑯
①
导入httpx库。它不是标准库的一部分,因此按照惯例,导入应放在标准库模块之后并空一行。
②
ISO 3166 国家代码列表,按人口递减顺序列出前 20 个人口最多的国家。
③
存放国旗图像的目录。⁴
④
图像保存的本地目录。
⑤
将img字节保存到DEST_DIR中的filename。
⑥
给定一个国家代码,构建 URL 并下载图像,返回响应的二进制内容。
⑦
为网络操作添加合理的超时是个好习惯,以避免无故阻塞几分钟。
⑧
默认情况下,HTTPX不会遵循重定向。⁵
⑨
这个脚本中没有错误处理,但是如果 HTTP 状态不在 2XX 范围内,此方法会引发异常——强烈建议避免静默失败。
⑩
download_many是用于比较并发实现的关键函数。
⑪
按字母顺序循环遍历国家代码列表,以便轻松查看输出中保留了顺序;返回下载的国家代码数量。
⑫
逐个显示一个国家代码,以便我们可以看到每次下载发生时的进度。end=' '参数用空格字符替换了通常在每行末尾打印的换行符,因此所有国家代码都逐步显示在同一行中。需要flush=True参数,因为默认情况下,Python 输出是行缓冲的,这意味着 Python 仅在换行后显示打印的字符。
⑬
必须使用将进行下载的函数调用main;这样,我们可以在threadpool和ascyncio示例中的其他download_many实现中将main用作库函数。
⑭
如果需要,创建DEST_DIR;如果目录已存在,则不会引发错误。
⑮
运行downloader函数后记录并报告经过的时间。
⑯
使用download_many函数调用main。
提示
HTTPX库受到 Pythonic requests包的启发,但建立在更现代的基础上。关键是,HTTPX提供同步和异步 API,因此我们可以在本章和下一章的所有 HTTP 客户端示例中使用它。Python 的标准库提供了urllib.request模块,但其 API 仅支持同步,并且不够用户友好。
flags.py 实际上没有什么新内容。它作为比较其他脚本的基准,并且我在实现它们时将其用作库,以避免冗余代码。现在让我们看看使用concurrent.futures重新实现的情况。
使用 concurrent.futures 进行下载
concurrent.futures包的主要特点是ThreadPoolExecutor和ProcessPoolExecutor类,它们实现了一个 API,用于在不同线程或进程中提交可调用对象进行执行。这些类透明地管理一组工作线程或进程以及队列来分发作业和收集结果。但接口非常高级,对于像我们的标志下载这样的简单用例,我们不需要了解任何这些细节。
示例 20-3 展示了实现并发下载的最简单方法,使用ThreadPoolExecutor.map方法。
示例 20-3. flags_threadpool.py:使用futures.ThreadPoolExecutor的线程下载脚本
from concurrent import futures
from flags import save_flag, get_flag, main # ①
def download_one(cc: str): # ②
image = get_flag(cc)
save_flag(image, f'{cc}.gif')
print(cc, end=' ', flush=True)
return cc
def download_many(cc_list: list[str]) -> int:
with futures.ThreadPoolExecutor() as executor: # ③
res = executor.map(download_one, sorted(cc_list)) # ④
return len(list(res)) # ⑤
if __name__ == '__main__':
main(download_many) # ⑥
①
从flags模块中重用一些函数(示例 20-2)。
②
用于下载单个图像的函数;这是每个工作线程将执行的内容。
③
将ThreadPoolExecutor实例化为上下文管理器;executor.__exit__方法将调用executor.shutdown(wait=True),这将阻塞直到所有线程完成。
④
map方法类似于内置的map,不同之处在于download_one函数将并发地从多个线程调用;它返回一个生成器,您可以迭代以检索每个函数调用返回的值—在本例中,每次调用download_one都将返回一个国家代码。
⑤
返回获得的结果数量。如果任何线程调用引发异常,当 list 构造函数内部的隐式 next() 调用尝试从 executor.map 返回的迭代器中检索相应的返回值时,异常会在此处引发。
⑥
从 flags 模块调用 main 函数,传递并发版本的 download_many。
请注意,来自 示例 20-3 的 download_one 函数本质上是来自 示例 20-2 中的 download_many 函数中 for 循环的主体。这是在编写并发代码时常见的重构:将顺序 for 循环的主体转换为一个要并发调用的函数。
提示
示例 20-3 非常简短,因为我能够重用顺序执行的 flags.py 脚本中的大部分函数。concurrent.futures 最好的特性之一是使得在传统的顺序代码之上添加并发执行变得简单。
ThreadPoolExecutor 构造函数接受几个未显示的参数,但第一个且最重要的是 max_workers,设置要执行的工作线程的最大数量。当 max_workers 为 None(默认值)时,ThreadPoolExecutor 使用以下表达式决定其值—自 Python 3.8 起:
max_workers = min(32, os.cpu_count() + 4)
这个理念在 ThreadPoolExecutor 文档 中有解释:
这个默认值至少保留了 5 个工作线程用于 I/O 绑定任务。对于释放 GIL 的 CPU 绑定任务,它最多利用 32 个 CPU 核心。它避免在多核机器上隐式使用非常大的资源。
ThreadPoolExecutor现在在启动max_workers工作线程之前重用空闲的工作线程。
总之:max_workers 的默认计算是合理的,ThreadPoolExecutor 避免不必要地启动新的工作线程。理解 max_workers 背后的逻辑可能会帮助您决定何时以及如何自行设置它。
这个库被称为 concurrency.futures,但在 示例 20-3 中看不到 futures,所以你可能会想知道它们在哪里。接下来的部分会解释。
未来在哪里?
Futures 是 concurrent.futures 和 asyncio 的核心组件,但作为这些库的用户,我们有时看不到它们。示例 20-3 在幕后依赖于 futures,但我编写的代码并没有直接涉及它们。本节是 futures 的概述,其中包含一个展示它们运作的示例。
自 Python 3.4 起,标准库中有两个名为 Future 的类:concurrent.futures.Future 和 asyncio.Future。它们的作用相同:Future 类的实例代表一个延迟计算,可能已经完成,也可能尚未完成。这在某种程度上类似于 Twisted 中的 Deferred 类、Tornado 中的 Future 类以及现代 JavaScript 中的 Promise。
Futures 封装了待处理的操作,以便我们可以将它们放入队列,检查它们是否完成,并在结果(或异常)可用时检索结果。
关于 futures 的一个重要事项是,你和我不应该创建它们:它们应该由并发框架专门实例化,无论是 concurrent.futures 还是 asyncio。原因在于:Future 代表着最终会运行的东西,因此必须安排其运行,这是框架的工作。特别是,concurrent.futures.Future 实例仅在使用 concurrent.futures.Executor 子类提交可调用对象以执行时才会创建。例如,Executor.submit() 方法接受一个可调用对象,安排其运行,并返回一个 Future。
应用代码不应该改变 future 的状态:当它所代表的计算完成时,并发框架会改变 future 的状态,我们无法控制何时发生这种情况。
两种类型的Future都有一个非阻塞的.done()方法,返回一个布尔值,告诉你被该future包装的可调用是否已执行。然而,客户端代码通常不会反复询问future是否完成,而是要求通知。这就是为什么两种Future类都有一个.add_done_callback()方法:你给它一个可调用对象,当future完成时,该可调用对象将以future作为唯一参数被调用。请注意,回调可调用对象将在运行包装在future中的函数的工作线程或进程中运行。
还有一个.result()方法,在future完成时两种类中的工作方式相同:它返回可调用对象的结果,或者在执行可调用对象时抛出的任何异常。然而,当future未完成时,result方法在两种Future的行为上有很大不同。在concurrency.futures.Future实例中,调用f.result()将阻塞调用者的线程,直到结果准备就绪。可以传递一个可选的timeout参数,如果在指定时间内future未完成,result方法将引发TimeoutError。asyncio.Future.result方法不支持超时,await是在asyncio中获取future结果的首选方式,但await不能与concurrency.futures.Future实例一起使用。
两个库中的几个函数返回future;其他函数在其实现中使用future的方式对用户来说是透明的。后者的一个例子是我们在示例 20-3 中看到的Executor.map:它返回一个迭代器,其中__next__调用每个future的result方法,因此我们得到future的结果,而不是future本身。
为了实际查看future,我们可以重写示例 20-3 以使用concurrent.futures.as_completed函数,该函数接受一个future的可迭代对象,并返回一个迭代器,按照完成的顺序产生future。
使用futures.as_completed仅需要更改download_many函数。高级executor.map调用被两个for循环替换:一个用于创建和调度future,另一个用于检索它们的结果。在此过程中,我们将添加一些print调用来显示每个future在完成前后的状态。示例 20-4 展示了新download_many函数的代码。download_many函数的代码从 5 行增长到 17 行,但现在我们可以检查神秘的future。其余函数与示例 20-3 中的相同。
示例 20-4. flags_threadpool_futures.py: 在download_many函数中用executor.submit和futures.as_completed替换executor.map。
def download_many(cc_list: list[str]) -> int:
cc_list = cc_list[:5] # ①
with futures.ThreadPoolExecutor(max_workers=3) as executor: # ②
to_do: list[futures.Future] = []
for cc in sorted(cc_list): # ③
future = executor.submit(download_one, cc) # ④
to_do.append(future) # ⑤
print(f'Scheduled for {cc}: {future}') # ⑥
for count, future in enumerate(futures.as_completed(to_do), 1): # ⑦
res: str = future.result() # ⑧
print(f'{future} result: {res!r}') # ⑨
return count
①
为了演示,只使用人口最多的前五个国家。
②
将max_workers设置为3,这样我们可以在输出中看到待处理的future。
③
按字母顺序遍历国家代码,以明确结果将无序到达。
④
executor.submit调度可调用对象的执行,并返回代表此挂起操作的future。
⑤
存储每个future,以便稍后使用as_completed检索它们。
⑥
显示带有国家代码和相应future的消息。
⑦
as_completed在future完成时产生future。
⑧
获取这个future的结果。
⑨
显示future及其结果。
注意,在这个例子中,future.result() 调用永远不会阻塞,因为 future 是从 as_completed 中出来的。示例 20-5 展示了示例 20-4 的一次运行的输出。
示例 20-5. flags_threadpool_futures.py 的输出
$ python3 flags_threadpool_futures.py
Scheduled for BR: <Future at 0x100791518 state=running> # ① Scheduled for CN: <Future at 0x100791710 state=running>
Scheduled for ID: <Future at 0x100791a90 state=running>
Scheduled for IN: <Future at 0x101807080 state=pending> # ② Scheduled for US: <Future at 0x101807128 state=pending>
CN <Future at 0x100791710 state=finished returned str> result: 'CN' # ③ BR ID <Future at 0x100791518 state=finished returned str> result: 'BR' # ④ <Future at 0x100791a90 state=finished returned str> result: 'ID'
IN <Future at 0x101807080 state=finished returned str> result: 'IN'
US <Future at 0x101807128 state=finished returned str> result: 'US'
5 downloads in 0.70s
①
未来按字母顺序安排;未来的 repr() 显示其状态:前三个是 running,因为有三个工作线程。
②
最后两个未来是 pending,等待工作线程。
③
这里的第一个 CN 是在工作线程中的 download_one 的输出;其余行是 download_many 的输出。
④
在主线程的 download_many 显示结果之前,两个线程在输出代码。
提示
我建议尝试 flags_threadpool_futures.py。如果你多次运行它,你会看到结果的顺序变化。将 max_workers 增加到 5 将增加结果顺序的变化。将其减少到 1 将使此脚本按顺序运行,结果的顺序将始终是 submit 调用的顺序。
我们看到了两个使用 concurrent.futures 的下载脚本变体:一个在示例 20-3 中使用 ThreadPoolExecutor.map,另一个在示例 20-4 中使用 futures.as_completed。如果你对 flags_asyncio.py 的代码感兴趣,可以查看第二十一章中的示例 21-3 进行了解。
现在让我们简要看一下使用 concurrent.futures 绕过 GIL 处理 CPU 密集型任务的简单方法。
使用 concurrent.futures 启动进程
concurrent.futures 文档页面 的副标题是“启动并行任务”。该软件包支持在多核计算机上进行并行计算,因为它支持使用 ProcessPoolExecutor 类在多个 Python 进程之间分发工作。
ProcessPoolExecutor 和 ThreadPoolExecutor 都实现了Executor 接口,因此使用 concurrent.futures 从基于线程的解决方案切换到基于进程的解决方案很容易。
对于下载标志示例或任何 I/O 密集型任务,使用 ProcessPoolExecutor 没有优势。很容易验证这一点;只需更改示例 20-3 中的这些行:
def download_many(cc_list: list[str]) -> int:
with futures.ThreadPoolExecutor() as executor:
到这里:
def download_many(cc_list: list[str]) -> int:
with futures.ProcessPoolExecutor() as executor:
ProcessPoolExecutor 的构造函数也有一个 max_workers 参数,默认为 None。在这种情况下,执行器将工作进程的数量限制为 os.cpu_count() 返回的数量。
进程使用更多内存,启动时间比线程长,所以 ProcessPoolExecutor 的真正价值在于 CPU 密集型任务。让我们回到“自制进程池”中的素数检查示例,使用 concurrent.futures 重新编写它。
多核素数检查器 Redux
在“多核素数检查器的代码”中,我们研究了 procs.py,一个使用 multiprocessing 检查一些大数的素数性质的脚本。在示例 20-6 中,我们使用 ProcessPoolExecutor 在 proc_pool.py 程序中解决了相同的问题。从第一个导入到最后的 main() 调用,procs.py 有 43 行非空代码,而 proc_pool.py 只有 31 行,比原来的短了 28%。
示例 20-6. proc_pool.py: procs.py 使用 ProcessPoolExecutor 重写
import sys
from concurrent import futures # ①
from time import perf_counter
from typing import NamedTuple
from primes import is_prime, NUMBERS
class PrimeResult(NamedTuple): # ②
n: int
flag: bool
elapsed: float
def check(n: int) -> PrimeResult:
t0 = perf_counter()
res = is_prime(n)
return PrimeResult(n, res, perf_counter() - t0)
def main() -> None:
if len(sys.argv) < 2:
workers = None # ③
else:
workers = int(sys.argv[1])
executor = futures.ProcessPoolExecutor(workers) # ④
actual_workers = executor._max_workers # type: ignore # ⑤
print(f'Checking {len(NUMBERS)} numbers with {actual_workers} processes:')
t0 = perf_counter()
numbers = sorted(NUMBERS, reverse=True) # ⑥
with executor: # ⑦
for n, prime, elapsed in executor.map(check, numbers): # ⑧
label = 'P' if prime else ' '
print(f'{n:16} {label} {elapsed:9.6f}s')
time = perf_counter() - t0
print(f'Total time: {time:.2f}s')
if __name__ == '__main__':
main()
①
不需要导入 multiprocessing、SimpleQueue 等;concurrent.futures 隐藏了所有这些。
②
PrimeResult元组和check函数与procs.py中看到的相同,但我们不再需要队列和worker函数。
③
如果没有给出命令行参数,我们不再决定使用多少工作进程,而是将workers设置为None,让ProcessPoolExecutor自行决定。
④
在➐中我在with块之前构建了ProcessPoolExecutor,这样我就可以在下一行显示实际的工作进程数。
⑤
_max_workers是ProcessPoolExecutor的一个未记录的实例属性。我决定使用它来显示workers变量为None时的工作进程数。Mypy在我访问它时正确地抱怨,所以我放了type: ignore注释来消除警告。
⑥
将要检查的数字按降序排序。这将揭示proc_pool.py与procs.py在行为上的差异。请参见本示例后的解释。
⑦
使用executor作为上下文管理器。
⑧
executor.map调用返回由check返回的PrimeResult实例,顺序与numbers参数相同。
如果你运行示例 20-6,你会看到结果严格按降序出现,就像示例 20-7 中所示。相比之下,procs.py的输出顺序(在“基于进程的解决方案”中显示)受到检查每个数字是否为质数的难度的影响。例如,procs.py在顶部显示了 7777777777777777 的结果,因为它有一个较低的除数 7,所以is_prime很快确定它不是质数。
相比之下,7777777536340681 是 88191709²,因此is_prime将花费更长的时间来确定它是一个合数,甚至更长的时间来找出 7777777777777753 是质数—因此这两个数字都出现在procs.py输出的末尾。
运行proc_pool.py,你会观察到结果严格按降序排列,但在显示 9999999999999999 的结果后,程序似乎会卡住。
示例 20-7. proc_pool.py 的输出
$ ./proc_pool.py
Checking 20 numbers with 12 processes:
9999999999999999 0.000024s # ① 9999999999999917 P 9.500677s # ② 7777777777777777 0.000022s # ③ 7777777777777753 P 8.976933s
7777777536340681 8.896149s
6666667141414921 8.537621s
6666666666666719 P 8.548641s
6666666666666666 0.000002s
5555555555555555 0.000017s
5555555555555503 P 8.214086s
5555553133149889 8.067247s
4444444488888889 7.546234s
4444444444444444 0.000002s
4444444444444423 P 7.622370s
3333335652092209 6.724649s
3333333333333333 0.000018s
3333333333333301 P 6.655039s
299593572317531 P 2.072723s
142702110479723 P 1.461840s
2 P 0.000001s
Total time: 9.65s
①
这行出现得非常快。
②
这行需要超过 9.5 秒才能显示出来。
③
所有剩下的行几乎立即出现。
这就是proc_pool.py表现出这种方式的原因:
-
如前所述,
executor.map(check, numbers)返回的结果与给定的numbers顺序相同。 -
默认情况下,proc_pool.py使用与 CPU 数量相同的工作进程数——当
max_workers为None时,这就是ProcessPoolExecutor的做法。在这台笔记本电脑上是 12 个进程。 -
因为我们按降序提交
numbers,第一个是 9999999999999999;以 9 为除数,它会迅速返回。 -
第二个数字是 9999999999999917,样本中最大的质数。这将比所有其他数字检查花费更长的时间。
-
与此同时,其余的 11 个进程将检查其他数字,这些数字要么是质数,要么是具有大因子的合数,要么是具有非常小因子的合数。
-
当负责 9999999999999917 的工作进程最终确定那是一个质数时,所有其他进程已经完成了最后的工作,因此结果会立即显示出来。
注意
尽管proc_pool.py的进度不像procs.py那样明显,但对于相同数量的工作进程和 CPU 核心,总体执行时间几乎与图 19-2 中描述的相同。
理解并发程序的行为并不直接,因此这里有第二个实验,可以帮助你可视化Executor.map的操作。
试验Executor.map
让我们来研究Executor.map,现在使用一个具有三个工作线程的ThreadPoolExecutor运行五个可调用函数,输出带时间戳的消息。代码在示例 20-8 中,输出在示例 20-9 中。
示例 20-8。demo_executor_map.py:ThreadPoolExecutor的map方法的简单演示。
from time import sleep, strftime
from concurrent import futures
def display(*args): # ①
print(strftime('[%H:%M:%S]'), end=' ')
print(*args)
def loiter(n): # ②
msg = '{}loiter({}): doing nothing for {}s...'
display(msg.format('\t'*n, n, n))
sleep(n)
msg = '{}loiter({}): done.'
display(msg.format('\t'*n, n))
return n * 10 # ③
def main():
display('Script starting.')
executor = futures.ThreadPoolExecutor(max_workers=3) # ④
results = executor.map(loiter, range(5)) # ⑤
display('results:', results) # ⑥
display('Waiting for individual results:')
for i, result in enumerate(results): # ⑦
display(f'result {i}: {result}')
if __name__ == '__main__':
main()
①
这个函数简单地打印出它收到的任何参数,前面加上格式为[HH:MM:SS]的时间戳。
②
loiter除了在开始时显示消息、休眠n秒,然后在结束时显示消息外什么也不做;制表符用于根据n的值缩进消息。
③
loiter返回n * 10,因此我们可以看到如何收集结果。
④
创建一个具有三个线程的ThreadPoolExecutor。
⑤
向executor提交五个任务。由于只有三个线程,因此只有其中三个任务会立即启动:调用loiter(0)、loiter(1)和loiter(2);这是一个非阻塞调用。
⑥
立即显示调用executor.map的results:它是一个生成器,正如示例 20-9 中的输出所示。
⑦
for循环中的enumerate调用将隐式调用next(results),这将进而在(内部的)代表第一个调用loiter(0)的_f future 上调用_f.result()。result方法将阻塞直到 future 完成,因此此循环中的每次迭代都必须等待下一个结果准备就绪。
鼓励你运行示例 20-8,看到显示逐步更新。在此过程中,尝试调整ThreadPoolExecutor的max_workers参数以及产生executor.map调用参数的range函数,或者用手动选择的值列表替换它以创建不同的延迟。
示例 20-9 展示了示例 20-8 的一个运行示例。
示例 20-9。来自示例 20-8 的 demo_executor_map.py 的示例运行。
$ python3 demo_executor_map.py
[15:56:50] Script starting. # ① [15:56:50] loiter(0): doing nothing for 0s... # ② [15:56:50] loiter(0): done.
[15:56:50] loiter(1): doing nothing for 1s... # ③ [15:56:50] loiter(2): doing nothing for 2s...
[15:56:50] results: <generator object result_iterator at 0x106517168> # ④ [15:56:50] loiter(3): doing nothing for 3s... # ⑤ [15:56:50] Waiting for individual results:
[15:56:50] result 0: 0 # ⑥ [15:56:51] loiter(1): done. # ⑦ [15:56:51] loiter(4): doing nothing for 4s...
[15:56:51] result 1: 10 # ⑧ [15:56:52] loiter(2): done. # ⑨ [15:56:52] result 2: 20
[15:56:53] loiter(3): done.
[15:56:53] result 3: 30
[15:56:55] loiter(4): done. # ⑩ [15:56:55] result 4: 40
①
此运行开始于 15:56:50。
②
第一个线程执行loiter(0),因此它将休眠 0 秒并在第二个线程有机会启动之前返回,但结果可能有所不同。⁶
③
loiter(1)和loiter(2)立即启动(因为线程池有三个工作线程,可以同时运行三个函数)。
④
这表明executor.map返回的results是一个生成器;到目前为止,无论任务数量和max_workers设置如何,都不会阻塞。
⑤
因为loiter(0)已经完成,第一个工作线程现在可以开始第四个线程执行loiter(3)。
⑥
这是执行可能会阻塞的地方,取决于给loiter调用的参数:results生成器的__next__方法必须等待第一个 future 完成。在这种情况下,它不会阻塞,因为对loiter(0)的调用在此循环开始之前已经完成。请注意,到目前为止,所有操作都发生在同一秒内:15:56:50。
⑦
一秒钟后,loiter(1)完成,在 15:56:51。线程被释放以启动loiter(4)。
⑧
loiter(1)的结果显示为:10。现在for循环将阻塞等待loiter(2)的结果。
⑨
模式重复:loiter(2)完成,显示其结果;loiter(3)也是如此。
⑩
直到loiter(4)完成前有 2 秒的延迟,因为它在 15:56:51 开始,并且 4 秒内什么也没做。
Executor.map函数易于使用,但通常最好在准备就绪时获取结果,而不考虑提交的顺序。为此,我们需要Executor.submit方法和futures.as_completed函数的组合,正如我们在 Example 20-4 中看到的那样。我们将在“使用 futures.as_completed”中回到这种技术。
提示
executor.submit和futures.as_completed的组合比executor.map更灵活,因为您可以submit不同的可调用函数和参数,而executor.map设计为在不同的参数上运行相同的可调用函数。此外,您传递给futures.as_completed的 future 集合可能来自多个执行器——也许一些是由ThreadPoolExecutor实例创建的,而其他一些来自ProcessPoolExecutor。
在下一节中,我们将使用新要求恢复标志下载示例,这将迫使我们迭代futures.as_completed的结果,而不是使用executor.map。
带有进度显示和错误处理的下载
如前所述,“并发 Web 下载”中的脚本没有错误处理,以使其更易于阅读,并对比三种方法的结构:顺序,线程和异步。
为了测试处理各种错误条件,我创建了flags2示例:
flags2_common.py
该模块包含所有flags2示例中使用的常见函数和设置,包括一个main函数,负责命令行解析,计时和报告结果。这实际上是支持代码,与本章主题无直接关系,因此我不会在这里列出源代码,但您可以在fluentpython/example-code-2e存储库中阅读:20-executors/getflags/flags2_common.py。
flags2_sequential.py
具有适当错误处理和进度条显示的顺序 HTTP 客户端。其download_one函数也被flags2_threadpool.py使用。
flags2_threadpool.py
基于futures.ThreadPoolExecutor的并发 HTTP 客户端,用于演示错误处理和进度条的集成。
flags2_asyncio.py
与上一个示例具有相同功能,但使用asyncio和httpx实现。这将在“增强 asyncio 下载器”中介绍,在第二十一章中。
在测试并发客户端时要小心
在公共 Web 服务器上测试并发 HTTP 客户端时,您可能每秒生成许多请求,这就是拒绝服务(DoS)攻击的方式。在命中公共服务器时,请谨慎限制您的客户端。对于测试,请设置本地 HTTP 服务器。有关说明,请参阅“设置测试服务器”。
flags2示例最显著的特点是它们具有一个使用tqdm包实现的动画文本模式进度条。我在 YouTube 上发布了一个108 秒的视频来展示进度条,并对比三个flags2脚本的速度。在视频中,我从顺序下载开始,但在 32 秒后中断了,因为要花费超过 5 分钟才能访问 676 个 URL 并获取 194 个标志。然后我分别运行了线程和asyncio脚本三次,每次都在 6 秒内完成任务(即,速度超过 60 倍)。图 20-1 显示了两个屏幕截图:运行flags2_threadpool.py时和脚本完成后。
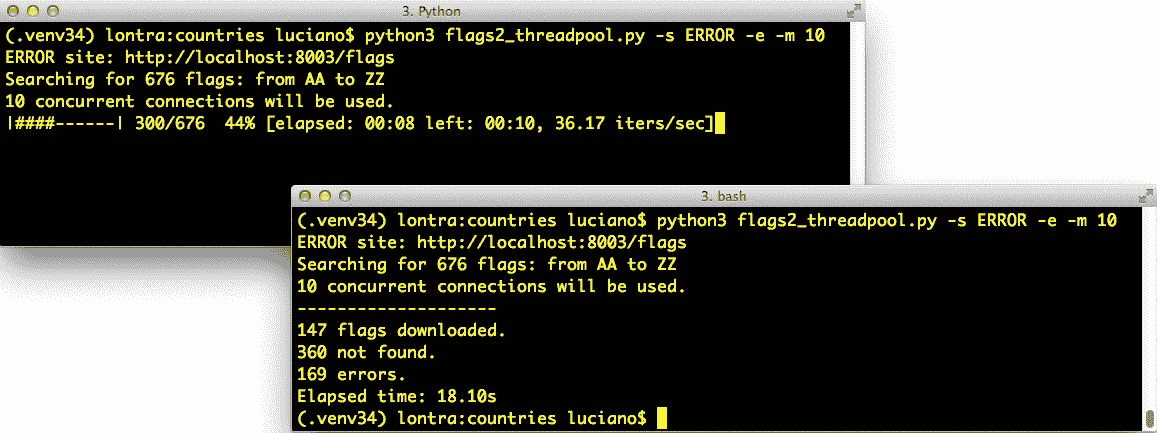
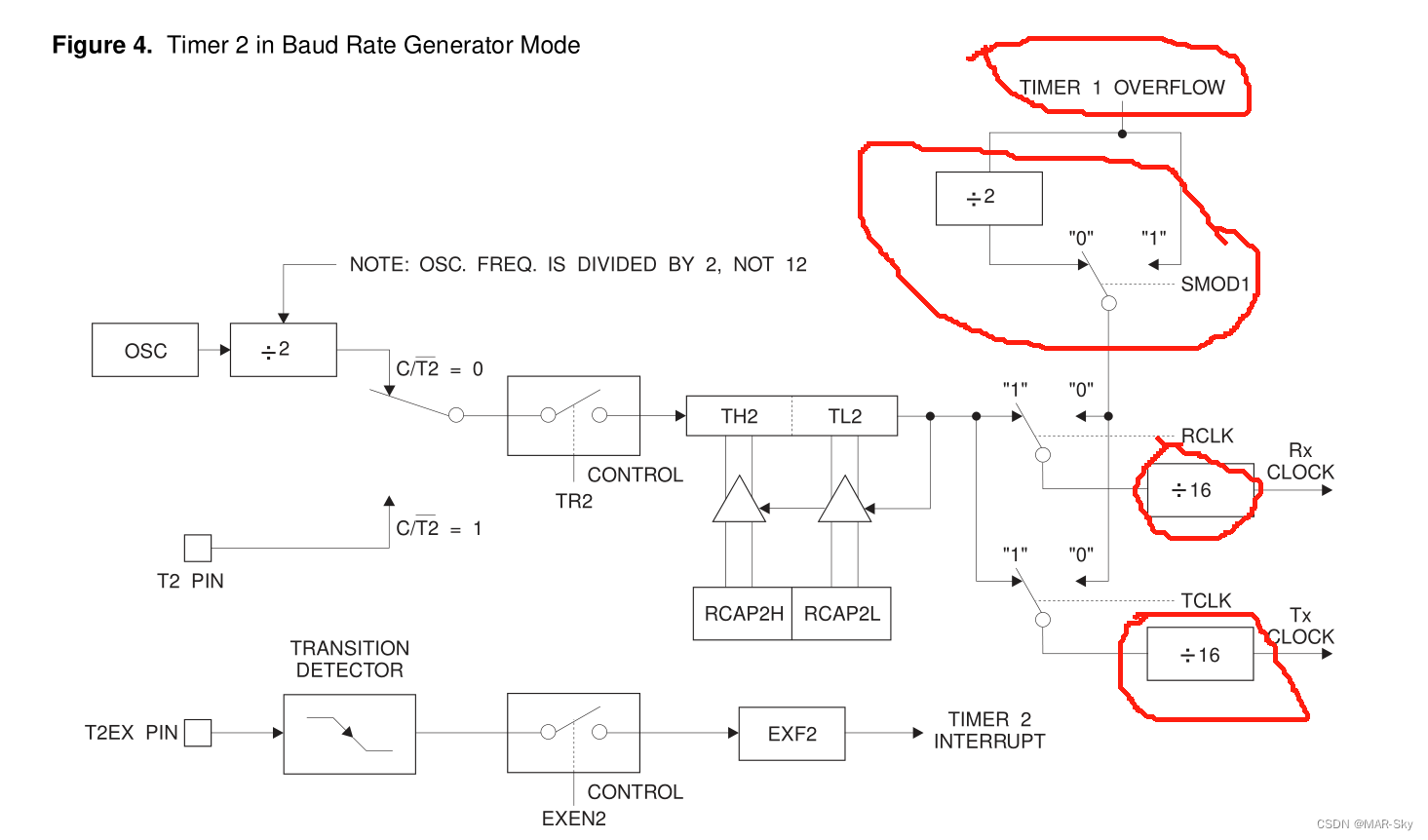
图 20-1。左上角:flags2_threadpool.py 运行时由 tqdm 生成的实时进度条;右下角:脚本完成后相同的终端窗口。
最简单的tqdm示例出现在项目的README.md中的动画*.gif中。如果在安装了tqdm*包后在 Python 控制台中输入以下代码,您将看到一个动画进度条,其中的注释是:
>>> import time
>>> from tqdm import tqdm
>>> for i in tqdm(range(1000)):
... time.sleep(.01)
...
>>> # -> progress bar will appear here <-
除了整洁的效果外,tqdm函数在概念上也很有趣:它消耗任何可迭代对象,并生成一个迭代器,当它被消耗时,显示进度条并估计完成所有迭代所需的剩余时间。为了计算这个估计值,tqdm需要获得一个具有len的可迭代对象,或者另外接收期望的项目数量作为total=参数。将tqdm与我们的flags2示例集成提供了一个机会,深入了解并发脚本的实际工作原理,强制我们使用futures.as_completed和asyncio.as_completed函数,以便tqdm可以在每个未来完成时显示进度。
flags2示例的另一个特点是命令行界面。所有三个脚本都接受相同的选项,您可以通过在任何脚本中使用-h选项来查看它们。示例 20-10 显示了帮助文本。
示例 20-10。flags2 系列脚本的帮助界面
$ python3 flags2_threadpool.py -h
usage: flags2_threadpool.py [-h] [-a] [-e] [-l N] [-m CONCURRENT] [-s LABEL]
[-v]
[CC [CC ...]]
Download flags for country codes. Default: top 20 countries by population.
positional arguments:
CC country code or 1st letter (eg. B for BA...BZ)
optional arguments:
-h, --help show this help message and exit
-a, --all get all available flags (AD to ZW)
-e, --every get flags for every possible code (AA...ZZ)
-l N, --limit N limit to N first codes
-m CONCURRENT, --max_req CONCURRENT
maximum concurrent requests (default=30)
-s LABEL, --server LABEL
Server to hit; one of DELAY, ERROR, LOCAL, REMOTE
(default=LOCAL)
-v, --verbose output detailed progress info
所有参数都是可选的。但-s/--server对于测试是必不可少的:它让您选择在测试中使用哪个 HTTP 服务器和端口。传递这些不区分大小写的标签之一,以确定脚本将在哪里查找标志:
本地
使用http://localhost:8000/flags;这是默认设置。您应该配置一个本地 HTTP 服务器以在端口 8000 回答。查看以下说明。
远程
使用http://fluentpython.com/data/flags;这是我拥有的一个公共网站,托管在共享服务器上。请不要对其进行过多的并发请求。fluentpython.com域名由Cloudflare CDN(内容交付网络)处理,因此您可能会注意到初始下载速度较慢,但当 CDN 缓存热身时速度会加快。
延迟
使用http://localhost:8001/flags;一个延迟 HTTP 响应的服务器应该监听端口 8001。我编写了slow_server.py来使实验更加容易。您可以在Fluent Python代码库的*20-futures/getflags/*目录中找到它。查看以下说明。
错误
使用http://localhost:8002/flags;一个返回一些 HTTP 错误的服务器应该监听端口 8002。接下来是说明。
设置测试服务器
如果您没有用于测试的本地 HTTP 服务器,我在fluentpython/example-code-2e代码库的20-executors/getflags/README.adoc中使用仅 Python ≥ 3.9(无外部库)编写了设置说明。简而言之,README.adoc描述了如何使用:
python3 -m http.server
本地服务器端口 8000
python3 slow_server.py
在端口 8001 上的DELAY服务器,在每个响应之前增加随机延迟 0.5 秒至 5 秒
python3 slow_server.py 8002 --error-rate .25
在端口 8002 上的ERROR服务器,除了随机延迟外,还有 25%的几率返回“418 我是一个茶壶”错误响应
默认情况下,每个flags2.py脚本将使用默认的并发连接数从LOCAL服务器(http://localhost:8000/flags)获取人口最多的 20 个国家的标志,这在脚本之间有所不同。示例 20-11 展示了使用所有默认值运行flags2_sequential.py*脚本的示例。要运行它,您需要一个本地服务器,如“测试并发客户端时要小心”中所解释的那样。
示例 20-11. 使用所有默认值运行 flags2_sequential.py:LOCAL 站点,前 20 个标志,1 个并发连接
$ python3 flags2_sequential.py
LOCAL site: http://localhost:8000/flags
Searching for 20 flags: from BD to VN
1 concurrent connection will be used.
--------------------
20 flags downloaded.
Elapsed time: 0.10s
您可以通过多种方式选择要下载的标志。示例 20-12 展示了如何下载所有以字母 A、B 或 C 开头的国家代码的标志。
示例 20-12. 运行 flags2_threadpool.py 从DELAY服务器获取所有以 A、B 或 C 开头的国家代码前缀的标志
$ python3 flags2_threadpool.py -s DELAY a b c
DELAY site: http://localhost:8001/flags
Searching for 78 flags: from AA to CZ
30 concurrent connections will be used.
--------------------
43 flags downloaded.
35 not found.
Elapsed time: 1.72s
无论如何选择国家代码,要获取的标志数量都可以通过-l/--limit选项限制。示例 20-13 演示了如何运行确切的 100 个请求,结合-a选项获取所有标志和-l 100。
示例 20-13. 运行 flags2_asyncio.py 从ERROR服务器获取 100 个标志(-al 100),使用 100 个并发请求(-m 100)
$ python3 flags2_asyncio.py -s ERROR -al 100 -m 100
ERROR site: http://localhost:8002/flags
Searching for 100 flags: from AD to LK
100 concurrent connections will be used.
--------------------
73 flags downloaded.
27 errors.
Elapsed time: 0.64s
这是flags2示例的用户界面。让我们看看它们是如何实现的。
flags2 示例中的错误处理
处理 flags2 示例中所有三个示例中 HTTP 错误的常见策略是,404 错误(未找到)由负责下载单个文件的函数(download_one)处理。任何其他异常都会传播以由download_many函数或supervisor协程处理—在asyncio示例中。
再次,我们将从研究顺序代码开始,这样更容易跟踪—并且大部分被线程池脚本重用。示例 20-14 展示了在flags2_sequential.py和flags2_threadpool.py脚本中执行实际下载的函数。
示例 20-14. flags2_sequential.py:负责下载的基本函数;两者在 flags2_threadpool.py 中都被重用
from collections import Counter
from http import HTTPStatus
import httpx
import tqdm # type: ignore # ①
from flags2_common import main, save_flag, DownloadStatus # ②
DEFAULT_CONCUR_REQ = 1
MAX_CONCUR_REQ = 1
def get_flag(base_url: str, cc: str) -> bytes:
url = f'{base_url}/{cc}/{cc}.gif'.lower()
resp = httpx.get(url, timeout=3.1, follow_redirects=True)
resp.raise_for_status() # ③
return resp.content
def download_one(cc: str, base_url: str, verbose: bool = False) -> DownloadStatus:
try:
image = get_flag(base_url, cc)
except httpx.HTTPStatusError as exc: # ④
res = exc.response
if res.status_code == HTTPStatus.NOT_FOUND:
status = DownloadStatus.NOT_FOUND # ⑤
msg = f'not found: {res.url}'
else:
raise # ⑥
else:
save_flag(image, f'{cc}.gif')
status = DownloadStatus.OK
msg = 'OK'
if verbose: # ⑦
print(cc, msg)
return status
①
导入tqdm进度条显示库,并告诉 Mypy 跳过检查它。⁷
②
从flags2_common模块导入一对函数和一个Enum。
③
如果 HTTP 状态码不在range(200, 300)中,则引发HTTPStetusError。
④
download_one捕获HTTPStatusError以处理特定的 HTTP 代码 404…
⑤
通过将其本地status设置为DownloadStatus.NOT_FOUND来处理; DownloadStatus是从flags2_common.py导入的Enum。
⑥
其他任何HTTPStatusError异常都会重新引发以传播给调用者。
⑦
如果设置了-v/--verbose命令行选项,则显示国家代码和状态消息;这是您在详细模式下看到进度的方式。
示例 20-15 列出了download_many函数的顺序版本。这段代码很简单,但值得研究,以与即将出现的并发版本进行对比。关注它如何报告进度,处理错误和统计下载量。
示例 20-15. flags2_sequential.py:download_many的顺序实现
def download_many(cc_list: list[str],
base_url: str,
verbose: bool,
_unused_concur_req: int) -> Counter[DownloadStatus]:
counter: Counter[DownloadStatus] = Counter() # ①
cc_iter = sorted(cc_list) # ②
if not verbose:
cc_iter = tqdm.tqdm(cc_iter) # ③
for cc in cc_iter:
try:
status = download_one(cc, base_url, verbose) # ④
except httpx.HTTPStatusError as exc: # ⑤
error_msg = 'HTTP error {resp.status_code} - {resp.reason_phrase}'
error_msg = error_msg.format(resp=exc.response)
except httpx.RequestError as exc: # ⑥
error_msg = f'{exc} {type(exc)}'.strip()
except KeyboardInterrupt: # ⑦
break
else: # ⑧
error_msg = ''
if error_msg:
status = DownloadStatus.ERROR # ⑨
counter[status] += 1 # ⑩
if verbose and error_msg: ⑪
print(f'{cc} error: {error_msg}')
return counter ⑫
①
这个Counter将统计不同的下载结果:DownloadStatus.OK、DownloadStatus.NOT_FOUND或DownloadStatus.ERROR。
②
cc_iter保存按字母顺序排列的国家代码列表。
③
如果不在详细模式下运行,将cc_iter传递给tqdm,它会返回一个迭代器,该迭代器会产生cc_iter中的项目,并同时显示进度条。
④
连续调用download_one。
⑤
由get_flag引发的 HTTP 状态码异常,且未被download_one处理的异常在此处理。
⑥
其他与网络相关的异常在此处理。任何其他异常都会中止脚本,因为调用download_many的flags2_common.main函数没有try/except。
⑦
如果用户按下 Ctrl-C,则退出循环。
⑧
如果download_one没有发生异常,清除错误消息。
⑨
如果发生错误,相应地设置本地status。
⑩
为该status增加计数。
⑪
在详细模式下,显示当前国家代码的错误消息(如果有)。
⑫
返回counter,以便main函数可以在最终报告中显示数字。
我们现在将学习重构后的线程池示例,flags2_threadpool.py。
使用futures.as_completed
为了集成tqdm进度条并处理每个请求的错误,flags2_threadpool.py脚本使用了futures.ThreadPoolExecutor和我们已经见过的futures.as_completed函数。示例 20-16 是flags2_threadpool.py的完整代码清单。只实现了download_many函数;其他函数是从flags2_common.py和flags2_sequential.py中重用的。
示例 20-16. flags2_threadpool.py:完整代码清单
from collections import Counter
from concurrent.futures import ThreadPoolExecutor, as_completed
import httpx
import tqdm # type: ignore
from flags2_common import main, DownloadStatus
from flags2_sequential import download_one # ①
DEFAULT_CONCUR_REQ = 30 # ②
MAX_CONCUR_REQ = 1000 # ③
def download_many(cc_list: list[str],
base_url: str,
verbose: bool,
concur_req: int) -> Counter[DownloadStatus]:
counter: Counter[DownloadStatus] = Counter()
with ThreadPoolExecutor(max_workers=concur_req) as executor: # ④
to_do_map = {} # ⑤
for cc in sorted(cc_list): # ⑥
future = executor.submit(download_one, cc,
base_url, verbose) # ⑦
to_do_map[future] = cc # ⑧
done_iter = as_completed(to_do_map) # ⑨
if not verbose:
done_iter = tqdm.tqdm(done_iter, total=len(cc_list)) # ⑩
for future in done_iter: ⑪
try:
status = future.result() ⑫
except httpx.HTTPStatusError as exc: ⑬
error_msg = 'HTTP error {resp.status_code} - {resp.reason_phrase}'
error_msg = error_msg.format(resp=exc.response)
except httpx.RequestError as exc:
error_msg = f'{exc} {type(exc)}'.strip()
except KeyboardInterrupt:
break
else:
error_msg = ''
if error_msg:
status = DownloadStatus.ERROR
counter[status] += 1
if verbose and error_msg:
cc = to_do_map[future] ⑭
print(f'{cc} error: {error_msg}')
return counter
if __name__ == '__main__':
main(download_many, DEFAULT_CONCUR_REQ, MAX_CONCUR_REQ)
①
从flags2_sequential中重用download_one(示例 20-14)。
②
如果没有给出-m/--max_req命令行选项,这将是最大并发请求的数量,实现为线程池的大小;如果要下载的标志数量较少,实际数量可能会更小。
③
MAX_CONCUR_REQ限制了最大并发请求的数量,不管要下载的标志数量或-m/--max_req命令行选项的值如何。这是为了避免启动过多线程带来的显著内存开销的安全预防措施。
④
使用max_workers设置为由main函数计算的concur_req创建executor,concur_req是以下两者中较小的一个:MAX_CONCUR_REQ、cc_list的长度,或者-m/--max_req命令行选项的值。这样可以避免创建过多的线程。
⑤
这个dict将把每个代表一个下载的Future实例与相应的国家代码进行映射,以便进行错误报告。
⑥
按字母顺序遍历国家代码列表。结果的顺序将取决于 HTTP 响应的时间,但如果线程池的大小(由concur_req给出)远小于len(cc_list),您可能会注意到按字母顺序批量下载。
⑦
每次调用 executor.submit 都会安排一个可调用函数的执行,并返回一个 Future 实例。第一个参数是可调用函数,其余参数是它将接收的参数。
⑧
将 future 和国家代码存储在 dict 中。
⑨
futures.as_completed 返回一个迭代器,每当任务完成时就会产生一个 future。
⑩
如果不处于详细模式,将 as_completed 的结果用 tqdm 函数包装起来以显示进度条;因为 done_iter 没有 len,我们必须告诉 tqdm 预期的项目数量是多少,作为 total= 参数,这样 tqdm 就可以估计剩余的工作量。
⑪
遍历已完成的 futures。
⑫
在 future 上调用 result 方法会返回可调用函数的返回值,或者在执行可调用函数时捕获的任何异常。这个方法可能会阻塞等待解决,但在这个例子中不会,因为 as_completed 只返回已完成的 future。
⑬
处理潜在的异常;这个函数的其余部分与示例 20-15)中的顺序 download_many 相同,除了下一个 callout。
⑭
为了提供错误消息的上下文,使用当前的 future 作为键从 to_do_map 中检索国家代码。这在顺序版本中是不必要的,因为我们是在国家代码列表上进行迭代,所以我们知道当前的 cc;而在这里我们是在 futures 上进行迭代。
提示
示例 20-16 使用了一个在 futures.as_completed 中非常有用的习语:构建一个 dict 来将每个 future 映射到在 future 完成时可能有用的其他数据。这里的 to_do_map 将每个 future 映射到分配给它的国家代码。这使得很容易对 futures 的结果进行后续处理,尽管它们是无序生成的。
Python 线程非常适合 I/O 密集型应用程序,而 concurrent.futures 包使得在某些用例中相对简单地使用它变得可能。通过 ProcessPoolExecutor,您还可以在多个核心上解决 CPU 密集型问题——如果计算是“尴尬地并行”的话。这结束了我们对 concurrent.futures 的基本介绍。
章节总结
我们通过比较两个并发的 HTTP 客户端和一个顺序的客户端来开始本章,演示了并发解决方案相对于顺序脚本显示出的显著性能提升。
在学习基于 concurrent.futures 的第一个例子之后,我们更仔细地研究了 future 对象,无论是 concurrent.futures.Future 的实例还是 asyncio.Future,强调了这些类有什么共同之处(它们的差异将在第二十一章中强调)。我们看到如何通过调用 Executor.submit 创建 futures,并使用 concurrent.futures.as_completed 迭代已完成的 futures。
然后,我们讨论了如何使用 concurrent.futures.ProcessPoolExecutor 类与多个进程一起工作,绕过 GIL 并使用多个 CPU 核心来简化我们在第十九章中首次看到的多核素数检查器。
在接下来的部分中,我们看到了 concurrent.futures.ThreadPoolExecutor 如何通过一个示教性的例子工作,启动了几个任务,这些任务只是等待几秒钟,除了显示它们的状态和时间戳。
接下来我们回到了下载标志的示例。通过增加进度条和适当的错误处理来增强它们,促使进一步探索future.as_completed生成器函数,展示了一个常见模式:在提交时将 futures 存储在dict中以将进一步信息链接到它们,这样我们可以在 future 从as_completed迭代器中出来时使用该信息。
进一步阅读
concurrent.futures包是由 Brian Quinlan 贡献的,他在 PyCon Australia 2010 年的一次名为“未来即将到来!”的精彩演讲中介绍了它。Quinlan 的演讲没有幻灯片;他通过在 Python 控制台中直接输入代码来展示库的功能。作为一个激励性的例子,演示中展示了一个短视频,其中 XKCD 漫画家/程序员 Randall Munroe 无意中对 Google 地图发起了 DoS 攻击,以构建他所在城市周围的驾驶时间彩色地图。该库的正式介绍是PEP 3148 - futures - 异步执行计算。在 PEP 中,Quinlan 写道,concurrent.futures库“受到了 Javajava.util.concurrent包的重大影响。”
有关concurrent.futures的其他资源,请参阅第十九章。所有涵盖 Python 的threading和multiprocessing的参考资料也包括“使用线程和进程进行并发处理”。
¹ 来自 Michele Simionato 的帖子“Python 中的线程、进程和并发性:一些思考”,总结为“消除多核(非)革命周围的炒作以及关于线程和其他形式并发性的一些(希望是)明智的评论。”
² 特别是如果您的云服务提供商按秒租用机器,而不管 CPU 有多忙。
³ 对于可能受到许多客户端攻击的服务器,有一个区别:协程比线程更具扩展性,因为它们使用的内存比线程少得多,并且还减少了上下文切换的成本,我在“基于线程的非解决方案”中提到过。
⁴ 这些图片最初来自CIA 世界概况,这是一份公共领域的美国政府出版物。我将它们复制到我的网站上,以避免对cia.gov发起 DOS 攻击的风险。
⁵ 设置follow_redirects=True对于这个示例并不需要,但我想强调HTTPX和requests之间的这个重要区别。此外,在这个示例中设置follow_redirects=True给了我将来在其他地方托管图像文件的灵活性。我认为HTTPX默认设置为follow_redirects=False是明智的,因为意外的重定向可能掩盖不必要的请求并复杂化错误诊断。
⁶ 你的体验可能有所不同:使用线程,你永远不知道几乎同时发生的事件的确切顺序;在另一台机器上,可能会看到loiter(1)在loiter(0)完成之前开始,特别是因为sleep总是释放 GIL,所以即使你睡眠 0 秒,Python 也可能切换到另一个线程。
⁷ 截至 2021 年 9 月,当前版本的tdqm中没有类型提示。没关系。世界不会因此而终结。感谢 Guido 提供可选类型提示!
⁸ 来自 PyCon 2009 年演示的“关于协程和并发性的一门好奇课程”教程的幻灯片#9。
第二十一章:异步编程
异步编程的常规方法的问题在于它们是全有或全无的命题。你要么重写所有代码以便没有阻塞,要么你只是在浪费时间。
Alvaro Videla 和 Jason J. W. Williams,《RabbitMQ 实战》¹
本章涉及三个密切相关的主题:
-
Python 的
async def,await,async with和async for构造 -
支持这些构造的对象:原生协程和异步上下文管理器、可迭代对象、生成器和推导式的异步变体
-
asyncio和其他异步库
本章建立在可迭代对象和生成器的思想上(第十七章,特别是“经典协程”),上下文管理器(第十八章),以及并发编程的一般概念(第十九章)。
我们将研究类似于我们在第二十章中看到的并发 HTTP 客户端,使用原生协程和异步上下文管理器进行重写,使用与之前相同的HTTPX库,但现在通过其异步 API。我们还将看到如何通过将慢速操作委托给线程或进程执行器来避免阻塞事件循环。
在 HTTP 客户端示例之后,我们将看到两个简单的异步服务器端应用程序,其中一个使用越来越受欢迎的FastAPI框架。然后我们将介绍由async/await关键字启用的其他语言构造:异步生成器函数,异步推导式和异步生成器表达式。为了强调这些语言特性与asyncio无关的事实,我们将看到一个示例被重写以使用Curio——由 David Beazley 发明的优雅而创新的异步框架。
最后,我写了一个简短的部分来总结异步编程的优势和陷阱。
这是很多内容要涵盖的。我们只有空间来展示基本示例,但它们将说明每个想法的最重要特点。
提示
asyncio文档在 Yury Selivanov²重新组织后要好得多,将对应用程序开发者有用的少数函数与用于创建诸如 Web 框架和数据库驱动程序的低级 API 分开。
对于asyncio的书籍长度覆盖,我推荐 Caleb Hattingh(O’Reilly)的在 Python 中使用 Asyncio。完全透明:Caleb 是本书的技术审阅者之一。
本章的新内容
当我写第一版流畅的 Python时,asyncio库是临时的,async/await关键字不存在。因此,我不得不更新本章中的所有示例。我还创建了新的示例:域探测脚本,FastAPI网络服务以及与 Python 的新异步控制台模式的实验。
新的章节涵盖了当时不存在的语言特性,如原生协程、async with、async for以及支持这些构造的对象。
“异步工作原理及其不足之处”中的思想反映了我认为对于任何使用异步编程的人来说都是必读的艰辛经验。它们可能会为你节省很多麻烦——无论你是使用 Python 还是 Node.js。
最后,我删除了关于asyncio.Futures的几段内容,这现在被认为是低级asyncioAPI 的一部分。
一些定义
在“经典协程”的开头,我们看到 Python 3.5 及更高版本提供了三种协程类型:
原生协程
使用async def定义的协程函数。您可以使用await关键字从一个本机协程委托到另一个本机协程,类似于经典协程使用yield from。async def语句始终定义一个本机协程,即使在其主体中未使用await关键字。await关键字不能在本机协程之外使用。³
经典协程
一个生成器函数,通过my_coro.send(data)调用接收发送给它的数据,并通过在表达式中使用yield来读取该数据。经典协程可以使用yield from委托给其他经典协程。经典协程不能由await驱动,并且不再受asyncio支持。
基于生成器的协程
使用@types.coroutine装饰的生成器函数—在 Python 3.5 中引入。该装饰器使生成器与新的await关键字兼容。
在本章中,我们专注于本机协程以及异步生成器:
异步生成器
使用async def定义的生成器函数,在其主体中使用yield。它返回一个提供__anext__的异步生成器对象,这是一个用于检索下一个项目的协程方法。
@asyncio.coroutine 没有未来⁴
对于经典协程和基于生成器的协程,@asyncio.coroutine装饰器在 Python 3.8 中已被弃用,并计划在 Python 3.11 中删除,根据Issue 43216。相反,根据Issue 36921,@types.coroutine应该保留。它不再受asyncio支持,但在Curio和Trio异步框架的低级代码中使用。
一个异步示例:探测域名
想象一下,你即将在 Python 上开始一个新博客,并计划注册一个使用 Python 关键字和*.DEV后缀的域名,例如:AWAIT.DEV. 示例 21-1 是一个使用asyncio*检查多个域名的脚本。这是它产生的输出:
$ python3 blogdom.py
with.dev
+ elif.dev
+ def.dev
from.dev
else.dev
or.dev
if.dev
del.dev
+ as.dev
none.dev
pass.dev
true.dev
+ in.dev
+ for.dev
+ is.dev
+ and.dev
+ try.dev
+ not.dev
请注意,域名是无序的。如果运行脚本,您将看到它们一个接一个地显示,延迟不同。+符号表示您的计算机能够通过 DNS 解析域名。否则,该域名未解析,可能可用。⁵
在blogdom.py中,DNS 探测通过本机协程对象完成。由于异步操作是交错进行的,检查这 18 个域名所需的时间远远少于按顺序检查它们所需的时间。实际上,总时间几乎与单个最慢的 DNS 响应的时间相同,而不是所有响应时间的总和。
示例 21-1 显示了blogdom.py的代码。
示例 21-1. blogdom.py:搜索 Python 博客的域名
#!/usr/bin/env python3
import asyncio
import socket
from keyword import kwlist
MAX_KEYWORD_LEN = 4 # ①
async def probe(domain: str) -> tuple[str, bool]: # ②
loop = asyncio.get_running_loop() # ③
try:
await loop.getaddrinfo(domain, None) # ④
except socket.gaierror:
return (domain, False)
return (domain, True)
async def main() -> None: # ⑤
names = (kw for kw in kwlist if len(kw) <= MAX_KEYWORD_LEN) # ⑥
domains = (f'{name}.dev'.lower() for name in names) # ⑦
coros = [probe(domain) for domain in domains] # ⑧
for coro in asyncio.as_completed(coros): # ⑨
domain, found = await coro # ⑩
mark = '+' if found else ' '
print(f'{mark} {domain}')
if __name__ == '__main__':
asyncio.run(main()) ⑪
①
设置域名关键字的最大长度,因为长度较短更好。
②
probe返回一个包含域名和布尔值的元组;True表示域名已解析。返回域名将使显示结果更容易。
③
获取对asyncio事件循环的引用,以便我们可以在下一步中使用它。
④
loop.getaddrinfo(…)协程方法返回一个五部分参数元组,以使用套接字连接到给定地址。在这个例子中,我们不需要结果。如果我们得到了结果,域名就解析了;否则,它没有解析。
⑤
main必须是一个协程,这样我们就可以在其中使用await。
⑥
生成器以不超过MAX_KEYWORD_LEN长度的 Python 关键字。
⑦
生成器以.dev后缀的域名为结果。
⑧
通过使用probe协程调用每个domain参数来构建协程对象列表。
⑨
asyncio.as_completed是一个生成器,按照完成的顺序而不是提交的顺序,产生传递给它的协程的结果。它类似于我们在第二十章中看到的futures.as_completed,示例 20-4。
⑩
到这一步,我们知道协程已经完成,因为这就是as_completed的工作原理。因此,await表达式不会阻塞,但我们需要它来获取coro的结果。如果coro引发了未处理的异常,它将在这里重新引发。
⑪
asyncio.run启动事件循环,并仅在事件循环退出时返回。这是使用asyncio的脚本的常见模式:将main实现为协程,并在if __name__ == '__main__':块中使用asyncio.run来驱动它。
提示
asyncio.get_running_loop函数在 Python 3.7 中添加,用于在协程内部使用,如probe所示。如果没有运行的循环,asyncio.get_running_loop会引发RuntimeError。它的实现比asyncio.get_event_loop更简单更快,后者可能在必要时启动事件循环。自 Python 3.10 起,asyncio.get_event_loop已被弃用,最终将成为asyncio.get_running_loop的别名。
Guido 的阅读异步代码的技巧
在asyncio中有很多新概念需要掌握,但如果你采用 Guido van Rossum 本人建议的技巧:眯起眼睛,假装async和await关键字不存在,那么你会意识到协程读起来就像普通的顺序函数。
例如,想象一下这个协程的主体…
async def probe(domain: str) -> tuple[str, bool]:
loop = asyncio.get_running_loop()
try:
await loop.getaddrinfo(domain, None)
except socket.gaierror:
return (domain, False)
return (domain, True)
…的工作方式类似于以下函数,只是它神奇地永远不会阻塞:
def probe(domain: str) -> tuple[str, bool]: # no async
loop = asyncio.get_running_loop()
try:
loop.getaddrinfo(domain, None) # no await
except socket.gaierror:
return (domain, False)
return (domain, True)
使用语法await loop.getaddrinfo(...)避免阻塞,因为await挂起当前协程对象。例如,在执行probe('if.dev')协程期间,getaddrinfo('if.dev', None)创建了一个新的协程对象。等待它会启动低级addrinfo查询,并将控制权返回给事件循环,而不是suspend的probe(‘if.dev’)协程。事件循环然后可以驱动其他待处理的协程对象,比如probe('or.dev')。
当事件循环收到getaddrinfo('if.dev', None)查询的响应时,特定的协程对象恢复并将控制返回给suspend在await处的probe('if.dev'),现在可以处理可能的异常并返回结果元组。
到目前为止,我们只看到asyncio.as_completed和await应用于协程。但它们处理任何可等待对象。下面将解释这个概念。
新概念:可等待对象
for 关键字与可迭代对象一起使用。await 关键字与可等待对象一起使用。
作为asyncio的最终用户,这些是你每天会看到的可等待对象:
-
一个本机协程对象,通过调用本机协程函数来获得
-
一个
asyncio.Task,通常通过将协程对象传递给asyncio.create_task()来获得
然而,最终用户代码并不总是需要在Task上await。我们使用asyncio.create_task(one_coro())来安排one_coro以并发执行,而无需等待其返回。这就是我们在spinner_async.py中对spinner协程所做的事情(示例 19-4)。如果你不打算取消任务或等待它,就没有必要保留从create_task返回的Task对象。创建任务足以安排协程运行。
相比之下,我们使用await other_coro()来立即运行other_coro并等待其完成,因为我们需要它的结果才能继续。在spinner_async.py中,supervisor协程执行了res = await slow()来执行slow并获取其结果。
在实现异步库或为asyncio本身做贡献时,您可能还会处理这些更低级别的可等待对象:
-
具有返回迭代器的
__await__方法的对象;例如,一个asyncio.Future实例(asyncio.Task是asyncio.Future的子类) -
使用 Python/C API 编写的对象具有
tp_as_async.am_await函数,返回一个迭代器(类似于__await__方法)
现有的代码库可能还有一种额外的可等待对象:基于生成器的协程对象—正在被弃用中。
注意
PEP 492 指出,await表达式“使用yield from实现,并增加了验证其参数的额外步骤”,“await只接受可等待对象”。PEP 没有详细解释该实现,但参考了PEP 380,该 PEP 引入了yield from。我在fluentpython.com的“经典协程”部分的“yield from 的含义”中发布了详细解释。
现在让我们来学习一个下载固定一组国旗图像的脚本的asyncio版本。
使用 asyncio 和 HTTPX 进行下载
flags_asyncio.py脚本从fluentpython.com下载了一组固定的 20 个国旗。我们在“并发网络下载”中首次提到它,但现在我们将详细研究它,应用我们刚刚看到的概念。
截至 Python 3.10,asyncio仅直接支持 TCP 和 UDP,标准库中没有异步 HTTP 客户端或服务器包。我在所有 HTTP 客户端示例中使用HTTPX。
我们将从底向上探索flags_asyncio.py,即首先查看在示例 21-2 中设置操作的函数。
警告
为了使代码更易于阅读,flags_asyncio.py没有错误处理。随着我们引入async/await,最初专注于“快乐路径”是有用的,以了解如何在程序中安排常规函数和协程。从“增强 asyncio 下载器”开始,示例包括错误处理和更多功能。
本章和第二十章中的flags_.py示例共享代码和数据,因此我将它们放在example-code-2e/20-executors/getflags目录中。
示例 21-2. flags_asyncio.py:启动函数
def download_many(cc_list: list[str]) -> int: # ①
return asyncio.run(supervisor(cc_list)) # ②
async def supervisor(cc_list: list[str]) -> int:
async with AsyncClient() as client: # ③
to_do = [download_one(client, cc)
for cc in sorted(cc_list)] # ④
res = await asyncio.gather(*to_do) # ⑤
return len(res) # ⑥
if __name__ == '__main__':
main(download_many)
①
这需要是一个普通函数—而不是协程—这样它就可以被flags.py模块的main函数传递和调用(示例 20-2)。
②
执行驱动supervisor(cc_list)协程对象的事件循环,直到其返回。这将在事件循环运行时阻塞。此行的结果是supervisor的返回值。
③
httpx中的异步 HTTP 客户端操作是AsyncClient的方法,它也是一个异步上下文管理器:具有异步设置和拆卸方法的上下文管理器(有关更多信息,请参阅“异步上下文管理器”)。
④
通过为每个要检索的国旗调用一次download_one协程来构建协程对象列表。
⑤
等待asyncio.gather协程,它接受一个或多个可等待参数,并等待它们全部完成,按照提交的可等待对象的顺序返回结果列表。
⑥
supervisor返回asyncio.gather返回的列表的长度。
现在让我们回顾flags_asyncio.py的顶部(示例 21-3)。我重新组织了协程,以便我们可以按照它们被事件循环启动的顺序来阅读它们。
示例 21-3. flags_asyncio.py:导入和下载函数
import asyncio
from httpx import AsyncClient # ①
from flags import BASE_URL, save_flag, main # ②
async def download_one(client: AsyncClient, cc: str): # ③
image = await get_flag(client, cc)
save_flag(image, f'{cc}.gif')
print(cc, end=' ', flush=True)
return cc
async def get_flag(client: AsyncClient, cc: str) -> bytes: # ④
url = f'{BASE_URL}/{cc}/{cc}.gif'.lower()
resp = await client.get(url, timeout=6.1,
follow_redirects=True) # ⑤
return resp.read() # ⑥
①
必须安装httpx——它不在标准库中。
②
从flags.py(示例 20-2)中重用代码。
③
download_one必须是一个原生协程,这样它就可以await在get_flag上——后者执行 HTTP 请求。然后显示下载标志的代码,并保存图像。
④
get_flag需要接收AsyncClient来发起请求。
⑤
httpx.AsyncClient实例的get方法返回一个ClientResponse对象,也是一个异步上下文管理器。
⑥
网络 I/O 操作被实现为协程方法,因此它们由asyncio事件循环异步驱动。
注意
为了提高性能,get_flag内部的save_flag调用应该是异步的,以避免阻塞事件循环。然而,asyncio目前并没有像 Node.js 那样提供异步文件系统 API。
“使用 asyncio.as_completed 和线程”将展示如何将save_flag委托给一个线程。
您的代码通过await显式委托给httpx协程,或通过异步上下文管理器的特殊方法(如AsyncClient和ClientResponse)隐式委托,正如我们将在“异步上下文管理器”中看到的那样。
本地协程的秘密:谦逊的生成器
我们在“经典协程”中看到的经典协程示例与flags_asyncio.py之间的一个关键区别是后者中没有可见的.send()调用或yield表达式。您的代码位于asyncio库和您正在使用的异步库(如HTTPX)之间,这在图 21-1 中有所说明。
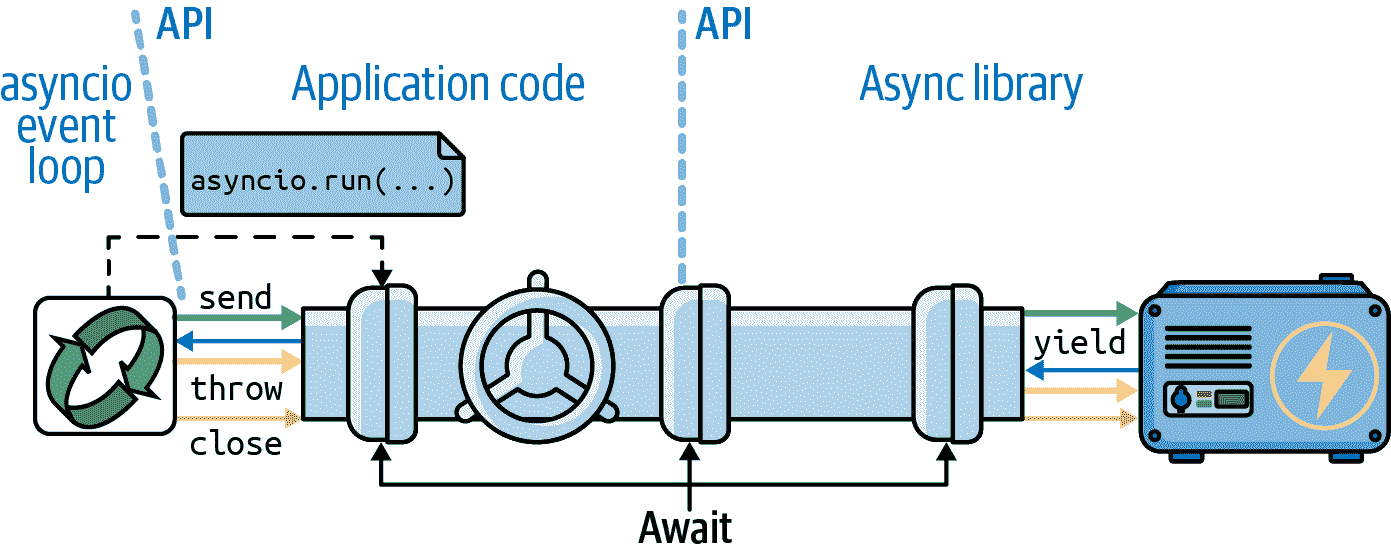
图 21-1. 在异步程序中,用户的函数启动事件循环,使用asyncio.run调度初始协程。每个用户的协程通过await表达式驱动下一个协程,形成一个通道,使得像HTTPX这样的库与事件循环之间能够进行通信。
在幕后,asyncio事件循环进行.send调用来驱动您的协程,您的协程await其他协程,包括库协程。正如前面提到的,await大部分实现来自yield from,后者也进行.send调用来驱动协程。
await链最终会到达一个低级可等待对象,它返回一个生成器,事件循环可以响应诸如计时器或网络 I/O 之类的事件来驱动它。这些await链末端的低级可等待对象和生成器深入到库中实现,不是其 API 的一部分,可能是 Python/C 扩展。
使用asyncio.gather和asyncio.create_task等函数,您可以启动多个并发的await通道,实现由单个事件循环在单个线程驱动的多个 I/O 操作的并发执行。
一切或无事可做问题
请注意,在 示例 21-3 中,我无法重用 flags.py 中的 get_flag 函数(示例 20-2)。我必须将其重写为一个协程,以使用 HTTPX 的异步 API。为了在 asyncio 中获得最佳性能,我们必须用 await 或 asyncio.create_task 替换每个执行 I/O 操作的函数,以便在函数等待 I/O 时将控制返回给事件循环。如果无法将阻塞函数重写为协程,应该在单独的线程或进程中运行它,正如我们将在 “委托任务给执行器” 中看到的。
这就是我选择本章的引语的原因,其中包括这样的建议:“你需要重写所有的代码,以便没有任何阻塞,否则你只是在浪费时间。”
出于同样的原因,我也无法重用 flags_threadpool.py 中的 download_one 函数(示例 20-3)。示例 21-3 中的代码使用 await 驱动 get_flag,因此 download_one 也必须是一个协程。对于每个请求,在 supervisor 中创建一个 download_one 协程对象,并且它们都由 asyncio.gather 协程驱动。
现在让我们研究出现在 supervisor(示例 21-2)和 get_flag(示例 21-3)中的 async with 语句。
异步上下文管理器
在 “上下文管理器和 with 语句” 中,我们看到一个对象如何在其类提供 __enter__ 和 __exit__ 方法的情况下用于在 with 块的主体之前和之后运行代码。
现在,考虑来自 asyncpg asyncio 兼容的 PostgreSQL 驱动器事务文档中的 示例 21-4。
示例 21-4. asyncpg PostgreSQL 驱动器文档中的示例代码
tr = connection.transaction()
await tr.start()
try:
await connection.execute("INSERT INTO mytable VALUES (1, 2, 3)")
except:
await tr.rollback()
raise
else:
await tr.commit()
数据库事务是上下文管理器协议的自然适用对象:事务必须启动,使用 connection.execute 更改数据,然后根据更改的结果进行回滚或提交。
在像 asyncpg 这样的异步驱动器中,设置和收尾需要是协程,以便其他操作可以同时进行。然而,经典 with 语句的实现不支持协程来执行 __enter__ 或 __exit__ 的工作。
这就是为什么 PEP 492—使用 async 和 await 语法的协程 引入了 async with 语句,它与实现了 __aenter__ 和 __aexit__ 方法的异步上下文管理器一起工作。
使用 async with,示例 21-4 可以像下面这样从 asyncpg 文档 中的另一个片段中编写:
async with connection.transaction():
await connection.execute("INSERT INTO mytable VALUES (1, 2, 3)")
在 asyncpg.Transaction 类中,__aenter__ 协程方法执行 await self.start(),而 __aexit__ 协程则等待私有的 __rollback 或 __commit 协程方法,取决于是否发生异常。使用协程来实现 Transaction 作为异步上下文管理器,使 asyncpg 能够同时处理许多事务。
Caleb Hattingh 关于 asyncpg
asyncpg 的另一个非常棒的地方是,它还解决了 PostgreSQL 缺乏高并发支持的问题(它为每个连接使用一个服务器端进程),通过为内部连接到 Postgres 本身实现了一个连接池。
这意味着你不需要像在 asyncpg 文档 中解释的那样额外使用 pgbouncer 这样的工具。⁶
回到 flags_asyncio.py,httpx 的 AsyncClient 类是一个异步上下文管理器,因此它可以在其 __aenter__ 和 __aexit__ 特殊协程方法中使用可等待对象。
注意
“异步生成器作为上下文管理器”展示了如何使用 Python 的contextlib创建一个异步上下文管理器,而无需编写类。由于先决主题:“异步生成器函数”,这个解释稍后在本章中提供。
现在我们将通过一个进度条增强asyncio标志下载示例,这将使我们更深入地探索asyncio API。
加强 asyncio 下载器
请回顾一下“带进度显示和错误处理的下载”,flags2示例集共享相同的命令行界面,并在下载进行时显示进度条。它们还包括错误处理。
提示
我鼓励您尝试使用flags2示例来培养对并发 HTTP 客户端性能的直觉。使用-h选项查看示例 20-10 中的帮助屏幕。使用-a、-e和-l命令行选项来控制下载数量,使用-m选项来设置并发下载数量。针对LOCAL、REMOTE、DELAY和ERROR服务器运行测试。发现最大化各服务器吞吐量所需的最佳并发下载数量。根据“设置测试服务器”中的描述调整测试服务器的选项。
例如,示例 21-5 展示了尝试从ERROR服务器获取 100 个标志(-al 100),使用 100 个并发请求(-m 100)。结果中的 48 个错误要么是 HTTP 418 错误,要么是超时错误——slow_server.py的预期(误)行为。
示例 21-5。运行 flags2_asyncio.py
$ python3 flags2_asyncio.py -s ERROR -al 100 -m 100
ERROR site: http://localhost:8002/flags
Searching for 100 flags: from AD to LK
100 concurrent connections will be used.
100%|█████████████████████████████████████████| 100/100 [00:03<00:00, 30.48it/s]
--------------------
52 flags downloaded.
48 errors.
Elapsed time: 3.31s
在测试并发客户端时要负责任
即使线程和asyncio HTTP 客户端之间的整体下载时间没有太大差异,asyncio可以更快地发送请求,因此服务器更有可能怀疑遭受到 DoS 攻击。为了真正全力运行这些并发客户端,请使用本地 HTTP 服务器进行测试,如“设置测试服务器”中所述。
现在让我们看看flags2_asyncio.py是如何实现的。
使用asyncio.as_completed和一个线程
在示例 21-3 中,我们将几个协程传递给asyncio.gather,它返回一个列表,其中包含按提交顺序排列的协程的结果。这意味着asyncio.gather只有在所有等待完成时才能返回。然而,为了更新进度条,我们需要在完成时获取结果。
幸运的是,asyncio中有一个与我们在线程池示例中使用的as_completed生成器函数等效的函数。
示例 21-6 显示了flags2_asyncio.py脚本的顶部,其中定义了get_flag和download_one协程。示例 21-7 列出了源代码的其余部分,包括supervisor和download_many。由于错误处理,此脚本比flags_asyncio.py更长。
示例 21-6。flags2_asyncio.py:脚本的顶部部分;其余代码在示例 21-7 中
import asyncio
from collections import Counter
from http import HTTPStatus
from pathlib import Path
import httpx
import tqdm # type: ignore
from flags2_common import main, DownloadStatus, save_flag
# low concurrency default to avoid errors from remote site,
# such as 503 - Service Temporarily Unavailable
DEFAULT_CONCUR_REQ = 5
MAX_CONCUR_REQ = 1000
async def get_flag(client: httpx.AsyncClient, # ①
base_url: str,
cc: str) -> bytes:
url = f'{base_url}/{cc}/{cc}.gif'.lower()
resp = await client.get(url, timeout=3.1, follow_redirects=True) # ②
resp.raise_for_status()
return resp.content
async def download_one(client: httpx.AsyncClient,
cc: str,
base_url: str,
semaphore: asyncio.Semaphore,
verbose: bool) -> DownloadStatus:
try:
async with semaphore: # ③
image = await get_flag(client, base_url, cc)
except httpx.HTTPStatusError as exc: # ④
res = exc.response
if res.status_code == HTTPStatus.NOT_FOUND:
status = DownloadStatus.NOT_FOUND
msg = f'not found: {res.url}'
else:
raise
else:
await asyncio.to_thread(save_flag, image, f'{cc}.gif') # ⑤
status = DownloadStatus.OK
msg = 'OK'
if verbose and msg:
print(cc, msg)
return status
①
get_flag与示例 20-14 中的顺序版本非常相似。第一个区别:它需要client参数。
②
第二和第三个区别:.get是AsyncClient的方法,它是一个协程,因此我们需要await它。
③
使用semaphore作为异步上下文管理器,以便整个程序不被阻塞;只有当信号量计数为零时,此协程才会被挂起。有关更多信息,请参阅“Python 的信号量”。
④
错误处理逻辑与download_one中的相同,来自示例 20-14。
⑤
保存图像是一个 I/O 操作。为了避免阻塞事件循环,在一个线程中运行save_flag。
所有网络 I/O 都是通过asyncio中的协程完成的,但文件 I/O 不是。然而,文件 I/O 也是“阻塞的”——因为读取/写入文件比读取/写入 RAM 要花费数千倍的时间。如果使用网络附加存储,甚至可能涉及网络 I/O。
自 Python 3.9 起,asyncio.to_thread协程使得将文件 I/O 委托给asyncio提供的线程池变得容易。如果需要支持 Python 3.7 或 3.8,“委托任务给执行器”展示了如何添加几行代码来实现。但首先,让我们完成对 HTTP 客户端代码的研究。
使用信号量限制请求
我们正在研究的网络客户端应该被限制(即,限制)以避免向服务器发送过多并发请求。
信号量是一种同步原语,比锁更灵活。信号量可以被多个协程持有,最大数量可配置。这使其成为限制活动并发协程数量的理想选择。“Python 的信号量”有更多信息。
在flags2_threadpool.py(示例 20-16)中,通过在download_many函数中将所需的max_workers参数设置为concur_req来完成限流。在flags2_asyncio.py中,通过supervisor函数创建一个asyncio.Semaphore(在示例 21-7 中显示),并将其作为semaphore参数传递给示例 21-6 中的download_one。
现在让我们看一下示例 21-7 中剩下的脚本。
示例 21-7. flags2_asyncio.py:脚本从示例 21-6 继续
async def supervisor(cc_list: list[str],
base_url: str,
verbose: bool,
concur_req: int) -> Counter[DownloadStatus]: # ①
counter: Counter[DownloadStatus] = Counter()
semaphore = asyncio.Semaphore(concur_req) # ②
async with httpx.AsyncClient() as client:
to_do = [download_one(client, cc, base_url, semaphore, verbose)
for cc in sorted(cc_list)] # ③
to_do_iter = asyncio.as_completed(to_do) # ④
if not verbose:
to_do_iter = tqdm.tqdm(to_do_iter, total=len(cc_list)) # ⑤
error: httpx.HTTPError | None = None # ⑥
for coro in to_do_iter: # ⑦
try:
status = await coro # ⑧
except httpx.HTTPStatusError as exc:
error_msg = 'HTTP error {resp.status_code} - {resp.reason_phrase}'
error_msg = error_msg.format(resp=exc.response)
error = exc # ⑨
except httpx.RequestError as exc:
error_msg = f'{exc} {type(exc)}'.strip()
error = exc # ⑩
except KeyboardInterrupt:
break
if error:
status = DownloadStatus.ERROR ⑪
if verbose:
url = str(error.request.url) ⑫
cc = Path(url).stem.upper() ⑬
print(f'{cc} error: {error_msg}')
counter[status] += 1
return counter
def download_many(cc_list: list[str],
base_url: str,
verbose: bool,
concur_req: int) -> Counter[DownloadStatus]:
coro = supervisor(cc_list, base_url, verbose, concur_req)
counts = asyncio.run(coro) ⑭
return counts
if __name__ == '__main__':
main(download_many, DEFAULT_CONCUR_REQ, MAX_CONCUR_REQ)
①
supervisor接受与download_many函数相同的参数,但不能直接从main中调用,因为它是一个协程,不像download_many那样是一个普通函数。
②
创建一个asyncio.Semaphore,不允许使用此信号量的协程中有超过concur_req个活动协程。concur_req的值由flags2_common.py中的main函数根据命令行选项和每个示例中设置的常量计算得出。
③
创建一个协程对象列表,每个调用download_one协程对应一个。
④
获取一个迭代器,将会在完成时返回协程对象。我没有直接将这个as_completed调用放在下面的for循环中,因为根据用户对详细程度的选择,我可能需要用tqdm迭代器包装它以显示进度条。
⑤
使用tqdm生成器函数包装as_completed迭代器以显示进度。
⑥
使用None声明和初始化error;如果在try/except语句之外引发异常,将使用此变量来保存异常。
⑦
迭代完成的协程对象;此循环类似于示例 20-16 中的download_many中的循环。
⑧
await协程以获取其结果。这不会阻塞,因为as_completed只会产生已完成的协程。
⑨
这个赋值是必要的,因为exc变量的作用域仅限于这个except子句,但我需要保留其值以供以后使用。
⑩
与之前相同。
⑪
如果出现错误,设置status。
⑫
在详细模式下,从引发的异常中提取 URL…
⑬
…并提取文件名以显示国家代码。
⑭
download_many实例化supervisor协程对象,并将其传递给事件循环以使用asyncio.run,在事件循环结束时收集supervisor返回的计数器。
在示例 21-7 中,我们无法使用我们在示例 20-16 中看到的将未来映射到国家代码的映射,因为asyncio.as_completed返回的可等待对象与我们传递给as_completed调用的可等待对象相同。在内部,asyncio机制可能会用最终产生相同结果的其他可等待对象替换我们提供的可等待对象。⁸
提示
由于在失败的情况下无法使用可等待对象作为键从dict中检索国家代码,我不得不从异常中提取国家代码。为此,我将异常保留在error变量中,以便在try/except语句之外检索。Python 不是块作用域语言:诸如循环和try/except之类的语句不会在其管理的块中创建局部作用域。但是,如果except子句将异常绑定到变量,就像我们刚刚看到的exc变量一样,那个绑定仅存在于该特定except子句内部的块中。
这里结束了对与flags2_threadpool.py在功能上等效的asyncio示例的讨论。
下一个示例演示了使用协程依次执行一个异步任务的简单模式。这值得我们关注,因为有经验的 JavaScript 用户都知道,依次运行一个异步函数是导致嵌套编码模式(称为doom 金字塔)的原因。await关键字让这个问题消失了。这就是为什么await现在成为 Python 和 JavaScript 的一部分。
为每个下载进行多个请求
假设您想要保存每个国家的国旗与国家名称和国家代码一起,而不仅仅是国家代码。现在您需要为每个旗帜进行两个 HTTP 请求:一个用于获取国旗图像本身,另一个用于获取与图像相同目录中的metadata.json文件,其中记录了国家的名称。
在线程脚本中协调多个请求很容易:只需依次发出一个请求,然后另一个请求,两次阻塞线程,并将两个数据(国家代码和名称)保存在本地变量中,以便在保存文件时使用。如果您需要在具有回调的异步脚本中执行相同操作,则需要嵌套函数,以便在闭包中可用国家代码和名称,直到可以保存文件,因为每个回调在不同的局部作用域中运行。await关键字可以解决这个问题,允许您依次驱动异步请求,共享驱动协程的局部作用域。
提示
如果你正在使用现代 Python 进行异步应用程序编程,并且有很多回调,那么你可能正在应用在现代 Python 中没有意义的旧模式。如果你正在编写一个与不支持协程的遗留或低级代码进行交互的库,这是合理的。无论如何,StackOverflow 的问答“future.add_done_callback()的用例是什么?”解释了为什么在低级代码中需要回调,但在现代 Python 应用级代码中并不是很有用。
asyncio标志下载脚本的第三个变体有一些变化:
get_country
这个新协程为国家代码获取metadata.json文件,并从中获取国家名称。
download_one
这个协程现在使用await委托给get_flag和新的get_country协程,使用后者的结果构建要保存的文件名。
让我们从get_country的代码开始(示例 21-8)。请注意,它与示例 21-6 中的get_flag非常相似。
示例 21-8. flags3_asyncio.py:get_country协程
async def get_country(client: httpx.AsyncClient,
base_url: str,
cc: str) -> str: # ①
url = f'{base_url}/{cc}/metadata.json'.lower()
resp = await client.get(url, timeout=3.1, follow_redirects=True)
resp.raise_for_status()
metadata = resp.json() # ②
return metadata['country'] # ③
①
这个协程返回一个包含国家名称的字符串——如果一切顺利的话。
②
metadata将从响应的 JSON 内容构建一个 Python dict。
③
返回国家名称。
现在让我们看看修改后的download_one在示例 21-9 中,与示例 21-6 中的相同协程相比,只有几行代码发生了变化。
示例 21-9. flags3_asyncio.py:download_one协程
async def download_one(client: httpx.AsyncClient,
cc: str,
base_url: str,
semaphore: asyncio.Semaphore,
verbose: bool) -> DownloadStatus:
try:
async with semaphore: # ①
image = await get_flag(client, base_url, cc)
async with semaphore: # ②
country = await get_country(client, base_url, cc)
except httpx.HTTPStatusError as exc:
res = exc.response
if res.status_code == HTTPStatus.NOT_FOUND:
status = DownloadStatus.NOT_FOUND
msg = f'not found: {res.url}'
else:
raise
else:
filename = country.replace(' ', '_') # ③
await asyncio.to_thread(save_flag, image, f'{filename}.gif')
status = DownloadStatus.OK
msg = 'OK'
if verbose and msg:
print(cc, msg)
return status
①
持有semaphore以await获取get_flag…
②
…再次为get_country。
③
使用国家名称创建文件名。作为一个命令行用户,我不喜欢在文件名中看到空格。
比嵌套回调好多了!
我将对get_flag和get_country的调用放在由semaphore控制的独立with块中,因为尽可能短暂地持有信号量和锁是一个良好的实践。
我可以使用asyncio.gather并行调度get_flag和get_country,但如果get_flag引发异常,则没有图像可保存,因此运行get_country是没有意义的。但有些情况下,使用asyncio.gather同时命中几个 API 而不是等待一个响应再发出下一个请求是有意义的。
在flags3_asyncio.py中,await语法出现了六次,async with出现了三次。希望你能掌握 Python 中的异步编程。一个挑战是要知道何时必须使用await以及何时不能使用它。原则上答案很简单:你await协程和其他可等待对象,比如asyncio.Task实例。但有些 API 很棘手,以看似任意的方式混合协程和普通函数,就像我们将在示例 21-14 中使用的StreamWriter类一样。
示例 21-9 总结了flags示例集。现在让我们讨论在异步编程中使用线程或进程执行者。
将任务委托给执行者
Node.js 相对于 Python 在异步编程方面的一个重要优势是 Node.js 标准库,它为所有 I/O 提供了异步 API,而不仅仅是网络 I/O。在 Python 中,如果不小心,文件 I/O 可能会严重降低异步应用程序的性能,因为在主线程中读取和写入存储会阻塞事件循环。
在示例 21-6 的download_one协程中,我使用了这行代码将下载的图像保存到磁盘上:
await asyncio.to_thread(save_flag, image, f'{cc}.gif')
如前所述,asyncio.to_thread是在 Python 3.9 中添加的。如果需要支持 3.7 或 3.8,则用示例 21-10 中的行替换那一行。
示例 21-10. 替代await asyncio.to_thread的行
loop = asyncio.get_running_loop() # ①
loop.run_in_executor(None, save_flag, # ②
image, f'{cc}.gif') # ③
①
获取事件循环的引用。
②
第一个参数是要使用的执行器;传递None会选择asyncio事件循环中始终可用的默认ThreadPoolExecutor。
③
你可以向要运行的函数传递位置参数,但如果需要传递关键字参数,则需要使用functool.partial,如run_in_executor文档中所述。
新的asyncio.to_thread函数更易于使用,更灵活,因为它还接受关键字参数。
asyncio本身的实现在一些地方使用run_in_executor。例如,我们在示例 21-1 中看到的loop.getaddrinfo(…)协程是通过调用socket模块中的getaddrinfo函数来实现的——这是一个可能需要几秒钟才能返回的阻塞函数,因为它依赖于 DNS 解析。
异步 API 中的常见模式是使用run_in_executor在协程中包装作为实现细节的阻塞调用。这样,您提供了一个一致的协程接口供await驱动,并隐藏了出于实用原因需要使用的线程。用于 MongoDB 的Motor异步驱动程序具有与async/await兼容的 API,实际上是一个围绕与数据库服务器通信的线程核心的外观。Motor 的首席开发人员 A. Jesse Jiryu Davis 在“异步 Python 和数据库的响应”中解释了他的理由。剧透:Davis 发现在线程池在数据库驱动程序的特定用例中更高效——尽管有一个关于异步方法总是比网络 I/O 的线程更快的神话。
将显式Executor传递给loop.run_in_executor的主要原因是,如果要执行的函数对 CPU 密集型,则可以使用ProcessPoolExecutor,以便在不同的 Python 进程中运行,避免争用 GIL。由于高启动成本,最好在supervisor中启动ProcessPoolExecutor,并将其传递给需要使用它的协程。
《Python 异步编程》的作者 Caleb Hattingh(O’Reilly)是本书的技术审阅者之一,并建议我添加关于执行器和asyncio的以下警告。
Caleb 关于 run_in_executors 的警告
使用run_in_executor可能会产生难以调试的问题,因为取消操作的工作方式可能不如预期。使用执行器的协程仅仅给出了取消的假象:底层线程(如果是ThreadPoolExecutor)没有取消机制。例如,在run_in_executor调用内创建的长时间运行的线程可能会阻止您的asyncio程序干净地关闭:asyncio.run将等待执行器完全关闭才返回,并且如果执行器的作业没有以某种方式停止,它将永远等待。我倾向于希望该函数被命名为run_in_executor_uncancellable。
现在我们将从客户端脚本转向使用asyncio编写服务器。
编写 asyncio 服务器
TCP 服务器的经典玩具示例是回显服务器。我们将构建稍微有趣的玩具:首先使用FastAPI和 HTTP,然后仅使用asyncio和纯 TCP 实现服务器端 Unicode 字符搜索实用程序。
这些服务器允许用户根据我们在“Unicode 数据库”中讨论的unicodedata模块中的标准名称中的单词查询 Unicode 字符。图 21-2 展示了与web_mojifinder.py进行的会话,这是我们将构建的第一个服务器。

图 21-2. 浏览器窗口显示来自 web_mojifinder.py 服务的“mountain”搜索结果。
这些示例中的 Unicode 搜索逻辑在Fluent Python代码存储库中的charindex.py模块中的InvertedIndex类中。在那个小模块中没有并发,所以我将在接下来的可选框中简要概述。您可以跳到“一个 FastAPI Web 服务”中的 HTTP 服务器实现。
一个 FastAPI Web 服务
我编写了下一个示例—web_mojifinder.py—使用FastAPI:这是“ASGI—异步服务器网关接口”中提到的 Python ASGI Web 框架之一。图 21-2 是前端的屏幕截图。这是一个超级简单的 SPA(单页应用程序):在初始 HTML 下载后,UI 通过客户端 JavaScript 与服务器通信来更新。
FastAPI旨在为 SPA 和移动应用程序实现后端,这些应用程序主要由返回 JSON 响应的 Web API 端点组成,而不是服务器呈现的 HTML。 FastAPI利用装饰器、类型提示和代码内省来消除大量用于 Web API 的样板代码,并自动发布交互式 OpenAPI(又名Swagger)文档,用于我们创建的 API。图 21-4 展示了web_mojifinder.py的自动生成的/docs页面。
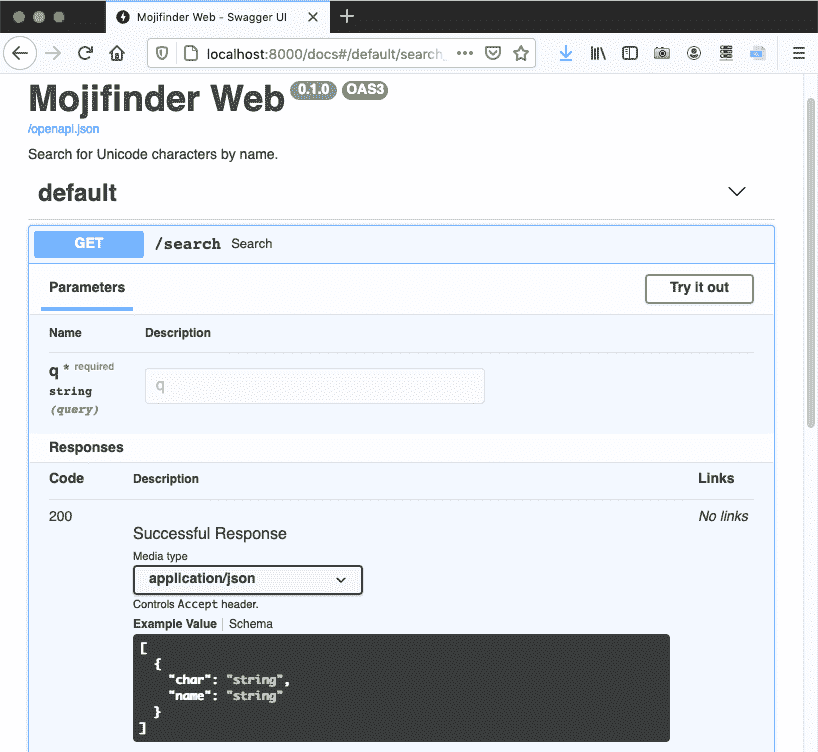
图 21-4. /search端点的自动生成 OpenAPI 模式。
示例 21-11 是web_mojifinder.py的代码,但那只是后端代码。当您访问根 URL/时,服务器会发送form.html文件,其中包括 81 行代码,其中包括 54 行 JavaScript 代码,用于与服务器通信并将结果填充到表中。如果您有兴趣阅读纯粹的无框架 JavaScript,请在Fluent Python代码存储库中找到21-async/mojifinder/static/form.html。
要运行web_mojifinder.py,您需要安装两个包及其依赖项:FastAPI和uvicorn。¹⁰ 这是在开发模式下使用uvicorn运行示例 21-11 的命令:
$ uvicorn web_mojifinder:app --reload
参数为:
web_mojifinder:app
包名称、冒号和其中定义的 ASGI 应用程序的名称——app是常规名称。
--reload
使uvicorn监视应用程序源文件的更改并自动重新加载它们。仅在开发过程中有用。
现在让我们研究web_mojifinder.py的源代码。
示例 21-11. web_mojifinder.py:完整源码
from pathlib import Path
from unicodedata import name
from fastapi import FastAPI
from fastapi.responses import HTMLResponse
from pydantic import BaseModel
from charindex import InvertedIndex
STATIC_PATH = Path(__file__).parent.absolute() / 'static' # ①
app = FastAPI( # ②
title='Mojifinder Web',
description='Search for Unicode characters by name.',
)
class CharName(BaseModel): # ③
char: str
name: str
def init(app): # ④
app.state.index = InvertedIndex()
app.state.form = (STATIC_PATH / 'form.html').read_text()
init(app) # ⑤
@app.get('/search', response_model=list[CharName]) # ⑥
async def search(q: str): # ⑦
chars = sorted(app.state.index.search(q))
return ({'char': c, 'name': name(c)} for c in chars) # ⑧
@app.get('/', response_class=HTMLResponse, include_in_schema=False)
def form(): # ⑨
return app.state.form
# no main funcion # ⑩
①
与本章主题无关,但值得注意的是pathlib通过重载的/运算符的优雅使用。¹¹
②
此行定义了 ASGI 应用程序。它可以简单到app = FastAPI()。所示的参数是自动生成文档的元数据。
③
一个带有char和name字段的 JSON 响应的pydantic模式。¹²
④
构建index并加载静态 HTML 表单,将两者附加到app.state以供以后使用。
⑤
当此模块由 ASGI 服务器加载时运行init。
⑥
/search端点的路由;response_model使用CharName pydantic模型描述响应格式。
⑦
FastAPI假设在函数或协程签名中出现的任何参数,而不在路由路径中的参数将传递到 HTTP 查询字符串中,例如,/search?q=cat。由于q没有默认值,如果查询字符串中缺少q,FastAPI将返回 422(无法处理的实体)状态。
⑧
返回与response_model模式兼容的dicts的可迭代对象允许FastAPI根据@app.get装饰器中的response_model构建 JSON 响应。
⑨
常规函数(即非异步函数)也可以用于生成响应。
⑩
这个模块没有主函数。在这个示例中,它由 ASGI 服务器—uvicorn加载和驱动。
示例 21-11 没有直接调用asyncio。FastAPI是建立在Starlette ASGI 工具包之上的,而Starlette又使用asyncio。
还要注意,search的主体不使用await、async with或async for,因此它可以是一个普通函数。我将search定义为协程只是为了展示FastAPI知道如何处理它。在真实的应用程序中,大多数端点将查询数据库或访问其他远程服务器,因此FastAPI支持可以利用异步库进行网络 I/O 的协程是FastAPI和 ASGI 框架的关键优势。
提示
我编写的init和form函数用于加载和提供静态 HTML 表单,这是为了让示例变得简短且易于运行。推荐的最佳实践是在 ASGI 服务器前面放置一个代理/负载均衡器来处理所有静态资产,并在可能的情况下使用 CDN(内容交付网络)。其中一个这样的代理/负载均衡器是Traefik,一个自称为“边缘路由器”的工具,“代表您的系统接收请求并找出哪些组件负责处理它们”。FastAPI有项目生成脚本,可以准备您的代码来实现这一点。
爱好类型提示的人可能已经注意到search和form中没有返回类型提示。相反,FastAPI依赖于路由装饰器中的response_model=关键字参数。FastAPI文档中的“响应模型”页面解释了:
响应模型在此参数中声明,而不是作为函数返回类型注释,因为路径函数实际上可能不返回该响应模型,而是返回一个 dict、数据库对象或其他模型,然后使用
response_model执行字段限制和序列化。
例如,在search中,我返回了一个dict项的生成器,而不是CharName对象的列表,但这对于FastAPI和pydantic来说已经足够验证我的数据并构建与response_model=list[CharName]兼容的适当 JSON 响应。
现在我们将专注于tcp_mojifinder.py脚本,该脚本正在回答图 21-5 中的查询。
一个 asyncio TCP 服务器
tcp_mojifinder.py程序使用普通 TCP 与像 Telnet 或 Netcat 这样的客户端通信,因此我可以使用asyncio编写它而无需外部依赖项—也无需重新发明 HTTP。图 21-5 展示了基于文本的用户界面。
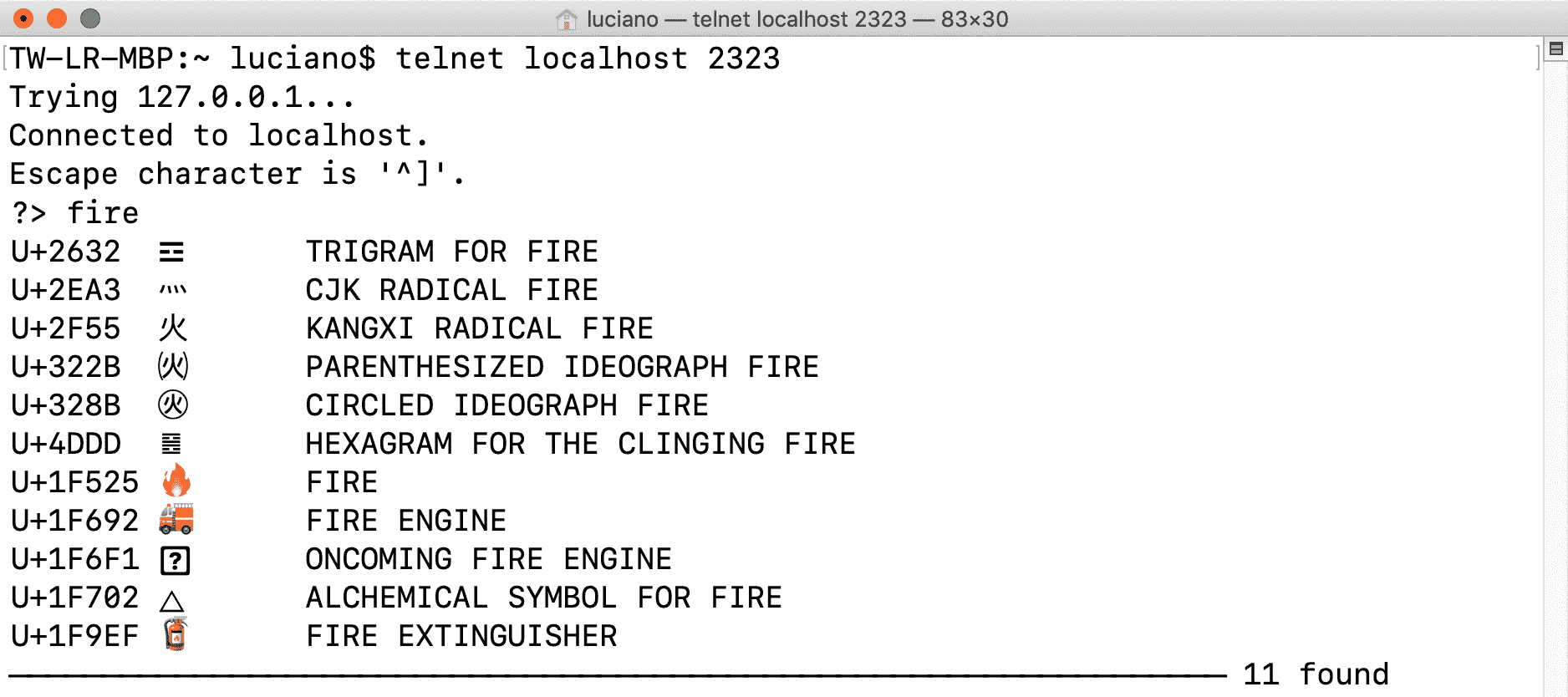
图 21-5. 使用 tcp_mojifinder.py 服务器进行 Telnet 会话:查询“fire”。
这个程序比web_mojifinder.py长一倍,所以我将演示分为三部分:示例 21-12、示例 21-14 和示例 21-15。tcp_mojifinder.py的顶部—包括import语句—在示例 21-14 中,但我将从描述supervisor协程和驱动程序的main函数开始。
示例 21-12. tcp_mojifinder.py:一个简单的 TCP 服务器;继续查看示例 21-14
async def supervisor(index: InvertedIndex, host: str, port: int) -> None:
server = await asyncio.start_server( # ①
functools.partial(finder, index), # ②
host, port) # ③
socket_list = cast(tuple[TransportSocket, ...], server.sockets) # ④
addr = socket_list[0].getsockname()
print(f'Serving on {addr}. Hit CTRL-C to stop.') # ⑤
await server.serve_forever() # ⑥
def main(host: str = '127.0.0.1', port_arg: str = '2323'):
port = int(port_arg)
print('Building index.')
index = InvertedIndex() # ⑦
try:
asyncio.run(supervisor(index, host, port)) # ⑧
except KeyboardInterrupt: # ⑨
print('\nServer shut down.')
if __name__ == '__main__':
main(*sys.argv[1:])
①
这个await快速获取了一个asyncio.Server实例,一个 TCP 套接字服务器。默认情况下,start_server创建并启动服务器,因此它已准备好接收连接。
②
start_server的第一个参数是client_connected_cb,一个在新客户端连接开始时运行的回调函数。回调函数可以是一个函数或一个协程,但必须接受两个参数:一个asyncio.StreamReader和一个asyncio.StreamWriter。然而,我的finder协程还需要获取一个index,所以我使用functools.partial来绑定该参数并获得一个接受读取器和写入器的可调用对象。将用户函数适配为回调 API 是functools.partial的最常见用例。
③
host和port是start_server的第二个和第三个参数。在asyncio文档中查看完整的签名。
④
这个cast是必需的,因为typeshed对Server类的sockets属性的类型提示已过时—截至 2021 年 5 月。参见typeshed上的Issue #5535。¹³
⑤
显示服务器的第一个套接字的地址和端口。
⑥
尽管start_server已经将服务器作为并发任务启动,但我需要在server_forever方法上await,以便我的supervisor在此处暂停。如果没有这行,supervisor将立即返回,结束由asyncio.run(supervisor(…))启动的循环,并退出程序。Server.serve_forever的文档中说:“如果服务器已经接受连接,则可以调用此方法。”
⑦
构建倒排索引。¹⁴
⑧
启动运行supervisor的事件循环。
⑨
捕获KeyboardInterrupt以避免在终止运行它的终端上使用 Ctrl-C 停止服务器时出现令人分心的回溯。
如果您研究服务器控制台上生成的输出,可以更容易地理解tcp_mojifinder.py中的控制流程,在示例 21-13 中列出。
示例 21-13. tcp_mojifinder.py:这是图 21-5 中描述的会话的服务器端
$ python3 tcp_mojifinder.py
Building index. # ① Serving on ('127.0.0.1', 2323). Hit Ctrl-C to stop. # ② From ('127.0.0.1', 58192): 'cat face' # ③ To ('127.0.0.1', 58192): 10 results.
From ('127.0.0.1', 58192): 'fire' # ④ To ('127.0.0.1', 58192): 11 results.
From ('127.0.0.1', 58192): '\x00' # ⑤ Close ('127.0.0.1', 58192). # ⑥ ^C # ⑦ Server shut down. # ⑧ $
①
main输出。在下一行出现之前,我在我的机器上看到了 0.6 秒的延迟,因为正在构建索引。
②
supervisor输出。
③
finder中while循环的第一次迭代。TCP/IP 堆栈将端口 58192 分配给了我的 Telnet 客户端。如果将多个客户端连接到服务器,您将在输出中看到它们的各种端口。
④
finder中while循环的第二次迭代。
⑤
我在客户端终端上按下了 Ctrl-C;finder中的while循环退出。
⑥
finder协程显示此消息然后退出。与此同时,服务器仍在运行,准备为另一个客户端提供服务。
⑦
我在服务器终端上按下了 Ctrl-C;server.serve_forever被取消,结束了supervisor和事件循环。
⑧
由main输出。
在main构建索引并启动事件循环后,supervisor快速显示Serving on…消息,并在await server.serve_forever()行处暂停。此时,控制流进入事件循环并留在那里,偶尔返回到finder协程,每当需要等待网络发送或接收数据时,它将控制权交还给事件循环。
当事件循环处于活动状态时,将为连接到服务器的每个客户端启动一个新的finder协程实例。通过这种方式,这个简单的服务器可以同时处理许多客户端。直到服务器上发生KeyboardInterrupt或其进程被操作系统终止。
现在让我们看看tcp_mojifinder.py的顶部,其中包含finder协程。
示例 21-14. tcp_mojifinder.py:续自示例 21-12
import asyncio
import functools
import sys
from asyncio.trsock import TransportSocket
from typing import cast
from charindex import InvertedIndex, format_results # ①
CRLF = b'\r\n'
PROMPT = b'?> '
async def finder(index: InvertedIndex, # ②
reader: asyncio.StreamReader,
writer: asyncio.StreamWriter) -> None:
client = writer.get_extra_info('peername') # ③
while True: # ④
writer.write(PROMPT) # can't await! # ⑤
await writer.drain() # must await! # ⑥
data = await reader.readline() # ⑦
if not data: # ⑧
break
try:
query = data.decode().strip() # ⑨
except UnicodeDecodeError: # ⑩
query = '\x00'
print(f' From {client}: {query!r}') ⑪
if query:
if ord(query[:1]) < 32: ⑫
break
results = await search(query, index, writer) ⑬
print(f' To {client}: {results} results.') ⑭
writer.close() ⑮
await writer.wait_closed() ⑯
print(f'Close {client}.') # ⑰
①
format_results对InvertedIndex.search的结果进行显示,在文本界面(如命令行或 Telnet 会话)中非常有用。
②
为了将finder传递给asyncio.start_server,我使用functools.partial对其进行了包装,因为服务器期望一个只接受reader和writer参数的协程或函数。
③
获取与套接字连接的远程客户端地址。
④
此循环处理一个对话,直到从客户端接收到控制字符为止。
⑤
StreamWriter.write方法不是一个协程,只是一个普通函数;这一行发送?>提示符。
⑥
StreamWriter.drain刷新writer缓冲区;它是一个协程,因此必须使用await来驱动它。
⑦
StreamWriter.readline是一个返回bytes的协程。
⑧
如果没有接收到任何字节,则客户端关闭了连接,因此退出循环。
⑨
将bytes解码为str,使用默认的 UTF-8 编码。
⑩
当用户按下 Ctrl-C 并且 Telnet 客户端发送控制字节时,可能会发生UnicodeDecodeError;如果发生这种情况,为简单起见,用空字符替换查询。
⑪
将查询记录到服务器控制台。
⑫
如果接收到控制字符或空字符,则退出循环。
⑬
执行实际的search;代码将在下面呈现。
⑭
将响应记录到服务器控制台。
⑮
关闭StreamWriter。
⑯
等待StreamWriter关闭。这在.close()方法文档中推荐。
⑰
将此客户端会话的结束记录到服务器控制台。
这个示例的最后一部分是search协程,如示例 21-15 所示。
示例 21-15. tcp_mojifinder.py:search协程
async def search(query: str, # ①
index: InvertedIndex,
writer: asyncio.StreamWriter) -> int:
chars = index.search(query) # ②
lines = (line.encode() + CRLF for line # ③
in format_results(chars))
writer.writelines(lines) # ④
await writer.drain() # ⑤
status_line = f'{"─" * 66} {len(chars)} found' # ⑥
writer.write(status_line.encode() + CRLF)
await writer.drain()
return len(chars)
①
search必须是一个协程,因为它写入一个StreamWriter并必须使用它的.drain()协程方法。
②
查询反向索引。
③
这个生成器表达式将产生用 UTF-8 编码的字节字符串,包含 Unicode 代码点、实际字符、其名称和一个CRLF序列,例如,b'U+0039\t9\tDIGIT NINE\r\n'。
④
发送lines。令人惊讶的是,writer.writelines不是一个协程。
⑤
但writer.drain()是一个协程。不要忘记await!
⑥
构建一个状态行,然后发送它。
请注意,tcp_mojifinder.py中的所有网络 I/O 都是以bytes形式;我们需要解码从网络接收的bytes,并在发送之前对字符串进行编码。在 Python 3 中,默认编码是 UTF-8,这就是我在本示例中所有encode和decode调用中隐式使用的编码。
警告
请注意,一些 I/O 方法是协程,必须使用await来驱动,而其他一些是简单的函数。例如,StreamWriter.write是一个普通函数,因为它写入缓冲区。另一方面,StreamWriter.drain——用于刷新缓冲区并执行网络 I/O 的协程,以及StreamReader.readline——但不是StreamWriter.writelines!在我写这本书的第一版时,asyncio API 文档通过清晰标记协程得到了改进。
tcp_mojifinder.py代码利用了高级别的asyncio Streams API,提供了一个可直接使用的服务器,因此你只需要实现一个处理函数,可以是一个普通回调函数或一个协程。还有一个更低级别的Transports and Protocols API,受到Twisted框架中传输和协议抽象的启发。请参考asyncio文档以获取更多信息,包括使用该低级别 API 实现的TCP 和 UDP 回显服务器和客户端。
我们下一个主题是async for和使其工作的对象。
异步迭代和异步可迭代对象
我们在“异步上下文管理器”中看到了async with如何与实现__aenter__和__aexit__方法返回可等待对象的对象一起工作——通常是协程对象的形式。
同样,async for适用于异步可迭代对象:实现了__aiter__的对象。然而,__aiter__必须是一个常规方法——不是一个协程方法——并且必须返回一个异步迭代器。
异步迭代器提供了一个__anext__协程方法,返回一个可等待对象——通常是一个协程对象。它们还应该实现__aiter__,通常返回self。这反映了我们在“不要让可迭代对象成为自身的迭代器”中讨论的可迭代对象和迭代器的重要区别。
aiopg异步 PostgreSQL 驱动程序文档中有一个示例,演示了使用async for来迭代数据库游标的行:
async def go():
pool = await aiopg.create_pool(dsn)
async with pool.acquire() as conn:
async with conn.cursor() as cur:
await cur.execute("SELECT 1")
ret = []
async for row in cur:
ret.append(row)
assert ret == [(1,)]
在这个示例中,查询将返回一行,但在实际情况下,你可能会对SELECT查询的响应有成千上万行。对于大量响应,游标不会一次性加载所有行。因此,很重要的是async for row in cur:不会阻塞事件循环,而游标可能正在等待更多行。通过将游标实现为异步迭代器,aiopg可以在每次__anext__调用时让出事件循环,并在后来从 PostgreSQL 接收更多行时恢复。
异步生成器函数
你可以通过编写一个带有__anext__和__aiter__的类来实现异步迭代器,但有一种更简单的方法:编写一个使用async def声明的函数,并在其体内使用yield。这与生成器函数简化经典的迭代器模式的方式相似。
让我们研究一个简单的例子,使用async for并实现一个异步生成器。在示例 21-1 中,我们看到了blogdom.py,一个探测域名的脚本。现在假设我们找到了我们在那里定义的probe协程的其他用途,并决定将其放入一个新模块—domainlib.py—与一个新的multi_probe异步生成器一起,该生成器接受一个域名列表,并在探测时产生结果。
我们很快将看到domainlib.py的实现,但首先让我们看看它如何与 Python 的新异步控制台一起使用。
尝试使用 Python 的异步控制台
自 Python 3.8 起,你可以使用-m asyncio命令行选项运行解释器,以获得一个“异步 REPL”:一个导入asyncio,提供运行事件循环,并在顶级提示符接受await、async for和async with的 Python 控制台——否则在外部协程之外使用时会产生语法错误。¹⁵
要尝试domainlib.py,请转到你本地Fluent Python代码库中的*21-async/domains/asyncio/*目录。然后运行:
$ python -m asyncio
你会看到控制台启动,类似于这样:
asyncio REPL 3.9.1 (v3.9.1:1e5d33e9b9, Dec 7 2020, 12:10:52)
[Clang 6.0 (clang-600.0.57)] on darwin
Use "await" directly instead of "asyncio.run()".
Type "help", "copyright", "credits" or "license" for more information.
>>> import asyncio
>>>
注意标题中说你可以使用await而不是asyncio.run()来驱动协程和其他可等待对象。另外:我没有输入import asyncio。asyncio模块会自动导入,并且该行使用户清楚地了解这一事实。
现在让我们导入domainlib.py并尝试其两个协程:probe和multi_probe(示例 21-16)。
示例 21-16. 在运行python3 -m asyncio后尝试domainlib.py
>>> await asyncio.sleep(3, 'Rise and shine!') # ①
'Rise and shine!' >>> from domainlib import *
>>> await probe('python.org') # ②
Result(domain='python.org', found=True) # ③
>>> names = 'python.org rust-lang.org golang.org no-lang.invalid'.split() # ④
>>> async for result in multi_probe(names): # ⑤
... print(*result, sep='\t')
...
golang.org True # ⑥
no-lang.invalid False python.org True rust-lang.org True >>>
①
尝试一个简单的await来看看异步控制台的运行情况。提示:asyncio.sleep()接受一个可选的第二个参数,在你await它时返回。
②
驱动probe协程。
③
probe的domainlib版本返回一个名为Result的命名元组。
④
制作一个域名列表。.invalid顶级域名保留用于测试。对于这些域的 DNS 查询总是从 DNS 服务器获得 NXDOMAIN 响应,意味着“该域名不存在”。¹⁶
⑤
使用async for迭代multi_probe异步生成器以显示结果。
⑥
注意结果不是按照传递给multiprobe的域的顺序出现的。它们会在每个 DNS 响应返回时出现。
示例 21-16 表明multi_probe是一个异步生成器,因为它与async for兼容。现在让我们进行一些更多的实验,从那个示例继续,使用示例 21-17。
示例 21-17. 更多实验,从示例 21-16 继续
>>> probe('python.org') # ①
<coroutine object probe at 0x10e313740> >>> multi_probe(names) # ②
<async_generator object multi_probe at 0x10e246b80> >>> for r in multi_probe(names): # ③
... print(r)
...
Traceback (most recent call last):
...
TypeError: 'async_generator' object is not iterable
①
调用一个原生协程会给你一个协程对象。
②
调用异步生成器会给你一个async_generator对象。
③
我们不能使用常规的for循环与异步生成器,因为它们实现了__aiter__而不是__iter__。
异步生成器由async for驱动,它可以是一个块语句(如示例 21-16 中所见),它还出现在异步推导式中,我们很快会介绍。
实现异步生成器
现在让我们研究domainlib.py中的代码,使用multi_probe异步生成器(示例 21-18)。
示例 21-18. domainlib.py:用于探测域的函数
import asyncio
import socket
from collections.abc import Iterable, AsyncIterator
from typing import NamedTuple, Optional
class Result(NamedTuple): # ①
domain: str
found: bool
OptionalLoop = Optional[asyncio.AbstractEventLoop] # ②
async def probe(domain: str, loop: OptionalLoop = None) -> Result: # ③
if loop is None:
loop = asyncio.get_running_loop()
try:
await loop.getaddrinfo(domain, None)
except socket.gaierror:
return Result(domain, False)
return Result(domain, True)
async def multi_probe(domains: Iterable[str]) -> AsyncIterator[Result]: # ④
loop = asyncio.get_running_loop()
coros = [probe(domain, loop) for domain in domains] # ⑤
for coro in asyncio.as_completed(coros): # ⑥
result = await coro # ⑦
yield result # ⑧
①
NamedTuple使得从probe得到的结果更易于阅读和调试。
②
这个类型别名是为了避免书中列表过长。
③
probe现在获得了一个可选的loop参数,以避免在此协程由multi_probe驱动时重复调用get_running_loop。
④
异步生成器函数产生一个异步生成器对象,可以注释为AsyncIterator[SomeType]。
⑤
构建包含不同domain的probe协程对象列表。
⑥
这不是async for,因为asyncio.as_completed是一个经典生成器。
⑦
等待协程对象以检索结果。
⑧
返回result。这一行使multi_probe成为一个异步生成器。
注意
示例 21-18 中的for循环可以更简洁:
for coro in asyncio.as_completed(coros):
yield await coro
Python 将其解析为yield (await coro),所以它有效。
我认为在书中第一个异步生成器示例中使用该快捷方式可能会让人困惑,所以我将其拆分为两行。
给定domainlib.py,我们可以演示在domaincheck.py中使用multi_probe异步生成器的方法:一个脚本,接受一个域后缀并搜索由短 Python 关键字组成的域。
这是domaincheck.py的一个示例输出:
$ ./domaincheck.py net
FOUND NOT FOUND
===== =========
in.net
del.net
true.net
for.net
is.net
none.net
try.net
from.net
and.net
or.net
else.net
with.net
if.net
as.net
elif.net
pass.net
not.net
def.net
多亏了domainlib,domaincheck.py的代码非常简单,如示例 21-19 所示。
示例 21-19. domaincheck.py:使用 domainlib 探测域的实用程序
#!/usr/bin/env python3
import asyncio
import sys
from keyword import kwlist
from domainlib import multi_probe
async def main(tld: str) -> None:
tld = tld.strip('.')
names = (kw for kw in kwlist if len(kw) <= 4) # ①
domains = (f'{name}.{tld}'.lower() for name in names) # ②
print('FOUND\t\tNOT FOUND') # ③
print('=====\t\t=========')
async for domain, found in multi_probe(domains): # ④
indent = '' if found else '\t\t' # ⑤
print(f'{indent}{domain}')
if __name__ == '__main__':
if len(sys.argv) == 2:
asyncio.run(main(sys.argv[1])) # ⑥
else:
print('Please provide a TLD.', f'Example: {sys.argv[0]} COM.BR')
①
生成长度最多为4的关键字。
②
生成具有给定后缀作为 TLD 的域名。
③
为表格输出格式化标题。
④
在multi_probe(domains)上异步迭代。
⑤
将indent设置为零或两个制表符,以将结果放在正确的列中。
⑥
使用给定的命令行参数运行main协程。
生成器有一个与迭代无关的额外用途:它们可以转换为上下文管理器。这也适用于异步生成器。
异步生成器作为上下文管理器
编写我们自己的异步上下文管理器并不是一个经常出现的编程任务,但如果您需要编写一个,考虑使用 Python 3.7 中添加到contextlib模块的@asynccontextmanager装饰器。这与我们在“使用@contextmanager”中学习的@contextmanager装饰器非常相似。
一个有趣的示例结合了@asynccontextmanager和loop.run_in_executor,出现在 Caleb Hattingh 的书Using Asyncio in Python中。示例 21-20 是 Caleb 的代码,只有一个变化和添加的标注。
示例 21-20. 使用@asynccontextmanager和loop.run_in_executor的示例
from contextlib import asynccontextmanager
@asynccontextmanager
async def web_page(url): # ①
loop = asyncio.get_running_loop() # ②
data = await loop.run_in_executor( # ③
None, download_webpage, url)
yield data # ④
await loop.run_in_executor(None, update_stats, url) # ⑤
async with web_page('google.com') as data: # ⑥
process(data)
①
被修饰的函数必须是一个异步生成器。
②
对 Caleb 的代码进行了小更新:使用轻量级的get_running_loop代替get_event_loop。
③
假设download_webpage是使用requests库的阻塞函数;我们在单独的线程中运行它以避免阻塞事件循环。
④
在此yield表达式之前的所有行将成为装饰器构建的异步上下文管理器的__aenter__协程方法。data的值将在下面的async with语句中的as子句后绑定到data变量。
⑤
yield之后的行将成为__aexit__协程方法。在这里,另一个阻塞调用被委托给线程执行器。
⑥
使用web_page和async with。
这与顺序的@contextmanager装饰器非常相似。请参阅“使用 @contextmanager”以获取更多详细信息,包括在yield行处的错误处理。有关@asynccontextmanager的另一个示例,请参阅contextlib文档。
现在让我们通过将它们与本地协程进行对比来结束异步生成器函数的覆盖范围。
异步生成器与本地协程
以下是本地协程和异步生成器函数之间的一些关键相似性和差异:
-
两者都使用
async def声明。 -
异步生成器的主体中始终包含一个
yield表达式—这就是使其成为生成器的原因。本地协程永远不包含yield。 -
本地协程可能会
return除None之外的某个值。异步生成器只能使用空的return语句。 -
本地协程是可等待的:它们可以被
await表达式驱动或传递给许多接受可等待参数的asyncio函数,例如create_task。异步生成器不可等待。它们是异步可迭代对象,由async for或异步推导驱动。
是时候谈谈异步推导了。
异步推导和异步生成器表达式
PEP 530—异步推导引入了在 Python 3.6 中开始使用async for和await语法的推导和生成器表达式。
PEP 530 定义的唯一可以出现在async def体外的构造是异步生成器表达式。
定义和使用异步生成器表达式
给定来自示例 21-18 的multi_probe异步生成器,我们可以编写另一个异步生成器,仅返回找到的域的名称。下面是如何实现的——再次使用启动了-m asyncio的异步控制台:
>>> from domainlib import multi_probe
>>> names = 'python.org rust-lang.org golang.org no-lang.invalid'.split()
>>> gen_found = (name async for name, found in multi_probe(names) if found) # ①
>>> gen_found
<async_generator object <genexpr> at 0x10a8f9700> # ②
>>> async for name in gen_found: # ③
... print(name)
...
golang.org python.org rust-lang.org
①
使用async for使其成为异步生成器表达式。它可以在 Python 模块的任何地方定义。
②
异步生成器表达式构建了一个async_generator对象——与multi_probe等异步生成器函数返回的对象完全相同。
③
异步生成器对象由async for语句驱动,而async for语句只能出现在async def体内或我在此示例中使用的魔术异步控制台中。
总结一下:异步生成器表达式可以在程序的任何地方定义,但只能在本地协程或异步生成器函数内消耗。
PEP 530 引入的其余构造只能在本地协程或异步生成器函数内定义和使用。
异步推导
PEP 530 的作者 Yury Selivanov 通过下面重现的三个简短代码片段证明了异步推导的必要性。
我们都同意我们应该能够重写这段代码:
result = []
async for i in aiter():
if i % 2:
result.append(i)
就像这样:
result = [i async for i in aiter() if i % 2]
此外,给定一个原生协程 fun,我们应该能够编写这样的代码:
result = [await fun() for fun in funcs]
提示
在列表推导式中使用 await 类似于使用 asyncio.gather。但是 gather 通过其可选的 return_exceptions 参数使您对异常处理有更多控制。Caleb Hattingh 建议始终设置 return_exceptions=True(默认为 False)。请查看 asyncio.gather 文档 了解更多信息。
回到神奇的异步控制台:
>>> names = 'python.org rust-lang.org golang.org no-lang.invalid'.split()
>>> names = sorted(names)
>>> coros = [probe(name) for name in names]
>>> await asyncio.gather(*coros)
[Result(domain='golang.org', found=True),
Result(domain='no-lang.invalid', found=False),
Result(domain='python.org', found=True),
Result(domain='rust-lang.org', found=True)]
>>> [await probe(name) for name in names]
[Result(domain='golang.org', found=True),
Result(domain='no-lang.invalid', found=False),
Result(domain='python.org', found=True),
Result(domain='rust-lang.org', found=True)]
>>>
请注意,我对名称列表进行了排序,以显示结果按提交顺序输出。
PEP 530 允许在列表推导式以及 dict 和 set 推导式中使用 async for 和 await。例如,这里是一个在异步控制台中存储 multi_probe 结果的 dict 推导式:
>>> {name: found async for name, found in multi_probe(names)}
{'golang.org': True, 'python.org': True, 'no-lang.invalid': False,
'rust-lang.org': True}
我们可以在 for 或 async for 子句之前的表达式中使用 await 关键字,也可以在 if 子句之后的表达式中使用。这里是在异步控制台中的一个集合推导式,仅收集找到的域:
>>> {name for name in names if (await probe(name)).found}
{'rust-lang.org', 'python.org', 'golang.org'}
由于 __getattr__ 运算符 .(点)的优先级较高,我不得不在 await 表达式周围加上额外的括号。
再次强调,所有这些推导式只能出现在 async def 主体内或在增强的异步控制台中。
现在让我们谈谈 async 语句、async 表达式以及它们创建的对象的一个非常重要的特性。这些构造经常与 asyncio 一起使用,但实际上它们是独立于库的。
异步超越 asyncio:Curio
Python 的 async/await 语言构造与任何特定的事件循环或库无关。¹⁷ 由于特殊方法提供的可扩展 API,任何足够有动力的人都可以编写自己的异步运行时环境和框架,以驱动原生协程、异步生成器等。
这就是大卫·比兹利在他的 Curio 项目中所做的。他对重新思考如何利用这些新语言特性构建一个从头开始的框架很感兴趣。回想一下,asyncio 是在 Python 3.4 中发布的,它使用 yield from 而不是 await,因此其 API 无法利用异步上下文管理器、异步迭代器以及 async/await 关键字所可能实现的一切。因此,与 asyncio 相比,Curio 具有更清晰的 API 和更简单的实现。
示例 21-21 展示了重新使用 Curio 编写的 blogdom.py 脚本(示例 21-1)。
示例 21-21. blogdom.py:示例 21-1,现在使用 Curio
#!/usr/bin/env python3
from curio import run, TaskGroup
import curio.socket as socket
from keyword import kwlist
MAX_KEYWORD_LEN = 4
async def probe(domain: str) -> tuple[str, bool]: # ①
try:
await socket.getaddrinfo(domain, None) # ②
except socket.gaierror:
return (domain, False)
return (domain, True)
async def main() -> None:
names = (kw for kw in kwlist if len(kw) <= MAX_KEYWORD_LEN)
domains = (f'{name}.dev'.lower() for name in names)
async with TaskGroup() as group: # ③
for domain in domains:
await group.spawn(probe, domain) # ④
async for task in group: # ⑤
domain, found = task.result
mark = '+' if found else ' '
print(f'{mark} {domain}')
if __name__ == '__main__':
run(main()) # ⑥
①
probe 不需要获取事件循环,因为…
②
…getaddrinfo 是 curio.socket 的顶级函数,而不是 loop 对象的方法—就像在 asyncio 中一样。
③
TaskGroup 是 Curio 中的一个核心概念,用于监视和控制多个协程,并确保它们都被执行和清理。
④
TaskGroup.spawn 是启动由特定 TaskGroup 实例管理的协程的方法。该协程由一个 Task 包装。
⑤
使用 async for 在 TaskGroup 上迭代会在每个完成时产生 Task 实例。这对应于 示例 21-1 中使用 for … as_completed(…): 的行。
⑥
Curio 开创了这种在 Python 中启动异步程序的明智方式。
要进一步扩展上述观点:如果您查看第一版 Fluent Python 中关于 asyncio 的代码示例,您会看到反复出现这样的代码行:
loop = asyncio.get_event_loop()
loop.run_until_complete(main())
loop.close()
Curio的TaskGroup是一个异步上下文管理器,替代了asyncio中的几个临时 API 和编码模式。我们刚刚看到如何遍历TaskGroup使得asyncio.as_completed(…)函数变得不再必要。另一个例子:这段来自“任务组”文档的代码收集了组中所有任务的结果:
async with TaskGroup(wait=all) as g:
await g.spawn(coro1)
await g.spawn(coro2)
await g.spawn(coro3)
print('Results:', g.results)
任务组支持结构化并发:一种并发编程形式,将一组异步任务的所有活动限制在单个入口和出口点。这类似于结构化编程,它避免了GOTO命令,并引入了块语句来限制循环和子程序的入口和出口点。当作为异步上下文管理器使用时,TaskGroup确保所有在内部生成的任务在退出封闭块时完成或取消,并处理引发的任何异常。
注意
结构化并发可能会在即将发布的 Python 版本中被asyncio采用。在PEP 654–异常组和 except*中出现了强烈迹象,该 PEP 已经获得了 Python 3.11 的批准。“动机”部分提到了Trio的“nurseries”,他们对任务组的命名方式:“受 Trio nurseries 启发,在asyncio中实现更好的任务生成 API 是这个 PEP 的主要动机。”
Curio的另一个重要特性是更好地支持在同一代码库中使用协程和线程进行编程——这在大多数复杂的异步程序中是必需的。使用await spawn_thread(func, …)启动线程会返回一个具有类似Task接口的AsyncThread对象。线程可以调用协程,这要归功于一个特殊的AWAIT(coro)函数——因为await现在是一个关键字,所以用全大写命名。
Curio还提供了一个UniversalQueue,可用于协调线程、Curio协程和asyncio协程之间的工作。没错,Curio具有允许其在一个线程中与另一个线程中的asyncio一起运行的功能,在同一进程中通过UniversalQueue和UniversalEvent进行通信。这些“通用”类的 API 在协程内外是相同的,但在协程中,您需要在调用前加上await前缀。
当我在 2021 年 10 月写这篇文章时,HTTPX是第一个与Curio兼容的 HTTP 客户端库,但我还不知道有哪些异步数据库库支持它。在Curio存储库中有一组令人印象深刻的网络编程示例,包括一个使用WebSocket的示例,以及实现RFC 8305—Happy Eyeballs并发算法的另一个示例,用于连接到 IPv6 端点,如果需要的话快速回退到 IPv4。
Curio的设计具有影响力。由 Nathaniel J. Smith 创建的Trio框架受Curio的启发很深。Curio可能也促使 Python 贡献者改进了asyncio API 的可用性。例如,在最早的版本中,asyncio用户经常需要获取并传递loop对象,因为一些基本函数要么是loop方法,要么需要一个loop参数。在 Python 的最新版本中,不再经常需要直接访问循环,实际上,几个接受可选loop参数的函数现在正在弃用该参数。
异步类型的类型注释是我们下一个讨论的主题。
异步对象的类型提示
本机协程的返回类型描述了在该协程上await时会得到什么,这是出现在本机协程函数体中return语句的对象类型。¹⁸
本章提供了许多带注释的本机协程示例,包括来自示例 21-21 的probe:
async def probe(domain: str) -> tuple[str, bool]:
try:
await socket.getaddrinfo(domain, None)
except socket.gaierror:
return (domain, False)
return (domain, True)
如果您需要注释一个接受协程对象的参数,则通用类型是:
class typing.Coroutine(Awaitable[V_co], Generic[T_co, T_contra, V_co]):
...
这种类型以及以下类型是在 Python 3.5 和 3.6 中引入的,用于注释异步对象:
class typing.AsyncContextManager(Generic[T_co]):
...
class typing.AsyncIterable(Generic[T_co]):
...
class typing.AsyncIterator(AsyncIterable[T_co]):
...
class typing.AsyncGenerator(AsyncIterator[T_co], Generic[T_co, T_contra]):
...
class typing.Awaitable(Generic[T_co]):
...
使用 Python ≥ 3.9,使用这些的collections.abc等价物。
我想强调这些通用类型的三个方面。
第一点:它们在第一个类型参数上都是协变的,这是从这些对象中产生的项目的类型。回想一下“协变法则”的规则#1:
如果一个正式类型参数定义了对象初始构造后传入对象的数据类型,那么它可以是逆变的。
第二点:AsyncGenerator和Coroutine在倒数第二个参数上是逆变的。这是事件循环调用以驱动异步生成器和协程的低级.send()方法的参数类型。因此,它是一个“输入”类型。因此,它可以是逆变的,根据“逆变法则”#2:
如果一个正式类型参数定义了对象初始构造后进入对象的数据类型,那么它可以是逆变的。
第三点:AsyncGenerator没有返回类型,与我们在“经典协程的通用类型提示”中看到的typing.Generator形成对比。通过引发StopIteration(value)来返回值是使生成器能够作为协程运行并支持yield from的一种技巧,正如我们在“经典协程”中看到的那样。在异步对象之间没有这种重叠:AsyncGenerator对象不返回值,并且与用typing.Coroutine注释的本机协程对象完全分开。
最后,让我们简要讨论异步编程的优势和挑战。
异步工作原理及其不足之处
本章结束部分讨论了关于异步编程的高层思想,无论您使用的是哪种语言或库。
让我们首先解释为什么异步编程如此吸引人的第一个原因,接着是一个流行的神话,以及如何处理它。
绕过阻塞调用
Node.js 的发明者 Ryan Dahl 通过说“我们完全错误地进行 I/O”来介绍他的项目的理念。他将阻塞函数定义为执行文件或网络 I/O 的函数,并认为我们不能像对待非阻塞函数那样对待它们。为了解释原因,他展示了表 21-1 的第二列中的数字。
表 21-1。从不同设备读取数据的现代计算机延迟;第三列显示了按比例的时间,这样我们这些慢人类更容易理解
| 设备 | CPU 周期 | 比例“人类”尺度 |
|---|---|---|
| L1 缓存 | 3 | 3 秒 |
| L2 缓存 | 14 | 14 秒 |
| RAM | 250 | 250 秒 |
| 磁盘 | 41,000,000 | 1.3 年 |
| 网络 | 240,000,000 | 7.6 年 |
要理解表 21-1 的意义,请记住具有 GHz 时钟的现代 CPU 每秒运行数十亿个周期。假设一个 CPU 每秒运行恰好 10 亿个周期。该 CPU 可以在 1 秒内进行超过 3.33 亿次 L1 缓存读取,或者在同一时间内进行 4 次(四次!)网络读取。表 21-1 的第三列通过将第二列乘以一个常数因子来将这些数字放入透视中。因此,在另一个宇宙中,如果从 L1 缓存读取需要 3 秒,那么从网络读取将需要 7.6 年!
表 21-1 解释了为什么对异步编程采取纪律性方法可以导致高性能服务器。挑战在于实现这种纪律。第一步是认识到“I/O 绑定系统”是一个幻想。
I/O 绑定系统的神话
一个常见的重复的梗是异步编程对“I/O 绑定系统”有好处。我以艰难的方式学到,没有“I/O 绑定系统”。你可能有 I/O 绑定函数。也许你系统中绝大多数函数都是 I/O 绑定的;即它们花费更多时间等待 I/O 而不是处理数据。在等待时,它们将控制权让给事件循环,然后事件循环可以驱动其他挂起的任务。但不可避免地,任何非平凡系统都会有一些部分是 CPU 绑定的。即使是微不足道的系统在压力下也会显露出来。在“讲台”中,我讲述了两个异步程序的故事,它们因 CPU 绑定函数减慢事件循环而严重影响性能。
鉴于任何非平凡系统都会有 CPU 绑定函数,处理它们是异步编程成功的关键。
避免 CPU 绑定陷阱
如果你在规模上使用 Python,你应该有一些专门设计用于检测性能回归的自动化测试,一旦它们出现就立即检测到。这在异步代码中至关重要,但也与线程化的 Python 代码相关—因为 GIL。如果你等到减速开始困扰开发团队,那就太晚了。修复可能需要一些重大改变。
当你确定存在 CPU 占用瓶颈时,以下是一些选项:
-
将任务委托给 Python 进程池。
-
将任务委托给外部任务队列。
-
用 Cython、C、Rust 或其他编译为机器码并与 Python/C API 接口的语言重写相关代码,最好释放 GIL。
-
决定你可以承受性能损失并且什么都不做—但记录这个决定以便以后更容易恢复。
外部任务队列应该在项目开始时尽快选择和集成,这样团队中的任何人在需要时都不会犹豫使用它。
最后一个选项—什么都不做—属于技术债务类别。
并发编程是一个迷人的话题,我很想写更多关于它的内容。但这不是本书的主要焦点,而且这已经是最长的章节之一,所以让我们结束吧。
章节总结
对于常规的异步编程方法的问题在于它们都是全有或全无的命题。你要重写所有代码,以便没有任何阻塞,否则你只是在浪费时间。
Alvaro Videla 和 Jason J. W. Williams,《RabbitMQ 实战》
我选择这个章节的引语有两个原因。在高层次上,它提醒我们通过将慢任务委托给不同的处理单元来避免阻塞事件循环,从简单的线程到分布式任务队列。在较低层次上,它也是一个警告:一旦你写下第一个async def,你的程序不可避免地会有越来越多的async def、await、async with和async for。并且使用非异步库突然变得具有挑战性。
在第十九章中简单的spinner示例之后,我们的主要重点是使用本机协程进行异步编程,从blogdom.py DNS 探测示例开始,接着是awaitables的概念。在阅读flags_asyncio.py的源代码时,我们发现了第一个异步上下文管理器的示例。
flag 下载程序的更高级变体引入了两个强大的函数:asyncio.as_completed 生成器和loop.run_in_executor 协程。我们还看到了使用信号量限制并发下载数量的概念和应用—这是对表现良好的 HTTP 客户端的预期。
服务器端异步编程通过mojifinder示例进行展示:一个FastAPI web 服务和tcp_mojifinder.py—后者仅使用asyncio和 TCP 协议。
异步迭代和异步可迭代是接下来的主要话题,包括async for、Python 的异步控制台、异步生成器、异步生成器表达式和异步推导式。
本章的最后一个示例是使用Curio框架重写的blogdom.py,以演示 Python 的异步特性并不局限于asyncio包。Curio还展示了结构化并发的概念,这可能对整个行业产生影响,为并发代码带来更多的清晰度。
最后,在“异步工作原理及其不足之处”下的章节中讨论了异步编程的主要吸引力,对“I/O-bound 系统”的误解,以及如何处理程序中不可避免的 CPU-bound 部分。
进一步阅读
大卫·比兹利在 PyOhio 2016 年的主题演讲“异步中的恐惧和期待”是一个精彩的、现场编码的介绍,展示了由尤里·谢利万诺夫在 Python 3.5 中贡献的async/await关键字所可能带来的语言特性的潜力。在演讲中,比兹利曾抱怨await不能在列表推导式中使用,但谢利万诺夫在同年稍后实现了PEP 530—异步推导式,并在 Python 3.6 中修复了这个问题。除此之外,比兹利演讲中的其他内容都是永恒的,他演示了本章中我们看到的异步对象是如何工作的,而无需任何框架的帮助——只需一个简单的run函数,使用.send(None)来驱动协程。仅在最后,比兹利展示了Curio,这是他在那一年开始的一个实验,看看在没有回调或未来基础的情况下,只使用协程能走多远。事实证明,你可以走得很远——正如Curio的演变和后来由纳撒尼尔·J·史密斯创建的Trio所证明的那样。Curio的文档中有链接指向比兹利在该主题上的更多讲话。
除了创建Trio,纳撒尼尔·J·史密斯还撰写了两篇深度博客文章,我强烈推荐:“在后 async/await 世界中对异步 API 设计的一些思考”,对比了Curio的设计与asyncio的设计,以及“关于结构化并发的笔记,或者:Go 语句为何有害”,关于结构化并发。史密斯还在 StackOverflow 上对问题“asyncio 和 trio 之间的核心区别是什么?”给出了一篇长而富有信息量的回答。
要了解更多关于asyncio包的信息,我在本章开头提到了我所知道的最好的书面资源:由尤里·谢利万诺夫在 2018 年开始的官方文档以及卡勒布·哈廷的书籍Using Asyncio in Python(O’Reilly)。在官方文档中,请务必阅读“使用 asyncio 进行开发”:记录了asyncio调试模式,并讨论了常见的错误和陷阱以及如何避免它们。
对于异步编程的一个非常易懂的、30 分钟的介绍,以及asyncio,可以观看米格尔·格林伯格在 PyCon 2017 上的“面向完全初学者的异步 Python”。另一个很好的介绍是迈克尔·肯尼迪的“揭秘 Python 的 Async 和 Await 关键字”,其中我了解到了unsync库,提供了一个装饰器来将协程、I/O-bound 函数和 CPU-bound 函数的执行委托给asyncio、threading或multiprocessing。
在 EuroPython 2019 上,Lynn Root —— PyLadies 的全球领导者 —— 呈现了优秀的 “高级 asyncio:解决实际生产问题”,这是她在 Spotify 担任工程师的经验所得。
在 2020 年,Łukasz Langa 制作了一系列关于 asyncio 的优秀视频,从 “学习 Python 的 AsyncIO #1—异步生态系统” 开始。Langa 还制作了非常酷的视频 “AsyncIO + 音乐” 为 2020 年的 PyCon,不仅展示了 asyncio 在一个非常具体的事件驱动领域中的应用,还从基础开始解释了它。
另一个被事件驱动编程主导的领域是嵌入式系统。这就是为什么 Damien George 在他的 MicroPython 解释器中为微控制器添加了对 async/await 的支持。在 2018 年的澳大利亚 PyCon 上,Matt Trentini 展示了 uasyncio 库,这是 MicroPython 标准库中 asyncio 的一个子集。
想要更深入地思考 Python 中的异步编程,请阅读 Tom Christie 的博文 “Python 异步框架—超越开发者部落主义”。
最后,我推荐阅读 Bob Nystrom 的 “你的函数是什么颜色?”,讨论了普通函数与异步函数(即协程)在 JavaScript、Python、C# 和其他语言中不兼容的执行模型。剧透警告:Nystrom 的结论是,做对了的语言是 Go,那里所有函数都是同一颜色。我喜欢 Go 的这一点。但我也认为 Nathaniel J. Smith 在他写的 “Go 语句有害” 中有一定道理。没有什么是完美的,而并发编程总是困难的。
¹ Videla & Williams 的 RabbitMQ 实战(Manning),第四章,“用 Rabbit 解决问题:编码和模式”,第 61 页。
² Selivanov 在 Python 中实现了 async/await,并撰写了相关的 PEPs 492、525 和 530。
³ 有一个例外:如果你使用 -m asyncio 选项运行 Python,你可以直接在 >>> 提示符下使用 await 驱动本机协程。这在 “使用 Python 的异步控制台进行实验” 中有解释。
⁴ 对不起,我忍不住了。
⁵ 我写这篇文章时,true.dev 的年费为 360 美元。我看到 for.dev 已注册,但未配置 DNS。
⁶ 这个提示是由技术审阅员 Caleb Hattingh 的评论原文引用。谢谢,Caleb!
⁷ 感谢 Guto Maia 指出,在他阅读本章第一版草稿时,信号量的概念没有得到解释。
⁸ 关于这个问题的详细讨论可以在我在 python-tulip 群组中发起的一个主题中找到,标题为 “asyncio.as_completed 还可能产生哪些其他 futures?”。Guido 回应,并就 as_completed 的实现以及 asyncio 中 futures 和协程之间的密切关系提供了见解。
⁹ 屏幕截图中的带框问号不是你正在阅读的书籍或电子书的缺陷。这是 U+101EC—PHAISTOS DISC SIGN CAT 字符,这个字符在我使用的终端字体中缺失。Phaistos 圆盘 是一件古代文物,上面刻有象形文字,发现于克里特岛。
¹⁰ 你可以使用另一个 ASGI 服务器,如 hypercorn 或 Daphne,而不是 uvicorn。查看官方 ASGI 文档中关于 实现 的页面获取更多信息。
¹¹ 感谢技术审阅员 Miroslav Šedivý指出在代码示例中使用pathlib的好地方。
¹² 如第八章中所述,pydantic在运行时强制执行类型提示,用于数据验证。
¹³ 截至 2021 年 10 月,问题#5535 已关闭,但自那时起 Mypy 并没有发布新版本,因此错误仍然存在。
¹⁴ 技术审阅员 Leonardo Rochael 指出,可以使用loop.run_with_executor()在supervisor协程中将构建索引的工作委托给另一个线程,因此服务器在构建索引的同时即可立即接受请求。这是正确的,但在这个示例中,查询索引是这个服务器唯一要做的事情,所以这并不会带来很大的收益。
¹⁵ 这对于像 Node.js 控制台这样的实验非常有用。感谢 Yury Selivanov 为异步 Python 做出的又一次出色贡献。
¹⁶ 请参阅RFC 6761—特殊用途域名。
¹⁷ 这与 JavaScript 相反,其中async/await被硬编码到内置事件循环和运行时环境中,即浏览器、Node.js 或 Deno。
¹⁸ 这与经典协程的注解不同,如“经典协程的通用类型提示”中所讨论的。
¹⁹ 视频:“Node.js 简介”在 4:55 处。
²⁰ 直到 Go 1.5 发布之前,使用单个线程是默认设置。多年前,Go 已经因为能够实现高度并发的网络系统而赢得了当之无愧的声誉。这是另一个证据,表明并发不需要多个线程或 CPU 核心。
²¹ 不管技术选择如何,这可能是这个项目中最大的错误:利益相关者没有采用 MVP 方法——尽快交付一个最小可行产品,然后以稳定的步伐添加功能。